
基于频率域信息与BiLSTM的PM2.5浓度预测模型
2023-12-15 09:28唐雪明
无线电通信技术 2023年6期
唐雪明,吴 楠
(1.南宁师范大学 物理与电子学院,广西 南宁 530199;2.南宁师范大学 计算机与信息工程学院,广西 南宁 530199)
0 引言
人类生活离不开干净的空气,但随着社会快速发展,空气污染严重威胁健康。颗粒物(Particulate Matter,PM)是影响人类健康的主要因素,特别是PM10和PM2.5,能够渗透到呼吸系统中[1]。其中,PM2.5能穿透肺部气体交换区,可能影响其他器官[2]。因此,准确及时的PM2.5浓度预测不仅可以帮助城市管理制定预防措施,还能优化人们日常安排。
现有的PM2.5浓度预测的研究工作中,深度学习及其相关方法是一种比较新颖的预测方法,尤其以长短期记忆(Long Short-Term Memory,LSTM)神经网络为代表的反馈神经网络,已被广泛运用于PM2.5浓度的预测[3-5]。此外,LSTM还可作为非线性单元,融入更为复杂的混合模型中。蒋洪迅等人[6]建立了一个基于经验模态分解(Empirical Modal Decomposition,EMD)和LSTM的EMD-LSTM模型,通过EMD分解原始PM2.5时间序列,以捕捉不同时间尺度上的周期性变化。实验证明该方法预测PM2.5浓度准确且具有泛化能力。刘晴晴等人[7]提出了一种基于赋权K近邻算法的LSTM神经网络模型来预测PM2.5浓度,相对于传统模型,预测效果有所提升。此外,Zhu等人[8]尝试整合目标站点与周边监测站的数据,发现这种数据融合能显著提高预测性能。Teng等人[9]构建了一种新型混合预测模型,将EMD方法、样本熵(Sample Entropy,SE)指标和双向长短期记忆(Bidirectional Long Short-Term Memory,BiLSTM)神经网络相结合。实验证明,相比其他单一深度学习模型,该新型模型至少提高了50%的短期PM2.5浓度预测准确性。
时间序列中蕴含丰富频率域信息,充分利用这些信息可提高预测效果。Zhou等人[10]在Transformer结构中提出了傅立叶增强块和小波增强块,实现频域映射,有力捕捉时间序列重要结构。实验证实这种模型在6个基准数据集上取得了最佳预测性能。Jiang等人[11]提出了一种新颖的频率增强型信道注意力(Frequency Enhanced Channel Attention Mechanism,FECAM),它基于离散余弦变换(Discrete Cosine Transform,DCT)自适应地模拟信道之间的频率相互依存关系。广泛实验表明,FECAM 作为一种通用方法,在6个真实世界数据集上始终以相当大的优势提升了4种主流Transformer和基于Non-transformer的方法,并实现了最先进的性能。
