
无人机视角下基于深度学习的多目标跟踪研究进展
2023-12-11 07:11宋品德钟春来曹立佳
计算机工程与应用 2023年23期
杨 洋,宋品德,钟春来,曹立佳
1.四川轻化工大学 自动化与信息工程学院,四川 宜宾 644000
2.四川轻化工大学 计算机科学与工程学院,四川 宜宾 644000
3.人工智能四川省重点实验室,四川 宜宾 644000
4.企业信息化与物联网测控技术四川省高校重点实验室,四川 宜宾 644000
基于深度学习的多目标跟踪(multi-object tracking,MOT)作为计算机视觉与遥感领域的重要课题,在智慧城市、农业生产、灾害预警以及地质探勘等领域有着广泛应用[1-3]。随着无人机(unmanned aerial vehicle,UAV)技术的快速发展,无人机已被广泛应用于灾后搜救、农业生产及军事打击等各个方面[4-5]。得益于优秀的网络模型设计和硬件性能的提升,使得无人机平台有望能够完成空对地多目标跟踪任务[6-7]。然而,与普通视角下相比,无人机视角下的多目标跟踪(multi-object tracking from the UAV perspective,UAV-MOT)仍然面临着诸多挑战。这些挑战主要包括目标尺度的变化、相似目标的干扰、目标被遮挡、目标分布不均匀、目标运动的非线性、相机抖动以及实时性等。由于无人机运动和目标移动,目标在机载相机的成像平面上的尺度会频繁变化导致跟踪失败。无人机视角下目标尺度较小,使得能够提取的特征较少,相似目标(如穿着相同颜色衣服的行人、同一样式的车辆等)会导致频繁的身份切换,使得跟踪系统生成较多碎片轨迹。无人机飞行高度较高,虽然增大了信息获取能力,但也会将更多建筑物、树木等背景元素纳于成像平面中,使得跟踪环境更加复杂。在这种复杂动态环境中,目标与目标之间存在相互遮挡,背景元素同样会遮挡目标,导致跟踪失败。以无人机视角下的城市交通为例,成像平面中所有的目标集中在道路及其两侧,使得遮挡发生更为频繁,导致跟踪失败。由于无人机和目标之间存在较强的运动耦合,即成像平面上目标的运动实际上是机载相机的运动与目标运动叠加的结果,使得以假设目标线性运动为主的普通视角下的多目标跟踪算法难以适用于UAV-MOT 任务。例如无人机跟踪正在移动的目标时,若目标与无人机同向且同速度移动,目标在机载相机的成像平面上的坐标将不会变化;若目标与无人机运动方向相反,目标在机载相机的成像平面上的坐标将出现较大变化,这些情况均会使得目标运动非线性,导致轨迹难以预测。由于无人机飞行环境复杂,在飞行过程中容易受到各种干扰,如惯性测量单元(inertial measurement unit,IMU)等传感器误差导致飞行不稳定、强风等外部干扰导致的晃动和机架的结构设计和装配缺陷导致无法自稳等,使得机载相机抖动,导致成像平面中同一目标在相邻帧出现较大位移,最终跟踪失败。无人机因为自身载荷限制,无法搭载较大算力的设备,使得基于深度学习的MOT算法,无法满足无人机多目标跟踪系统的实时性。这些问题受到学术界和工业界的广泛关注,也成为了大量研究的热点[8-9]。
作为计算机视觉领域的重要问题,多目标跟踪在其发展过程中经历了从传统方法阶段到基于深度学习的不断演进。在传统方法中,需要通过手工设计特征来实现多目标跟踪,这不仅过程繁琐,还效率低下[10]。此外,传统方法在应对目标尺度变化、相似目标干扰、目标被遮挡等复杂场景时表现不佳,难以实现准确和鲁棒的多目标跟踪。然而,随着深度学习技术的发展,特别是卷积神经网络(convolutional neural network,CNN)的兴起,基于深度学习的多目标跟踪方法逐渐崭露头角。基于深度学习的多目标跟踪方法使用CNN来提取目标的视觉特征,然后利用这些特征进行多目标跟踪。这种方法可以更好地适应不同场景下的目标变化,并且在复杂环境中表现出更好的鲁棒性。目前,基于深度学习的多目标跟踪方法已成为多目标跟踪的主流框架,基于深度学习的MOT 方法分为基于检测的跟踪(tracking by detection,TBD)和联合检测的跟踪(joint detection tracking,JDT)。TBD算法采用了多阶段设计结构,将检测与跟踪模块分离,使得这两个模块可以单独进行优化。然而,这种设计可能导致不能得到最优解。相比之下,JDT 算法融合了检测模块与跟踪模块,虽然提高了推理速度,在简单场景下优于TBD算法,但在复杂场景下表现不佳。
文献[11]提出了基于TBD设计模式的SORT(simple online and realtime tracking)算法,其利用FRCNN(faster region CNN)进行目标检测,设计了一种基于卡尔曼滤波器(Kalman filter,KF)和匈牙利算法的实时跟踪器,并利用相邻帧边界框的IoU(intersection over union)距离处理目标的短期遮挡,其匹配速度非常快,但是无法解决目标长时间遮挡和相似目标干扰等问题,而导致对同一个目标生成大量ID(identity)切换。文献[12]在SORT 的基础上提出了DeepSORT 算法,其引入ReID(re-identification)网络提取的外观特征,对目标进行深度关联度量,匹配策略上同时考虑了运动信息和外观特征,有效降低了被跟踪目标的ID切换,与SORT相比,身份切换数量减少了45%。