
动态环境下基于深度学习的视觉SLAM研究
2023-12-14 19:16:40张庆永杨旭东
贵州大学学报(自然科学版) 2023年6期
关键词:目标检测
张庆永 杨旭东









摘 要:由于传统的同步定位与建图(simultaneous localization and mapping,SLAM)中有很强的静态刚性假设,故系统定位精度和鲁棒性容易受到环境中动态对象的干扰。针对这种现象,提出一种在室内动态环境下基于深度学习的视觉SLAM算法。基于ORB-SLAM2进行改进,在SLAM前端加入多视角几何,并与YOLOv5s目标检测算法进行融合,最后对处理后的静态特征点进行帧间匹配。实验使用TUM数据集进行测试,结果显示:SLAM算法结合多视角几何、目标检测后,系统的绝对位姿估计精度在高动态环境中相较于ORB-SLAM2有明显提高。与其他SLAM算法的定位精度相比,改进算法仍有不同程度的改善。
关键词:多视角几何;目标检测;同步定位与建图;动态环境
中图分类号:TP391.9
文献标志码:A
同步定位与建图(simultaneous localization and mapping,SLAM)是指机器人在未知环境下,通过自身搭配的传感器对自身位姿进行估计并构建环境地图。该技术被认为是机器人执行定位、导航等自主化行为的重要技术[1]。
目前,视觉SLAM根据使用方法可分为两种:以FAST角点为特征提取并以BRIEF描述子作为身份信息匹配的特征点法,可进行稀疏点云建图;以图像灰度值信息来直接判断相机运动的直接法,可进行稠密点云建图,但具有一定的灰度不变性假设。ORB-SLAM2[2]被认为是最完整的视觉SLAM框架之一,同时也是特征点法的代表,但其在高动态工作环境下效果不尽人意,导致SLAM系统在实际场景中的适用性不高。直接法的实现基于灰度不变的假设,但环境中的光线时常变化,假设很难完全成立,因此基于直接法的SLAM系统鲁棒性较差。在室内动态环境中,无规律变化的运动物体上提取的特征点会严重影响相机位姿评估的准确性。ENGEL等[3]提出的LSD-SLAM利用灰度值来实现定位并构建半稠密点云建图,基于稀疏直接法的DSO-SLAM[4]则在鲁棒性、精度和速度上都较好于LSD-SLAM,但其不包含回环检测功能,是一个不完整的SLAM算法。
随着深度学习的快速发展,基于深度学习的室内动态场景视觉SLAM逐渐受到人们的关注[5]。YU等[6]基于ORB-SLAM2的视觉系统,与SegNet[7]语义分割网络融合提出了DS-SLAM。该系统消除了环境中运动对象的影响,极大程度上提高了相机的定位精度,并建立了八叉树语义地图。BESCOS等[8]提出的DynaSLAM将实例分割网络与多视角几何结合,实现了动态特征点的去除以及背景修复的功能。