
改进EfficientNet图像分类的恶意流量检测模型
2024-01-05 13:22周子云黄洪
四川轻化工大学学报(自然科学版) 2023年6期
周子云,黄洪,2
(1.四川轻化工大学计算机科学与工程学院,四川 宜宾 644000;2.桥梁无损检测与工程计算四川省高校重点实验室,四川 宜宾 644000)
引言
随着网络流量的激增,流量检测成为保障我们网络安全的重要组成部分,目前流量检测技术主要包括机器学习、深度学习、强化学习和可视化技术等[1]。其中基于经典机器学习网络流量分类方法成为恶意流量检测的主流方法之一[2]。这种检测方法的准确率主要依赖于特征集标签的设计,然而设计合适的特征标签仍然是目前很难解决的问题[3-4]。随着深度学习的发展,其在处理和识别图像的方法上取得了巨大进步,研究者们开始使用深度学习将数据原始特征直接从图像中提取出来,既能解决人工进行标记标签的困难,又能提高检测效率[5]。
Wang等[6]提出一种基于卷积神经网络的恶意流量分类方法,将流量转换为图像进行分类,该方法不需要人工对恶意流量进行特征标记,因而提高了检测的效率。孔令爽[7]采用卷积神经网络进行特征提取和学习。它主要是对预处理后的数据通过概率计算的方式进行特征学习。通过降低数据的维度,可以使之后的入侵检测更为准确。陈红松等[8]提出将多条流量样本转换为灰度图像并利用残差神经网络和双向长短期记忆网络(LSTM)融合对图像进行分类,在对图像样本特征降维的同时使其分类,准确率达到96.77%,同时也兼顾了效率。李道全等[9]将孪生神经网络与恶意流量检测相结合,在解决样本不均衡问题的同时,依然有着良好的检测效果。杨铭等[10]提出一种采用SimHash 方法的卷积神经网络模型来识别恶意流量,相较于传统的机器学习模型有一定提高。谭茹涵等[11]提出基于图像特征融合的恶意代码检测方法,在用于多特征的恶意代码检测上有着不错的效果。龙墨澜等[12]提出一种基于代码可视化的恶意代码检测方法,该方法通过使用样本期望体积来调整不同恶意代码家族在模型训练过程中的权重参数,缓解模型过拟合的影响,从而提高模型的性能。