
深度学习在结肠息肉分割中的应用综述
2023-12-11 07:11孙福艳吕宗旺龚春艳
计算机工程与应用 2023年23期
孙福艳,王 琼,吕宗旺,龚春艳
1.河南工业大学 信息科学与工程学院,郑州 450001
2.中原智慧园区与智能建筑研究院,郑州 450001
结直肠癌(colorectal cancer,CRC)是世界三大高发癌症之一。2020 年,我国CRC 总体发病率已跃升至恶性肿瘤的第2 位,CRC 的死亡率也位居第5 位[1]。近70%~80%的CRC 起源于结肠息肉,早期筛查可以显著提高存活率[2]。CRC 早期筛查的黄金标准就是使用结肠镜检测,在内窥镜下检测并切除前驱病变(主要是腺瘤),可大大降低CRC 的发病率[3]。但人工结肠镜检查受限于操作者的状态及经验,平均有26%的息肉在视频检查中被漏检[4]。
使用计算机辅助诊断系统对结肠息肉进行精确分割,可以辅助临床医生定位息肉,提高结肠镜检查中息肉的检出率[5],对后续的息肉分类、治疗环节至关重要。但结肠镜采集到的息肉图像存在镜面高光、腔内褶皱及排泄物遮挡等情况,此外,息肉本身的大小、形状、颜色、纹理多变,与背景肠壁分界模糊,这些使得息肉分割非常具有挑战性。
本文首先总结传统息肉分割算法,分析传统的图像处理、机器学习分割算法的优缺点;接着总结基于深度学习的息肉分割算法,按照网络结构划分为基于经典CNN 结构、U-Net 结构及多模型融合的分割模型,归纳总结算法改进策略及其优劣势;然后归纳结肠息肉图像公开数据集及数据预处理方法;总结各方法在常用数据集上的评价指标结果;最后分析基于深度学习的息肉分割研究面临的挑战和发展趋势。
1 传统的结肠息肉分割算法
传统的息肉分割算法按照发展历程主要可以分为两类:基于图像处理技术、基于机器学习技术。
早期的图像处理技术根据分割方式不同将其划分为基于阈值[6]、边缘[7-8]、区域[7,9-10]、形态学[6]四种分割方法。基于阈值的方法将灰度图像中灰度值高于设定阈值的像素点视为前景区域(即息肉区域);基于边缘的方法针对图像的边缘像素特点分割息肉;基于区域的方法将图像分成多个区域,根据同一区域内颜色、纹理、形状等特征的相似性对区域进行判断;基于形态学的方法是分割前的预处理操作,腐蚀操作去除图像噪声,膨胀操作增强息肉边界。
机器学习技术更充分地利用提取到的颜色、纹理、形态外观等特征,通过支持向量机[11-12]、像素聚类[13]等方法自动学习特征并对特征进行分类。基于支持向量机的方法将特征映射到高维空间,以数学方法寻找一个决策边界将像素点分类为非息肉像素和息肉像素;基于像素聚类的方法将像素转换为向量形式,将具有相似性的像素点聚类成不同区域。
上述传统息肉分割算法的应用及对比分析如表1所示。传统的图像处理和机器学习方法过分依赖于手工提取特征,其局限性有以下几点:(1)息肉的形态多变,很难找到一个适合所有息肉的形状外观特征。(2)不同成像方式(白光和窄带光)下息肉的颜色、纹理差异较大,很难找到一个融合息肉多种特征的全局特征提取算法,导致在一组图像上表现良好的模型在另一组图像上表现不佳。(3)人工提取特征的算法复杂耗时,分割速度和精度都难以满足临床需求。

表1 传统息肉分割算法对比分析Table 1 Comparison of traditional polyp segmentation algorithms
2 基于深度学习的结肠息肉分割算法
