
基于CLAHE的PCA-LDA典型地域人脸识别研究
2024-01-05 13:22:40何李蒋行国李嘉利李德才
四川轻化工大学学报(自然科学版) 2023年6期
何李,蒋行国,2,李嘉利,李德才
(1.四川轻化工大学自动化与信息工程学院,四川 宜宾 644000;2.人工智能四川省重点实验室,四川 宜宾 644000)
引言
人类学的相关研究表明,中国南方和北方典型地域人脸虽然有年龄、性别的差异,但整体上相同地域内的却有着同一性[1]。相比南方人,北方人具有头部更宽,两下颌角间更宽,且鼻较窄,面较狭等普遍特征[1],这些典型性差异也为人脸地域研究奠定了基础。
目前人脸特征提取方法有很多,主要包括局部特征提取和全局特征提取两大类。局部特征提取主要有局部二值模式(LBP)[1]、定向梯度直方图(HOG)[2]、Gabor滤波特征提取[3]等。全局特征提取主要有主成分分析(PCA)[4]、线性判别分析(LDA)[5]等。而人脸的典型地域特征研究作为人脸识别的一个重要研究方向,通过研究不同地域面部的地域特征,以提高人脸识别的深度,这在刑事侦破、身份识别等领域具有重大应用前景。因此,使用更高效、快捷的方法分析人脸典型地域特征,对人脸地域研究的开展具有重要意义。国外,如Islam等[6]使用各种统计模型分析了面部特征和属性的地理依赖性。Bessinger等[7]采用一种双组件生成网络架构(GPS2Face),通过面部特征合成了世界不同地域可能的人脸。当前,国内的人脸地域特征研究仍停留在提取面部几何特征以分类不同地域人脸的阶段,如李伟红等[8]对区域内的人脸提取几何特征进行最小误差贝叶斯分类,对东北和西南两大典型区域人脸进行了分类。张红梅等[9]通过自动提取算法抽取面部几何特征,再使用感知器算法对华北和西南两大区域进行了分类。