
改进YOLOV4-Tiny的SAR图像舰船小目标检测
2023-12-13 01:39徐继尚柳翠寅
小型微型计算机系统 2023年12期
徐继尚,柳翠寅,2,刘 明,2
1(昆明理工大学 信息工程与自动化学院,昆明 650500) 2(昆明理工大学 计算中心,昆明 650500)
1 引 言
合成孔径雷达(Synthetic Aperture Radar,SAR) 是一种先进的主动式微波对地观测系统,可以全天时、全天候的对地实施观测[1-3].如今,SAR系统越来越多的被使用在海洋交通管制、非法捕鱼检测、海上应急救援中[4,5].当SAR图像分辨率较低或舰船目标实际尺寸较小时,舰船在SAR图像中仅可能会显示为一个亮斑[6],普通目标检测算法在对这些小目标进行特征提取时,很容易丢掉一些重要的特征信息,进而导致错检、漏检,不仅如此,还需要考虑到轻量化、实时性因素.
近年来,深度学习与目标检测任务的结合使得目标检测领域得到了快速的发展,相比于传统算法,深度学习利用自动学习数据中的特征表达和学习能力,在检测速度和准确率方面均有显著提升[7].随着硬件条件的提升以及卷积神经网络的发展,国内外研究者开发出各种各样的检测模型,其目的是在网络自动学习参数后可以识别目标并给出其所在的位置[8].检测模型通常分为两阶段目标检测模型和单阶段目标检测模型,两阶段目标检测模型如:R-CNN[9],Fast-RCNN[10],Faster-RCNN[11]等,此类模型将目标检测任务分成两个阶段,第1阶段用来生成候选区域,第2阶段从候选区域中得到目标的位置和种类,精度一般较高,但模型通常更为复杂,需要更长时间训练,检测速度也很难满足实时性的需求.单阶段目标检测模型如:SSD[12],RetinaNet[13],YOLO[14-17]等,此类模型直接输出目标位置和种类信息,是一种端到端、兼顾速度和精度的目标检测模型.
为进一步提高目标检测算法精度并考虑到实时性,本文使用公开的SAR舰船图像数据集SSDD[18],经对比实验后,选择以YOLOV4-Tiny为基础进行改进.首先,将原YOLOV4-Tiny模型增加对下采样8倍特征图的检测,提高网络对小目标的检测效果.其次,为了提高网络感受野,融合不同尺度的特征并考虑到检测速度,在改进后的骨干网络输出的3种尺度后面加入新设计的特征提取模块Module,实验证明Module能够提高模型的检测精度,仅略微的增加耗时.最后,对将要进行检测的特征图添加SE[19]通道注意力机制,并选出合适的参数,实现检测精度的提升且兼顾检测速度.
2 原始YOLOV4-Tiny模型
2.1 网络结构
YOLOV4-Tiny是一种轻量级模型,相比于YOLOV4具有更快的检测速度.YOLOV4-Tiny为了加强骨干网络对特征的提取能力并缩减模型参数,使用CSPDarknet-Tiny作为特征提取网络.CSPDarknet-Tiny主要由CSP-Tiny结构和基础的卷积、最大池化下采样组成.其中CSP-Tiny结构分为两个独立的部分,第1部分对输入不进行任何处理;第2部分对输入进行Spilt操作,取输入特征通道的后半部分,通道数缩减为原来的一半;CSP-Tiny借鉴DenseNet[20]思想,在第2部分对特征进行一次拼接(Concat),通道数量恢复,并使用1×1卷积来进行特征的整合;最后,将第1部分和第2部分的输出再进行一次拼接,得到相比于输入通道翻倍的特征.CSPDarknet-Tiny会输出下采样32倍和16倍的特征图,对于下采样32倍的特征图,网络在经过若干卷积操作之后,直接输出预测结果,即Head1.对于下采样16倍的特征图,先与上采样之后的特征进行拼接,再经过若干卷积操作,最后输出预测结果,即Head2.原始网络结构如图1所示.