王悦等[13]提出一种融合注意力机制的EfficientNet 网络模型,实现图像端到端的自动分类,并且模型使用Focal Loss 损失函数可以解决样本不均衡问题,使模型最终分类准确率达到95.2%,在糖尿病医学领域得到了很好的应用。但是经过分析,文献[6]虽然采用深度学习的技术应用于图像流量的分类,但未考虑因图像样本的不平衡、特征提取的难易度不同导致特征提取不佳的问题。文献[7-8]虽然降低图像数据集的维度,使得图像的特征更好地提取,但在降低维度的同时也丢失了部分重要特征,导致特征提取不完整,检测效果不佳。文献[9]虽然解决样本不均衡的问题,但如果有新的恶意流量与现有恶意流量完全不同时,检测效果会很差。文献[10]虽然使用了多重特征选择的方法,使模型在提取多维度特征时有一定的优势,但没有考虑特征提取时因样本的复杂度导致特征提取的难易度问题,这会使得模型在预测复杂度不一样的样本时,表现不佳。文献[11]虽然对多特征样本提取确实有很大的提高,但在提取特征时将一些冗余特征一起提取是非常没有必要的,去掉这些冗余特征,模型的效果应该会更好。文献[12]虽然通过使用样本期望体积来调整不同恶意代码家族在模型训练过程中的权重参数,缓解模型过拟合的影响,但模型对于样本特征降维处理后会导致特征通道的维度降低,使网络的性能变差。
综上所述,数据在转换成图像后,会出现图像样本因复杂度不同导致的不平衡问题,这会使模型由于图像样本不平衡,导致准确率下降。针对此类问题,本文提出了一种改进EfficientNet 图像分类的恶意流量检测模型。用改进的EfficientNet 模型来提取流量图像中包含的特征,在神经网络中将注意力机制SE 模块替换为ECA 模块,以使模型在分类时更专注于图像复杂度更高的难分样本,改进一维卷积自适应地确定卷积核的大小,避免降维所导致的特征丢失,提高网络模型的精度。同时,将原有交叉熵损失函数替换为Focal Loss 损失函数来解决难易样本不平衡的问题,以进一步提高检测的准确率和精确度。
