
邻域信息修正的不完整数据多填充集成分类方法
2023-12-11 07:11朱先远严远亭张燕平
计算机工程与应用 2023年23期
朱先远,严远亭,张燕平
1.安徽商贸职业技术学院 信息与人工智能学院,安徽 芜湖 241002
2.安徽大学 计算机科学与技术学院,合肥 230601
数据分类是机器学习、数据挖掘和模式识别等领域的重要任务[1-2],但由于数据收集、网络传输等,人们拿到的待分类数据往往都有一定程度的不完整性,这类数据称为不完整数据集,如:微阵列数据[3-4]、移动电话数据[5]、可视化数据[6]、工业数据[7]、软件项目数据[8]等。对不完整数据集分类首先需要对其进行预处理再分类。不完整数据集预处理常用方法有删除法和填充法两类方法。删除法即直接删除含有缺失值的数据样本,数据集中只保留信息完整的数据样本。在数据样本获取代价较高情形下,删除含有缺失值的数据样本会造成数字资源浪费和有用信息的丢失。填充法是利用一些经典填充算法对不完整数据集中的缺失值进行估计填充。在不完整数据分类前利用填充算法将不完整数据填充为完整数据可以提高分类精确度[9]。不完整数据的填充算法研究,对不完整数据分类具有重要现实意义。
目前,针对不完整数据集的缺失值填充已积累了不少研究成果[10-14],这些成果在缺失值填充上多是基于统计学指标和机器学习算法。如均值填充(mean imputation,MEI)[15],其用数据样本中非空属性值的均值对缺失值进行填充,其一般适合缺失值极少情况或者需要快速填充的场景,类似地还有矩阵分解填充(imputation iterative SVD,ISVD)[16]、SoftImput[17]等,利用矩阵分解技术,对数据进行降维,然后在降维后的数据矩阵利用统计学指标来估计缺失值。在机器学习填充算法中,数据样本空间中完整数据样本作为训练和测试的输入,待填充的空缺值被看作是模型的目标输出,常见的算法有K最近邻填充(Knearest neighbor imputation,KNNI)[18]、聚类填充(CKNNI)[19]、决策树填充等。K近邻填充利用离缺失样本最近的K个邻居样本产生一个估计值进行填充,在数据填充问题上不需要复杂模型,但其在不平衡数据问题上表现效果不佳。聚类填充是将所有样本聚类到若干个簇中,利用簇内相似度较高的完整样本对缺失值进行填充。其一定程度上考虑了样本空间分布,但其初始聚类中心数依赖于样本数据,不同样本数据进行调参过程复杂多变,难以控制。
这些经典数据填充算法目前已被广泛应用于解决不完整数据的填充问题。但这些研究方法在不完整数据分类的缺失值填充处理上,往往都是选择一种填充方法进行填充,很少考虑融合多种填充方法。此外,相邻的数据样本属性值具有相关性,如何快速有效地找到缺失样本的近邻数据样本,用这些近邻数据样本邻域信息对缺失值进行填充仍需做进一步研究。
结合对不完整数据分类问题的上述考虑,本文提出一种基于邻域信息修正不完整数据多填充集成分类方法。该方法一方面通过嵌入基于邻域信息的修正填充策略,实现了利用近邻数据样本邻域信息对缺失值的填充,另一方面也利用多填充的数据多样性,通过集成学习融合了不同经典填充方法的优势。
1 相关工作
1.1 不完整数据集及相关预填充方法
预填充和修正填充主要都是以不完整数据集的缺失值为对象,为了方便描述,这里先给出一个不完整数据集和缺失值集合的定义。
定义1(不完整数据集)D={X1,X2,…,Xn} 表示一个不完整数据集,其中,n表示数据样本的数量,Xi表示一个数据样本,每个数据样本由m个属性组成,为不完整数据集D的第i个数据样本的第j维属性值,表示数据集中第i个样本的第j维属性值为空,即缺失值。
定义2(缺失值集合)给定一个不完整数据集D={X1,X2,…,Xn},所有缺失值的集合IND为:
对不完整数据进行预填充,就是利用一些经典填充算法对不完整数据集D的缺失值集合IND中所有元素进行填充。下面给出几种常用预填充算法的定义。
定义3(均值填充(MEI))[15]一种简单的基于统计学的单一填充方法,适用于快速完成数据填充需求,对缺失值的计算如公式(2)所示:
其中,I为第k维属性值非空的数据样本集合,|I|为第k维属性值非空的数据样本的个数。
定义4(中值填充(median imputation,MDI))[15]一种缺失值处理方法,它使用样本数据中的中位数来填补缺失值。对缺失值的计算如公式(3)所示:
其中,I为第k维属性值非空的数据样本集合,I*为集合I中进行排序后集合。
定义5(矩阵分解填充(ISVD))[16]一种基于矩阵分解的缺失值填充方法,它采用奇异值分解(SVD)来分解矩阵,并使用迭代过程逐步重建缺失值。
定义6(K近邻填充(KNNI))[17]一种基于KNN 算法的一种缺失值填充方法,对缺失值的计算如公式(4)所示:
其中,Ni表示的是第j维属性不缺失且距离第i个样本最近的k个样本集合;|Ni|表示的是Ni集合中的样本个数。
定义7(相似度加权平均填充(similarity weighted averaging impute,SWAI))[20]一种基于相似性的插补方法,它的基本思想是利用与含缺失值样本相似的完整样本对缺失值进行填充。在这种方法中,对于每个缺失的数据样本,先寻找与该样本相似的其他数据样本(通常是欧几里德距离或余弦相似度等度量方法),然后对这些相似数据样本的已知值进行加权平均以获得缺失值的估计值。
其中均值填充、中值填充都属于基于统计学指标的填充策略;ISVD 为矩阵分解填充策略的代表;K近邻填充属于使用机器学习算法进行填充策略;相似度加权平均填充是利用样本间的相似性来推断缺失值,在基因表达数据集上测试结果十分优异的填充算法代表。
1.2 修正填充相关方法
修正填充是对不完整数据进行预填充后,进一步对填充值进行修改和优化的过程。在相关研究中,Liu等[21]提出了一种基于两阶段深度自动编码器的缺失数据插补方法。该方法可以分为两个阶段:第一阶段利用已知数据训练一个深度自动编码器,以学习数据的潜在表示。然后使用该自动编码器来重构缺失数据,并计算真实数据和重构数据之间的重构误差。在第二阶段,使用另一个自动编码器来进一步优化缺失数据的重构,以减小重构误差。严远亭等[22]提出了一种构造性覆盖下不完整数据修正填充方法。首先利用现有填充方法对样本进行预填充;然后再通过引入一种空间邻域信息挖掘方法来找到与待填样本具有更高相似度的若干个空间邻域;最后利用待填样本的空间邻域内的有效信息对现有填充方法产生的填充结果进行修正。Choudhury等[23-24]基于神经网络给出分类任务中的缺失数据填充方法。该方法使用已知数据进行训练构建一个神经网络结构。然后,通过在神经网络中进行信息传播和融合的方式,将已知数据的信息传递给缺失数据样本,以预测和修正填充缺失值。该方法可以利用全局信息和数据的内在结构,提高修正填充的准确性。
除了上述方法,还有其他修正填充方法,每种方法都有其独特的特点和适用场景,选择合适的方法需要考虑数据集的特征、缺失值的模式以及应用需求等因素。
1.3 集成学习方法
集成学习(ensemble learning)[25]就是组合多个弱监督模型以期得到一个更好、更全面的强监督模型,研究始于1990年,是由Hansen和Salamon[26]提出的神经网络集成的方法。集成学习潜在的思想是即便某一个弱分类器得到了错误的预测,其他弱分类器也可以将错误纠正回来。按照用于集成学习算法中的基分类器是否相同可以将集成学习划分为同质集成和异质集成。同质集成是指构成集成的所有基分类器都是同一种分类器,而异质集成是指使用不同的分类器构成集成学习。当前已有的集成学习方法中,同质集成学习最为常见。同质集成学习又可以根据各个体学习器间是否存在依赖关系分为两类:存在强依赖关系的个体学习器和不存在强依赖关系的个体学习器。前者的典型代表算法为Boosting算法[27];后者的典型代表算法有Bagging算法[28]。
