
CRCLA编译前端中代码检测与DFG生成技术研究
2023-12-11 07:11杨晨光杜怡然
计算机工程与应用 2023年23期
杨晨光,李 伟,杜怡然
战略支援部队信息工程大学 密码工程学院,郑州 450001
粗粒度可重构处理器具有丰富的计算资源和互连资源,能够适用于密集型计算,同时兼具高能效与灵活性的特点使其受到了学者的广泛关注。粗粒度可重构密码逻辑阵列(coarse-grained reconfigurable cipher logical array,CRCLA)作为一种面向密码算法的专用可重构处理器,在运算单元中添加了适用于密码运算的模块,并在互连以及控制方面做了针对性设计,但这也导致传统的通用可重构阵列编译架构已不解决的问题。
对于面向CRCLA 的编译技术来说,其可分为前端设计与后端划分、映射。首先不同的编译前端因优化方式的不同将生成不同的数据流图,从而造成编译后端映射性能的差异。那么为充分发挥本文CRCLA的执行效率,需结合CRCLA 结构与密码算法运算特征对前端的编译框架、编译技术进行研究,构建面向CRCLA的前端分析。同时为了扩展CRCLA 的可用性,本文采用高级语言C++来编写密码算法代码,虽然开发人员无需理解硬件实际结构,但也增加了前端生成中间格式的难度。
可重构阵列编译器的支持,不仅能最大程度发挥出阵列的性能还可以降低开发难度。REmus II可重构处理器编译器[1],以带有标注信息的代码作为输入,通过预处理与模板调用模块进行识别,并对识别成功的模块调用模板进行代码宏替换,最终进行配置信息的生成,但该编译器对输入代码的语法具有极大的限制,且不支持跨循环的输入输出依赖。Spatial[2]编译器支持在可重构架构上实现的加速器,使用专门的领域特定语言Spatial允许领域专家快速开发、优化硬件加速器,但Spatial 语言只支持加速器,无法适应粗粒度可重构阵列的开发。TIRAMISU[3]是一个多面体编译器框架,引入了一种命令式的调度语言,允许进行细粒度的优化,从而生成高性能的代码,但命令式调度语言的编写需熟悉具体的硬件结构。TPA-S[4]编译器基于众核处理器结构,以CUDA 编程语言为输入,主要专注于控制流程序,但在面对密码算法这种计算复杂的程序时无法发挥较好的性能。
上述编译器基本采用专门的领域专用语言进行开发,同时针对硬件结构进行了优化,没有统一的编译框架与结构模型,因此在面对其他可重构结构时具有不确定性。由于本文的可重构密码逻辑阵列针对密码算法的实现进行了特殊设计,上述编译器在实现密码算法代码映射时不能达到较好的性能。因此,为发挥本文可重构密码逻辑阵列的高性能与灵活性的特点,本文设计以C++编写的代码作为输入,以FLEX、BISON编译框架进行自动化识别的前端。
设计过程中,由于密码算法众的特殊运算如S盒等可用C++代码以不同的方式实现,但在可重构密码逻辑阵列中可用单个算子运行,因此本文以基于注意力机制的图嵌入模型进行检测识别,以较高的分类精度精简数据流图。同时,基于可重构密码逻辑阵列结构特点对数据流图进行优化,提高了映射性能。
1 基于C++的密码算法代码识别与分析
