
大数据视角下数字社区用户群体人格画像
2023-12-14 19:16:40符虔赵海腾赵小青帅懿芯
贵州大学学报(自然科学版) 2023年6期
符虔 赵海腾 赵小青 帅懿芯





摘 要:人格特征是人类行为的关键驱动因素,时刻影响人们的日常生活。尤其在突发公共事件情境下,这种影响机制可能更具有个体差异性。数字社区的出现使得基于用户信息行为大数据自动有效地进行用户群体人格画像成为可能,但相关研究还相对较少。以Twitter用户在COVID-19疫情期间发布的相关信息和其相关信息行为记录为样本,进行用户群体人格画像。首先,邀请专业心理咨询师基于自恋人格的定义和量表设定了数据标注规则并对数据集进行标注;其次,设计了13个潜在的用户行为指标,构建了Logit回归模型,并评估了模型的分类性能(分类准确率达到70.34%);再次,确定了一组与用户群体自恋人格特征密切相关的信息行为指标。这组指标共有5项,具体包括:用户近三年发表的推文总数、负面情感倾向推文所占比例、推文中动词平均数、推文中话题标签平均数、推文中感叹号平均数。从而,提出了一种针对特定情境(突发公共事件)基于用户信息行为大数据分析的群体人格画像的方法,为维护民众心理健康和数字社区清朗空间提供了新的思路。
关键词:数字社区;群体人格;自恋人格;人格画像;Logit回归
中图分类号:TP18;B848
文献标志码:A
人格是认知、情感和行为的复杂组织,决定了人的行为模式[1]。自恋(narcissism)被认为是元心理(metapsychology)结构[2]和“黑暗人格三联征”的主要特质之一[3]。已有的研究主要關注用户的自恋人格特征(personality profiles)[4]对其在数字社区中自我表露[5]、自我展示[6]和发布自拍贴[7]的影响。然而,关于在一些特定情境下,例如突发公共事件,用户的自恋特征对其在数字社区中的信息行为的影响,以及如何根据用户的信息行为对用户群体人格(group personality)[8]特征进行画像(profiling)[9],还有待进一步探索。
对于自恋人格特征相对明显的用户来说,数字社区为他们提供了一个展现自我、赢得关注和赞赏的理想“舞台”,他们借助各种数字技术来打造个人网络形象并构建其虚拟社交网络[10]。Twitter作为全球最大的数字社区之一,其日均活跃用户人数在2022年已经突破2.5亿。在COVID-19疫情期间,大量的Twitter用户发表相关推文并对他人发布的相关推文进行评论,从而提供了大量真实的数据。本文基于这些数据资源,探索在突发公共事件情境下影响用户信息行为的主要自恋人格特征以及如何借助大数据技术为用户群体人格画像。
1 数据收集与标注
如图1所示,本文使用网络爬虫技术获取了COVID-19疫情期间用户在Twitter数字社区中发布的相关信息和其信息行为记录,构建了数据集;邀请富有经验的专业咨询师设计了自恋人格特征标注规则并对数据集进行标注,然后采用Logit回归对数据集进行分析。
1.1 Twitter数据爬取
Selenium是一个自动化测试工具,可以用来模拟用户在网站上的行为。本文利用Chrome driver和Selenium模拟Twitter用户登录、浏览和搜索等行为,针对关键词、评论和用户这3个条目收集数据。
1)爬取推文
设置关键词为“COVID-19”,从Twitter搜索爬取了10 231条推文。
2)爬取评论
针对关键词爬取的10 231条推文,进一步爬取了每条推文对应的评论,共爬取到58 051条评论及对应的评论者。
3)爬取用户历史推文