Boosting 算法是将弱学习器提升为强学习器的算法。主要的工作机制:首先利用初始训练集训练出一个弱学习器T1;再根据T1 的表现对训练样本分布进行调整,依据学习误差率来对训练样本的权重进行更新,让先前被T1判断错误的样本在后续学习中得到更多的关注。
Bagging 算法是另一种典型的集成学习策略,是从训练集进行子抽样组成每个基模型所需要的子训练集,来训练个体学习器(弱学习器),其主要工作机制:从原始样本集中抽取训练集;每次使用一个训练集得到一个模型,k个训练集共得到k个模型;对分类问题:将上步得到的k个模型采用投票的方式得到分类结果,对回归问题,计算上述模型的均值作为最后的结果。
集成方法是将几种机器学习技术组合成一个预测模型的元算法,以达到减小方差(Bagging)、偏差(Boosting)或改进预测(Stacking)的效果。集成学习的结合策略根据处理问题的差异,可以采用平均法、投票法[29]和学习法等。其中投票法是集成学习中最基础的方法之一,其又分为硬投票和软投票。硬投票是指取预测结果中票数最高的类别作为集成结果。软投票则是将基分类器的预测概率加权平均作为最终的预测结果。虽然软投票方法的效果会更好一些,但在实际运用中需要耗费更多的计算资源和时间,因此硬投票方法使用更为广泛。鉴于以上考虑,本文采用了硬投票策略对几个分类器预测的结果进行投票。
2 邻域信息修正的不完整数据多填充集成分类方法
本章将从不完整数据集成分类总体框架、不完整数据修正填充和多填充集成分类三方面,对本文提出的基于邻域信息修正的不完整数据多填充集成分类方法做具体介绍。
2.1 不完整数据集成分类总体框架
本文提出邻域信息修正的不完整数据多填充集成分类框架如图1所示。其主要包括预填充、修正填充和集成分类等模块组成。
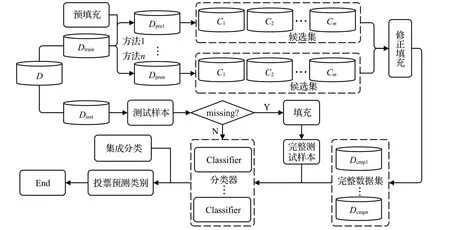
图1 邻域信息修正的多填充集成分类框架Fig.1 Multiple imputation-revision ensemble classification framework with neighborhood information
对于一份原始不完整数据集D划分为训练集Dtrain、测试集Dtest。对于训练集Dtrain,首先根据1.1节中介绍的五种经典缺失值填充算法(MEI、KNNI、MICE、SWAI和ISVD)进行预填充。对于同一个Dtrain每使用一种填充方法进行预填充都可以得到一个完整数据集,若使用n种预填充方法将可以得到一组完整数据集{Dpre1,Dpre2,…,Dpren}。在预填充后、数据分类前的阶段本框架嵌入了修正填充模块,利用该模块对{Dpre1,Dpre2,…,Dpren}中的填充值做进一步修正,修正填充后可以得到一组完整数据集{Dcmp1,Dcmp2,…,Dcmpn}。最后,该框架引入集成学习方法,将多填充得到的完整数据集集合{Dcmp1,Dcmp2,…,Dcmpn}分别作为输入,分别训练基分类器,最终通过集成投票策略给出最终分类。在测试阶段,对于一个测试样本,首先判断其是否包含缺失值,如不包含缺失值,则直接输入集成分类器确定类别,如包含缺失值则先进行预填充,然后利用已训练的分类器进行集成分类,投票确定其类别。
2.2 不完整数据修正填充
