
基于神经网络嵌入学习的篮球群体行为识别
2023-12-26 08:41汪振华
安阳工学院学报 2023年6期
汪振华
(安徽国际商务职业学院 文化旅游学院,合肥 230000)
随着传感技术的不断进步,大量的轨迹跟踪数据可用于智能体育分析,如网球中的鹰眼、足球中的各种跟踪系统等。篮球中的一些单人行为(例如投篮),可以通过专家编程的规则来进行识别,而群体行为往往涉及多个参与者,他们的动作随着时间推移极具复杂性,很难通过手写规则来进行描述[1-2]。以篮球运动中一种常见的“挡拆”战术为例,2 名进攻球员共同努力阻挡防守球员的最佳防守路径,如图1 所示。而另一种常见的战术称为“手递手传球”,即2 名进攻球员交叉路径,通过短传来转移控球权。要将这2 种行为区分开来十分困难,因为挡拆和手递手传球的行为看起来非常相似。
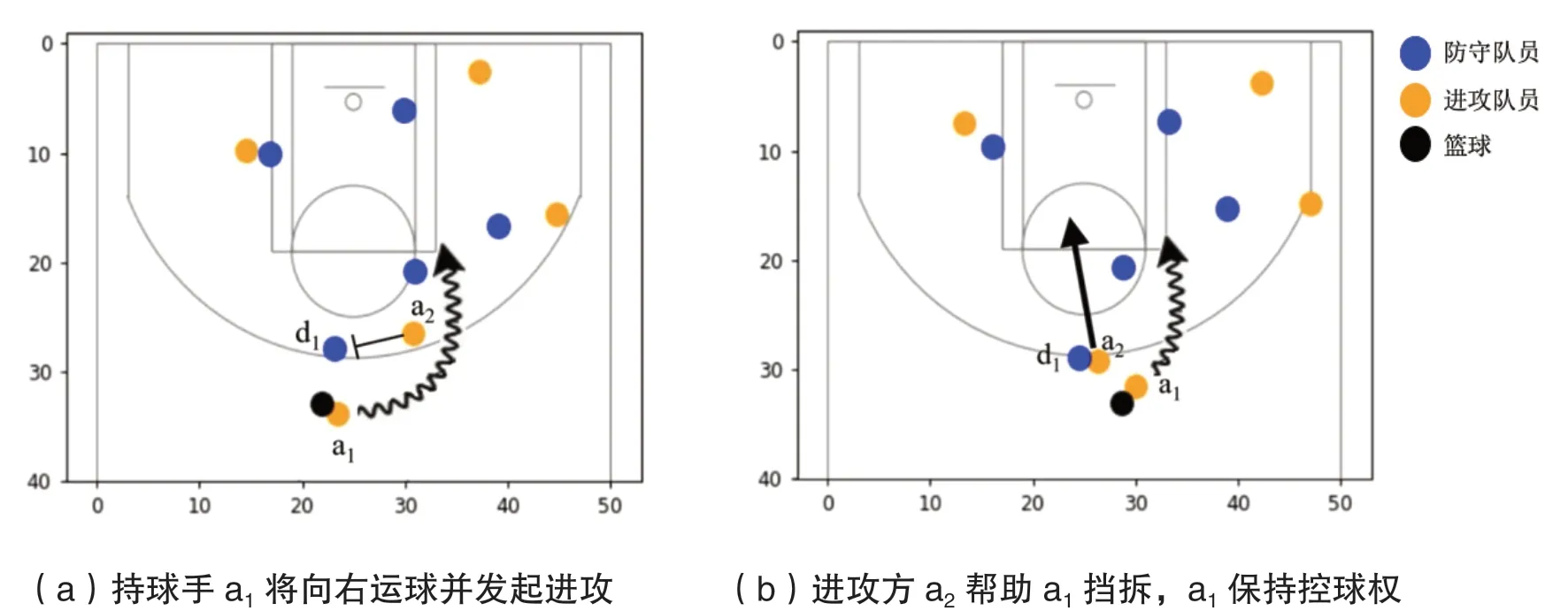
图1 经典的挡拆行为示意图
基于深度学习模型的群体行为识别模型依赖大量的标注序列。然而,手动标注比赛序列是十分耗时的,因为它需要在观看比赛时全程保持注意力集中,同时关注多个球员的实时状况。现有的手动标记的挡拆数据集只包含了大约1 000 个序列[3-4],这远不足以训练强大的神经网络模型。产生更多标注数据的一种方法是基于规则来识别行为,并作为弱标签。在深度学习模型的训练过程中可以利用这些弱标签,并进行自监督的预训练和轨迹预测任务。通过这种方式预训练的神经网络可以在少量标注数据上进行微调,用于群体行为识别。在网络结构方面,可使用变换器架构[5],为每个球员创建上下文的感知嵌入信息,这些嵌入通过团队池化层进行聚集。本研究提出基于神经嵌入的团队运动识别模型,使用长短期记忆(Long Short Term Memory,LSTM)[6]来编码时间序列,以允许对数据的时序信息进行建模,并通过团队级别的池化层对团队中的球员创建输入顺序无关的特征嵌入。
1 神经嵌入变换器(Neural Embedding Transformer,NETS)方法介绍