文献[13]提出MOTDT 框架,利用R-FCN 对观测框进行进一步的前景和背景分类,使用KF完成目标的运动估计;将观测框和跟踪框合并,并做NMS(non-maximum suppression)操作,以修正其中每个目标框的置信度;先基于ReID相似度进行匹配,再对剩余的利用IoU 进行关联。文献[14]提出了基于DeepSORT 的MF-SORT 算法,在数据关联中引入目标的运动特征,能够有效且高效地跟踪静态摄像机中的物体。文献[15]提出Bot-SORT 算法,使用全局运动补偿(global motion compensation,GMC)技术将相机运动补偿引入跟踪器以解决相机抖动带来的干扰,通过融合IoU 距离矩阵和余弦距离矩阵作为新的匹配方法。文献[16]提出了ByteTrack算法,为解决低检测得分而不能跟踪的问题,将每个检测框根据得分分成两类,高分框和低分框进行两次匹配。文献[17]提出了StrongSORT,针对检测缺失和关联缺失的问题,提出了高斯平滑插值算法(Gaussian smoothed interpolation algorithm,GSI),使用高斯过程回归算法来修复插值边界框,用于解决检测缺失的问题;提出了一种外观无关的链接模型(appearance free link model,AFLink),仅利用时空信息来预测两个输入轨迹是否属于同一个目标,用于解决关联缺失的问题。文献[18]提出了OC-SORT,针对高帧率放大了使用KF进行状态估计时的噪声和目标被遮挡而导致状态估计的噪声随着KF更新阶段没有可用观测值而不断累积的问题,设计了以观察为中心的重新更新(observation-centric re-update,ORU)和以观察为中心的动量(observation-centric momentum,OCM),使用目标状态观察来减少目标重识别后的累积噪声。SORT方法在处理目标重识别时存在困难。当目标在跟踪过程中发生遮挡或目标外观发生变化时,其很难准确识别是否为同一个目标。DeepSORT 通过引入ReID 网络提高了目标重识别能力,但是随着跟踪目标数量的增加,ReID网络的推理速度降低,会严重影响系统实时性。而且在高密度目标场景中,DeepSORT还会面临相似目标ID冲突和目标重叠的问题。MOTDT 通过从检测框和跟踪框中共同生成候选框来解决检测不可靠的问题。MFSORT 在面临机载相机抖动时表现不佳。Bot-SORT 通过结合运动和外观信息,并引入相机运动补偿,提高了跟踪系统鲁棒性,但与DeepSORT一样面临实时性较低的问题。ByteTrack虽然提高了低检测得分目标的跟踪准确性,但面临遮挡时无法保证跟踪鲁棒性。StrongSORT具有较强的跟踪鲁棒性,但是其实时性较低。其有良好的关联丢失回复能力,但是无法处理错误关联。OC-SORT使用ORU和OCM提高了跟踪系统的实时性和鲁棒性,但仍存在目标关联错误的问题。
文献[19]提出了一种基于JDT设计模式的ConvNet架构,通过改进的R-FCN(region-based fully convolutional network)检测网络,在传统目标检测的分类和回归任务上增加了一个跟踪分支。这样的设计使得模型能够同时进行目标检测和目标跟踪,将跟踪任务转化为预测相邻两帧各目标位置相对偏移量的回归任务。文献[20]提出Tracktor++算法,其检测部分不仅仅用于前景和背景的进一步分类,还利用回归对目标进行了进一步修正。算法核心在于利用跟踪框和观测框代替原有的RPN(region proposal network)模块,从而得到真正的观测框,最后利用数据关联实现跟踪框和观测框的匹配。文献[21]提出了FFT(flow fuse tracker)算法,其基于Tracktor++的框架,直接增加一个光流预测分支,将Tracktor++中的跟踪框和观测框,变成了光流预测框和观测框。文献[22]基于Tracktor++框架,将FrRCNN 换成CenterNet 提出了CenterTrack,除了对相邻两帧利用CenterNet进行检测之外,预测同时存在于两帧中目标的相对位移,由此进行跟踪预测。文献[23]提出了FairMOT算法,通过两个平行的分支来预测像素级的目标得分和ReID特征。这种任务之间的公平性设计使得FairMOT在多目标检测和跟踪任务中都能获得高水平的精度。ConvNet 存在数据依赖性和计算复杂度高的问题。其性能高度依赖于大规模标注的数据集,但目前应用于无人机视角下的多目标跟踪数据集较少。其使用深度神经网络同时进行检测和跟踪任务,使得网络计算复杂,推理速度慢,无法满足跟踪系统实时性。Tracktor++在目标被遮挡和目标尺度变化时具有较强鲁棒性,但仍然存在检测器性能影响跟踪性能的问题,而且其模型难以训练。FFT避免了ReID网络,提高了系统实时性,但由于引入光流,无法用于运动的相机。CenterTrack具有较高的跟踪准确性和实时性,但面临目标被遮挡时表现不佳。FairMOT在一定程度上改善了计算复杂度,但仍存在对环境中的背景杂波和相似目标敏感的问题,这会导致跟踪器性能下降。