本文采用FLEX、BISON 编译框架来设计编译器,以高级语言C++编写的代码作为输入,该语言能够忽略底层结构,从而方便非专业人员无障碍使用可编程密码逻辑阵列[5-6]。FLEX、BISON编译框架源代码公开,且免费使用,同时默认生成C 语言程序,相对其他框架在面对C++工程项目时更易维护。
编译前端的分析器设计中,FLEX 将具有输入的程序分割成有意义的单元,这些单元可以是变量名、操作名、字符串等,FLEX使用一系列的标记描述产生一个能识别程序的词法分析器。定义一系列能够理解的规则列表,将这些标记进行连接,即为语法分析器。提取出语法树中的关键信息,即为语义分析器。
1.1 基于FLEX、BISON编译框架的词法、语法分析
词法分析将顺序地读入输入源程序的有限字符序列,根据分析器中的词法规则进行匹配[7],匹配采用的方法为正则表达式法。通过词法规则可以识别简单的字符、运算符号、变量名、变量类型的匹配,还可识别自定义的函数名。同时采取匹配优先级的方法来解决规则冲突,具体指的是在前面的优先级较高,如匹配函数名“matrix”,只需将函数名的定义放在变量名的定义之前即可。
词法分析器将输入的字符流识别为有意义的单词符号,语法分析程序根据语法规则,采用递归下降、移进规约的思想识别单词符号构建语法树[8-9]。自叶子节点进行语法匹配并逐步规约到根节点,其中语法规则的设置需要依据编程语言的文法而确定的。
以常规运算“Value=Msg^Key”作为推导示例,从语法规则逐步递进进行语法匹配,每个词素都将被识别到对应的标识符,最后逐步归约,并将每一步归约的节点信息存入节点链表中。其中目的操作数“Value”经“Exp->VAR->Value”匹配规则可递归到“Exp”,并经由“Exp ASSIGN EXP ->DefList”将整条语句规约到根节点“DefList”,那么将每次递归到的节点存入链表中,就会得到完整的语法树链表。
1.2 语义分析
语义分析主要是对构建的语法树进行分析,通过相应的子程序进行语义检查提取出关键信息[10-12]。本文以生成数据流图为目标,因此需提取有关运算语句间数据传递的关键信息,将其以相应的数据格式保存起来,并最终生成运算操作表。操作表中的运算操作需按顺序存放,以指示密码算法代码中运算的执行顺序。同时为存储密码算法中的输入数据供可重构密码逻辑阵列的使用,将定义的变量名存入变量表中。
本文针对数据流图生成的需求,设计了语义分析程序。该程序根据语法树的格式编写代码,从语法树根节点出发,逐条语句进行分析,识别密码算法中的运算语句的关键信息,具体语义分析流程图如图1所示。
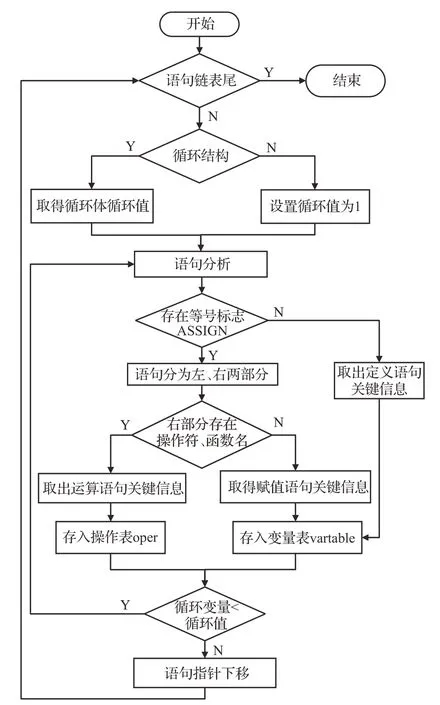
图1 语义分析流程图Fig.1 Semantic analysis flow chart
图1中语义分析流程从语句链表开始,将循环结构展开。然后依据等号标志ASSIGN、操作符与函数名取出定义语句、运算语句、赋值语句的关键信息,并将操作对应的源操作数、目的操作数与运算符存入操作表oper中,将变量名与值存入变量表vartable中,逐条语句进行分析直到语句链表为空。
2 数据流图自动化生成