1.1 任务定义及符号说明
该任务的目标是训练神经网络识别篮球比赛中的团体行为。自2013 年以来,每个NBA 竞技场都有一个摄像系统,用于跟踪篮球比赛中的球员(每支球队5 名)和球。该系统通过11 个被跟踪物体在x-y 平面中的位置来观察它们,其中x 轴穿过球场的长度,y 轴从边线到边线。首先对数据进行预处理,使进攻队沿着y 轴进攻。将目标o 在时间t 的位置定义为,其中,其中o 表示被跟踪目标的集合,即球B、5 个进攻方和5 个防守方,被跟踪目标o 的轨迹可以表示为,时间步长为∆t。
1.2 整体框架与技术路线
为群体行为识别任务训练神经网络模型的一种标准做法是在真实标注数据上进行监督学习。然而,如前所述,手动标注既耗时又昂贵。可以通过对轨迹预测任务进行自监督预训练来有效地对神经网络进行初始化,并使用大量基于规则生成的弱标签对其进行微调,最后使用少量高质量的手动标注进行微调。为了实现预训练和微调过程,使用了模块化的神经网络架构,如图2 所示。对于轨迹预测任务,轨迹被输入到基础变换器。然后将变换器的输出作为轨迹预测头的输入,用作预训练。而对于群体行为识别任务,则使用相同的基础变换器,但使用一个分类头网络来进行行为分类。这种模块化的方法允许在轨迹预测预训练之后再对分类任务的变换器权重进行微调。
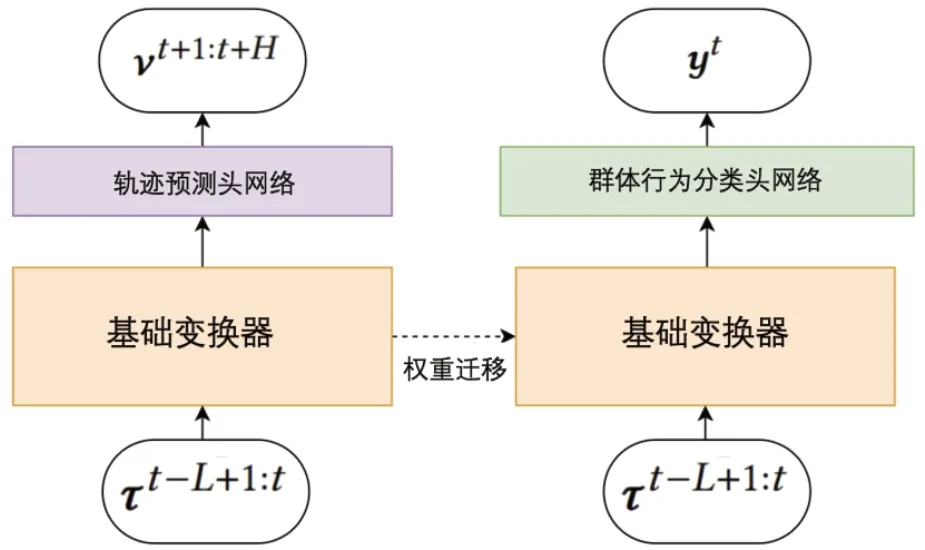
图2 基于神经嵌入的群体行为识别网络(NETS)结构示意图
1.3 神经网络结构
网络结构主要包含3 个部分,分别是基础变换器、轨迹预测头网络和行为分类头网络。
基础变换器的输入数据由给定的所有11 个目标组成的运动序列。由于这些输入向量表示每个被跟踪目标o 的时间序列,使用LSTM 层将这些轨迹嵌入到向量中,如图3 所示,以充分利用输入数据的时序信息[6]。
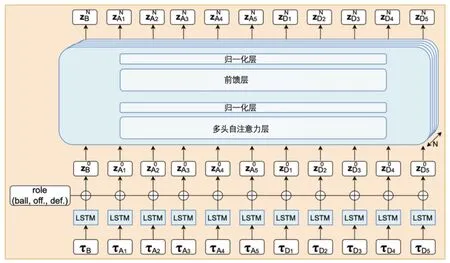
图3 基础变换器网络结构示意图