1 相关理论
1.1 EfficientNet模型
EfficientNet 模型[14-15]用更少的训练量达到更高的识别度。具体特点是运用残差神经网络增加神经网络深度,通过更深层的神经网络来实现特征提取。通过改变每一层提取的特征层数,实现更多层的特征提取,得到更多的特征。通过增大输入图片的分辨率使网络可以学习和表达更丰富的信息,这有利于提高模型精确度。本文则是采用EfficientNet作为基线网络并在其基础上进行改进。
在EfficientNet 网络结构中,核心为MBConv 模块[16],其中包含深度可分离卷积,批处理归一化以及Swish 激活函数,并引入SE 通道注意力模块,使得浅层网络也能通过全局感受野来捕获图像特征并对图像进行描述。MBConv 网络模型结构如图1所示。
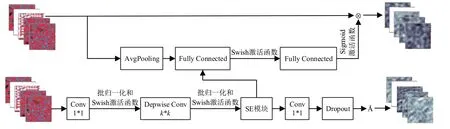
图1 MBConv结构图
1.2 SE模块
SE(squeeze-excitation)模块[17-18]是MBConv网络模型结构上的一种注意力机制。它是通过自动学习来获取每个通道的重要程度,然后根据重要程度为每个通道赋予权值,使得神经网络重点关注权值大的通道并学习有用的特征。SE 模块结构如图2所示。
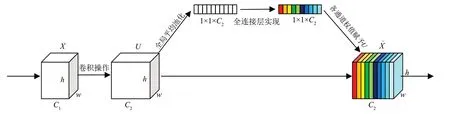
图2 SE模块结构图
2 改进EfficientNet恶意流量检测模型
2.1 注意力模块的替换
本文将SE模块替换为ECA 模块,ECA 模块[19]是一种轻量的通道注意力模块,它将SE模块中的全连接层学习通道改为一维卷积层学习通道。SE 模块在对特征图降维之后,会使通道维度缩减,导致网络性能的降低,并且捕获所有的通道交互,这种依赖关系是低效和不必要的。而ECA 模块可以在不改变输入特征通道的维度的情况下,通过一维卷积有效捕获跨通道交互,完成局部跨通道融合的策略,从而达到了降低模型计算量和复杂度的效果。这样可以加强对于小目标和部分遮挡目标的识别精度,同时计算量没有显著增加。ECA 模块的结构如图3所示。
