
基于偏旁部首计数分析网络的零样本汉字识别
2023-12-14 19:16:40张琼霞王大寒朱顺痣
贵州大学学报(自然科学版) 2023年6期
关键词:注意力机制
张琼霞 王大寒 朱顺痣






摘 要:为了提高零样本汉字识别的准确率,克服传统方法在未见汉字识别上的局限性,并进一步改进以偏旁部首为基元的汉字识别方法,本研究提出了一种以注意力机制为基础的编码器-解码器架构的部首计数分析网络,用于零样本汉字识别问题。在编码器阶段,引入了多尺度部首计数模块;而在解码器阶段,则运用了多尺度注意力机制。本文将一个汉字看作是由若干偏旁部首及其空间结构组成的序列,通过计算偏旁部首及空间结构的数量,实现了对汉字的有效识别。实验结果表明,在SCUT-SPCC和CTW两个基准数据集上,本文所提出的新模型在零样本汉字识别方面表现优异。本研究能够更好地捕捉汉字的特征信息,并实现对未见汉字的准确识别。这对汉字识别领域的研究与应用具有重要指导意义,可为相关领域的研究提供新思路和方法。
关键词:汉字识别;零样本学习;部首计数分析网络;多尺度;注意力机制
中图分类号:TP391.4
文献标志码:A
作为光学字符识别(optical character recognition,OCR)领域的一个重要分支,零样本汉字识别(zero-shot Chinese character recognition,ZSCCR)已被研究多年,并在相關领域发挥着重要作用。鉴于汉字字符数量繁多、新字符层出不穷,且有些汉字(如古籍文字等)缺乏或完全没有标注样本,因此,零样本汉字识别仍是一个极具挑战性的问题。就图像识别而言,研究人员把零样本学习这一思想纳入图像识别的过程之中,赋予了图像对未见类别进行识别的功能。近些年来,很多研究人员开始在汉字识别中运用零样本学习,以解决未见汉字识别的难题。汉字是由共用的基元(偏旁部首)组成,大约500个部首便足以涵盖2万多个汉字。基于偏旁部首的零样本汉字识别方法,将汉字进行分解,形成由偏旁部首和空间结构组成的序列,将该序列作为辅助信息,参与到网络的训练和测试阶段,显著减少了识别词汇的规模,并显著提高了相似字符之间的区分度。由于有限的偏旁部首在训练阶段均已出现过,因此,基于偏旁部首的零样本汉字识别方法具备对训练集中未见过的类别进行辨识的能力。
本研究提出了一种以注意力机制为基础的编码器-解码器框架的部首计数分析网络[1],将汉字识别问题转换为图像到序列的转换问题。具体而言,本文将汉字视为由若干偏旁部首及其空间结构所构成的序列,并在编码器部分插入多尺度偏旁部首计数模块。使用此弱监督计数模块,一方面,计数结果表示部首及空间结构的数量,可以作为额外的全局信息来提高识别精度。另一方面,部首计数能够额外提供每个部首的位置信息,生成的表示计数结果的一维计数向量可以使注意力结果更加准确,从而提高识别的性能。在解码器部分,本文采用改进的覆盖注意力机制,原先覆盖注意力向量是通过简单累加而获得的,改进后的注意力机制降低大维度,提高小维度,能够关注到未被关注过的区域,从而使注意力结果更为准确,进一步提升识别准确率。
1 相关工作
在深度学习快速发展的背景下,汉字识别方法不断革新。基于深度学习技术的零样本汉字识别方法大致可分为3类[2](见图1):基于字符的方法、基于偏旁部首的方法和基于笔画的方法。
1.1 基于字符的方法
基于字符的方法将每个汉字视为一个整体来处理和标注。Ciresan等[3]提出一种端到端的多列深度神经网络(multi-column deep neural networks,MCDNN),该网络首次在汉字识别中应用卷积神经网络,通过整合8个深度网络的研究结果,在手写字符识别方面取得了优于人类水平的性能。此后,Zhang等[4]提出将传统方向图与卷积神经网络模型相结合,在当时的竞赛中,达到了最佳模型的效果,并对在线和离线手写中文字符识别进行了全面研究和新的基准数据集构建。然而,基于字符的方法面临着无法识别未见类、标记数据工作量大以及需要优化的参数过多等问题。为解决这些问题,可以将基于字符的方法与其他技术相结合,例如,结合基于模板的方法,通过学习字符与模板之间的映射关系或相似度度量来识别未知汉字。
