
三维人脸识别研究进展
2023-12-11 07:11赵国强
计算机工程与应用 2023年23期
刘 力,龚 勇,赵国强,2
1.中国电子科技南湖研究院,浙江 嘉兴 314002
2.浙江大学 信息与电子工程学院,杭州 310027
近年来,随着人工智能技术的快速发展,人脸识别技术已经广泛应用于社会安防、智能家居、金融支付、教育、医疗、交通等领域。人脸识别技术无须用户过多参与,对用户不造成任何损害,通常采用非接触式的数据采集方式,识别设备小巧便携,被称为21世纪最有前途的身份验证方法。Minaee等[1]对包括人脸在内的120多项生物特征识别的前景工作进行了全面调查,阐述了人脸识别技术的重要性。目前大多数人脸识别方法建立在二维数据的基础上,即对单一的二维彩色图像进行识别,技术相对成熟,但容易受到年龄、肤色、纹理及复杂环境因素的干扰和影响,识别精度和应用范围受限,Kortli 等[2]对二维人脸识别技术的传统算法与最新研究进行了全面的总结。Wang等[3]、Dalvi等[4]对人脸识别的发展历史、技术流程及应用进行了详细介绍。Du等[5]主要考虑基于深度学习的二维人脸识别,部分方法涉及三维人脸对齐和检测技术。
相对二维人脸数据,三维人脸数据包含更加丰富的身份信息,基于三维数据开发的人脸识别技术可以克服或减轻环境因素的影响,能够抵御各种形式的攻击,因此三维人脸识别方法得到越来越多的重视。Zhou 等[6]基于姿态变化、表情变化和存在遮挡三种不同情况,对相关三维人脸识别技术的发展历史和研究方法进行了总结,Guo 等[7]在此基础上进一步讨论了视频和异构数据的识别问题。Sharma 等[8]深入分析了基于深度学习的三维人脸重建技术,但讨论的应用领域有所局限。Zhang 等[9]总结了三维面部和头部技术,包括数据捕获技术和仪器、数据集、建模流程以及产品应用场景,但主要集中在传统方法方面,对于机器学习、深度学习等关键方法涉及很少。Topsakal等[10]总结了数量最多的三维面部地标检测算法,但缺乏三维面部识别环节的调研。Cava[11]从监控视频和面部照片图像中分析了3D人脸重建算法的研究进展,Wang 等[12]从去噪、超分辨率、去模糊、伪影去除等方向详细讨论了三维人脸重建技术,但二者都缺乏对其他类型三维人脸数据的研究调研。Jing等[13]回顾了过去十年中开发的三维人脸识别技术,涵盖了三维人脸识别的传统方法和深度学习方法,Kittler等[14]详细介绍了三维人脸建模和结合二维信息的三维人脸匹配方面技术,但都没有涵盖最新的研究进展。近三年来,三维人脸识别的研究进展迅速,应用场景不断扩大,在识别精度和运行速度上取得了巨大的提升,是解决人脸识别瓶颈的关键技术。
因此,本文全面地阐述了三维人脸识别技术的最新研究进展,根据人脸数据的不同格式,将三维人脸识别方法分为从单目彩色RGB图像进行三维人脸重构的识别方法、基于点云数据的人脸识别方法、基于RGB-D数据的人脸识别方法,以及基于多模态数据的人脸识别方法,总结各类方法原理和流程,对各类三维人脸识别的最新研究方法进行总结和对比,阐述、分析了不同类型的三维人脸数据集,分析现有方法存在的问题,预测技术发展趋势。
1 三维人脸识别研究进展
由于采集方式不同,三维人脸数据具有多种类型,主要分为彩色图-深度图(RGB-depth,RGB-D)、点云和网格,如图1所示[15]。在点云数据中,每个点对应一个三维坐标(x,y,z),若增加纹理、形状等属性,则点云数据可以扩展为(x,y,z,p,q,…) 。深度图以二维格式保存,与拍摄的二维彩色图像大小相同,但每个位置保存的是深度值,与RGB 图像结合即可获得人脸的纹理和深度信息。网格数据通过点构成线,再由线构成多边形,最后由多边形构成面,并通过阴影、纹理等信息表达网格表面。各类数据可以互相进行转化,在网格数据上进行点采样可以获得点云数据,采用插值法或逼近法等网格生成算法可以将点云转换为网格;深度图经过坐标变换可以计算点云数据,有规则且必要的点云数据可以反算出深度图。
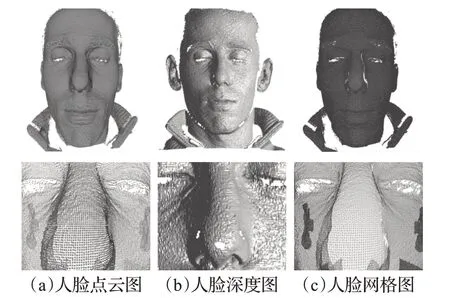
图1 不同类型的人脸数据Fig.1 Different types of face data
本章根据人脸数据的不同格式,将三维人脸识别方法分为从单目彩色RGB图像进行三维人脸重构的识别方法、基于点云数据的人脸识别方法、基于RGB-D数据的人脸识别方法,以及基于多模态数据的人脸识别方法,图2总结了各类方法原理的区别与联系。
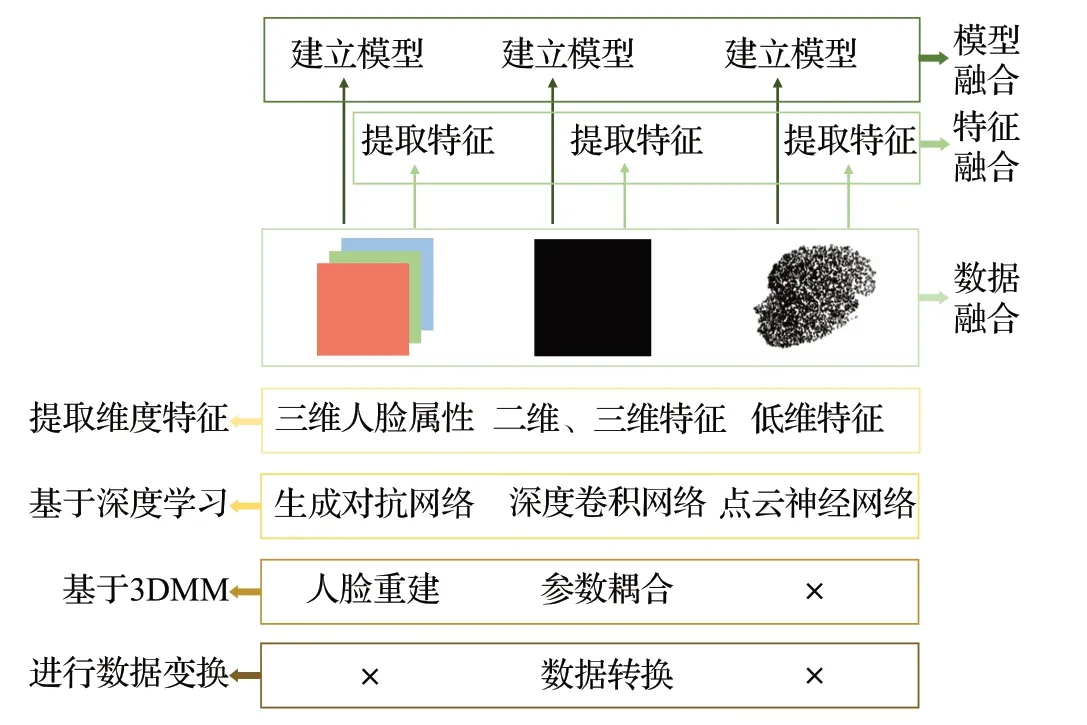
图2 各类方法的区别与联系Fig.2 Differences and connections between various methods
各类方法的识别流程大致相同,如图3 所示,首先对原始数据进行人脸检测与对齐、数据增强等预处理,再建立合适的模型从数据中提取面部特征或参数,最后得到识别结果。

图3 三维人脸识别流程Fig.3 Process for 3D face recognition
表1 梳理了近期各类三维人脸识别方法的研究概况[16-93]。

表1 三维人脸识别方法总结Table 1 Summary of 3D face recognition methods
1.1 基于单目RGB图像的三维人脸识别
从单目图像进行人脸识别是计算机视觉的基本任务之一。在过去的二十年中,研究界一直聚焦从RGB图像提取关键点[93-94]、轮廓信息[95]和分割信息[96]等,根据手工提取的特征直接进行识别。近年来,研究人员开始利用单目RGB 图像重构三维人脸,并在三维空间中进行人脸识别,识别流程主要包括预处理、建模和预测环节,预处理阶段通常包括面部裁剪、面部对齐等,但预处理阶段不是必需的,Sharma 和Kumar[97-99]没有使用面部对齐。
本节介绍了基于单目RGB图像重构三维人脸并进行识别的方法。
1.1.1 基于人脸三维属性参数估计的方法
人脸属性包括表情、姿势等内部参数和照明、视角等外部参数,如图4所示。该类方法是对人脸的三维属性参数进行估计,再根据参数进行三维人脸识别。
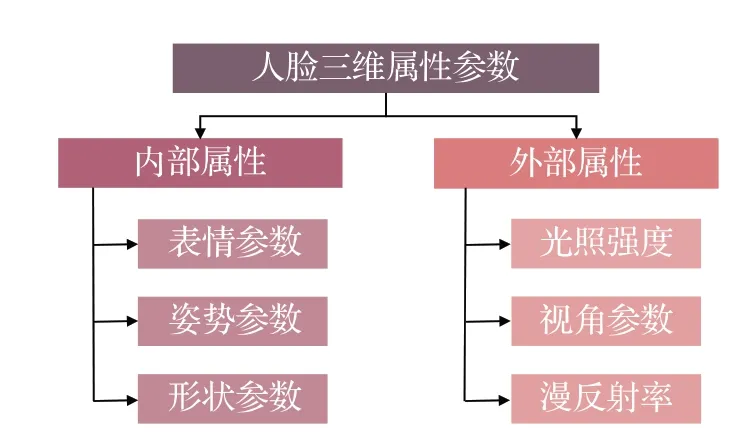
图4 人脸三维属性参数Fig.4 3D facial attribute parameters
部分研究只考虑内部属性参数或只考虑外部属性参数对人脸建模效果的影响,针对性强,对特定场景的识别效果好,但鲁棒性较差。同时对内外属性参数建模的方法复杂度提升,但识别效果相对较好。
(1)单类参数估计方法