本文提出的修正填充主要思想是以与缺失值高相关性的近邻样本信息为依据,对缺失值进行再估算。要解决的关键问题是在预填充得到的完整数据集Dpre中找出与待填充样本高相关性的近邻数据样本集合。K近邻算法填充是依据距离大小搜索最近的K个邻居,但对于不平衡数据集搜索时,K近邻算法决策结果容易被其周围的多数类近邻样本所误导。为了避免在搜索不平衡数据集出现同样问题,本文在搜索与待填充样本高相关性的近邻数据样本时,除了考虑样本空间距离因素外,还融合了候选样本集中的类别纯度因素。此外,为了方便在高维空间中快速搜索到近邻样本,在修正填充过程中还引入球树[30]。为了方便描述,这里先给出球树、纯度和邻域半径的定义。
定义8(球树(BallTree))一种二叉树,其每个节点表示一个d维的超球面,或称为球,球树的每个内部节点将数据点集合划分为两个不相交的集合,这两个集合与不同的球相关联。当球本身可能相交时,每个点根据它到球心的距离被分配到其中一个球中。树中每个叶节点定义了一个球并枚举该球内的所有数据点。
球树的主要优点在于它能够快速地定位到距离查询点最近的一些数据点,对于高维数据具有较好的性能,因为它能够避免在高维空间中出现“维度灾难”问题。
定义9(纯度(purity))对于由若干数据样本点构成的超球体,纯度是指球心同类别的样本点在超球体内的占比,即待填充样本点的候选集中与待填充样本点同类别的点在候选集中的占比,纯度计算公式如公式(5)所示:
其中,|B|表示超球体内的样本点数,yi表示样本点Xi的类别,yB表示超球体球心类别,I是一个指示函数,当yi=yB时取值为1,否则为0。
定义10(邻域半径(R))对于由若干数据样本点构成的超球体,邻域半径是指超球体的半径,即一个数据样本与其相邻样本共同构造的邻域空间的半径。对于一个完整数据集Dpre={X1,X2,…,Xn},邻域半径初始值R0的计算如公式(6)所示:
其中,n表示的数据集Dpre样本数,d(Xi,Xj)表示Xi,Xj两个样本间的欧氏距离。
本文提出的基于邻域信息修正填充方法是首先利用球树作为样本点间距离的存储结构,将所有数据样本点划分到一组嵌套的超球体内,通过纯度purity和邻域半径R,找出与缺失样本相邻的数据样本,从而利用与缺失样本相邻的数据样本信息对缺失值进行修正填充。具体基于邻域信息修正填充方法如下:
(1)利用公式(6)计算邻域半径初始值R0。
其中,min{d(Xi,Xj)}为与待填充样本的所有同类别的样本欧式距离的最小值,经过迭代计算邻域半径R不断接近min{d(Xi,Xj)}。
(3)对缺失值进行修正填充。对于一个含缺失值的数据样本Xi,假定经过步骤2 后得到候选集为Candidate,则的计算如公式(8)所示:
其中,SETsc为候选集Candidate中与待填充样本同类别的所有样本组成的集合,|SETsc|表示集合SETsc中样本数量,当|SETsc|≠0 时,缺失值用候选集中所有与待填充样本同类别的样本第j维属性值的均值对其进行修正填充。在少数情形下|SETsc|=0,即候选集内没有与待填充样本同类别的数据样本,对于这类特殊情形不做修正填充,保留预填充值。
(4)重复步骤(2)、(3),直到完成所有缺失值的修正填充。
2.3 多填充集成分类
同一个不完整数据集经过不同的预填充和修正后,得到了一组互不相同的完整数据集{Dcmp1,Dcmp2,…,Dcmpn}。为了融合不同填充算法的优势,本文引入基于bagging 的集成学习策略,将{Dcmp1,Dcmp2,…,Dcmpn}中每一个Dcmpi均作为一个基分类器的输入,以此训练n个基分类器,最终通过集成学习的投票策略给出最终分类。多填充集成分类(multiple imputation ensemble classification,MIEC)算法伪代码如算法1所示。
算法1多填充集成分类算法
3 实验