基于以上分析,提出了一种基于频率域信息与BiLSTM(Frequency-Domain Information BiLSTM,FD-BiLSTM)的PM2.5浓度预测模型。通过DCT将时间序列转换到频率域,捕获信号的频率特征,保留适量低频DCT系数以捕捉周期性和趋势;利用BiLSTM全面提取空气污染物特征,实现PM2.5浓度预测。最后,通过北京市12个站点数据集测试模型并评估性能,对比单变量LSTM模型、BiLSTM模型、BiLSTM-attention模型和卷积神经网络BiLSTM(Convolutional Neural Network BiLSTM,CNN-BiLSTM)模型,验证所提单变量FD-BiLSTM模型的有效性;同时比较4种不同输入变量的多变量FD-BiLSTM模型预测结果,实验结果显示选择本站点和11个邻域站点的PM2.5浓度作为输入变量的多变量FD-BiLSTM模型预测效果最佳。
1 离散余弦变换
时间序列包含时间域信息和频率域信息。时间域信息反映不同时间点上的观测数据,用于分析趋势、季节性和周期性等特征。频率域信息是指将时间序列表示为不同频率成分的总和。这可以通过进行傅里叶变换或其他频谱分析方法来实现。频率域分析可以揭示时间序列中不同频率成分(例如周期性或振荡)的存在,并帮助识别周期性模式、季节性变化等。
傅立叶变换可能因其周期性而引入高频成分,导致边界信息误差,即吉布斯现象[11]。吉布斯现象会导致逼近过程中的误差,尤其是在突变点附近。在频谱分析中,吉布斯现象可能会导致信号频谱的泄漏,即频谱中的能量分布到频谱图上不正确的位置,这会影响频域分析的准确性。此外,逆运算需要复杂的操作,进而需要额外的计算。
时间序列的频率信息蕴含着更多深层次的信息,然而在时域中往往难以完整揭示。当信号受到噪声干扰时,其时域波形可能变得复杂难以辨认,或难以将信号与噪声分离[12]。而在频域中,这种情况则可以清晰地区分。与傅立叶变换不同,通过离散余弦变换引入频率信息,能够从本质上避免吉布斯现象。
利用DCT预测时间序列的核心操作如下:
① 分解
将原始的长度为N的时间序列信号x(n)分成一系列相等长度的子序列,并将这些子序列称为块。这些块可以是连续的、重叠的或非重叠的。