WU等[9]设计了一个Darknet19-YOLOv3 的轻量级目标检测网络,采用低延迟骨干网加速,将物体检测和几何约束结合提高了鲁棒性,但是仅利用了动态信息,未结合其他静态信息。高逸等[10]基于YOLOv5s目标检测网络提取动态特征点,并结合几何约束剔除其他潜在动态特征点。CHEN等[11]提出一种将目标监测网络与传统单目结合的SLAM算法,框选出环境中的动态物体并删除框内特征点,起到了去除动态特征点的效果,但因框体过大而剔除过多的有效特征点,定位精度下降。WEN等[12]提出一种新的SLAM方法,对每一个关键点分配鲁棒权重,利用Mask R-CNN[13]检测环境中的动态物体并为每个像素点创建标签来建立语义地图,实现分割动态对象的目的。文献[14]提出了一种基于实例分割和多视角几何的动态视觉SLAM框架。房立金等[15]提出一种利用深度学习提高定位精度的视觉SLAM方法,通过光流法与实例分割网络的结合,来达到去除动态特征点的效果。
以上国内外学者的研究都融合了深度学习和纯几何的动态检测算法,但实例分割对硬件性能要求较高,使用目标检测会遗漏其他先验信息。为了确保SLAM系统能够适应复杂多变的室内动态环境,本文提出了一种基于深度学习和多视角几何的SLAM框架,对YOLOv5目标检测框内物体进行动静态对象区分,并结合多视角几何去除干扰特征点。改进后的系统于TUM数据集上进行仿真实验,结果与ORB-SLAM2以及其他开源的优秀算法进行对比,验证了理论的可行性。
1 系统框架
1.1 ORB-SLAM2系统
ORB-SLAM2是目前应用较广的一套完整的开源SLAM方案。它主要由跟踪(Tracking)、局部建图(Local mapping)和回环检测(Loop closing)3个线程组成,如图1所示。跟踪线程对传入系统的每一帧提取ORB特征点并建立描述子匹配,以此推测帧间位姿。局部建图线程将上一个线程产生的关键帧插入,遍历后择优建图。回环检测线程判断是否产生回环并融合校正。
1.2 改进的SLAM系统
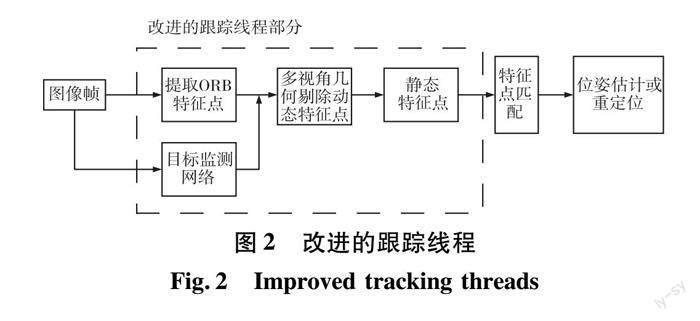
对于传统的跟踪线程中,动态对象上提取的ORB特征点会在匹配位姿时不断给系统增加累积误差,最终导致位姿评估精度降低甚至定位失败。为了降低动态物体对系统的干扰,影响系统定位精度的問题,本文对ORB-SLAM2的跟踪线程进行改进,增加了目标检测模块和多视角几何,如图2所示。在前端新增一个检测线程,跟踪与检测线程信息共享。首先,当图像帧传入系统后,输入跟踪与检测线程。跟踪线程对图像提取ORB特征点,检测线程根据先验信息识别对象(本文主要识别屏幕、椅子、人),计算各个类别的框体位置并传回跟踪线程,跟踪线程根据传回的框体信息和类别编号划分动静态框,下文通过动静框结合的策略判断动态特征点。其次,使用多视角几何算法,根据当前帧与关键帧的关键点进行计算,通过投影深度的变化大小来判断动态特征点。再次,将目标检测和多视角几何判定的动态特征点去除,对剩下的静态点进行特征匹配来估计位姿。