3.1 评价指标
本文选取NRMSE 评价指标对不完整数据集的填充效果进行评价,选取Accuracy对不完整数据的分类精确度进行评价。NRMSE和Accuracy的定义如下:
(1)NRMSE
其中,xo和xg分别为数据集中缺失值对应的原始值和被填充后的估计值。NRMSE值可以衡量出对缺失值的填充效果,值越小则代表填充的数据越接近原始值。
(2)Accuracy
其中,TP表示预测为正样本实际也为正样本的数量,TN表示预测为负样本实际也为负样本的数量,P和N分别表示正样本数量和负样本数量。Accuracy表示预测类别正确的样本数量占所有样本数量的比例,值越大则代表分类越好。
为了方便对比不同算法对不完整数据集的分类精确度,本文引入了精确度提高率(ImproveRate)概念,用来表示本文提出算法相对于其他分类算法的精度改善程度。
其中,Accuracy为本文提出算法的分类精确度,Accuracylevel为其他对比算法的分类精确度。ImproveRate若为正值,则表示本文分类算法分类精确度有提高,若为负值则表示本文分类算法分类精确度不如对比方法。
3.2 基准数据集下算法性能分析
对于真实不完整数据集,由于缺失值所对应的原始数据丢失,难以评估出填充算法的填充值与数据集原始值的拟合程度。为了方便评估缺失值填充实验的填充效果,实验时采用对完整数据集随机删除属性值来模拟不完整数据集,最后通过对比填充算法给出的填充值与原始值的归一化均方根误差来评估算法填充效果。实验时从UCI 选取10 个完整数据集作为基准数据集,如表1所示。

表1 基准数据集Table 1 Benchmark dataset
这10个数据集涉及不同领域,数据集规模、数据特征数各不相同,样本数量规模从178 至13 611 个,样本属性数量从3 至32,样本类别数量从2 分类至13 分类,其中ecoli、haberman、vertebral 为不平衡数据集。实验时按照1%、5%、10%、20%这4 种不同缺失率对数据集的样本属性值进行随机删除,模拟生成不同缺失率的不完整数据集。
3.2.1 算法填充效果实验
为验证本文提出的不完整数据多填充集成分类方法中嵌入的修正填充算法效果,实验时将1%、5%、10%、20%这4 种缺失率的不完整数据集作为输入,在嵌入修正填充前后分别计算NRMSE 值做对比实验。实验时首先采用1.1 节介绍的MEI 填充、MDI 填充、KNNI 填充、SWAI填充和ISVD填充5种经典填充方法对输入数据集进行预填充,并根据公式(9)计算NRMSE值,然后再利用本文2.2 节给出的修正填充方法进行修正填充,并根据公式(9)计算修正填充后的NRMSE 值。图2 为不同缺失率下的10种数据集上嵌入修正填充前后的填充效果对比图。其中,每个颜色柱的高度值为该填充算法的NRMSE值,MEI表示均值填充,R-MEI填充表示先均值填充再基于邻域信息修正填充,MDI 表示中值填充,R-MDI 填充表示先中值填充再基于邻域信息修正填充,KNNI 表示K近邻填充,R-KNNI 表示先K近邻填充再基于邻域信息修正填充,ISVD 表示矩阵分解填充,R-ISVD 表示先矩阵分解填充再修正填充,SWAI 表示相似度加权平均填充,R-SWAI 表示先相似度加权平均填充再修正填充。为了避免了单次实验得到的NRMSE 数据不稳定性,实验得到的NRMSE 值均为循环100次实验获取数据的均值。
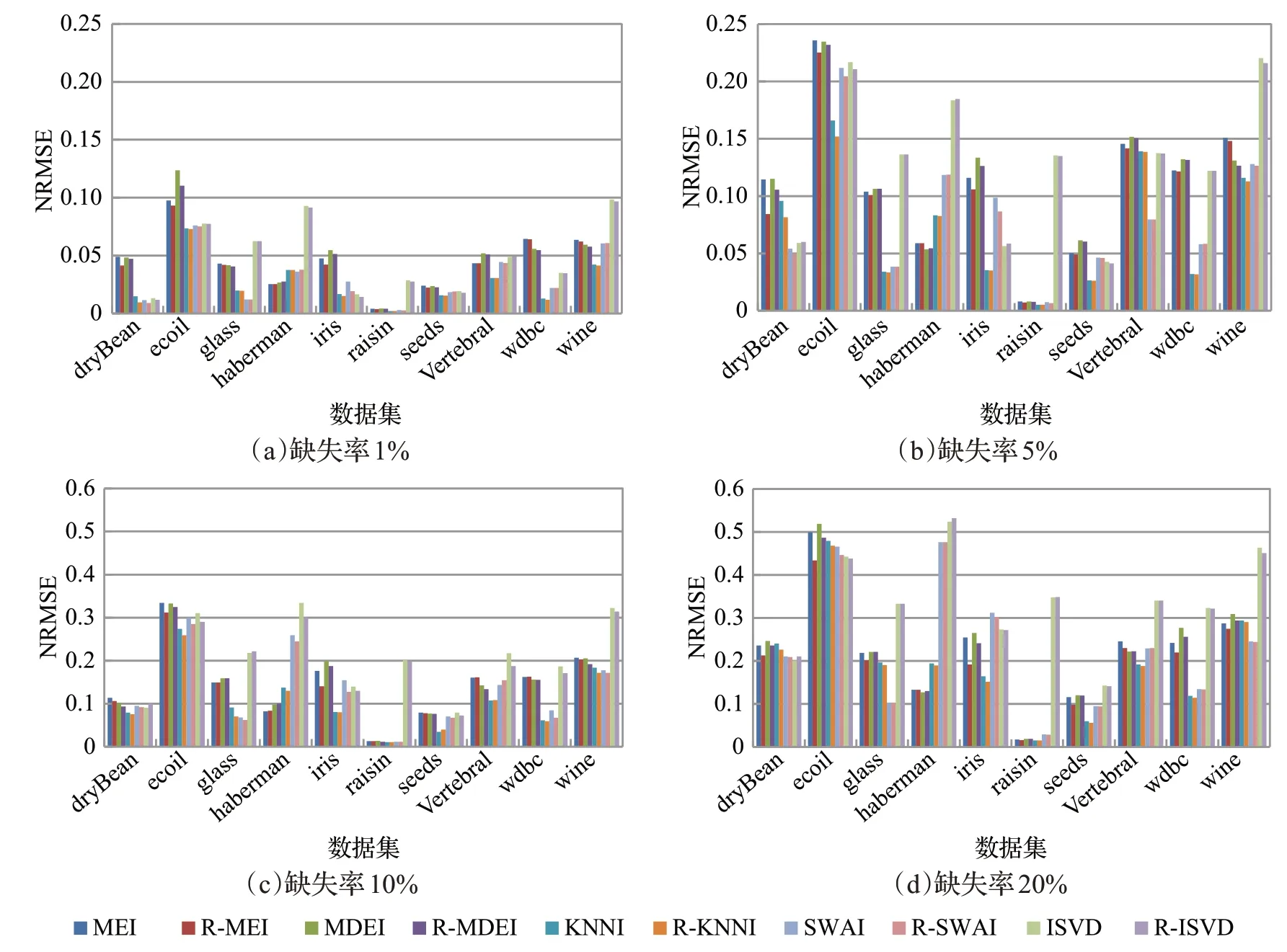
图2 填充效果对比图Fig.2 Comparison diagram of imputation effects