1.2 基于偏旁部首的方法
在2018年,Zhang等[5]提出了一种新型偏旁部首分析网络(radical analysis network,RAN),用于在印刷体汉字识别中实现零样本学习。通过将空间注意力机制运用到编码器-解码器架构中,利用高效的注意力机制,能够自适应地聚焦于与汉字部首相关的最重要信息。Wang等[6]所提出的密集偏旁部首分析网络(DenseRAN)利用密集连接网络和注意力机制同时分析汉字部首及其二维结构,把每个字符视为一个部首序列,将识别任务看作是图像字幕。Wang等[7]提出了一种新型偏旁部首聚合网络(FewShotRAN),包括部首映射编码器、部首聚合模块和字符分析解码器,以利用汉字的部首级别结构实现少样本/零样本离线手写汉字识别。相较于传统的基于整体字符的识别方法,这些基于偏旁部首的识别策略在降低分类规模方面表现出显著优势,并且能够有效地应对未见类别或新出现的字符识别任务。
1.3 基于笔画的方法
基于笔画的方法将每个字符分解为笔画序列,笔画序列是汉字的最基本单元。Chen等[2]提出基于笔画分解的网络(stroke-level decomposition network,SLD-Net),将字符分解为5个笔画的组合,并采用一种基于匹配的策略,将预测的笔画序列转换为特定字符,从而有利于从根本上解决零样本问题。
人类能够在极少甚至零样本的情况下学习新概念。为了模仿这种能力,研究者们提出了零样本学习[8]的方法,以降低所需数据集数量。零样本学习的核心思想在于利用辅助信息(如属性或文本)来支持表征学习和度量学习,以实现可见类信息向未见类信息的推理迁移学习为目标,进一步推动信息在不同类别之间的迁移。零样本学习被认为是解决汉字识别字符类别繁多、已标注数据难获取及识别未见类的一种有效方法。它假设除了文本描述或属性定义等辅助信息之外,没有新类别的训练数据可用。迄今为止,许多工作已被提出用于零样本目标分类。
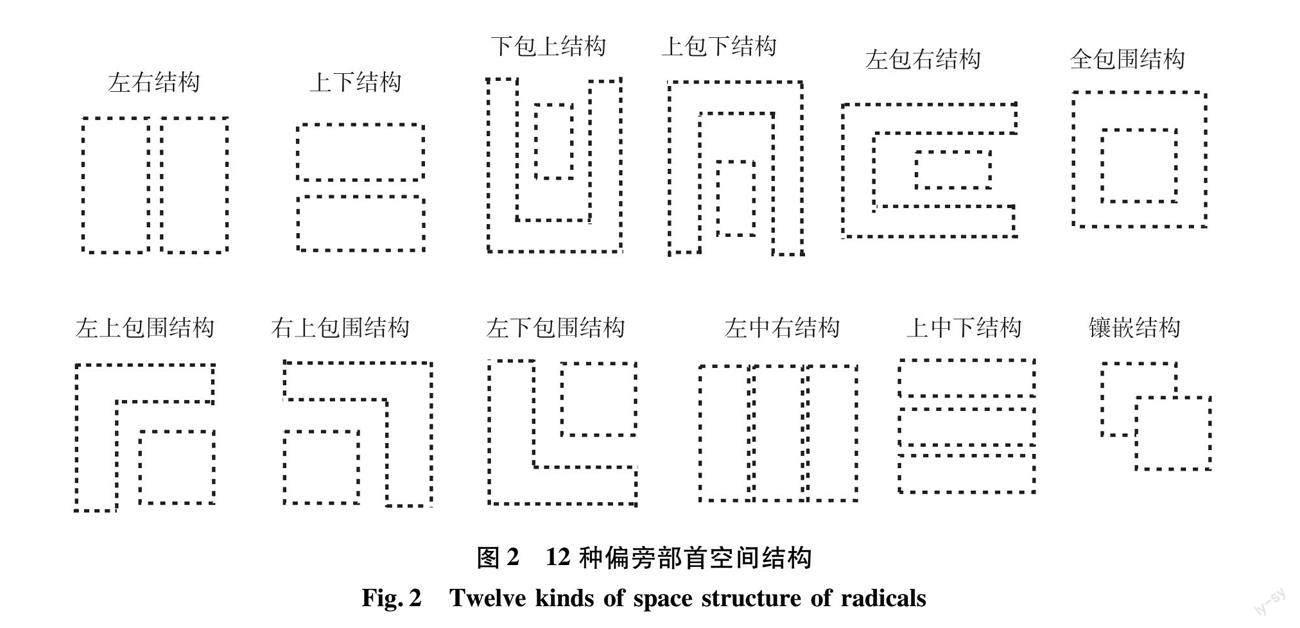
零样本汉字识别研究中最为主流的方法仍然是以基于偏旁部首分析为基础的。RAN[5]将汉字描述为500多个偏旁部首和12个字体结构的序列组合,图2展示了12种偏旁部首的空间结构,这些空间结构特征可用于描述汉字中偏旁部首的结构形态。同时,提出了一种以注意力机制为基础的编码器-解码器架构,以序列生成的形式识别汉字。Wu等[9]提出了联合空间和偏旁部首的分析网络(joint spatial and radical analysis network,JSRAN)进一步开发了RAN的潜能,并且利用空间变换机制处理旋转汉字。Yang等[10]采用了具有更强表达能力的Transformer解码器替代RAN中的GRU解码器,为汉字生成表意文字描述序列(ideographic description sequences,IDS),这增强了网络对空间结构的提取能力。2020年,Cao等[11]提出了一种新的分层分解嵌入方法(hierarchical decomposition embedding,HDE),该方法利用样本特征与语义嵌入的兼容性,实现了零样本字符分类。Huang等[12]提出了一种新型伪孪生神经网络(hippocampus-heuristic character recognition network,HCRN),使机器人能够像人类一样对特征进行记忆与总结,使机器“学会学习”。Ao等[13]提出跨模态原型学习方法(cross-modal prototype learning,CMPL),以达到零样本识别的目的。