
基于小样本StyleGAN的多类别车损图像生成方法
2023-12-11 07:11杨佳熹那崇宁
计算机工程与应用 2023年23期
丁 锴,杨佳熹,杨 耀,那崇宁
之江实验室,杭州 311121
基于图像的车损评估在交通事故快速处理、车险保费预测、车险理赔反欺诈等方面有重要意义。但现有的车损图像公开数据集较少,标注质量不高,训练样本量不足[1],这些问题一方面涉及到数据隐私原因,另一方面也与真实场景中车损类型分布极不均衡有关。如图1所示对某小型车险公司2019年有图像数据的车险类别分析,其中碰撞(包括两车及多车碰撞)占车险总量的92.2%,未知原因损伤5.3%,水淹1.2%,玻璃破碎0.5%,着火、坠物砸伤、倾覆等共占比不足0.8%,且未知原因损伤大部分也是轻微碰撞等。这种极端不均衡的情况对下游深度学习模型带来较大的挑战,特别是样本分布差异导致的模型迁移能力变差。例如,基于训练数据的图像分类模型,在测试集中对样本较少的类别预测精度较差。

图1 车险类型统计分析Fig.1 Statistical analysis of car damage types
近年来,运用对抗网络(GAN)的图像生成技术,可实现图像样本扩增,对降低样本的标注工作量,提高训练集的多样性等有很好的效果。特别地,StyleGAN[2]及其衍生模型可支持高分辨率图像生成,因此在人脸图像、医学图像等领域获得广泛关注。StyleGAN 可以将不同尺度以及来自不同图像的特征混合,组成新的高保真图像。例如,针对高清人脸图像,可以将A 人脸的眼镜特征移植到B图像上。针对车险图像,如果能将样本较少的损伤特征移植到无损车辆上,并可以调整损伤的严重程度,就可以得到足够多训练样本,覆盖测试集样本范围,从而保证模型对测试集的适用性。但是,训练StyleGAN 同样需基于样本数量充足、图像质量高的数据库(如LSUN-CAR[3]、FFHQ[4]等),目前尚未有公开的高质量车损图像数据集,且在实际车损图像应用场景中也较难以快速构建出标注清晰完整的车损数据集。另外,StyleGAN有一个较强且容易被忽视的假设条件,即数据需进行对齐预处理。例如,人脸需进行方向校正,否则模型难以收敛或者生成图像扭曲失真,这种条件在很多数据库上也是无法满足的。StyleGAN后续工作对此进行了改进,增强了模型对多样性和多视角未对齐等条件的兼容性,如StyleGAN V3[5]和StyleGAN XL[6],但这些工作都是基于大数据库如ImageNet 等,未能在小样本数据库上进行验证。
针对目前车损图像集存在样本数量少、样本质量差、样本类别之间分布不均衡等缺陷,本文研究使用StyleGAN 进行车损图像生成的问题,主要包括:(1)基于StyleGAN的多类小样本车损图像对抗生成模型如何训练,能否收敛,最优模型效果如何?(2)如何利用该模型框架生成新的多分类车损图像,能否使生成图像按期望路径变化?(3)生成图像能否有效扩增原训练集空间,从而实现下游分类任务精度的提升?
本文贡献在于:(1)验证了StyleGAN小样本学习在高样本多样性数据上的收敛性,并分析了影响收敛的因素。(2)实现了StyleGAN 特征解耦,可以沿特定维度方向生成新车损图像。(3)基于训练模型对图像分类任务进行图像扩增,验证了对测试集的有效性。
1 相关研究
1.1 GAN的小样本收敛
GAN 同样需要面对样本不足的问题,并非所有的数据库都如同FFHQ,构建这些数据库需要大量的标注工作,在很多实际应用场景并不具备相应条件。样本过少导致GAN判决器过拟合,从而引起整个系统的失效,表现在训练次数超过特定值时,模型效果开始变差,生成图像逐渐退化为类似初始噪声图像,FID等模型度量参数开始发散。如何平衡生成器与判决器之间的关系,优化生成图像,是小样本图像生成研究目标。