1.3 YOLOv5目标检测网络
YOLO是一种基于神经网络的对象识别和定位算法,运行速度快且可以运用于实时系统,是目前应用最为广泛的单阶段目标检测算法之一[16]。YOLOv5版本包含YOLOv5n、YOLOv5s、YOLOv5m、YOLOv5l、YOLO5x这5个模型。从YOLOv5n到YOLO5x,YOLOv5模型的检测精度逐渐上升,检测速度逐渐下降。各版本之间网络架构基本相同,模型的主要区别是depth_multiple和width_multiple,通过调节这2个参数来控制网络的深度和宽度。
与之前发布的YOLOv3[17]、YOLOv4[18]相比,YOLOv5有以下几点改进:训练模型阶段进行了Mosaic数据增强、自适应anchor和letterbox的优化;Backbone层融合了Focus结构和CSP结构;Neck网络添加了FPN+PAN结构;Head输出层针对损失函数GIOU_Loss以及预测框筛选的GIOU_nms进行了改进。
因YOLOv5s在精度和速度上取得较好的平衡,本文选择使用较广的YOLOv5s网络进行动态目标检测。相比于YOLOv4,YOLOv5s大小仅为27 MiB,推理速度快,满足视觉SLAM系统的实时检测需求。
YOLOv5检测框的数据结构以(X, Y, W, H, class, confidence)格式输出,其分别代表检测框中心点的X坐标、Y坐标,框的宽度、高度,以及类别和置信度。为了方便在SLAM系统中读取,我们将前4个位置信息转化成原图像下的坐标,转换公式如下:
X1=(X-W2)×640
X2=(X+W2)×640
Y1=(Y+H2)×480
Y2=(Y-H2)×480 (1)
式中:(X1,Y1)、(X2,Y2)分别为检测框的左上角和右下角坐标;640和480分别为图片的宽和高。
本文根据类别来定义动静框,对人的检测框设为动态框,对其他物体暂定为静态框。跟踪线程提取ORB特征点后收到来自YOLOv5的检测数据,接着遍历框内的特征点,根据框的不同定义不同的特征点。图3是特征点示意图。当2框重叠时,判断特征点是否在动态框内且在静态框外,满足则将其定义为动态特征点,不满足则为静态特征点。
以TUM数据集为例,室内动态场景中除人之外还有很多静态物体,如:桌子、电脑等,椅子则是潜在运动物体,它跟随人的状态变化而变化。如果单一地去除人像目标检测框中的特征点,则容易因为特征点过少而跟踪失败,故采取动静框结合的策略提取动态特征点。提取的动态特征点去除后的效果如图4所示。由图4可见:在人体目标检测框中的ORB特征点并没有全部删除,因为检测框中的物体并不全是动态对象,还有诸如电脑屏幕、主机等其他静态物体,因此,动态物体检测框内的静态物体检测框中的特征点依然保留。