编译前端需要将密码算法代码生成可被后端使用的中间形式,而可重构密码逻辑阵列运行密码算法,是通过分析算法中的运算及数据依赖生成配置数据,数据流图形式符合编译后端需求,因此采用数据流图作为中间代码格式。针对数据流图的生成,本文对1.2 节经语义分析后得到的操作表oper 和变量表vartable 进行分析,oper 中顺序存放着密码算法运算操作,单条运算包含源操作数、目的操作数、操作符,vartable 中存储着密码算法代码中所有的变量名,通过分析可得运算节点间的依赖关系。
2.1 数据流图生成
本文针对数据流图的生成设计了算法,如下所示为数据流图生成算法的伪代码,算法输入为1.2 节得到的运算操作表Operate,输出为数据流图Graph,整体过程为构建操作表中各操作的父子节点关系,具体生成过程如下。
2.2 基于注意力与图嵌入的代码检测
本文采用高级语言C++,屏蔽掉了可重构密码逻辑阵列的内部结构,便于非专业人员使用以编写代码,但为了使得代码更好地在可重构密码阵列上运行,在编译前端时还需进行具体的分析和优化。从密码算法特征和阵列内部结构来看,密码算法中某些特殊运算如S盒替换运算、比特置换等运算在可重构密码阵列中可当作单步算子进行计算,而在C++编写的代码中,因编写人员的不同,可能会有多种方式编写代码来实现上述算子的功能。那么在生成中间格式时,需对上述得到的数据流图进行检测,以识别相应子图所对应的功能。
本文对于代码相似性检测问题,提出一种以图嵌入与注意力机制结合的方法。图嵌入方法将代码转化的数据流图转化为低维embedding降维,并提取出特征向量[13-15],图注意力可对周围邻居节点的特征进行聚合[16-18]。为提高子图识别的准确度,在图嵌入的基础上,加入图注意力机制构建节点与其邻接节点的注意力系数,然后聚合邻居节点的特征以优化当前节点的特征向量,最后对子图所含节点的向量使用加权平均得到整张图的向量。
2.2.1 基于注意力的图嵌入模型
图嵌入的目的就是将高维的图数据转化为低维稠密向量,并且保留原图的结构特征。图嵌入预定义一个嵌入维数D(D远小于节点数量N),使得G转换到D维空间[19]。在图2 所示的基于GAT 和注意力机制的图嵌入模型中,首先将数据流图数输入GAT 网络中进行运算以获得有依赖关系的节点对间注意力权重与节点特征向量,再根据权重采取随机游走策略生成多个节点路径,并输入deepwalk 图嵌入模型中生成节点特征向量,最后使用Attention注意力机制获得图嵌入向量展示。
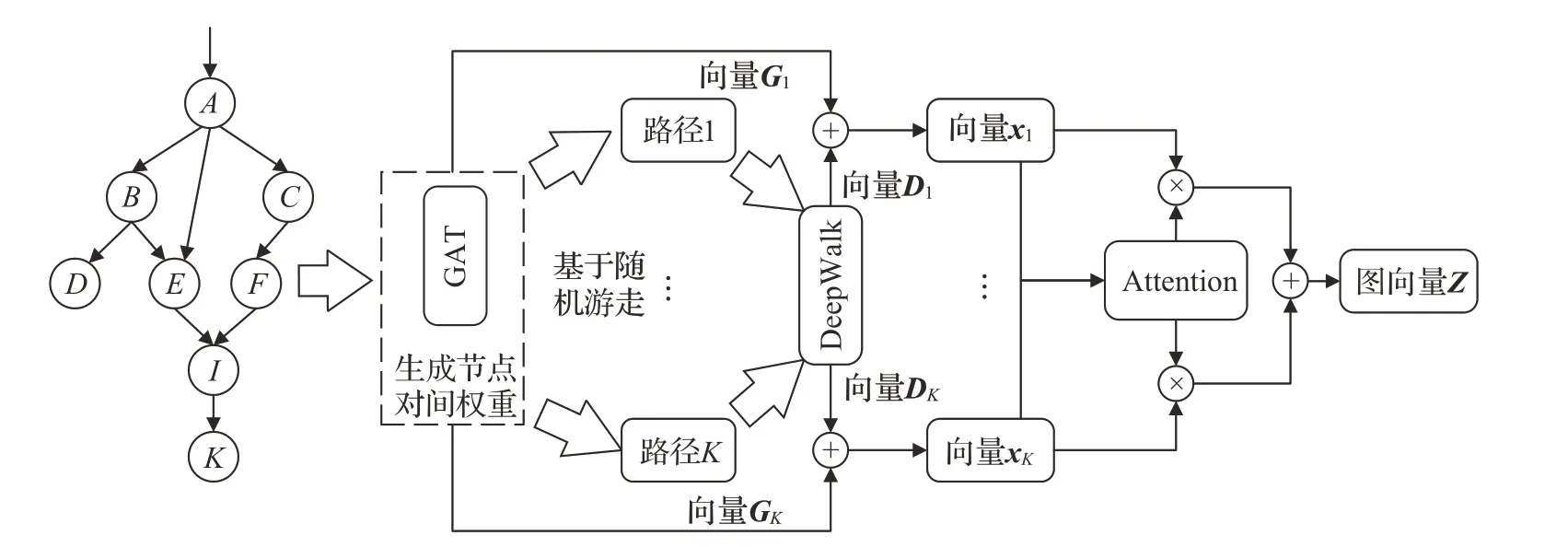
图2 基于注意力机制的图嵌入模型Fig.2 Graph embedding model based on attention mechanism
在进行运算之前,需明确图的输入。给定一个图G=(V,E),其中V为图中节点集合,E代表图中所有边,可以对每个节点采用一个D维的特征向量表示。为了使得节点特征参与运算,需提取出图中节点的特征表示。数据流图中节点主要由AG、BP、NBF、LG、LT等不同运算类型组成,图3(a)中不同类型节点具有不同的属性,图3(b)则表示由不同的节点属性所组成的图,且采用one-hot编码。

图3 图输入示例Fig.3 Figure input example
