
基于边缘计算的实时目标检测算法*
2023-12-13 12:12刘立昂葛海波魏秋月李文浩
传感器与微系统 2023年12期
刘立昂,葛海波,魏秋月,李文浩
(1.西安邮电大学自动化学院,陕西 西安 710121;2.西安邮电大学电子工程学院,陕西 西安 710121)
0 引 言
自动驾驶、无人机配送、智能家居、安防系统等领域对于目标检测的精度和速度要求越来越高,但现有的目标检测网络在实际应用中存在很大的挑战,比如模型权重参数过多,存储需求大,难以应用于边缘计算设备。
Liu W等人[1]将YOLO[2]和Faster R-CNN[3]2 个算法思想相结合,提出SSD(single shot multibox detector)算法[4],在保证检测速度的同时,保证目标的定位效果。文献[5]将SSD算法的骨干网络换成DenseNet,但适用领域存在局限性,仅适用于与传统图像相差较大的领域,例如医疗影像;文献[6,7]使用MobileNet 作为SSD 的骨干网络,但MobileNet 存在1 ×1 卷积计算参数量大的问题;文献[8~10]将SSD算法的骨干网络改为ResNet,虽然检测精度有所增加,但增加了模型参数量导致实时性较差;文献[11]保留ResNet结构的同时引入ShuffleNet和特征金字塔网络(feature pyramid network,FPN),因为引入较多的卷积层,导致参数量增加;文献[12]采用ShuffleNet 克服了通道信息融合带来的参数压力,参数量显著降低,但特别依赖实现细节,导致实时性较差。为了解决文献[12]中的实时性问题,文献[13]提出ShuffleNet V2,该模型减少了网络分支数量,缩小特征图尺寸,更符合轻量化模型的设计原则。
本文根据“终端网络层-边缘服务层-云层”边缘网络体系架构[14]开展目标检测研究。
1 边缘计算中的目标检测算法
1.1 边缘计算中目标检测体系架构
在终端网络层,物联网通过广泛部署的摄像机设备,不间断地收集各类图像信息,这些信息在终端设备中经过初步处理,将其中的有效图像数据传输,并存储在就近的边缘服务器中。通过边缘服务器收集服务范围内的图像数据,并且能够实现对终端设备的有效管理。终端设备网络和边缘网络之间的连接具有低延迟,高时效性等特点。而在云端,云服务器主要用来处理更加复杂而庞大的计算密集型数据和任务,如深度学习的模型训练。