1.4 基于多视角几何的动态物体判别方法
对于每一个传入系统的输入帧,选择5个之前和输入帧有最高重合度的关键帧,其中,重合度是由每个关键帧和传入系统的新一帧之间的距离和旋转来决定。图5是基于多视角几何的动态点检测算法。如图5所示,我们将先前关键帧中的每个关键点都投影到当前帧,得到关键点p′和它们的投影深度dproj,d′是当前帧中关键点的深度,每个关键点对应的3D点是P。计算p和p′反投影之间的视差角度α。深度的重投影误差Δd=dproj-d′。
如果视差角α>30°,则认为该点有可能是静态点出现遮挡情况,在之后的进程中将会被忽略;如果视差角α<30°且△d>τd时,关键点p′就会被视为动态物体。其中,τd为深度阈值。为了有一个好的精度和召回率,通过最大化0.7×Precision+0.3×Recall [6],可以将τd设定为0.4。
使用多视角几何时,系统从当前帧相近的关键帧中抽取特征点,当获得的投影深度与其实际深度之差大于τd时,则判定特征点为动态。同时对位于动态物体边界上被标记为动态的关键点进行判定,若该关键点被设定为动态,但在深度图中其周围区域存在很大的方差,则更改标签为静态。最后,将目标检测得出的动态标签点与多视角几何判定的动态特征点剔除。图6为多视角几何动态检测效果,动态特征点已被剔除。
目标检测虽能迅速地找到动态对象,但有些物体本身是静态的,只有当人接触并使用的时候才变为动态,如数据集中的椅子。我们不能直接把椅子作为动态对象,因为这样会失去很多它静态时的有用的特征点。使用多视角几何时可以有效地根据椅子的运动状态来去除特征点,但是仅仅使用多视角几何也并不合适。当人运动到隔板后时,多视角几何也不能对其覆盖掩膜,动态特征点仍然存在。图7是目标检测融合多视角几何的效果。由图7可以看出:(a)图右边椅子上还有零散的特征点分布;(b)图人体身上覆盖掩膜,这是人在坐下的过程中拉动或者推动椅子,导致椅子由静态物体转变成为一个动态物体;(c)图椅子上的特征点已经被去除了。
2 实验与建图
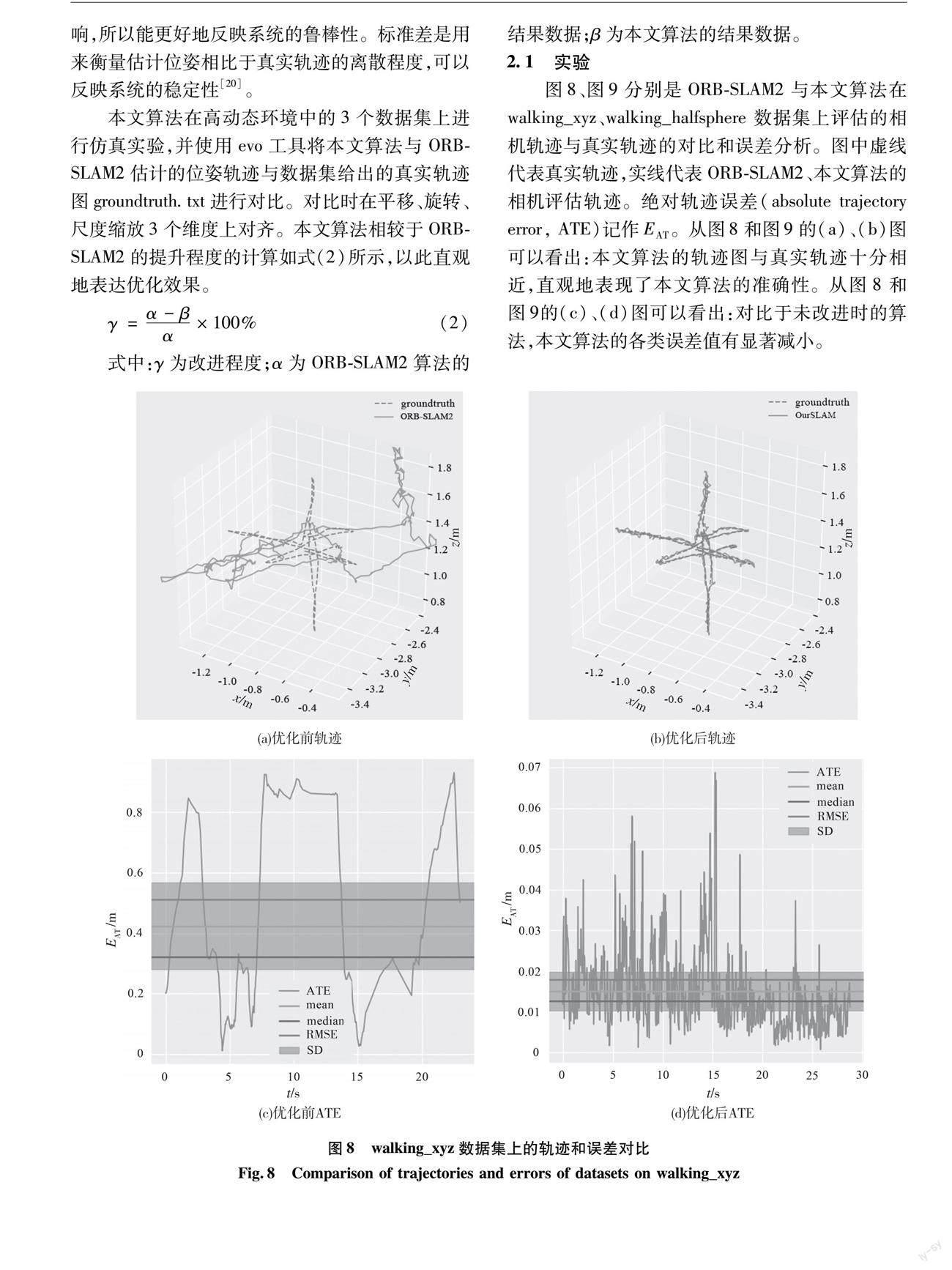
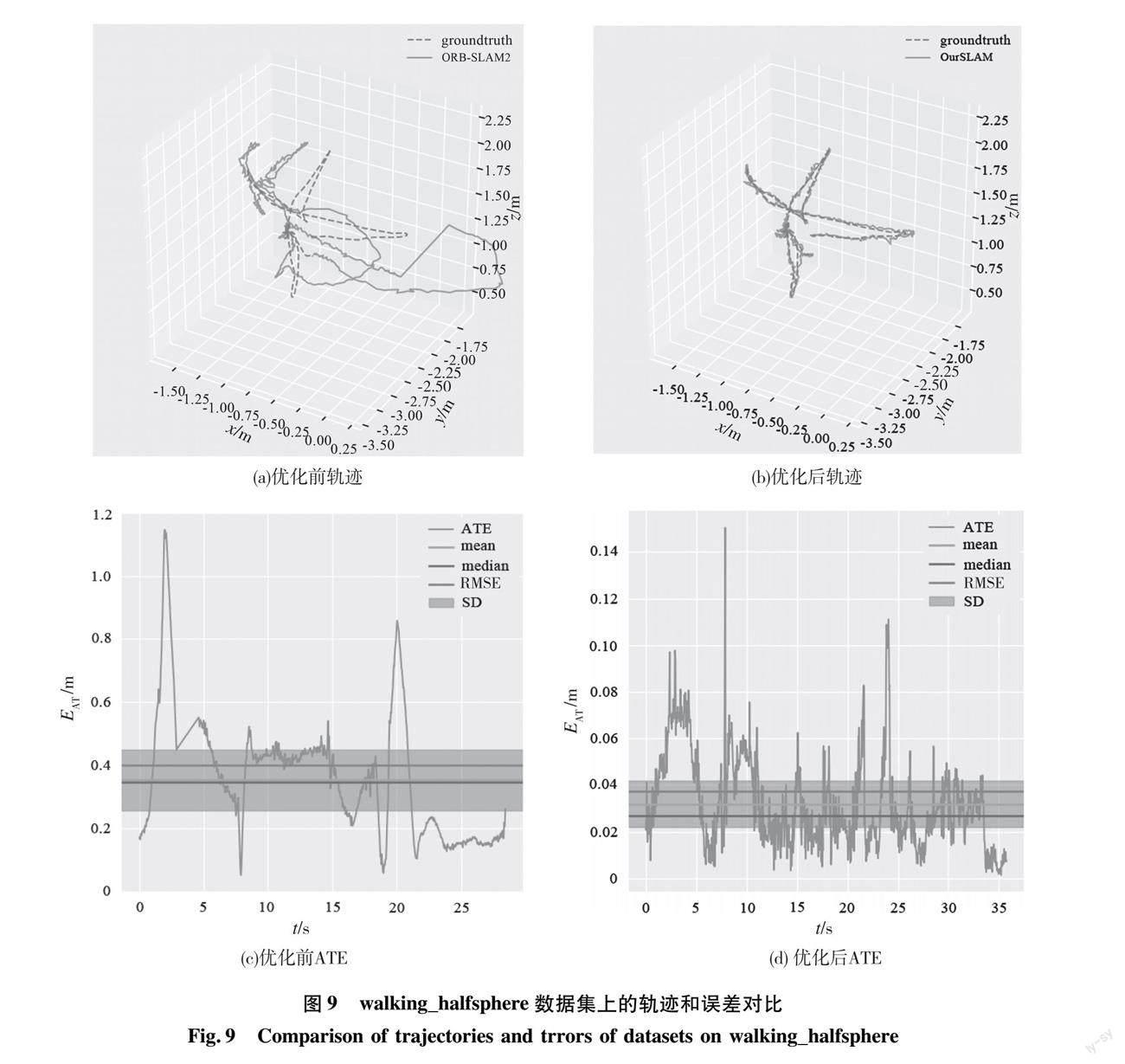
本文主要对TUM RGB-D公开数据集[19]中的3个高动态图像序列walking_xyz 、walking_halfsphere 和walking_static进行测试对比。高精度捕获系统和惯性测量系统实时获得的实际数据集中轨迹可以看作是相机实际位置的数据,因此研究视觉SLAM的研究人员大多将该数据集作为评价视觉SLAM算法的标准数据集。