刘嘉敏等[10]通过数码相机系统将分类区域内的人脸图像采样,然后用区域几何特征识别技术提取特征进行分类。Gong等[11]通过3D数码相机对按照中国行政区划分的人脸图像进行采样并登记到人脸图像库中,再采用几何方法提取特征识别不同地区人脸。文献[8-11]为重庆大学智能化信息系统实验室开展的地域探索性研究,其中文献[8]对东北地域分类准确率为80.0%,西南分类准确率为72.2%,但实验数据库未公开且人脸数据样本相对较少,仍需要扩大数据样本进一步研究。
在人脸特征研究中,特征脸作为一种基于主成分分析(PCA)的特征识别技术被广泛应用,它能够在减少需要分析的指标的同时,达到使用少量的特征信息进行全面分析的目的。因此,为更充分地获取反映地域特征的人脸轮廓与五官信息,同时兼顾局部与全局特征,提出使用限制对比度自适应直方图均衡化(CLAHE)局部增强人脸特征,然后通过PCA算法提取全局特征并降维,并结合LDA 算法缩小样本类间距离,最后将优化的支持向量机(SVM)用于地域人脸识别,验证提出的算法在分类地域人脸方面的有效性。
1 限制对比度自适应直方图均衡化的PCALDA算法
基于限制对比度自适应直方图均衡化的PCALDA算法系统框架如图1所示,其算法流程如下:
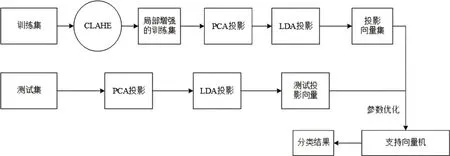
图1 系统框架
1)将训练图像分割为一系列均匀子块,通过CLAHE增强局部特征;
2)将处理后的训练图像执行PCA 算法,选择前d个特征值对应的特征向量,归一化后组成投影向量;
3)将投影向量输入LDA 算法中,寻找最佳投影方向形成新的投影向量集;
4)测试图像也先后经过PCA 与LDA 降维生成投影向量;
5)将图像投影的特征向量集输入参数优化的SVM进行分类。
1.1 限制对比度自适应直方图均衡化(CLAHE)