对评论者去重后共得到46 075位不重复的评论者。因为发文量较少的用户所提供的信息过少以至于难以进行相关分析,所以本文从46 075人中选择发文量大于或等于5条的1 008名用户,爬取到他们的历史推文共10 373条。
1.2 数据清洗与整理
首先,清除商业营销账号。由于从Twitter获得的数据中,不可避免地会掺杂大量的商业营销账号,而商业营销账号不具备人格特征,因此本文根据Twitter商业营销的特点(比如营销账号内容包含广告、促销信息等,其链接会指向某个产品,或其语言风格会使用与品牌相关的风格来增加辨识度)对上述爬取的3组数据都进行了人工清理。其次,以评论者为“连接点”,将3个数据集整合为1个数据集。这个数据集包含推文,推文对应的评论者,以及评论者的历史推文。
1.3 数据标注
邀请3位专业心理咨询师(他们的从业时间均超过15年)浏览上述1 008名Twitter用户的历史推文后判断其人格特征,即自恋人格特征相对明显或自恋人格特征相对不明显。对于标注结果不一致的情况,3位标注者进行讨论,通过多数表决的方式来确定最终的标注结果。具体标注流程如下:
1)设定标注规则
根据Emmons[11]的定义,将自恋视为包括4个方面特征的一维结构,并基于Ames 的自恋量表[12]制定了以下标注规则:
(1)用户觉得所有人都喜欢听他/她的故事(优越/傲慢);
(2)用户觉得人们似乎总能意识到他/她的权威地位(领导/权威);
(3)用户觉得他/她比他人更能干(强势/权力);
(4)用户觉得他/她是杰出的人(自我陶醉/自我欣赏)。
当用户满足上述一个或多个条件时均被判定为自恋人格特征相对明显,并被标注为1;反之,则被视为自恋人格特征相对不明显,被标注为0。最终得到了1 008名的Twitter用户的人格标注结果,其中自恋人格特征相对明显的用户为466名,自恋人格特征相对不明显的用户为542名。
2)检测标注结果
本文使用Fleiss’ kappa系数来分析不同标注人员标注结果的一致性。Fleiss’ kappa系数分布在-1到1之间。如果Fleiss’ kappa系数<0,则说明观察一致率小于机遇一致率;如果Fleiss’ kappa系数=0,则说明结果完全由随机因素导致;如果Fleiss’ kappa系数>0,则说明研究对象之间存在一定的一致性。Fleiss’ kappa系数越接近1,一致性越大。经过计算,Fleiss’ kappa系数为0.637,表明本研究的标注结果具有较好的一致性。
2 用户自恋人格特征分析
2.1 指标设计
本文根据Twitter的功能和用户在Twitter社区中的信息行为特点,设计了13个指标,涉及的符号说明见表1。
1)用户近三年发表的推文总数
一个自恋人格特征相对明显的用户可能会经常发布推文来展示自己的想法和行动。
x1=count(tweets)
2)正面情感倾向推文所占比例
一个自恋人格特征相对明显的用户可能会更倾向于发布积极情感倾向的信息(例如与自己成功、幸福感有关的事情)。
x2=count(positive_tweets)x1
3)负面情感倾向推文所占比例
在突发公共事件情境下,一个自恋人格特征相对明显的用户可能会更倾向于发布与突发公共事件相关的负面情感信息以吸引更多人的注意并引起共鸣,从而提升自己的影响力;而且,可能会表达对政府机构的不满或对行为主体的不认可。
x3=count(negative_tweets)x1
4)推文中形容词平均数
自恋人格特征相对明显的用户可能会用大量的形容词来描述自己的外貌、成就和性格。
x4=count(adjectives)x1
5)推文中动词平均数
自戀人格特征相对明显的用户可能会强调自己的行动和成就,以增强对他人的影响。
x5=count(verbs)x1
6)推文中名词平均数