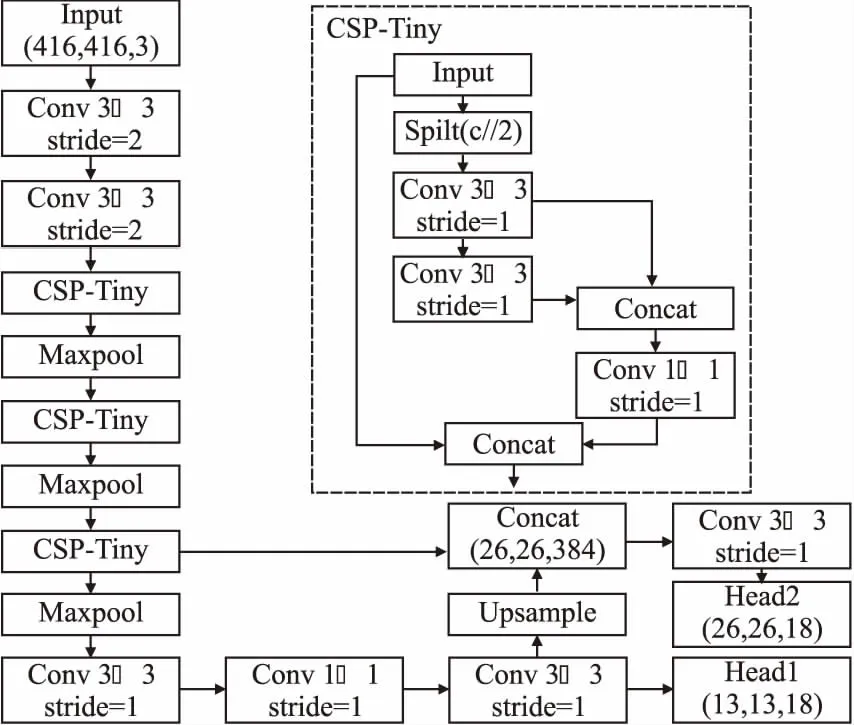
图1 YOLOV4-Tiny网络结构Fig.1 YOLOV4-Tiny network structure
2.2 预测框
YOLOV4-Tiny使用聚类算法来选取锚框(Anchor Box),为了加快检测速度,选择锚框数量为6,YOLOV4-Tiny中有两种待检测尺度,因此,每种尺度会分别对应3个锚框,下采样32倍的特征图分配较大锚框用来检测大目标,下采样16倍的特征图分配较小锚框用来检测中小目标.为了更加准确、快速的生成预测框,网络会针对锚框输出4个偏移量,分别是tx,ty,tw,th,并且使用Sigmoid将tx,ty约束在0-1之间,预测框根据这些偏移量计算得到.公式如式(1)所示:
bx=σ(tx)+cx
by=σ(ty)+cy
bw=pwetw
bh=pheth
(1)
式中,σ表示Sigmoid函数,bx,by,bw,bh是锚框经过调整后得到的预测框的中心坐标和宽高.cx,cy是图像归一化之后当前网格相对于图像左上角偏移的距离,pw,ph是锚框的宽和高,图2展示了锚框在调整之后产生预测框.
3 改进目标检测模型构建
3.1 通道注意力机制
ECA-Net是由Wang等[21]提出的一种通道注意力机制,为了提高计算效率,使用1D卷积对全局平均池化(Global Average Pooling,GAP)后的特征进行处理,如图3所示,其跨通道交互距离由自适应模块决定,特征重要程度的标定决策于Conv1D所捕获的局部跨通道的交互信息.
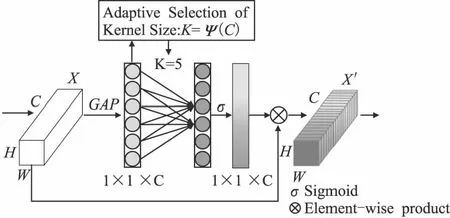
图3 有效自适应通道注意力机制网络Fig.3 Efficient adaptive channel attention mechanism network
原论文中自适应模块使用式(2)来选择最佳跨通道数:
(2)
式中,C表示输入特征的维度,γ和b是常数项分别设置为2和1,|m|odd表示最接近m的奇数.