2.2.2 GAT网络模块
在获得图的输入形式后,就可以通过GAT 图注意力网络获得节点对间的注意力权重。注意力权重需同时考虑两个节点的影响,那么其表达公式如下所示:
其中,公式(1)中显示节点j对节点i的影响,hi和hj分别代表节点i和j的特征表示,W为投影矩阵,用于对节点进行特征维度的变换,||表示向量拼接操作,在这个过程中特征向量进行了可学习的线性映射。
公式(2)中LeakyReLU为激活函数,使公式(1)中得到的向量映射为一个标量,最后使用公式(3)中的softmax进行归一化操作,其中Ni为节点i的所有邻居节点。公式(4)利用归一化后的注意力权重,计算与邻居节点特征的加权平均,从而优化当前节点的特征向量。后续GAT中将以公式(3)和公式(4)不断优化注意力权重系数与特征向量。
2.2.3 图嵌入网络模块
获得权重系数后,本文采用基于随机游走的deepwalk 进行图嵌入,在进行随机游走时采用AliasTable 方法。本文的数据流图为有向数据流图,采用C_Table 列表存储每个节点的子节点,那么游走的节点就从子节点中进行随机选取,最终组成多条路径,并生成节点的嵌入向量。
如图4中所示,为AliasTable转移策略。假设有A、B、C、D四个转移节点,把转移概率想象成等长度的线段,并且根据可转移节点想象成N份,那么优化时采取多缺少补的策略逐步转化为图4(b)所示的等长度转移表。为使得选取过程更快,AliasTable 方法用1 表示转移表的长度,随机选择一个[0,1]的随机数random,以图4(b)为例,若0<random<1/6就选择节点A转移,1/6<random<1/4就选择节点B转移。经过随机游走后将产生的多条路径输入到deepwalk 图嵌入网络中将生成K条特征向量。

图4 AliasTable转移策略Fig.4 AliasTable migration policy
2.2.4 注意力机制模块
由上述GAT网络模块与图嵌入模块分别得到节点特征向量Gi、Di,为充分利用从不同方面得到的向量,则利用公式(5)进行相加得到最终向量xi,但由于不同的向量对整张图的影响是不同的,因此需求得向量xi对应的权重,则这K向量的权重可由下式得到:
公式(6)中b为偏置向量,W为权重矩阵,为注意力向量,计算过后将得到该向量的注意力分数。那么为与其他进行比较,公式(7)用softmax进行归一化的操作,显然当计算出的αi越大时,该向量对整张图的影响越大,最后如公式(8)利用αi计算出图特征向量Z。最后采用余弦相似度度量代码片段之间的相似值[20-22],并进行分类。
2.3 数据流图优化
在代码识别并替代后得到的数据流图,还存在着冗余节点及节点并行度不足的缺点[23],其中冗余节点增加了数据流图的长度,节点并行度决定着运算的性能。密码算法代码中可能存在函数,在进行语义分析时函数体与主代码是分别进行分析的,因此为保证密码算法数据流图的完整,需用函数数据流图替换对应的函数节点,获得完整数据流图后。本节采用函数展开、冗余节点消除与数据流图分层的顺序对数据流图进行优化。
2.3.1 函数展开