自恋人格特征相对明显的用户可能会经常提到自己的名字、外貌、成就等等,以体现个人的重要性。
x6=count(nouns)x1
7)推文中副词平均数
自恋人格特征相对明显的用户可能会使用副词来描述自己的行动和情感状态,以体现其影响力更大。
x7=count(adverbs)x1
8)推文中话题标签平均数
自恋人格特征相对明显的用户可能会使用话题标签来使自己的推文更加易于被发现和关注。
x8=count(hashtags)x1
9)推文中@他人平均数
自恋人格特征相对明显的用户可能会在推文中@自己的粉丝或其他关注者,以获得更多的关注和回应。
x9=count(mentions)x1
10)推文中插入图片平均数
自恋人格特征相对明显的用户可能会发布大量的照片和自拍照,以展示自己的外貌和生活。
x10=count(pictures)x1
11)推文中问号平均数
自恋人格特征相对明显的用户可能会在推文中使用问号来引起关注和好奇心,以吸引更多的关注和回应。
x11=count(question_marks)x1
12)推文中感叹号平均数
自恋人格特征相对明显的用户可能会使用一个或多个感叹号来强调自己的情感强烈程度和推文的重要性。
x12=count(exclaimation_marks)x1
13)推文中单词平均数
自恋人格特征相对明显的用户可能会发布大篇幅(单词数量较多)的推文来描述自己的行动、成就、想法和情感状态。
x13=count(words)x1
随后,本文利用Python的vader sentiment模块获得用户推文的情感极性。其他指标均使用Python的正则匹配方法计算。
2.2 描述性统计及相关性分析
为了量化样本在各个指标上的结构特点,本文计算了每个指标的均值、标准差、最小值、25%分位数、50%分位数(中位数)、75%分位数和最大值,对13个指标进行描述性统计,见表2。
从表2可以看出:用户的最大推文数为50条,平均每个用户发推文10条。从推文的正面(x2)、负面(x3)情感占比来看,两种情感占比相近。此外,对vader sentiment模块生成的正、负情感效价进行从小到大排序后,25%至75%分位差的数值表明,推文正面情感在0.45范围内波动,而负面情感在0.60范围内波动,说明负面情感的占比更离散。从每条推文的形容词(x4)、动词(x5)、名词(x6)、副词(x7)使用量均值来看,平均每条推文中的名词数量最高,为9.91;副词数量最低,为1.59。话题标签(x8)、@他人(x9)的均值超过了1,说明用户习惯于在推文中加入话题以及和别人互动。但是推文插入图片的均值为0.28(x10),表明大多数用户不习惯在推文中加入图片。从推文标点的使用情况来看,问号(x11)和感叹号(x12)的均值相近,但是感叹号的最大值为10.33,远高于问号的最大值2.67,说明在表达强烈的情感时,用户更习惯使用感叹号。从每条推文单词的平均数(x13)来看,用户平均每条推文的单词数为31.59。标准差反映了用户间的差异性。用户每条推文的平均单词数的差异性最大,用户近三年发表的推文总数的差异性次之,负面情感倾向推文的占比差异最小。
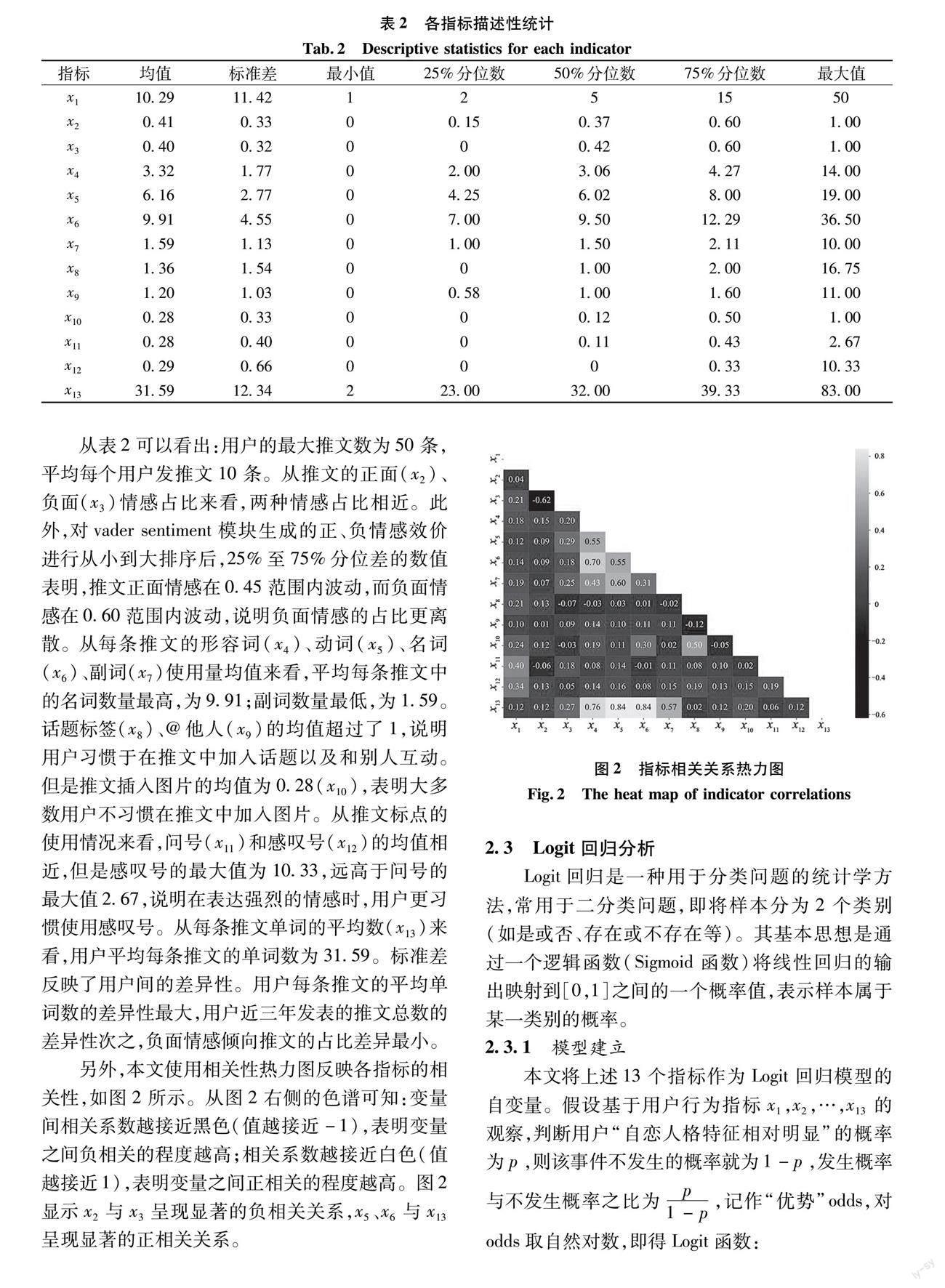
另外,本文使用相关性热力图反映各指标的相关性,如图2所示。从图2右侧的色谱可知:变量间相关系数越接近黑色(值越接近-1),表明变量之间负相关的程度越高;相关系数越接近白色(值越接近1),表明变量之间正相关的程度越高。图2显示x2与x3呈现显著的负相关关系,x5、x6与x13呈现显著的正相关关系。
2.3 Logit回归分析
