
基于3D残差卷积注意力网络的跨域手势识别*
2023-12-13 12:12常俊,黄彬,武浩
传感器与微系统 2023年12期
常 俊,黄 彬,武 浩
(1.云南大学云南省高校物联网技术及应用重点实验室,云南 昆明 655000;2.云南大学信息学院,云南 昆明 655000)
0 引 言
近些年来,手势识别一直是一个非常热门和具有挑战性的课题。尤其是基于无设备的手势识别技术,无需穿戴即可完成对人体手势的识别,将促使人机交互朝着更加便捷的方向迈进。传统的手势识别工作中,主要依赖摄像头[1,2],传感器[3,4],射频识别(radio frequency identification,RFID)[5,6],雷达[7]等。与这些方法相比,基于WiFi的手势识别具有成本低、无需穿戴、隐私保护等优势,引发了利用WiFi手势识别的广泛研究。
目前,基于WiFi的手势研究中使用的信号指标一般是接收信号强度(received signal strength,RSS)和信道状态信息(channel state infomation,CSI),RSS 收集便利,但随着距离增加多径现象明显,RSS 的性能会严重降低,如WiDraw[8]以RSS为指标严重限制了其准确性。而与RSS相比,CSI可以提供更多信息,大大提高了手势识别的准确性。基于CSI的手势识别方法主要有3 种:基于模型的手势识别,如CARM[9]使用CSI 速度模型和CSI 活动模型来估计动态CSI和人类活动之间的相关性。QGesture[10]分别建立了一维场景模型和二维场景模型,可以测量2 种模型下的手势移动距离和方向,其方法容易训练且无需大规模数据集,但具有较强的环境依赖性,在新场景下难以有效识别。基于指纹库的手势识别是通过建立一个完整的CSI特征的指纹库,通过手势特征与指纹库特征进行匹配来识别给定手势,如WiGeR[11],WiFinger[12],其精度较高,但需要足够的样本构建指纹库,在新场景下无法实现最好的性能。基于学习的手势识别是结合信号处理算法与机器学习来进行手势识别,如WiSign[13]它利用深度信念网络(deep belief network,DBN)处理后的振幅和相位CSI 轮廓进行手势识别。SignFi[14]使用卷积神经网络(convolutional neural network,CNN)实现了276 个手势的识别。CrossSense[15]通过迁移在不同的场景下重构数据实现跨场景感知,但其需要训练大量不同场景下的数据样本,原始CSI 干扰较多准确率不高,无法实现零努力跨域识别。Widar3.0[16]针对上述问题提出了一种领域无关特征人体坐标速度谱(body-coordinate velocity profile,BVP),同时公布了其使用的数据集,通过BVP结合CNN与循环神经网络(RNN)实现了有效的跨场景手势识别。但BVP通过CNN后会造成BVP时间维度上的信息丢失,导致后续RNN处理效果降低,识别率下降。
针对上述问题,本文提出了一种基于3D 残差卷积注意力网络(residual convolutional attention network,RAN)的CSI跨场景识别方法。通过使用Widar3.0[16]公开数据集,提取出与场景无关的BVP作为特征,运用3D RAN进行信息提取以及分类识别,该模型能更好捕捉学习BVP在空间和时间上的特性,从而提高了跨场景手势识别的准确率。