近年来,国内多目标跟踪研究进展迅速。文献[24]针对跟踪过程出现的轨迹漏检、误检及身份切换等问题,将vision transformer(ViT)引入到YOLO(you only look once)X 的骨干网络,增强网络的局部特征提取能力,并采用BYTE 数据关联方法和非线性卡尔曼滤波。该算法提高跟踪算法的实时性和鲁棒性,但仍存在目标重识别能力弱的问题。文献[25]针对JDT 模式中检测器性能影响跟踪系统性能的局限,基于标签多伯努利(labeled multi-bernoulli,LMB)滤波设计了目标重识别方法,并对算法采用并行计算提高运行效率。该算法能够在短时间内维持标签的不变性,减少碎片化轨迹及标签跳变数,提高跟踪鲁棒性,但仍存在较多相似目标干扰下算法表现不佳的问题。文献[26]基于CNN 和Transformer,提出一种基于CNN-Transformer双分支主干网络进行特征提取和融合的多目标跟踪算法CTMOT(CNNtransformer multi object tracking)。该算法在跟踪的实时性和准确性上达到了较好的平衡,但仍存在数据关联阶段设计简单,导致ID错误匹配的问题。本文总结了近来基于深度学习的MOT技术发展路线,如图1所示。

图1 2016—2023基于深度学习的MOT发展路线Fig.1 2016—2023 MOT development route based on deep learning
在无人机视角下的对地多目标跟踪中,大多数研究采用了TBD 的设计模式。本文以TBD 模式为主要框架,首先,阐述并分析了基于目标特征建模、基于目标轨迹预测和基于SOT 辅助等多目标跟踪算法。这些算法可帮助在无人机视角下实现更准确和鲁棒的多目标跟踪。其次,总结了无人机视角下的多目标跟踪性能指标、相关数据集和应用。这些信息对评估和比较不同算法的性能以及实际应用中的选择具有重要意义。最后,分析了当前无人机视角下多目标跟踪所面临的挑战和未来发展方向,希望能够为该领域的进一步发展提供有益的参考和指导。
1 无人机视角下的多目标跟踪算法进展
1.1 基于目标特征建模的UAV-MOT
通过目标的外观特征实现多目标跟踪是一种常见的方法。该方法利用相似性准则,可以在相邻帧中找到最相似的目标,从而实现目标的连续跟踪。在多目标跟踪过程中,目标可能会由于遮挡等原因导致检测丢失。为了解决这个问题,可以利用ReID 网络,对目标的ID进行恢复,从而实现目标的重识别。通过重识别,系统能够将目标在不同帧中的观测进行关联,确保目标的连续性和正确性。这种基于目标外观特征的多目标跟踪方法在很多场景下表现出较好的鲁棒性和准确性。不过需要注意的是,目标的外观特征提取和重识别过程,随着目标的增多会增加计算负担,尤其在大规模多目标场景中。因此,在实际应用中,需要根据具体场景和系统要求进行权衡和优化,以实现高效且准确的多目标跟踪。
文献[27]针对目标尺度变化导致外观模型质量下降,从而影响跟踪精度的问题,基于空间和时间正则化来对两个相邻帧之间的残差进行建模的方法,提出了残差感知相关滤波器,同时设计了一种尺度细化策略。该算法增强了尺度估计的准确性,提高了跟踪精度,但是仍存在对遮挡敏感的问题。文献[28]针对目标外观变化以及背景杂波、相似目标等复杂场景,导致跟踪漂移甚至失败的问题,设计了目标滤波器和全局滤波器,采用双回归策略,提出了双回归相关滤波方法。该算法增强了目标特征学习能力,但增加了计算量,降低了系统实时性。文献[29]为了提高跟踪器的判别能力,将上下文注意力、维度注意力和时空注意力,集成到基于相关滤波器的训练和检测阶段。该算法通过使用上下文注意力来考虑目标与其周围目标的关系,使用维度注意力来选择与目标跟踪相关的特征维度,并使用时空注意力来捕获目标的运动轨迹,增强了跟踪系统的鲁棒性,但仍然存在无法处理的目标尺度剧烈变化的问题。文献[30]针对空间边界效应会显著降低判别相关滤波器学习性能的问题,通过联合稀疏特征学习来有效处理边界效应,同时抑制背景像素和噪声的影响,提出了一种增强鲁棒空间特征选择和相关滤波器学习的方法。该算法提高了滤波器学习性能,能够显著抑制背景像素和噪声的影响,但仍然存在学习阶段收敛速度慢的问题。文献[31]针在对弱光照和黑暗环境中,跟踪鲁棒性较差,甚至跟踪失败的问题,提出了一种基于判别相关滤波器的算法,该算法具有光照自适应和抗暗能力。该算法提高了弱光环境下的跟踪鲁棒性。文献[32]为了提高跟踪实时性,提出基于哈希集匹配算法(HashSet matching algorithm,HSMA)的多目标跟踪算法。该算法结合了HOG(histogram of oriented gradients)和光流特征进行目标跟踪,进一步提高了实时处理速度,但仍然存在跟踪精度低的问题。
文献[33]针对遮挡导致跟踪失败的问题,提出了一种硬软注意网络来提高ReID性能并获得不同目标的鲁棒外观特征。该网络包含姿势引导硬注意(pose-guided hard attention,PHA)模块和区域软注意(regional soft attention,RSA)模块,并使用基于密度的空间聚类算法(density-based spatial clustering algorithm,DSCAN)对行人进行分组。该算法有效解决了由于遮挡导致的跟踪失败,但仍存在实时性较低的问题。文献[34]为了提高特征提取能力,设计了一个基于图神经网络的重新识别网络,其使用中心点外观特征以加强整体特征提取能力,并且在训练过程中加入了基于类别的三元组损失,以提高中心点外观特征的辨别能力。该算法提高目标的ReID 性能,但仍存在视野边缘跟踪差的问题。文献[35]针对外观和运动特征在现有方法中是单独使用或通过权重融合,而不能适应复杂环境的问题,提出了一种融合外观相似性和运动一致性的自平衡方法。文献[36]设计了一种新颖的相似性度量,将位置、外观和大小信息结合在一起,提出了PAS-Tracker算法,并利用相机运动补偿模型来对齐跨帧的跟踪位置。