Gafni 等[16]只考虑内部参数对建模的影响,将场景表示网络与低维多阶段模型相结合,对表情和姿势参数进行显式建模,使用嵌入在规范空间中的多层感知器建立动态辐射场,再使用体积渲染方法从混合表示中生成三维人脸。该方法能够快速地对头发、眼镜、帽子等任意的几何体和拓扑关系建模,对不同表情、不同场景的应用具有较强的鲁棒性,但缺乏对眼部的建模。Han等[17]只考虑外部光照条件的影响,根据镜面反射和漫反射的细微差异,提出了非朗伯表面的单目三维偏振成像方法,根据提取的梯度场确定表面法线,进而完成三维人脸重构,该方法对于自然照明下的人脸重构具有一定效果,可以达到微米级分辨率。Mallikarjun等[18]仅对外部视角参数建模,在几何畸变的不变空间中生成一组基本面,对输入光的方向、视角和面几何参数进行建模。该方法考虑了亚表面散射、镜面反射、自阴影和其他高阶效应等物理效应,在人脸建模过程中取得了较好的效果。然而该方法无法估计眼部的反射率,且镜面反射和阴影等边界较为模糊、建模效果不佳。
(2)内、外部参数同时建模方法
Bai 等[19]提出了一种可装配的三维人脸重建方法,对个性化的人脸关键点和每个图像的表情、姿势、照明等参数联合建模。该方法超越静态重建,能够应用于视频重定位、目标重定位等场景。Dib 等[20]利用卷积神经网络估计表情、姿态、光强、漫反射率等参数,可微光线跟踪器利用这些参数生成光线跟踪图像,对人脸进行基本重建。采用两个额外的解码器估计反射率先验参数,提高了一般化场景中人脸重建的质量和鲁棒性。该方法不能适应光照和表情变化,无法对肤色建模,且漫反射率可能受到极端阴影的影响。Wu等[21]认为人脸数据的不对称性是由形状变形、不对称反射和不对称照明等因素引起的,因此设计自动编码器将输入图像分解为深度、漫反射、视角和照明度因子,估计输入图像中每个像素对称的概率。该方法无须任何监督和事先的形状模型,适用范围较广,能够应用于视频场景,在不同帧之间产生一致、平滑的重建,准确恢复面部运动的细节,但无法克服遮挡等情况。Zhang 等[22]发现图形渲染器近似真实成像,神经渲染方法能生产高精度外观,提出物理引导的离散隐式渲染(physically-guided disentangled implicit rendering,PhyDIR)框架进行高保真三维人脸建模,采用三维渲染和光栅化模块控制渲染器,求解光线、面部形状和视角参数,该方法能够恢复纹理细节,但模型的推理速度慢,适合应用于对细节和精度要求高的场景。Wen等[23]基于自监督学习,提出了条件估计框架,通过学习参数的统计依赖性,求解形状、反射率、视角和光强等三维参数,结合图像重构三维人脸。该方法无须假定条件独立,首次考虑了参数的统计性,但对形状的估计效果不佳。Jiang 等[24]提出球面人脸模型(sphere face model,SFM),将RGB图像分解为人脸表面的尺寸参数、形状参数、表情参数,和反射率参数、照明参数、姿态参数、相机参数等渲染参数,从而控制人脸表面的形成,该方法的一致性和保真度较高,但眼部重建质量低。
1.1.2 基于三维可形变模型的方法
该类方法从数据库中训练通用的三维人脸模型——三维可形变模型(3D morphable models,3DMM)[25],所有要生成的人脸都处于密集的对应点对中,这可以通过人脸注册过程来实现。通过密集对应生成形态面。这项技术的重点是将面部颜色和形状与光照、亮度、对比度等其他因素分离开来[26]。任意人脸可以由其他多幅人脸正交基加权表达,建模过程如图5 所示,根据重建结果进行三维人脸识别。该类方法原理简单,求解速度快,重建结果完整,拓扑结构已知;但是在求解病态问题过程中,容易陷入效果不佳的局部解,难以重建细节特征,背景干扰、存在遮挡等情况对建模效果影响较大。
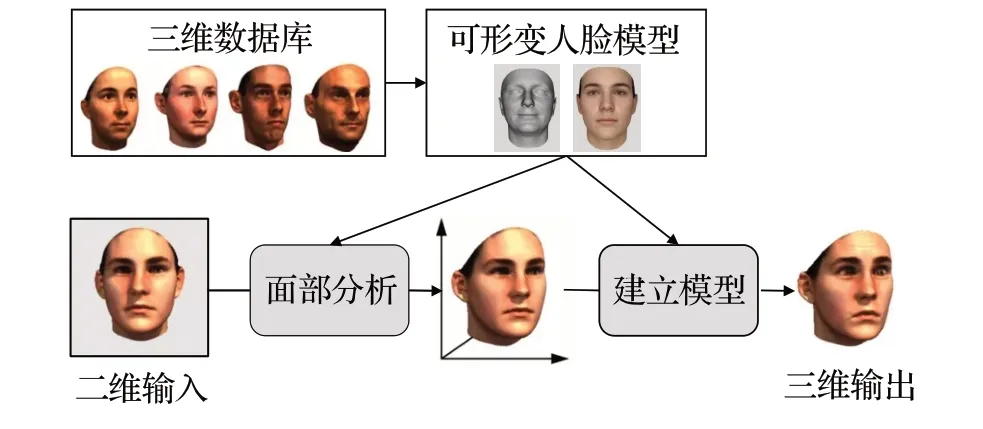
图5 3DMM流程Fig.5 Process of 3DMM
大多数情况下,该类方法使用的是线性3DMM 模型,也有一些基于非线性3DMM模型的研究[27]。根据学习范式的不同,将该类方法细分为有监督学习、无监督学习、自监督学习和弱监督学习方法。
(1)有监督学习方法
该类方法通过计算重建人脸与三维真实人脸之间的误差进行训练,可以获得较好的重建效果,如图6所示。

图6 3DMM有监督学习Fig.6 3DMM supervised learning
Jin等[28]提出了一种从单目图像重建三维人脸的粗-中-细框架。粗糙阶段估计3DMM 模型的形状、姿势参数,中间阶段检测输入图像中的密集关键点,对粗糙形状进行拉普拉斯变形;精细阶段估计照明、反射率和阴影分量的初始值,耦合反射率优化的纹理损失和细节损失。该方法能在多个尺度上实现优化,提高了估计的准确性和鲁棒性,但耗时较长,不满足实时应用的需要。Wu等[29]基于3DMM和三维面部关键点的协同关系建立模型,基于MobileNet-V2网络估计3DMM系数并构建面部网格。该方法对3DMM系数应用自约束一致性建立协同过程,能够合成逼真的细节,提高了人脸重建性能,但提出的两个模块为模型每次迭代增加了5%的耗时。Yang 等[30]基于关键点对齐、像素一致性拟合基础模型,再采用神经网络从纹理图中获得静态特征、从变形图中获得动态特征,获得多张位移图,以不同权重组合得到三维人脸,以此进行识别,该方法具有较高的保真度。
(2)无监督学习方法
该类方法通常通过分析单张图像中的明暗信息来判断物体表面的法线方向,从而恢复表面形状,如图7所示。首先输入一张在真实世界中拍摄的RGB 人脸图像,在朗博假设下,将图像分解为形状,反射和光照三类信息。
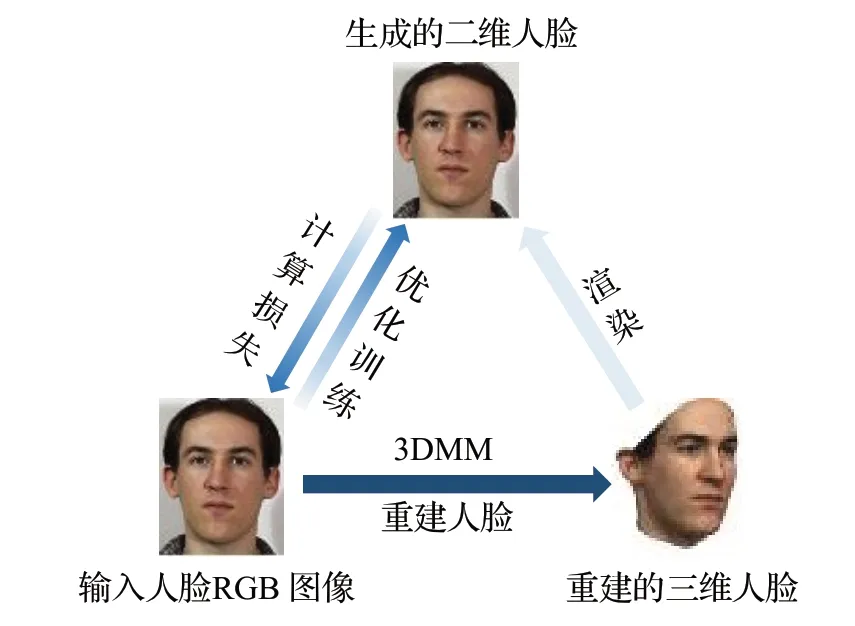
图7 3DMM无监督学习Fig.7 3DMM unsupervised learning
Tiwari 等[31]提出了减少依赖性的快速无监督三维人脸重建(reduced dependency fast unsupervised 3D face reconstruction,RED-FUSE)框架,通过人脸图像估计3DMM 系数,重建三维面部网格,再投影至二维平面,根据二维图像的一致性重建人脸形状和纹理。该方法运行速度快,克服了对真实标注的依赖,但是缺乏对多个视图的建模。Zhang等[32]提出了三维人脸模型的聚合个性化(learning to aggregate and personalize,LAP)框架,基于面部结构的一致性,对基本的面部几何和纹理进行重构,再添加个性化的属性和细节,完成三维人脸模型的构建。该方法不依赖先验信息和监督学习,对面部形状和纹理的建模效果较好,但该模型较为复杂,运行时间较长,分辨率较低。Genova[33]设计的无监督训练模型也采用了编码器-解码器架构,使用三重损失:批量分布损失、环回损失和多视图损失。该方法改进了眉毛纹理、鼻子形状等特征的相似性,更能抵抗身份、表情、肤色和光照等复杂变量的影响。
(3)自监督学习方法
三维人脸重建中真实的数据集获取成本非常高,研究者往往基于少量数据或者仿真数据进行研究,所训练出来的模型泛化能力会受到限制,自监督的方法则是一个解决该问题的重要思路。这一类方法不依赖于真实的成对数据集,它将二维图像重建到三维,再投影回二维图,以系数损失作为约束进行训练,如图8所示。