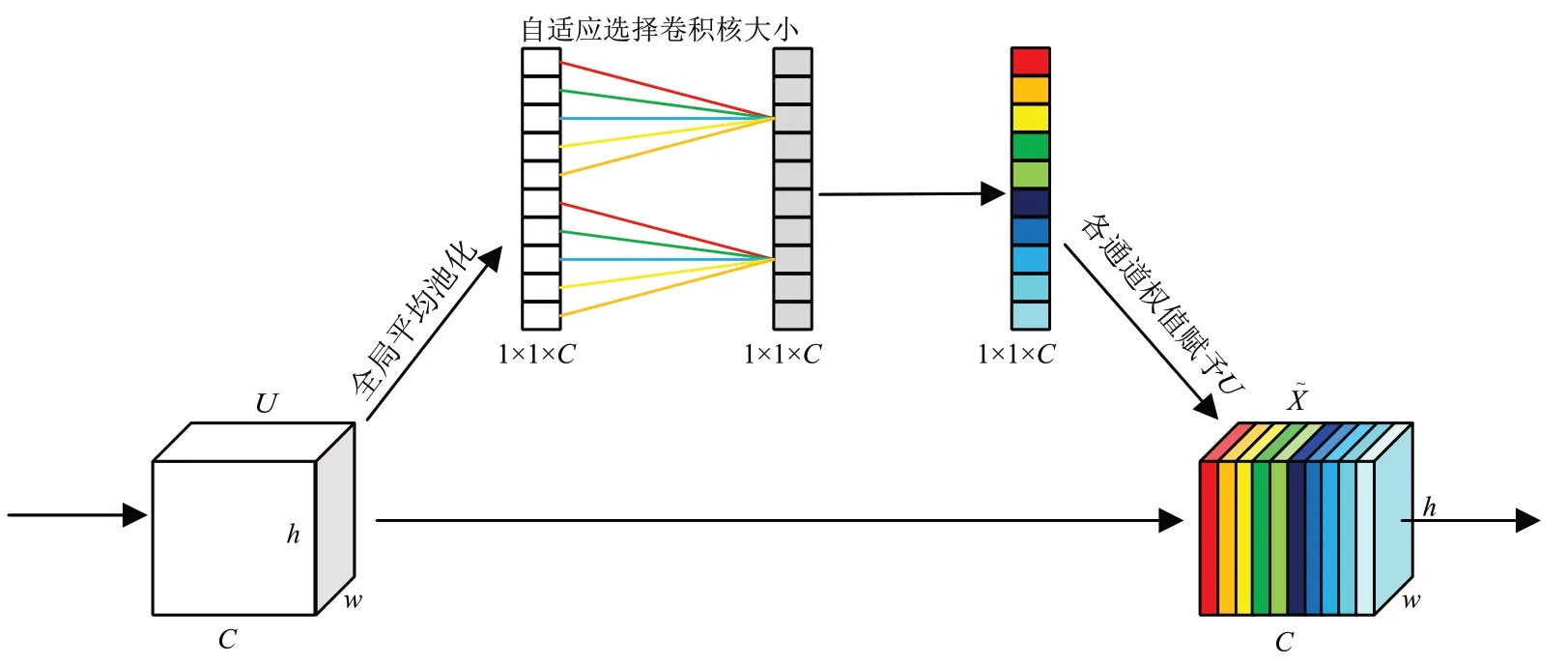
图3 ECA模块结构图
2.2 损失函数的改进
为了解决难易样本不平衡问题,本文对损失函数做了改进,将原交叉熵损失函数改为Focal Loss损失函数[20]。Focal Loss 损失函数在交叉熵损失函数的基础上进行了改进,这个函数通过减少易分类样本权重,从而使模型训练更加专注于难分类样本,交叉熵损失函数的公式如式(1)~ (2)所示:
其中,L为损失值,y'为预测输出值,y为经过激活函数后的实际输出值。
Focal Loss损失函数如式(3)所示:
其中,α为权重参数,用来抑制正负样本的数量平衡。γ为可调节因子,用来聚焦难分类样本。两个参数都有相应的取值范围,它们的取值相互间也是有影响的。当样本越容易被区分,调节因子也越小。当γ为0 时,就变为了普通的损失函数。当真实值趋于1时,说明样本是易分类样本,此时调制因子趋于0,说明对损失的贡献最小,即减少了易分类样本的损失比例。当真实值趋于0 时,说明该样本被错分的几率较大,此时,调制因子趋于1,对模型损失值也没有多大影响。
通过加入可调节因子来平衡正负样本,但只加入可调节因子无法解决简单样本与困难样本的分类问题,所以添加α来平衡简单样本的权重,从而使模型训练更加专注于难分类的样本,提高难分类样本的准确率。
2.3 加入容忍度机制
给模型设定一个容忍度,假设容忍度值为N,这个值相当于一个超参数,模型每过一个epoch,就回看下验证集的准确率。如果连续n个epoch 都未能提高准确率,那么就停止模型训练,并依据指标回调模型的学习率[21]。回调学习率的原因是当学习率较大时,容易在搜索过程中发生震荡,而发生震荡的根本原因则是搜索步长迈得太大,这时需要通过降低学习率来稳定步长大小。回调模型需要用到衰减因子decay[22],具体操作流程如图4所示。
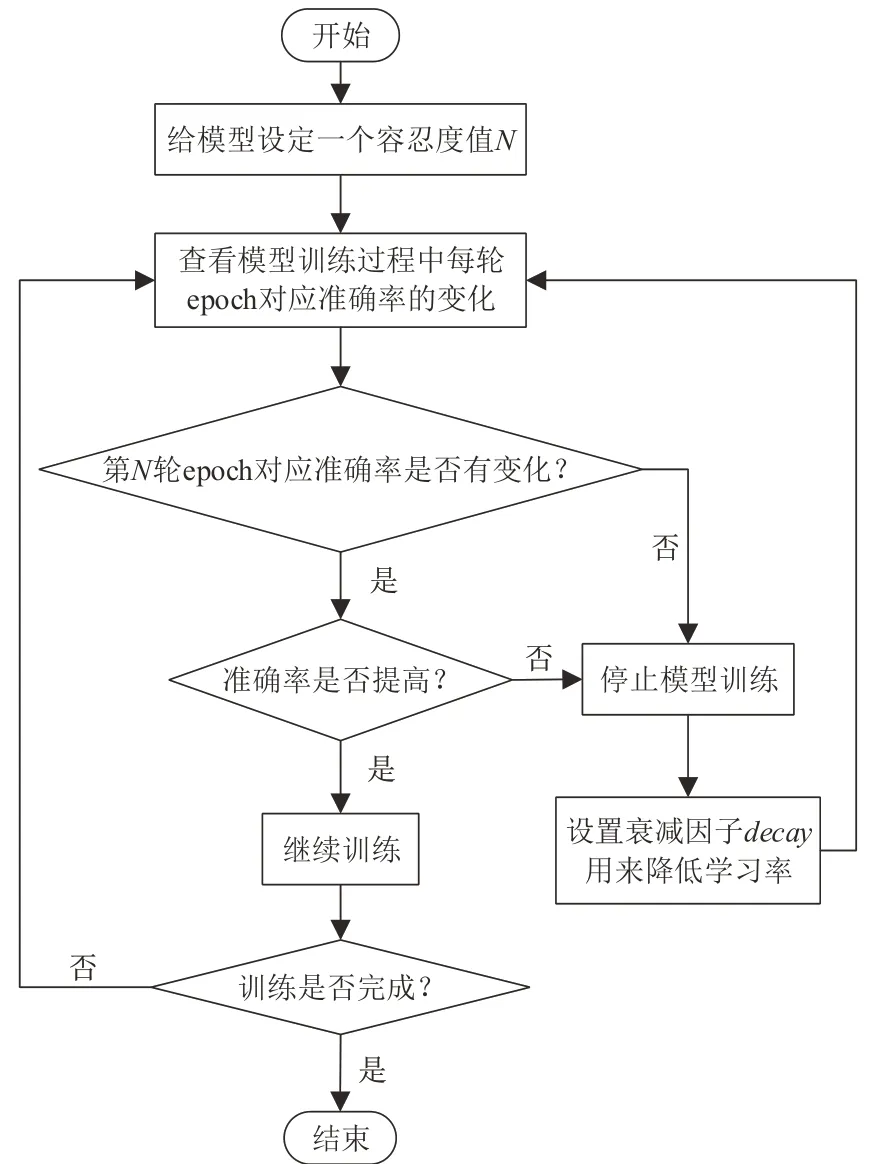