近年来,深度学习被广泛应用于自然图像、医学图像分割等领域。相对于传统的息肉分割算法,深度学习模型在处理噪声、分割精度、处理速度、泛化能力等方面都具有优越性,可以应对不同采样环境下的图像及息肉形状多样性,模型鲁棒性强,自主学习特征和规律,极大地减少手工特征设计的工作量。基于深度学习的息肉分割算法流程图,如图1所示。
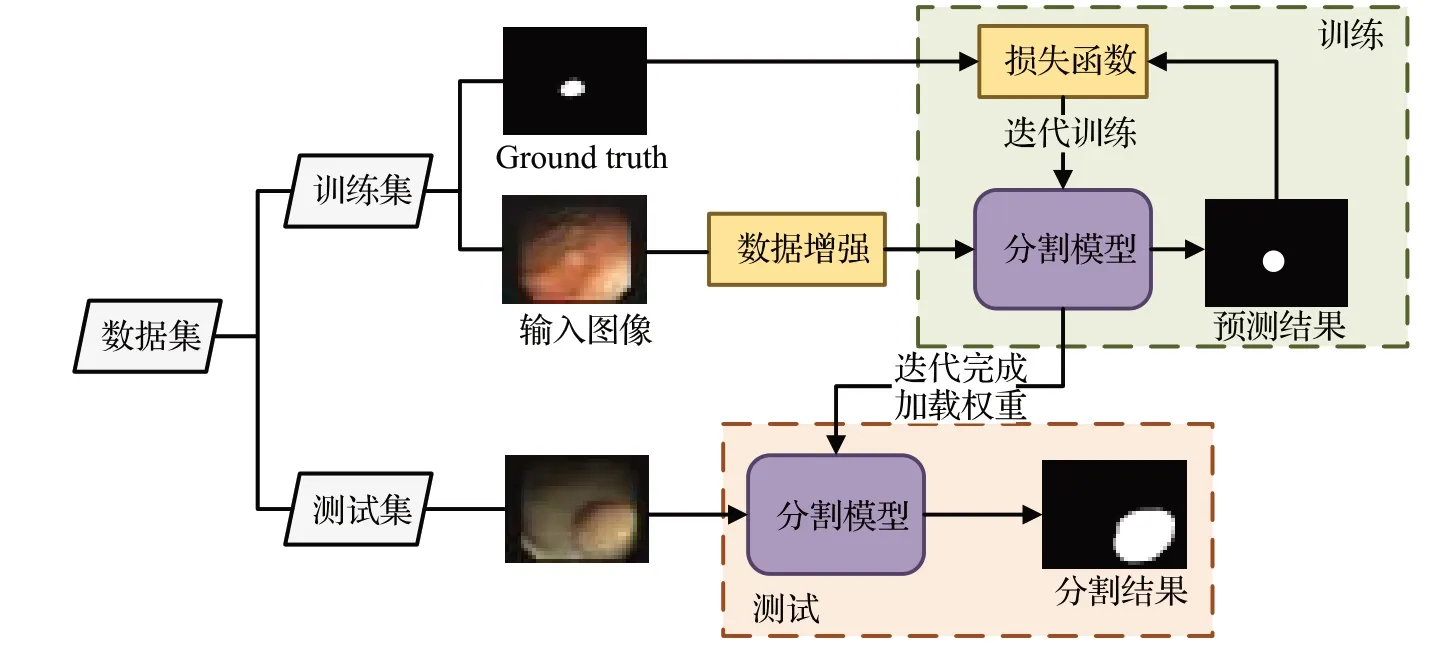
图1 基于深度学习的息肉分割算法流程图Fig.1 Flow chart of deep learning method for polyp segmentation
本章按照深度学习分割模型的网络结构将其划分为经典CNN 结构、U-Net 结构及多模型融合三类,总结其改进策略,并分析各改进策略的优势和局限性。
2.1 基于经典CNN结构的分割模型
2.1.1 基于FCN与传统特征的改进方法
CNN 网络[14]在图像级别的分类和回归任务中表现良好,全卷积神经网络(fully convolutional network,FCN)[15]继承CNN的思想,将CNN的全连接层替换为卷积层,采用反卷积层对最后一个卷积层的特征图进行上采样,在上采样的特征图中逐像素进行分类,达到在语义级别上分割息肉的效果。CNN与FCN网络结构如图2所示。
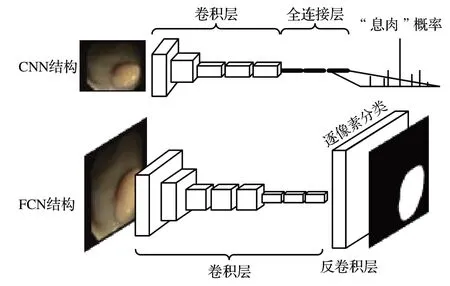
图2 CNN与FCN网络结构Fig.2 CNN and FCN network structure
文献[16]使用不同深度的网络进行息肉分割,实验结果表明相较于深层网络,浅层网络的分割结果更精确。这是由于浅层网络能够提取图像的细节信息,如颜色、纹理等特征,这些特征对于息肉分割具有重要意义;而深层网络更加专注于提取图像语义信息,如大小、位置等特征,同时随着网络层数加深,图像的边缘信息会严重丢失。
为了充分利用息肉的浅层细节特征,文献[17]将FCN-8S与Otsu阈值结合进行特征提取,并利用Ground truth 引导图像块选择进行数据增强。该方法能够更鲁棒地适应息肉形状和颜色强度的变化。同样文献[18]结合深度学习和手工提取的特征,采用FCN进行像素预测和初始息肉区域候选,从每个候选区域计算出texton特征,再利用随机森林分类器对候选区域进行细化,作出最终决策。该方法实现了分层学习息肉特征,accuracy达到97.54%。文献[19]将预训练模型和FCN 结合以缩短训练时间,之后又利用从阴影形状中导出的相对深度信息作为附加信息输入通道[20],提高分割准确率。
FCN在一定程度上实现像素级的分割效果,在自然图像分割中表现优秀。但连续的下采样和上采样操作丢失很多细节信息,导致分割结果边界模糊,因此在需要精确分割的医学图像中应用有限。
2.1.2 基于RNN的改进方法
循环神经网络(recurrent neural network,RNN)[21]与CNN 相比,拥有一个循环单元,用于处理序列数据,它保存前一时刻的信息并在当前时刻将其作为输入,因此RNN可以处理任意长度的序列数据。但是由于循环单元的参数共享,容易出现梯度消失、梯度爆炸和长期依赖的问题,长短期记忆网络(long short-term memory,LSTM)[22]则通过遗忘门将短期记忆和长期记忆结合起来,在一定程度上改善这些问题。文献[23]使用Deep-Labv3结合LSTM解决网络加深导致的息肉位置信息丢失问题,利用LSTM的记忆功能增强息肉位置信息。分割效果较DeepLabv3 模型有所提高,但训练时间较长。RNN在序列检测和自然语言处理等领域得到了广泛的应用,但应用于单帧息肉分割的相关研究较少,多用于视频息肉检测和分类领域。