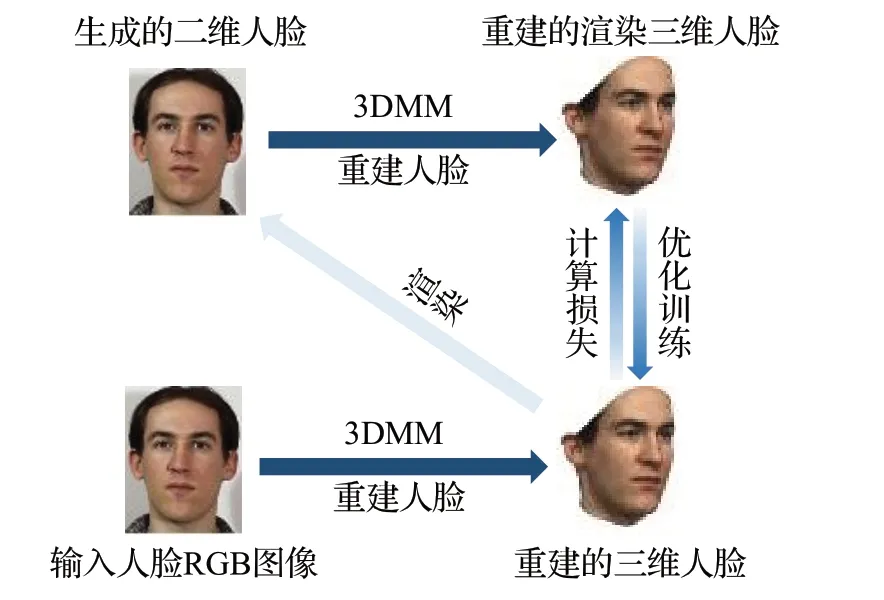
图8 3DMM自监督学习Fig.8 3DMM self-supervised learning
Tiwari 等[34]提出的自监督鲁棒制导(self-supervised robustifying guidance,ROGUE)框架,包括鲁棒管道和制导管道,制导管道将三维网格投影到二维空间,根据其与输入图像的一致性获得参数;鲁棒管道从输入图像与遮挡、噪声图像的一致性学习几何参数和纹理参数。该方法以自监督的方式学习三维人脸,对图像中的遮挡和噪声具有较强的鲁棒性,但对训练集的依赖严重,且不可缺少的预处理环节大大增加了训练模型的时间。Shang等[35]基于自监督学习,提出了多视图几何一致网络(multi-view geometry consistency network,MGCNet),该架构建立了一种多视图几何约束,基于3DMM 先验人脸模型,对不同视图中的几何体建立一致性规范。该架构为人脸姿态和深度估计提供了可靠的约束,在表情、姿态和照明条件发生巨大变化时较为鲁棒,该方法精度较高,但模型运行速度慢,能够应用在没有标记的场景,有应用于视频识别的潜力。
(4)弱监督学习方法
该类方法利用弱监督信息进行训练,如面部关键点、皮肤掩码等,如图9所示。
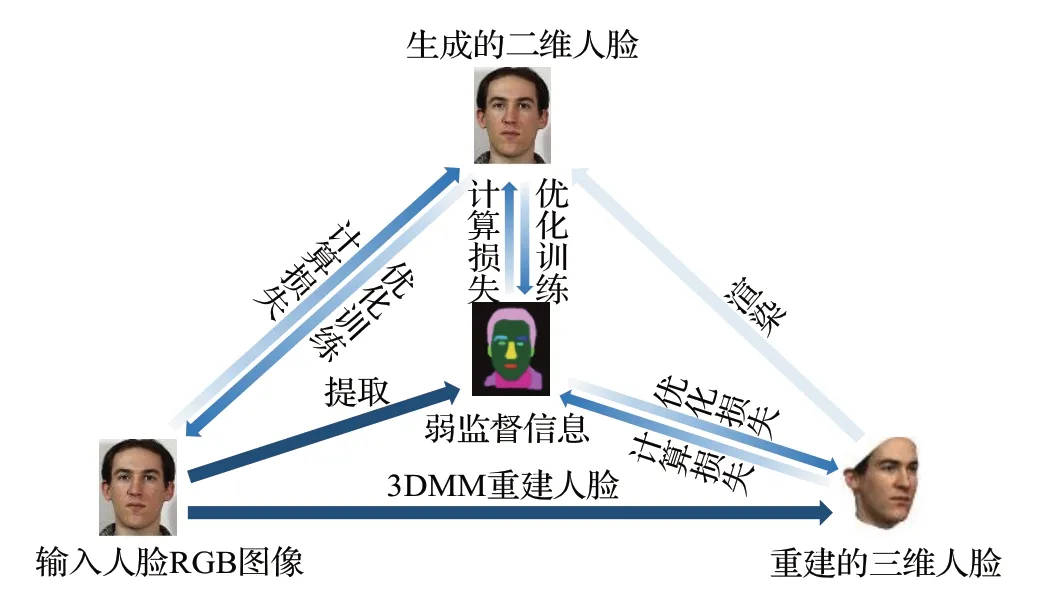
图9 3DMM弱监督学习Fig.9 3DMM weakly supervised learning
Deng 等[36]利用图像低层信息和感知层信息进行弱监督学习,使用R-Net 回归3DMM 参数,基于重建图像和原始图像的图像级损失和感知层损失训练模型,该方法能够以较快的速度建模,具有对遮挡和大姿态鲁棒性强的特点,但纹理和形状的拟合不够稳健,方差大。Tran等[37]认为线性基限制了3DMM的表达能力,设计了包含一个编码器和两个解码器的模型,能够从大量自然人脸图像中学习非线性3DMM模型。该方法建立了端到端的模型,重建误差更小,面部纹理重建效果好,但该模型具有超过500M的参数,模型运行时间长。
1.1.3 基于生成对抗网络的方法
生成对抗网络(generative adversarial network,GAN)具有强大的数据合成能力,在基于单目图像重建的过程中得到越来越多的应用。该类方法的基本思路是设计合适的GAN,基于单目图像生成三维人脸形状、纹理,并根据重建结果进行三维人脸识别,流程如图10所示。

图10 基于GAN的三维重建识别流程Fig.10 3D reconstruction and recognition process based on GAN
Jin等[38]提出伪RGB-D人脸识别框架D+GAN,生成器由残差模块、自注意力模块、卷积模块组成,利用条件图像及对应标签生成假图像;判别器不仅判定输入样本是否真实,并对每个样本进行多类别分类,识别深度图的生成质量,实现了具有人脸属性的多条件图像到深度图的转换,提高了人脸识别的准确性。该模型参数量巨大,且训练过程中难以收敛,无法应用于实时解决方案。Chiu等[39]提出了分段感知深度估计网络DepthNet,由一个生成器和三个判别器组成,能够从RGB 图像中生成深度图。生成器基于UNet架构设计了带有快捷连接模块的面部编码器、面部解码器和辅助解码器,面部编码器编码图像的输入信息,辅助解码器生成输入图像对应的深度图和语义分割掩码,面部解码器重建人脸模型。该网络能够实现准确的人脸区域定位,但模型相对复杂,参数量大,训练时间长,实时性差。Tewari等[40]设计了三维生成对抗网络(3D generative adversarial network,3D-GAN),利用生成模型分别从几何和外观空间中独立采样,对人脸的几何参数和外观参数建模。使用多层感知机编码三维坐标,回归三维体积的密度和纹理,使用体积积分从虚拟相机中渲染输出体积、生成人脸。该方法有助于改善三维场景和相机视角之间的消隐效果,但重建效果不及真实图像和2D GAN 网络。Xu等[41]开发了由生成对抗网络和视觉显著网络组成的框架relight GAN,如图11 所示,判别器进行多尺度识别,框架中设置照明激发注意力机制,提升了人脸识别性能。该方法既不需要照明分类信息和三维信息,也不需要严格的面部对齐,解决了面部照明感知和处理的问题,有效提高人脸重建的效果,该方法应用于野外图像时性能下降。
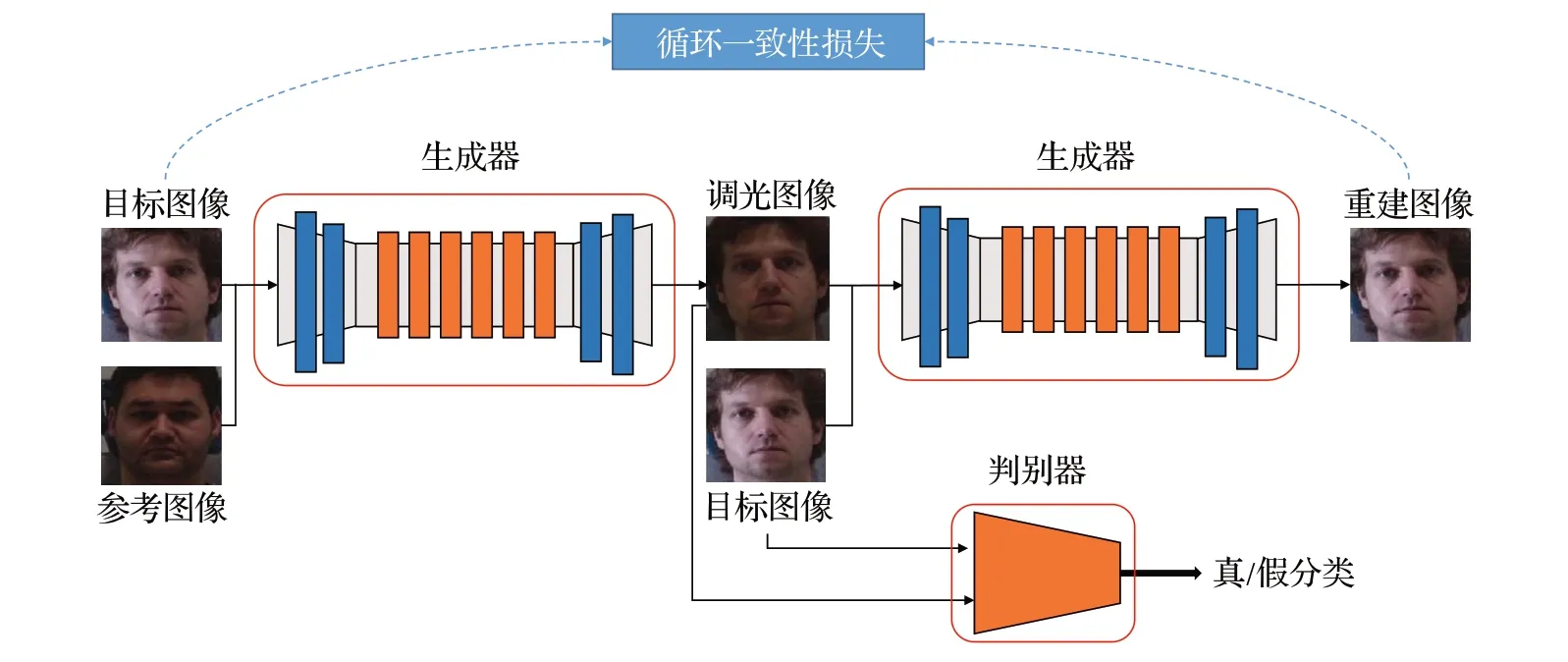
图11 Relight GAN架构Fig.11 Relight GAN frame
1.2 基于点云数据的三维人脸识别
最初的研究通常将点云格式的三维人脸数据转换为体素表示,不仅数据更加庞大,而且识别过程更加繁琐。近年的研究主要分为两类,将点云数据转化为低维度特征和利用深度神经网络直接处理点云数据。将三维数据转换为低维度特征时,需要克服几何信息损失、计算成本增加等问题。建立深度学习模型时需要克服点云数据的无序性和刚性变换不变性。本节介绍了最新的基于点云数据的三维人脸识别方法。
1.2.1 将点云数据转化为低维度特征
该类方法是从点云数据中提取人脸纹理、法线、曲率等低维度特征,进行三维人脸识别。
机器学习方法易于实现,计算量低,能够快速完成三维人脸识别。Wang 等[42]针对不同点云之间的法线、曲率和配准相似性,提出了三维人脸相似性评分算法,解决了光线不稳定和黑暗环境中的面部识别问题,不需要复杂的训练,计算速度很快。Nassih等[43]基于黎曼几何最短距离、随机森林算法和快速匹配算法,提出了GD-FM+RF算法,计算特定点对之间的几何距离,使用主成分分析算法提取特征,输入到随机森林中进行分类,该方法完全基于机器学习算法,算法参数量小,运行速度快,但识别精度弱于深度学习方法。Zhang 等[44]将点云数据表示为七个点,包括三维坐标、面部数量和曲率,使用改进的PointNet++网络提取具有不同感受野的局部、全局特征,人脸识别效果有所提升,对表情和姿势变化较为鲁棒,采用的三重损失能够有效提升时间效率。
此外,借助神经网络识别低维度特征能够有效提升三维人脸识别的效果。Atik 等[45]从点云中提取几何特征,使用网格函数生成深度图,使用六个相邻点计算法向角图,利用Claxton表面函数计算平均曲率图,将新的特征图进行组合输入到ResNet 网络中进行人脸识别,取得较好的识别效果,但该模型基于ResNet 101 网络建模效果最好,参数量超过85×106,训练速度很慢,也无法克服遮挡情况。Moschoglou等[46]提出3DFaceGAN模型对三维面部表面分布建模,生成器和鉴别器采用重构损失和对抗性损失,如图12所示,该模型能够保留三维面部形状的高频细节,并且能够用来进行多标签分类;但GANs很难训练,在GV100 NVIDIA GPU上的进行训练仍需耗时5天,不能应用于实时的三维人脸解决方案。