图4 依据指标调整学习率
3 实验验证
3.1 数据来源
为了验证本文模型的实际效果,需要在相同的数据集上与其他文献中的模型进行对比。本文所用数据集是通过IEEE DataPort 网站下载得到的公开数据集[23]。该数据集是通过抓取十六进制的PCAP数据包,并通过Hilbert空间填充曲线方法[24]将其转换成图像收集得到,有338 个正常流量图像和518 个恶意流量图像,总共有800 多个样本,数据分布见表1。

表1 数据分布
数据集中恶意流量样本占比见表2。
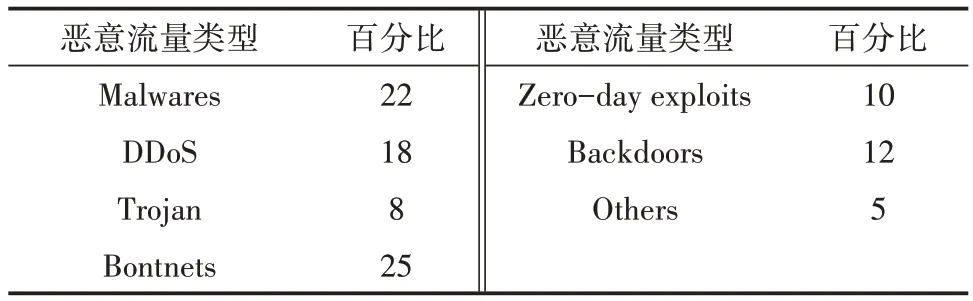
表2 依据恶意类型的恶意流量样本占比[23] %
从表2可知恶意样本中的恶意流量类型和它们在样本中的比重,其中主要的恶意流量类型是僵尸网络(Bontnets)、有恶意软件(Malwares)、分布式拒绝服务(DDoS)。其余的分别是特洛伊木马(Trojan)、零日漏洞(Zero-day exploits)、后 门(Backdoors)、其 他(Others)。
3.2 实验设计
3.2.1 实验环境
为了使恶意流量分类实验顺利进行,采用python 里面的pytorch 深度学习框架。具体的实验硬件环境和软件环境见表3。
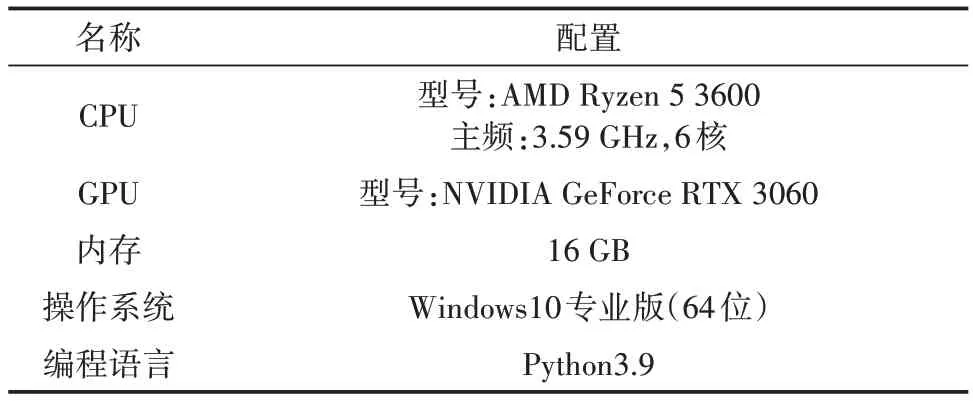
表3 实验环境
3.2.2 实验评估指标
采用准确率(Accuracy)、精确率(Precision)、召回率(Recall)、F1分数(F1-Score)对模型进行评估。
3.3 实验结果分析
3.3.1 参数设置
实验模型的超参数配置见表4。
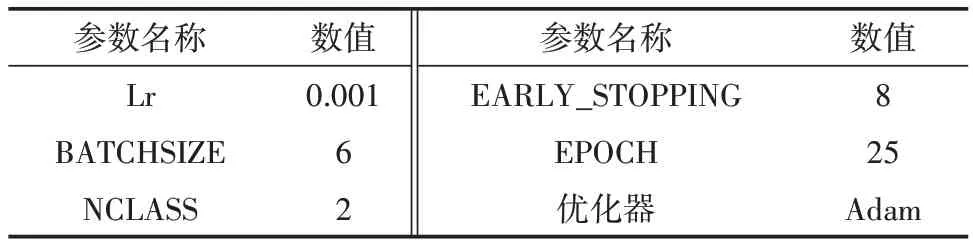
表4 模型超参数配置
由于EfficientNet-B4 图像分辨率高,神经网络宽度和深度均比EfficientNet-B0 大,因此使用EfficientNet-B4 作为实验模型。EfficientNet-B4 与EfficientNet-B0在参数上的具体区别见表5。