对于每个字符类,通过将打印字符映射到深度神经网络特征空间来生成原型,对于未见类,其原型可直接从打印的字符样本中产生,通过线上线下数据共享原型,实现了跨模态联合学习。Luo等[14]提出基于偏旁部首自信息的方法(self information of radicals,SIR),用于衡量偏旁部首在汉字识别的重要性,在基于序列匹配的框架中,提出了汉字不确定性消除方法(Chinese character uncertainty elimination,CUE),以减轻偏旁部首序列不匹配问题。在基于属性嵌入的框架中,提出了部首信息嵌入方法(radical information embedding,RIE),可以突显不可或缺偏旁部首的重要性,同时削弱一些不必要偏旁部首的影响。
2 部首计数分析网络
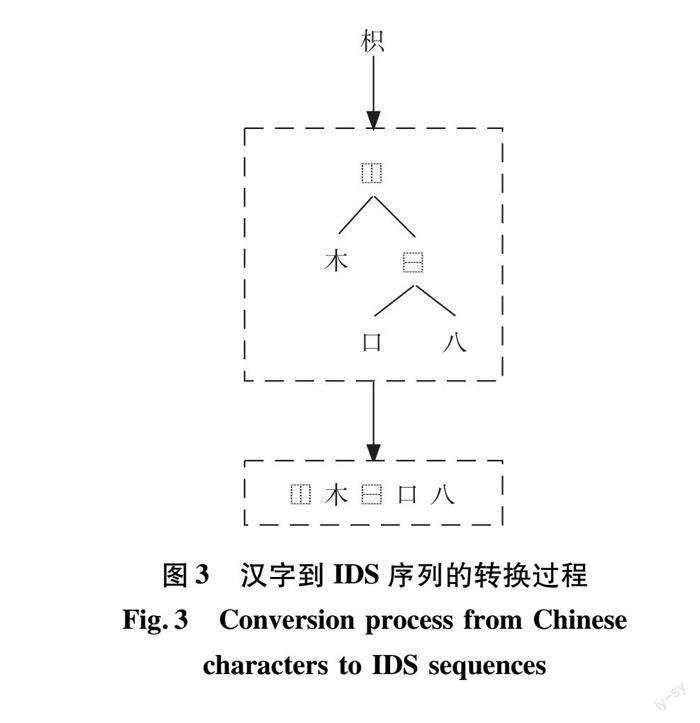
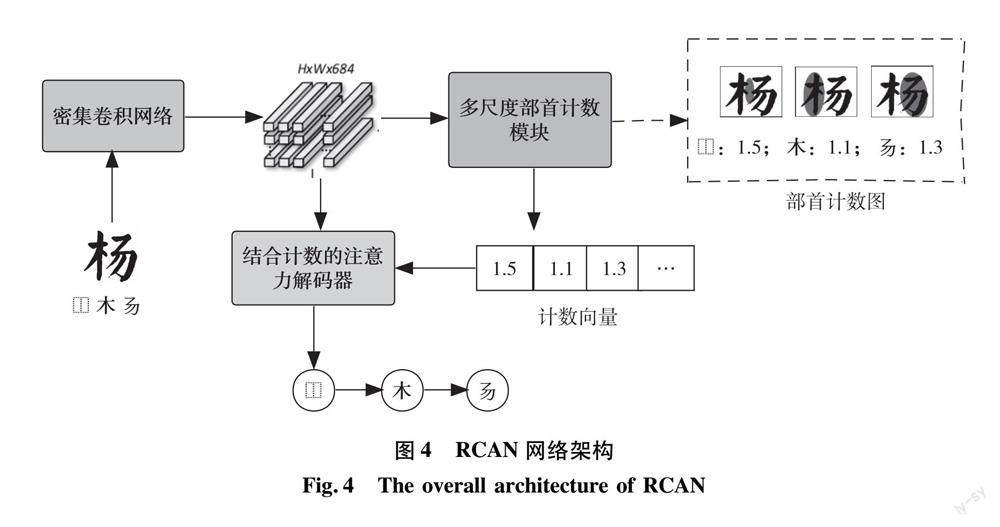
由于汉字的偏旁部首在尺寸和形状上可能表现出显著差异,同时汉字的空间结构具有多样性和复杂性,为了应对这些难题,本研究提出了一种以注意力机制为基础的编码器-解码器架构,名为部首计数分析网络(radical counter analysis network,RCAN),旨在通过将汉字图像识别为偏旁部首序列(IDS)以实现汉字识别。图3中的IDS序列是通过对偏旁部首结构树进行深度优先遍历,其中根节点上的字符表示偏旁部首结构,叶子节点上的字符表示偏旁部首,依次遍历所得。RCAN的网络架构由3个部分组成,包括主干网络、多尺度部首计数模块以及结合计数的多尺度注意力解码器。在编码器阶段,我们采用多尺度部首计数模块,其核心理念是使模型能够自主学习汉字中的偏旁部首和空间结构的计数信息。汉字通常由多个偏旁部首和空间结构组成,其出现频率和排列方式对汉字的结构和语义具有关键作用。计数感知模块能够捕获这些信息,从而有助于模型更深入地理解汉字的内在特性,进一步提升识别任务中的性能。在解码器阶段,我们应用了多尺度注意力机制,将编码器部分的向量作为输入,根据该向量生成输出序列。图4展示了RCAN的总体架构。
2.1 编码器
在编码器-解码器架构中,编码器的主要作用是从图像中提取特征,以便进行后续处理。本文选取DenseNet[15](密集卷积网络)作为主干网络,该网络采用高度稠密的短路连接策略,也就是每层输入都包括了前面全部层输出的并集。这种连接策略有助于增强特征在模型内的传递,从而使特征能够被重复利用,并在很大程度上缓解了梯度消失问题。
在本文中,使用DenseNet网络从给定的灰度图中提取高维视觉特征F,其尺寸为H×W×C,其中H表示高度,W表示宽度,C代表偏旁部首的数量。所提取的高维视觉特征将用于多尺度部首计数模块以及结合计数的注意力解码器部分。
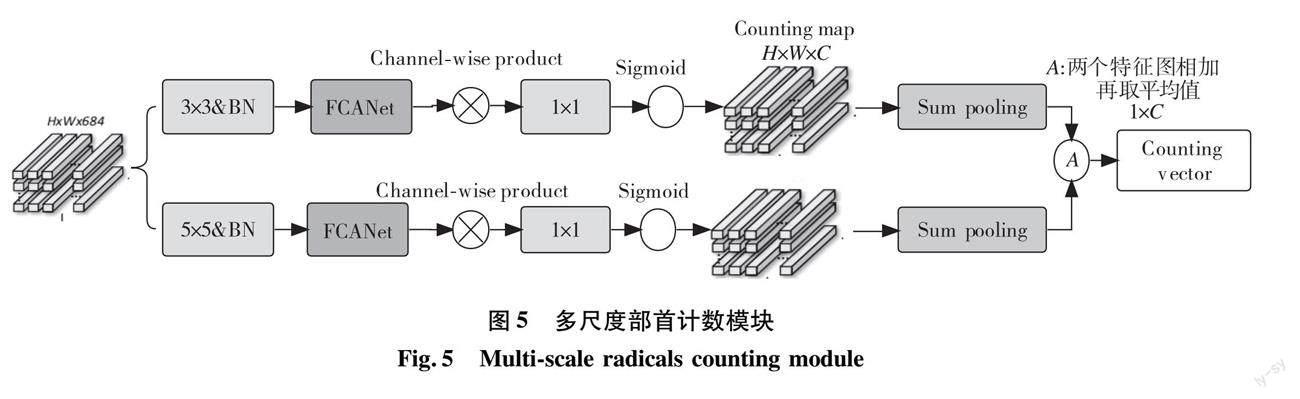
2.2 多尺度部首计数模块
在编码器部分插入多尺度部首计数模块,旨在预测汉字偏旁部首及其空间结构的数量。如图5所示,多尺度部首计数模块由多尺度特征提取、通道注意力和和池化层组成。使用大小不同的两个卷积核(分别为3×3和5×5)并行提取多尺度特征,通过并行卷积操作获得新的大小不同的特征图,从而丰富图像特征。
注意力机制实质上是通过网络自主学习,获得一组权重系数,并且采用“动态加权”方法,突出感兴趣区域并抑制与之无关的背景区域。注意力机制可以大致分为强注意力与软注意力两种类型。强注意力机制能够有效地突出动态变化。尽管效果很好,但是考虑到它不可微的特点,致使它的应用受到了一定程度的制约。区别于强注意力,软注意力具有可微性,可由神經网络中的梯度下降法训练得到,故适用范围更广。软注意力可按通道注意力、空间注意力、自注意力等不同维度(例如,通道、空间、时间、范畴等等)加以归类。利用通道注意力机制来呈现不同特征通道间的相关关系,利用深度学习自动得到各特征通道显著程度并赋予不同权重系数,从而增强了重要特征表达,抑制了非重要特征影响。