② 离散余弦变换
利用离散余弦变换将每个块表示为一组余弦函数分量,每个分量代表不同频率的变化。这样,每个块都被转换为在频率域中表示的系数X(k)。对x(n)的DCT如式(1)所示:
(1)
式中:k=0,1,…,N-1。
③ 选择分量
只保留较低频的DCT系数,因为这一部分包含了信号的主要能量[13]。
④ 逆离散余弦变换
将保留的DCT系数进行逆离散余弦变换,将它们转换回时间域。这将产生一个近似的预测结果。DCT逆变换如式(2)所示:
(2)
式中:n=0,1,…,N-1。
⑤ 重建
将连续的预测结果连接起来,得到整个时间序列的预测。
2 FD-BiLSTM PM2.5浓度预测模型设计
2.1 FD-BiLSTM模型
FD-BiLSTM模型的示意图如图1所示,图中L表示时间序列的长度,N表示变量个数,v={v0,v1,…,vn-1}(n=N)代表时间序列的子序列,即块,DCT={DCT0,DCT1,…,DCTn-1}(n=N)表示每个块的余弦函数分量,F={F0,F1,…,Fn-1}(n=N)表示每个块在频率域中的系数。首先利用DCT将数据转换为频率域数据,捕获信号的频率特征以及数据的周期性和趋势;然后利用BiLSTM网络提取数据间的长期和短期依赖,并预测结果;最后通过全连接层得到最终的预测结果。

图1 FD-BiLSTM模型示意图Fig.1 Diagram of the FD-BiLSTM model
2.2 模型预测步骤
基于FD-BiLSTM模型进行PM2.5浓度预测的步骤描述如下:
步骤1数据预处理。首先,删除原始数据集中的异常值,并用随机森林插值算法[14]填充相应的缺失数据;然后,使用归一化算法将数据缩小到0~1,这样可以加快数据的收敛速度。
步骤2划分数据集。将数据集划分为训练集和测试集,其中80%为训练集,20%为测试集。
步骤3构建模型,利用DCT将数据转换为频率域信息,并使用适当的参数训练BiLSTM模型。
步骤4使用训练好的模型,对测试集进行PM2.5浓度预测。
步骤5对输出的数据进行反归一化。反归一化方法如式(3)所示:
x=x′(max+min)+min,
(3)
式中:x′为归一化后的数据,max和min分别为原始数据的最大值和最小值。
步骤6计算误差。
2.3 数据预处理
本文的空气质量数据集来源于Zhang等人[15]提供的数据集,该数据集可以从加州大学欧文分校机器学习资源库页面下载。该数据集包含北京及其周边地区的12个不同的国控监测点2013—2017年的空气质量数据。这12个监测点分别是:奥体中心、昌平、定陵、东四、沽源、古城、怀柔、农讲所、顺义、天坛、万柳和万寿宫。为了方便描述,将上述提到的站点进行编号,奥体中心记为S1、昌平记为S2、定陵记为S3,以此类推。