Logit回归是一种用于分类问题的统计学方法,常用于二分类问题,即将样本分为2个类别(如是或否、存在或不存在等)。其基本思想是通过一个逻辑函数(Sigmoid函数)将线性回归的输出映射到[0,1]之间的一个概率值,表示样本属于某一类别的概率。
2.3.1 模型建立
本文将上述13个指标作为Logit回归模型的自变量。假设基于用户行为指标x1,x2,…,x13的观察,判断用户“自恋人格特征相对明显”的概率为p,则该事件不发生的概率就为1-p,发生概率与不发生概率之比为p1-p,记作“优势”odds,对odds取自然对数,即得Logit函数:
Logit(p)=ln(odds)=ln(p1-p)
称为p的Logit 变换,则Logit回归模型为
Logit(p)=ln(p1-p)
=β0+β1x1+β2x2+…+β13x13 (1)
式中:β0为常数项;β1,β2,…,β13为回归系数,反映了自变量每变化一个单位,几率(odds)的对数的变化情况。
从式(1)可以看出:当p在(0,1)之间变化时,对应的Logit(p)在(-∞,+∞)之间变化,自变量x1,x2,…,x13则可在任何范围内取值。
2.3.2 模型求解
当自变量很多时,自变量之间可能会存在多重共线性,这会造成模型与实际不符,因此本文首先对数据进行多重共线性诊断。而度量多重共线性严重程度的一个重要指标是指标矩阵条件数κ,其计算公式如下:
κ(X)=‖X‖‖X-1‖
其中:‖X‖=max1≤j≤n{∑mi=1xij},xij为指标矩阵X的元素。
从实际应用的经验角度来看:κ<100,被认为多重共线性的程度很小;100≤κ≤1 000,被认为存在中等程度或较强的多重共线性;若κ>1 000,则认为存在严重的多重共线性[11]。经过计算,研究的13个用户行为指标的矩阵条件数为108.92,说明各指标间存在中等程度的多重共线性。
指标间存在多重共线性会导致建模结果变差。因此,本研究利用逐步回归的方法进行指标筛选,以保证在不损失重要指标的前提下消除多重共线性问题。首先用13个指标作为自变量建立一个回归模型,然后计算在剔除任意一个自变量后回归模型的拟合度,模型的拟合度最优时对应的变量即要剔除的变量。依此类推,直至回归模型剩余的p个变量中再任意剔除一个变量,模型的拟合度都会变差,此时已经没有可以继续剔除的自变量,因此包含这p个变量的回归模型就是最終确定的模型。
本文使用AIC准则(Akaike information criterion)来衡量模型拟合的优劣,其计算公式如下:
CAI=2k-ln(L^)
式中:CAI为AIC值;k为模型中待估参数的数量;L^是该模型极大似然估计的最大值。
AIC值越小,说明该统计模型损失的信息越少,统计模型的建模效果越好。因此,在进行逐步回归求解时,模型筛选变量的目标是:第一,模型中的变量均为显著;第二,模型整体显著且AIC值最低。
本文使用Python工具包statsmodels进行模型求解,得到系数的显著性,见表3。
模型的p值反映了模型的显著水平,其值为5.144 1e-43 (<0.05),表明模型显著。从模型的回归系数来看,用户近三年发表的推文总数(x1)、负面情感倾向推文所占比例(x3)、推文中动词平均数(x5)、推文中话题标签平均数(x8)和推文中感叹号平均数(x12)的p值小于0.05,说明这5个行为指标构成的信息行为特征组与用户群体自恋人格特征显著相关。本文对逐步回归分析后得到的变量进行多重共线性检验,以上5个指标的矩阵条件数为1.89,远小于100,说明指标间多重共线性问题已经得到很大程度改善。因此,本文得到的Logit回归模型为
Logit(p)
=ln(p1-p)
=1.847 5+0.073 9x1+0.736 8x3+
0.089 9x5+0.116 4x8+0.791 3x12(2)