SE-Net是由Hu[19]等提出的一种通道注意力机制,如下图4所示,首先是压缩操作Fsq,用来对输入特征h×w×c进
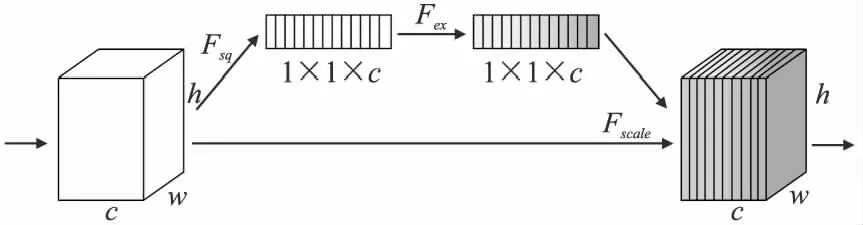
图4 压缩激励通道注意力机制网络Fig.4 Squeeze and excitation channel attention mechanism network
行GAP操作得到1×1×c向量;其次是激励操作Fex,通过两次全连接和一次非线性激活操作来考虑所有通道间的信息并增强网络表达能力,再通过一次Sigmoid操作输出1×1×c的权重向量;最后是Fscale操作,将输入为h×w×c的特征与1×1×c权重向量相乘,进行输入特征通道重要程度的标定.
图5展示了本文所使用的SE-Net结构,其中ratio可以设置通道缩减的倍数,可以用来控制模型的复杂度,原论文选择16倍的通道缩减.
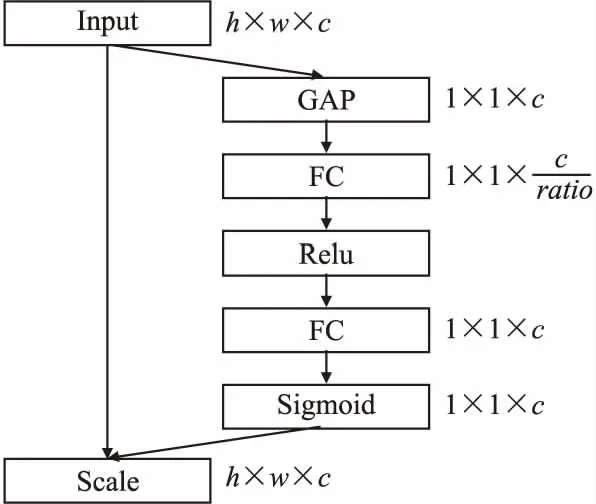
图5 SE-Net结构图Fig.5 SE-Net structure diagram
3.2 特征提取模块Module
受启发于Inception[22]和SPP(Spatial Pyramid Pooling)[23]网络,设计出一种新的特征提取模块Module,对于输入进来的特征,会分别经历两个部分,左边部分使用1×1卷积进一步整合特征信息,保持了特征的重用性;右边部分首先使用1×1卷积缩减通道,接着分别送入3个分支,5×5和7×7的池化核能够有效扩大网络的感受野,并且3×3的卷积也能够进一步提取更深层的语义信息,最后将这些特征进行融合,能够有效改善对小目标的检测效果.该模块能够在提取多尺度特征,丰富语义信息的同时,避免加入过多复杂的结构而导致网络精度、速度的下降.具体结构如图6所示.
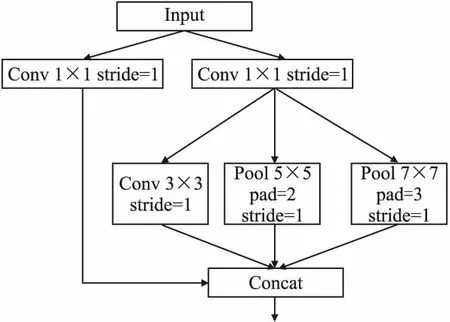
图6 Module网络结构Fig.6 Module network structure
3.3 改进YOLOV4-Tiny模型
YOLOV4-Tiny在检测速度方面有着极大优势,原因之一是骨干网络只输出两种尺度待检测特征图,Head层也只对两种尺度特征图进行预测.这不利于检测含有大量小目标的SAR图像.改进后的骨干网络增加了对下采样8倍大尺度特征图的输出,并相应的添加Head3输出.在骨干网络输出待检测特征图之后,使用设计的Module进行处理,在浅层时能更有利于扩大感受野,丰富语义信息,进一步增强对小目标的检测能力;在深层时可以更有利于提取多尺度特征,融合更多的特征信息.同时,在Head层输出结果之前,使用SE-Net进行特征重要程度的筛选.用虚线框表示新加入的结构,最终改进后的YOLOV4-Tiny如图7所示.