各个站点是原始的传感器数据以每小时的时间步长收集的,跨越1 461天,共有35 064个数据样本。每个站点的数据集中都包含12个特征,如PM2.5、PM10、CO、NO2等。
为了消除特征之间的不同维度,加快数据收敛,将数据集归一化并缩放到[0,1],以加快收敛速度,提高模型精度。其中,归一化方法如式(4)所示:
(4)
2.4 特征选择
本文采用皮尔逊相关系数[16]来表示S1站点的污染物因素、气象因素和其他11个站点的PM2.5浓度之间的关系。皮尔逊相关系数的计算如式(5)所示:
(5)
式中:x和y表示输入的特征,n为序列中的样本数。
图2展示了S1站点的PM2.5浓度与5个污染物因素以及4个气象因素之间的相关性热图。横纵坐标对应了这10个特征,每个小格子表示对应两个特征之间的皮尔逊相关系数。图3展示了S1站点的PM2.5浓度与北京市其他11个站点的PM2.5浓度之间的相关性热图,横纵坐标代表了这11个特征。图中,“TEMP”为气温、“PRES”为气压、“DEWP”为湿度、“WSPM”为风速,“S2”“S3”“S4”等分别表示不同站点的PM2.5浓度。
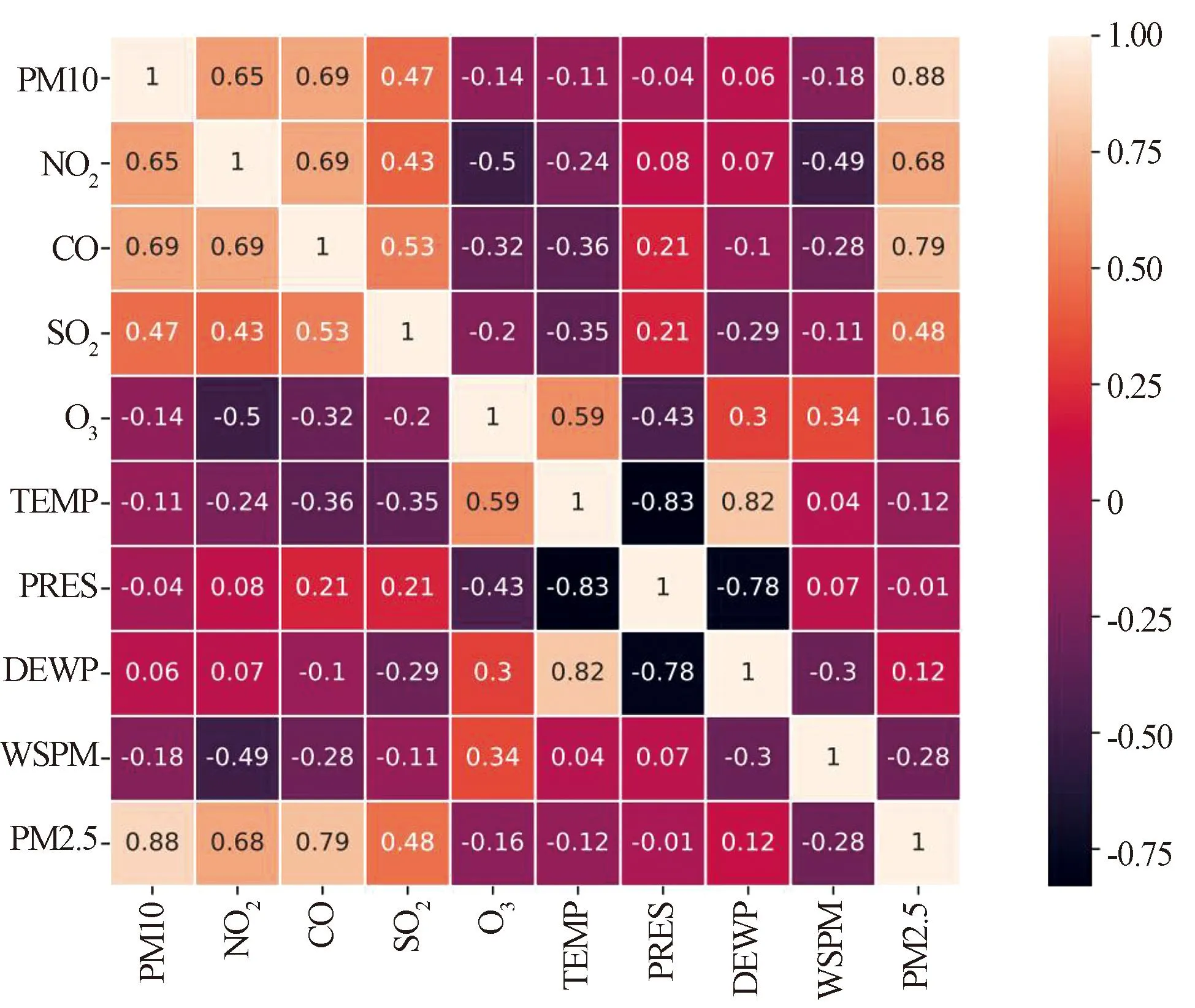
图2 S1站点的污染物因素与气象因素之间的相关性热图Fig.2 Heat map of correlation between pollutant factors and meteorological factors at site S1
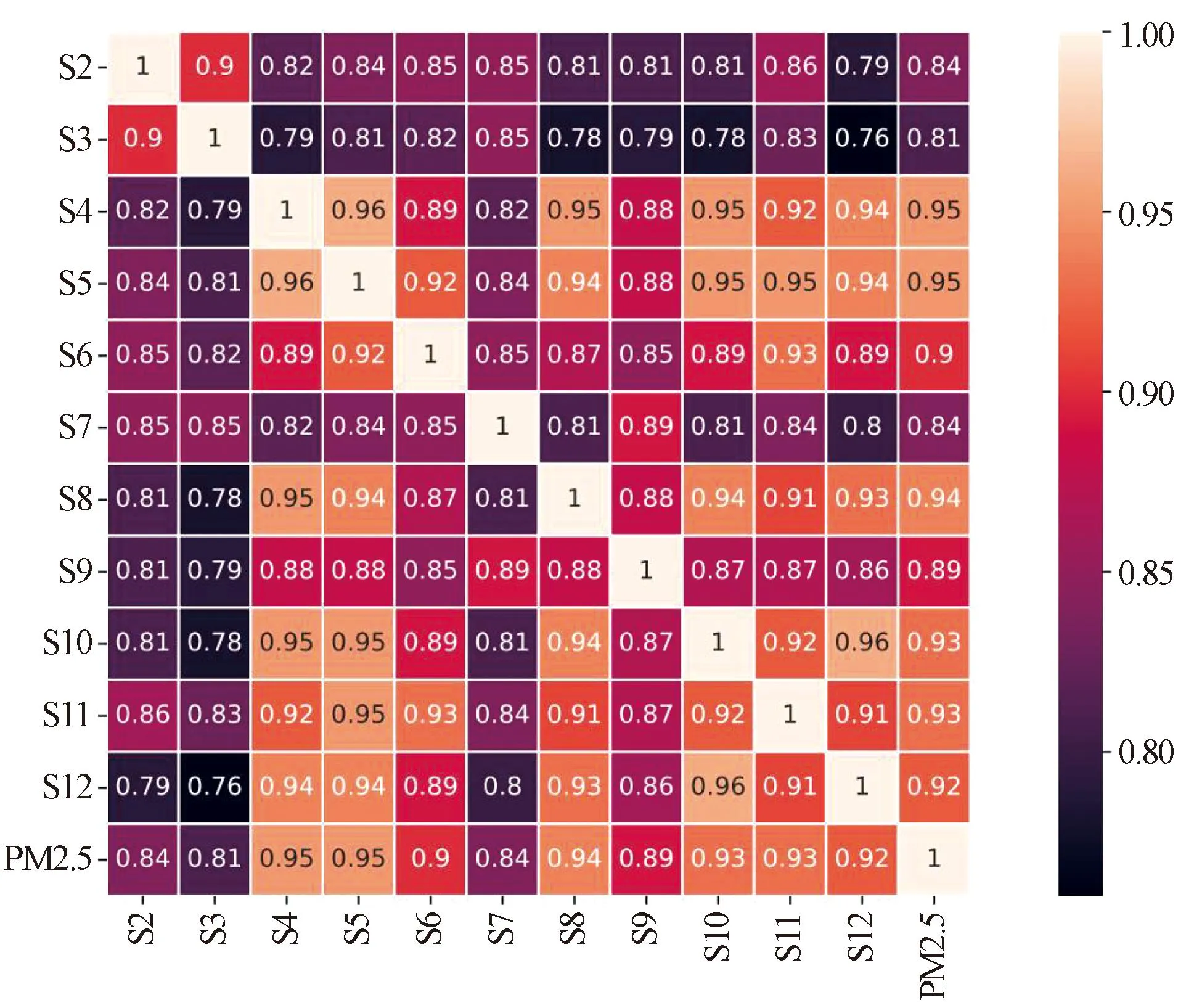
图3 S1站点的PM2.5浓度与其他站点的PM2.5浓度之间的相关性热图Fig.3 Heat map of correlation between PM2.5 concentration at site S1 and PM2.5 concentration at other sites
从图2中可以看出,S1站点的PM2.5浓度与5个污染物因素和4个气象因素的相关性差别很大,它与本站点的PM10浓度相关性最大,与本站点的风速相关性最小,从整体上看,PM2.5浓度与4个气象因素之间的相关性都很弱。与之相反的是,从图3可以看出,12个站点的PM2.5的浓度之间都是强相关的(ρ>0.7)。强相关性意味着各站点之间对PM2.5存在高度的空间依赖性。