直方图均衡化是常用于调节图像对比度的方法,通过一定的变换,使得输出图像灰度直方图达到均匀分布的效果,但原始的直方图均衡化方法未考虑局部,会导致过度增强从而丢失有用信息。为避免这一问题,采用CLAHE[12],该方法是自适应直方图均衡化(AHE)的改进,能有效增强人脸局部特征,突出细节信息并减少噪声的干扰。CLAHE 实现步骤如图2 所示,首先将原图像划分为m×n个局部子区域并计算每个子块的灰度直方图,接着对每个子区域进行对比度限制并剪切灰度直方图,然后将每个超出限幅值的多余像素均分到其他灰度中,使直方图自适应均衡化,最后通过插值处理得到增强图像。
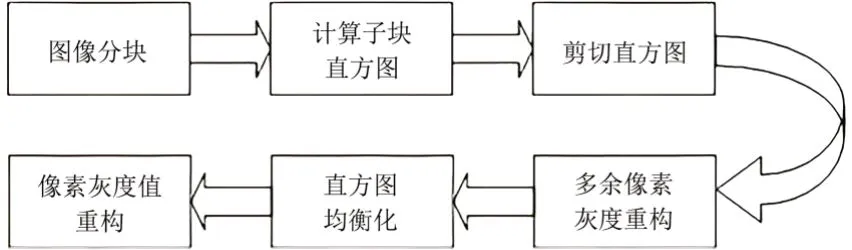
图2 CLAHE实现步骤
分块子区域越大,丢失的细节信息更多,因此选用划分8 × 8 的子区域。图3 所示为原始图像与采用AHE 和CLAHE 两种方法的对比图。从图3 可知,传统的自适应直方图均衡化后生成的图像与原始图像对比度明显提高,但增加了噪声,而经过CLAHE处理后人脸细节特征明显增强。
1.2 PCA-LDA算法
PCA 通过降维将人脸转换为一系列核心特征,即特征脸。将数据从高维空间映射到低维空间,能够消除样本之间的相关性与噪声[13]。设有n张人脸图像,xi表示第i幅人脸图像形成的人脸向量,则样本的均值向量为:
所有样本的协方差矩阵为:
采用奇异值分解(SVD)求解该协方差矩阵的特征值以及特征向量。由SVD 可知,矩阵S=XXT与矩阵P=XTX具有r个相同的非零特征值,设为λi(i=1,2,…,r),同时令矩阵P和矩阵S的特征向量分别为pi和si,由此得出的正交归一化特征向量为:协方差矩阵中特征值大小与特征向量息息相关。因此,选择包含信息最多的特征向量组成子集,即为特征脸空间。