从同一缺失率、某种数据集上各种填充算法嵌入修正填充前后的填充效果对比来看:R-KNNI 与KNNI 相比、R-MEI 与MEI 相比及MDI 与R-MDI 相比,在多数不完整数据集上嵌入修正填充后所表现出来的NRMSE值都较小,填充过效果较好,剩余少数数据集填充效果接近;R-SWAI 与SWAI 相比、ISVD 与R-ISVD 相比,在多数数据集上进行修正填充后的NRMSE 值略小或近似相等,即填充效果有小幅提升或接近。从图2(a)、(b)、(c)、(d)图整体看,在ecoli、haberman、vertebral、wine 数据集上相比于其他数据集的算法填充NRMSE值都较大,究其原因,像wine 数据集的样本量只有178个,用于填充可依据的数据样本信息较少,所以填充的NRMSE 值都较大,填充效果欠佳。像ecoli、haberman、vertebral数据集为不平衡数据集,不平衡数据集中缺失值如果为少数类时,填充容易受到多数类影响,所以一般来说填充算法在不平衡数据集上填充效果都较一般,但就嵌入修正填充后的R-MEI、R-MDI、R-KNNI、R-SWAI、R-SVD 的几种算法修正效果,相比于MDI、KNNI、SWAI、SVD来说,在多数不平衡数据集上填充效果都有提高。总体来说,嵌入修正填充相比于单独采用MEI、MDI、KNNI、SWAI和ISVD算法填充,在大多数的不完整数据上的填充效果都有提高。
3.2.2 不完整数据分类精确度实验结果与分析
为验证本文提出的邻域信息修正的不完整数据多填充集成分类方法在解决不完整数据集分类问题上的效果,本小节在表1给出的10种基准数据集上做了精确度提高率对比实验。实验时首先采用MEI填充、MDI填充、KNNI填充、SWAI填充和ISVD填充5种算法填充得到五份完整数据集对某种分类器(本实验数据采用KNN 作为分类器得到,采用其他分类器可以得到类似实验结果)进行训练,得出分类精确度;然后将预填充的5份数据集再进一步修正填充得到对应完整数据集,并利用最终得到的5份完整数据集对5个基分类器进行训练,得出分类精确度;最后根据公式(11)计算出本文提出的多填充集成分类方法相对于其他分类方法的精确度提高率。图3 为在10 种不同缺失率的不完整数据下算法分类精度提升率对比图,其中,MEI、KNNI、SWAI、MED和ISVD这5种颜色柱,分别表示使用本文提出邻域信息修正的不完整数据多填充集成分类方法相比于采用一种算法单填充后的分类精度提高率,如果颜色柱位于x轴上方表示本文提出的分类算法提高了分类准确率,反之则表示算法的分类效果不理想。
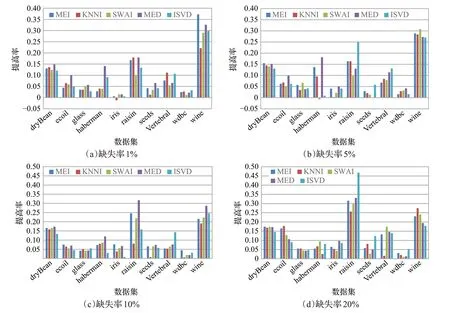
图3 分类精度提升率对比图Fig.3 Comparison diagram of classification accuracy improvement rates
从最终实验结果看,本文提出的邻域信息修正的不完整数据多填充集成分类方法的精确度,在4种缺失率的10 种不完整数据集上,只有两个颜色柱位于x轴下方,其余198个颜色柱都位于x轴上方。也就是说本文提出的邻域信息修正的不完整数据多填充集成分类方法,基本上都比仅采用某种算法单填充后分类的分类精确度要高。尤其是在raisin、wine数据集上,算法的分类精度提升率最明显。结合3.2.1小节填充效果实验结果看,wine数据集在进行3.2.1小节填充效果实验时,各种填充算法填充效果都不理想。然而,在本节分类精度提升率实验中,采用本文提出的分类算法后,其分类精确度有了明显的提高。这表明,本文提出的融合不同填充算法的多填充集成分类算法是有效的,提高了不完整数据集分类精度。
3.3 真实不完整数据集下对比实验及结果分析