一般评估SLAM算法会从时耗、复杂度、精度等多个方面进行评价,其中对精度的评估往往是最受关注的。绝对轨迹误差和相对轨迹误差是精度评价过程中使用的2个精度指标。本文使用均方根误差(root mean square error,RMSE) ERMS和 标准偏差(standard deviation,SD)DS作为评估这2个指标的参数。均方根误差是用来衡量观测值与真实值之间的偏差,由于容易受到较大或偶发错误的影响,所以能更好地反映系统的鲁棒性。标准差是用来衡量估计位姿相比于真实轨迹的离散程度,可以反映系统的稳定性[20]。
本文算法在高动态环境中的3个数据集上进行仿真实验,并使用evo工具将本文算法與ORB-SLAM2估计的位姿轨迹与数据集给出的真实轨迹图groundtruth.txt进行对比。对比时在平移、旋转、尺度缩放3个维度上对齐。本文算法相较于ORB-SLAM2的提升程度的计算如式(2)所示,以此直观地表达优化效果。
γ=α-βα×100%(2)
式中:γ為改进程度;α为ORB-SLAM2算法的结果数据;β为本文算法的结果数据。
2.1 实验
图8、图9分别是ORB-SLAM2与本文算法在walking_xyz、walking_halfsphere 数据集上评估的相机轨迹与真实轨迹的对比和误差分析。图中虚线代表真实轨迹,实线代表ORB-SLAM2、本文算法的相机评估轨迹。绝对轨迹误差(absolute trajectory error, ATE)记作EAT。从图8和图9的(a)、(b)图可以看出:本文算法的轨迹图与真实轨迹十分相近,直观地表现了本文算法的准确性。从图8和图9的(c)、(d)图可以看出:对比于未改进时的算法,本文算法的各类误差值有显著减小。
为验证实验设计的有效性,在TUM数据集上进行消融实验,以ORB-SLAM2为基础组,分别测试基础组+YOLOv5s(ORB+YOLO)和基础组+多视角几何(ORB+Multiview)以及本文算法,对比结果如表1所示。表1数据显示本文算法的效果更优秀。
2.2 稠密点云建图
相较于ORB-SLAM2的稀疏特征点地图,去除动态对象之后的稠密点云地图更能直观地表现原始的室内环境。本文剔除关键帧中的动态区域,包括动态检测框及覆盖的掩膜部分。根据剩下静态图像的颜色和深度信息可以方便计算RGB点云,利用精确的估计位姿可以更好地拼接点云,简单的点云相加即可获得精确的稠密全局点云地图。walking_static剔除动态对象前后的稠密点云地图展示了建图效果,如图10所示。
3 结果分析