因为球的行为与攻击者不同,这11 个物体具有不同的性质。如图3 所示,首先对这个角色信息进行编码,并选择1 个热点位置编码来区分每个目标类别(即球、进攻球员和防守球员)。将这些三维向量拼接到LSTM 层的输出,并创建第一个注意力层的输入。尽管可以分别为每个球员创建嵌入信息,但之前的工作表明,添加球员嵌入信息后的提升效果微乎其微,同时需要大量的特征工程[7]。
为了生成上下文感知的球员嵌入信息,在给定输入嵌入的情况下,使用具有多头自注意机制的变换器来进行特征编码[5]。变换器的编码部分由多个注意力层组成,每一层都学习如何调整目标相对于其他目标的表征。具体来说,变换器将第l 层的输入处理为输出嵌入,输入和输出的维度为dv。其次,输入被进一步转换为三个矩阵,分别是查询Q、关键字K 和值V,其中每个矩阵表示堆叠的输入嵌入。然后用可训练矩阵,,对上述3 个矩阵进行变换,其中dg是模型超参数,h 是自注意头的数量。多头自注意函数包括残差连接,计算如下:
其中LN 代表层归一化,FF 是全连接的前馈网络。根据常规做法设置来简化超参数。变换器包含一系列N 个相同的注意力层。通过这种注意力机制,神经网络考虑了所有其他球员和球的信息后,为每个被跟踪的目标o 生成嵌入。
轨迹预测头在为每个被跟踪目标生成嵌入后,通过使用前馈神经网络(FF)为每个被追踪目标生成输出向量来预测未来的轨迹(图4)。由于球的运动物理特性与人类非常不同,而且进攻球员的行为与防守球员的行为不同,因此为每个角色使用单独的FF 来生成对应的轨迹。
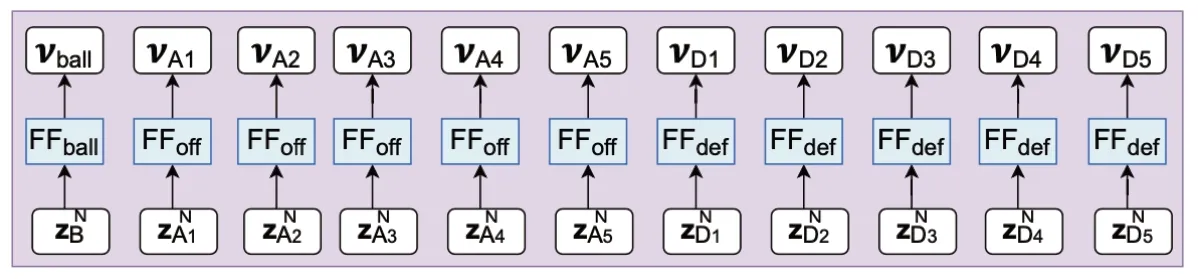
图4 轨迹预测头网络
分类头网络为了预测群体行为的标签,考虑了球员和来自最后一个转换层的球的上下文感知转换嵌入。对于群体行为识别任务来说,团队中球员的输入顺序不应影响被指定的行为标案,并且本文的模型对于每个团队的球员输入顺序都应是无关的。使用了一个团队级的池化层,它分别聚集了属于进攻方和防守方所有球员的嵌入信息(图5)。可以将输出值计为:
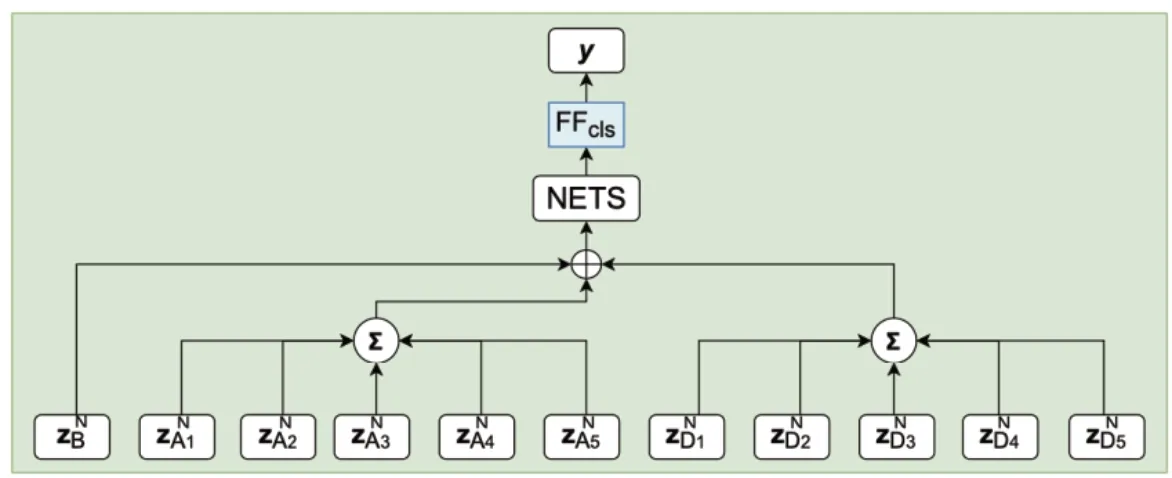