上述两种算法在复杂环境中具有较强的跟踪鲁棒性,但仍存在动态权重策略设计复杂和权重设计没有通用性的问题。文献[37]针对无人机视角下捕获的目标体积通常很小,目标的外观信息并不总是可靠的问题,使用基于边界的四元组和深度网络来跟踪拥挤环境中的目标。应用深度四元组网络(deep quadruplet network,DQN)来跟踪从拥挤环境中检测的目标的移动,并对其进行建模以利用新的四元组损失函数来研究特征空间,该算法在拥挤环境中能够有效跟踪目标的移动,但仍存在由于神经网络设计简单,特征提取较少导致跟踪丢失的问题。文献[38]提出一种基于YOLOv5和DeepSORT的无人机多目标跟踪算法。此算法引入了时空注意力模块的残差网络作为特征提取网络,以加强网络感知微小外观特征及抗干扰的能力,最后采用三元组损失函数加强神经网络分辨类内差异的能力。该算法加强了网络感知微小外观特征及抗干扰的能力,但仍存在无法满足实时性的问题。文献[39]针对目标外观变化、遮挡等问题,提出了一种具有空间特征和视觉特征的堆叠双向前向长短期记忆网络(stacked bidirectional-forward long short term memory,SBF-LSTM)跟踪器用于对象跟踪,并基于边界框距离、外观和大小度量来处理对象关联,有效减少了对象身份切换,从而提高了跟踪精度,但仍存在网络推理速度较慢,无法满足实时性的问题。文献[40]为解决无人机视场中拍摄场景复杂、目标特征不明显造成相似物易混淆、跟踪性能下降的问题,提出了一种基于门限卷积孪生网络的无人机对地目标跟踪方法,其以SiameseFC(fully-convolutional siamese network)作为基础网络,在目标特征提取阶段,引入上下文门限卷积以修改方形卷积核的权重,增强网络对全局上下文的关注能力,突出目标本身的特征,提升网络模型的鲁棒性。文献[41]提出了一种时间特征聚合跟踪算法来解决图像特征提取过程中由于微小目标而导致的特征信息不足的问题。上述两种算法提升了跟踪鲁棒性,但仍存在无法处理目标被遮挡的问题。文献[42]为提高目标分类性能,基于Siamese 神经网络,设计了一种用于UAV-MOT的方法。该算法解决了训练阶段正、负样本之间的数据不平衡问题,但仍存在无法处理相似目标的问题。文献[43]针对无人机应用场景复杂,运动目标分辨率低,目标特征提取和识别难度大的问题,采用多尺度学习、残差块及注意力机制等方法提出了名为倒置瓶颈聚合网络的重识别网络。文献[44]针对UAV 视角下目标严重的尺度变化导致跟踪失败的问题,提出了一种基于Siamese的无模型尺度感知跟踪器。文献[45]针对重识别精度低的问题,设计了一个ReID head,其结合了非局部块和Transformer层来探索全局语义关系。上述三种算法增强了尺度变化中的特征处理能力,提高跟踪系统的准确度,但仍存在实时性较低或无法实时的问题。表1对无人机视角下基于特征的多目标跟踪进行了分析总结。
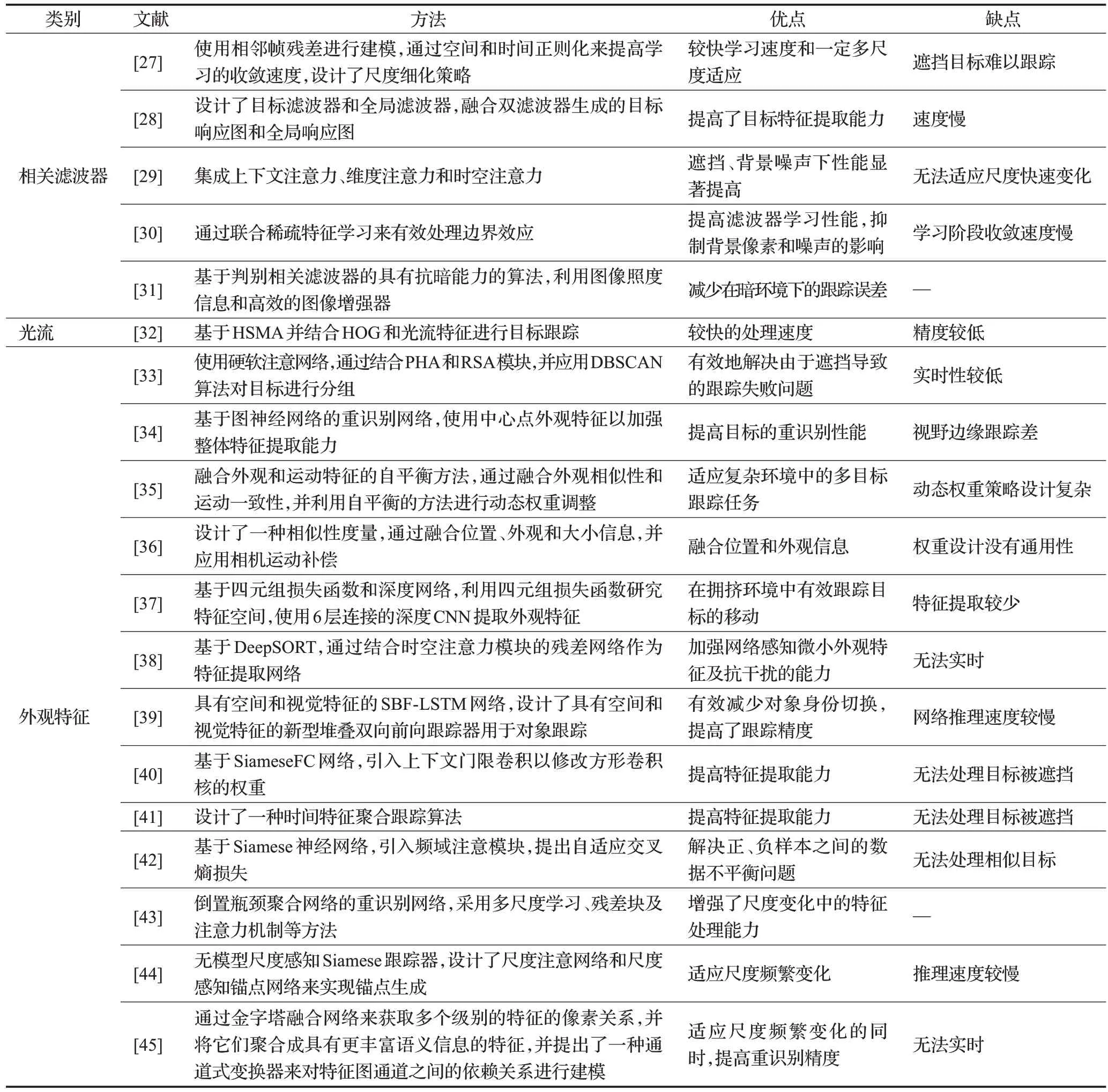
表1 基于特征的UAV-MOT算法总结Table 1 Summary of feature-based UAV-MOT algorithms
基于相关滤波器和光流的UAV-MOT 算法具有实时性高的优点以及通过历史观测来预测目标的未来状态,从而实现对跟踪轨迹的平滑性,有助于提高跟踪稳定性。然而,由于存在特征学习能力较低以及有限全局上下文的问题,该类算法无法处理尺度变化频繁、遮挡等场景。其次,相关滤波方法通常依赖于目标的运动模型,当目标的运动模式变化时,跟踪性能可能受到影响。再次,目标丢失或重新获得时可能需要一些时间来适应新的观测信息,这可能导致跟踪的中断或不稳定。相关研究通过提高特征提取能力、提高尺度适应能力以及增强上下文信息关联能力等,以克服这些限制。
基于外观特征的UAV-MOT算法具有判别类表示、对光照变化的鲁棒性以及有效的处理遮挡和重新识别的能力。通常不依赖于目标运动模型,因此适用于各种不同的目标运动模式和场景。然而,受数据集限制,泛化能力差、对环境变化的敏感、处理尺度变化困难以及高维特征空间等问题,该类算法无法处理未学习过的新目标、无法适应尺度变化影响外观特征以及实时性差等。特别是在具有较多相似目标场景和目标剧烈运动或发生较大外观变化时,会出现跟踪失败的情况。相关研究通过融合外观与运动特征、设计更有效的ReID 网络以及提高尺度适应能力等,以克服这些限制。
1.2 基于目标轨迹预测的UAV-MOT
基于目标轨迹预测的方法一般使用卡尔曼滤波器,其中包含预测和更新两步。预测步骤使用状态模型估计目标在下一帧中的位置,而更新步骤基于观测模型由当前观测值更新目标的位置。通过交替进行预测和更新,卡尔曼滤波器能够动态地预测目标的位置,并根据观测信息实时地更新目标的状态。这使得卡尔曼滤波器在许多实时目标跟踪应用中表现优秀。