3 实验与性能分析
3.1 环境配置与评价指标
实验所使用的计算机配置为:Intel(R) Core(TM) i5-7200U CPU @ 2.50 GHz 2.71 GHz,内存为16 GB,Windows 10(64位)操作系统,软件开发环境为Python 3.8.1。
在实验中,设置FD-BiLSTM的模型参数为:预测窗口长度为7,隐藏层神经元个数为11,batch_size为16,迭代次数epoch为20,学习率为0.000 1。此外,优化函数设置为“Adam”。
为了评估模型预测的准确性,选择平均绝对误差(Mean Absolute Error,MAE)、均方根误差(Root Mean Square Error,RMSE)、平均绝对百分比误差(Mean Absolute Percentage Error,MAPE)和决定系数(R2)作为模型评价指标。这4个评价指标的计算方法如式(6)~式(9)所示:
(6)
(7)
(8)
(9)

较低的MAE、RMSE、MAPE值反映了较低的误差水平,意味着预测更准确。同时,R2的值越接近于1,模型的拟合效果越好。
3.2 单变量FD-BiLSTM模型PM2.5浓度预测与分析
单变量FD-BiLSTM模型在S1站点上的预测值与真实值的对比如图4所示,可以看出,该单变量模型整体具有较好的拟合效果,在预测PM2.5浓度方面具有一定的实用性。
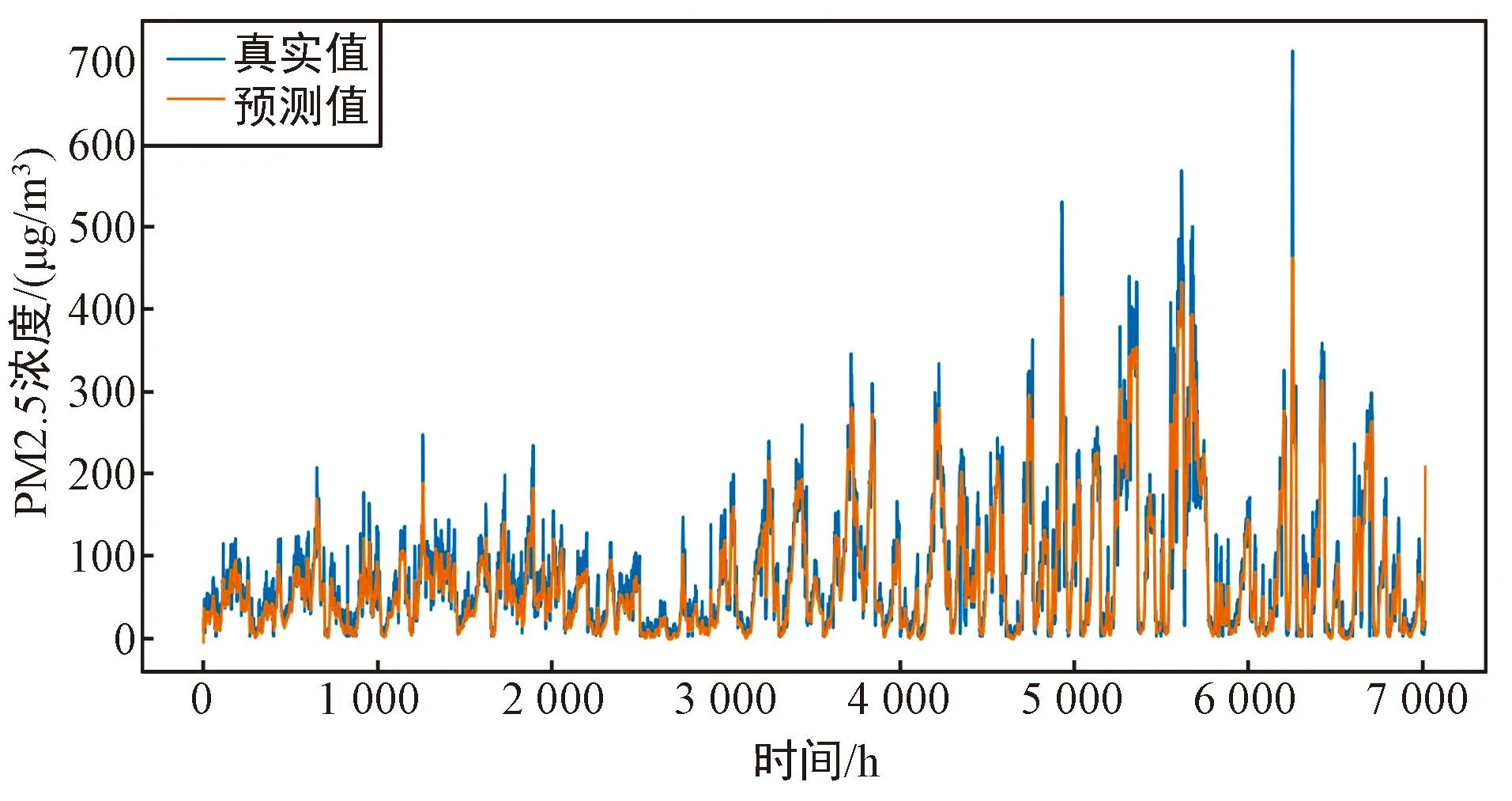
图4 单变量FD-BiLSTM模型在S1站点上的预测值与真实值的对比图Fig.4 Plot of predicted versus true values of the univariate FD-BiLSTM model on site S1
为了进一步说明本文提出的模型的有效性,以S1站点为例,将单变量FD-BiLSTM模型与单变量LSTM[17]模型、BiLSTM[17]模型、BiLSTM-attention[18]模型、CNN-BiLSTM[17]模型预测效果进行对比。对比模型在相同参数上选用本文提出的模型参数的设定值,各个单变量模型的预测性能比较如表1所示。从表1中可以看出,单变量FD-BiLSTM模型的RMSE和MAPE值都是最小的,并且R2值是最大的,这说明单变量FD-BiLSTM模型的预测效果要优于表中的其他几个单变量模型。

表1 不同单变量模型的预测性能比较Tab.1 Comparison of predictive performance of different univariate models