图5 分类头网络
其中,ak是用来平衡不平等类别分布的权重因子,yk是代表真实标注的1 个独热编码(One-hot)表示,是该动作属于类别k 的预测概率。
2 实验设置
2.1 数据集
使用了从2015-2016 年赛季632 场NBA 比赛中收集的公开运动数据进行实验。这相当于110万s 的比赛数据,每0.04 s 捕捉1 次球员和球的位置。将数据下采样3 倍,以降低计算成本,并获得∆t=0.12 s 的采样率。对于所有模型,使用L=10 个时间步长作为输入,即1.2 s。通过将数据分割成1.2 s 长的非重叠片段来构建数据集,得到869 905 个有效序列。对于每一个序列,还包含了下一个H 时间步长的未来范围,在实验中分别尝试了不同值(H=10、H=20 和H=40)。
2.2 标注篮球团体运动的行为
分别生成了挡拆和手递手传球2 个标签,不属于这2 类的动作序列被标记为“其他”,因此K=3。为了减少人工标注的数量和成本,首先采用一些既定的规则来进行自动的标注,即弱标签生成。
对于挡拆动作的弱标签生成,基于规则的方法将每个防守球员与1 名进攻球员进行匹配,然后判断当挡拆球员与持球手的防守球员非常接近的情况。对于手递手传球的弱标签生成,基于规则的方法是试图识别2 名球员之间位置的变化。球员之间的距离很小,球的转换时间很短。
弱标注过程产生了45 802 个“挡拆”行为、15 251 个“手递手传球”行为和808 852 个“其他”行为序列。此外,还为1 800 个片段进行了手动标注。该标注工具通过加载输入的视频序列,人为地对每个运动员的行为进行打标签。由于数据集是高度不平衡的,符合弱标签分布,从所有3个弱标签子群中平均采样行为序列。为了分配标签,为每个片段生成了长度为1.2 s 的视频表示。然后从3 个弱标签中的每一个中采样并标记一个视频,直到为每个类别找到600 个手动标记的样本。最终,使用了50%的手动标签进行测试,50%用于微调本研究提出的模型。
3 团队行为识别