当前小样本图像生成分为两种不同情况,一种是有基础数据库辅助,另外一种没有基础数据库辅助,本文研究属于第二种情况。有基础数据库辅助时,可以通过在目标小样本数据库上精调或者直接使用在基础 数据库上学习的模型进行图像生成,相关工作包括LofGAN[7]、FUNIT[8]等。这些方法的缺点是需要已标注的辅助数据库,并且辅助数据库样本分布与目标数据库有较强的相关性。例如常用的动物头像和花卉数据库,不同动物的头像,不同植物的花朵之间有较强的相关性。没有额外数据库辅助的图像生成,只借助自有样本实现新样本生成,相关工作包括StyleGAN-ADA[9]、StyleGAN-APA[10]、Diff-GAN[11]和小样本图像合成[12]等。小样本图像合成是非条件生成,大多针对数据集为单类的情况(如人脸生成等),而StyleGAN-ADA、StyleGANAPA、Diff-GAN 可以实现条件图像生成,也可用于非条件图像生成。从图像生成方式分类,当前小样本图像生成可被分为融合生成和变形生成,融合生成是在像素空间通过特征对齐与加权求和的方式将两个以上样本合成为新样本,例如LofGAN,变形生成则是在嵌入空间通过单个样本的特征维度变换形成新样本,例如StyleGANADA和Diff-GAN,对称一致性约束(bCR)[13]等。
bCR 和Diff-GAN 是面向小样本GAN 训练的通用型方法,StyleGAN-ADA 和StyleGAN-APA 则仅针对StyleGAN。其中bCR 方法利用传统数据增强方式,在判决器前进行数据扩增,同时调整判决器惩罚函数,以消除扩增数据带来的渗漏。但此方法仅对判决器进行数据扩增,仍会带来数据渗漏问题。Diff-GAN 通过同时对生成器和判决器进行可微分数据扩增,实现扩增不渗漏到生成器,并延缓判决器过早收敛。StyleGANADA 使用类似Diff-GAN 对生成器判决器同时增强的方法,确保增强效果不渗漏到生成器。另外,它提出自适应地控制若干增强参数的方式,保证StyleGAN 模型在小样本条件下的收敛性。StyleGAN-APA采用在判决器的真实集中增加生成图像以缓解StyleGAN判决器过拟合的方法。
目前针对小样本GAN收敛问题仍有很多待研究方向。例如,基于有基础数据库辅助的小样本生成技术对于源域和目标域数据分布差异的容忍程度[14];GAN模型的早期训练阶段生成图像无实际意义,如何更好地初始化生成器,直接跳过此阶段,从而加快收敛速度;如何使用通用预训练模型,或者基于跨域预训练模型进行域迁移精调等方法提高训练效率等[15-16]。考虑到车损图像的特殊性,目前尚缺乏具备迁移价值的源域图像数据,因此本文中的研究工作未采用有基础数据库辅助的方法,而是使用无辅助数据库方法,具体地,利用传统增强结合自适应增强约束的方式实现小样本GAN的收敛。
1.2 基于GAN的图像生成
GAN 生成图像的方法有多种:随机生成新样本,混合生成新样本,以及对潜在向量操纵等。随机生成新样本是传统的基于GAN 进行数据增强的方法,利用随机种子向量生成与训练集样本相似的“假”样本。StyleGAN 是近年较好的可生成高清图像的方法,使用了渐进式分层生成,分辨率从小到大生成的过程中分别使用不同层特征,从而实现高清图像生成。同时,渐进式生成完成了对不同层特征即潜向量的解耦,启发了对操纵潜向量以生成新图像的研究,相关方法包括样式编码器(Styleencoder)[17]、像素到样式到像素(PSP)[18]、面向编辑的编码器(E4E)[19]和HyperStyle[20]等。研究分为两个方向,一种是潜向量空间和图像作为一对映射,训练一个编码器学习这种映射,然后利用编码器将训练集外图像一次映射到潜向量空间,例如E4E、HyperStyle、PSP。另外一种是无需训练,直接使用StyleGAN 迭代式将训练集外图像映射到潜向量空间,相关研究包括Styleencoder、StyleGAN 等。对潜向量操纵需解耦StyleGAN 的生成器,找出潜空间的主要方向及其物理意义,相关工作如基于GAN 的人脸潜向量解释性研究[21]等。
1.3 基于GAN数据增强
基于GAN的数据增强的研究主要样本分布不均衡的情况,相关工作包括小样本分类GAN(FSCGAN)[22]、多虚类GAN(MFC_GAN)[23]和皮肤黑色素瘤增强(SLAStyleGAN)[24]等,FSCGAN 使用条件GAN 的方法,在GAN 中增加类别惩罚函数,保证生成样本在分布上对训练集形成补充。MFC_GAN 延续了FSC GAN 的研究,提出改进的多虚类惩罚函数,提升类别粒度以增大类间距离。但以上算法使用的GAN 模型仅针对CIFAR10等分辨率较低的图像数据库,无法应用于高分辨率图像。SLA-StyleGAN研究面向高分辨率黑色素瘤图像,该研究利用StyleGAN 模型对样本稀少的类进行扩增,然后对扩增后的数据进行分类,验证了方法的有效性。但仅在黑色素瘤等医学图像纹理较简单、图像质量较好的条件下可行。可见,基于GAN 图像增强的研究还有较强的条件约束,例如要求不同图像中目标需对齐,拍摄角度差异不能太大等。这些约束在车损图像等多样性强,样本差异大,图像质量不一致的复杂数据库上难以满足。