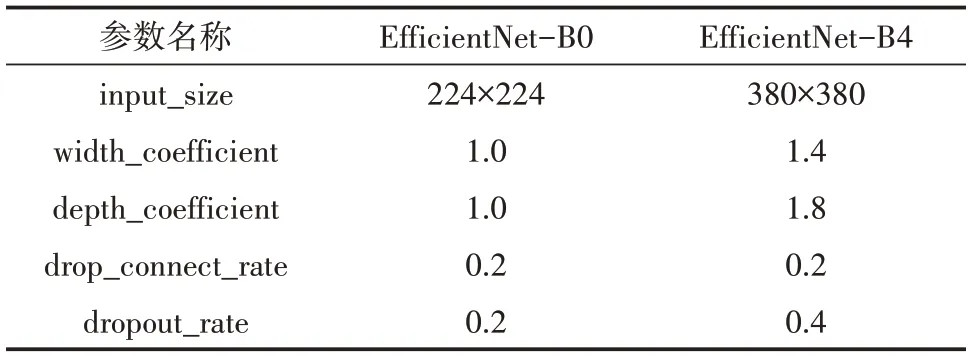
表5 两模型在参数上的对比
3.3.2 实验验证
使用十折交叉验证对模型进行10次测试,测试结果如图5 所示。从图5 可以看出十折交叉验证的准确率一直在95%~99%之间,这表明模型有较强的泛化能力且在图像分类方面的性能较高,这是由于本文模型引入ECA 模块,避免了原SE 模块中存在的学习通道间的相互依赖关系造成效率低的问题,能使模型学习到更多更深层的特征。其次通过替换模型中的损失函数解决了难分类样本的特征提取问题,从而获得更高细粒度的特征模板,让模型看到的图像细节就越多,从而使模型即使在样本不平衡的情况下依然保持很高的识别准确度。
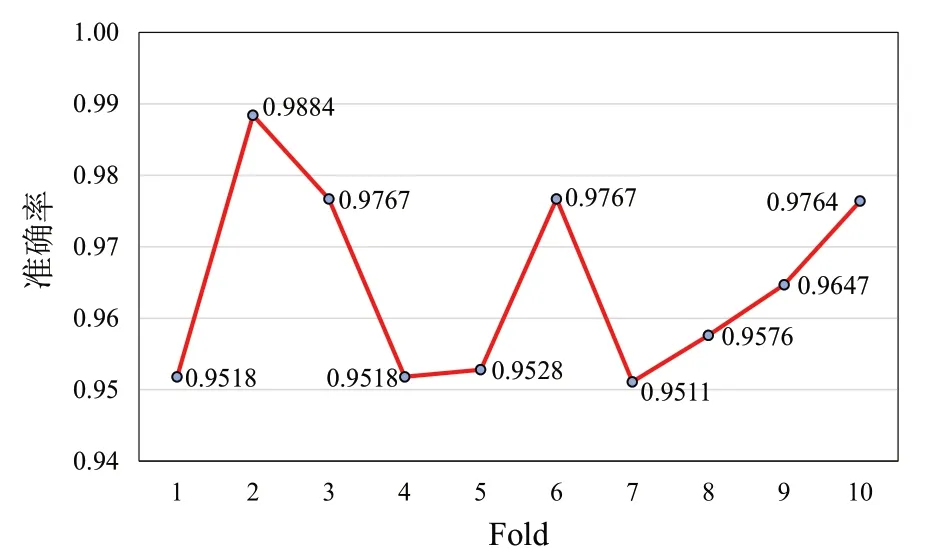
图5 十折交叉验证准确率
在十折交叉验证中,本文又选取其中一折进行分析,并与没改进之前的传统模型做了对比,在这一折中实验进行了25轮的测试训练,模型准确率和损失率对比如图6所示。
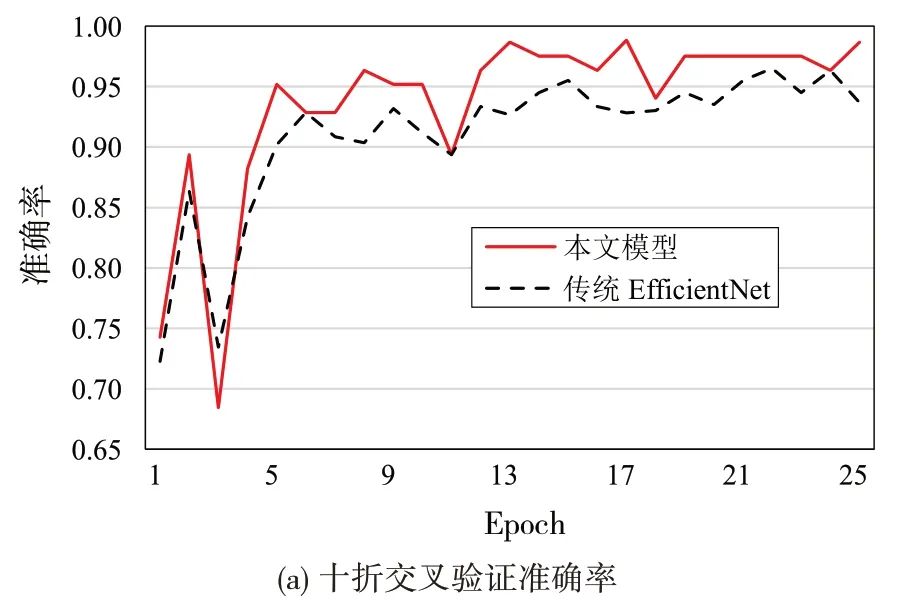
图6 十折交叉验证准确率与损失率
从图6(a)可以看出,本文EfficientNet-B4模型的准确度从第3 轮开始稳步上升,到第20 轮基本趋于平稳,准确率为97.51%,而原模型的准确率从第三轮开始上升速度不如本模型,从第六轮准确率一直低于改进模型的准确率。这主要由于原模型的注意力机制学习通道间的依赖关系较弱,而本文模型首先通过引入ECA 机制避免图像特征降维并能高效学习通道间的依赖关系,这有利于模型提取更多更深的图像特征,从而增强模型的检测准确率;其次替换损失函数解决了原模型存在的样本不平衡问题,使得模型能对图像进行深层次提取,从而能够使模型获得更高细粒度的图像特征,因而提高了模型准确率。
