
基于注意力机制和U-net 网络的漆面图像分割方法*
2023-12-09 08:51常红杰丁明解
计算机与数字工程 2023年9期
常红杰 高 键 丁明解 齐 亮
(江苏科技大学电子信息学院 镇江 212003)
1 引言
在自动除漆小车的视觉导航过程中,必须对漆面进行分割。此外,为了保证良好的除漆效果,漆面的分割精度必须足够高,分割的实时性也要很好。
近年来,各种基于神经网络的图像分割算法层出不穷,其中,U-net 网络是在FCN 网络基础上发展而来的一种图像分割网络[1]。相比于FCN,U-net 舍弃了全连接环节,使得网络结构更加轻量化,参数量更少,而关键的特征融合环节的引入,显著提升了网络的分割精度。因此U-net 网络适用于语义简单、边界模糊的图像分割。
陈泽斌等[2]针对传统的图像分割方法耗时且准确度低的问题,结合Adam 算法对传统的U-net模型进行改进,实现了比传统模型更高精度、更好实时性的路面图像分割。宋廷强等[3]以U-net模型为基础,提出了一种深度语义分割模型AS-Unet,用于视觉导航中的图像分割,改善了图像分割的精度。李鸿翔等[4]针对图像分割中边缘识别错误的问题,提出了一种GAN-Unet 的分割模型,与传统的U-net 模型相比,图像分割精度有所提升,边缘分割误差显著减小。王红等[5]以传统的U-net为基础,引入并行双注意力模块,提出了PCAW-UNet模型,大幅度提高了视觉导航图像的分割精度,分割准确率达到了98.7%。并且该模型的实时处理速度相较于传统的U-net模型也有显著提升。
本文以钢板除漆维护为具体应用背景,提出了一种基于串行双注意力机制和U-net 网络的漆面图像分割方法。
2 材料和增强
2.1 数据收集
本文主要以船舶油漆面为研究对象,由于没有现成的油漆面数据集供本文使用,只能通过搜集有关图像和模拟油漆面的方式,组成数据集。第一部分共搜寻到150张漆面图片组成数据集。如图1所示。