对密码算法代码进行分析可能会得到多个数据流图,分别为主代码和函数体生成,而函数在主代码数据流图Graph中为一个运算节点,因此为得到完整的数据流图,需将函数代表的运算填补到该函数节点,即函数展开方式。函数展开是用相应的数据流图替代函数节点,并不会影响函数体数据流图内的连接关系,关键是主代码中函数节点的源操作数、目的操作数如何替代函数体的参数与返回值,并建立运算节点间的连接关系。
图5(a)展示了函数在代码中的使用方式,即可将返回值直接赋值,也可直接参与运算。进行函数展开主要包括如下三个方面:

图5 函数展开方式Fig.5 Function expansion
(1)构造函数操作数、参数连接关系
将函数节点分为两个赋值节点,两节点间为函数体。具体过程如图5(b)所示,将源操作数与函数体参数构成赋值语句A1;函数节点为运算节点,直接将返回值替代函数参与运算,构成语句A2。
(2)消除编号、变量名冲突
对函数体数据流图中的节点标志Tag 进行重新编号,同时若定义的变量名存在于主代码中需重新构造,这是为避免编号值、变量名重复,造成数据流图混乱。
(3)构造A1、A2 父子节点
根据原函数节点的父子节点,重新构造A1 与其父节点,A2 与其子节点的连接关系,展开后主代码数据流图填补完整。
2.3.2 冗余节点消除
目前数据流图Graph 中还存在着许多不影响运算结果的节点,也就是冗余节点。冗余节点主要是由赋值语句,及可计算的运算语句构成的。运算语句目的操作数可经由计算得到值,赋值语句作为中转节点,连接不同运算节点。冗余节点的两种形式如图6所示。
为简化数据流图Graph,需消除冗余节点。对于图6(a)运算冗余,由于其可计算性,依据循环变量值进行计算得到目的值,并替换此次循环内部所有目的值,如图6所示“keys[index-1]”,若当前s为0可得目的值index为4,替换后可得“keys[3]”,经由简化后不仅去除了冗余节点,还优化了循环内部运算。
对于循环中的赋值语句冗余节点如图6(b)中所示,r是由tmp2 进行赋值的,因此r可用tmp2 代替。那么为消除循环内的赋值语句,可构建其父节点与子节点两者间的连接,以简化数据流图。
2.3.3 数据流图分层
本文为提取数据流图间节点的并行性,设计了数据流图分层算法。如下所示为数据流图分层的伪代码,算法利用数据流图Graph作为输入,以分层后的数据流图Graph_Level为输出。
若节点中源操作数为外部输入,数据流图生成的Graph不考虑其连接关系。若父节点为空即运算数据都为外部输入,则为无前驱节点。本文算法以无前驱节点作为并行的依据,将无前驱的节点作为一层,此后删除该层节点与其子节点的连接关系,从剩余的节点中选择新的无前驱节点作为一层,直到数据流图为空。
3 实验与分析
为验证可重构密码处理器编译前端的有效性,将从词法、语法、语法分析器功能测试,以及数据流图生成与优化两大部分进行测试。本文使用C++在VSCODE 平台上编写代码,并基于QT 图形用户界面开发框架综合所研究内容,设计一款CRCLA 前端测试平台。本节选取典型的密码算法在测试平台上进行中间格式生成实验,实验运行环境为Intel Core i5-6300HQ@ 2.30 GHz内存。
3.1 分析器功能测试