2.3.3 结果分析
从式(2)可以得出:在突发公共事件情境下的Twitter社区中,最能反映用户自恋人格特征的信息行为指标组合为:用户近三年发表的推文总数、负面情感倾向推文所占比例、推文中动词平均数、推文中话题标签平均数和推文中感叹号平均数。其中用户近三年发表的推文总数的系数为0.073 9,这表明当其他变量保持不变时,用户推文量每增加一个单位,用户自恋人格特征相对明显的概率将提升0.073 9。类似地,当固定其他信息行为指标不变时,其余4个影响因素每增加一个单位,用户自恋的概率分别增加0.736 8、0.089 9、0.116 4、0.791 3。
2.3.4 模型评估
针对二分类任务结果可以得到4个值:真阳性(true positive,TP)、假阳性(false positive,FP)、真阴性(true negative,TN)和假阴性(false negative,FN),这4个值构成了图3所示的混淆矩阵。
在本文中,TP =431,表示自恋人格特征相对明显用户被正确分类的数量;FP =188,表示自恋人格特征相对不明显用户被错误分类的数量;TN =278,表示自恋人格特征相对不明显用户被正确分类的数量;FN =111,表示自恋人格特征相对明显用户被错误分类的数量。
由上述4个值,本文得出准确度A、精确度P、召回率R和F1-score值F1用以评估模型的分类效果。
准确度表示总体数据中,有多少数据被分类正确了。其计算结果为
A=TP+TNTP+TN+FP+FN=0.703 4
精确度表示分类为自恋人格特征相对明显且分类正确的数量占实际为自恋人格特征相对明显样本数量的比例。其计算结果为
P=TPTP+FP=0.696 3
召回率表示分类为自恋人格特征相对明显且分类正确的数量占全部分类为自恋人格特征相对明显数量的比例。其计算结果为
R=TPTP+FN=0.795 2
F1值是精确度和召回率的調和均值。其计算结果为
F1=2×P×RP+R=0.742 5
准确度值为0.703 4表明该模型的分类准确性较好的。而且,精确度、召回率和F1值接近,表明模型的分类结果中正例和负例的比例是相近的,且分类结果与实际结果相符合的样本数量和误判样本数量相近,说明本文中自恋人格特征分类模型的性能较好。
3 总结与展望
本文通过对网络爬虫获取的大样本数据构建Logit回归模型,证明了在突发公共事件情境下,用户的4种群体自恋人格特征(优越/傲慢、领导/权威、强势/权力、自我陶醉/自我欣赏)中的一种或多种组合都与他们在数字社区中的信息行为特征(用户近三年发表的推文总数、负面情感倾向推文所占比例、推文中动词平均数、推文中话题标签平均数和推文中感叹号平均数)相关组合。这表明针对突发公共事件,自恋人格特征相对明显的用户群体更倾向于在数字社区中发布更多的、负面情感倾向、有一定煽动性、级联性、情感效价较高的相关信息。同时也说明,自恋人格特征相对明显的用户群体更渴望在数字社区中得到关注、认可、赞赏、积极回应以满足其人格正常和谐发展的需要。
上述研究结果为如何实现大数据赋能突发公共事件应急响应和维护民众心理健康提供了2条思路:第一,通过大数据建模实现自恋人格画像,更精准地关注可能需要干预的用户群体,预防网络暴力、负面数字情绪感染、负面情感信息级联的发生;第二,更为精准地判断不同用户的自恋人格特征及其心理需求,从而更有针对性地为他们提供个性化的数字服务以促进他们的心理健康。总之,进行用户群体人格画像研究对促进数字社区健康发展,拓展大数据技术、人工智能技术应用场景都具有重要意义。
参考文献:
PERVIN L A. 人格科学[M]. 上海: 华东师范大学出版社, 2001: 467.