从图6(b)中可以看出本文模型第25轮损失率为0.02,原模型损失率为0.03。本文模型从第4轮开始损失率就一直低于原模型。这是由于本文模型更注重模型中学习率的相关问题,相对于原模型拟合更快,且性能稳定。一般模型自动调节学习率机制,使得模型在准确率下降的同时损失率会上升,而本文模型通过指标回调学习率,在制止模型准确率下跌的同时损失率也降低。
从图6 中可以看出,本文模型的准确率都略高于传统的模型,且损失率都略低于传统的模型。这是由于本文模型引入ECA 注意力模块后,ECA 模块用一个具有自适应内核大小的1D 卷积层来替换通用CA 模块中的两个2D 卷积层,使网络专注于有效地捕获强大的特征图,从而提高模型的准确率。其次损失函数由交叉熵函数替换为Focal Loss函数,从而减少模型中的易分类样本权重,增大难分类样本权重,使模型训练更加专注于难分类样本,使模型对于难分类样本提取的特征相比一般模型更为准确,从而增大模型对恶意流量检测准确度。再者,模型拥有一个自动调节机制,使模型在准确率下降的时候快速调整学习率,制止了模型过拟合现象的发生,从而间接提高了模型的准确率,也减少了模型的损失率。
为了进一步验证提出模型的可靠性,加入了Accuracy、Precision、Recall、F1-Score等评估参数,并和其他模型做了对比,对比结果如图7所示。
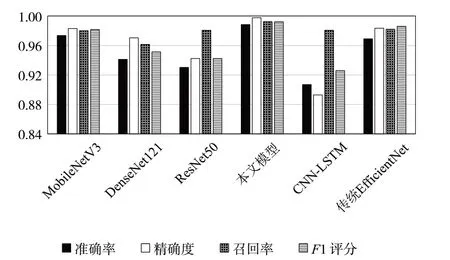
图7 各模型评估指标对比图
图7 中可以看出,本文模型的准确率、精确率、召回率和F1 值分别为98.84%、99.77%、99.01%和99.22%。首先将原EfficientNet 模型和改进后的EfficientNet模型相比,原EfficientNet模型的准确率、精确率、召回率和F1 值分别为96.91%、98.35%、98.21% 和98.61%,分别比本文差1.93%、1.42%、0.80% 和0.61%,由此可见,本文模型优于原EfficientNet 模型。另外,从图7 中可以直观地看出其他模型与本文模型有明显差距。本文改进的EfficientNet 模型用ECA 注意力机制替换了原有的SE 注意力机制。