对比了提出的群体行为识别方法的性能。首先评估了这些模型对大型弱标记数据集进行分类的能力。主要研究轨迹预测的自监督任务是否可以帮助提高群体行为识别的准确性。然后,在手动标记的数据上评估了本方法(NETS),以确定深度学习方法是否可以优于基于规则的标记方法。
3.1 实验设计
由于模块化的架构设计,除了最后一个预测层之外,神经网络架构与轨迹预测任务相同。对所有这些行为序列按80%、10%、10%分别进行训练、验证和测试,并在50 个迭代周期后应用提前停止操作。为了平衡45 802 个“挡拆”、15 251 个“手递手传球”和808 852 个“其他”行为序列的分布,将其他行为事件向下采样到45802 个(与“挡拆”相同),分别对“挡拆”、“手递手传球”和“其他”使用0.77、2.34 和0.77的加权因子ak。
由于群体行为标签主要是标记为“其他”的行为序列,该分类器在预测该类时可以获得93.0%的准确性。因此,在实验中主要统计多类的F1 分数来比较模型的性能。并计算了混淆矩阵M,其中Mij表示真实标签i 分类为j 的序列次数。通过将3 分类问题转换为3 个二元分类问题来计算F1 分数:
3.2 基线方法
将NETS 架构与具有相同设置下基于LSTM的神经网络进行了比较。为了进行公平的比较,使用了相同的训练顺序,即使用轨迹预测任务对模型进行预训练,然后改变预测头以实现群体行为分类。
对于群体行为分类任务来说,由于缺乏使用深度学习的基线方法,使用了若干标准的机器学习方法作为基线,包括逻辑回归LReg、随机森林分类器RForest 和梯度增强分类器GBoost。为了建立基线结果来进行对比,使用流行的sklearn 实现训练了3 个浅层模型。这些浅层模型的输入是由220 个特征组成的序列,并通过网格搜索找到了最优的参数设置。
3.3 弱标签上的验证结果
表1 显示了使用弱标签数据的F1 分数。NET模型在很大程度上优于浅层方法。结果表明,群体行为的分类对于LReg、RForest 和GBoost 等浅层模型来说是一个难题,这些传统机器学习算法的F1 分数相对较低就表明了这一点。