在PCA 后,通过线性判别分析(LDA)优化算法,能使样本降维的同时,类间离散度更大,类内离散度更小[14]。令总均值向量为c,各类样本的均值为ci,经PCA 变换后的人脸图像为aij(aij表示第i类的第j个样本),总共包括m类,每类有k个样本。则人脸样本的类内离散矩阵Sw与类间离散矩阵Sb分别为:
由此可得出特征值λ与对应的特征向量w即最佳投影方向之间关系:
选取n(n为降维后的维数)个最大特征值对应的特征向量W=[w1,w2,w3,…,wn]作为投影方向,该投影矩阵W能很好地表示样本特征[15]。
1.3 支持向量机(SVM)
支持向量机主要用于二分类问题,其分类思想以样本与超平面的距离作为确信度,确信度高的相比确信度低的更容易区分[16]。而SVM 目标就是找到一个超平面H使得两类样本有效分开,并加大类间距离,分类原理如图4所示。
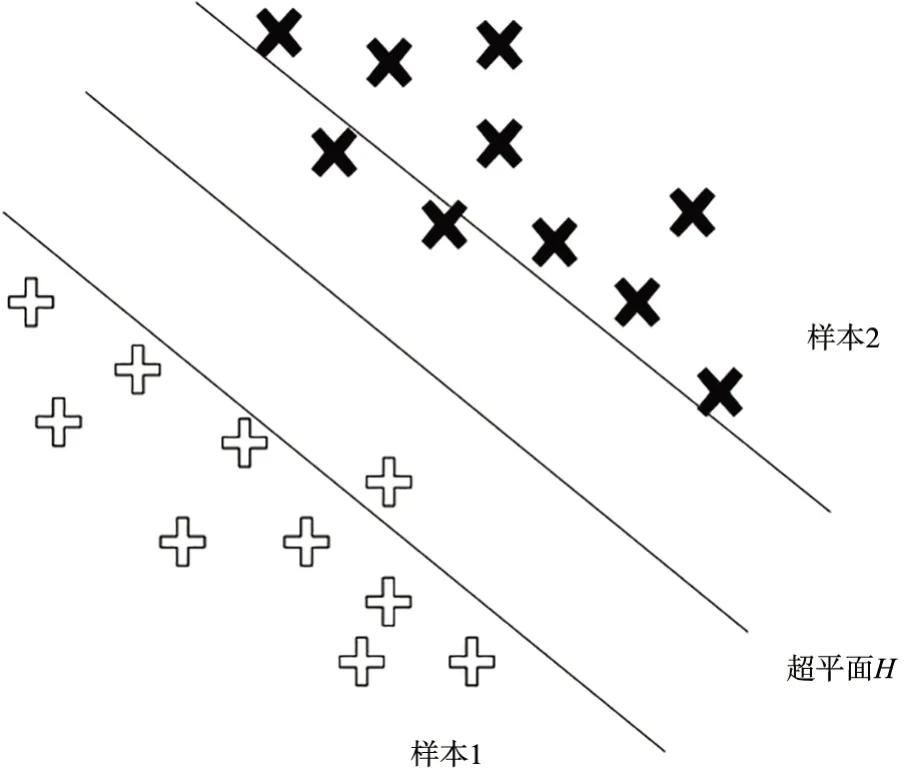
图4 SVM分类原理图
对于空间中的非线性问题,需要应用核函数技术[16-17]。常用的核函数有如下3 种(其中x与z表示两个样本)。
1)高斯径 向基核函数(RBF):K(x,z)=,参数σ决定了函数作用范围。
2)多项式 核函数(polynomial):K(x,z)=(γ(x,z)+c)d,其中d为多项式的阶,c为偏置系数,γ为核函数宽度。
3)sigmoid 核函数:K(x,z)=tanh(η(x,z)+c),与径向基函数类似,但需要选择η和c两个参数。
核函数参数的选择需要采用优化算法,因此选用交叉验证与网格搜索法进行参数寻优[18]。网格搜索法首先对惩罚因子和高斯核函数设定一系列参数,然后使每对参数遍历模型进行训练,最终模型参数选用效果最好的一对参数。交叉验证将训练数据集均分为k份,每次选取其中一份作为测试数据,总共经过k次训练。每个模型产生一个性能指标,再对所有性能指标求均值得出模型的最优参数。本文采取网格法设定参数变化范围,再将不同组合的参数运用交叉验证。