1.2 边缘服务层算法
1.2.1 设计思路
本文提出了一种基于SSD 算法改进的SFF(shuffle fusion focal)-SSD 算法。选取ShuffleNet V2 作为SSD 算法的主干网络。
SFF-SSD算法采用ShuffleNet V2网络作为SSD网络的主干网络,并将ShuffleNet V2 中的Stage2_3 和Stage3_7 融合产生新的特征图N_Stage3_7作为SSD网络的第1层输出特征图,卷积(Conv)5 的结果作为SSD 网络的第2 层输出特征图,之后的4层Conv6_2、Conv7_2、Conv8_2、Conv9_2 都是由Conv5特征图经过3 ×3 和1 ×1 等卷积操作得到的,保持与经典SSD网络特征图的大小与数量一致,经典SSD网络结构如图1(a)所示,SFF-SSD网络结构模型如图1(b)所示。

图1 经典SSD和SFF-SSD网络结构
1.2.2 改进策略
1)特征融合
ShuffleNet V2网络结构如图2 所示。待检测目标经过全局池化操作后会丢失一些细节信息,同时为了避免引入全连接(fully connected,FC)层增加模型的参数量,因此本文将删除图2 中虚线框部分。对于每个阶段(stage),第一个基本单元采用步长(stride)为2,使特征图宽和高各降低50%,而通道数增加1倍。后面的基本单元均是步长为1,特征图和通道数保持不变。对于基本单元来说,其中3 ×3卷积层的通道数为输出通道数的1/4,这与残差单元的设计理念相似[15]。
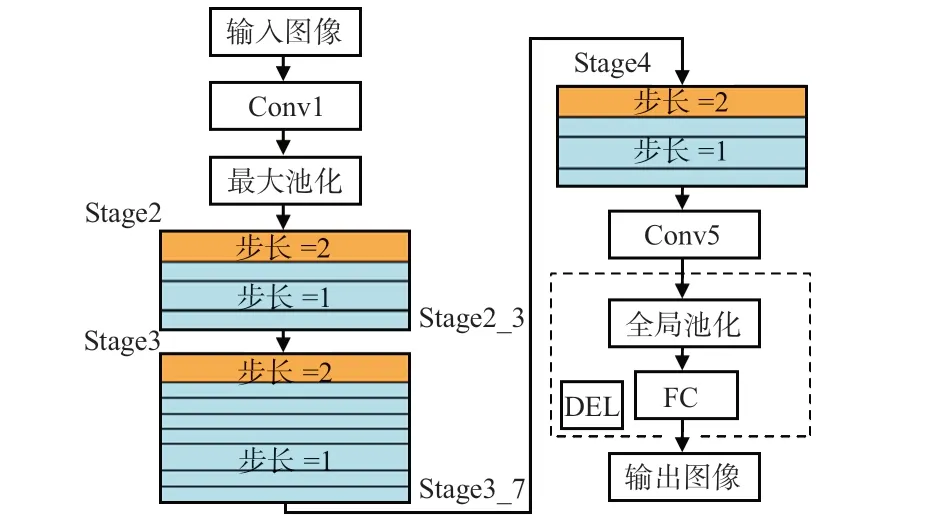
图2 ShuffleNet V2 网络结构
如图3 所示,本文将ShuffleNet V2 网络的Stage2_3 和Stage3_7特征图进行融合,使其对小目标的检测效果更好。
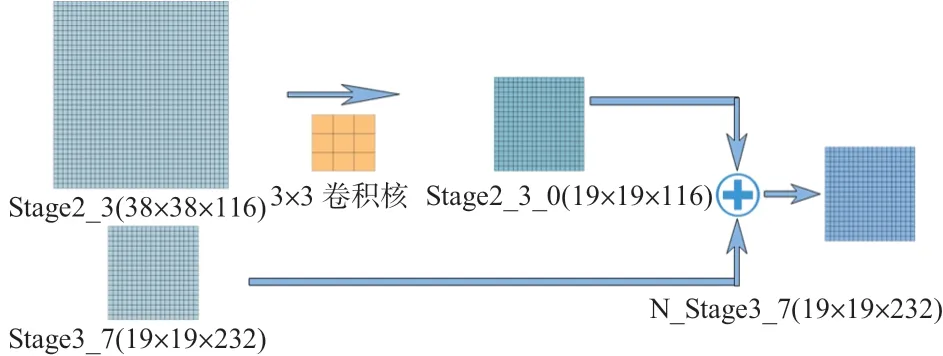
图3 特征融合示意
2)SENet模块
SENet模块是一种通道注意力模块,使模型可以自动学习到不同通道特征的重要程度,并对其重要程度进行标定,让模型更加关注信息量大的通道特征,而抑制那些不重要的通道特征[16]。SENet可以分为3个阶段:挤压(squeeze)、激励(excitation)和加权[17],其具体实现方式如图4所示。