ORB-SLAM2与本文算法的绝对轨迹误差对比见表2。由表2可以看出:在高动态环境下,对于3个walking类数据集,本文算法相较于ORB-SLAM2算法,RMSE平均提升率高达83.02%,SD平均提升率高达86.16%。在低动态环境下,对于2个sitting数据集,RMSE和SD的平均提升率在30%以内,改善效果不理想。此类数据集中动态对象移动较小,在低动态场景中大部分时候没有起到很好的掩膜作用,多视角几何的效果不突出,故单纯地去除人像的特征点效果并不明显。
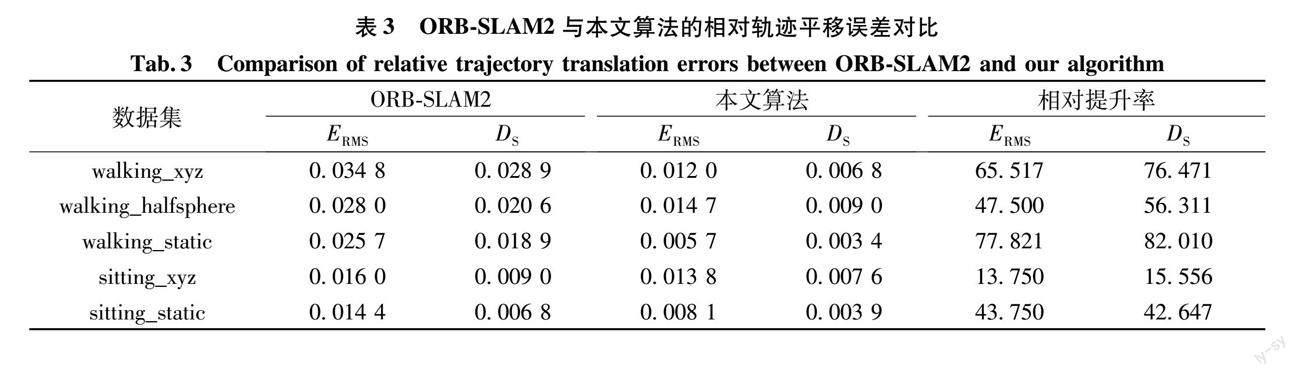
表3是ORB-SLAM2与本文算法在不同场景下相对位姿平移误差的对比。由表3可以看出:在高动态环境下,相较于ORB-SLAM2算法,本文算法的RMSE平均提升率为63.61%,SD平均提升率为71.60%。在低动态环境下,改善效果不理想。
表4是ORB-SLAM2与本文算法的相对轨迹旋转误差的对比。由表4可以看出:在高动态环境下,RMSE的平均提升率为57.81%,SD的平均提升率为63.54%。在低动态环境下,提升效果并不显著。由此可见,本文算法在高动态场景下有着较好的表现,但对于低动态环境下的改善不明显。
近年来国内学者提出了使用深度学习和纯几何方法融合的优秀案例[10,14],为了进一步验证算法的可靠性,将本文算法与近年国内外动态视觉SLAM算法进行对比,结果如表5所示。表5数据显示,本文算法在高动态场景下也具有较为可观的定位精度,证实了本文算法的可靠性。
4 结语
本文提出了一种基于深度学习的视觉SLAM,对于现有的视觉SLAM在高动态环境下易受动态物体干扰而影响定位精度的问题,在ORB-SLAM2的基础上加入多视角几何和YOLOv5s目标检测框架,通过两种算法的结合剔除动态特征点,从而实现对静态物体上的特征点进行帧间匹配和位姿估计。
实验数据表明:与ORB-SLAM2相比,高动态场景下本文算法的绝对轨迹误差平均提高了83.02%,与其他动态SLAM相比,也有较好的精度。但本文算法依然有局限性,例如不适用于室外复杂多变的场景,存在多视角几何速度运行较慢等问题。下一步工作将会考虑针对这些问题深入研究,选取速度更快、精度更好的动态检测算法,并对使用YOLOv5s目标检测模块的算法进行改进,使其可以适用于更复杂的环境。
参考文献:
张伟伟, 陈超, 徐军. 融合激光与视觉点云信息的定位与建图方法[J]. 计算机应用与软件, 2020, 37(7): 114-119.
[2] MUR-ARTAL R, TARDOS J D. ORB-SLAM2: an open-source slam system for monocular, stereo, and RGB-D cameras[J]. IEEE Transactions on Robotics, 2017, 33(5): 1255-1262.