2 实验与结果
2.1 实验设置
2.1.1 实验数据
由于缺乏能够采用的公开数据集,因此采取网络爬取南北典型地域人脸图片,其中,选取吉林、辽宁、黑龙江等作为典型北方地域,广东、广西等作为典型南方地域,所搜集数据能够保证不同地域的均衡。为标准化人脸,使用机器学习库Dlib 裁剪人脸,统一裁剪为224×224大小,然后将具有清晰人脸的图片筛选出,转换为灰度图像,最后获得南方和北方地域各70 组人脸图像,每组包括10 张图片。两个地域分别取前50 组为训练集,剩下的20 组为测试集,选取测试集数据与训练集无重合。部分人脸样本如图5所示。
2.1.2 实验环境
实验环境硬件平台为Windows 10,64 位操作系统,内存为8 GB,NVIDIA GeForce GTX 1050Ti和 Intel(R) Core(TM) i5—10400F CPU @ 2.90GHz,软件为python3.6、Pytorch深度学习框架。
2.2 基于CLAHE的特征脸分析
将训练数据中的图像进行CLAHE 增强,使图像局部特征更明显,再将其转换为向量形式投影到新的特征空间。
地域特征脸对比如图6 所示,图中9 张人脸图像为降低维数后产生的“特征脸”,图6(a)所示为原始PCA 所生成,图6(b)所示为PCA 结合AHE 后产生的“特征脸”,而经过CLAHE 局部增强后的“特征脸”如图6(c)所示,可以看出,经过两种直方图均衡化后,面部都有一定的增强,而图6(c)相比图6(b)五官轮廓更加清晰,能更好地表示出该类人脸所包含的地域特征。

图6 地域特征脸对比
实验通过主成分分析提取不同个数的特征向量,然后使用SVM 进行分类预测。核函数选用RBF,参数c和gamma运用Sklearn库的Grid-SearchCV 函数进行网格搜索法寻优,参数范围设置为:
表1 和图7 所示为选取不同特征向量经过SVM分类的识别率,由此可看出原始PCA 算法识别率最高达到了64.0%。结合AHE 的PCA 算法在取前300个特征向量时最高识别率达到65.5%,而结合CLAHE 的PCA 算法随特征向量增加识别率总体上升,在取前300 个特征向量时识别率达到了68.5%,特征向量超过300 后准确率下降。因此,CLAHE 算法能够增强人脸地域特征,再结合PCA 算法,提取的特征更有表现力,识别率有明显提高。
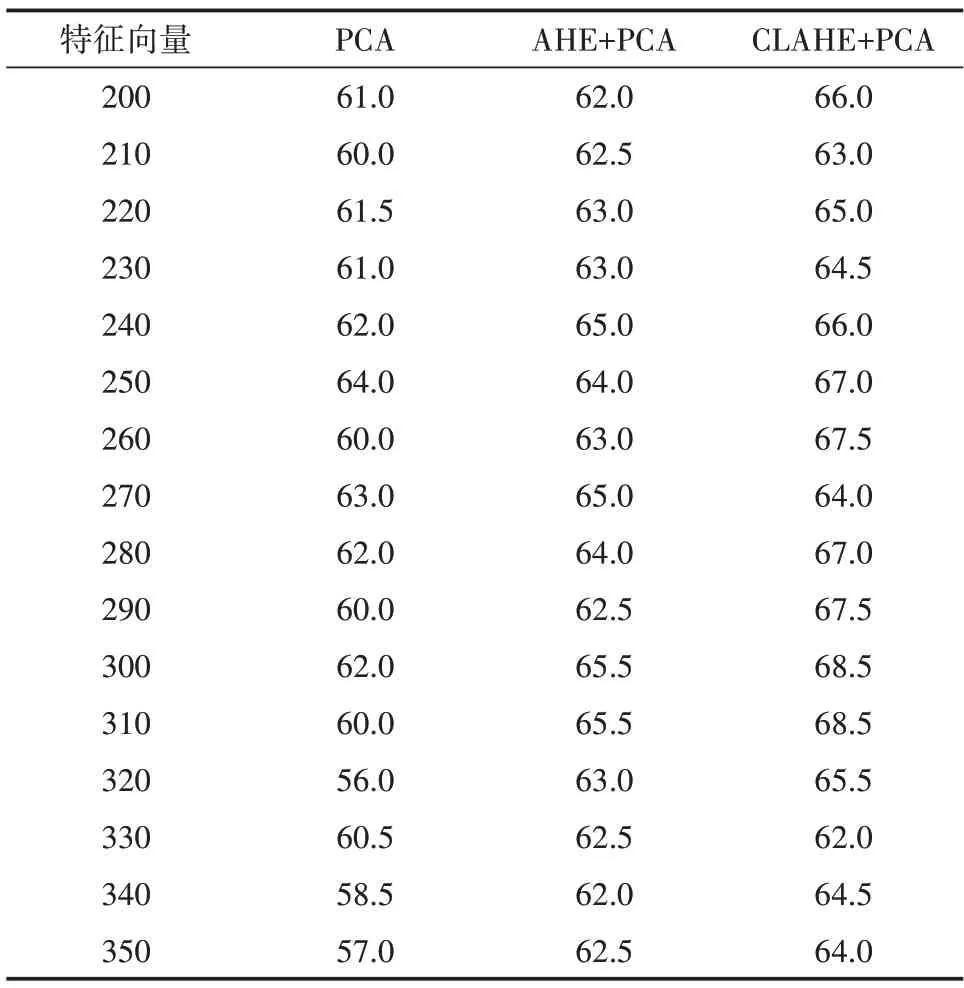
表1 PCA改进算法不同特征向量下识别率 %
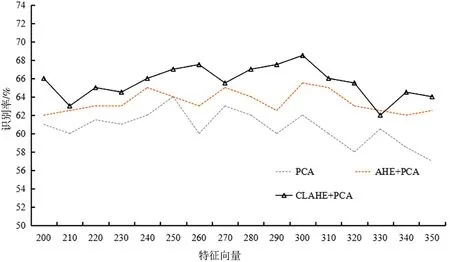
图7 不同算法的识别率
2.3 基于CLAHE的PCA-LDA算法
经过PCA 降维后,加入LDA 能弥补PCA 不能获取样本类别信息的缺点,并能对样本再次降低维度。设定PCA 取前300 个特征向量,LDA 依次选取不同的特征向量,随着特征向量的增加,识别率先呈上升趋势,当特征向量取120 时获得最大平均识别率为70.5%,之后随着特征向量增加准确率逐渐降低,实验结果如图8所示。
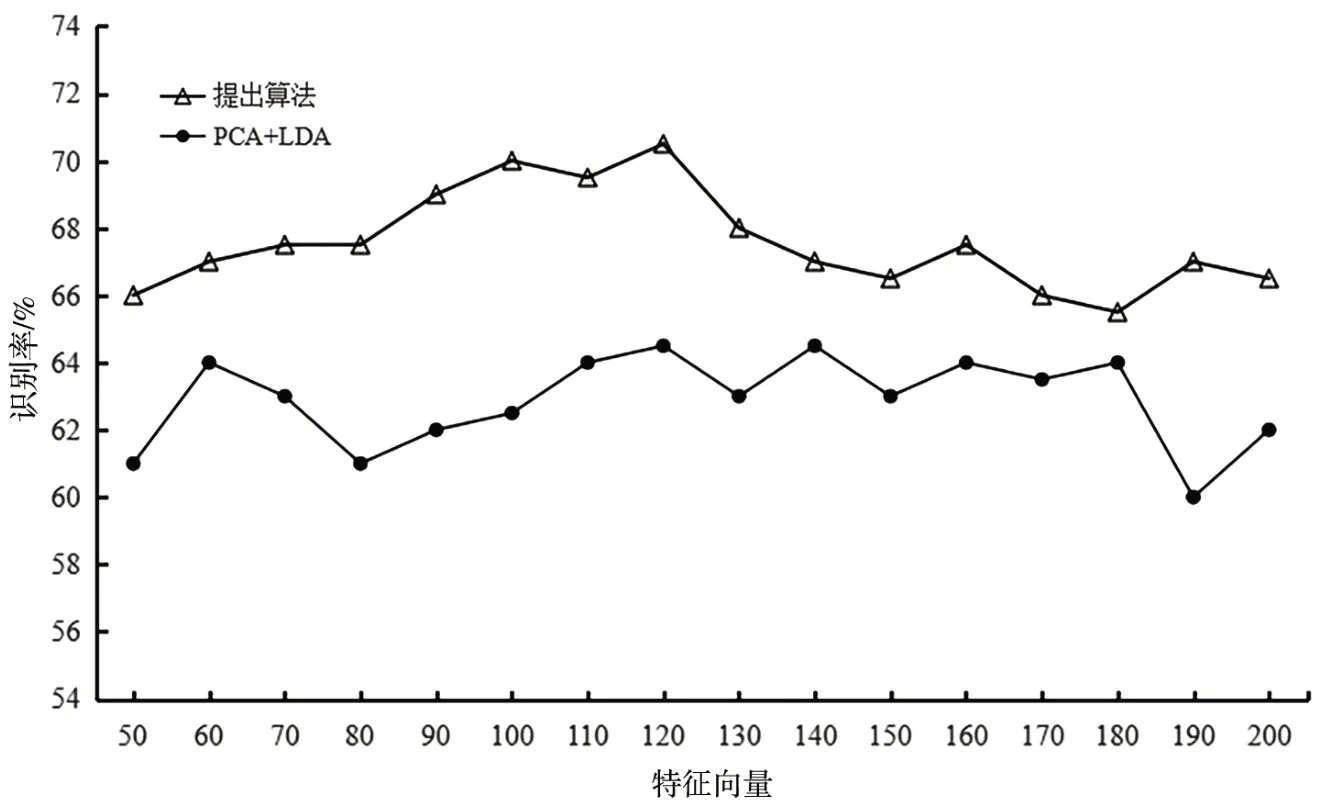
图8 LDA取不同特征向量与识别率的关系
通过设置多个实验,对比提出的算法与其他经典算法对典型地域特征的分类准确率,其中,分类器SVM 设定同一参数,实验结果见表2。由表2 可知,实验1~3 的局部二值模式(LBP)与方向梯度直方图(HOG)所提取的特征信息量少,用于分类地域人脸准确率大大低于PCA 算法;实验4~7 与提出算法进行消融实验对比,验证了提出算法的有效性。结合南方和北方典型地域混淆矩阵(图9)观察算法在各个类别上的表现,混淆矩阵的行标签表示预测值,列标签表示真实值,可以看出,该算法在南方和北方典型区域的分类识别率分别达到64.0%和77.0%。