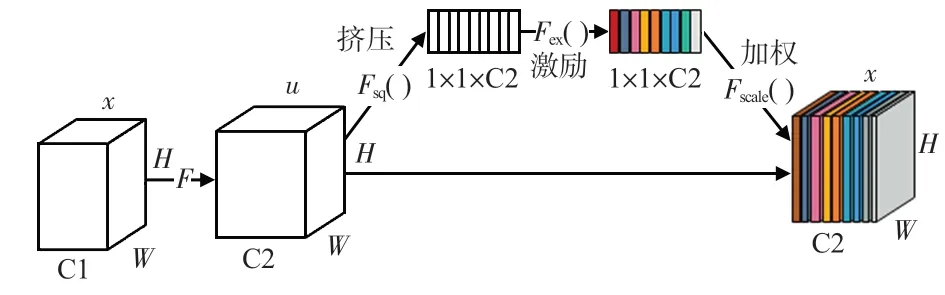
图4 SENet模块结构
运算公式如式(1)所示
式中H,W为特征图的高和宽,uc为特征图的第c个通道,uc(i,j)为第c个通道中的第i行、第j列的像素,zc为挤压操作的输出。然后将挤压操作得到的全局特征先经过一个全连接层将维度从C2降为1/C2,用ReLU6函数进行激活,再经过一个全连接层将维度升维到原始维度C2,使用Sigmoid激活函数得到各个通道的权重系数,即“激励”操作。其运算公式如式(2)所示
式中W1和W2为全连接操作,z为挤压操作的输出,δ 为ReLU6激活函数,σ 为Sigmoid 激活函数,sc为激励操作的输出。最后,将激励操作得到的权重系数与特征图u相乘,实现对特征重要性的重新校准,以此更新特征图,即“加权”操作。其运算公式如式(3)所示
式中sc为特征图第c个通道的权重,加权操作的输出。
由于SENet 本身增加的参数主要来自于2 个全连接层,对算法的实时性和参数量影响较小,本文经过试凑法实验测试后,在卷积层Conv1 之后加入SENet。SFF-SSD网络层加入SENet情况如表1所示。
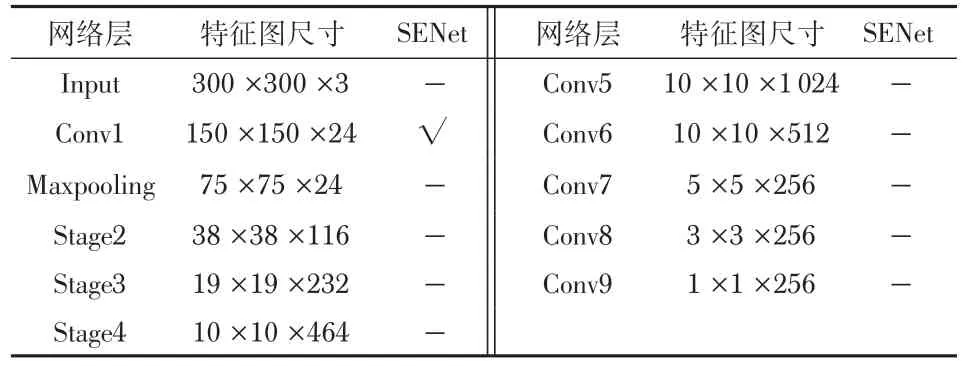
表1 SFF-SSD网络层加入SENet情况
3)焦点损失
焦点损失(focal loss,FL)是在交叉熵里面用一个调整项,将学习专注于难分的负样本上面,并且降低易分负样本的权值[18]。首先,从对于二分类的交叉熵(cross entropy,CE)损失来介绍FL
式中p∈[0,1]为模型对于标签y=1的估计概率。
当大量的简单样本叠加,小的损失值可以主导稀少的类。针对样本不平衡问题的常用方法是用一个权重参数α∈[0,1]对应类1,1 -α对应类-1。实际应用上,α(定义为αt)一般被设定为类频率的逆或者作为超参数,通过交叉验证设定。训练时遇到很大的类别不平衡会主导交叉熵损失。易分负样本在梯度和损失中占据主导地位。而αt平衡了正负样本的重要性,但它不会区别易分样本和难分样本。而将(1 -Pt)γ加到交叉熵损失函数上降低易分样本的权重,专注于训练难分负样本。Α-balanced的FL如式(6)
式中 γ为可以调节的焦点参数,γ >0。
2 分析与讨论