2.1.3 基于GAN的改进方法
生成对抗网络(generative adversarial network,GAN)[24]是生成网络(G)和判别网络(D)的组合,两个网络仍采用CNN结构。GAN网络结构如图3所示。
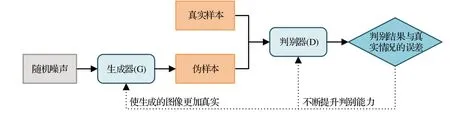
图3 生成对抗网络(GAN)结构Fig.3 Generative adversarial network(GAN)structure
文献[25]和文献[26]借助GAN 网络学习息肉特征生成伪样本,扩充息肉样本。G将随机噪声矢量作为输入生成息肉伪样本;D接收伪样本和真实样本并对其进行学习和判别。根据判别结果与真实情况之间的误差,D进行自身优化使判别结果更加准确;同时误差反馈给G 指导其优化更新,生成更加真实的伪样本;G 和D 之间进行迭代对抗训练直到达到纳什平衡。
文献[27]则是以原始息肉图像和分割掩码作为输入,学习标注区域的特征,G 生成的不是息肉伪样本而是预测分割掩码。为了稳定训练,将原始息肉图像与掩码(真实掩码和生成掩码)分别配对送入D,D对掩码的真实性进行判断。两个网络基于D 的判别结果以对抗方式更新迭代,迫使G 生成足够接近ground truth 的预测分割掩码来欺骗D,以使D将其分类为真实掩码。
GAN 在无监督和半监督领域取得了很好的效果,其生成的伪样本能够丰富数据多样性,增强模型鲁棒性。但模型训练过程不稳定,难以找到很好达到纳什平衡的方法。
表2 列举了CNN 结构息肉分割模型基于以上改进策略的其他文献,并对各改进策略的优势和局限性进行归纳总结[25-26,28-32]。
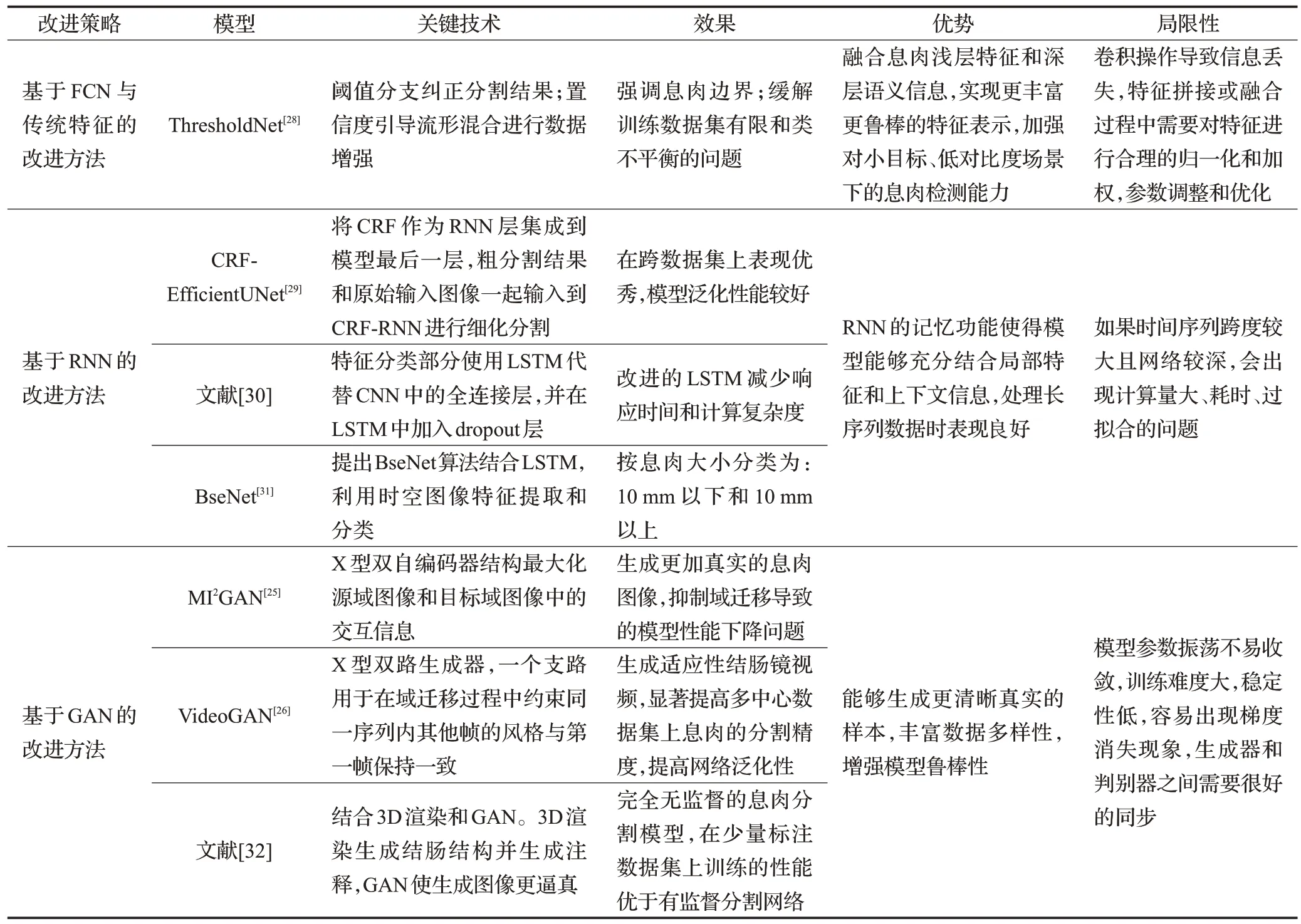
表2 CNN结构息肉分割模型的改进方法对比Table 2 Comparison of improved methods for CNN structural polyp segmentation models
2.2 基于U-Net结构的分割模型
2015年,U-Net[33]的提出为医学图像分割带来了革命性的改变,极大地推动了深度学习技术在医学图像分割中的应用。U-Net的编码器和解码器分别用于捕获上下文和恢复细节特征,同时利用跳跃连接增强浅层和深层特征的融合,模型可扩展性强;其采用的数据增强技术和Dropout等正则化方法使U-Net能够适应较小的训练集,因此在标注较少的医学图像数据集上表现优秀。
由于U-Net结构的分割高精确度和高可扩展性,衍生出一系列基于U-Net分割模型的改进方法,将改进方法概括为:基于扩张卷积、改进注意力、Transformer及多尺度特征融合的改进方法。
2.2.1 基于扩张卷积的改进方法
U-Net 中的卷积层感受野有限,虽然增大卷积核能够增大感受野,但同时也会增加模型参数量;此外下采样过程中图像分辨率降低导致信息丢失。针对这些问题,扩张卷积通过在标准卷积中插入“空洞”来增大感受野捕获更广泛的上下文信息,同时不增加参数量和模型复杂度,并保持特征图分辨率。