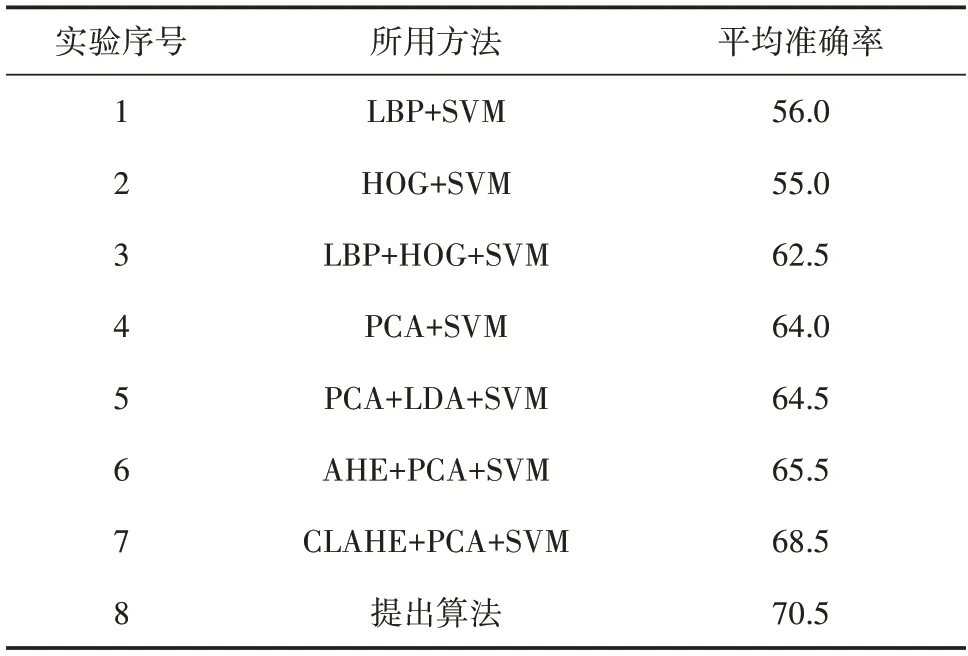
表2 不同实验平均准确率 %
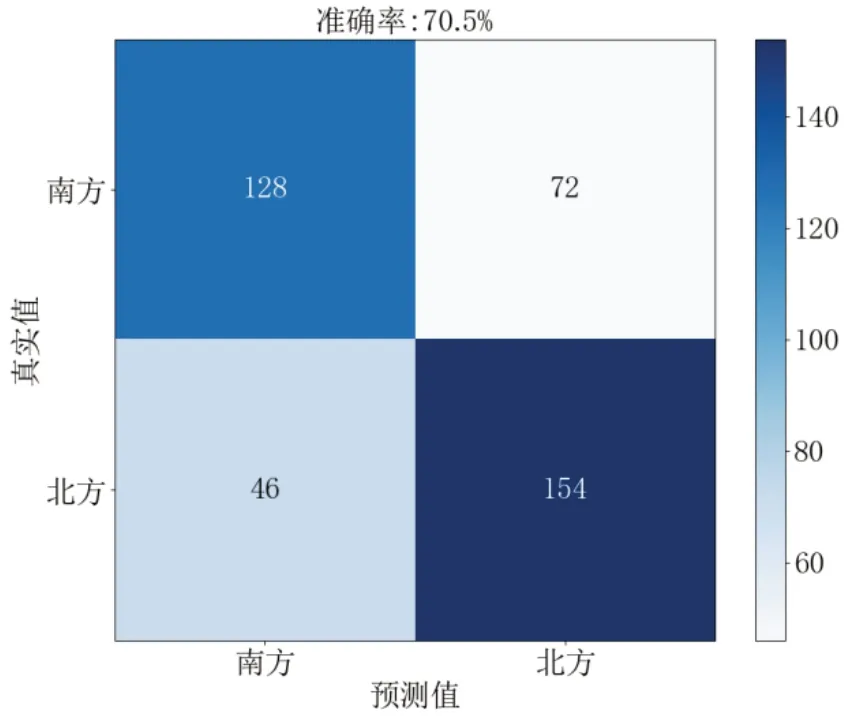
图9 南方和北方典型地域混淆矩阵
3 结束语
人脸典型地域特征研究在理论和应用方面都具有广阔的前景,通过构建一个中国南北典型地域的人脸数据集,并从全局与局部特征的角度进行了分析。为增强提取的地域特征信息,使用CLAHE技术增强人脸图像的局部对比度并降噪,之后通过PCA 算法将高维空间人脸图像投影到低维空间,获得特征脸,再结合LDA 算法寻找最佳投影方向,最后运用优化参数的SVM 分类器进行分类。最终结果表明,相较于其他传统算法,本文提出的算法能更有效地分类地域人脸。
猜你喜欢
高中数理化(2024年1期)2024-03-02 17:52:40
九江职业技术学院学报(2022年1期)2022-12-02 09:46:54
湘潭大学自然科学学报(2022年2期)2022-07-28 05:26:40
保定学院学报(2022年2期)2022-04-07 02:26:50
计算机工程(2020年3期)2020-03-19 12:24:50
中国听力语言康复科学杂志(2019年3期)2019-06-24 09:51:20
摄影之友(影像视觉)(2018年12期)2019-01-28 09:01:02
中国交通信息化(2018年3期)2018-06-13 03:27:58
许昌学院学报(2018年4期)2018-05-02 12:27:37
中华建设(2017年1期)2017-06-07 02:56:14