本文实验的数据集PASCAL(pattern analysis,statical modeling and computational learning)VOC2007是公开的目标检测数据集[2]。PASCAL VOC2007数据集包含20 类,总共9 963张图片。
实验采用消融实验的方法,确保训练和测试的设备统一,TensorFlow框架一致,图像输入尺寸保持一致(300 ×300 ×3),分别使用 VGG16-SSD 和 SFF-SSD 网络在VOC2007数据集上进行训练和验证测试,得出参数量、均值平均精度(mAP)、帧率(FPS)等评价指标。
2.1 训练与推理
与需要目标建议的方法相比,SSD 完全消除了建议生成和随后的像素或特征重采样阶段,并将所有计算封装在单个网络中,这使得它易于训练,并且可以直接集成到需要检测组件的系统中[19];同时,SSD 网络为训练和推理提供了一个统一的框架,模型训练所占用的显存小。使用PASCAL VOC2007数据集作为本文实验的训练数据集和测试数据集。分别使用VGG16-SSD 和SFF-SSD 网络在VOC2007数据集上进行多组实验,训练集、验证集和测试集的比例为81∶9∶10,训练结合了迁移学习[20]的思想,加入预训练权重作为初始权重加快了训练速度,同时使用GPU的cuDNN工具包进行进一步加速,训练初始设置为100 代,batchsize 设置为16,学习率设置为1 ×10-4。得到权重文件(. h5 文件),并将其加载入测试程序进行预测。
在预测时,网络为每个默认框中存在的每个对象类别生成分数,并对默认框进行调整以更好地匹配目标形状。此外,网络结合具有不同分辨率的多个特征图的预测结果,使得处理不同大小的目标更方便。加载训练得到的权重文件,选取部分测试集中的图片进行预测,结果如图5所示。

图5 不同网络模型生成的预测图对比
2.2 结果与分析
本文使用38 ×38,19 ×19,10 ×10,5 ×5,3 ×3,1 ×1特征图(表3中的大特征图)尺寸与19 ×19,10 ×10,5 ×5,3 ×3,2 ×2,1 ×1 特征图(表3 中的小特征图)尺寸进行对比,同时,加入通道注意力模块SENet,采用更好的损失函数-FL函数,对SFF-SSD在VOC2007 数据集上进行消融实验,得到mAP、FPS、参数量等结果,如表2所示。
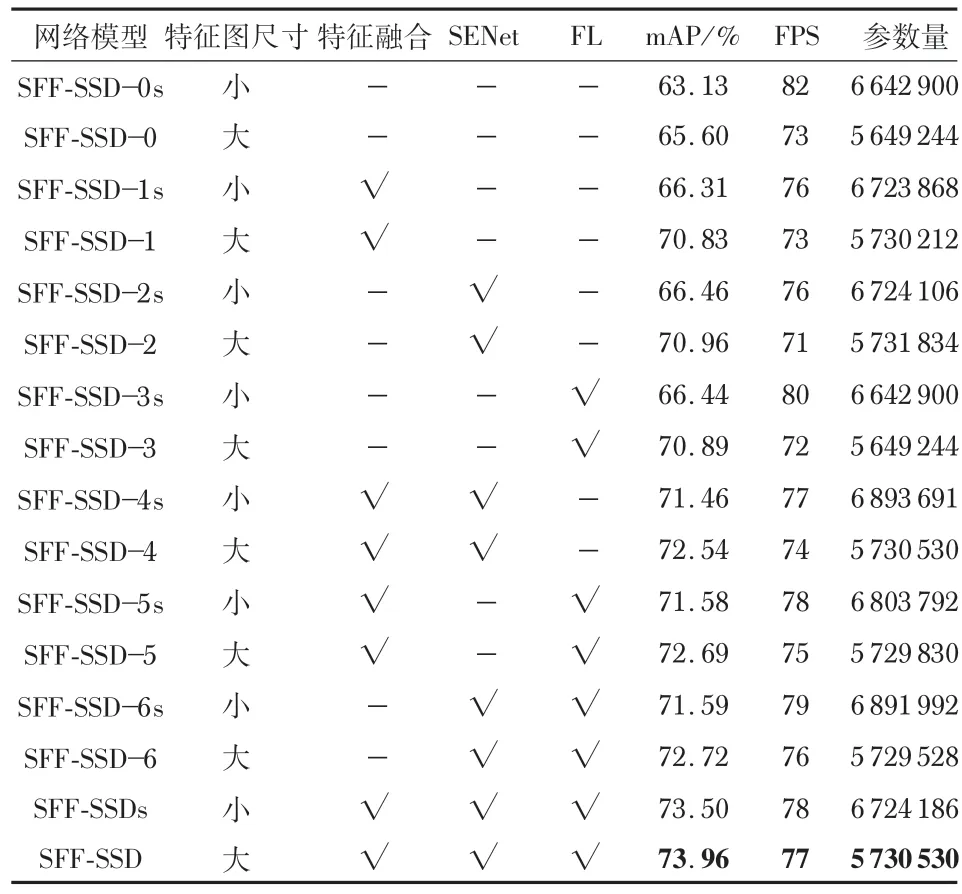
表2 SFF-SSD算法的改进优化结果对比