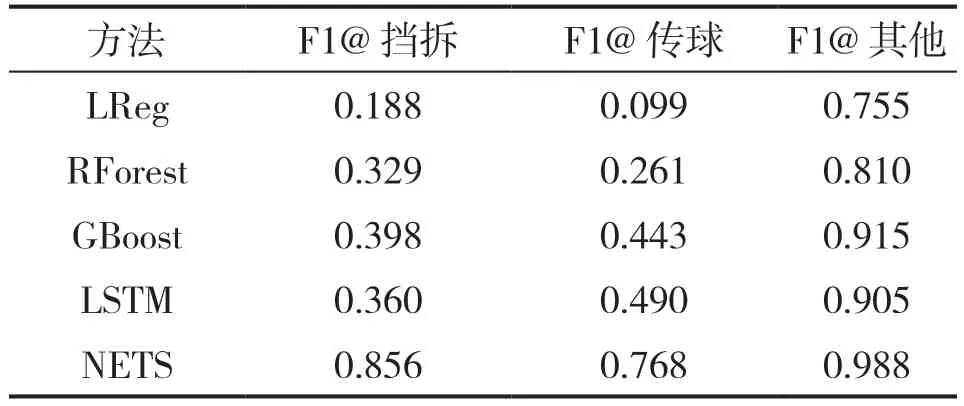
表1 与基线方法的分类效果(F1 得分)对比
接着对NETS 模型进行了消融研究,以评估本研究的网络结构设计。通过去除LSTM 嵌入创建了模型消融,按照经验对输入嵌入了2 层前馈神经网络进行替换,还检查了团队池化层的影响,替换了求和操作,直接拼接了所有的表示。
表2 中的所有模型都是NETS 的消融实验结果,并且都是基于变换器架构。可以看到,所有这些模型的性能都优于表1 中给出的浅层模型或基于LSTM 的模型。与未进行预训练的相同模型相比,所有经过预训练的模型都显示出明显的改进。同时,当在基础变换器的输入端使用LSTM嵌入而不是密集的嵌入层时,有了显著的改进。此外,还观察到在输出中使用团队池化层时有了进一步提升。根据经验,在没有预训练的情况下,从头训练一个群体行为识别模型需要大约500 个迭代周期,但当从预训练的模型开始时,只需要 大约200 个迭代周期。
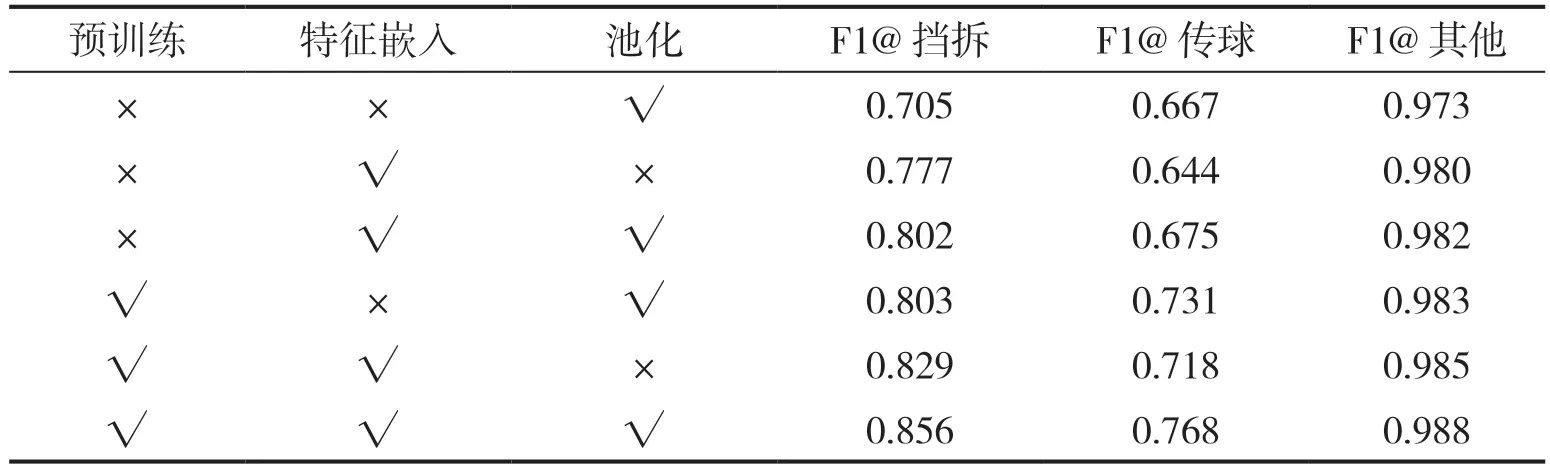
表2 不同网络结构在分类测试效果(F1 得分)上的消融实验
3.4 手动标签上的验证结果
为了深入了解基于规则的弱标签方法的性能,在表3 中展示了弱标签的混淆表。虽然弱标签规则倾向于提取许多正确标记的序列,但“挡拆”和“手递手传球”的规则都包括24 个和21个行为序列,它们通过手动标签被标记为“其他”序列。此外,将“手递手传球”误分类为“挡拆”操作的情况也相对频繁。

表3 弱标签在手动标注测试集上分类结果的混淆矩阵
接着评估了手动标签的性能。在测试这些手动标签时,还检查了弱标签和手动标签的有用性。主要评估了以下方法:(1)使用基于规则的弱标记方法对群体活动进行分类,这需要人类专业知识来定义规则,而不是一种深度学习方法。(2)在轨迹预测任务上预训练NETS模型,并使用大量弱标签对模型进行微调。(3)在轨迹预测任务上预训练NETS 模型,并仅使用900 个手动标签对模型进行微调。(4)在轨迹预测任务上预训练NETS 模型,使用训练集中的弱标签和验证集中的手动标签进行提前停止操作。(5)在轨迹预测任务上预训练NETS模型,首先在弱标签上进行微调,然后在手动标签上再次进行微调。