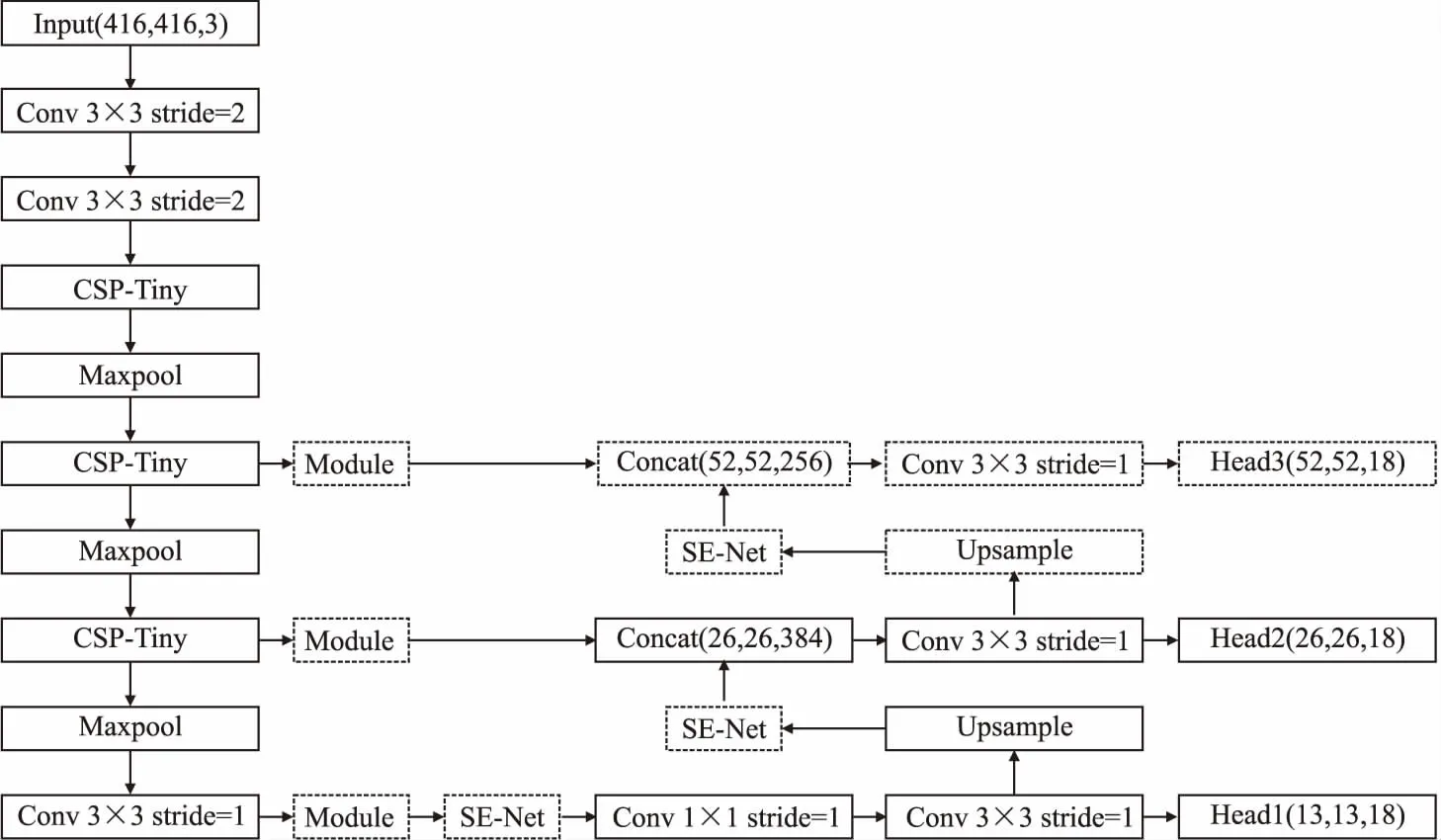
图7 改进后的YOLOV4-Tiny网络结构Fig.7 Improved YOLOV4-Tiny network structure
4 实验与分析
4.1 实验环境与模型训练策略
4.1.1 实验环境
实验所使用显卡为NVIDIA GeForce RTX 2060 12G,CPU为AMD Ryzen 5 1600,RAM为16G,模型训练和测试均在Windows10操作系统,使用深度学习框架Pytorch,并配置对应的CUDA和CUDNN.