在这里,选择其中一个分支进行简单说明。本文中采用的部首计数模块在卷积层之后,采用通道注意力FCANet[16]算法对特征信息进行进一步的增强。将输入的特征图Xi(i ∈ {0,1,… ,n-1})按通道维度划分为多个部分:[X0,X 1,…,Xn-1];对其中每一部分,计算它们的二维离散余弦变换(2DDCT)频率分量Freq(以下公式中简写为f),并作为通道注意力的预处理结果,其中u,v是与Xi对应的频率分量的2D索引。具体地,可用式(1)表示。
fi=f u,v2DDCT(Xi)(1)
为了综合各部分的频域成分,通过连接(concatenate)将给定的维度进行组合,得到式(2)。
f=cat([f 0, f 1,…, f n-1])(2)
多频谱通道注意力机制描述如式(3)。
S=fsigmoid(fc(f))(3)
其中,S表示频率通道的注意力权重,用于调整频率通道的重要性,fc表示全连接层(fully connected layer),能将输入向量进行线性变换。
本方法有效地解决了通道注意力机制中信息不充分的问题。具体而言,通过对各个通道的不同频率分量进行独立评估,确定每个频率成分的重要度,并进一步分析不同数量的频率成分对结果的影响。通过使用1×1卷积将信道数从C’降低为C,其中C是偏旁部首的数量,我们得到了一个sigmoid函数生成的(0,1)范围内的计数伪密度图M∈RH×W×C。对于每个Mi∈RH×W,它能够有效地反映第i个符号类别的位置。从这个角度看,每个Mi实际上是一个伪密度图,可以利用求和池化来获得计数向量V∈R1×C ,其中Vi 表示第i类符号的预测计数,如公式(4)所示。
Vi=∑Hp=1∑Wq=1Mi,pq(4)
值得注意的是,不同分支所包含的特征图包含不同尺度的信息,并且具有高度互补性。因此,将互补计数向量结合起来,并使用平均操作生成最终计数结果:Vf∈R1×C,将此结果输入到解码器中。
2.3 带注意力的解码器
RCAN的解码器利用编码器部分得到的高维视觉特征来生成目标序列,即汉字的偏旁部首及空间结构序列(IDS)。IDS序列可用数学符号表示为Y={y1,y2,…,yT},其中yi∈RC,C表示IDS序列中字符构成的字典大小,包括 396个偏旁部首和12个偏旁空间结构(在识别时将空间结构视为偏旁部首)。结合计数的注意力解码器的部分结构如图6所示。
从图片获得高维视觉特征F∈RH×W×684。首先,采用1×1大小的卷积核来调整通道数量,并得到转换后的特征T∈RH×W×512。为了增强模型对空间位置的感知能力,使用固定的绝对编码P∈RH×W×512来表示T中不同的空间位置。具体而言,采用了空间位置编码[17],该编码对两个空间坐标独立使用具有不同频率的正弦和余弦函数。
在生成注意力图时,采用一个11×11的大卷积核和一个5×5的小卷积核并行地提取多尺度特征,较大的卷积核能够捕捉输入图像更广阔的信息范围,而小的卷积核则能够获取像素八领域信息的最小尺寸。通过同时使用不同尺寸的卷积核进行并行卷积操作,可以增强图像特征的丰富性。
图像到序列识别的输入输出是可变长度的,为解决可变长度的输入输出对齐问题,本文采用带注意力机制的解码器进行图像到序列的识别。在解码过程中,第t步解码时,利用第t-1步的输出符号yt-1嵌入到GRU(门控循环单位)中,计算得到隐藏状态ht∈R1×256。通过这个隐藏状态,可以得到注意力系数αT∈RH×W,如式(7)所示。
ht=GRU(yt-1,ht-1)(5)
et=ωTtanh(T+P+WaA+Whht)+b(6)
αt,ij=exp(et,ij)/∑Hp=1∑Wq=1et,pq (7)
其中,et是当前时间步的输出值,αt,ij是第t解码时刻输出与输入里第i个元素的注意力概率,ω、Wa、Wh和b是可优化参数和偏置项,覆盖注意力A是所有过去注意力权重的总和。