2 基于小样本图像生成的车损数据增强
本章介绍基于有限车损图像样本进行StyleGAN模型训练、并找出有效保持收敛的方法。其次,对GAN模型进行潜向量空间解耦,分析解耦对应车损相关物理意义。最后,针对随机生成,样式合成等图像生成方式实现图像扩增,分析了样本扩增对图像分类任务提升效果的差异,并对后续可进一步研究的方向进行了讨论。
2.1 有限样本车损图像集StyleGAN训练
样本过少导致判决器过拟合,从而引起整个GAN的失效,它表现在生成器的无意义生成以及损失函数值的发散。数据增强在图像分类任务中的成功证明了多样化的数据增强是有益的,为此本文希望通过数据增强使GAN 收敛。但是,通过直接变换的方式增加训练集样本会引起生成器泄露,即生成样本上也带有这些变换。针对此问题,StyleGAN-ADA提出随机一致性规范的增强方法,对批次样本进行概率增强,并在生成和判决阶段加入数据增强惩罚函数,这种方法可进行无泄漏增强。这里,同样使用StyleGAN-ADA,分以下步骤:首先,构建一个由变换组成的模块,这些变换分为6 个类别:像素调整(水平翻转、90°旋转、整数平移)、投影几何变换、颜色变换、图像空间过滤、加性噪声和图像裁剪。最佳的增强强度在很大程度上取决于训练数据的数量,而且并非所有的增强类别在实践中都同样有用。在针对高清人脸的训练集FFHQ中,绝大部分的效果提升来自于像素调整和投影几何变换,颜色变换、图像空间滤波、加性噪声和图像剪裁并不是特别有用。但是,鉴于车辆损伤图像的差别远超过高清人脸图像,本文需要对上述六种变换重新进行有效性评估,具体实验及分析见3.2节。
在训练过程中,数据增强的强度由p∈[0,1]控制,上述六种变换以固定顺序作用于图像,即每个变换都以概率p应用,或以概率1-p跳过。鉴于流程中存在多种增强,即使是相当小的p值,也会使某些增强因概率累加效应生效,从而使增强图像区别于原图。在某轮训练中,所有的变换总是使用相同的p值,只要p保持在安全阈值以下,生成器就会被引导到只生成无渗漏的图像。
为了优化模型收敛效果,本文沿用自适应控制p的方法。原ADA算法以连续4批次图像的判别器输出值平均正负值为标准,E(sign(D(x))),其中E()表示均值,D()为判决器的输出,表达式为:
其中,real表示x为真实图像,fake表示x为生成图像。上述过拟合判定标准根据经验被固定设为0.6,当E的计算值低于此值,判决器欠拟合,不需进行增强,仅利用原图像训练模型;超过此值,判决器过拟合,p被设定为正值,原图像被增强后用于训练。如果两次以上被判定为过拟合,p值增高,从而保证判决器快速恢复到欠拟合状态。
2.2 条件图像的StyleGAN生成
车损图像生成是一个条件生成问题。所谓条件图像生成与非条件图像生成,主要区别在于条件图像生成时,初始化潜向量中包含样本的类别信息。这会导致在生成网络训练过程中,类别信息会限制不同类之间图像的相互学习,因此条件图像生成网络需要更多的训练样本以保证模型收敛。
基于StyleGAN 的条件图像生成过程如图2 所示,图左侧为映射网络(mapping network),可将初始化向量映射到潜向量空间。这里的映射网络相当于encoderdecoder结构中的encoder,但映射网络使用全连接网络,可以降低参数数量,提升训练速度。这里,初始化向量被映射网络按层投影到潜向量空间,每层对应不同分辨率,如4×4,8×8,…,256×256。然后,生成模块按层将潜向量转换到图像空间,并加入噪声数据,增强数据的多样性。接着,第一层生成的低分辨率图像和第二层生成的较高分辨率图像融合,形成较高分辨率图像。按此顺序,最终合成高分辨率图像。这种逐层生成方式,可以在低分辨率上快速试错,从而实现收敛;而后低分辨率生成图像又为高分辨率生成提供约束,最终保证整个模型的收敛。