词法分析器对输入的密码算法源代码进行分析,得到所有字符串对应的标识,语法分析器依据语法规则识别出字符串间的关系,通过语义分析提取出关键信息。使用测试用例在软件平台上进行词法、语法分析测试,所得结果如图7所示。从图中可知,分析器将输入的词素流,转换成对应的标识,并依据语法规则生成语法树,经过比对语法树与对应的语句完全对应。

图7 词法、语法分析结果Fig.7 Results of lexical and grammatical analysis
通过对测试结果的分析,可以发现字符流可以被正确识别,如图中左侧的for 循环,其循环变量“s”与循环值“9”在右图中被正确识别为变量ID与整数INT。循环内部的第一条运算语句其目的操作数“Msg”、等号“=”被正确识别为ID、ASSIGNOP。该测试表明无论是循环、运算语句都能识别正确。
对于语法树结构,可以看到按照语法规则识别从标志Statement 开始,以SEMI 结束,中间为语句中提取出的关键信息,相邻两行不对齐表父子节点,对齐为兄弟节点。分析结果显示提取出了用例中的所有关键信息,语法树结构正确。
将图7中的语法树作为识别对象,根据语法树结构编写语义分析器,目的是从中提取出语句的关键信息,如运算操作符、函数名,以及源操作数、目的操作数等,并组成操作表。操作表可为后面数据流图的生成提供必要信息,语义分析后得到的操作表如图8所示。

图8 语义分析结果Fig.8 Semantic analysis results
图8 中的操作表与图7 左侧的for 循环对比对可以看到循环已被展开,且图8 中的每条操作存储着操作符、变量名及数组位置。经过比对可发现操作表中操作的顺序及其存储信息存放正确,接下来可依据该操作表进行数据流图的生成与优化。
3.2 数据流图生成与优化测试
从操作表与测试用例对比中可以看到循环已被展开,那么以存储正确的操作表为输入,接下来可进行数据流图的生成与优化,根据本文设计的数据流图生成算法得到数据流图Graph。
如图9(a)所示测试采用DES加密密码算法中的单次循环,经过数据流图生成后将会得到如图9(b)所示的数据流图Graph,Graph中的元素包括节点标志、父母节点、子节点与运算类型FU,从数据中可以分析出节点间的连接关系。与测试用例进行比对,数据流图生成正确。

图9 数据流图生成流程Fig.9 Data flow chart generation process
3.2.1 代码检测实验与分析
为研究本文基于注意力的图嵌入模型对代码识别的效果,本文将其与deepwalk、GAT 网络在同样的实验条件下进行对比,并进行分析。实验使用BigClone-Bench代码克隆数据集,从中提取出克隆代码片段及克隆对的类别,并且将提取出的数据以8∶2的比例分割为训练集和测试集,在进行测试前先对相应的代码片段预处理,生成数据流图。接着对数据集进行标注,功能相似的标注为1,反之为0。测试结果为相似功能测试,从同功能测试数据集中抽取5个代码对,进行排列组合后生成10 组测试用例,并送入上述3 个模型中进行测试,测试结果如表1所示。