在这一节中,为验证本文分类算法对解决真实不完整数据分类问题的有效性,从UCI 中下载了10 个真实不完整数据集进行实验,数据集的详细信息如表2 所示。这10 个数据集规模、数据特征数各不相同,样本数量规模从32 至2 536 个,样本属性数量从6 至279,样本类别数量从2分类至16分类,缺失率从2.2%至98.1%,这10 个数据集除了horse-colic、lung-cancer 和primarytumor均为不平衡数据集。
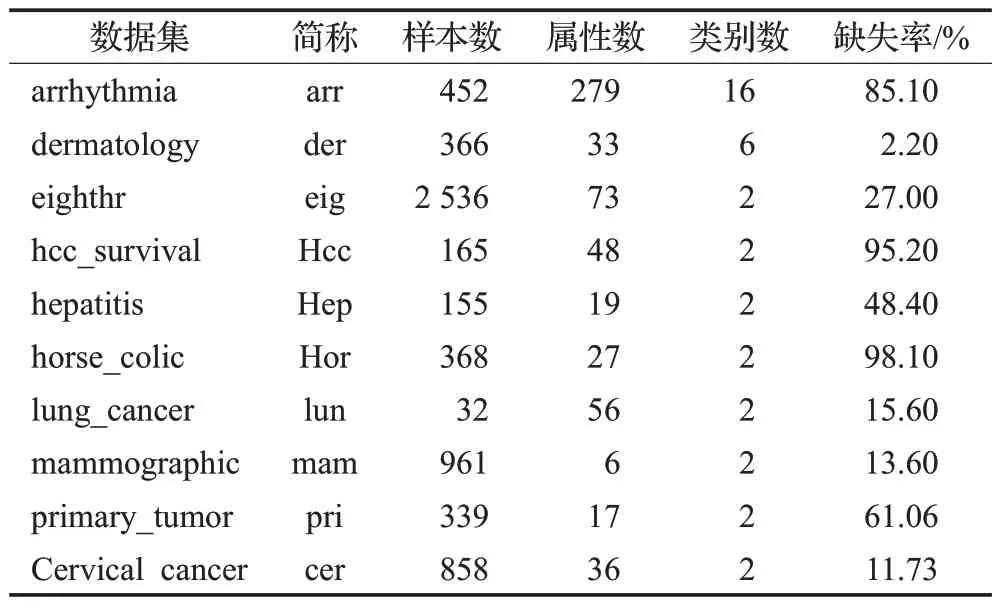
表2 真实数据集信息描述Table 2 Real dataset information
实验过程中先分别用MEI、MDI、KNNI、SWAI 和ISVD 填充算法进行预填充,得到5 份完整数据集。然后这5 份完整数据集作为输入,并分别在KNN、RandomForestClassifier(RF)、SVM、DecisionTreeClassifier(DT)和LogisticRegression(LR)这5 种分类器中进行分类实验,根据公式(10)计算分类精确度;然后再利用本文2.3 节算法1(MIEC)进行多填充集成分类实验,根据公式(10)计算分类精确度。实验中采用10倍交叉验证方式将数据集分为训练集和测试集。表3至表7记录了这10种真实不完整数据集在5种分类器中分类精确度,每张表的最后一行给出了各种数据集下分类精确度的均值。
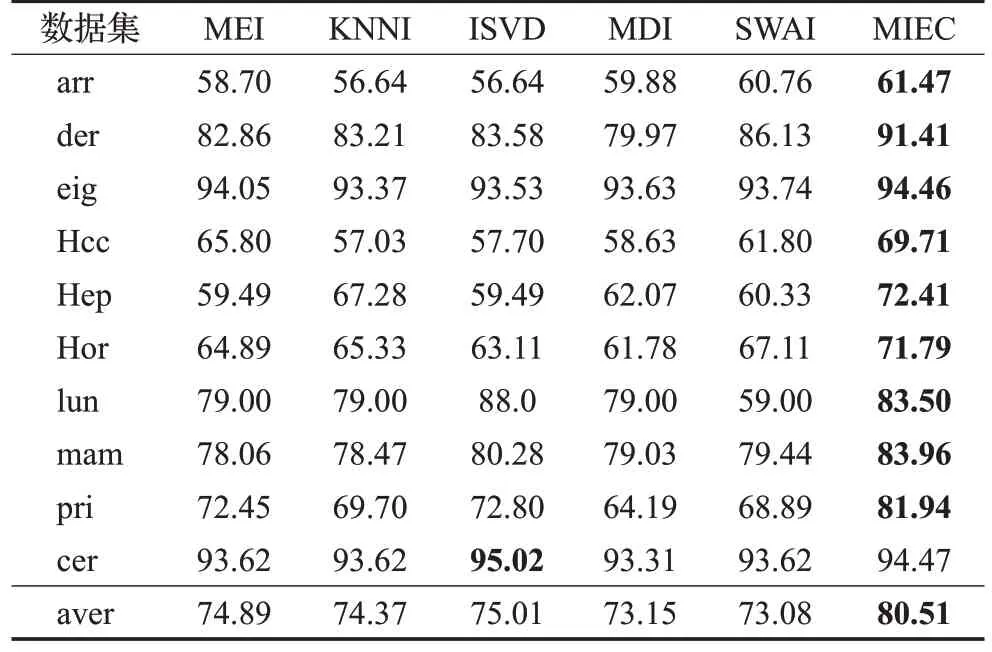
表3 KNN分类器上实验结果Table 3 Experimental results on KNN单位:%
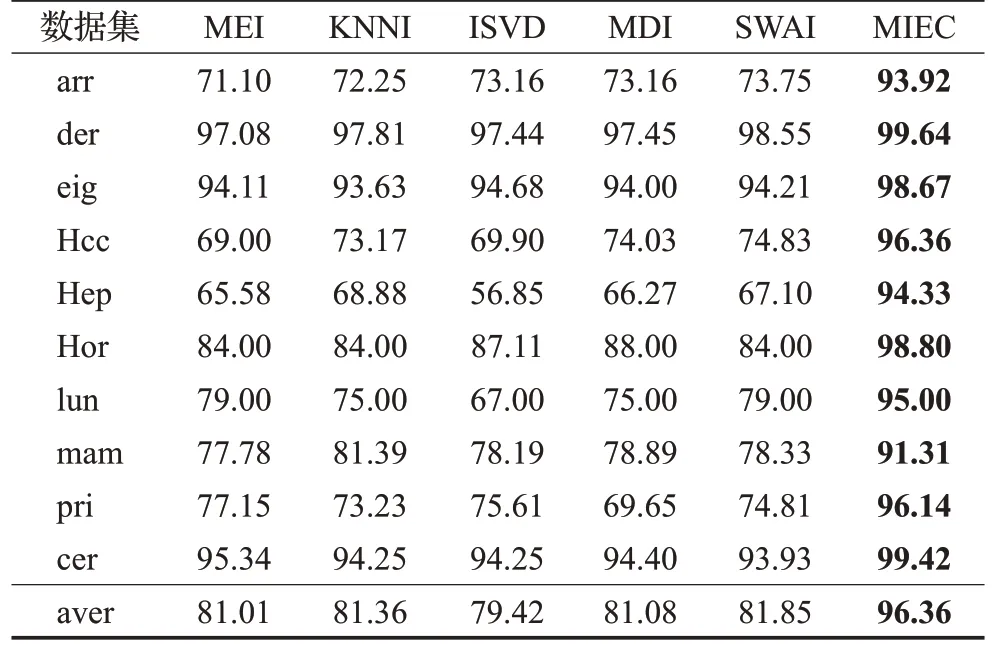
表4 RF分类器上实验结果Table 4 Experimental results on RF 单位:%

表5 SVM分类器上实验结果Table 5 Experimental results on SVM 单位:%
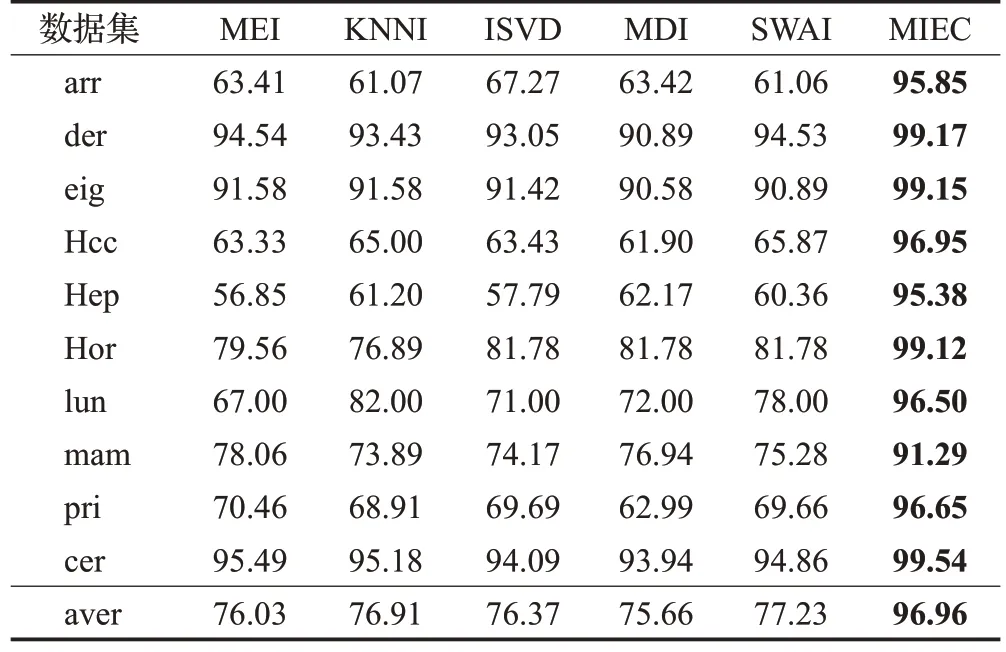
表6 DT分类器上实验结果Table 6 Experimental results on DT 单位:%
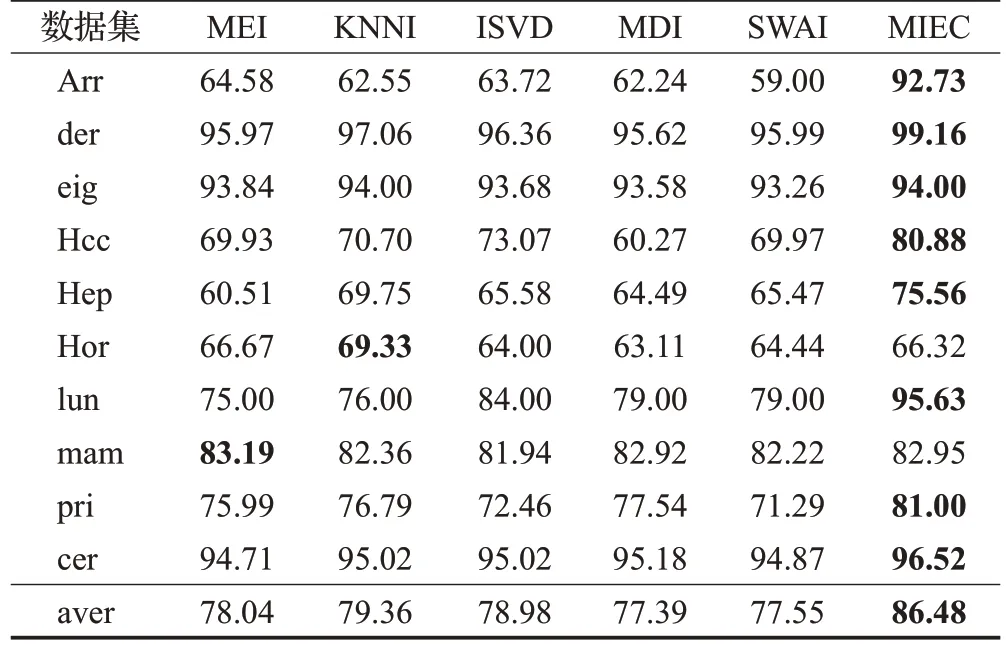
表7 LR分类器上实验结果Table 7 Experimental results on LR 单位:%
从实验结果看,在10 种不完整数据集上,采用5 种填充方法进行预填充,再根据邻域信息进行修正填充,得到5组完整数据集,最后采用本文提出的多填充集成分类算法(MIEC)进行分类实验,其分类精确度明显高于其他对比算法。其中采用RF、DT作为分类器时,本文提出的MIEC算法平均分类精度值高达90%以上。采用KNN、SVM和LR作为分类器时,本文提出的MIEC算法在各种数据集上的平均分类精度值为79.51%、75.03%和85.03%,均优于其他对比算法的平均分类精度。综合来说,本文提出的邻域信息修正的不完整数据多填充集成分类方法对不完整数据的分类精确度都有大大提升。
为进一步验证本文提出的修正填充方法在真实不完整数据集上的有效性,对经预填充后得到的5组完整数据集进行了对比实验。其中,在进行修正填充前和修正填充后分别将5组完整数据集作为集成分类的输入,并计算两种情形下集成分类算法的精确度。表8 为未嵌入和嵌入修正填充的集成分类算法精度对比实验结果表。实验中依次采用KNN、RF、SVM、DT 和LR 这5种分类器作为集成学习的基分类器。
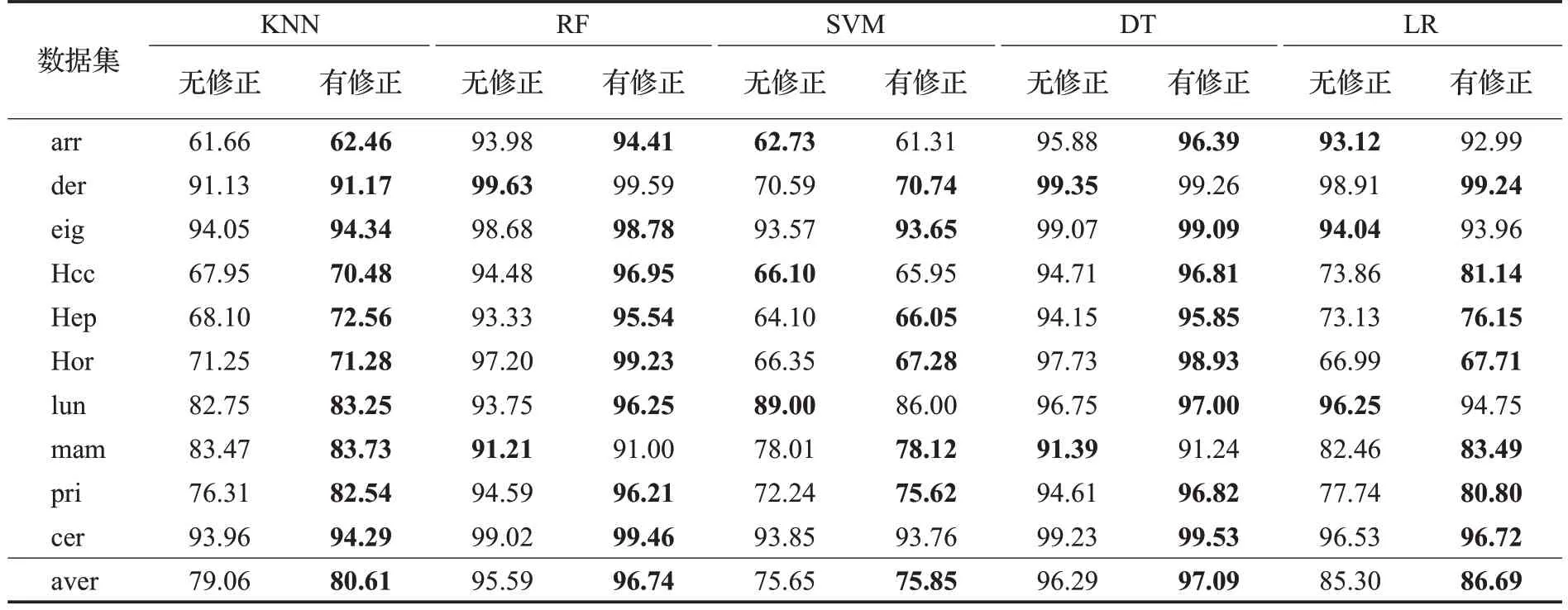
表8 算法精度对比实验结果Table 8 Experimental results for algorithm accuracy comparison 单位:%
