
融合多层次交互注意力的引文推荐算法
2023-12-13 01:39樊加倍钱宇华彭甫镕
小型微型计算机系统 2023年12期
樊加倍,钱宇华,彭甫镕
1(山西大学 大数据科学与产业研究院,太原 030006) 2(山西大学 计算机与信息技术学院,太原 030006) 3(山西大学 计算智能与中文信息处理教育部重点实验室,太原 030006)
1 引 言
随着科学技术的发展,学术文献发表数量以每年8%~9%的速度快速增长[1],学者需要花费大量的时间从海量学术资源中获取需要的资源.当前,获取学术文献的主要方法是从中国知网、谷歌学术、微软学术等学术检索系统做关键词文本匹配查询.这类系统通过对用户输入文本与数据库内的学术资源进行分词、索引、匹配、打分等操作获取相关论文.主要优点是使用方法简单,系统容易被用户理解,但是缺乏对查询文本语义信息的挖掘利用,用户需要手动完成对检索结果语义层面的筛选.近年来,随着深度学习对信息检索等自然语言处理任务产生的巨大影响[2],大量基于深度学习的文本匹配方法[3]试图提高查询内容与目标内容的语义相关性.
现有文本匹配技术多集中于短文本匹配任务,在学术论文标题、关键字等匹配任务中取得较好效果,但是受限于查询文本短,语义化匹配程度低,用户获取检索结果后仍需花费大量时间阅读文献正文进行二次筛选.学术文献属于篇章级长文本,传统短文本匹配模型并不适用于长文本匹配任务:一方面,模型忽略了长文的语义结构,难以充分挖掘学术论文的语义信息;另一方面,基于深度神经网络的模型主要用于句子对之间的匹配,文本越长模型计算复杂度越高,难以处理篇章级的文本[4].
为了克服以上问题,本文提出了基于层次化交互注意力的学术引文匹配模型,做出的主要贡献如下:
1)使用多层次的深度神经网络架构,对输入的论文文本进行单词、句子两个层次的编码,有效获取学术论文多层次结构化信息,增强模型语义编码效果.
2)对查询论文与匹配论文进行跨文档注意力交互表示,挖掘论文间引用匹配特征.
3)在3个数据集上测试本模型,实验结果表明本文提出的HIA模型在学术引文匹配任务中达到较好效果.
2 相关工作
19世纪中期以来,推荐系统成为一个重要的研究课题,并逐渐应用于商品、影视资源、新闻、学术文献等.2002年S.M.McNee[5]将推荐系统技术应用于学术文献的推荐,2007年,T.Strohman[6]首次提出了引文推荐的概念.学术引文推荐按照任务需求可以分为局部引文推荐与全局引文推荐[7].全局引文推荐是针对整篇学术论文的参考文献列表预测与推荐[6];局部引文推荐指对需要添加引用的特定位置的语句或者专业术语进行具体引用文献的推荐[8].学术论文推荐领域常用的推荐技术大致可分为4种,分别是基于内容的推荐[9]、协同过滤推荐[10]、基于图模型的推荐[11]以及混合推荐方法[12].其中,基于内容的引文推荐的关键在于实现学术文本内容之间的精准匹配,本文构建学术引文匹配模型,基于学术文本内容的语义挖掘完成全局引文推荐任务.
不同于传统文献检索输入关键词等短查询文本,在引文推荐研究中,为了获取科研人员的需求,通常需要将用户检索需求表述为一段目标查询文本[8],文本段落中所包含的信息更为丰富,能够更加精确合理地识别用户需求.同时,也需要对候选论文进行内容编码,获取学术论文的语义特征.摘要是对全文信息的概括,避免了全文文本中的信息冗余,常用作学术论文编码输入.还有学者认为,文献标题是全文主旨的精炼表达,更能突出论文核心内容[13],Guo等人在论文编码过程中采用标题-摘要注意力机制,使得标题中的主题信息能够在编码表示过程中占据更重要的权重[14],从而使得到的学术论文表示兼顾语义丰富性与主题信息.
文本匹配是自然语言处理领域的重要方向,主要研究两段文本之间的关系.近年来,深度学习技术的快速发展开启了文本匹配的新篇章.深度学习文本匹配方法主要包括两种类型,分别是基于表示(representation)[15]的匹配方法与基于交互(interaction)[16]的匹配方法.基于表示的匹配方法[15,17-19],对需要匹配的两个文本分别进行处理与编码,得到相应的文本表征,然后基于文本表征结果,计算文本相似度;基于交互的匹配方法[16,17,20,21],针对基于表示的方法过于依赖前期文本表征的质量,且容易丢失文本内容词法及句法特征的问题,提出在表征阶段对两个文本进行不同粒度的特征交互,再加权融合得到最终的匹配分数.