1 WiFi感知模型与系统设计
1.1 CSI概述
无线信道由于正交频分复用可以分成若干个彼此正交的子信道,将数据流分散到各个彼此正交的子信道中传输。CSI描述了信号在传输路径上的衰减。其中散射、距离、环境等信息都会对CSI造成影响[17]。
Intel®5300网卡中提取出的CSI表征了无线信道的频率响应,是链路的信道属性,每组CSI信息包含了幅度和相位信息,第k个子载波的CSI可描述如下
式中H(k)为第k个子载波的CSI数据,‖H(k)‖为第k个子载波幅值,ej<H(k)为第k个子载波的相位。设X(f,t)和Y(f,t)分别为频率f、时间t时刻的发送和接收信号的频域表示,模型可以简化为
式中H(f,t)为在时间t时,频率为f的信道频率响应(CFR)。CSI基本包含这些CFR值。
1.2 无线信号传输模型
考虑多径传播现象,当信号通过N条路径到达接收端时,在频率为f,时刻为t的无线信道可建模为
式中L为多径数,αl(f,t)为第l条多径幅值的衰减,τl为第l条路径的传播时延,ε(f,t)为由时序对准偏移,采样频率偏移和载波频率偏移引起的时变随机相位偏移。根据路径的是否变化[16]可以将L条路径划分为动态路径和静态路径,式(3)可变为
式中Hs(f)为所有静态分量总和,Hd(f)为所有动态分量总和。
1.3 系统设计
系统包含4个部分,如图1所示。
2 BVP
BVP是一种环境无依赖的三维信号特征,其刻画了人员在进行特定活动时的信号能量在不同速度下分布的变化趋势,BVP的分布情况,对应了活动人员不同身体部位的速度,与单独的躯干速度相比,BVP所表现出的信息更为丰富。通过在手势对应的CSI 中提取BVP 特征来实现手势的跨域感知,从CSI 中获取BVP 需要经过2 个步骤:1)从CSI中获取多普勒频移(DFS);2)从DFS中推导出BVP。
首先,CSI描绘了室内不同时刻、不同子载波下信号到达的多径现象,而信号传播路径长度的变化导致了DFS[18]。人体活动手势反射信号导致的频移可表示如下
式中 λ,f,τ(t)分别为波长、载波频率和信号传播的时间(即传播延时);d(t)为活动手势反射信号路径的长度。因此,CSI可以表示为由手势活动导致的DFS的叠加
通过对网卡上的2个天线收到的CSI做共轭相乘可以去除随机偏移,同时采用Hample滤波滤除带外噪声和准静态偏移,仅仅保留下由手势运动导致的DFS。进一步采用短期傅里叶变换(short term Fourier transform,STFT)可生成在DFS 和时域上的功率分布图。将每个时刻的DFS 功率分布表示为DFS数据,每个DFS数据是维数为F×M的矩阵,其中,F为频域中采样点的数量,M为WiFi链路的数量(发射器数量×接收器数量)。
在提取到对应的DFS 后,采用压缩感知(compressed sensing,CS)的思想来从DFS 数据中导出BVP,根据CS 可以将BVP的估计公式表述为一个优化问题[19]
式中M为WiFi 链路的数量,V为BVP,Di为第i个链路的DFS数据,η为稀疏系数,‖V‖0为V非零分量的数量。A(i)为V在第i条链路上与Di的投影关系,具体形式为
3 3D RAN结构
3.1 3D残差注意力模型
ResNet[20]引入了绕过信号的从一层到另一层的快捷连接,加深了网络。3D ReNet和原始的ResNet之间的区别是卷积核和池化的维数为3。在3D 卷积上加入注意力模块,能够更有效地提取时空特征,如图2所示。