[2] RASKIN R, HOWARD T. A principal-components analysis of the narcissistic personality inventory and further evidence of its construct validity[J]. Journal of Personality and Social Psychology, 1988, 54(5): 890-902.
[3] GEEL M V, ANOUK G, FATIH T, et al. Which personality traits are related to traditional bullying and cyberbullying? A study with the Big Five, Dark Triad and sadism[J]. Personality and Individual Differences, 2017, 106: 231-235.
[4] MCCRAE R, ANTONIO T. Personality profiles of cultures: aggregate personality traits[J]. Journal of Personality and Social Psychology, 2005, 89(3): 407-425.
[5] LEE J, JIHYE L, YOUNG S, et al. Self-disclosures on Facebook: the two faces of narcissism[J]. International Journal of Advanced Culture Technology, 2020, 8(2): 139-145.
[6] HUANG L V, LIU S S. Presenting an ideal self on Weibo: the effects of narcissism and self-presentation valence on uses and gratification[J]. Frontiers in Psychology, 2020, 11:1310.1-1310.6.
[7] CHRISTINA S, SCHWARTZ A M, RUDY A H, et al. I love my selfie! An investigation of overt and covert narcissism to understand selfie-posting behaviors within three geographic communities[J]. Computers in Human Behavior, 2020, 104(10): 106158.1-106158.11.
[8] WILLCOX G, DAVID A, LOUIS R, et al. Measuring group personality with swarm AI[C]// 2019 First International Conference on Transdisciplinary AI (TRANSAI 2019), Laguna Hills, CA: IEEE, 2019: 10-17.
[9] YANG Q, ALEKSANDR F, SERGEY N, et al. Do we behave differently on Twitter and Facebook: multi-view social network user personality profiling for content recommendation?[J]. Frontiers in Big Data, 2022, 5: 931206.1-931206.16.
[10]LIU D, BAUMEISTER R F. Social networking online and personality of self-worth: a meta-analysis[J]. Journal of Research in Personality, 2016, 64: 79-89.
[11]EMMONS R A. Factor analysis and construct validity of the narcissistic personality inventory[J]. Journal of Personality Assessment, 1984, 48(3): 291-300.
[12]AMES D R, ROSE P, ANDERSON C P. The NPI-16 as a short measure of narcissism[J]. Journal of Research in Personality, 2006, 40(4): 440-450.
(責任编辑:周晓南)
Digital Community User Group Personality Profiling
Through the Lens of Big Data
FU Qian1, ZHAO Haiteng2, ZHAO Xiaoqing*1, SHUAI Yixin1
(1.Mental Health Education & Consulting Center, Guizhou University, Guiyang 550025, China;2.Computer Science and Technology, Guizhou University, Guiyang 550025, China)
Abstract:
Personality profiles are key drivers behind human behaviors, and they influence people’s daily life all the time. In the context of public emergencies, there may be more individual differences in this influence mechanism. The emergence of digital communities makes it possible to automatically and effectively capture user group personality profiles by analyzing big data of user information behaviors. However, research efforts on this issue are relatively sparse. This study takes the relevant information released by Twitter users during the COVID-19 epidemic and their related information behavior records as samples to conduct user group personality profiling. First, professional counselors were invited to set labelling rules and label the data based on the definition and scale of narcissism personality. Then, this study designs 13 potential user behavior indicators, builds a logit regression model, and evaluates the classification performance of this model (the accuracy reaching 70.34%). Finally, this study identifies a set of information behavior indicators closely related to the narcissism personality profiles of user groups. There are five indicators in this constellation, including the total number of tweets published by users in the past three years, the proportion of negative sentiment tweets, the average number of verbs in tweets, the average number of hashtags in tweets, and the average number of exclamation marks in tweets. Thus, we propose a group personality profiling method based on big data analysis of user information behaviors for specific situations (e.g. public emergencies, etc.), which provides a new idea for maintaining users’ mental health and clear space for digital community.
Key words:
digital community; group personality; narcissism personality; personality profiling; Logit regression
贵州大学学报(自然科学版)2023年6期