学术文献匹配任务面向的是长文本内容的匹配,现有的文本匹配技术多集中于短文本匹配,无法满足长文本内容的深层次语义匹配需求,面向长文本的分类及表征任务,逐渐得到一些学者的关注.Yang[22]等人认为长文本中包含丰富的语义与结构信息,提出HAN层次注意力网络,获取文本结构的语义信息.Liu[23]等人采用分治思想,利用图结构分解长文章的内容,把长文章的匹配转化为图节点上的短文本匹配.Yang[24]等人,提出了对长文本分句后进行加权短句子得分方法来解决长文本匹配问题,这些模型均对长文本匹配任务进行了很好的尝试.本文则充分利用基于交互的文本匹配模型与长文本的层次化结构特点,使用交互匹配模型架构,挖掘学术论文的多层次结构化信息,精准获取隐含的引用匹配特征.
3 层次交互注意力引文推荐
引文推荐根据输入的查询文档从候选集中选择语义相似度及引用匹配度高的学术论文进行推荐,为了有效利用学术文献的结构信息,提高推荐结果的语义匹配度,提出一种层次化交互注意力(Hierarchical Interactive Attention,HIA)模型,如图1所示.为便于对模型的理解,本节首先给出模型问题定义,然后介绍模型框架和具体模块.
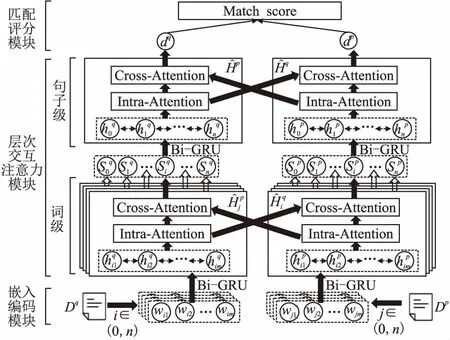
图1 层次交互注意力模型框架Fig.1 Architecture of hierarchical interactive attention model
3.1 问题定义
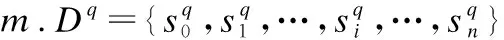
3.2 模型框架
层次化交互注意力(Hierarchical Interactive Attention,HIA)模型采用“双塔”结构[25],即左右两边采用相近似的网络架构,如图1所示.该模型主要由嵌入编码模块、层次交互注意力模块和匹配评分模块组成.其中,层次交互注意力模块对文本进行词级和句子级两个层次编码,每个层次的编码过程包含文档内部注意力(Intra-Attention)和跨文档引文间交互注意力(Cross-Attention)两种注意力机制.
3.3 嵌入编码模块
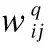
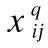
(1)
(2)
(3)
3.4 论文内部注意力(Intra-Attention)
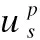
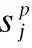
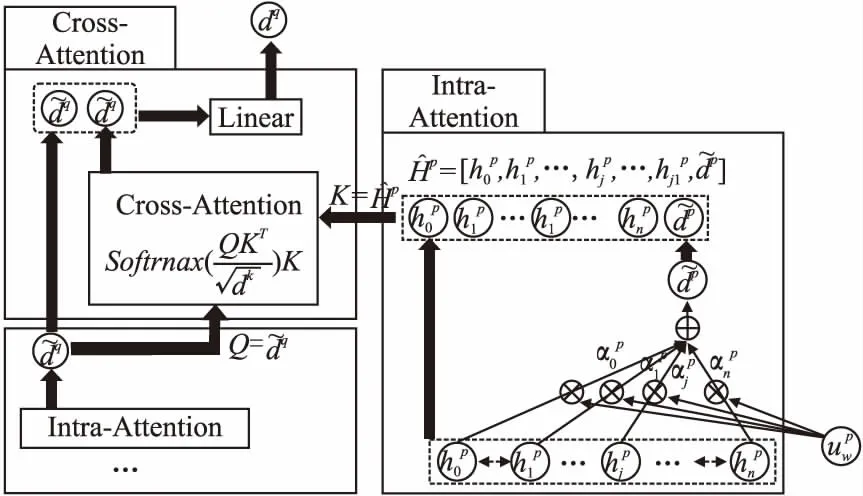
图2 HIA模型句子级注意力机制Fig.2 HIA model sentence-level attention mechanism
(4)
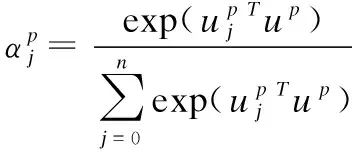
(5)
(6)
3.5 引文间注意力(Cross-Attention)
存在引用关系的两篇文本往往具有较强的语义相关性,或拥有相似的潜在话题分布.不过,学术引文的选择,不单单只建立在两篇学术论文高语义相似性的基础上,还有大量引用行文发生在论文局部内容匹配的情况下,这些细粒度的信息匹配特征,对引文推荐效果的提升也值得关注.为了挖掘学术引文间细粒度文本内容匹配特征,本文设计了Cross-Attention模块,在文本编码过程中对查询文献与引文文献进行跨文档注意力交互,获取论文之间细粒度的信息依赖关系.