由于ECA 的一维卷积不进行通道压缩,保证了其通道注意力被完整地传递给后续网络,因此其注意力较SE 模块更为有效。再者,本模型替换了原EfficientNet 模型最后Softmax 层中的损失函数,将传统的交叉熵损失函数改为Focal Loss损失函数,解决了基于图像的异常流量检测模型中经常出现的样本不平衡问题,使其既能够克服因为训练集过小出现准确率降低的问题,也能够避免由于图像未能深层提取而导致的模型过拟合或欠拟合问题,最终使模型各项性能优于其他模型。
4 结论
为了解决恶意流量图像样本少、维度高等问题,提出一种改进EfficientNet 图像分类的恶意流量检测模型。通过恶意网络流量PCAP 可视化图像公共数据集进行实验验证,主要得到以下结论:
1)将原有交叉熵损失函数改为Focal Loss 损失函数,通过更新权重有效解决样本不平衡问题,提高了模型对恶意流量的识别率。
2)将原有SE 模块改为ECA 注意力模块,通过避免特征维度降低和有效的跨通道信息交互,保证了其通道注意力被完整地传递给后续网络,因此其注意力较SE模块更为有效。
3)本文改进的EfficientNet 模型属于轻量级模型,在参数量方面都远远小于其他模型,这使本文模型能适用于多种场景。它可以通过在反向传播阶段更新权值从而增大模型对难分类样本的比重,进而实现对难分类样本图像特征深层提取,解决了样本不平衡问题,从而改善了模型的性能。
猜你喜欢
玩具世界(2022年2期)2022-06-15
房地产导刊(2021年8期)2021-10-13
数学小灵通(1-2年级)(2021年4期)2021-06-09
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
出版人(2020年4期)2020-11-14
中学生数理化·七年级数学人教版(2019年4期)2019-05-20
中国交通信息化(2018年5期)2018-08-21
中学生数理化·七年级数学人教版(2018年6期)2018-06-26