文献[46]针对目标运动之间的相互作用引起遮挡的问题,提出了一种用于UAV 视角下多目标跟踪的四阶段层次关联框架,结合了基于数据关联的跟踪方法和使用压缩跟踪方法的目标跟踪,以有效地处理局部轨迹生成、局部轨迹构建、全局漂移轨迹校正和全局碎片轨迹链接,该算法减少了碎片轨迹生成,提高了轨迹预测鲁棒性,但仍存在多阶段设计难以计算最优解的问题。文献[47]针对无人机和跟踪目标存在相对运动,使得基于匀速运动模型的KF 无法有效跟踪的问题,提出了一种基于环境反馈的变速KF 算法。同时,对匹配过程进行了改进,通过引入了更多的环境信息和特征,该算法提高了目标和轨迹匹配的准确性和跟踪鲁棒性,但仍存在无法处理运动模糊的问题。文献[48]为了减少在真实环境下的轨迹预测噪声,提出了一种称为深度扩展卡尔曼滤波器(deep extended Kalman filter,DeepEKF)的运动学预测模型。该算法提高了跟踪的精度和稳定性,但仍存在由于网络复杂而无法实时的问题。文献[49]为了提高轨迹预测精度,使用LSTM作为跟踪位置预测器。该算法能够准确预测目标轨迹,但仍存在无法处理过多跟踪目标的问题。文献[50]针对机载相机移动导致的无人机视频中对象的不规则运动问题,提出了一种自适应运动滤波器用于复杂运动目标的跟踪。该算法提高了跟踪的准确性和鲁棒性,但仍存在设计的运动状态有限而没有通用性的问题。文献[51]提出一种基于运动模型的无人机对地视觉目标跟踪方法。该算法通过解耦目标与机载相机的运动,提高目标轨迹预测精度,但仍存在无法适应目标和无人机的快速运动的问题。文献[52]为了减少低质量检测对跟踪的影响,设计了名为G-Byte的数据关联方法,其保留所有检测框,并通过置信度将它们分为高分和低分框,使用噪声尺度自适应卡尔曼滤波器和广义交并集(generalized intersection over union,GIoU)度量来预测轨迹在新坐标系中的位置。该算法提高了低检测置信度目标的跟踪能力,但仍存在过多跟踪目标导致实时性降低的问题。文献[53]针对机载相机运动下的多目标跟踪存在目标位置漂移和状态预测失效等问题,提出了一种基于薄板样条函数的无人机多目标跟踪方法。该算法提高了轨迹预测精度和跟踪鲁棒性,但仍存在实时性低的问题。文献[54]针对无人机和目标高速运动导致运动模糊以及机载相机的全局运动与目标运动的运动耦合等问题,提出了一种用于无人机多目标跟踪的算法。该算法使用混合去模糊模块、特征匹配和非线性轨迹预测的方法,能够有效地处理无人机和目标高速运动引起的运动模糊和全局运动耦合问题,提高了目标检测和跟踪的准确性和鲁棒性,但仍存在特征设计复杂,通用性低的问题。表2 对无人机视角下基于目标轨迹预测的多目标跟踪进行了分析总结。
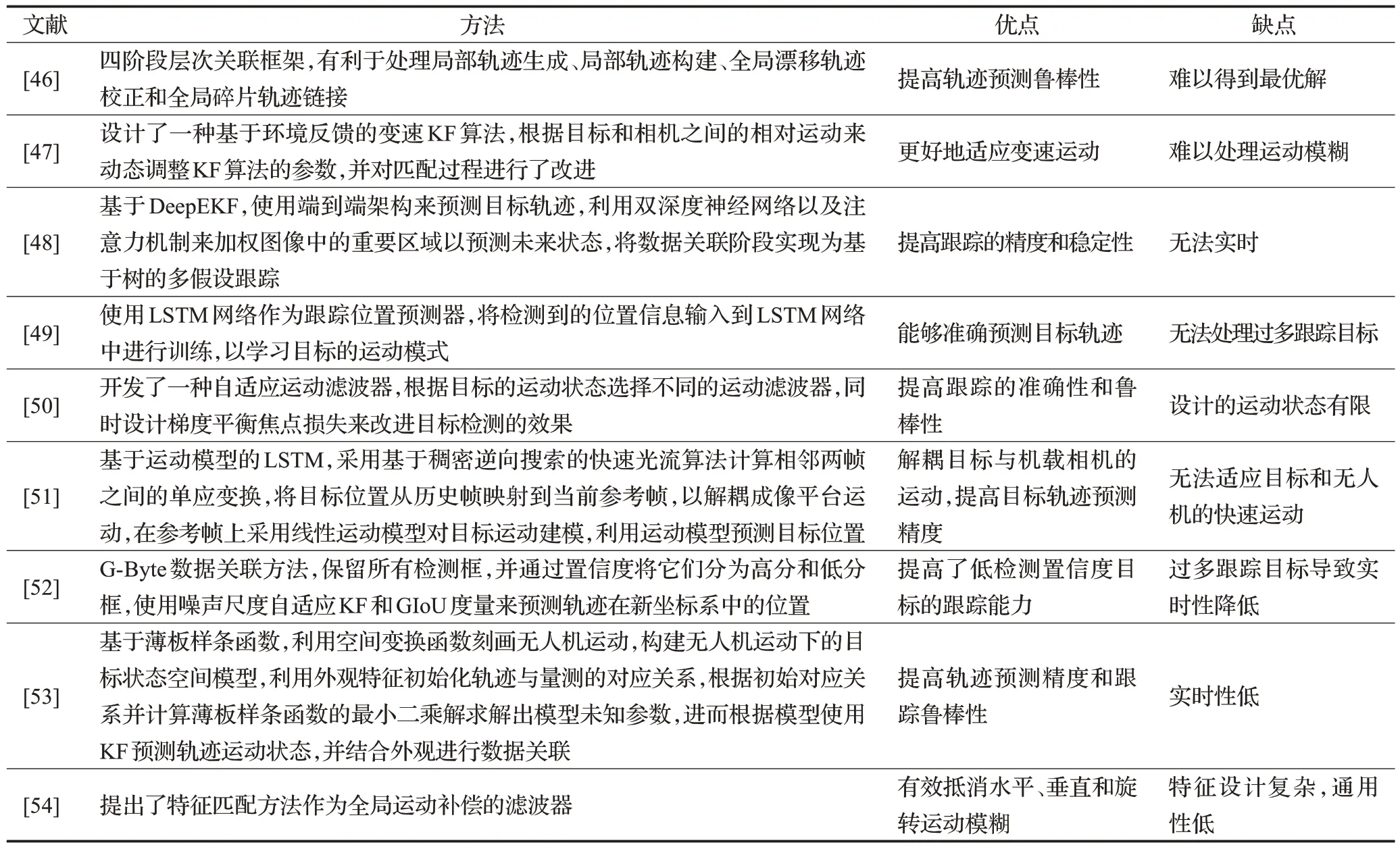
表2 基于目标轨迹预测的UAV-MOT算法总结Table 2 Summary of UAV-MOT algorithm based on target trajectory prediction
基于目标轨迹预测的UAV-MOT具有长时跟踪、适应目标动态变化、数据关联等方面具有显著优势。轨迹预测信息可以在目标关联阶段起到积极作用,帮助系统更好地将观测到的目标与已知轨迹进行关联,从而减少遮挡、交叉等情况带来的干扰。然而,由于存在预测噪声、计算复杂性以及运动模型不准确等问题,该类算法无法处理目标突然运动变化和大规模复杂场景。在复杂动态环境中,目标的运动可能会受到其他目标或障碍物的影响,这可能导致轨迹预测失效或不准确。而且,实现准确的目标轨迹预测通常需要设计复杂的运动模型,这会增加算法的复杂性和调试难度,同时,不同类型的目标可能需要不同的轨迹预测模型和参数设置。相关研究通过设计鲁棒性更高的自适应预测模型、更有效的数据关联机制等,以克服这些限制。
1.3 其他的无人机视角下多目标跟踪方法
除了上述的方法外,基于SOT辅助和基于JDT的方法同样也被应用于UAV-MOT。在UAV-MOT 中,可以借助单目标跟踪的技术来辅助多目标跟踪。通过先对单个目标进行跟踪,获取目标的位置和特征信息,再将这些信息应用于多目标跟踪中,有助于提高多目标跟踪的准确性和鲁棒性。JDT 算法将目标检测和多目标跟踪两个步骤合并为一个联合优化问题,从而在简单场景下可能优于传统的分离式方法。然而,在复杂场景下,JDT 算法可能无法适应目标的尺度变化和遮挡等问题。Transformer 是一种基于自注意力机制的神经网络结构,最初用于自然语言处理任务,但近年来在计算机视觉领域也取得了显著的成果。可以利用Transformer网络来建模目标之间的关系和上下文信息,从而增强多目标跟踪器的性能。
(1)基于SOT辅助的UAV-MOT
文献[55]针对在复杂环境下检测器工作性能受干扰而引入较大噪声的问题,将单个目标跟踪和数据关联方法集成在一个统一的框架中,提出了一种具有空间和时间注意机制的双重匹配注意网络(double match attention network,DMAN)的MOT 方法。该算法提高了遮挡发生时的跟踪鲁棒性,但仍存在随目标增多,实时性降低甚至无法保证实时性的问题。文献[56]针对机载相机快速移动的问题,提出了一种通过单应矩阵的二范数来定位帧的方法,在此基础上,设计了一种分层MOT 算法。该算法提高多目标跟踪的性能,但仍存在SOT 性能影响整体跟踪性能的问题。文献[57]针对传统的运动模型不可避免地受到无人机自主运动影响的问题,提出了一种基于条件生成对抗网络(generative adversarial network,GAN)的模型,用以预测无人机视角下的复杂运动。该算法能够较准确预测目标的运动轨迹,但仍存在模型难以训练的问题。
(2)基于JDT的UAV-MOT