但通常很难找到一个合适大小的感受野来捕获不同尺度的息肉信息,文献[34]选择聚合不同扩张率的扩张卷积,其设计的深度扩张初始化模块(depth dilated inception,DDI)结构如图4所示。初始的逐点卷积加深输入特征图;在加深的特征图上并行连接多个扩张率指数倍递增的深度卷积,以从不同感受野中积累特征;在每个并行路径中顺序连接(3×1)和(1×3)的不对称内核深度卷积,这两个非对称卷积与(3×3)卷积核有相同大小的感受野,但前者参数少得多;最后级联聚合多个深度扩张卷积产生的并行输出,进行最终的逐点卷积。作者将多个DDI顺序连接集成到U-Net的层结构中,利用具有变化扩张率的扩张卷积实现了多样性的息肉特征提取。
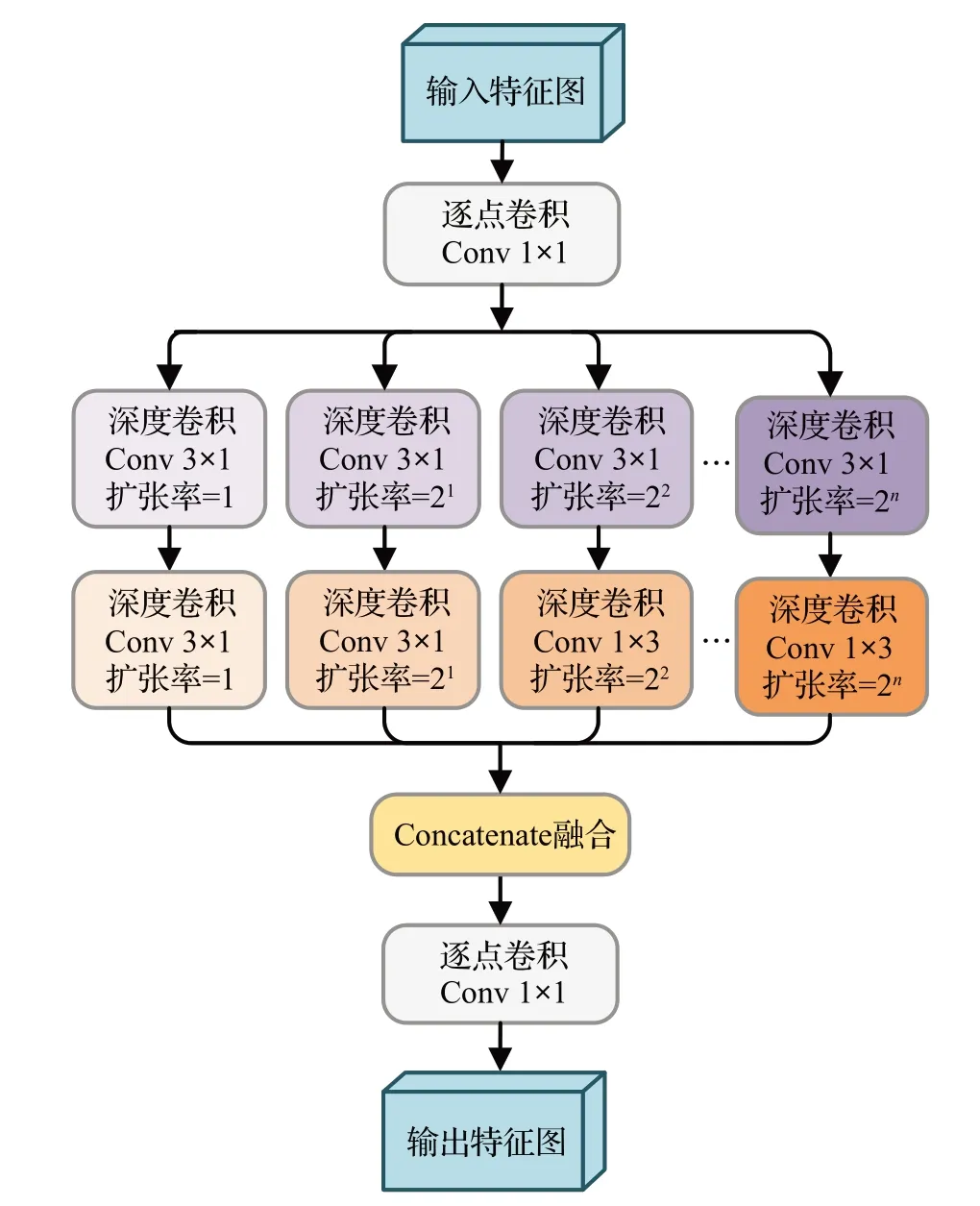
图4 深度扩张初始化(DDI)模块结构Fig.4 Depth dilated inception(DDI)module structure
文献[35]在编解码器之间使用空洞空间金字塔池化(atrous spatial pyramid pooling,ASPP),该模块同样通过组合不同扩张率卷积的方式处理不同尺度的息肉。但卷积核边缘部分穿插的“空洞”导致部分像素丢失,因此分割息肉边界较为模糊。
2.2.2 基于注意力的改进方法
虽然利用不同大小内核的卷积能够捕获多尺度息肉特征,但由于卷积的平等性,重要特征无法突出,注意力机制可以使模型更多地关注重要信息部分。文献[36]以DoubleU-Net 为基础架构,在U-Net 内部的跳跃连接处引入空间和通道注意力加强特征传递,同时在第二个编码器的输入端引入多尺度选择核心通道注意力模块,自适应地调节接收域大小,选择不同的感受野,提高小目标的分割精度。
文献[37]设计了浅层注意力模型,在深层特征的辅助下过滤掉浅层特征的噪声并保留小息肉,充分利用不同特征之间的互补性。为解决息肉边缘与背景肠壁分界模糊导致的分割结果边缘模糊问题,文献[38]提出不确定性增强上下文注意方法,将图像划分为前景、背景、不确定区域(息肉边界),增强息肉边缘信息;此外引入并行轴向注意力作为编码器主干解决计算量大的问题。考虑到息肉大小的变化对模型训练的影响(模型在大多数尺寸的息肉样本上表现优秀,但处理特殊大小的息肉时会提供次优结果),文献[39]提出了基于文本引导注意力的TGANet,在训练过程中以文本注意力的形式将息肉图像特征编码为{单个,多个,小,中,大},并为其分配不同的权重。该模型能够明显适应不同大小及多个息肉的情况,对临床诊断中重要的扁平和无蒂息肉提供了更高的分割精度。
注意力机制能够根据数据的不同情况自适应地调整网络权重,因此具有高可扩展性和鲁棒性。但注意力机制对输入数据的加权和筛选操作导致信息丢失和误判;此外大量的矩阵计算和映射操作增加网络复杂度。
2.2.3 基于Transformer的改进方法
文献[40]提出了第一个用于图像识别的基于自注意力的视觉Transformer(vision Transformer,ViT)框架,ViT 计算所有图像块之间的成对交互,生成上下文特征。这种上下文分析类似于U-Net中的上采样过程,不同之处在于U-Net 中卷积层感受野有限,需要通过池化、扩张等操作扩大感受野;而ViT无卷积层,通过多头注意力机制实现全局感受野。Transformer 编码器结构如图5所示。
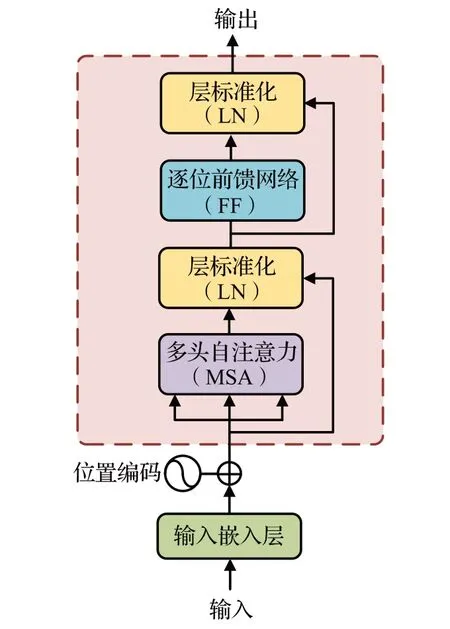
图5 Transformer编码器结构Fig.5 Transformer encoder structure