4.1.2 评价指标
本文采用精度(Precision)和召回率(Recall)所围成的P-R曲线下的面积AP、单张图像检测时间(t/s)、参数量(Params)作为评价指标.Params为模型中权重参数总量.Precision、Recall和AP定义如下所示:
(3)
(4)

(5)
式中:TP表示正样本被正确分类,FP表示负样本被错误分类,FN表示正样本被错误分类,P表示精度,R表示召回率.
4.1.3 模型训练
SSDD公开数据集由RadarSat-2,TerraSAR-X,Sentinel-1卫星采集得到,包含1160张图像,共2456只舰船,平均每张图像中含有2.12个舰船目标.为更加充分利用数据集和更好的学习特征,本文使用8∶2的比例进行训练集和测试集的划分,以图像名称中1和9结尾的作为测试集,其余数字结尾的图像作为训练集.由此得到的训练集中的图像数量为928张,测试集中的图像数量为232张.为避免模型陷入局部最优以及更快寻找最优参数,使用预训练权重进行迁移学习和微调.训练时使用Adam优化器并将整个过程分为两个阶段,第1阶段,冻结骨干网络,对Neck层以及Head层进行训练,学习率设置为0.001,批量大小设置为64,迭代50回合;第2阶段,解冻所有网络,联合训练解冻和添加的网络层,迭代450回合,共计500回合.
4.2 基于YOLOV3和YOLOV4、YOLOV4_Tiny的对比实验
表1列出了YOLOV3,YOLOV3_v1,YOLOV4,YOLOV4-Tiny模型的参数及其检测结果,其中YOLOV3_v1是YOLOV3部分通道减半版本,参数量为16.34M,约为YOLOV3参数量的27%.经过训练后,AP值相对YOLOV3降低0.26%,但大幅缩减了参数量,单张图像检测耗时也减少了4ms.因此,含有过多通道数的网络在检测特征较简单的SAR图像时存在着冗余现象.YOLOV4对比YOLOV3提升1.06%的AP值,但由于YOLOV4模型更加复杂,单张图像检测时间增加12ms,参数量也比YOLOV3多2.42M.而YOLOV4-Tiny单张图像检测耗时0.014s,参数量为5.87M,AP值能够达到94.24%.尽管YOLOV4使用了特征提取能力更强的CSP-DarkNet53,但其中也包含大量卷积操作和过多特征通道数,也不太适合检测SAR图像.可以发现,卷积操作和通道数较少的YOLOV4-Tiny在检测精度与速度方面具有很大优势.
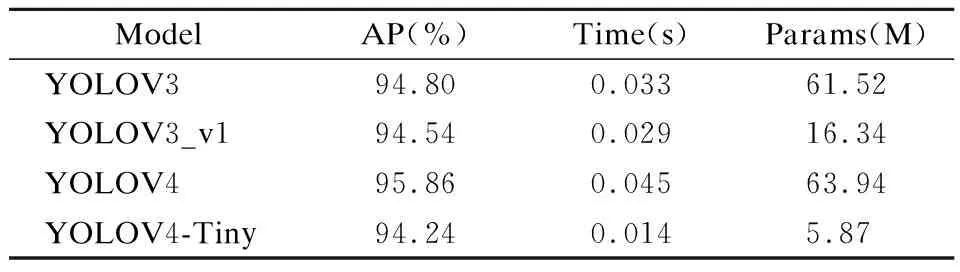
表1 不同YOLOV3版本以及YOLOV4,YOLOV4-Tiny的参数及检测效果Table 1 Parameters and detection effect of different versions of YOLOV3,YOLOV4 and YOLOV4-Tiny
4.3 添加8倍下采样以及Module的对比实验
表2列出了添加8倍下采样之后的YOLOV4-Tiny,将其命名为YOLOV4-Tiny_v1,其AP值相比原始YOLOV4-Tiny提高1.23%,单张图像检测时间增加5ms,参数量增加0.65M.