JDT 框架迅速发展,受到了许多研究UAV-MOT 学者的重视,并得到了推广和应用。文献[58]针对无人机图像帧序列具有平台高速运动、视角旋转强烈的问题,提出一种基于粗匹配-精细匹配的双级旋转不变特征空间检测与并行特征提取跟踪的无人机对地目标图像帧序列自动快速目标检测与跟踪算法。该算法增强了无人机在高速运动、强烈视角旋转时的跟踪鲁棒性,但仍存在相似目标较多的场景表现不佳的问题。文献[59]针对UAV视角下目标尺度变化频繁且种类不平衡的问题,在将检测跟踪架构融合的同时,提出了一种分层深度高分辨率网络(hierarchical deep high-resolution network,HDHNet)。该算法提高了目标尺度频繁变化时的跟踪稳定性,但仍存在无法实时的问题。文献[60]为了提高推理速度,将目标检测和重新识别结合在一个统一的网络中,通过使两个子任务共享特征来显著减少计算开销,并提出了一种特征解耦网络(feature decoupling network,FDN)。该算法有效提高了模型推理速度,但仍存在不能处理碎片轨迹的问题。文献[61]使用深度聚合网络作为目标检测的骨干网络,并构建目标检测和特征提取的联合网络。提出了相机运动判别模型,并将图像配准应用于多目标跟踪,以解决在无人机视角下的复杂环境中目标跟踪的问题。该算法有效提高了跟踪实时性,但仍存在重识别效率低的问题。文献[62]为了充分利用时间信息决策,提高跟踪性能,基于FairMOT框架,构建了一个基于时序信息的特征增强结构。该算法提高了模型的训练效率,但仍存在时序信息特征设计复杂的问题。文献[63]基于Transformer提出了TransTrack算法,设计了基于注意力的查询密钥机制,将前一帧的对象特征应用为当前帧的查询,并引入一组学习的对象查询来检测新出现的对象。该算法简化了跟踪方法中复杂设计,但仍存在无法处理相似目标干扰的问题。文献[64]以基于窗口注意力的Swin Transformer结构作为骨干网络,提出了一种端到端的基于注意力机制的无人机对地多目标跟踪算法。该算法提升了跟踪系统的鲁棒性,但仍存在无法保证实时性的问题。文献[65]为了平衡跟踪器的速度与精度,将Transformer 结合Siamese 特征提取网络,提出了SiamTrans 算法,并提出跟踪漂移抑制策略(tracking drift suppression strategy,TDSS)来抑制相似目标的漂移。该算法框架简单,避免了传统跟踪中的超参数,而且提高了跟踪性能,但仍存在无法处理机载相机快速运动的问题。文献[66]针对UAV视角下由于尺寸变化、分辨率低、目标遮挡等场景导致跟踪目标框漂移的问题,提出一种基于Transformer的自适应更新的DUTrack算法。文献[67]针对夜间UAV难以进行跟踪的问题,提出了一种基于空间通道Transformer 的低光增强器。上述两种算法在复杂环境中具有较强的跟踪鲁棒性,但仍存在实时性低或无法保证实时性的问题。表3 对无人机视角下的其他多目标跟踪进行了分析总结。
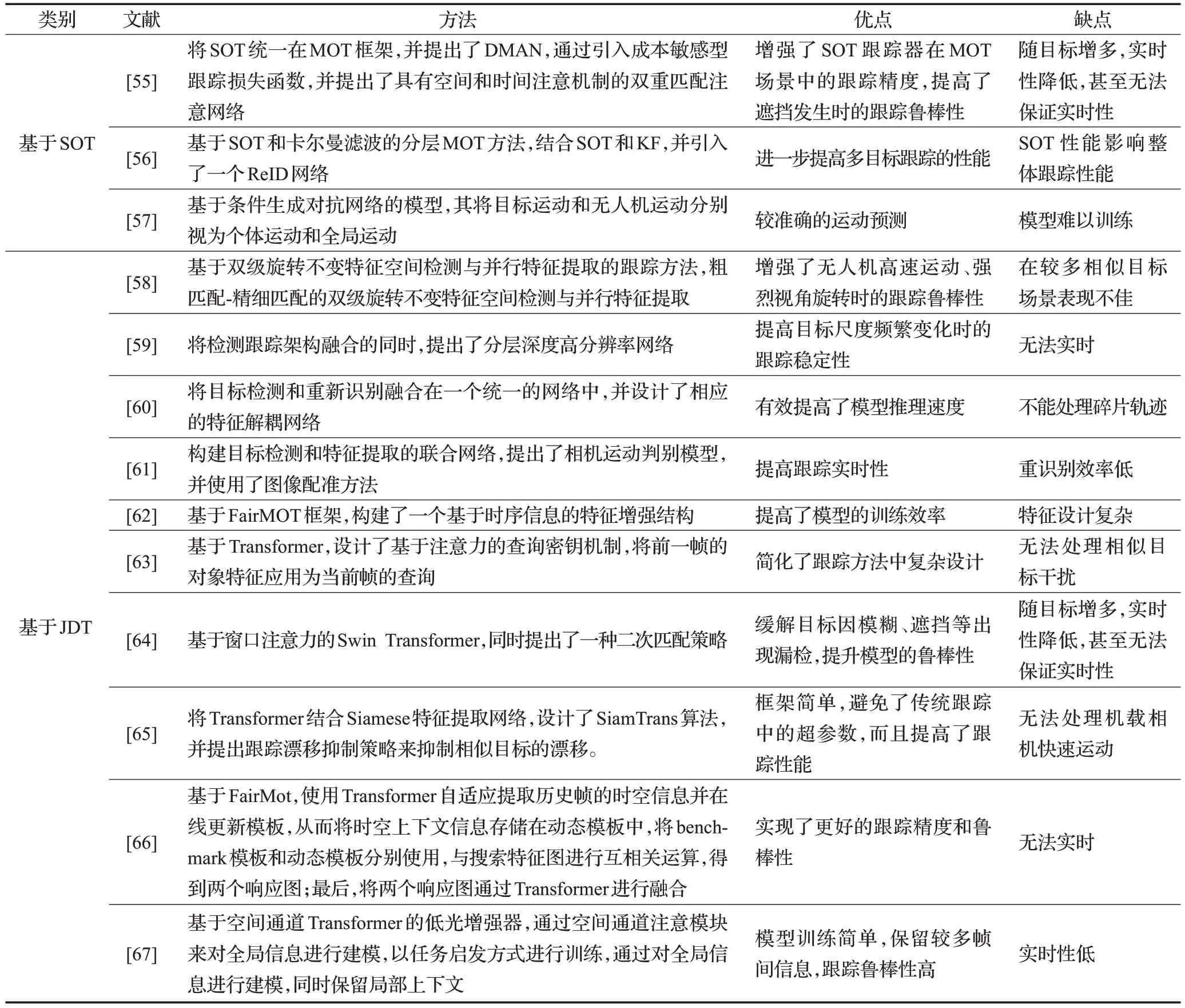
表3 其他的UAV-MOT算法总结Table 3 Summary of other UAV-MOT algorithms
基于SOT 辅助的UAV-MOT 具有鲁棒性高和适应动态环境方面具有优势。通过使用单目标跟踪,可以减少多目标跟踪阶段的计算复杂度,因为只需要在单目标跟踪的基础上对每个目标进行关联。同时,单目标跟踪可以提取目标的外观特征和运动特征,这些特征可以用于多目标关联和识别,提高多目标跟踪的性能。然而,由于存在有限的全局上下文、数据关联复杂性、SOT 性能影响MOT 的问题,该类算法无法适应大规模跟踪场景。特别是单目标跟踪的失败或错误可能会影响整体多目标跟踪的性能,因为多目标跟踪依赖于单目标跟踪的结果,同时也需要考虑计算开销和目标关联等问题。相关研究应平衡单目标跟踪辅助的优点和局限性,以克服这些限制。
基于JDT 的UAV-MOT 具有同时检测和跟踪、改进数据关联、目标轨迹的一致性和连续性、处理检测模糊性以及对动态场景的适应性方面具有优势。将目标检测和跟踪阶段融合在一起,可以在同一框架内处理目标的检测、初始化、跟踪和关联,简化了多目标跟踪的流程。由于融合了检测和跟踪信息,联合检测跟踪在目标关联阶段可能更加准确,能够更好地处理遮挡、交叉等复杂场景。然而,由于存在对检测错误的敏感性、可扩展性差等问题,该类算法无法处理目标运动剧烈变化和检测错误导致的累计误差。其次,受到底层目标检测算法的影响,如果目标检测算法性能较差,可能会影响整体跟踪性能。再次,JDT算法通常需要设计复杂的模型来融合检测和跟踪信息,这会增加算法的设计和调优难度。相关研究通过提高检测精度、引入图像配准、引入Transformr以及在检测网络中设计ReID分支等,以克服这些限制。
2 相关评价指标,数据集与应用
2.1 评价指标
MOT 的主要目的是找到正确的目标,并精确的估计目标在所有视频帧里的位置,为了保证在时间序列上,保持对目标跟踪的一致性应该为每个目标分配一个ID,并保持目标与ID在连续帧间正确关联。由于UAVMOT与MOT目的相同,因此UAV-MOT与MOT的评价指标一致,其应遵循以下设计标准。
(1)目标位置精度:确保跟踪器准确估计目标在每一帧中的位置,这是跟踪任务的关键指标之一。
(2)正确跟踪目标轨迹:每个目标只应该对应一条唯一的轨迹,避免出现轨迹重叠或分割的情况。目标轨迹的连续性对于跟踪任务的准确性和可靠性非常重要。
(3)减少目标ID切换:目标ID的频繁切换可能导致跟踪的不连续和混乱。因此,跟踪器应该尽量减少目标ID的切换,保持目标在不同帧中的稳定关联。