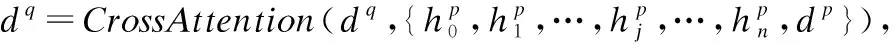
Q=dq
(7)
(8)
(9)
(10)
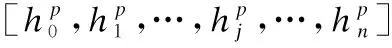
3.6 匹配评分模块
经过层次交互注意力模块,模型得到两段文本的编码表示dq和dp.接着需要对获得的向量表示进行相似度计算,常见的相似度度量方法有曼哈顿距离以及余弦相似度等.Jiang[28]等人指出,这些方法不能很好的获取长文本中的复杂语义关系,不适用于长文本数据,并提出了使用全连接层来度量长文本相似性的方法.模型采用这种全连接网络进行文本对的相似性度量,整体流程如图3所示.
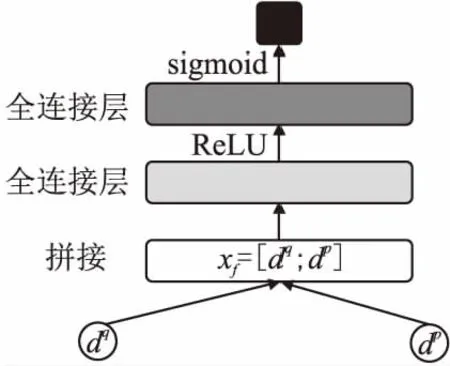
图3 匹配评分模块结构Fig.3 Architecture of match scoring module
首先拼接两个表示向量得到xf=[dq;dp],采用神经网络对xf计算相似性.
uf=ReLU(Fd(xf))
(11)
y′=σ(Ff(uf))
(12)
其中,Fd(·)和Ff(·)是两个全连接隐藏层;ReLU(·)是线性激活函数;σ(·)是为logistic sigmoid函数,用于生成文本相似度的概率分数y′.
3.7 模型训练
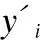
(13)
其中,N为总样本数量,yi=label为样本真实标签.
Adam算法[30]是随机梯度下降算法的扩展,通过计算梯度的一阶矩估计和二阶矩估计为不同参数设计独立的自适应性学习率,能够在占用较少资源的情况下令模型更快收敛,为此,使用Adam进行模型优化.
4 实 验
在DBLP[31]、S2ORC[32]和PeerRead[33]数据集上进行实验,与当前流行的文本匹配模型进行对比,并进行消融实验验证Cross-Attention模块的有效性,在Acc[34]与F1[34]等评价指标上比较模型性能.
4.1 数据集
从计算机、自然语言处理、医学等领域选择了3个英文学术文献数据集对模型进行验证.DBLP数据集使用AMiner公开的计算机领域引文网络数据集.S2ORC数据集为AllenAI研究院Semantic Scholar学术搜索引擎提供的学术论文资源,涵盖了计算机、神经科学及生物医学等研究领域.PeerRead数据集中的学术文献数据从ACL、NIPS、ICLR、CoNLL等自然语言处理领域会议收集.
3个数据集包含学术论文的标题、作者、摘要、发表期刊等信息,本文实验只使用了标题、摘要及引用关系信息(标题与摘要作为模型输入,引用关系作为数据标签).为统一格式与数据标签,需对数据进行文本解析、信息抽取等预处理操作(如图4所示).