图2 StyleGAN图像生成流程Fig.2 Flowchart of StyleGAN image generation
从上述过程可知,潜向量是影响生成图像最重要因素,而按层生成的结构使操纵潜向量的方式更为多样。本文使用三种方式操纵图像的生成:随机生成、样式混合和解耦放缩生成。
随机生成指利用训练集单个样本对应的潜向量进行生成,在生成模块中通过随机噪声形成与原图不同的新图像。
样式混合则使用两个样本,融合相应特征形成新图像。首先选择两个训练样本,将它们映射到潜向量空间,生成两个潜向量;然后在不同分辨率选用不同潜向量,从而以样式混合方式生成图像。具体过程分两个阶段,前阶段使用样本1的潜向量,引导生成低分辨率4×4到32×32 图像,这些图像对应物体的轮廓、朝向等粗特征;后阶段使用样本2的潜向量,引导生成高分辨率64×64 到256×256 图像,这些图像对应物体的小纹理、颜色等细节特征。最后合成图像融合两个阶段的特征。
解耦缩放生成指将潜向量解耦成不同特征方向,然后沿某特征方向增减固定值生成新图像。首先,通过对生成网络权值进行奇异值分解实现潜向量空间解耦。然后,对解耦后的某个奇异值进行增减,则潜向量W沿潜向量空间某个方向变化一定距离,形成新潜向量。最后,基于新潜向量生成新图像。生成图像相比原始图像,按照解耦奇异值对应的物理方向发生改变。例如,FFHQ人脸图像可解耦出年龄、喜怒等特征。本文在实验部分对车损图像解耦奇异值的物理含义进行分析。
2.3 基于GAN的图像分类增强
基于数据增强的图像分类使用两种方式,定量样本扩增和动态样本扩增。首先,比较直接的数据增强方式是通过生成固定数量的新样本,并加入到原训练集形成新训练集,即定量样本扩增。然后,基于新训练集训练模型。最后,在测试集上测试模型的精度提升效果。动态样本扩增比较复杂,因为理论上生成模型可以生成无数不同的新图像,但这些数据的分布可能与原数据不同,如果添加到训练集的新样本过多,训练集分布可能向生成图像的分布偏移。为此,本文使用动态样本扩增的分类器训练方法,如下所示:
步骤1构建efficientnet v2 分类器,loss 函数为Focal loss。
步骤2使用原始训练集X训练分类器,在测试集评估分类器精度。
步骤3使用GAN 按类别生成新图像集ΔX,加入到原始训练集,构建新训练集X′=X+ΔX。
步骤4精调分类器,计算生成图像样本的分类置信度,置信度定义为C(x)=1-|pred(x)-ct|,为样本x判定为其真实标签ct的概率,pred()为分类器预测函数。
步骤5以置信度为概率剔除生成样本,得到训练集X″=X′-rand(C(ΔX))·ΔX,rand()为概率函数。
步骤6再使用GAN生成图像并补充到X″,形成新训练集X‴,重复步骤4~6。
步骤7当重复n次步骤4~6,且分类器在测试集上精度无提升时,分类器训练结束。
迭代将图像加入训练集。筛选方法使用基于当前训练集的生成器生成图像,同时训练分类器,将生成样本按分类器预测置信度高低为概率系数决定保留或者删除,以得到扩增数据库。重复以上过程,不断生成新图像并更新训练集,在新数据集进行分类器训练与测试。为提高训练速度,使用efficientnet v2[25]+Focal loss[26]分类器。
3 实验
3.1 数据库构建
为了验证车损图像分类可以通过数据增强即图像生成提升分类精度。本文构建了两个数据库,如表1所示,首先是使用公开的车损图像数据库,总1 594 幅图片,分8类,包括{前灯,后灯,保险杠凹陷,保险杠刮蹭,车门凹陷,车门刮蹭,玻璃破碎,其他},图像分辨率256×256。整体图像质量尚可,但少量图像存在水印,干扰物体,边缘留白,噪声模糊等问题,如图3 所示,车损部位在这些图像不居中且面积较小,或者被醒目的水印等覆盖。本文将图像集分为训练集测试集其中训练集使用1 394幅图像,剩余200幅为测试集。考虑到上述车损图像的拍摄对象、角度、距离等一致性较差,而StyleGAN通常被证明对一致性较强的图片有效。为此,本文选择车灯作为目标提高图像一致性,构建了车灯图像集,共分四类,分别为前、后未损车灯,前、后损坏车灯。其中,未损车灯使用实际车损图像标注和手工筛选,并放缩到256×256 分辨率。训练集包括570 幅图像,测试集约80幅图像。