针对上述标准,文献[68]提出了MOTA与MOTP指标,用于评估跟踪的精度。文献[69]设计了IDF1、IDP及IDR 指标,用于评估目标ID 的鲁棒性。文献[70]基于MOTA 指标,使用相似系数设计了HOTA 指标,其将检测、关联和定位综合到统一的度量,同时也分解为数个子指标,以便分析跟踪器性能的不同组成部分。表4对比分析了各个指标的优缺点。

表4 主要评价指标优缺点分析Table 4 Analysis of advantages and disadvantages of evaluation indicators
MOTA指标用于评估跟踪准确度,受检测器精度影响较大,计算方法如式(1)所示:
其中,FN为漏检,FP为误检,ID_sw为ID的切换数量,GT是ground truth的数量,由式(1)看出其数值越大越好。
MOTP指标用于衡量跟踪位置误差,计算方法如式(2)所示:
其中,ct表示第t帧的匹配个数,匹配误差表示第t帧下目标与其配对假设位置之间的距离,由式(2)看出其数值越大越好。
IDP 指标为识别精度指每个边界框中目标ID 的识别精度,如式(3)所示,其中IDTP 表示真正的ID 数,IDFP表示假阳的ID数。
IDR指标是指每个边界框中目标ID识别的回召率,如式(4)所示,其中IDFN是假阴ID数。
IDF1指标是针对边界框中目标ID综合考虑IDP和IDR,其引入ID 信息,更加关注跟踪器减少同一个目标的ID变化,如式(5)所示:
HOTA 指标是高阶跟踪精度,建立在MOTA 基础上,将检测、关联和定位的效果平衡为一个统一指标,在阈值为α的情况下,如式(6)所示:
其中,Λ(c)如式(7)所示:
其中,TPA(c)表示对同一个目标,预测的ID 和ground truth的ID都为c;FNA(c)表示对同一个目标,预测的ID不为c,而ground truth 的ID 为c;FPA(c)表示对同一个目标,预测的ID为c,而ground truth的ID不为c。
HOTA 指标考虑了不同的阈值,即0.05,0.10,…,0.90,0.95,如式(8)所示:
综合来看,上述几种评价指标在评估无人机视角下的多目标跟踪算法时具有重要作用。由于每种指标仍然存在不足,为更全面地评估算法的性能,应将这几种指标一起使用。同时,针对具体的应用场景和目标特点,选择适合的性能评价指标非常重要。
2.2 数据集
对于深度学习而言,数据集有着不可缺少的重要性。文献[9]总结了2020 年以前主流的UAV 视角下的航拍数据集,如Stanford Drone数据集[71]、UAVDT(UAV detection and tracking)数据集[72]、VisDrone2018 数 据集[73]、VisDrone2019数据集[74]、BIRDSAI数据集[75]等。随着不断有学者将研究重点放在UAV-MOT上,无人机视角下的航拍数据集数量正在飞速增加。表5 统计了目前主流的用于无人机视角下多目标跟踪的数据集。
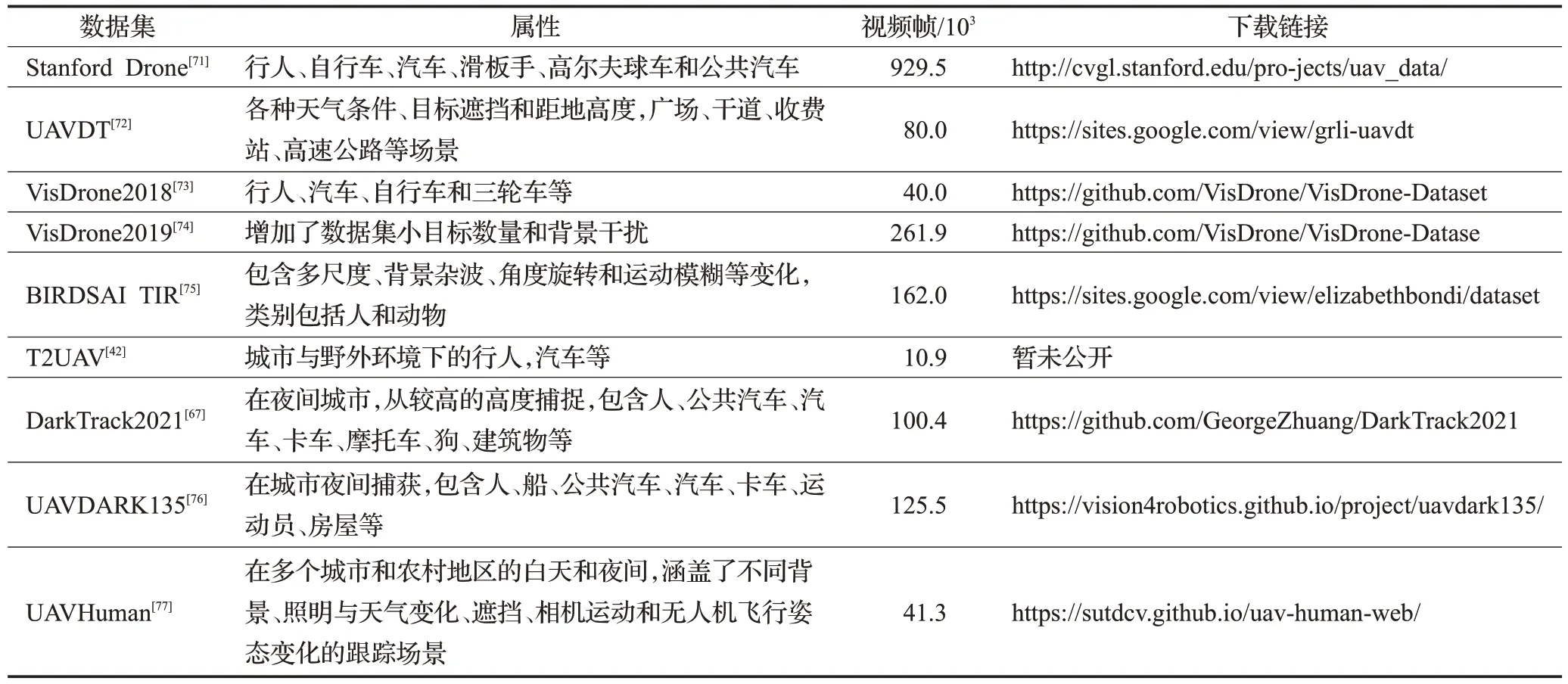
表5 主流的无人机视角下多目标跟踪数据集Table 5 Multi-target tracking dataset from mainstream UAV perspective
文献[41]提出了T2UAV数据集,使用无人机捕捉各种不同场景的视频数据,共收集了20 个视频序列。其中训练集包含15 个视频序列,测试集包含5 个视频序列,视频总帧数为10 912 帧,平均视频长度超过600帧。文献[67]提出了DarkTrack2021,在夜间城市中,从较高的高度捕捉,具有大量严重的光照变化和过度曝光/曝光不足的场景,其包含110 个具有挑战性的序列,总共100 377 帧。序列的最短、最长和平均长度分别为92、6 579和913帧。对象包含人、公共汽车、汽车、卡车、摩托车、狗、建筑物等,涵盖了现实世界无人机夜间跟踪任务的丰富场景。文献[76]针对夜间数据集缺失的问题,提出了UAVDARK135 数据集,其总共包含标准UAV夜间捕获的135个序列,并对其进行手工标注。该数据集包括各种跟踪场景,例如十字路口、丁字路口、道路、高速公路,并由不同类型的跟踪对象组成,如人、船、公共汽车、汽车、卡车、运动员、房屋等。该基准测试还包含一些来自YouTube 的在海上拍摄的序列。基准测试的总帧数、平均帧数、最大帧数和最小帧数分别为125 466、929、4 571 和216,适合大规模评估。文献[77]提出了UAVHuman数据集,专用于无人机视角下人类目标识别与跟踪,通过飞行无人机在多个城市和农村地区的白天和夜间在内进行收集,涵盖了不同背景、照明与天气变化、遮挡、相机运动和无人机飞行姿态变化的跟踪场景,其中包含67 428个多模态视频序列和119个用于动作识别的对象,22 476个用于姿势估计的帧,41 290个帧和1 144个用于人员重新识别的身份。
2.3 UAV-MOT的应用