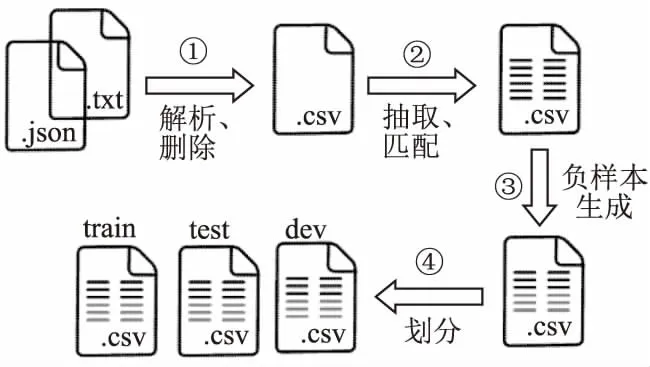
图4 数据处理过程图Fig.4 Data processing process
①解析原始数据,删除缺失项:将原数据格式解析为csv格式,对数据中缺失论文标题、摘要及引用关系的样本进行删除,生成的每条样本数据表示一篇学术论文,包含论文id、标题、摘要、作者及引用关系等属性.
②抽取论文文本,生成正样本:对每一条学术论文数据根据论文引用关系属性查找引文,拼接原文与对应引用论文的标题及摘要信息,得到引用论文对,设置样本label为1,生成引文正样本.
③负样本生成:每个学术论文数据集内部的论文研究领域相近,为了保证生成的负样本与正样本存在相关性,对每条正样本中的查询论文在数据集中随机选择一篇没有引用关系的论文,设置label为0,生成负样本.
④训练、验证、测试集划分:混合正负样本,对每个数据集,以3∶1∶1的比例随机划分train、test、dev数据集.
处理后的学术论文引用关系数据集如表1所示.实验过程中,受限于计算资源限制,对比实验主要在PeerRead与DBLP数据集上进行,模型在S2ORC数据集上的实验从总数据中随机抽取20%进行实验.
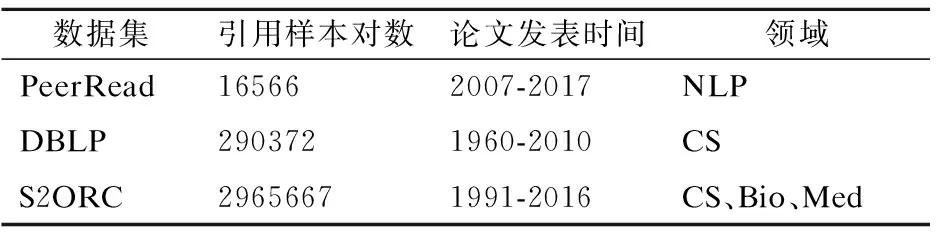
表1 数据集信息Table 1 Dataset information
4.2 实验设置
为了验证HIA模型的有效性,设计了如下对比实验与消融实验.
1)与当前主流文本匹配模型进行比较,评估HIA模型在学术引文匹配任务中的性能.
2)验证模型中引文间交互注意力模块在不同层次编码过程中的有效性.
在PeerRead与DBLP数据集上,选择6种基于开源项目MatchZoo[35]实现的模型进行比较:基于表示的文本匹配模型ARC-I[17],基于交互的模型ARC-II[17]、MVLSTM[19]、KNRM[20]、MatchPyramid[16]、ESIM[21].其中,ARC-I、ARC-II与MatchPyramid基于CNN神经网络,MVLSTM与ESIM基于RNN神经网络,KNRM基于核方法.
消融实验模型的设置如下:
HIA:在词级和句子级均进行引文间注意力交互.
HIA-N:取消编码过程中的引文间注意力交互.
HIA-W:仅在词级编码保留引文间注意力交互.
HIA-S:仅在句子级编码保留引文间注意力交互.
4.3 实验环境与参数设置
1)环境配置
使用深度学习框架PyTorch实现模型网络架构,所有实验在同一环境下进行训练、验证与测试.实验硬件设备装有500G内存和Tesla V100S PCIe(32G)GPU,操作系统为Ubuntu 16.04.6 LTS,使用的Python版本为3.5.6,PyTorch版本为1.2.0,Matchzoo-py版本为1.1.1.
2)参数设置
所有模型的嵌入层采用50维度的Glove模型对输入文本进行词嵌入,训练过程使用Adam优化器,并且设定初始学习率为0.0005,基于RNN结构的MVLSTM与ESIM模型中的隐藏层大小设置为50.消融实验模型的batchsize设置为64.