图12 3DFaceGAN网络Fig.12 3DFaceGAN network
1.2.2 基于点云深度神经网络的方法
该类方法设计端到端的神经网络,直接输入点云数据,并获得识别结果。最基本的三维人脸识别点云网络是将用于识别物体点云的PointNet 网络与常规卷积网络结合,提取相邻数据点间的邻近信息,如图13 所示,即可获得几何、纹理等特征,耦合全局信息。

图13 3D点及其邻域Fig.13 3D point and neighborhoods
Bhople 等[47]将PointNet 网络与卷积网络结合,提出了PointNet-CNN 网络,直接将点云作为输入进行特征提取,使用孪生神经网络进行相似性学习与分类。这一方法降低了数据转换的成本,但模型缺乏可解释性。与之相似,Wang 等[48]基于PointNet 提出三维人脸验证孪生网络,增加倒角距离度量,能够有效应对姿态变化和遮挡的干扰,在GTX 1080ti 上测试的推理帧率达到225 f/s,但模型存在信息冗余。Bhople 等[49]提出卷积点云网络(convolutional PointNet,CPN),将三维面部数据映射到欧氏空间,根据嵌入空间中锚定三维样本、正三维样本和负三维样本间的差异来区分三维人脸。该网络通过学习三维人脸之间的相似性和不相似性,有效提高人脸识别的精度,但计算复杂度高,运算速度慢。
直接将PointNet 网络与卷积网络结合的方法能够使用较为成熟的物体识别研究算法,原理简单,但缺乏对五官等关键点、面部形变等细节的关注,人脸识别精度有限。对此,许多研究加强了对人脸关键点和几何、纹理等信息的提取。Zou等[50]建立基于注意力机制的卷积神经网络,识别人脸的关键点、提取面部特征,避免了表情和照明干扰,但网络复杂度较高,参数量超过25×106。Bahri 等[51]将点云配准任务视为表面到表面的转换问题,提出编码器-解码器架构shape-my-face(SMF),利用带有快捷连接模块的图形卷积解码器,从点云中提取潜在的几何信息,学习人脸的非线性变形模型,在较少参数的前提下实现了较高的人脸识别精度,但缺乏对高频细节和面部纹理的重建。Cai等[52]提出改进的编码器-解码器网络(improved encoder-decoder network,MoEDN),对形变概率、形变区域大小、形变强度等参数建模,在大姿态情况下仍具有出色的性能,能够解决训练集过少和过拟合问题,模型相对复杂,体量较大,在GTX1660ti上测试耗时14.31 ms。
许多研究利用逐点卷积耦合不同通道在相同空间位置上的特征信息,即采用共享的1×1卷积对每个点独立建模,最后使用最大池化等对称聚合函数耦合全局特征,如图14所示。

图14 逐点卷积流程Fig.14 Process of pointwise convolution
Chang等[53]提出了FinerPCN网络,该网络分为编解码器和逐点卷积部分,分别用于生成粗略形状和细化局部结构,该模型有效利用了局部信息,在保持全局形状的同时减轻低输入质量对识别精度的影响,但需要确保足够多的输入点,且该方法无法解决姿态变化、遮挡等影响,缺乏广泛应用性,且参数量很大,超过87×106。Gao 等[54]提出点云特征提取网络ResPoint,其架构如图15所示,通过人脸几何关键点定位鼻尖点,并以该点为中心切割出面部区域,再使用ResPoint网络提取特征并进行分类。该模型对于稀疏点云有很好的识别结果,提高了多表情、多姿态情况下人脸识别的鲁棒性,但网络运行速度慢,无法满足实时性的要求。

图15 ResPoint网络Fig.15 ResPoint network
除点云卷积网络外,Yu 等[55]首次采用GAN 网络提高三维人脸识别准确率,提出了基于元学习的对抗性训练(meta-learning-based adversarial training,MLAT)框架,元训练阶段使用生成的点云训练深度三维人脸识别模型,元测试阶段识别三维面部点云,该架构有效提高了三维人脸识别模型的鲁棒性和准确性,但模型计算复杂,运算量大。
1.3 基于RGB-D数据的三维人脸识别
近年来,随着RGB-D 相机的普及,基于RGB-D 数据进行三维人脸识别的算法受到重视。本节介绍了最新的基于RGB-D数据的三维人脸识别方法。
1.3.1 基于3DMM模型的方法
该类方法利用3DMM 模型获得通用人脸模板,与RGB-D 数据耦合后进行识别。Luo 等[56]使用随机森林算法估计初始面部模型及其姿态,基于FaceWareHouse三维人脸数据库建立了通用双线性人脸模型,将其拟合到RGB-D图像中,对双线性人脸模型的姿态、身份和表情参数联合优化、输出识别结果。该方法在人脸旋转较大、表情各异时较为鲁棒,但缺乏对面部细节的重建,模型运行时间久,处理一帧需要35 ms。Zhu 等[57]提出了细粒度重建网络(fine-grained reconstruction network,FGNet),利用3DMM 模型获得三维人脸的刚性变换和初始形状,将RGB-D 图像和人脸纹理作为最近点匹配算法的强约束条件,将深度图与模板人脸耦合。将RGB图投影、归一化为特定编码、进行细粒度重建,估计形状修正参数,提高了预测精度。Li等[58]基于级联的深度神经网络,对每个顶点进行几何细化,用局部几何细节丰富3DMM 人脸,提出的语义一致性约束确保了生成的三维人脸和深度图像之间的结构对应。该模型在2080ti GPU上运行的推理时间为25 ms,且该方法无法描述面部细节。Zhong等[59]基于CycleGAN模型构建去噪网络,基于3DMM面部形状提出了特定的耦合损失,针对特征图、深度图和表面的形状一致性提出了三层约束,最后使用55维身份参数建立分类器,该方法能够适应有噪声的深度图,较为鲁棒。
1.3.2 基于特征提取的方法
该类方法直接从RGB-D 图像中提取二维、三维特征。Dutta 等[60]沿着4 个坐标方向提取4 个基本面部区域,将RGB-D 图像分解为4 个基本分量,结合数据级融合方法,生成36个额外的混合分量,从中提取、融合、选择特征,有效去除冗余特征值,提高了人脸识别性能,该方法与经典粒子群算法相比,需要更少的内存和运行时间。Boumedine 等[61]对RGB-D 图计算法线并将其分离为Nx,Ny,Nz这3 个方向的映射,仅在Y分量上应用SURF 检测器,并使用来自Ny图的相同检测关键点坐标构建3个分量图上的特征描述符,对每个法线分量构建字典、使用K最近邻分类器,将每个分量的最终分数进行融合从而找到最佳匹配点,其模型如图16 所示。Sui 等[62]提出了带掩码的特征融合网络(feature fusion network with masks,FFNet-M),计算权重分布在4个显著区域中的掩码,分别从深度图、RGB图中提取深度信息和法线特征,使用带有批归一化和掩码的VGG16 网络从纹理图像中提取特征,将特征连接后输入到分类器中进行识别。该方法使用了F3DNet-M与VGG网络,参数量大,训练成本高。