图1 漆面图像
在第二部分,本研究利用灰色卡纸替代钢板,用不同颜色的颜料在卡纸上面绘制各种图案,模拟破旧钢板上的漆面图案,如图2所示。

图2 模拟漆面图像
最后通过整个摄像头对模拟漆面进行采集组成第二部分的数据集,共100 张。经过扩充以后,将这些图像分为训练集、验证集。采用Labelme 工具进行数据处理,根据研究目标,本文只对漆面像素进行标注。
2.2 数据增强
本研究在训练之前对输入图像的尺寸进行统一,消除图像尺寸对训练结果的影响。此外,神经网络在训练的过程中有很多参数需要拟合,只有依靠大量的训练,才能防止出现神经网络过拟合的情况[6]。因此,必须扩充数据集的容量。本文通过旋转(90°、180°和270°)和翻转(水平、垂直)进行扩充,随后再进行随机Resize 变换,生成具有差异性的漆面图像,完成漆面数据集的扩充。
3 模型和方法
3.1 U-net基本模型
U-net模型采用跳跃连接的方式将编码网络和解码网络两部分连接起来。其中,编码阶段,负责图像特征提取,主要由四个下采样模块组成。解码阶段,负责特征融合和恢复图像尺寸,由四个上采样模块组成[7]。下采样模块通过卷积层堆叠的方式进行特征提取,随后利用池化层进行下采样。上采样模块则由卷积层和反卷积层组成,卷积层负责特征融合,反卷积层实现上采样,负责恢复图像尺寸[8]。
3.2 模型调整
相比于其他的神经网络模型,U-net 模型虽然结构更加轻量化,分割速度更快,然而在特征融合过程中,U-net 模型没有对编码器获得的特征信息进行过滤,使得模型易受到非漆面区域的特征信息,对模型的分割精度造成影响[9]。
为了进一步提高模型的分割精度、实时性和泛化能力,本文对U-net模型进行调整。