表3 SFF-SSD算法与SSD算法结果对比
由表2 分析可知,SFF-SSD 网络使用较大的特征图尺寸后,检测精度和检测速率均有所提升,证明使用大的特征图尺寸进行改进是可行的。其次,为了更好地利用大特征图的信息,本文对SFF-SSD 网络中的Stage2_3 和Stage3_7进行特征融合,结果表明各项指标都有所提升。由于深层特征层的特征映射尺寸小,且包含语义信息较强,不需要通过特征增强模块,因此,本文在Conv1 层后引入SENet 模块。最后,将原有的SoftMax Loss函数替换为FL 函数后各项性能指标也都有所提升。
由表3实验结果证实,SFF-SSD相对于VGG16-SSD,检测速率提高了21 fps,参数量减少了78.51%,没有VGG16-SSD的检测精度高,但本文研究的是使网络更易于应用在计算能力低且存储能力有限的边缘计算设备上。图5(a)的结果也表明检测能力满足检测要求。因此,SFF-SSD 算法在检测精度不受太大影响的情况下,使模型更小、速度更快,更适合部署在存储空间以及计算资源有限的边缘计算设备中。
3 结 论
为了保证目标检测网络能更好地在边缘计算设备上应用,本文使用更轻量的ShuffleNet V2 网络代替经典SSD 算法的VGG16网络,并进行特征融合,同时引入FL函数作为网络的分类损失函数,在特征提取层引入SENet。采用38 ×38,19 ×19,10 ×10,5 ×5,3 ×3,1 ×1 的特征图尺寸,使用VOC2007数据集对本文改进后的SFF-SSD 算法进行消融实验,实验结果表明,SFF-SSD 算法在各项评价指标中表现良好。后续可使用嵌入式设备作为移动边缘设备进行应用部署。
猜你喜欢
新世纪智能(数学备考)(2021年9期)2021-11-24
中学生数理化·中考版(2021年3期)2021-07-22
中学生数理化·高一版(2021年2期)2021-03-19
新世纪智能(数学备考)(2020年9期)2021-01-04
中学生数理化(高中版.高考数学)(2020年9期)2020-10-28
知识经济·中国直销(2018年8期)2018-08-23
通信产业报(2016年44期)2017-03-13
数学学习与研究(2017年3期)2017-03-09
中国老区建设(2016年1期)2016-02-28
雕塑(1999年2期)1999-06-28