根据3个数据集文本长度统计,设置模型输入文本的最大句子数量n与每个句子的最大单词数量m.模型在读取数据时会截断超过长度的文本,或为长度不足的文本填充“-1”.PeerRead、DBLP、S2ORC这3个数据集设定的最大句子数量(n)分别为:9、9、11,最大单词数量(m)分别为:32、33、39.
4.4 评价方法
模型采用预测准确率(Accuracy,Acc)与综合评价指标(F1-Measure)作为评价指标,对实验结果进行定量分析.Acc是分类任务常用的一种评价指标,F1值是对模型查准率(Precision)和查全率(Recall)两个指标的加权调和平均.他们的定义如下所示.
(14)
(15)
其中,TP表示成功判断出有引用关系的引文的样本数量.FN表示没能判断出论文对之间的引用关系的样本数量.FP表示将没有引用关系的样本对判断为有引用关系的数量.TN表示将没有引用关系的样本对判断为没有引用关系的数量.
Precision表示模型预测正确有引用关系的数量在全部预测有引用关系样本中的占比,Recall表示模型中有引用关系的论文被成功判断出来的样本数量中的占比,即:
(16)
(17)
4.5 实验结果分析
本文设计了HIA模型与6种当前流行的文本匹配模型的对比实验,和验证引文间注意力模块对模型影响的消融实验.其中,对比试验在PeerRead与DBLP两个数据集上做了训练、验证和测试,各个模型的测试结果如表2所示,模型训练过程中在PeerRead数据集的验证集accuracy值变化图如图5所示.模型消融实验在3个数据集上进行,得到消融实验结果如表3所示.
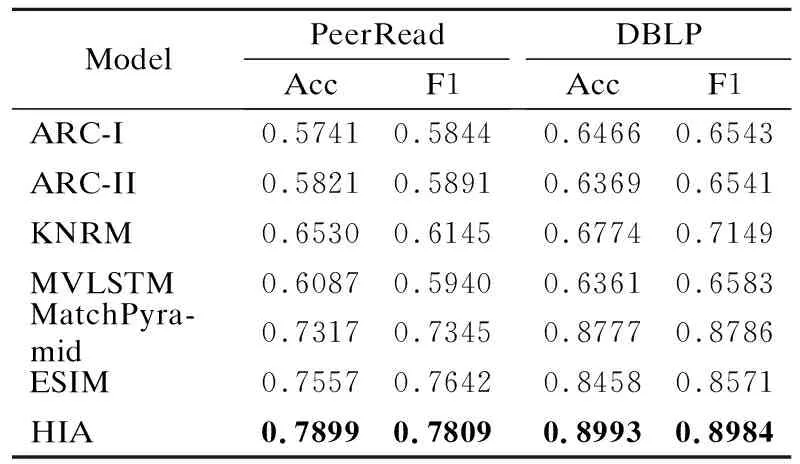
表2 HIA模型与对比实验结果表Table 2 Comparison HIA model with comparative experimental results
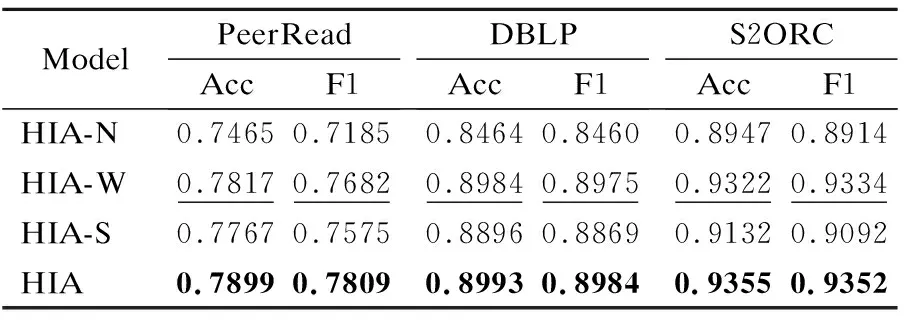
表3 Cross-Attention消融实验结果表Table 3 Comparison Cross-Attention ablation experimental results
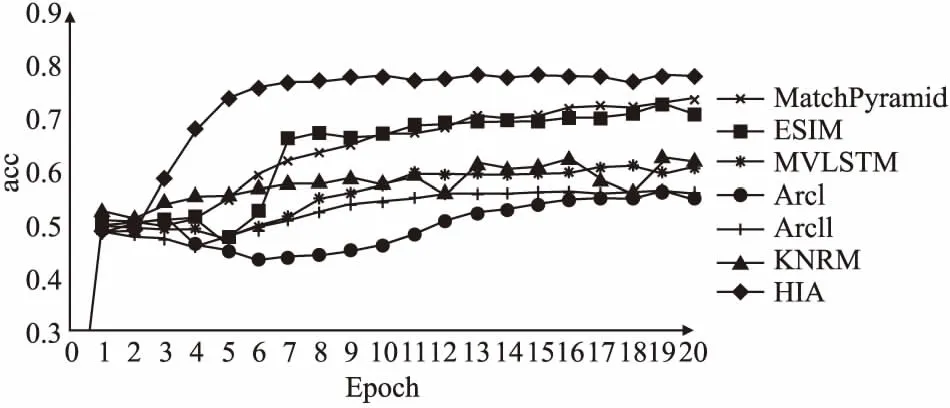
图5 PeerRead数据集不同模型验证集Acc值变化折线图Fig.5 Trends in different models validate set accuracy using PeerRead dataset
表2列出了HIA模型与对比模型在PeerRead和DBLP数据集上的实验结果对比.本文提出的HIA模型在两个论文数据集上的Acc与F1指标均超过其他对比文本匹配模型.本文实验输入的匹配数据为学术论文标题与摘要文本,学术文本为典型的长文本内容,为了获取长文本内容中的结构信息,HIA模型设计了层次化结构,进行词级与句子级编码.对比模型中,HIA模型与ESIM模型均使用了双向循环神经网络与交互注意力机制.在相同的参数设置下,进行层次化编码的HIA模型达到了更好的效果,特别是在DBLP数据集中Acc指标得到了5.35%的提升,充分证明了层次化结构的设计能更有效地挖掘学术论文中的深层语义信息,提高长文本匹配任务效果.