卷积运算的局限性限制了CNN 建模远程关系,尤其是当目标间纹理、形状和大小差异性较大时分割结果较差。Transformer 的全局感受野能够捕获远程相关性解决这一限制,但由于其在所有阶段进行全局上下文建模,导致在捕获细粒度细节方面有局限性。文献[41]结合两者的优势,提出了首个基于Transformer 的医学图像分割框架——TransUnet。该方法充分利用来自CNN特征的详细高分辨率空间信息和来自Transformer的全局上下文编码,浅层特征的密集融合提升了分割精度。
与TransUnet 以顺序方式堆叠CNN 与Transformer不同,文献[42]设计了一种融合技术——BiFusion模块,将CNN 与Transformer 以并行方式结合在一起,有效捕获浅层的空间特征和深层的语义上下文信息,且并行结构不需要非常深的网络,减轻了梯度消失和特征减少的问题,提高模型推理速度。但分割的息肉边界存在伪影,分割息肉内部不连续。
2.2.4 基于多尺度特征融合的改进方法
U-Net的跳跃连接结构弥补了深层特征和浅层特征之间存在的语义差距。为了更充分利用这些分层特征中包含的互补性语义信息,文献[43]在编码器中引入语义校准模块(semantic calibration module,SCM),利用深层的高级语义信息对浅层的特征图进行增强,通过解决语义错位问题使得两个相邻特征映射之间的语义更好地融合,从而有效地缓解了由于语义偏移而导致的息肉边界模糊和不可信的问题。此外,在解码器中引入语义细化模块(semantic refinement module,SRM),在解码器进行特征融合之前,根据全局上下文信息对特征图重新加权,可以同时增强目标和减弱背景,提高息肉与背景肠壁的特征区分度。提出的SCM 和SRM 弥补了不同层次特征图之间的语义鸿沟,从而充分利用这些特征的互补性来提高分割性能。
文献[44]设计了语义特征增强模块(semantic feature enhance module,SFEM),并重新设计解码器结构。SFEM使用三个并行分支对特定窗口大小的块分别应用非局部关注,该模块能够在不丢失空间信息的情况下进一步增强多尺度语义特征。编码器最后一层特征图通过SFEM增强后发送到解码器的每一层,解码器每一层融合来自编码器层、SFEM 及上采样的特征,实现高低层特征融合。
文献[45]重新设计跳跃连接部分,对跨层级的差异性特征进行聚合。其设计的减法单元(subtraction unit,SU)对相邻层级的特征图进行逐像素减法运算,用于捕获息肉浅层特征和深层特征的互补信息并突出其差异,将多个SU 金字塔式地连接起来构成多尺度减法模块,模块结构如图6 所示。多尺度减法模块中使用的减法运算降低了输入到解码器的结果特征在不同层次之间的冗余度,但对特征的重用仍然导致高计算资源需求。
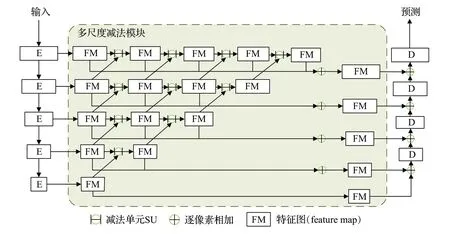
图6 多尺度减法模块结构Fig.6 Multi-scale subtraction module structure
表3列举了U-Net结构基于以上改进策略的其他文献,并对各改进策略的优势和局限性进行归纳总结[38,46-53]。
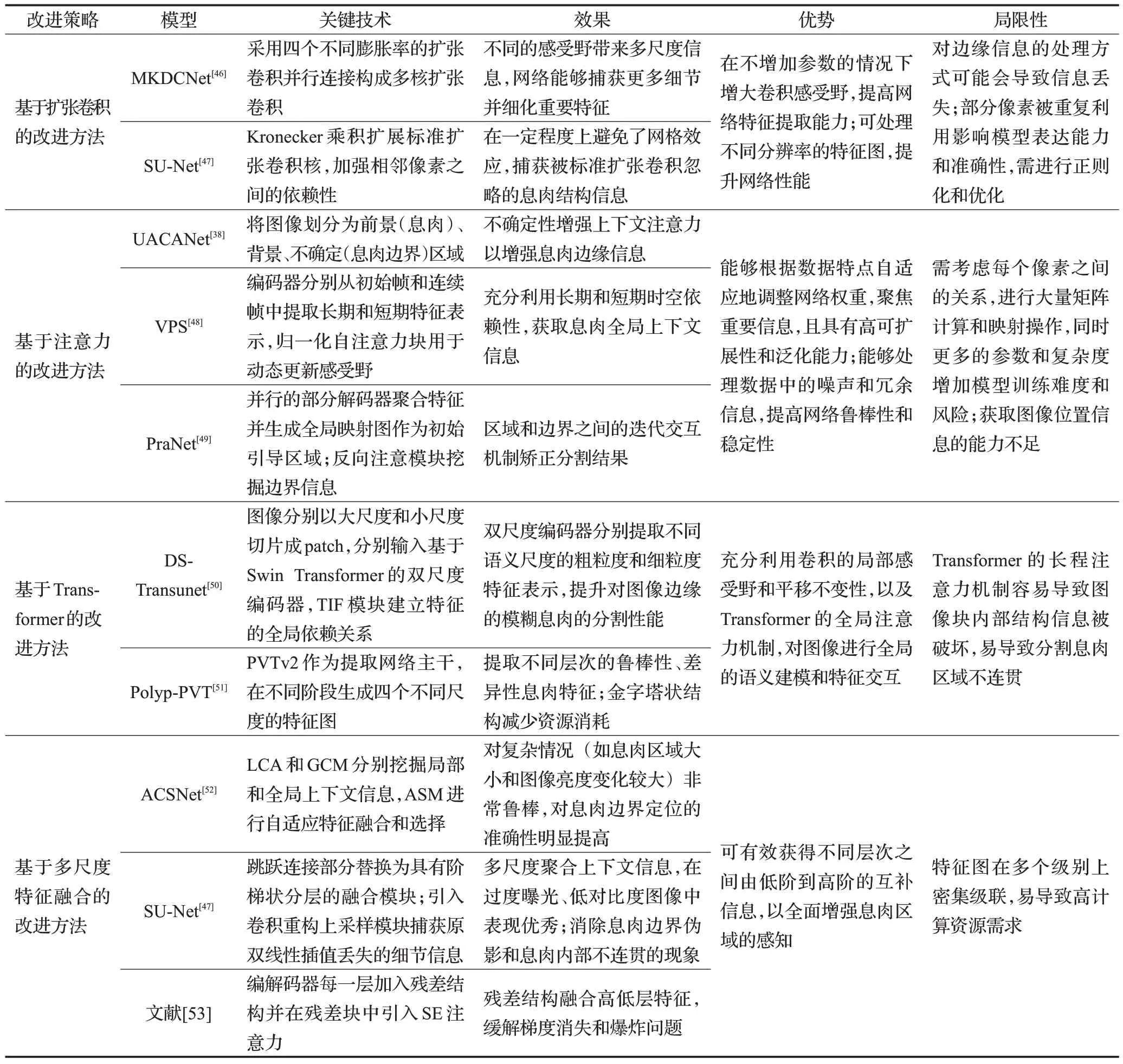
表3 U-Net结构息肉分割模型的改进方法对比Table 3 Comparison of improved methods for U-Net structural polyp segmentation models