覆盖注意力A通过注意力机制简单累加而获得,然而,由于两种分布的维度变化过于单一,可能导致原本关注过的区域获得更多的关注,而缺乏直接的维度变化。本文改进了覆盖注意力,借鉴了RMSPorp[18]和《带有覆盖率机制的文本摘要模型研究》[19]等论文的思想,将原来的覆盖注意力向量修改为如式(8),其目的是为了降低注意力机制在累加过程中被过分关注的维度。e-at-1为了降低大维度,提高小维度,使得st的累加结果能够关注到未被关注过的区域。 μ为超参数,调节 st累加的来源,实验选取0.85。
s=μst-1+(1-μ)e-at-1(8)
通过将注意力权重αt和高维视觉特征F进行空间乘积,可以得到上下文特征向量C’∈R1×256,其主要作用是为了对齐编码器和解码器,从而解决编码序列和解码序列长度不一致的问题。解码操作本质上也是分类问题,选取概率最高的字符作为当前的解码字符。实际上,上下文特征向量C’只对应于特征图F的局部区域,仅用于捕捉该位置周围的上下文信息,具有局部性。此外ht和E(yt-1)也缺乏全局信息。为了提高预测的准确性,考虑使用计数向量V作为额外的全局信息,并将它们与上下文特征向量C’组合起来预测yt,字符的输出概率如式(9),其中,ωo、Wc、Wv、Wt、We和bo是可优化参数和偏置项。
p(yt)=fsoftmax(ωTo(WoC’+WvV+Wtht+WeE))+bo(9)
yt~p(yt)(10)
3 实验分析
3.1 实验数据集
本研究在SCUT-SPCCI和CTW兩个数据集上进行了实验,证明所提方法的有效性。其中:
SCUT-SPCCI(South China University of Technology,Synthesized printed Chinese character image,华南理工大学合成印刷中文字符数据集)[20]为一个多字体打印字符数据集,包含280种不同的字体。本研究选择了3 755个常用字符和34种不同的字体作为整体数据集。这3 755个字符由406个偏旁部首以及12个空间结构所组成。如图7所示,基本训练集包含2 955个字符类别和30种字体,测试集由剩下的800个字符类别组成,这些字符类别有同样的30种字体。与少样本学习(few-shot)类似,N-shot训练集由基本训练集和其他N种字体的3 755个字符类别组成。在基本训练集中的字符包含所有部首的前提下,字符集划分是随机的。输入图像的大小为48×48。
CTW(Chinese text in the wild, 自然场景中文字符数据集)[21]是一个超大的街景图片中文文本数据集,具有大约100万个样本,这些样本由6个不同的属性组成,如图8所示为CTW数据集中不同属性的部分例子。由于其多样性和复杂性,CTW数据集是一个非常具有挑战性的常用数据集,能够真实地反映模型的实用性。在以下实验中,输入图像大小被均匀地调整为32×32。
3.2 实验配置
训练阶段使用一个NVIDIA Tesla V100 型号GPU。使用Adadelta优化器对模型参数进行优化,并将学习率初始化为1.0。为了避免模型过拟合,我们设置了一个权重衰减率为1e-4。此外,将训练批次大小设置为160,并使用字符识别准确率(ExpRate)作为评价标准。
3.3 主要实验结果
3.3.1 在SCUT-SPCC数据集上的结果
为了验证RCAN的性能,进行了一系列实验,其中包括了对WCN(whole character network,全字符网络)、RNA、RCN(radical counter network,部首计数网络)在零样本和少样本情况下的对比。如表1的实验结果所示,无论是在零样本或者少样本情况下,RCAN在汉字识别方面的准确率均高于所对比方法。这表明该网络能够有效学习汉字的偏旁部首和空间结构信息,并在一定程度上提升零样本汉字识别的准确率。以上识别准确率结果表明,RCAN可以从训练集中有效地学习汉字部首和空间结构信息,从而能够在一定程度上增强对未见汉字的识别准确率。这种提高准确率的能力可以归因于RCAN所采用的特殊方法。具体而言,该方法可以通过对汉字部首进行计数和分析,提取出汉字的特征信息。这些特征信息不仅包括汉字的语义信息,还包括其形状和结构信息,这些信息对于汉字的识别非常重要。此外,RCAN还可以通过学习汉字之间的相似性以及差异性,来进一步提高其识别准确率。总之,我们的实验结果表明,RCAN是一种非常有效的方法,可用于提高零样本汉字识别的准确率。