实验结果表明,当采用KNN、RF、SVM、DT和LR这5个分类器作为集成分类的基分类器时,有修正填充的集成分类精准度平均值均高于没有修正的情况。在KNN、RF 和DT 作为基分类器的情况下,集成分类方法使用改进填充方法的精准度明显高于没有修正的情况。同时,在SVM 和LR 分类器上,这种改进填充方法对10 种不完整数据集的集成分类有着更高的精确度,其中有7种数据集达到更高的分类精度。
3.4 时间复杂度分析
本文给出的多填充集成分类算法主要由预填充、修正填充和集成分类三个阶段组成,算法的时间复杂度由这三个阶段的时间复杂度组成。
预填充阶段的时间复杂度由选择的预填充算法时间复杂度决定,该阶段时间复杂度记为Oimpution;修正填充阶段包括构建球树、迭代缩小邻域半径寻找候选集和利用候选集计算修正值三个过程。构建球树包括计算欧几里德的距离和球树构建两个环节,时间复杂度为O(n×n×m)+O(n×lbn),其中,n为数据样本数,m为数据样本的属性数;寻找候选集的时间复杂度主要取决于遍历所有缺失值和迭代缩小半径两个过程。遍历缺失值集合的时间复杂度为O(p),这里p是缺失值个数。迭代缩小半径的迭代数最坏情况下是O(lbn),其中n为数据样本数。利用候选集计算修正值的时间复杂度、一些条件判断和球树查询等操作的时间复杂度近似为O(1),可忽略不计。因此修正填充阶段的时间复杂度为O(n×n×m)+O(n×lb n)+O(p),记作Orevision。
集成分类阶段的任务为根据各个基分类器的输出结果进行投票,确定数据样本类别。时间复杂度主要由基分类器的时间复杂度,记作Ovote。
综合所述,本文提出的多填充集成分类算法时间复杂度OMIEC可以表示为公式(12):
其中,i表示预填充所选用的经典填充算法个数,j表示所选用的基分类器个数。一般来说,这里的i和j都不会太大,相比于采用一种算法单填充后再利用一种分类器,时间复杂度并没有大幅度提高,且可以通过设计多节点并行执行算法来提高算法效率,因此,从时间复杂度来说,本文融合多种填充算法的优势,进行多填充集成分类方法具有一定可行性。
4 结语
针对不完整数据分类问题,本文提出了一种基于邻域信息修正的不完整数据多填充集成分类方法。该方法嵌入了修正填充步骤,利用纯度和邻域半径筛选出待修正填充的近邻数据样本,然后根据近邻数据样本对缺失值进行修正填充。基准数据集实验结果表明,该方法对缺失值的填充效果表现更优。此外,该方法通过引入多填充集成分类方法,融合了不同经典填充算法的优势。基准数据集分类精度提高率实验以及10个真实不完整数据集验证实验结果表明,本文提出的不完整数据集分类方法是有效的,并且相比于一般分类方法,分类精度得到了大幅提升。
尽管本文提出的基于邻域信息修正的不完整数据多填充集成分类方法能够较好地提升缺失值填充效果并提高分类精度,但仍需要进一步研究。例如,考虑结合不完整数据产生的实际应用场景,从数据对象相似度度量、聚类算法等角度考虑缺失值填充效果问题。此外,在高维不完整数据的多填充集成分类速度方面,还可以考虑如何设计分布式算法以加快分类速度。
猜你喜欢
云南教育·中学教师(2020年11期)2021-01-07
吉林大学学报(理学版)(2020年3期)2020-05-29
山东煤炭科技(2020年1期)2020-03-06
自动化学报(2018年7期)2018-08-20
电子测试(2018年1期)2018-04-18
光学精密工程(2016年4期)2016-11-07
光学精密工程(2016年3期)2016-11-07
周口师范学院学报(2016年5期)2016-10-17
电测与仪表(2014年15期)2014-04-04
华东理工大学学报(自然科学版)(2014年2期)2014-02-27