表1 车损图像库Table 1 Car damage classification data set

图3 含噪声样本示例Fig.3 Example with bad samples
此外,本文将上述两个数据库的图像分辨率压缩到128×128,从不同分辨率角度测试图像生成及基于图像数据增强的分类精度。
3.2 GAN模型选择评估
本节分别在Cifar10 和车损图像库对现有小样本GAN 模型进行了对比测试,模型包括StyleGAN-APA、StyleGAN-ADA、Diff-GAN,最优模型将被用于后续图像生成。
首先,通过Cifar10数据库,验证了主流方法Diff-GAN、StyleGAN-APA、StyleGAN-ADA 的有效性,实验使用同样的批样本数64,随机梯度下降方法和学习率。训练曲线如图4所示,图中纵坐标显示FID,横坐标显示训练样本总量kimg(千图像),三种方法在Cifar10 数据库都可实现收敛。其中Diff-GAN 的FID 为三者最优为3.63,Style_APA(StyleGAN-APA)的FID 为14.41,Style-ADA(StyleGAN-ADA)的FID为3.79。

图4 面向Cifar10数据库的图像生成FID对比Fig.4 Image generation FID comparison with different methods for Cifar10 database
其次,使用车损数据集测试了三种方法的效果,保持模型参数不变,训练曲线如图5 所示(虚线为单特征增强结果,实线为组合特征增强和自适应增强)。图中从零开始训练,仅Style-ADA和Style-APA实现了有效收敛,但Style-APA模型未能保持收敛状态,在训练超过2×106个样本后,逐渐转向发散。Diff-GAN 模型从开始一直处于随机震荡状态,未进入有效收敛阶段。Style-ADA效果较好,仅在1.4×107个样本时FID开始小幅升高。最后,基于已收敛StyleGAN预训练模型进行精调,如图5所示,仅有Style-ADA的FID保持稳定,其他两种模型都快速衰退到随机状态。从原因上,Cifar每类图像5 000,样本量大,图像分辨率低,与车损图像对比样本的一致性较强。由以上实验可知,针对类似车损图像集这种数据量小,样本多样性强,且为条件图像生成的场景,仅Style-ADA方法可行。对比以上三种方法,可知增强概率自适应控制对小样本收敛最为重要,其次是变换组合类型选择。同时对生成器和判决器进行增强能够保证生成模型不发生增强泄漏,但在保证模型收敛上无明显效果。