首先,在编码阶段用Efficientnet-B0 编码器代替原有的编码器。Efficientnet-B0 在提高模型分割精度的同时,大幅度减少了训练过程中的参数量,比起传统的神经网络模型有着更好的实时性和精准度。Efficientnet-B0编码模块结构如图3所示。
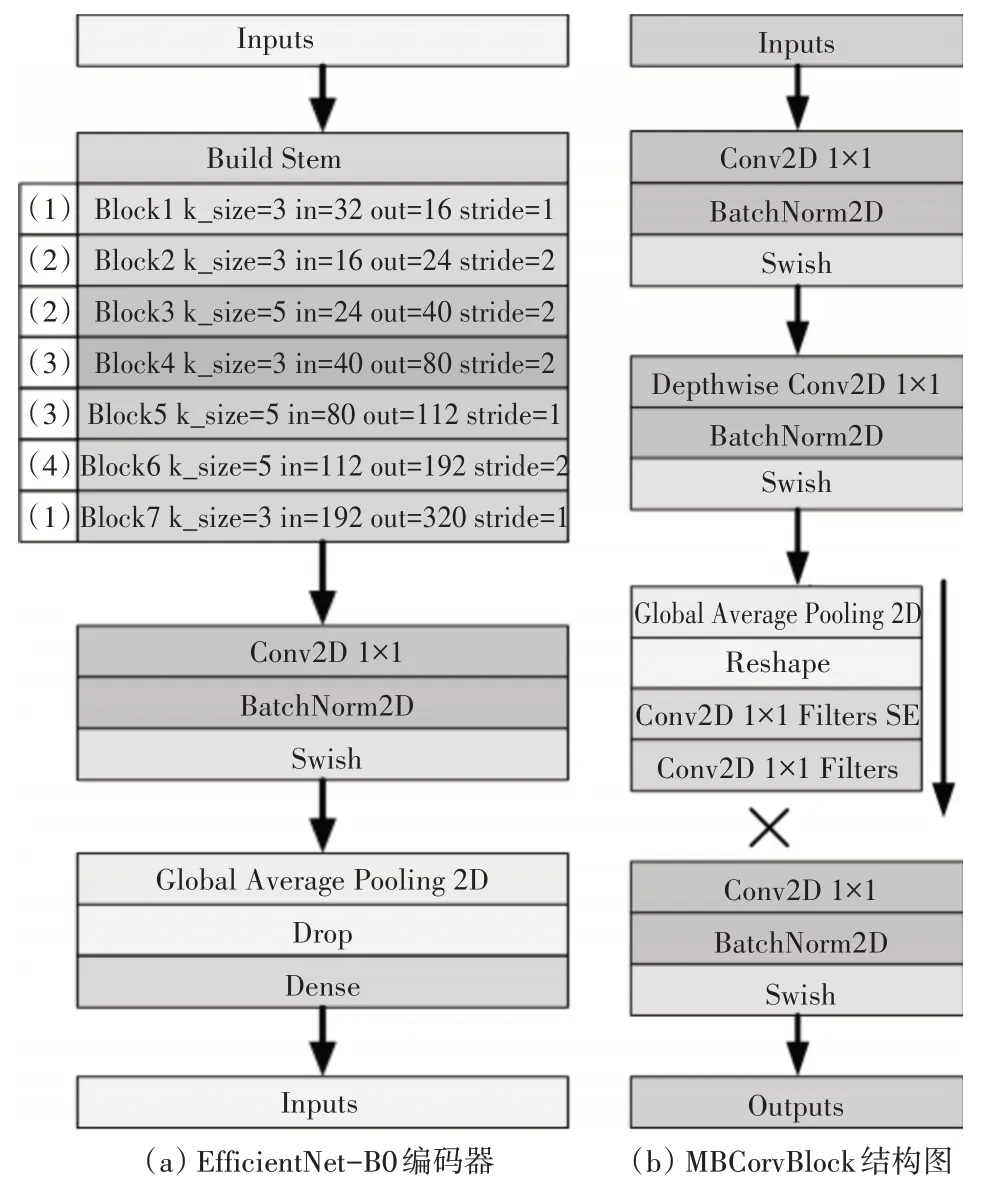
图3 Efficientnet-B0编码器结构
其次,引入Focal Loss 代替交叉熵损失函数。Focal Loss 调节系数可以改变不同样本的损失权重,有利于提高模型的分割准确率和精度[11]。
其中,αt和γ是权重调节系数,pi表示正确分类概率。
最后,在特征融合环节引入串行双注意力模块。用于进一步改善模型的信息处理能力和准确性。串行双注意力模块结构如图4所示。
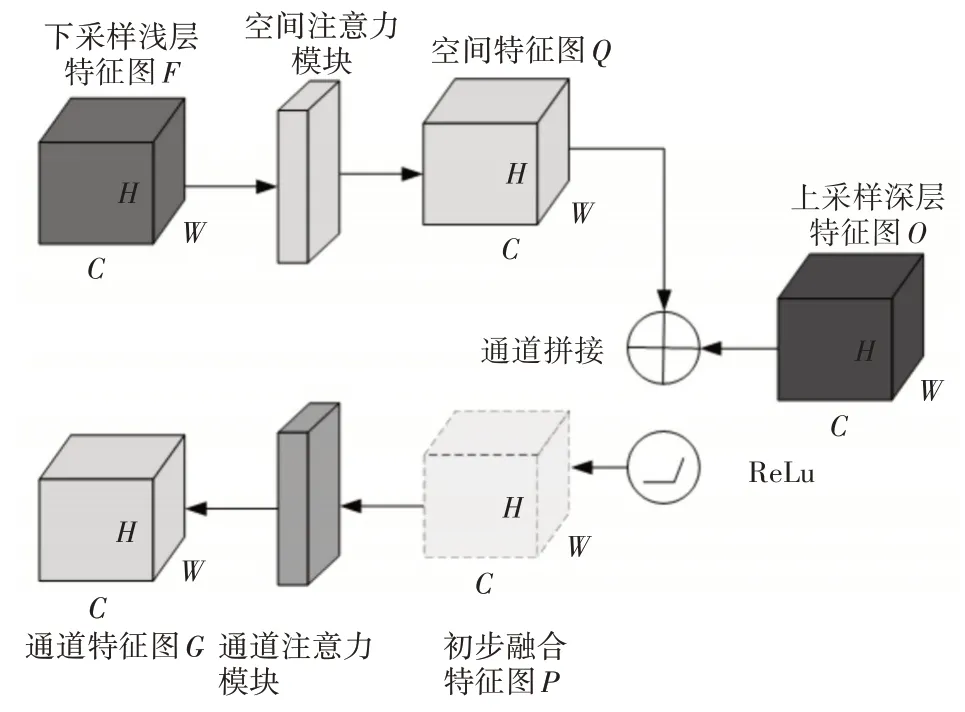
图4 串行双注意力模块结构
改进后U-net结构如图5所示。
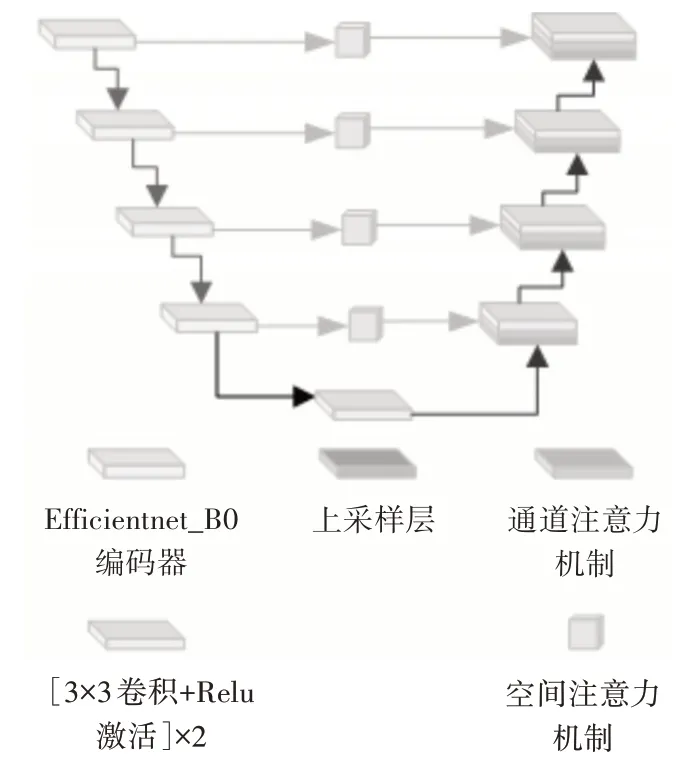
图5 改进后U-net模型结构
4 实验与分析
4.1 模型训练及参数设置
本文在如下环境中训练模型:操作系统采用Windows 10,深度学习框架为Pytorch 1.8,CPU 为Intel Xeon Sliver 4110 @ 2.10GHz,GPU 为NVIDIA GeForce RTX 2080Ti。
模型训练前,首先使用Efficientnet-b0 权重初始化方法对模型的初始参数进行设置。模型优化采用目前常用的Adam优化器以及参数使用其中的默认参数[14]:初始学习率为0.001,β1=0.9 ;β1=0.999;Epoch设置为100,Batch_size设置为8。
模型训练过程中,Adam 优化器在每一轮迭代时更新参数以减小损失值(Loss)。训练集Loss 值(Train Loss)随迭代次数变化的趋势分别如图6 所示。