3.3 不同变量组合的多变量FD-BiLSTM模型PM2.5浓度预测与分析
单变量PM2.5浓度预测模型是指只使用PM2.5浓度这一单一特征作为输入进行预测,该模型可以简单且直接地预测特定空气质量参数的变化趋势,但无法充分利用其他可能与空气质量相关的信息。多变量PM2.5浓度预测模型是指基于多个不同的输入特征来预测PM2.5浓度。这些特征除了PM2.5浓度外包括但不限于PM10、SO2、NO2、CO、O3、温度、湿度、风速、气压等。通过结合多种影响空气质量的因素,多变量模型能够更全面地分析、预测PM2.5浓度的变化。
影响PM2.5浓度的因素有很多,包括气象因素、人为排放因素、地理因素和季节性变化等[19]。PM2.5与其他空气质量参数(PM10、SO2、NO2、CO、O3)之间存在相关性。PM10中的大部分颗粒物包含在PM2.5中,即高PM10浓度通常与高PM2.5浓度相关,而SO2、NO2、CO、O3是大气中的主要污染物,它们的存在和浓度会影响大气的化学组成和反应过程,进而影响PM2.5的浓度。此外,Wardana等人[17]将北京市某一站点的PM2.5浓度和北京市其余11个站点的PM2.5浓度作为输入变量的多变量模型的预测效果要优于将某一站点的污染物因素和气象因素作为输入特征变量的多变量模型的预测效果。
为了探究不同变量组合对多变量模型的预测效果的影响,选择4组变量组合分别作为多变量FD-BiLSTM模型的输入变量,并将4组变量组合依次命名为M1、M2、M3和M4。M1包含S1站点的PM2.5浓度和5个污染物因素(PM10、SO2、NO2、CO、O3),M2包含S1站点的PM2.5浓度、S1站点的5个污染物因素和S1站点的4个气象因素(气温、气压、湿度、风速),M3包含S1站点的PM2.5浓度和其余11个站点的PM2.5浓度,M4包含S1站点的PM2.5浓度、S1站点的5个污染物因素、S1站点的4个气象因素和其余11个站点的PM2.5浓度。
不同变量组合的多变量FD-BiLSTM模型预测性能比较如表2所示,可以看出,M3作为多变量模型的输入变量预测效果最好,M4次之,这说明选择相邻站点的PM2.5浓度作为模型的输入变量,能够提高模型的预测效果。同时,结合上一节的特征选择的内容来看,只选择强相关的因素作为输入变量的模型预测效果要优于选择不同相关程度的因素作为输入变量的模型预测效果。
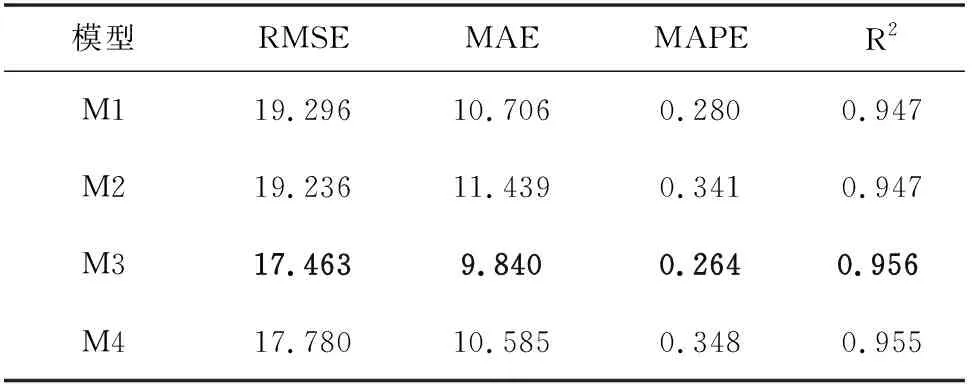