2.3 基于多模型融合的分割模型
ResUNet++[54]、PolypSegNet[34]虽然能够在多尺度上提取息肉特征信息,但只是对息肉内部区域进行较好的处理,对息肉边界的分割较为粗糙。许多研究者发现单一模型的预测能力有限,于是提出多模型融合的分割模型,将共享编码器和多个特定任务的解码器(例如区域分支和边界分支)集成到一个网络中,以提高分割性能。文献[55]在数据预处理时通过蓝色通道提取息肉图像中镜面高光部分,再引入Mumford-shah Euler图像模型的变分修复方法来重建出没有镜面反射的图像。之后集成双数小波池化CNN 模型(dual-tree wavelet pooled CNN,DT-WpCNN)和局部梯度嵌入式加权水平集方法(local gradient weighting-embedded level set method,
LGWe-LSM),将两种方法的分割结果进行像素级融合作为最终预测结果。双数小波池化方法相比传统的池化方法在保留结构的同时降低特征图的维数;LGWe-LSM 用于分割高度不均匀性和弱边界的息肉区域,抑制DT-WpCNN分割的高强度假阳性区域并确保息肉区域的平滑度。
一些多模型融合的分割模型[56-58]提升了多正则化特征表示对相关任务的区分能力,从而显著降低了过拟合的风险,但区域分支和边界分支分别进行训练,忽略了它们之间的相互依赖关系。文献[59]考虑区域和边界的双向约束,提出了SFANet。编码器和双解码器下的选择性特征聚合结构和边界敏感损失函数对区域边界进行约束,解决了边界模糊问题,但该模型泛化性能较弱。文献[60]则在恢复息肉边界的同时更加关注到模型本身的泛化能力。文献[61]设计了一个具有三个并行解码器的模型Psi-Net,一个解码器用于学习分割进行掩码预测,另外两个解码器用于辅助轮廓检测和距离图估计。辅助任务对掩码预测进行规范,以生成具有平滑边界的精细掩码。多模型融合的分割模型与单一模型相比分割准确率有所提高,但模型复杂,损失函数的设计较困难,训练难度和计算量较大,导致网络实时性较低。
3 常用数据集及预处理方法
3.1 结肠息肉图像数据集
目前使用的大多数公共息肉数据集都是由MICCAI挑战赛提供。在EndoVis子挑战赛[62]上提供了图片数据集CVC-ColonDB、CVC-ClinicDB和ETIS-Larib,视频数据集ASU-Mayo Clinic 和CVC-VideoClinicDB。CVCEndoSceneStill组合了CVC-ColonDB和CVC-ClinicDB,增加了其他类别的ground truth 掩码(管腔及反光),并划分了训练、验证和测试集,使得基于此数据集的分割方法能够进行直接比较。Kvasir[63]是一个多类图像数据集,包含息肉类以及其他病理结果标签。文献[64]提出了一个大型的视频息肉数据集LDPolypVideo,包含不同类息肉,并在此数据集基础上评估了许多息肉检测方法。此外,文献[65]提供了一个由不同病变(增生性病变、腺瘤和锯齿状腺瘤)组成的视频数据集,用于息肉分类的研究。
尽管这些数据集被广泛使用,但一些作者在实验中同时使用公开与私人数据集或仅使用私人数据集,以及对数据集的不同增强方法使得各方法难以进行公平的比较。表4 总结了当前公共可用的结肠镜检查图像数据集[48-49,64-76]。“CLS”表示息肉类别,“BBX”表示边界框,“PM”表示二进制掩码,“D”表示检测,“S”表示分割,“C”表示分类。