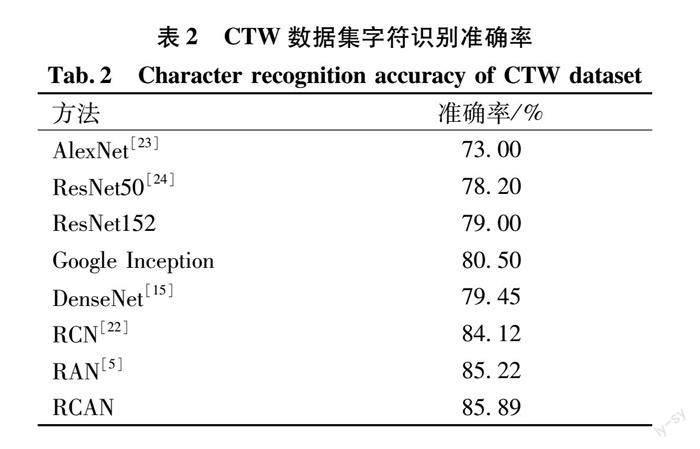
3.3.2 在CTW数据集上的结果
在本研究中,我们进行了与RCN[22]相似的实验,仅选取了CTW数据集中出现频率最高的前1 000个字符类别进行对比实验。如图9部分字符识别结果对比所示,与RCN相比,RCAN在识别构成字符的偏旁部首数量以及空间结构数量方面准确率更高。同时因为RCAN引入汉字的空间结构信息,从而避免了像RCN那样的识别顺序错误。如表2所示,通过对实验结果进行分析,证明RCAN在识别性能方面表现优于其他算法。
4 结论
本文引出了一种以注意力机制为基础的编码器-解码器架构的部首计数分析网络。在该网络中,采用密集卷积网络作为编码器,并引入多尺度部首计数模块。通过解码器阶段的多尺度注意力机制,将汉字视为由若干偏旁部首及其空间结构所构成的序列,并计算出构成一个汉字的部首及空间结构的数量。实验結果表明,本文提出的网络在未见类汉字识别方面具有优越性,并且在自然场景文本数据集上表现良好的鲁棒性。未来工作中,将探究该网络在其他语言识别任务中的应用能力,并将其应用于更为复杂的汉字识别任务,例如古籍文字识别等。此外,还将致力于进一步优化网络性能,以提高其在实际应用场景中的效果。综上,本研究提出的RCAN对于汉字相关领域的研究具有重要意义,并将为相关领域的研究提供有力支持。
参考文献:
LI B H,YE Y,LIANG D K,et al. When counting meets HMER: counting-aware network for handwritten mathematical expression recognition[C]//European Conference on Computer Vision. Cham: Springer Nature Switzerland, 2022: 197-214.
[2] CHEN J Y,LI B,XUE X. Zero-shot Chinese character recognition with stroke-level decomposition[C]//Proceedings of the Thirtieth International Joint Conference on Articicial Intelligence,IJCAI 2021,Virtual Event/Montreal Canada,19-27 August 2021.IJCAI ORG,2021: 615-621.
[3] CIRESAN D , SCHMIDHUBER J. Multi-column deep neural networks for offline handwritten Chinese character classification[C]//2015 International Joint Conference on Neural Networks (IJCNN). IEEE, 2015: 1-6.
[4] ZHANG X Y, BENGIO Y, LIU C L. Online and offline handwritten Chinese character recognition: a comprehensive study and new benchmark[J]. Pattern Recognition, 2017, 61: 348-360.