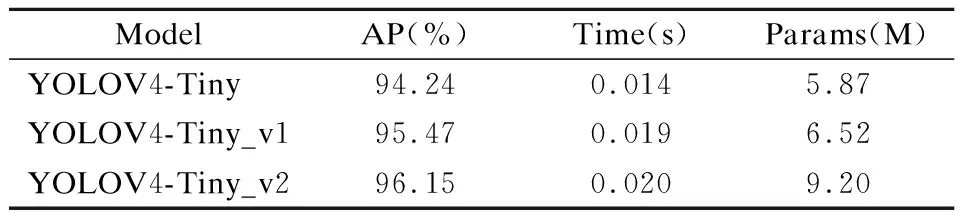
表2 YOLOV4-Tiny添加8倍下采样与Module之后的参数及检测效果Table 2 Parameters and detection effect of YOLOV4-Tiny after adding eightfold down sampling and Module
使用大尺度特征图进行检测有助于提升召回率和准确度,因此AP值也会相应提高,但同时也增加了网络复杂度.在YOLOV4-Tiny_v1基础上加入Module并将其命名为YOLOV4-Tiny_v2,相比于原始YOLOV4-Tiny,AP值提升1.91%,单张图像检测时间增加6ms,参数量增加3.33M.同时,YOLOV4-Tiny_v2比YOLOV4-Tiny_v1的AP值高出0.68%,这是因为特征在经过Module处理之后,不同池化核能有效扩大特征感受野,并实现不同感受野特征的融合,可以有效提高检测小目标的能力,3×3的卷积也能够进一步提取特征,增加不同尺度的特征,避免引入过多单一的卷积而破坏网络提取的特征,从而提升检测效果.由于需要整合四部分特征信息,参数量相比YOLOV4-Tiny_v1增加2.68M,单张图像检测时间增加1ms.
4.4 添加通道注意力机制
表3列出了在YOLOV4-Tiny_v1基础上分别添加两种注意力机制网络,使用ECA-Net后AP值提升0.40%,检测时间增加1ms,模型仅增加极少量参数;使用SE-Net后AP值提升0.62%,检测时间增加2ms,参数量增加约0.04M.说明在网络中加入通道注意力机制能够提升模型的检测效果.文献[21]中,ECA-Net被称为SE-Net的改进版,不仅在参数量上优于SE-Net,而且检测速度和精度也要优于SE-Net.然而,在SAR舰船目标检测中,使用ECA-Net之后的模型检测精度却不如SE-Net.经分析主要原因是:文献[21]使用MSCOCO作为测试集,其中的目标特征较为复杂和多样化,而SAR图像中舰船目标较小,特征简单,周围的干扰信息会对目标本身造成较大影响,Conv1D所捕获的跨通道信息有可能受这些干扰信息影响,从而降低原本效果,而SE-Net使用两次全连接能够结合全局通道信息做出判断,降低了这一影响.因此,选择SE-Net能更适合检测SAR舰船目标.但受SE-Net中全连接层参数的影响,检测时间相对于ECA-Net增加1ms,模型参数量增加约0.04M.