文献[78]设计了基于特征补偿矩阵的跟踪算法,用于无人机视角下的海上多个船只跟踪。在保证实时性的情况下,具有良好的跟踪精度。文献[79]使用YOLO+JPDA 设计了一个实时检测与跟踪的系统,并将其部署到小型四旋翼无人机上,用于车辆交通监控。文献[80]设计了一个MOTHe(multi-object tracking in heterogeneous environments),用于野外环境下的动物跟踪。文献[81]设计了一个具有精确相机定位、快速图像处理和多模态信息融合能力的智能云台系统和用于多目标跟踪的自适应的多尺度目标特征模型,并将其部署在无人机平台,开发了基于UAV 的目标跟踪和识别系统。文献[82]使用YOLOv4+DeepSORT算法,设计了基于UAV的车辆检测与跟踪算法,并设计了车辆目标位置估计模型。文献[83]使用YOLOv5+DeepSORT算法,并将其部署在无人机平台,设计了一个实时的应用于无人机平台的目标跟踪系统。文献[84]针对无人机高度和视频分辨率的变化,设计了一种车辆速度从像素空间到现实世界的指数映射模型,通过将跟踪过程与车辆重识别算法相关联,从而将运动特征与车辆的深度特征相结合,降低了数据关联的错误率,提出了一种基于UAV 的车辆跟踪和速度估计系统。
3 当前挑战与未来研究展望
3.1 当前挑战
随着无人机技术与深度学习算法的快速发展,无人机视角下基于深度学习的多目标跟踪研究取得优秀的成果,但仍面临诸多挑战:
(1)机载视频噪声干扰:由于无人机的快速运动和拍摄环境的不确定性,机载视频中会存在大量的运动模糊和噪声。这些噪声和干扰可能降低目标检测和特征提取的准确性,对跟踪器的性能产生负面影响。
(2)目标运动状态和无人机飞行状态非线性:目标和无人机的快速运动可能引起非线性运动状态,使得目标跟踪变得更加复杂。这样的非线性运动可能导致跟踪器难以准确地预测目标的位置和运动轨迹。
(3)存在相似目标干扰:无人机视角下往往存在多个相似目标,如形状、颜色等相似,这会增加目标跟踪的难度。区分相似目标并正确地将其与相应的ID关联是一个具有挑战性的任务。
(4)目标存在遮挡的情况:在复杂环境下,目标很容易被背景环境或者其他目标遮挡,导致目标跟踪失败。解决遮挡问题对于提高跟踪的稳定性和鲁棒性至关重要。
(5)网络模型复杂,实时性差:神经网络虽然有较强的特征提取能力,但是其庞大的参数量和计算量给无人机搭载的小算力设备带来了存储和计算上的灾难,当前的UAV-MOT无法平衡跟踪的准确性和实时性。
(6)数据集稀少:由于无人机视角下环境复杂,数据集难以依靠自动标注获取准确的标注信息,而人工标注虽然准确,但人力成本过高导致用于跟踪的数据集较少,这限制了深度学习算法在该领域的发展。
3.2 未来研究展望
目前UAV视角下基于深度学习的多目标跟踪算法虽然发展迅速,但其跟踪效果良莠不齐,将普通视角下的优秀多目标跟踪算法用于无人机平台时,仍有不少改进之处。
(1)设计更有效的目标跨帧信息传播机制:不同于目标检测,多目标跟踪需要在帧间传递目标的信息,以适应目标在图像序列中的变化。开发有效的信息传播和更新策略可以降低噪声干扰,提高长时间多目标跟踪的能力。
(2)利用多传感器融合:在复杂的UAV 场景中,光学相机所提供的目标特征可能不足以应对各种挑战。利用多模态传感器(如深度相机、双目相机、激光雷达等)进行数据融合可以提高跟踪性能,特别是应对目标尺度变化等问题。
(3)设计鲁棒性更高的无人机与目标相对运动模型:准确的目标轨迹预测对于UAV-MOT的性能至关重要。改进运动模型,使其更加准确地预测目标在帧间的运动轨迹,有助于提高数据关联阶段的准确性和跟踪器的鲁棒性。
(4)设计多无人机视角下的多目标跟踪算法:在复杂动态环境下,利用多无人机协同可以弥补单无人机视角下的局部信息缺失和全局信息不完整的问题。多无人机协同能够提高跟踪性能,使系统具备更好的适应性和鲁棒性。
(5)设计轻量化的特征提取网络:在无人机平台上,轻量化的网络模型对于实时性至关重要。通过应用剪枝和重参等技术,降低网络模型的参数量和计算量,可以提高UAV-MOT的实时性,使其在资源受限的设备上也能发挥良好的性能。
(6)使用有限的标记数据进行学习:如前所述,由于无人机场景的复杂性,收集UAV-MOT的标记数据具有挑战性。未来的研究可以探索半监督或无监督学习的技术,以更好地利用有限的标记数据。还可以研究迁移学习和领域适应方法,以利用从其他相关数据集或模式中学习到的知识。
4 结束语
本文首先对普通视角下的经典多目标跟踪算法进行了梳理,这是为了建立无人机视角下多目标跟踪研究的基础。然后,以TBD框架为主,综合分析了无人机视角下的多目标跟踪领域的主要技术路线和最新方法。本文还介绍了该领域的性能评估方法和主流数据集,这对于评估无人机多目标跟踪算法的有效性和鲁棒性至关重要。本文分析了当前无人机视角下多目标跟踪面临的主要挑战,包括机载视频噪声干扰、目标运动状态和无人机飞行状态非线性、存在相似目标干扰、目标存在遮挡等问题。这些挑战突出了该领域的复杂性和难度,也为后续研究的方向提供了指导。最后,本文对未来无人机视角下的多目标跟踪研究趋势进行了展望,提出了有效的目标跨帧信息传播机制、多传感器融合、鲁棒运动模型、多无人机视角下的多目标跟踪、轻量化特征提取网络,以及有限的标记数据进行学习等改进方向,希望能提供有价值的参考。
猜你喜欢
高技术通讯(2021年3期)2021-06-09
读友·少年文学(清雅版)(2020年4期)2020-08-24
读友·少年文学(清雅版)(2020年3期)2020-07-24
农业机械学报(2020年2期)2020-03-09
中华建设(2019年7期)2019-08-27
现代装饰(2018年5期)2018-05-26
电测与仪表(2017年24期)2017-12-19
中国三峡(2017年2期)2017-06-09
北京航空航天大学学报(2017年12期)2017-04-23
项目管理技术(2016年12期)2016-06-15