从表中可以看出本文提出的代码检测模型,对同种类代码检测的相似度都在80%以上,高于单独deepwalk、GAT 网络的检测结果。deepwalk 采取随机游走的策略虽然可以尽可能地探知上下文结构,但是代码中存在许多不重要的节点,从而产生了许多不必要的噪声影响结果,在GAT 网络中,当前节点聚合了邻居节点的特征,但只能获得相邻的一阶邻居,而无法影响过长的N阶邻居节点,影响了对整体结构特征的聚合。
本文的基于注意力的图嵌入模型,结合了两者的特点,首先提取出当前节点对其邻居节点的注意力权重,并在图嵌入网络中以此注意力权重构建有价值的节点序列,从而生成节点特征向量,最后聚合了GAT和图嵌入的特征向量能够充分代表当前代码片段的特征,模型较高的识别相似度有利于功能分类的正确性。
为测试对功能进行分类性能,将与deepwalk、node2vec、GAT经典算法进行分类性能的比较实验。实验中采取10折交叉验证(10-fold cross validation,10-CV)来对分类性能的准确率(Precision)、召回率(Recall)、F1等结果进行全面评估,具体的计算公式如下所示:
公式中TP为真值与预测值为正值1;FP为真值为假值0,预测值为正值1;FN为真值为1,预测值为0;TN为真值与预测都为0;公式(9)针对预测结果而言,预测正例的样本中有多少是真正正例的;公式(10)针对原来样本而言,代表正例有多少被预测成功了;F1 为考虑Precision与Recall影响的运算结果。最终的实验结果如表2所示。

表2 分类性能对比Table 2 Classification performance comparison
从表中可以看出,本文的方法取得了较好的分类性能,在Precision、Recall、F1 三个指标均取得了性能的提升,以上实验结果表示本文提出的模型可以很好地提取出节点之间的隐含关系特征,很大程度提升了功能分类预测的效果。
3.2.2 数据流图优化测试
在数据流图初始生成后,会存在各种缺陷,若不进行优化,会对后续的映射产生各种不利影响,因此需对生成后的数据流图进行相应优化。数据流图首先展开函数节点,消除冗余节点,最后采用数据流图分层算法进行并行化,具体的优化过程如图10所示。
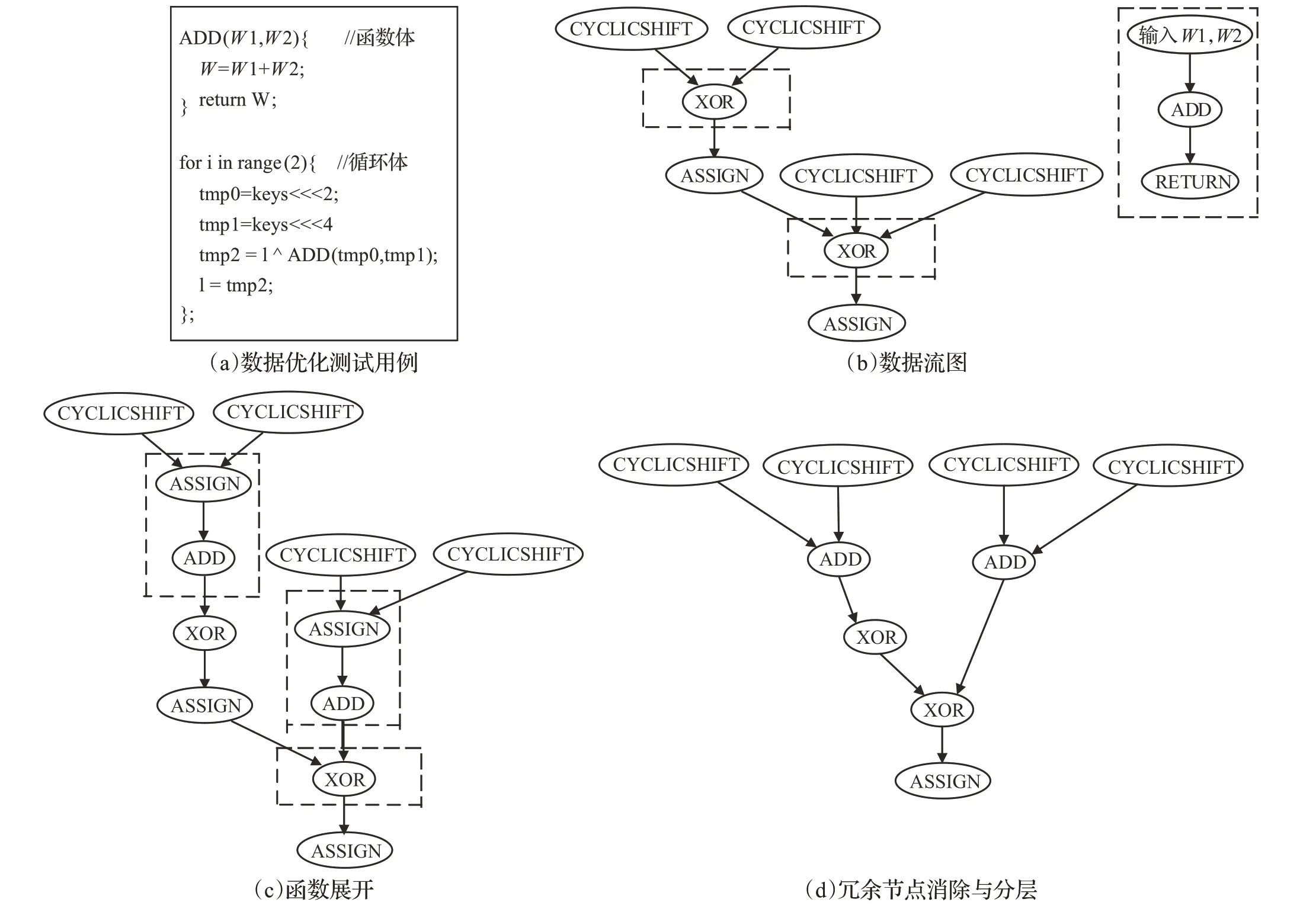
图10 数据流图优化流程Fig.10 Data flow diagram optimization process
如图10(a)所示采用包含函数和循环的一段代码作为测试用例,将循环体展开,经数据流图生成后可得到图10(b)所示的数据流图,虚线框中包含有可展开的函数节点,与函数体对应的数据流图。经函数展开后得到图10(c)所示的数据流图,虚线框中为展开后的函数节点,框中ASSIGN 节点为函数参数赋值语句,在测试用例中对应的为“W1,W2=tmp0,tmp1”,函数体的返回参数W直接参与运算。
由于数据流图中的ASSIGN语句为冗余节点,进行优化可缩减数据流图的规模,同时为提取出节点间的并行性,采用数据流图分层算法进行分层,运行后可得到图10(d)所示的数据流图。经数据流图优化过后,不仅提取出节点间的并行性,还精简了数据流图,并且数据流图与测试用例相对应。
3.3 性能测试