表2 不同变量组合的多变量FD-BiLSTM模型预测性能比较Tab.2 Comparison of prediction performance of multivariate FD-BiLSTM models with different combinations of variables
结合单变量预测模型,对比不同的特征输入,得出结果为增加输入特征的个数不一定会直接导致多变量模型的预测效果更好。多变量模型的预测效果受多方面因素影响,包括特征的选择、特征之间的相关性、模型的复杂度等。因此,精心选择少量的重要特征比使用大量特征更有效。
此外,将表1和表2的结果进行对比可以看出,多变量模型的预测效果要明显优于单变量模型的预测效果。这说明多变量模型能够更准确地捕捉影响空气质量的复杂关系,从而提高预测准确度。
以S1站点的PM2.5浓度和其余11个站点的PM2.5浓度作为变量的多变量FD-BiLSTM模型的预测值与真实值的对比如图5(a)所示,可以看出,多变量模型整体具有很好的拟合效果,多变量模型的拟合效果要优于单变量模型的拟合效果。选择本站点的PM2.5浓度和其他11个站点的PM2.5浓度作为多变量FD-BiLSTM模型的输入变量,12个站点的预测效果如表3和图5所示。图5(a)~图5(l)分别对应站点S1~S12的多变量FD-BiLSTM模型的预测值与真实值的对比。

表3 S1~S12站点的多变量FD-BiLSTM模型预测效果Tab.3 Predictive effectiveness of multivariate FD-BiLSTM models for sites S1~S12
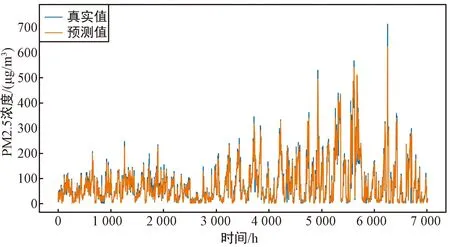
(a) S1站点的预测值与真实值的对比
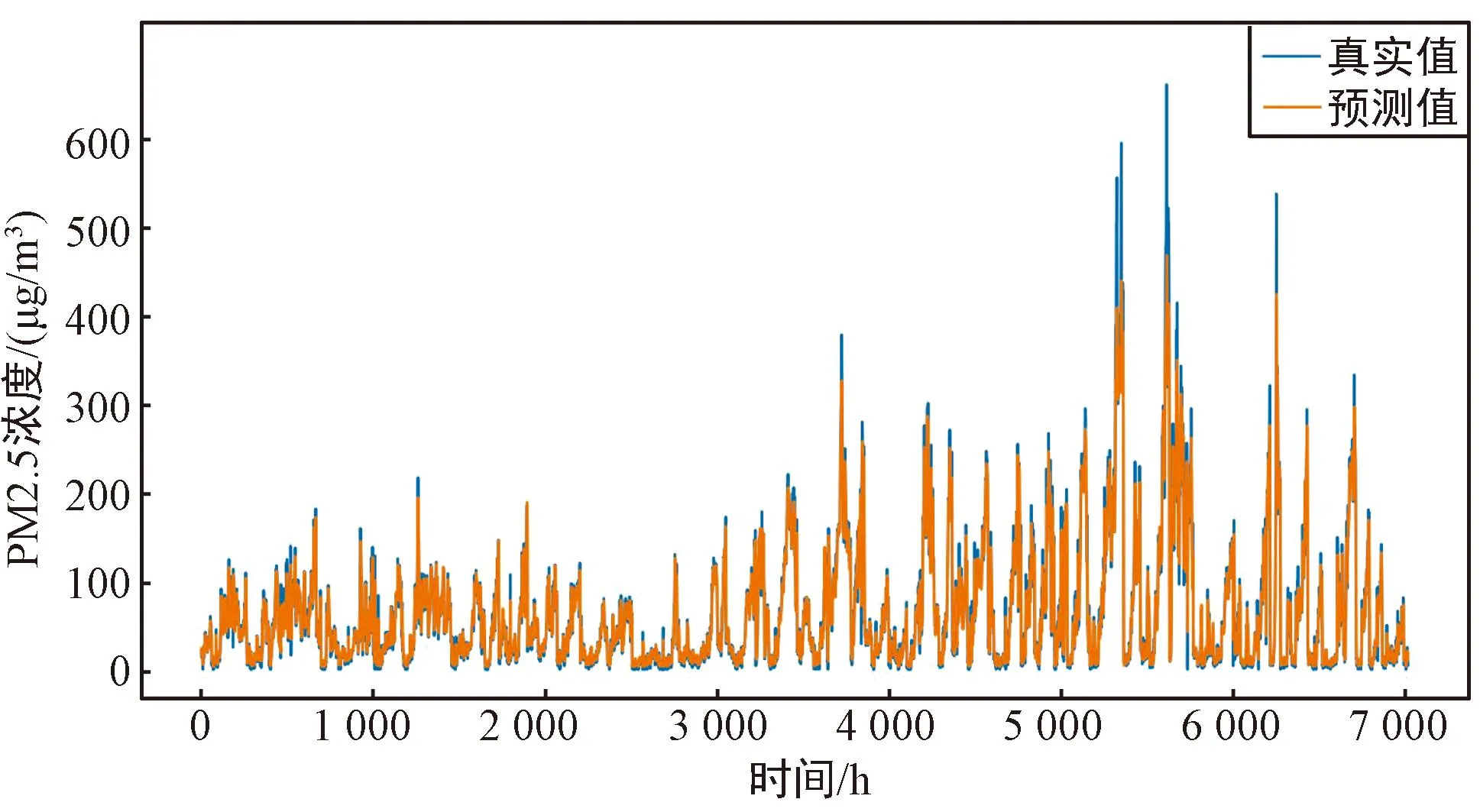
(b) S2站点的预测值与真实值的对比

(c) S3站点的预测值与真实值的对比

(d) S4站点的预测值与真实值的对比

(e) S5站点的预测值与真实值的对比

(f) S6站点的预测值与真实值的对比

(g) S7站点的预测值与真实值的对比

(h) S8站点的预测值与真实值的对比
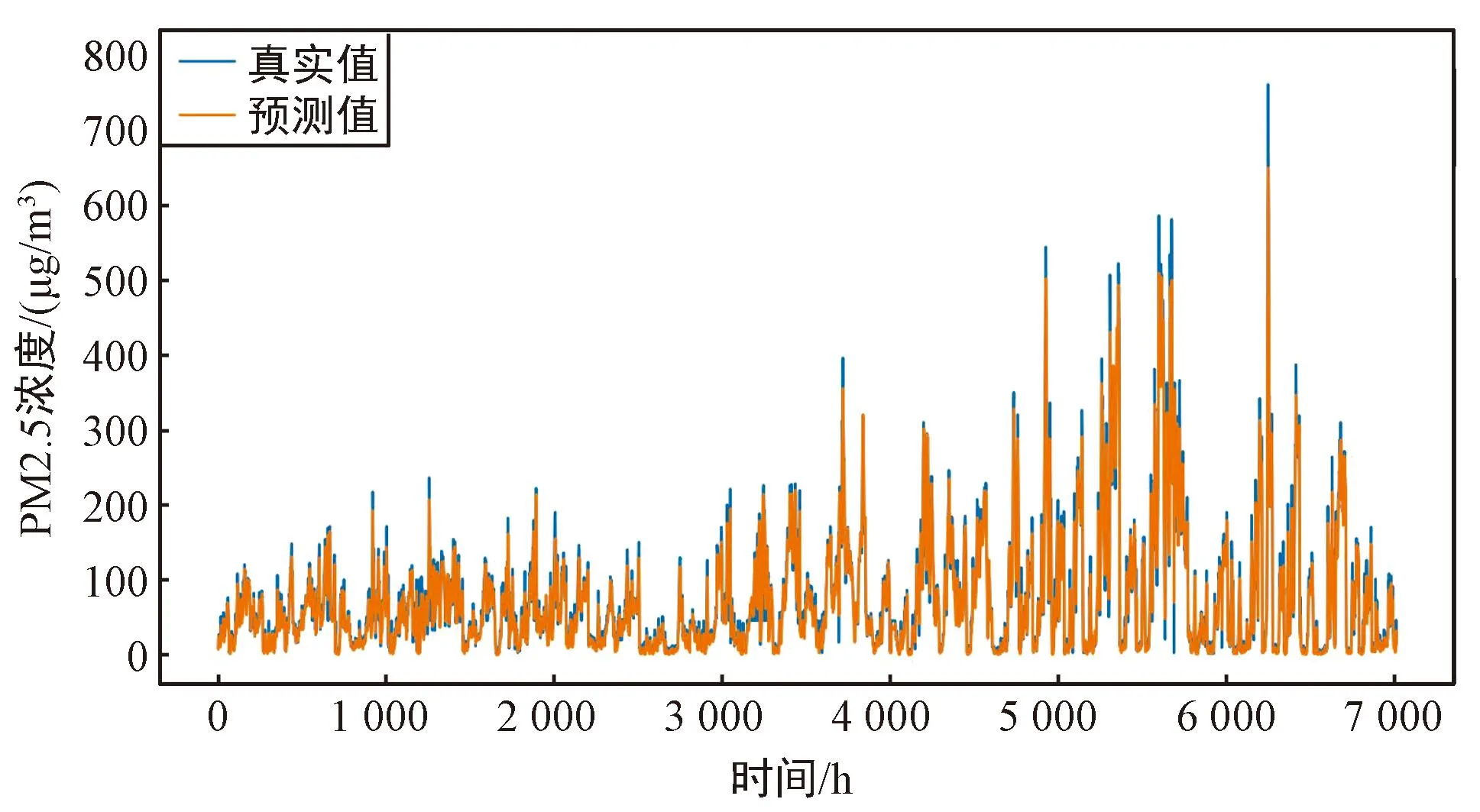
(i) S9站点的预测值与真实值的对比

(j) S10站点的预测值与真实值的对比
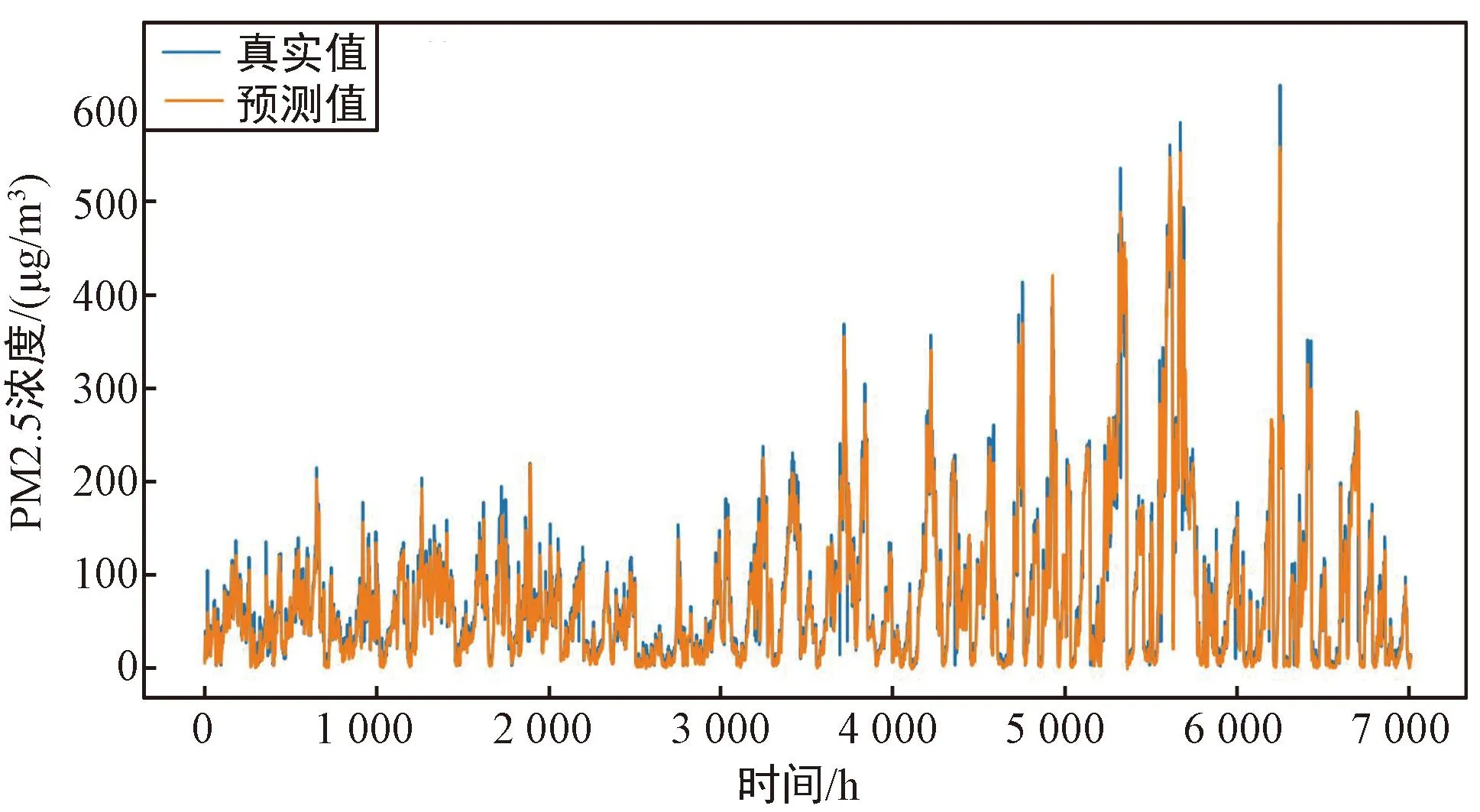
(k) S11站点的预测值与真实值的对比