[5] ZHANG J S, ZHU Y X, DU J, et al. Radical analysis network for zero-shot learning in printed Chinese character recognition[C]//2018 IEEE International Conference on Multimedia and Expo (ICME).San Diego, CA: IEEE, 2018: 1-6.
[6] WANG W C, ZHANG J S, DU J, et al. Denseran for offline handwritten Chinese character recognition[C]//2018 16th International Conference on Frontiers in Handwriting Recognition (ICFHR).Niagara Falls, NY, USA: IEEE, 2018: 104-109.
[7] WANG T W, XIE Z C, LI Z, et al. Radical aggregation network for few-shot offline handwritten Chinese character recognition[J]. Pattern Recognition Letters, 2019, 125: 821-827.
[8] ZHANG Z M, Saligrama V. Zero-shot learning via semantic similarity embedding[C]//Proceedings of the IEEE International Conference on Computer Vision.Santiago,Chile, 2015: 4166-4174.
[9] WU C J, WANG Z R, DU J, et al. Joint spatial and radical analysis network for distorted Chinese character recognition[C]//2019 International Conference on Document Analysis and Recognition Workshops (ICDARW).Sydney, Australia: IEEE, 2019, 5: 122-127.
[10]YANG C, WANG Q, DU J, et al. A transformer-based radical analysis network for Chinese character recognition[C]//2020 25th International Conference on Pattern Recognition (ICPR). Milan, Italy:IEEE, 2021: 3714-3719.
[11]CAO Z, LU J, CUI S, et al. Zero-shot handwritten Chinese character recognition with hierarchical decomposition embedding[J]. Pattern Recognition, 2020, 107: 107488.
[12]HUANG G J, LUO X Y, WANG S W, et al. Hippocampus-heuristic character recognition network for zero-shot learning in Chinese character recognition[J]. Pattern Recognition, 2022, 130: 108818.