图2 3D残差注意力模块
3.1.1 时间注意力模块
在时间深度上扩展了CBAM[21],使其在3D 卷积上增强卷积网络的性能。利用时间通道内的关系来生成时间注意力(temporal attention,TA)模型,如图3所示。

图3 TA模型
目标在于通过对中间特征图中的每个信号重新加权来提高网络的学习能力。记输入特征图为F∈RT×C×H×W,其中,T为时间间隔,C为通道数,H和W分别为空间域的高度和宽度。通过平均池化(Avgpool)和最大池化(Maxpool)结合的方式可以更加有效地利用时间通道信息[21],记为和,分别为Avgpool和Maxpool后的特征描述,两者将被转发到多层感知器(multi-layer perceptron,MLP),当其通过MLP后,使用元素加来产生一个输出特征图。TA 总结如下
式中w0w1和w2w3分别为2 个MLP的权重,σ 为Sigmod激活函数,BS为沿着空间维度传播TA。
3.1.2 空间注意力模块
空间注意力(spatial attention,SA)(图4)。空间特征图记为MS(F)∈RH×W,2个池化操作产生2 个特征描述记为为7 ×7的卷积,然后沿着时间通道传播SA ,其可以描述如下
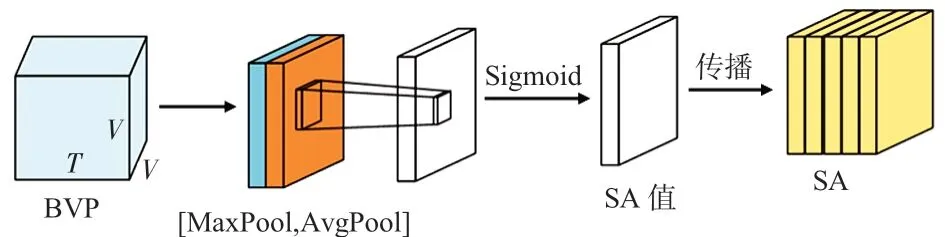
图4 SA模型
3.2 网络结构
RAN由多个残差注意力模块组成,在此省略了残差注意力模块中的批归一化层和激活层。表1 展示了原始的3D ResNet_18[22]和3D RAN 的网络体系结构,同原始3D ResNet之间的基本残差模块的区别在于,RAN中的基础残差块中增加了时空注意力模块。
4 实 验
4.1 实验结果
在Widar 3.0数据集[16]上进行了评估实验图5(a)已知场景中6 种手势的识别率,其中,推拉为91%,横扫为94%,拍手为96 %,滑动为91 %,画圆为89 %,画Z 为97%,平均识别率为93%;同样从图5(b)中可以看出,在未知场景的识别中,6种手势的识别率分别为推拉为85%,横扫为88%,拍手为90%,滑动为85%,画圆为0.83%,画Z为93%,平均识别率为87.4%。实验表明,本文的方法能够实现跨域手势识别。

图5 二种场景下的识别率
4.2 参数研究
4.2.1 时空注意力模块的影响
本文通过将3D ResNet结合不同的注意力模块验证了注意力模块的有效性,使用3D ResNet_18 作为基础网络,通过在ResNet_18 的基本残差模块中单独添加TA 模块、SA模块、时空注意力模块实现网络。表2 为使用不同注意子模块跨场景下6种手势的平均识别准确率。从这些结果可以发现:使用单TA 模块的准确率优于使用单SA 模块,且均高于原始网络。同时使用TA,SA取得了最好的效果。

表2 不同注意力模块下的准确率%
4.2.2 不同层数的残差网络的比较
表3显示了在3D RAN下不同深度下6种手势的平均识别准确率。尽管增加网络深度能够在一定程度上提升手势识别正确率,但随之而来的是参数量的翻倍增长。

表3 不同层数的RAN下准确率及参数量
4.3 方法比较
图6为3D RAN 与现有的方法的比较。对于普通的CNN,由于其只能提取空间上的信息,对于三维数据BVP,其忽略了时间维度的信息,正确率最低,只有75.6%;Widar[16]通过结合CNN和RNN 来提取时空特征,取得了83.4%的正确率;C3D能够同时提取时间特征与空间特征,正确率达到了84.67%;R3D[22]在C3D的基础上引入了快捷短接加深了网络,正确率为85.5%;本文基于3D RAN 的识别率高达87.4%,优于普通的3D 卷积,Widar,R3D。基于3D RAN的识别率更高在于通过加入注意力模块,通过注意力模块来重新加权以提高网络的学习能力。

图6 识别方法对比
5 结束语
本文提出了一种基于3D RAN的CSI跨场景手势识别方法。利用了网络公开的数据集,并按照不同房间划分训练集和测试集用于实验,实现了6种手势在不同方向,不同位置的跨场景识别。实验结果表明:3D RAN 模型能在跨场景的情况下实现较高的识别准确率,在同一场景中,平均识别准确率93%,在不同场景中,平均识别准确率达到了87.4%。证明了3D RAN在CSI活动识别方面的鲁棒性。
猜你喜欢
网络安全与数据管理(2022年3期)2022-05-23
北京航空航天大学学报(2020年10期)2020-11-14
计算机工程(2020年3期)2020-03-19
红领巾·萌芽(2019年9期)2019-10-09
自动化学报(2019年6期)2019-07-23
中国听力语言康复科学杂志(2019年3期)2019-06-24
小学科学(学生版)(2018年12期)2018-12-19
中国交通信息化(2018年3期)2018-06-13
小学阅读指南·低年级版(2017年6期)2017-06-12
中国交通信息化(2016年2期)2016-06-06