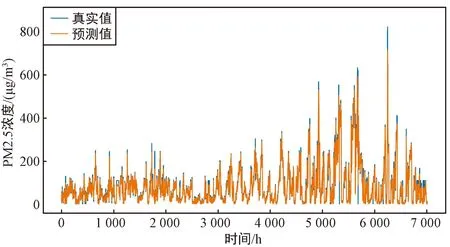
(l) S12站点的预测值与真实值的对比图5 多变量FD-BiLSTM模型在S1~S12站点上的预测值与真实值的对比Fig.5 Plot of predicted versus true values of the multivariate FD-BiLSTM model on site S1~S12
从表3和图5中可以看出,多变量FD-BiLSTM模型对北京市的12个站点PM2.5浓度预测都有较好的预测效果,R2均达到了0.934以上,RMSE、MAE、MAPE分别在22.225、12.511、0.382以下,且通过计算可以得到RMSE、MAE、MAPE、R2的均值分别为19.032、10.509、0.296、0.946。这说明本文所提出的多变量FD-BiLSTM模型能够很好地捕捉12个站点间的共同影响因素,从而在多个站点上都有良好的预测效果。
4 结束语
本文研究了PM2.5浓度预测问题,提出了一种基于频率域信息与BiLSTM的PM2.5浓度预测模型——FD-BiLSTM,以期提升PM2.5浓度预测的精度,帮助城市管理者制定科学有效的预防措施。首先,利用离散余弦变换将时间序列转换到频率域,捕获信号的频率特征;接着,使用BiLSTM可以更全面的提取出空气污染物的特征,并预测结果;最后,利用北京市12个站点的数据集进行模型测试和性能评估。实验结果表明,本文提出的单变量FD-BiLSTM模型的预测效果要优于单变量LSTM模型、BiLSTM模型、BiLSTM-attention模型、CNN-BiLSTM模型的预测效果。此外,本文提出的多变量FD-BiLSTM模型在北京市的12个站点的空气质量预测中都有较好的表现。虽然本文提出的模型在北京市的预测效果良好,但仍需要持续改进,需要在多个地区的数据上进行测试,以确保其在不同环境条件下的适应性。
猜你喜欢
今日农业(2021年19期)2022-01-12
环境保护与循环经济(2021年7期)2021-11-02
小学生学习指导(高年级)(2021年4期)2021-04-29
河北理科教学研究(2020年2期)2020-09-11
国外核新闻(2020年8期)2020-03-14
电子制作(2019年14期)2019-08-20
国际呼吸杂志(2019年1期)2019-01-28
中国自行车(2017年1期)2017-04-16
故事会(2016年21期)2016-11-10
数学年刊A辑(中文版)(2015年2期)2015-10-30