[13]AO X, ZHANG X Y, YANG H M, et al. Cross-modal prototype learning for zero-shot handwriting recognition[C]//2019 International Conference on Document Analysis and Recognition (ICDAR).Sydney, Australia:IEEE, 2019: 589-594.
[14]LUO G F, WANG D H, DU X, et al. Self-information of radicals: a new clue for zero-shot Chinese character recognition[J]. Pattern Recognition, 2023, 140: 109598.
[15]HUANG G, LIU Z, VAN DER MAATEN L, et al. Densely connected convolutional networks[C]//2017 IEEE Conference on Computer Vision and Pattern Recognition(CVPR).Honolulu,HI:IEEE, 2017:2261-2269.
[16]QIN Z Q, ZHANG P Y, WU F, et al. Fcanet: frequency channel attention networks[C]//Proceedings of the IEEE/CVF International Conference on Computer Vision. Montreal,Canada,2021: 783-792.
[17]VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need[J]. Advances in Neural Information Processing Systems, 2017:6000-6010.
[18]RUDER S. An overview of gradient descent optimization algorithms[J]. arXiv preprint arXiv:1609.04747, 2016.
[19]巩轶凡, 刘红岩, 何军, 等. 带有覆盖率机制的文本摘要模型研究[J]. 计算机科学与探索, 2019, 13(2): 205-213.
[20]ZHONG Z Y, JIN L W, FENG Z Y. Multi-font printed Chinese character recognition using multi-pooling convolutional neural network[C]//2015 13th International Conference on Document Analysis and Recognition (ICDAR). Beijing,China:IEEE, 2015: 96-100.
[21]YUAN T L, ZHU Z, XU K, et al. A large Chinese text dataset in the wild[J]. Journal of Computer Science and Technology, 2019, 34: 509-521.
[22]LI Y Q, ZHU Y X, DU J, et al. Radical counter network for robust Chinese character recognition[C]//2020 25th International Conference on Pattern Recognition (ICPR).Milan, Italy: IEEE, 2021: 4191-4197.
[23]KRIZHEVSKY A, SUTSKEVER I, HINTON G E. Imagenet classification with deep convolutional neural networks[J]. Communications of the ACM, 2017, 60(6): 84-90.
[24]HE K M, ZHANG X Y, REN S Q, et al. Deep residual learning for image recognition[C]//2016 IEEE Conference on Computer Vision and Pattern Recognition(CVPR).Las Vegas,NV,USA:IEEE, 2016: 770-778.
(責任编辑:曾 晶)
Radical Counter Analysis Network for Zero-shot Learning
Chinese Character Recognition
ZHANG Qiongxia1,2,3, WANG Dahan*1,2, ZHU Shunzhi1,2
(1.School of Computer and Information Engineering,Xiamen University of Technology,Xiamen 361000,China;
2.Fujian Key Laborary of Pattern Recognition and Image Understanding,Xiamen 361000,China;
3.School of Mechatronics and Information Engineering,Putian University,Putian 351100,China)
Abstract:
In order to improve the accuracy of zero-shot Chinese character recognition (ZSCCR), overcome the limitations of traditional methods for unseen Chinese character recognition,and further improve the Chinese character recognition methods which take radicals as primitives,this study proposes a radical counting analytic network based on the attention mechanism for an encoder-decoder architecture for the zero-shot Chinese character recognition problem. In the encoding stage, a multi-scale radical counting module is introduced, while in the decoding stage, a multi-scale attention mechanism is applied. In this paper, a Chinese character is regarded as a sequence consisting of a number of radicals and their spatial structures, and effective recognition of Chinese characters is achieved by counting the number of radicals and spatial structures. Experimental results on two benchmark datasets, SCUT-SPCC and CTW, show that the proposed model performs well in the recognition of zero-shot Chinese characters. This study is able to better capture the feature information of Chinese characters and achieve accurate recognition of unseen Chinese characters. This is of great significance in guiding the research and application in the field of Chinese character recognition, and can provide new ideas and methods for related fields.
Key words:
Chinese character recognition; zero-shot learning; radical counting analysis network; multi-scale; attention mechanism
猜你喜欢
计算机应用(2019年3期)2019-07-31 12:14:01
无线互联科技(2019年9期)2019-07-29 00:41:36
无线互联科技(2019年9期)2019-07-29 00:41:36
智能计算机与应用(2019年3期)2019-07-01 02:35:55
智能计算机与应用(2019年3期)2019-07-01 02:35:55
智能计算机与应用(2019年3期)2019-07-01 02:35:55
电子技术与软件工程(2019年5期)2019-06-20 10:31:23
软件导刊(2019年1期)2019-06-07 15:08:13
数字技术与应用(2019年2期)2019-05-14 08:25:10
现代电子技术(2018年8期)2018-04-13 06:36:32
贵州大学学报(自然科学版)2023年6期