图16 基于法线匹配的模型Fig.16 Model based on normal maps
1.3.3 基于神经网络的方法
该类方法直接利用深度神经网络模型挖掘RGB-D数据中的面部特征,进行识别。Wang 等[63]提出了细粒度的三维人脸识别模型FaceVerse,从大规模RGB-D 图像集中生成能够预测性别、年龄等属性的基础三维人脸模型,进一步构建条件StyleGAN模型,生成多尺度伪纹理图,判别器输出真假纹理图的相似性和映射关系,该模型增强了面部的几何和纹理细节,具有高保真度和强泛化能力,但该模型基于东亚人的数据训练,对其他地区泛化性能下降,且无法拟合胡须、皱纹等面部细节。Dutta 等[64]提出稀疏主成分分析网络(sparse principal component analysis network,SpP-CANet),利用卷积层学习多级滤波器,再进行稀疏主成分分析和二进制编码,在池化过程中计算逐块直方图,最后采用最近邻分类器进行识别,模型较为简单,运行速度较快。Lin等[65]提出一个两阶段框架,第一阶段利用像素变换网络从低质量深度图中生成高质量深度图,第二阶段使用卷积层和残差模块构建了多质量融合网络,提取、融合不同质量的特征,提高了人脸识别的性能,但该网络存在计算冗余,步骤繁琐。
为了提升神经网络的性能,许多深度神经网络模型中添加了注意力机制,其中最常见的就是空间注意力机制。Uppal[66]使用LSTM 网络生成空间注意力权重来处理特征图,使用卷积神经网络从深度图中生成注意力图,引导深度神经网络提取视觉特征。该模型体量较小,参数量仅为4×106,但该方法没有考虑其他特征属性,缺乏多尺度学习。Chiu等[39]提出掩码引导的RGB-D人脸识别模型(mask-guided RGB-D face recognition network),基于SENet 模型设计了RGB 识别分支、深度图识别分支和带有空间注意力模块的辅助分割掩码分支,RGB 识别分支和深度图识别分支分别提取相应RGB 图和深度图中的面部特征,辅助分割掩码分支从分割掩码中提取不同级别的特征图,再应用空间注意力模块提取特征。该模型对姿态的变化更加鲁棒,但模型相对复杂,实时性差。在该模型基础上,Chiu 等[67]进一步采用特征解纠缠方案将特征表示分解为身份相关和风格相关的分量,以缓解增强深度图和真实数据之间的类间差距。Jiang等[68]基于空间和通道注意力方法,提出端到端的多模态融合框架,基于ResNet 网络建立三个分支提取RGB图、深度图及其融合模态的特征,将特征融合后输入到共享层中,进一步提取深层特征,输入到空间注意力矢量化模块中进行识别。该方法建立3 个网络分支,能够在intellifusion RGB-D 数据集上取得了良好的结果,但也因此提高了模型的训练成本,不能很好地推广。与之相似,Zhu 等[69]采用空间和通道注意力机制耦合全局和通道信息,利用双流特征提取模块分别提取RGB图和深度图中的特征,并分别进行识别,与融合特征的识别结果加权获得最终的识别结果。该方法在姿势、遮挡等情况下较为稳健,能够适应低质量的RGB-D数据。
除了空间注意力机制,也提出了一些新的注意力方法。Neto 等[70]提出流式注意力网络(streamed attention network,SAN),能够对不同分辨率的人脸数据进行识别,从深度图中提取浅层表面描述算子,利用改进的三维局部二进制模式算法编码深度差异信息,生成四通道的特征图像进行识别。该方法减少了高分辨率和低分辨率数据之间的差异,更好地利用了浅层特征提供的丰富信息,具有高度鲁棒性,但网络复杂,步骤繁琐,计算量大。Uppal 等[71]基于注意力感知方法融合RGB 图和深度图,该方法使用预训练卷积神经网络提取特征,输入到两层注意力机制进行融合,第一层将LSTM网络作为条件编码器,学习RGB和深度图中特征关系;第二层关注卷积特征图的空间特征,提取最显著的特征,并进行人脸识别。该模型较为复杂,且分类器采用了四层全连接层,参数量巨大。
与上述提取全局面部特征不同的是,Zhang 等[72]更加关注人脸的局部特征,提出边缘引导卷积神经网络,包括边缘预测子网络和深度重建子网络,边缘预测子网络从输入的低分辨率深度图预测边缘特征,并提供最佳边缘引导图,深度重建子网络用级联特征重建超分辨率深度图,恢复尖锐边缘和精细结构。该方法对面部姿势的变换能够保持鲁棒,能够恢复高频边缘细节。Lee等[73]提出了三阶段联合学习架构,RGB人脸解析网络和深度人脸解析网络分别将RGB图、深度图的每个像素分类为不同的面部和语义组件,GAN将RGB图转换到深度图。该方法能够克服深度数据标注不足的问题。Ghosh等[74]基于重构的深度神经网络框架学习RGB图和深度数据的共享表示,堆叠映射模型学习从RGB图到深度图的映射,联合分层特征学习模型将不同层的特征进行组合表示,并在每个层上学习自动编码器,最后加权融合特征并进行分类。该框架在测试时不需要深度图像,适用于深度图像质量较差的场景,但模型复杂,需要多步训练。
Zhao等[75]同时关注全局信息和局部信息,设计了轻量级多尺度融合网络(lightweight multiscale fusion network,LMFNet),能够提取分层多尺度特征,增强面部局部信息的表达,能够有效适应姿态、遮挡等情况,但对噪声的鲁棒性不够。
基于transformer 的三维人脸识别研究取得了良好的效果。Zheng 等[76]提出互补多模态融合变换器(complementary multi-modal fusion transformer,CMMF-Trans),基于变换模块建立RGB图与深度图的局部长距离相关性,提取RGB图和六通道深度图中的低层特征,输入多层局部增强切割模块和多个互作用自注意力模块中。该方法将局部性和长期依赖性结合,对极端条件下的人脸识别更为鲁棒。Li 等[77]提出多模态面部表情视觉转换器(multimodal 2D+3D facial expression vision transformer,MFEViT),如图17 所示。该架构包含3 条支路,每个支路分别用深度图替换RGB图像的单通道,投影后输入迁移编码器进行识别。该模型是一种轻量级变换器网络,参数量约为23×106,具有较强的鲁棒性。
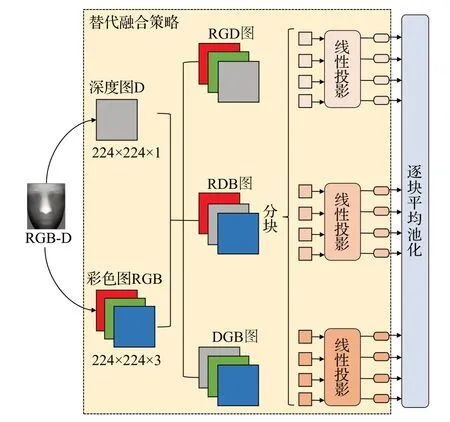
图17 MFEViT架构Fig.17 MFEViT frame
1.3.4 投影到三维空间的方法