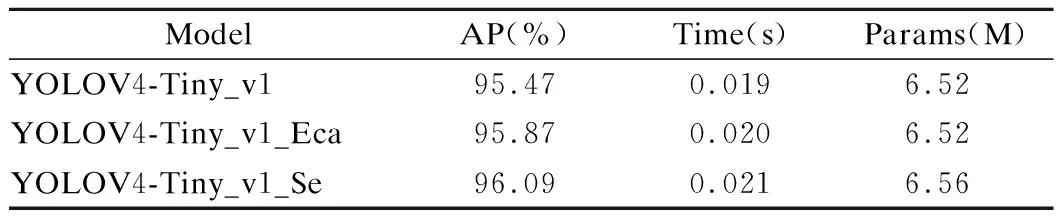
表3 YOLOV4-Tiny_v1添加不同通道注意力机制后的参数及检测效果Table 3 Parameters and detection effect of YOLOV4-Tiny_v1 after adding different channel attention mechanisms
表4列出了在YOLOV4-Tiny_v2基础上分别添加ECA-Net和SE-Net,并分别命名为YOLOV4-Tiny_v2_Eca和YOLOV4-Tiny_v2_Se,使用SE-Net的AP值仍比ECA-Net高0.37%,同时检测时间增加1ms,参数量增加约0.03M.
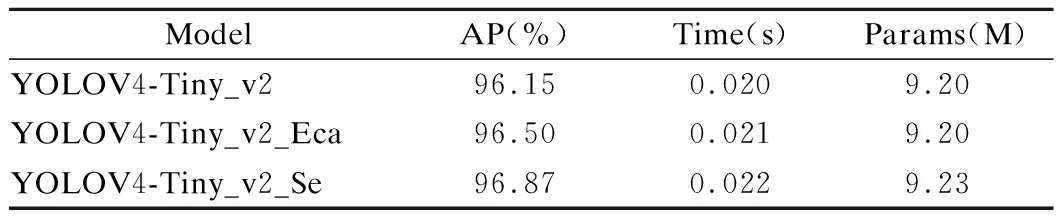
表4 YOLOV4-Tiny_v2添加不同通道注意力机制后的参数及检测效果Table 4 Parameters and detection effect of YOLOV4-Tiny_v2 after adding different channel attention mechanisms
4.5 选择最佳ratio
为了将SE-Net性能发挥到最佳,探究3种不同ratio对模型的影响,表5列出了在不同ratio取值下的模型参数和检测效果,使用原论文中ratio参数,AP值为96.87%,参数量为9.23M;将ratio设置为32时,全连接层中的参数减少了约0.01M,AP值达到97.17%,参数量为9.22M;将ratio设置为64时,全连接层的参数再次减少约0.01M,AP值为96.66%.因此,在设置ratio为32时,模型的检测精度能够达到最优.
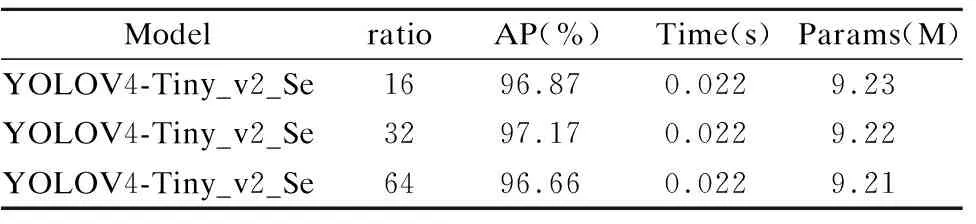
表5 ratio取不同值时的参数及检测效果Table 5 Parameters and detection effect when ratio takes different values
4.6 不同目标检测算法对比
将本文改进的YOLOV4-Tiny算法与其他主流目标检测算法作对比,每类目标检测算法实验环境相同,均采用同样的训练集和测试集数据.Faster RCNN、SSD、YOLOV3、YOLOV4、YOLOV4-Tiny与YOLOV4-Tiny-ours的性能对比如表6所示.其中,两阶段目标检测算法Faster RCNN参数量为136.69M,单张图像检测时间为0.108s,AP值为87.82%低于任何一种单阶段目标检测算法.SSD300作为单阶段目标检测算法相对YOLOV3和YOLOV4参数量有较大优势,且单张图像检测时间分别减少9ms和21ms,但AP值分别低5.08%和6.14%.耗时最短的YOLOV4-Tiny检测每张图像仅需0.014s,比YOLOV3和YOLOV4分别减少19ms和31ms,AP值分别低0.56%和1.62%.本文提出的YOLOV4-Tiny-ours相比YOLOV4-Tiny提升2.93%的AP值,检测时间增加8ms,参数量增加3.35M.YOLOV4-Tiny-ours在参数量、检测时间和AP值上均优于Faster RCNN、SSD、YOLOV3、YOLOV4经典模型.