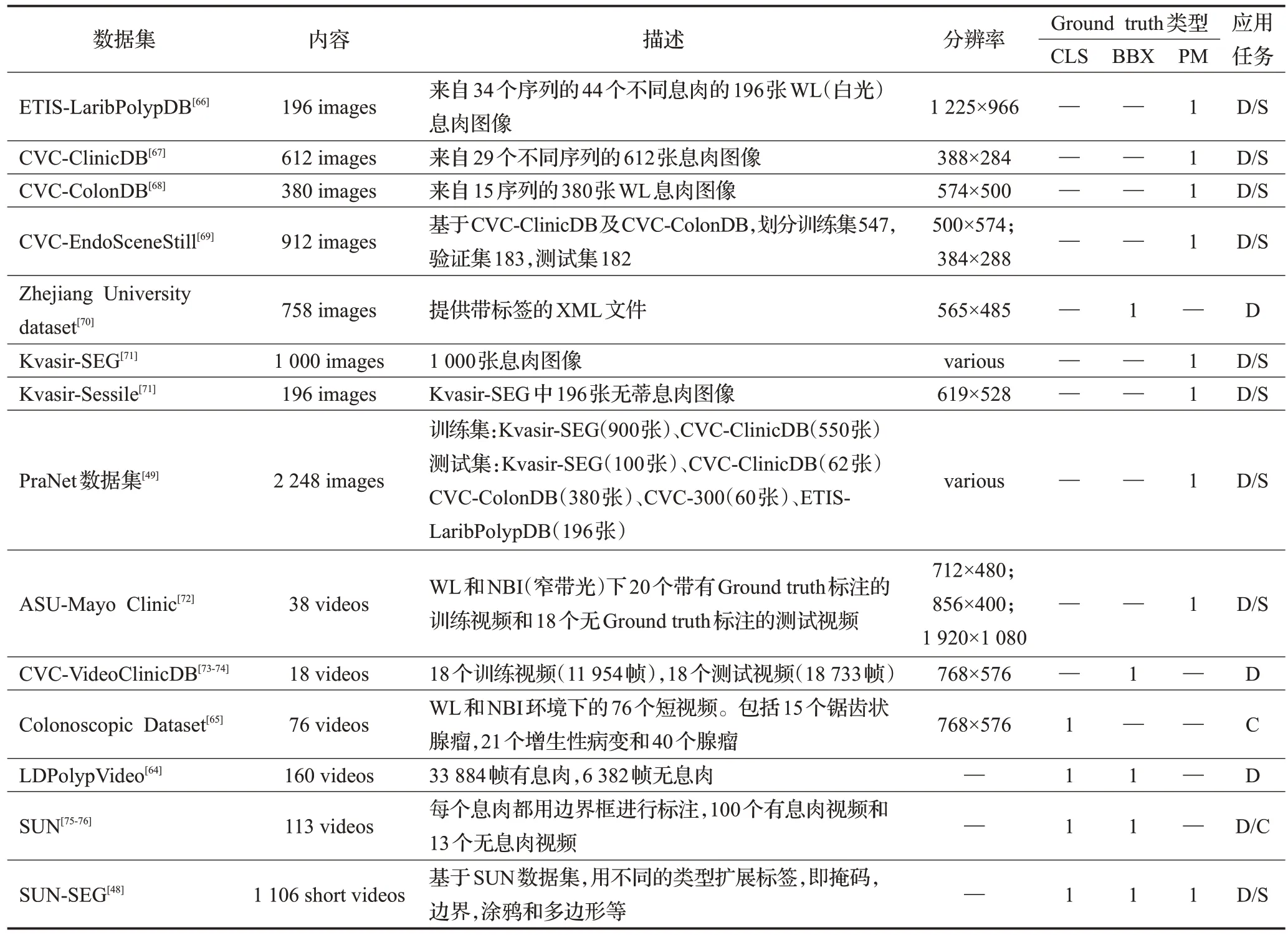
表4 公共可用结肠息肉图像数据集Table 4 Publicly used colon polyp image datasets
3.2 数据预处理
数据集的数量和质量很大程度上影响模型的性能,但由于涉及到隐私问题以及数据集的标注需要耗费大量人力资源,医学图像数据集大小往往受限。为了扩充样本多样性,通常在模型训练时采取一些数据增强策略,通过增加训练数据量及数据多样性来减少模型的过拟合,增强模型鲁棒性。
文献[69]在CVC-EndoSceneStill数据集上分析了不同数据增强策略对模型性能的影响,包括缩放、局部变形、裁剪、旋转以及混合方法等,数据表明混合数据增强方法使息肉类分割的IoU由44.4%提升到54.8%。文献[77]在数据预处理部分采用中值滤波去除图像反光像素,对分割结果也产生了一定的积极影响。文献[5]采用灰度图进行训练和识别。实验结果验证,当有较多的皱纹或光斑时,使用RGB 图像进行息肉检测会更加准确;而当息肉图像不太明显时,如未聚焦或残影,使用灰度图进行息肉检测效果更好。为了消除颜色对息肉分割的影响,文献[37]随机选取一个图像并将其颜色传递给其他输入图像,多次颜色交换后得到内容相同颜色不同的新输入图像。颜色交换操作可以解耦图像内容和颜色,迫使模型更加关注息肉形状和结构。
4 评价指标及模型性能比较
4.1 评价指标
分割模型常用评价指标计算方式如表5所示,其中最常用的是像素级的Dice和IoU[3]。
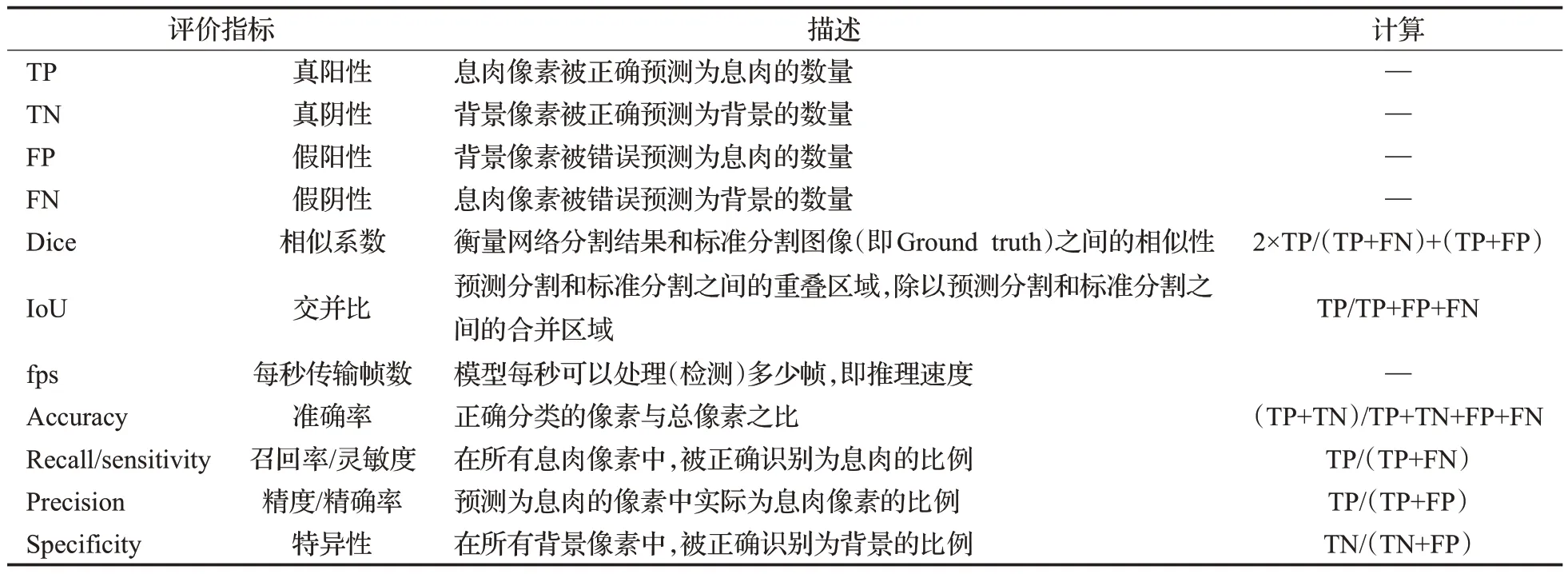
表5 常用评价指标计算方式Table 5 Calculation methods of commonly used evaluation indexes
4.2 模型性能比较
各分割方法在结肠息肉数据集上的评价指标结果如表6所示。在CVC-ClinicDB上,基于RNN方法的CRFEfficientUNet[29]采用了多种数据增强策略对训练集进行扩充,该方法的Dice最高,但该方法对参数的重复利用使得训练时间过长;基于文本引导注意力的TGANet[39]仅次于CRF-EfficientUNet[29],取得第二Dice 结果94.6,且该方法处理不同尺寸和数量的息肉图像时鲁棒性较高;Transformer强大的全局特征建模功能极大地提高了模型分割性能,Transfuse[42]并行结合CNN与Transformer的方式取得了94.2 的Dice 结果;基于GAN 方法的结果较差,但文献[32]在少量训练数据集(5 张,10 张,25 张)上的Dice要高于有监督的其他模型,适用于训练数据有限或数据分布不均衡等情况。在Kvasir-SEG上,基于多模型融合的文献[60]取得最高IoU,但同时双分支结构使得模型复杂,增加大量参数。

表6 息肉分割方法结果对比Table 6 Comparison of results of polyp segmentation methods
5 总结与展望