该类方法将RGB-D 图投影到三维空间,生成点云数据后再进行识别。Xiao等[78]将RGB图像与深度图对齐,从彩色图像中提取面部区域和关键点,映射到深度图像区域,转换为点云来获得粗略的三维人脸模型,进一步优化后用于人脸识别,该方法对数据质量要求较高,该方法需要花费较长的时间用于面部关键点检测,平均每帧耗时0.63 s。Petkova 等[79]提出的模型如图18所示,在RGB 图和深度图中提取面部边界框并检测框内的面部关键点,将关键点反向投影到三维空间中,获得三维人脸关键点的空间坐标,最后使用细粒度最近邻分类器对点云进行精细对齐匹配。Jiang 等[80]使用MTCN 模型在RGB 图中检测面部和五官,从深度图中提取对应的面部区域,再通过投影、双线性插值生成点云,取各维度最值组成六通道图像作为训练数据。该方法能够将性别、年龄、种族等属性纳入神经网络的训练中,有效提高人脸识别的准确性和鲁棒性,但不能适应需要区分深度数据细微差异的场景。

图18 Petkova等提出的框架Fig.18 Frame proposed by Petkova et al.
1.4 基于多模态数据融合的三维人脸识别
多模态数据的融合方式主要可以分为三类,即将数据进行转换并融合,将从不同模态数据中提取的特征进行融合,以及对不同模态数据分别建立识别模型、并对识别结果加权融合,在建模过程中的发生位置如图19所示。本节介绍了基于多模态数据的三维人脸识别研究进展。
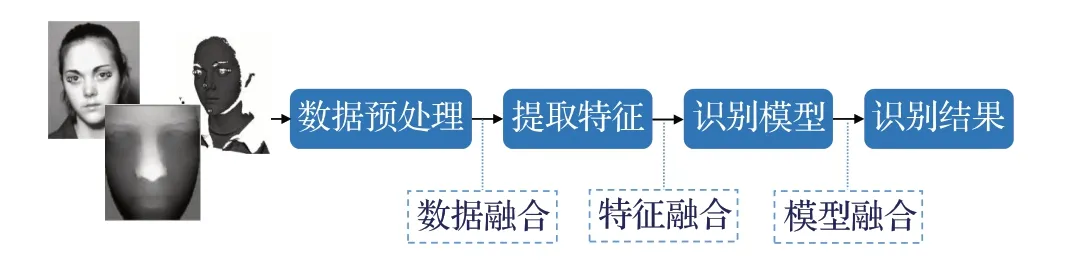
图19 多模态数据融合Fig.19 Multimodal data fusion
1.4.1 数据融合
该类方法将不同模态的数据融合,再进行特征提取和人脸识别,其流程如图20所示。

图20 数据融合流程Fig.20 Process of data fusion
Singh等[81]将输入的三维面部点云投影到深度图和RGB 图中,再在RGB 图像和深度图上分别进行图像混合,生成3DMM参数,在固定视图中将颜色特征图和深度特征图反向投影到点云。该方法在一定程度上可以抵御3D 人脸变形攻击的攻击,但该方法对数据质量要求很高,无法推广到野外数据中。Gu 等[82]提出基于注意力机制的多通道数据融合网络(attention-based multichannel data fusion network,AMDFN)处理二维和三维数据,将三维人脸数据映射成8幅二维人脸属性图像并进行通道融合,提取分层特征,再利用分层注意力模块对不同层的特征分配注意力权重,对不同层特征之间的依赖性建模。该模型主干网络的参数超过30×106,较为复杂。Devi等[83]提出同步估计面部子空间和关键点的框架同步区域学习和显著点估计方法,利用关键点映射策略在人脸上定位二维关键点,利用自动编码器同时学习二维子空间和三维关键点,由面部关键点对模型进行拉普拉斯变形,得到重建的人脸模型,该方法计算成本较低,但无法推广到多视角数据。Jiang等[24]采用两阶段框架分别训练三维人脸表面,第一阶段优化三维人脸的基矩阵、尺度参数和形状参数,第二阶段利用大规模RGB数据集进行无监督训练,对三维人脸重建模型进行微调。该方法对眼部区域的拟合效果差,制约了模型的性能。
1.4.2 特征融合
该类方法从二维和三维数据中分别提取特征,再将提取到的特征进行融合,最后对融合的特征进行人脸识别,其流程如图21所示。
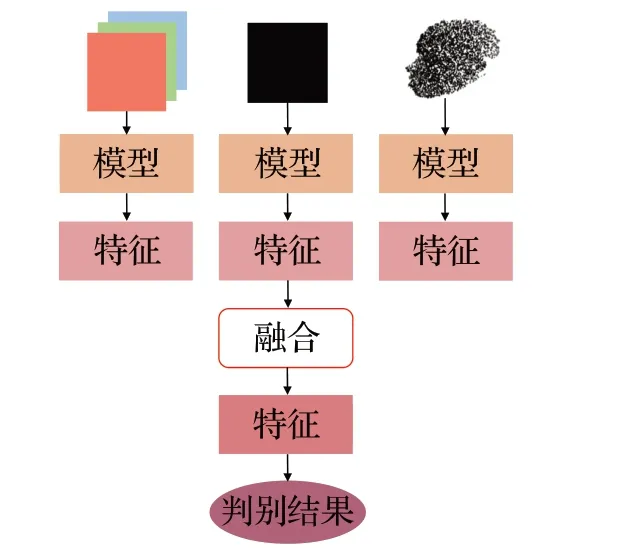
图21 特征融合流程Fig.21 Process of feature fusion
为了处理RGB 图像和点云数据,Xiao 等[84]提出Beauty3DFaceNet 网络,采用K近邻搜索算法对不同密度的点云样本分组,采用ResNet 模块提取RGB 图中的纹理特征,设计融合模块耦合二维、三维特征,匹配得到三维人脸的关键点。该模型较为轻量化,能从潜在空间中找到特征超平面,提高人脸识别质量,但该方法欠缺可解释性。Teng 等[85]提出多模态训练、单模态测试框架(multimodal training unimodal test,MTUT),基于ResNet 网络设计二维特征的编解码器,利用改进的PointNet网络处理点云数据,设计多模态嵌入发散损失函数对异质特征进行对齐耦合,可以自适应地避免冗余数据模态的干扰。
Niu等[86]设计了一种基于深度图像和曲率特征融合的人脸特征提取方法,将重建的三维人脸数据通过正交投影得到人脸深度图像,然后使用其平均曲率图来增强深度图像数据,利用改进的残差神经网络,将扫描的人脸与数据库中的人脸进行对比识别。该方法可以在无照明的情况下进行识别,但深度图像质量低时效果很差。
对于RGB 图像、点云及深度图数据,Guo 等[87]提出的自监督架构利用3 个分支编码器分别从数据提取颜色信息、几何特征和关键点,再利用形状解码器进行数据融合处理,构建出高质量的人脸模型,但对遮挡人脸重建不够鲁棒,无法恢复精细的面部细节,且模型复杂,运行时间长。Yang等[88]基于GAN建立空间强度增强和表情识别联合模型,将纹理特征和几何信息进行深度耦合,提升了识别精度。Sui等[89]提出了带掩码的自适应融合网络(adaptive fusion network with masks,AFNet-M),如图22 所示,利用网格匹配算法从三维数据中生成对齐的纹理和深度图像,由掩码注意力机制提取特征,在卷积层进行自适应的特征融合。该模型能够增强二维和三维空间局部特征,有效提高人脸识别能力,该方法参数量小、内存成本低,但对多模态数据的预处理过程较为繁琐。
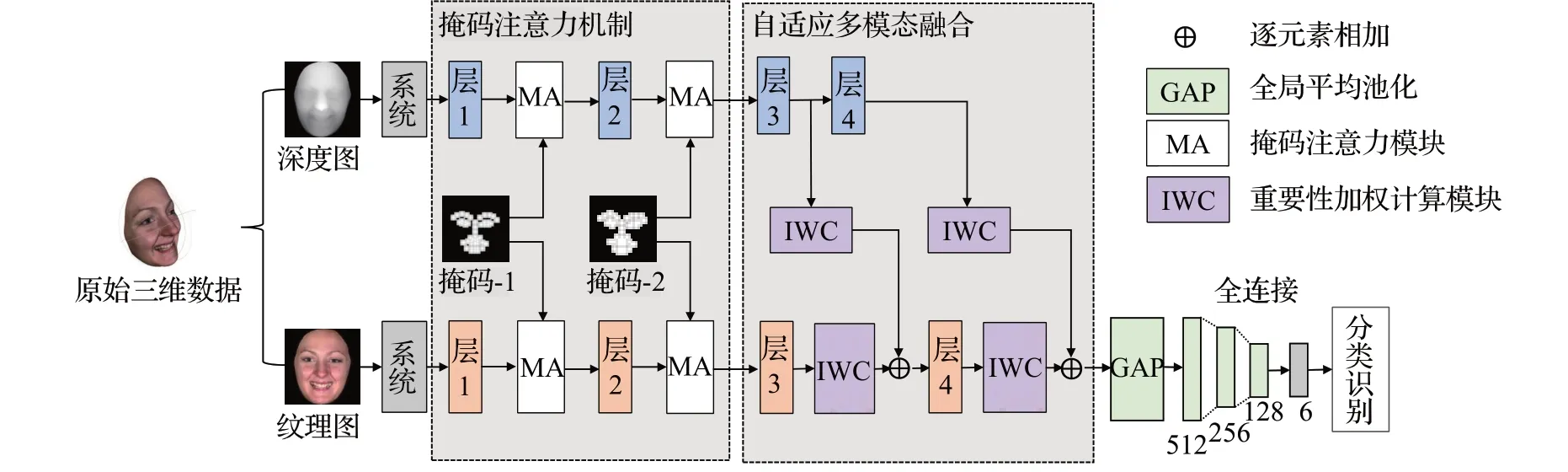
图22 AFNet网络Fig.22 AFNet network
1.4.3 模型融合
该类方法针对不同类型的数据,分别建立合适的模型,按照既定策略计算模型的得分,然后对得分进行加权融合,得到最终的识别结果,其流程如图23所示。
图23 模型融合流程Fig.23 Process of model fusion
Talab 等[90]基于局部描述算子设计人脸识别系统。该系统使用金字塔形状描述算子对三维数据进行分析。利用包含上下文结构信息的直方图匹配二维和三维数据,并在决策层进行数据融合,输入到基于稀疏表示的分类器中。该方法具有缩放、平移和旋转不变性,有效增强了模型的人脸识别性能。Liu等[91]使用深度神经网络获得RGB 图像的相似性得分,使用迭代最近点方法计算三维人脸模型的匹配度得分,对两个得分加权融合得到最终的识别结果。Tharewal 等[92]分别采用主成分分析法和独立成分分析法对三维人脸、三维人耳进行识别,并将得分进行融合得到最终的识别结果。该方法有效补充了人脸的三维信息,增强了识别效果。
2 人脸数据库
基于单目RGB图像的三维人脸识别在二维人脸数据库上进行,基于RGB-D数据、点云数据的三维人脸识别则需要三维人脸数据库。本章对常用的二维、三维人脸数据库进行介绍,详细阐述数据获取方式、数据类型等信息,分析重要方法在典型数据集上的表现。表2总结了常用的人脸数据库,对比了各数据库的数据类型、受试者数量及数据量、是否存在表情变化和遮挡等。