[3] ENGEL J, SCHPS T, CREMERS D. LSD-SLAM: large-scale direct monocular SLAM[C]// Proc of European Conference on Computer Vision. Cham: Springer, 2014: 834-849.
[4] WANG R, SCHWRER M, CREMERS D. Stereo DSO: large-scale direct sparse visual odometry with stereo cameras[C]// 2017 IEEE International Conference on Computer Vision (ICCV). Venice: IEEE, 2017: 3903-3911.
[5] 刘瑞军, 王向上, 张晨, 等. 基于深度学习的视觉SLAM综述[J]. 系统仿真学报, 2020, 32(7): 1244-1256.
[6] YU C, LIU Z X, LIU X J, et al. DS-SLAM: a semantic visual SLAM towards dynamic environments[C]// 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). Queensland: IEEE, 2018: 1168-1174.
[7] BADRINARAYANAN V, KENDALL A, SEGNET R C. A deep convolutional encoder-decoder architecture for image segmentation[DB/OL]. (2015-12-08)[2022-09-06]. https://arxiv.org/abs/1511.00561.
[8] BESCOS B, FCIL J M, CIVERA J, et al. DynaSLAM: tracking, mapping, and inpainting in dynamic scenes[J]. IEEE Robotics and Automation Letters, 2018, 3(4): 4076-4083.
[9] WU W X, GUO L, GAO H L, et al. YOLO-SLAM: a semantic SLAM system towards dynamic environment with geometric constraint[J]. Neural Computing and Applications, 2022, 34(8): 6011-6026.