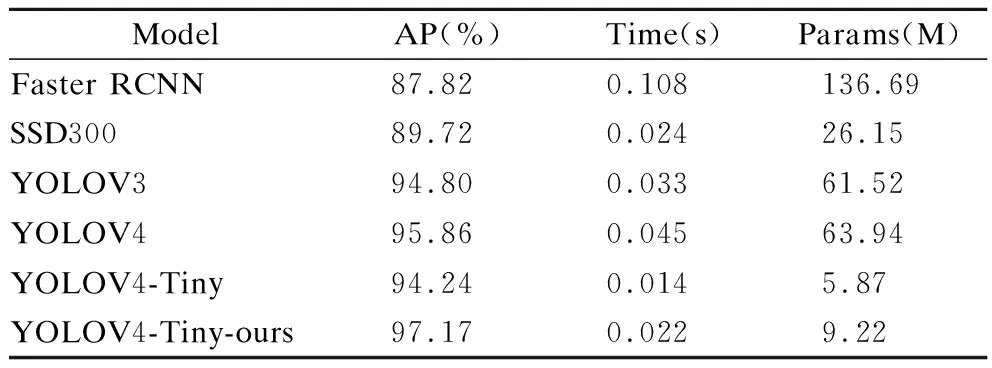
表6 不同检测算法性能对比Table 6 Performance comparison of different detection algorithms
4.7 改进模型检测效果
原始YOLOV4-Tiny和YOLOV4-Tiny-ours在测试集中的检测效果如图8所示,最左边一列是真实标注框(Ground Truth),通过对比可发现,改进后模型在检测精度、置信度方面有较好的改善,并能检测出更多小目标,但在舰船较密集情况下,网络容易将多个舰船当成一个整体,造成漏检,检测效果有所降低.

图8 模型改进前后检测效果对比Fig.8 Comparison of detection model before and after improvement
5 结 论
为了提高检测SAR图像舰船小目标的效果并考虑到实时性、模型轻量化,首先设计YOLOV3通道调整实验得出过多的通道数并不适合检测SAR图像中的舰船小目标,又对YOLOV4进行测试,AP值相对YOLOV3虽有1.06%提升,但检测耗时增加12ms,因此设想含有大量卷积和过多通道数的模型在检测SAR舰船小目标时存在冗余现象,CSPDarknet-Tiny在特征提取方面会更有效,因此使用YOLOV4-Tiny进行测试之后,AP值仅比YOLOV4低1.62%,检测耗时仅占其31%,所以YOLOV4-Tiny能够很好地适应SAR图像检测,因此,本文选择对YOLOV4-Tiny进行改进,改善其在检测小目标时存在的不足.在原网络中加入8倍下采样特征图,便可以将AP值提升至95.47%,相比YOLOV4低0.39%,检测时间仅占其42%,并且相对原始YOLOV4-Tiny提升1.23%AP值.使用设计的Module能够在增加8倍下采样的基础上既提升网络的感受野又提高小目标的语义信息,联合提高了对小目标的检测效果,且能够在高层提供更丰富的特征信息,改善整个网络的表达能力.尽管ECA-Net是SE-Net的改进版,但在用于检测SAR图像时,更需要考虑全面的特征信息来进一步提高检测准确率,因此使用SE-Net可以更好地增强重要特征.最终改进的YOLOV4-Tiny-ours检测精度达到97.17%,相比原始YOLOV4-Tiny提高2.93%的AP值,保持了模型的轻量化,满足实时性检测需求,后续研究工作可以通过对抗网络改善图像效果和使用更优的非极大值抑制算法来进一步提高检测精度.
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02
中外女性健康研究(2020年10期)2020-08-02
中国医学创新(2019年9期)2019-08-19
电子制作(2019年11期)2019-07-04
小学生学习指导(低年级)(2019年3期)2019-04-22
北京航空航天大学学报(2018年1期)2018-04-20
医学信息(2017年16期)2017-09-05
建筑建材装饰(2016年13期)2017-01-04
小猕猴智力画刊(2016年6期)2016-05-14
现代企业(2015年5期)2015-02-28