表2 常用人脸数据库Table 2 Common face database
2.1 二维人脸数据库
(1)无关键点标注
CASIA-WebFace[100]是从IMDb 网站上爬取图像并进行标注获得,包含10 575个人的494 414张人脸图像,包含不同角度、光照、国家、种族等信息,但该数据集图片表情单一,每个人的图片也较少。Celebrities in frontalprofle in the wild(CFP)[101]收集了500 位名人共7 000张图像,每人包含10 张正面图像和4 张侧面图像,具有不同的随机表情,但数据集较小。public figures face database(Pubg)[102]利用互联网搜索引擎获取200名公众人物的真实图像,在姿态、光照、表情、场景、成像条件等方面存在较大差异,具有年龄、性别、种族、发色等65个视觉特征属性。CAS-PEAL[103]具有99 594张彩色图像,由1 040名中国人组成,其中包括595名男性和445名女性,涵盖了姿态、表情、配饰、光照、背景、距离和时间等特征的变化,有灰度图和彩色图两个版本。WebFace260M[104]是目前最大规模的二维人脸数据集,从MS1M数据集中选取部分图像,结合IMDB数据库中选择的图像,组成了包含4百万受试者的2.6亿个人脸图像。通过自训练算法对该数据集进行自动提纯,获得WebFace42M[104]数据集,包含206万受试者的4 200万张图像,是目前最大的公开人脸识别训练集。labeled faces in the wild(LFW)[105]和Wider face[106]影响条件多,识别难度较大,LFW 包含5 749名知名人士的13 233张图像,其中1 680人具有2张及以上人脸图片,受多姿态、光照、表情、年龄、遮挡等因素影响;wider face由32 203张彩色图像构成,包括393 703张不同分辨率的人脸,在尺度、遮挡、姿态、光照、表情方面存在很大的变化范围,对每张人脸标注包含前额、下巴和脸颊的面部边界框,面部被遮挡时估计遮挡比例。
(2)有关键点标注
IARPA Janus benchmark A(IJB-A)[107]收集了500个受试者的5 712 张图像,手工标注面部检测边界框和双眼中心、鼻子底部3 个关键点,包含丰富的肤色、性别、面部姿势、遮挡(眼睛、嘴巴、鼻子、前额)和室内外环境信息。Celeb faces attributes dataset(CelebA)[108]具有超过20万名人脸图像,涵盖了大量姿态变化、背景杂乱的不同人脸,每个图像标注两个嘴角、双眼中心和鼻子5 个关键点,具有发色、眼睛形状、配饰等40 个属性。annotated faces-in-the-wild(AFW)[109]使用Flickr 网站图像建立人脸数据库,共包含205张人脸图像,其中有473个标记的人脸,每一个人脸具有方形边界框,标注了6个关键点和3 个姿势角度,如图24(a)所示[110]。annotated facial landmarks in the wild(AFLW)[83]是一个包括多姿态、多视角的大规模人脸数据库,提供了从Flickr网站收集的大量图像,包含不同的姿势、表情、种族、年龄、性别、环境等属性,在21 997 张真实的彩色图像中,共有25 993张人脸,每张人脸矩形框和椭圆框的脸部位置框,标注21 个关键点,如图24(b)所示[110],共380×103个关键点。labeled face parts in the wild(LFPW)[111]由网站下载的图像组成,包含1 132张训练人脸和300张测试人脸图像,大部分为正面人脸图像,每张人脸标注29个关键点,如图24(c)所示[110]。Helen facial feature dataset(Helen)[112]收集含有不同的姿势、照明条件、表情、遮挡和身份信息的面部图像,分为训练集和测试集,测试集包含了330张人脸图片,训练集包括2 000张人脸图片,每张人脸图片标注了68个关键点,如图24(d)所示[110]。

图24 不同数量的关键点Fig.24 Different number of key points
2.2 三维人脸数据库
(1)单一类型3D人脸数据库
Fine-grained 3D face(FG3D)[57]将3DMM模型拟合到FRGC、BP4D和CASIA-3D数据集的RGB-D图中,补全空间信息和网格信息,生成包含212 579个样本的大型三维人脸数据集。Northwestern Polytechnical University 3D(NPU3D)[113]包含300名中国人面部信息,每个人有35组不同的扫描数据,具有多种姿势、面部表情、配饰和遮挡。GavabDB[114]包括45名男性和16名女性的549组三维网格人脸数据,每个受试者分别采集9幅不同姿态、角度、表情的数据。SHREC11[115]从6 个不同角度扫描130个面具获得,没有表情变化,包含的信息较少。
(2)多模态3D人脸数据库
高质量的三维扫描数据能够提供丰富的面部信息。三维网格是常见的三维扫描数据,为了获得纹理信息,数据库中包含了二维彩色图像。Florence[116]从结构化光扫描系统获取53名受试者面部数据,包括高分辨率三维网格数据和不同分辨率、不同条件、不同缩放级别的二维视频序列。University of York 3D face database(UoY)[117]采用双目立体系统收集350名受试者超过5 000组彩色图像和三维网格数据,每人具有8 种面部表情和姿态变化。BJUT-3D[118]包含1 200名中国人的三维面部数据,所有人脸数据均为中性表情,没有配饰和遮挡。
Bosphorus[119]和LS3DFace[120]数据库收集了三维人脸点云数据。Bosphorus 通过结构光设备采集105 名受试者的4 666组人脸点云数据,每个人脸最多有35种表情以及不同的姿态,590组面部数据被眼镜、帽子、围巾和手等各种物体遮挡。LS3DFace从10个公共数据集中爬取数据,创建了包含1 853 个受试者共31 860 组点云数据,包含了表情、姿势、遮挡、缺失数据、传感器类型,也有少量同卵双胞胎数据。