图5 面向车损数据库的图像生成FID对比Fig.5 Image generation FID comparison with different methods for car damage database
3.3 StyleGAN训练测试
本节首先对基于有限车损样本的StyleGAN模型收敛性进行评估,其次,对StyleGAN潜向量空间进行了解耦分析。
本文对基于有限车损样本的StyleGAN模型收敛性能进行了多项实验,分别基于8类256×256分辨率、8类128×128分辨率、4类256×256分辨率以及128×128分辨率的车损数据集。FID 收敛情况如图6 所示,图中标识4-256-570分别表示类别-分辨率-样本总数量,四个数据集对应的最低FID 分别为59.9,43.9,116.0,90.0。从图中可知,同类别数量和样本数量的条件下,高分辨率图像最终的FID 数值较高,即分辨率越低,生成图像与真实图像相似度越高。不同样本数量条件下,样本数量越多,最终的FID数值越低。另外,对于样本数量在1 500幅以下的训练集,在8×106迭代以前FID收敛较快,其后此值趋于稳定。

图6 4个数据集FID曲线Fig.6 FID scores of four data sets
其次,本文对不同数据增强方法在StyleGAN 训练中的效果进行了评估。第一,在不使用自适应概率控制的情况下,评估六种图像变换方式的增强效果。第二,对比六种变换的组合增强在是否使用自适应概率控制情况下的增强效果。如图7所示,六种变换对模型收敛性的效果对比,六种变换增强对FID 收敛的有效性评估:如图所示,本文对像素调整(blit)、投影几何变换(geom)、颜色变换(color)、图像空间滤波(filter)、加性噪声(noise)和图像裁剪(crop)六项增强效果分别进行了评估,其中效果最好的是投影几何变换,其次是像素调整和图像空间滤波,裁剪和颜色增强也可以带来精度提升,噪声增强的效果最为有限。在第二组实验,本文对六种增强一起使用进行了评估,图中bgcnfc 曲线,发现其导致模型向较差的单种增强收敛。与此同时,本文对自适应调整增强强度p的方法进行了评估,见图中ada曲线,可知自适应调整增强强度p效果显著。因此,在样本数量为2 000 以下的情况,建议使用效果较好的单种增强geom或者geom,blit混合增强的方式,并配合自适应概率控制方法。
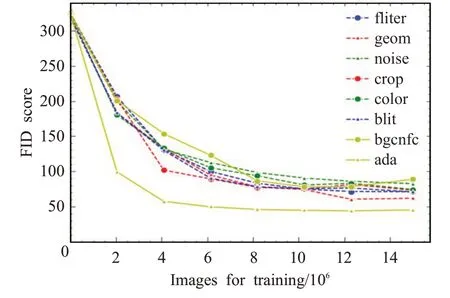
图7 不同增强方法的FID曲线Fig.7 FID scores by different augment methods
最后,本文对模型的计算复杂度进行分析。模型结构与分辨率有关,但不严格成正比。如表2 所示,模型参数的数量总体随图像分辨率变化,分辨率从32开始,每提升4 倍,参数数量变多一次,而两倍分辨率提升如128与256,参数差别不大。训练时服务器硬件配置为两张NVIDIA TeslaV100-32G显卡,批大小设置为128。总耗时按照训练完1×103万幅图像统计,因为此阶段模型已经明显收敛或发散,训练阶段结束。总耗时和平均耗时上,分辨率32 的训练集约为分辨率128 的1/5。计算复杂度使用单幅图像的浮点计算量(FLOPs)表示,分辨率32 图像对应FLOPs 为1.3×1010,分辨率128 图像FLOPs 为4.1×1010,分辨率256 图像FLOPs 为4.5×1010。V100 双精度计算能力为7.5 TFLOP/s,每秒可处理约600幅分辨率为32的图像,约140幅分辨率为128或256的图像。