表4 中的结果显示了根据混淆矩阵计算的基于规则的弱标签方法F1 分数。与弱标签本身相比,观察到在弱标签上训练NETS 时略有改善,假设这源于神经网络比单独的规则具有更好的泛化的能力。相比之下,只对手动标签进行微调比基于规则的标签更差,这表明没有足够的手动标签来训练大型神经网络。在验证集中使用手动标签则进一步提高了准确性,这意味着NETS 在没有手动标签的情况下过度填充弱标签。使用顺序微调方法可以获得最高的精度(第5 行)。当将第5 行与第1 行中的弱标签F1 分数进行比较时,可以观察到,“挡拆”的准确度从0.869 增加到0.951,“手递手传球”的准确度则从0.874 增加到0.938,“其他”的准确度也从0.893 增加到0.902。
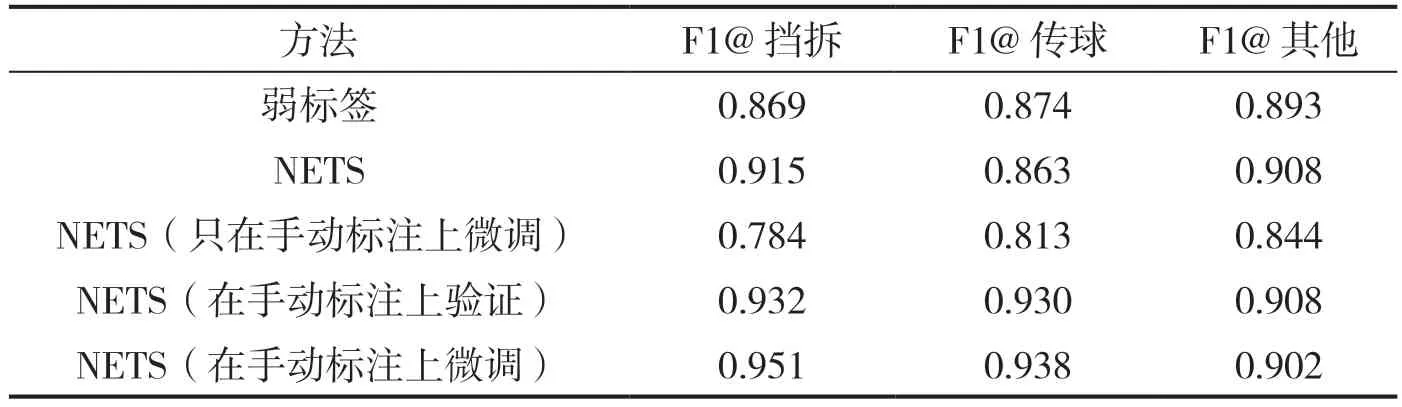
表4 四种不同网络变体的F1 得分对比
4 结语
提出的基于神经嵌入的群体行为识别模型具有专门设计的变换器架构,以解决体育分析中的常见问题,可以高精度地对篮球群体行为进行分类。实验结果表明,在自监督轨迹预测任务上预训练模型显著提高了模型在下游任务上的性能。
猜你喜欢
计算机与生活(2022年4期)2022-04-13
车迷(2018年11期)2018-08-30
海峡姐妹(2018年3期)2018-05-09
中国安全生产科学技术(2018年2期)2018-04-13
电子科技大学学报(2018年2期)2018-03-26
小学生导刊(2017年17期)2017-05-17
世界汽车(2016年8期)2016-09-28
世界汽车(2016年8期)2016-09-28
世界汽车(2016年8期)2016-09-28
公民与法治(2016年10期)2016-05-17