基于高质量三维扫描数据的人脸识别方法由于受设备成本和采集方式等因素影响,在现实场景中无法大规模应用。基于低成本RGB-D相机的人脸识别方法能够在更多场合下使用。University of Milano Bicocca 3D face database(UMBDB)[15]包含143名受试者的1 473对RGB-D数据,其中,二维图像具有眼角、嘴角、鼻尖7个关键点。IIIT-D数据集[121]利用Kinect采集106名成人的图像和深度图,每人有11到254张RGB-D图像,具有多种表情变化。3D twins expression challenge(3DTEC)[122]包含107 对面孔相似、表情不同的双胞胎的面部信息,该数据集非常具有挑战性。Texas-3D[123]包含1 149对使用立体相机采集的118名成人受试者的高分辨率、姿势归一化、预处理和完全对齐的彩色和深度图像,具有丰富的性别、种族、面部表情以及25 个面部关键点。face recognition grand challenge(FRGC-v2.0)[124]数据库中,二维训练集由222名受试者的12 776幅图像组成,三维训练集由943名受试者的三维数据组成,三维验证集包含466名受试者的4 007组三维数据。Lock3DFace[125]中的三维样本具有很高的噪声,并且包含表情、姿势、遮挡、光照、时间流逝等多种变化,适合在复杂情况下进行人脸识别算法评估。FIDENTIS 3D face database(F3D-FD)[126]收集了2 476 名受试者的三维面部扫描数据,其中包含1 322名女性,成年1 305人,且大多小于26岁,没有配饰和遮挡,保持中性表情,从3个角度进行收集。KinectFaceDB[127]提出了第一个基于Kinect 传感器的公开人脸数据库,该数据库由不同的数据模式和9种面部变化组成,包括52 名受试者的936 组RGB-D、点云数据和104个记录面部姿态变化的视频序列。
4DFAB[128]和FaceScape Dataset[30]收集了视频人脸数据。4DFAB是一个大型动态高分辨率3D人脸数据库,包含60名男性、120名女性,采集了180万个三维网格人脸,具有年龄、种族、文化背景等多个属性。FaceScape Dataset包含938名受试者的18 760个三维人脸,每个人脸都有20个特定的表情。
对于三维人脸识别任务,通常采用识别精度进行模型评估,即计算正确识别的人脸在全部人脸中的比例,表3 按时间顺序总结了重要方法在典型数据集上的识别精度。
对于从单目RGB图像中进行人脸重建并识别的方法,识别精度与重建质量息息相关。均方根误差(rootmean-squared error,RMSE)常用于评估重建质量,计算公式为:
其中,a、b代表两组数据,M、N代表数据尺寸,RMSE的值越小说明重建效果越好,识别性能相应更好。此外,结构相似性(structural similarity index measure,SSIM)[129]也常被用来评估两组数据的相似程度,值越大表明相似性越高,说明重建效果越好,其计算公式如下:
其中,μa、μb代表对应数据的局部均值,σa、σb代表标准差,σab代表两组数据的协方差,α、β、γ为正值权重,C1、C2、C3为常数,避免分母为0。表4 按照时间顺序总结了重要方法在典型数据集上的重建性能。
3 结语
本章基于人脸数据的不同类型,对比分析各类人脸识别方法的优缺点,讨论了三维人脸识别过程中面临的主要挑战,以及未来的研究方向。
基于单目图像重建三维人脸模型的方法,可以在三维空间进行识别,相较直接识别二维人脸图像的方法效果更好,但将人脸图像从二维空间提升到三维空间时,面临着信息孔洞、三维注释信息不足等困难,识别的准确性严重依赖算法恢复的深度数据精度,且建模过程通常比较耗时。此外,传统的人脸重建与三维人脸识别过程相互独立,导致人脸姿态多样性识别能力较弱,具有局限性。基于点云数据的三维人脸识别模型通常体量较小,识别速度较快,但受设备成本和采集方式等因素影响,在现实场景中无法大规模应用,如何克服点云数据的无序性和刚性变换不变性仍是较大的挑战。RGB-D相机可以以较低的成本直接、快速地获取RGB-D数据,因此基于RGB-D数据的三维人脸识别技术能够应用于更多的场合,但是如何克服RGB-D 数据的低质量问题仍值得进一步研究。多模态人脸数据包含更加丰富的信息,能够有效提升人脸识别的准确率和鲁棒性。如何融合多模态数据、处理异质特征是利用多模态数据进行人脸识别的关键问题。
三维人脸识别目前面临的主要挑战有:
(1)三维人脸数据库不足的问题。三维人脸扫描仪价格昂贵,收集耗时长,且需要受试者长期保持固定姿势或表情,限制了数据集的大规模推广。目前公开的三维人脸识别数据库较少,规模较小,在表情、姿态、遮挡等方面也存在一定的局限性,不能满足深度学习模型的训练需要。此外,三维人脸数据库由于采集数据的设备、收集数据的方法、获取数据的质量、处理数据的步骤、储存数据的格式等不尽相同,因此各个数据库之间的通用性较低。如何在无约束条件下以较低的成本和较快的速度创造大规模三维人脸数据集、研究三维数据增强方法是进一步探索的方向。
(2)人脸属性的影响。不同的表情情绪、肤色肤质、面部朝向、化妆、照明及遮挡情况对三维人脸识别精度有很大的影响,决定了三维人脸识别模型的迁移性。现有的大多数方法聚焦人脸刚性区域,采用不同的内外属性进行渲染,造成一定的信息损失。因此,如何提高三维人脸识别模型的速度、鲁棒性、泛化性是需要进一步研究的问题。
(3)跨年龄识别问题。对于同一个识别目标,其少年、中年、老年各个阶段的人脸存在显著差异,这使得跨年龄人脸识别成为一大难点。目前主要解决方案是使用生成模型生成目标年龄段的人脸图像辅助跨年龄人脸识别,但该方法较为复杂,计算成本高,识别精度不高。因此,如何使识别模型能够适应跨年龄人脸识别,是需要进一步研究的问题。
(4)人脸活体检测功能。在实际应用中,活体检测是必不可少的一个环节。如何提高三维人脸识别模型的活体检测能力,抵御照片、视频、面具、三维蒙版等欺诈攻击是一个重要的研究方向。活体检测与人脸识别技术之间的关系,也值得进一步地探究。
(5)多模态融合问题。有研究表明[130],数据融合可以充分利用不同模态信息,因此识别效果优于特征融合与决策融合。但目前的多模态研究集中在决策融合,因此需要进一步探索数据融合方法。此外,利用多模态数据中提取的多维特征进行识别时,必须计算出其中最具代表性的特征,使得类内距离最小、类间距离最大,因此,在特征匹配与融合过程中,需要进一步研究特征空间的压缩方法,提高特征提取的性能与效率。
(6)细节重建与识别问题。在嘴唇、口腔内部、眼睑、头发造型和完整头部的重建与识别等方面缺乏研究,制约着三维人脸识别性能。因此,如何增强五官与头部细节的差异化重建与识别,是需要进一步研究的问题。
猜你喜欢
作文中学版(2022年1期)2022-04-14
少儿美术·书法版(2021年9期)2021-10-20
学生天地(2020年31期)2020-06-01
计算机应用(2019年3期)2019-07-31
动漫星空(2018年9期)2018-10-26
软件导刊(2016年9期)2016-11-07
科技视界(2016年2期)2016-03-30
计算机工程(2015年8期)2015-07-03
发明与创新(2015年33期)2015-02-27
奇闻怪事(2014年5期)2014-05-13