表2 StyleGAN计算复杂度Table 2 Computational complexity of StyleGAN
3.4 StyleGAN图像生成
本节主要进行生成图像分析,生成模型潜向量解耦分析。首先是图像生成结果分析,如图8显示了生成的8 类128×128 分辨率的车损图像以及样式混合的效果。其中,图8(a)第一行为原始图像,第二行对照原始图像的生成图像,图8(b)第二行的第二幅以后图像为样式混合图像,样式混合实际是对两个生成图像的混合。相比于原始图像,生成图像可能产生轮廓变形,颜色改变等,并出现模糊,局部扭曲等问题。拍摄角度和物体区域占比,样本与训练集其他样本的相似度等决定了生成图像的保真度。物体区域占比适中,训练集相似样本较多,则生成图像的保真度较好。混合后的图像在颜色与车灯轮廓特征分别来源于相应的生成图像。

图8 生成图像及样式混合Fig.8 Random and style mixing image generation
通过对生成网络权值进行奇异值分解可以实现潜向量空间方向的解耦。图9 显示了基于潜向量空间解耦后,沿着选定方向对生成图像进行操纵变换的生成结果。图中显示了四组,每组第一幅为原生成图像,后面两幅是操纵变换的生成图像。其中,左侧两组分别对应车部件的颜色逐渐变深和变浅,右侧第一组对应车辆部件的纵向拉伸,第二组对应玻璃破碎、拉伸和颜色。注意,单个解耦方向与实际感知方向,如颜色、大小、程度等,并不一一对应。如图中左侧两组变换,仅大致对应颜色的变深和变浅。按特定感知方向进行潜空间解耦,需要额外有监督模型辅助。

图9 基于潜空间解耦的生成图像Fig.9 Images generated by manipulated disentangle space
3.5 生成图像增强分类实验
本节进行基于生成式图像增强的分类实验,实验对象包括8类车损图像集和4类车灯图像集。每个图像集分别在256×256 及128×128 分辨率条件下进行分类测试。分类模型为Efficientnet v2,模型训练采用学习率为0.005,批次64,每模型训练200 轮,dropout 值为0.5,GPU为v100。
首先,在8类车损图像集进行生成图像增强对照实验,分别对增强前后的图像集进行模型训练及预测精度评估。数据扩增方式分为固定样本数量扩增和动态样本扩增方式,先进行固定样本数量扩增测试。如表3所示,增强前图像集记为原始图像集,增强后图像集为原图像集加上生成图像集,基于这些图像集进行模型训练,然后在测试集统计分类精度。图像生成方式据2.2节所述,包括随机生成、样式混合生成、随机+样式混合以及沿解耦方向生成,对应表中+rand_gen、+mix_gen和+rand+mix_gen、+disentangle_gen。其中随机生成按100幅图片/类扩增数据,样式混合则随机取50个样本为前阶段源图像,另50个为后阶段源图像,按组生成50幅新图像,然后前后阶段互换,再生成50幅图片,随机+样式混合样本扩增量为上述两者之和。沿解耦方向生成时,取8个主要的方向,对随机选的100个样本分别按照正负向百分之10操纵生成新图像,单类样本增多1 600。分类精度上,256×256 分辨率原始图像集预测精度为(78.4±0.9)%,128×128 分辨率精度为(79.0±0.8)%。经随机生成的数据扩增,预测精度分别为(81.1±1.1)%,(81.2±0.5)%,经样式混合扩增,两种分辨率下预测精度分别为(81.5±0.7)%,(81.2±1.0)%,经随机+样式混合扩增,两种分辨率下预测精度分别为(81.5±0.3)%,(83.4±0.9)%。沿解耦方向生成,两种分辨率下的预测精度分别为(80.7±0.6)%和(81.9±0.9)%。图10 显示训练过程的测试精度,基于生成的数据扩增能够一定程度地丰富数据的多样性,为深度学习模型带来增益,在128×128分辨率上提升效果更为显著。比较而言,上述各种增强方法最终预测精度差别不大,+rand+mix_gen 方式为训练集融合了多种增强样本,效果稍优。本文认为提升效果与低分辨率的图像保真度较高有关,因为生成图像如果与真实图像差别较大,则其分布与原数据分布存在差异,所以生成数据的多样性无法体现到精度提升上。同时,受样本数量限制,测试集较小,其分布范围有限,加重了分布差异性的影响。

表3 在八分类训练集不同数据扩增方法的分类精度Table 3 Classification accuracy with different data enhancement methods on 8 category data set