为检验本文提出的CRCLA 编译前端的优势,本节从优化后的数据流图长度,以及最终映射在CRCLA 上的密码算法执行性能上进行对比。如表3所示,在处理相同的以高级语言C++编写的密码算法代码时,以前面介绍的面向可重构结构的编译器REmus、Spatial、TIRAMISU 与面向众核结构的TAP-S 编译器作为比较对象,本文生成的DFG长度只占其他编译器的十分之一左右。

表3 不同密码算法下的DFG长度Table 3 Length of DFG under different password algorithms
这是因为在实际编写密码算法程序的过程中,高级语言C++可以不同方式实现密码算法中的特殊函数运算如S盒、比特置换,但这些特殊功能在本文的CRCLA中可用单算子进行实现。其他编译器没有对此进行相应优化,在对源代码进行分析时依然采用原有的数据结构,而本文的编译器采取代码识别的方法对特殊功能结构进行识别并替代,因此其他编译器获得的DFG 长度远大于本文。
此外,本文取得的数据流图由于将特殊功能结构进行替换,从而避免了大量非必要的运算节点映射在CRCLA 中。因此在面对特殊功能如S 盒等,本文用单条运算映射,而其他编译器则需用一串运算节点进行映射。在这种情况下,本文映射密码算法到CRCLA上时,CRCLA 可用更少的计算步骤与时间进行运行,从而提高了映射性能。
为精确展示本文前端的有效性,以其他编译器前端分析产生的数据流图作为输入,将其映射到本文的CRCLA 硬件上进行仿真测试,最终得到的执行性能如表4所示。相比于其他编译器,本文前端获得的数据流图在CRCLA上执行的性能平均提高了约37%。
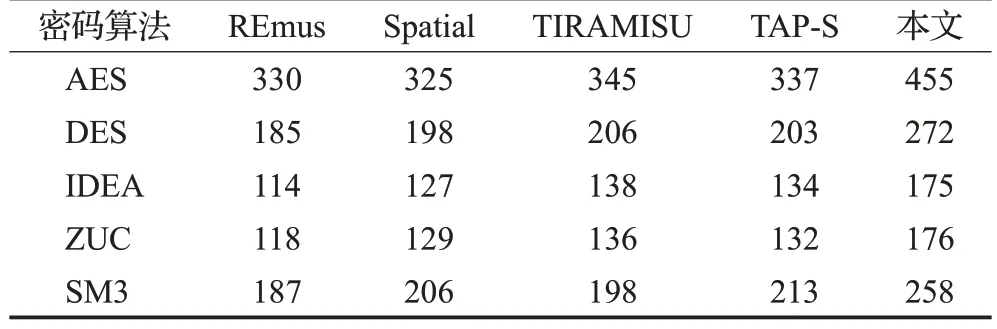
表4 不同密码算法下的映射性能对比Table 4 Comparison of mapping performance under different password algorithms 单位:Mbit/s
4 结束语
本文针对粗粒度可重构密码逻辑阵列,设计了一款自动化编译前端工具。该前端设计包含词法、语法、语义分析器,可提取出源代码中的关键信息并生成数据流图。利用基于注意力机制的图嵌入模型识别图结构,并用同功能的算子进行替换,解决如S 盒替换函数在CRCLA中可用单算子代替实现的问题。最终使用内联替换、冗余移除、数据流图分层算法等技术解决数据流图并行度不足与过长问题。该编译前端具有自动化生成适用于CRCLA 的数据流图,为可重构密码逻辑阵列的使用提供强有力的支持。实验结果验证了该编译前端工具自动化与高性能的优点。
猜你喜欢
新世纪智能(语文备考)(2020年4期)2020-07-25
汽车维修与保养(2020年11期)2020-06-09
铁道通信信号(2020年7期)2020-02-06
电脑与电信(2018年12期)2018-03-23
西北工业大学学报(2015年3期)2015-12-14
中国卫生(2014年7期)2014-11-10
组合机床与自动化加工技术(2014年10期)2014-03-01
语文知识(2014年4期)2014-02-28
单片机与嵌入式系统应用(2010年2期)2010-07-02
小雪花·初中高分作文(2009年8期)2009-11-16