本文总结了基于深度学习的息肉分割方法的主要改进策略,分析各方法的优势及局限性,发现目前该领域仍面临一些挑战:(1)数据有限:深度学习网络模型的训练需要大量的数据集并且需要对其进行标注,但大规模、高质量的标注医学图像数据集尤其是息肉图像非常稀缺,在一定程度上影响模型训练性能;(2)数据复杂性:不同成像设备扫描的息肉图像在颜色及质量方面有很大差异,且息肉形态多变,在不同时期呈现不同的颜色纹理特征,息肉与周围黏膜之间的边界不清晰,都导致息肉分割得不精确,模型训练困难;(3)临床使用率低:用于模型训练的数据集背景干净、清晰,通常与临床情况下的图像存在差异,导致模型的准确率在临床环境中无法再现。
分析现阶段深度学习息肉分割领域存在的问题,未来可以从以下几个方面深入研究:
(1)制作标准的公共数据。一个接近实际临床环境,并由专家标注的大型息肉图像数据集能够大幅提高息肉分割模型的性能,提高模型临床使用可行性。
(2)提升模型在小数据集上的分割性能。结合弱监督学习,利用少量标注信息,从非标注信息中进行学习;通过无监督的GAN 生成高质量息肉图像,避免数据较少导致的过拟合问题。或结合迁移学习,将其他数据集上的已训练好的分割模型参数迁移到息肉分割任务中,并进行微调,应用于小型的息肉图像数据集。2020年用于图像处理的视觉Transformer[40]被提出,在医学图像处理领域取得优秀的结果,但该方法需要通过大量训练数据提取全局关键特征获得高分割性能,因此,Transformer模型如何在息肉小数据集上获得高精度也是未来值得研究的方向。
(3)增强模型鲁棒性。从数据角度,通过图像增强策略提高图像对比度、清晰度,或通过颜色变换、局部扭曲等操作扩充样本多样性;从模型角度,通过引入注意力机制、Transformer[40]、深度可分离卷积[78]等,加强模型特征提取能力,提升其对不同采样环境、畸变、噪声等的适应性,进一步提升模型的精度和鲁棒性。
(4)研究基于视频的息肉分割技术。基于视频的分割模型[48]能够处理带有时间维度的动态医学影像,更准确定位和描述息肉的形态、大小、位置等信息。但目前息肉分割研究多为单帧的图像分割,视频语义分割领域仍存在很大挑战,可以从以下两方面研究视频语义分割:基于RNN[21]、LSTM[22]等方法利用视频帧之间的时序信息提升分割精度;利用帧之间的相似性减少模型计算量、提高模型运行速度。
(5)探究多任务模型。将息肉分割模型与其他检测或分类网络结合,通过共享网络层学习多个相关联任务的特征表示,模型在分割息肉的同时分类息肉类别(如腺瘤、增生等)。多任务模型通过在任务之间共享权重来减少模型参数,降低过拟合风险。但同时需要在实际任务中考虑数据不平衡、任务优先级及模型复杂度等情况。
6 结束语
目前深度学习在医学图像处理领域应用广泛,但针对特定任务(如息肉分割、脑肿瘤分割、皮肤黑色素瘤分割等)仍有很大改进空间。本文对深度学习在息肉分割方面的应用及其改进策略进行研究分析,总结该领域存在的挑战及未来研究方向,相信基于深度学习的息肉分割研究能够更好地辅助临床医生早期发现并切除结肠息肉病变。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02
速读·下旬(2021年11期)2021-10-12
家庭医学(下半月)(2020年3期)2020-05-30
大东方(2019年12期)2019-10-20
电子制作(2019年11期)2019-07-04
中国生殖健康(2019年3期)2019-02-01
北京航空航天大学学报(2018年1期)2018-04-20
科学与财富(2017年22期)2017-09-10
商情(2017年1期)2017-03-22
中国当代医药(2015年31期)2015-03-01