图10 不同图像生成方式的数据增强分类准确率Fig.10 Image classification accuracy rates with different image generation methods
其次,本文对8类车损图像进行了动态样本扩增分类测试,迭代式添加样本,并根据条件去除相似样本等,具体训练步骤见3.3节所述。这里仅对随机生成和样式混合进行测试,其中随机生成扩增最高精度82.7%,样式混合扩增最高精度83.2%,考虑随机性误差,效果与固定样本扩增接近,如表4所示。动态样本扩增实验中增加约800 幅图像/类,其效果未显著高于固定样本扩增,本文认为主要是因为样本的保真度和多样性两部分原因,其中更重要的是基于StyleGAN 扩增的样本多样性不足。如图11 所示,同批次生成样本中有多个样本外形极为相似,并且这种相似样本在每类中都会出现,从而大幅降低生成样本的多样性,导致图像分类模型的预测精度相比固定扩增方式难以提升。

表4 动态扩增多次迭代的分类精度变化Table 4 Classification result with dynamic enhancement method 单位:%

图11 不同随机种子的相似生成样本Fig.11 Similar generated images by different seeds
最后,为了测试生成模型对样本空间更小的数据集的扩增效果,本文在4类使用车灯图像进行生成图像增强对照实验,图像集包括前后车灯和前后损坏车灯共四类,总共570 幅训练集图像,79 幅测试集。增强前图像集为原始图像集,图像生成方式包括随机生成、样式混合生成、随机+样式混合,对应表中+rand_gen、+mix_gen和+rand+mix_gen,其中随机生成和样式混合按100幅图片/类扩增数据,随机+样式混合的类样本扩增量为两者之和。同样对分类精度进行5次评测,如表5所示,256×256 分辨率原始图像集预测精度为(90.2±0.9)%,128×128 分辨率精度为(91.2±1.0)%。经随机生成的数据扩增,预测精度分别为(91.1±1.1)%,(92.2±1.5)%,经样式混合扩增,两种分辨率下预测精度分别为(90.5±0.7)%,(91.2±1.2)%,经随机+样式混合扩增,两种分辨率下预测精度分别为(91.5±1.0)%,(91.5±0.9)%。总体而言,基于StyleGAN图像增扩对4类车灯数据的图像分类有一定程度提升,但相比8 类图像增扩,提升效果不显著。本文认为原因仍是生成图像的多样性和保真度问题,虽然本实验样本空间限制为车灯图像,但训练集样本量更少,引起FID 值较高。其次,本次实验中同样发现相似生成样本较多,即扩增样本多样性不足的问题。

表5 在四分类数据集上不同数据扩增方法的分类精度Table 5 Classification accuracy with different data enhancement methods on 4 category data set单位:%
4 结束语
本文研究了基于有限车辆样本的StyleGAN模型的训练方法,对常规增强训练流程进行了评估,证明在多样性,且未进行对齐的图像数据库上,像素调整结合投影变换的增强方式最优;并评估了StyleGAN-ada提出方法对有限样本训练集的有效性,证明了样本集500~1 500之间可以使StyleGAN模型收敛。然后对模型进行潜向量空间解耦与解耦方向实际意义分析。接着进行了随机生成、样式合成等图像生成方式实现。最后,针对不同的图像扩增方式,分析了样本扩增对图像分类任务提升效果的差异,并对后续可进一步研究的方向进行了讨论。
通过图像扩增及分类精度提升效果分析,StyleGAN的生成图像后续工作:(1)图像校正的高清车损图像集构建,包括对图像进行校正、滤波等预处理,提升图像集数量和质量,这是最直接的提升生成样本保真度,从而提高分类器预测精度的方法。(2)StyleGAN基于更优的初始向量,而非随机初始向量进行图像生成。(3)基于向量化变分自动编解码VQVAE[27]等方法,提升样本的多样性。
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
数学物理学报(2019年3期)2019-07-23
家庭影院技术(2018年9期)2018-11-02
电子制作(2018年11期)2018-08-04
自动化学报(2017年5期)2017-05-14
成都信息工程大学学报(2017年6期)2017-03-16
高中生学习·高三版(2016年9期)2016-05-14
测绘科学与工程(2016年5期)2016-04-17
新高考·高二数学(2015年11期)2015-12-23