图5展示了各模型在PeerRead数据验证集的训练过程中Acc指标变化情况(DBLP数据集数据量大,所有模型在较少epoch训练轮次均能迅速收敛).从图中可以看出,HIA模型在训练过程中能够迅速收敛,且Acc值始终优于其他对比模型,验证了模型的稳定性.
表3展示了引文间交互匹配模块的消融实验结果.为了验证本文所提出的跨文档交互注意力模块(Cross-Attention)的有效性,设计消融实验验证模块对学术引文匹配任务是否有效,比较模块在词级、句子级编码过程中产生的作用.
HIA-N模型表示去掉跨文档注意力交互模块后的模型,与HIA-N模型相比,在不同层次引入引文间注意力模块均对准确率Acc值与F1值有明显提升,表明Cross-Attention模块的有效性.且在引入Cross-Attention模块的3类模型中,在词级与句子级均添加此模块的HIA模型达到了最优,验证了模型在词级和句子级编码过程中都能挖掘到有利于引文匹配的特征.对比HIA-W与HIA-S模块,可以发现在词级编码过程中引入Cross-Attention后效果显著提升更明显,表明低级文本间的细粒度交互特征更有利于语义信息特征的表示.
5 结束语
本文首先介绍了学术文本检索任务面临的挑战,接着介绍了学术引文推荐与文本匹配现有模型方法,通过分析任务需求与现有模型优缺点提出了层次化交互注意力匹配的学术引文推荐模型(HIA).对学术文献进行层次化编码表示,通过神经网络获得长文本结构特征;引入文档内词级与句子级内部注意力机制,增强学术论文内部语义信息表示;构建跨文档引文间交互注意力,使得模型学习到引用论文间细粒度引用匹配特征.将HIA与其他文本匹配模型进行对比试验,HIA在Acc与F1两个指标上均表现良好,有效提高学术引文匹配效果.尽管本文的工作提升了学术引文匹配任务中的效果,但本文只考虑了用户检索获取引文过程中的输入文本内容,缺乏对用户个性化兴趣倾向的关注,接下来的工作可以利用学者已发表论文的信息,挖掘学者研究兴趣,达到更好的学术引文推荐效果.
猜你喜欢
系统医学(2023年18期)2024-01-10
系统医学(2023年13期)2023-10-26
系统医学(2022年17期)2022-11-07
系统医学(2022年2期)2022-05-05
小雪花·成长指南(2022年1期)2022-04-09
开放教育研究(2020年2期)2020-03-31
传媒评论(2017年3期)2017-06-13
第二课堂(课外活动版)(2016年2期)2016-10-21
现代语文(2016年21期)2016-05-25
大连民族大学学报(2015年2期)2015-02-27