[10]高逸, 王庆, 杨高朝, 等. 基于几何约束和目标检测的室内动态SLAM[J]. 全球定位系统, 2022, 47(5): 51-56.
[11]CHEN W, FANG M, LIU Y H, et al. Monocular semantic SLAM in dynamic street scene based on multiple object tracking[C]// 2017 IEEE 8th International Conference on CIS & RA. Ningbo: IEEE, 2017: 599-604.
[12]WEN S H, LI P J, ZHAO Y J, et al. Semantic visual SLAM in dynamic environment[J]. Autonomous Robots, 2021, 45(4): 493-504.
[13]HE K M, GKIOXARI G, DOLLR P, et al. Mask R-CNN[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2020, 42: 386-397.
[14]肖田邹子, 周小博, 罗欣, 等. 动态环境下结合实例分割与聚类的鲁棒RGB-D SLAM系统[J/OL]. 计算机应用:1-8[2022-06-06]. http://kns.cnki.net/kcms/detail/51.1307.TP.20220602.1632.012.html.
[15]房立金, 刘博, 万应才. 基于深度学习的动态场景语义SLAM[J]. 华中科技大学学报(自然科学版), 2020, 48(1): 121-126.
[16]REDMON J, FARHADI A. Yolov3: an incre-mental improvement[DB/OL]. (2018-04-08)[2022-09-06]. https://arxiv.org/abs/1804.02767.
[17]严尚朋. 面向侵权监测的图像精确检索研究[D]. 上海: 上海交通大学, 2020.
[18]BOCHKOVSKIY A, WANG C Y, LIAO H Y M. Yolov4: optimal speed and accuracy of object detection[DB/OL]. (2020-04-23)[2022-09-06]. https://arxiv.org/abs/2004.10934.
[19]STURM J, ENGELHARD N, ENDRES F, et al. A benchmark for the evaluation of RGB-D SLAM systems[C]// 2012 IEEE/RSJ international conference on intelligent robots and systems. Vilamoura-Algarve: IEEE, 2012: 573-580.
[20]郑思诚, 孔令华, 游通飞, 等. 动态环境下基于深度学习的语义SLAM算法[J]. 计算机应用, 2021, 41(10): 2945-2951.
(责任编辑:周曉南)
Study on Visual SLAM Based on Deep Learning
in Dynamic Environment
ZHANG Qingyong*1,2, YANG Xudong1,2
(1.School of Mechanical and Automotive Engineering, Fujian University of Technology, Fuzhou 305118, China;
2.Fujian Automotive Electronics and Electric Drive Laboratory, Fuzhou 305118, China)
Abstract:
Due to the strong static rigid assumption in the traditional simultaneous localization and mapping (SLAM), the system positioning accuracy and robustness are easily disturbed by dynamic objects in the environment. In view of this phenomenon, a visual SLAM algorithm based on deep learning in an indoor environment is proposed. Improving ORB-SLAM2, this research adds multi-view geometry to the front end of SLAM, integrates it with the YOLOv5s target detection algorithm, and finally performs frame-to-frame matching on the processed static feature points. The experiment uses the TUM data set for testing, and it is found that after combining multi-view geometry, target detection and SLAM algorithm, the absolute pose estimation accuracy of the system is significantly improved compared with ORB-SLAM2 in a highly dynamic environment. Compared with the positioning accuracy of other SLAM algorithms, this method also has different degrees of improvement.
Key words:
multi-view geometry; object detection; SLAM; dynamic environment
猜你喜欢
科技创新与应用(2016年36期)2017-02-21 18:48:01
软件(2016年4期)2017-01-20 09:38:03
科教导刊·电子版(2016年28期)2017-01-10 22:25:23
科学与财富(2016年28期)2016-10-14 23:45:18
无线互联科技(2016年7期)2016-05-30 13:57:06
电脑知识与技术(2016年5期)2016-04-14 13:48:16
科技视界(2016年4期)2016-02-22 13:09:19
哈尔滨理工大学学报(2015年5期)2016-01-19 18:06:12
湖南大学学报·自然科学版(2015年10期)2015-11-30 18:52:07
现代电子技术(2015年20期)2015-10-26 22:48:16
贵州大学学报(自然科学版)2023年6期