图6 训练集Loss值随迭代次数变化的趋势
4.2 评价指标
对于多分类问题,图像分割精度主要从以下三个指标进行评价:像素准确率PA、平均像素精度mPA、平均交并比mIoU。计算式分别为
其中,mIoU表示平均交并比;k+1 表示类别数,pij表示预测错误的像素数量,pii表示判断正确的像素数量,TP表示真正例,FP表示假正例,FN表示假反例,TN真反例。
4.3 结果分析
模型训练完成之后,为了验证本文改进算法的有效性,设计了对比实验。
在数据增强之前和数据增强之后,分别训练U-net模型。由表1 可以看出,经过数据增强,各项评价指标有明显的提升。可以验证的是,数据集容量对于模型的分割精度有着较大影响。

表1 数据增强前后漆面分割指标对比/%
完成数据增强对比试验之后,对原生U-net 模型结构进行调整。随后选取目前比较常用的图像分割模型进行对比实验。对比试验的评价指标结果如表2所示。

表2 不同模型的漆面分割精度/%
不难看出,相比于U-net 模型和ResUnet 模型,本文改进的算法相比于传统的U-net模型和ResUnet模型,在分割精度上有着显著的改进。此外,本文改进的算法在各项指标上与目前最先进的Deep-LabV3模型以及DeepLabV3+模型几乎一致。
为了验证本文改进模型的分割性能,计算各指标的平均值μ和方差σ。此外,还加入了模型的训练时间(Training time)和分割时间(Segmentation time),完善模型的性能测试维度。
随后按照一定的优先级对上述指标进行加权求和,得到模型的综合得分(Score)。根据经验,本文将模型的精度(平均值μ),稳定性(方差σ),模型的训练时间(Tra-time)和分割时间(Seg-time)的权重分别设置为100,80,-10 和-50。性能评比结果如表3所示。
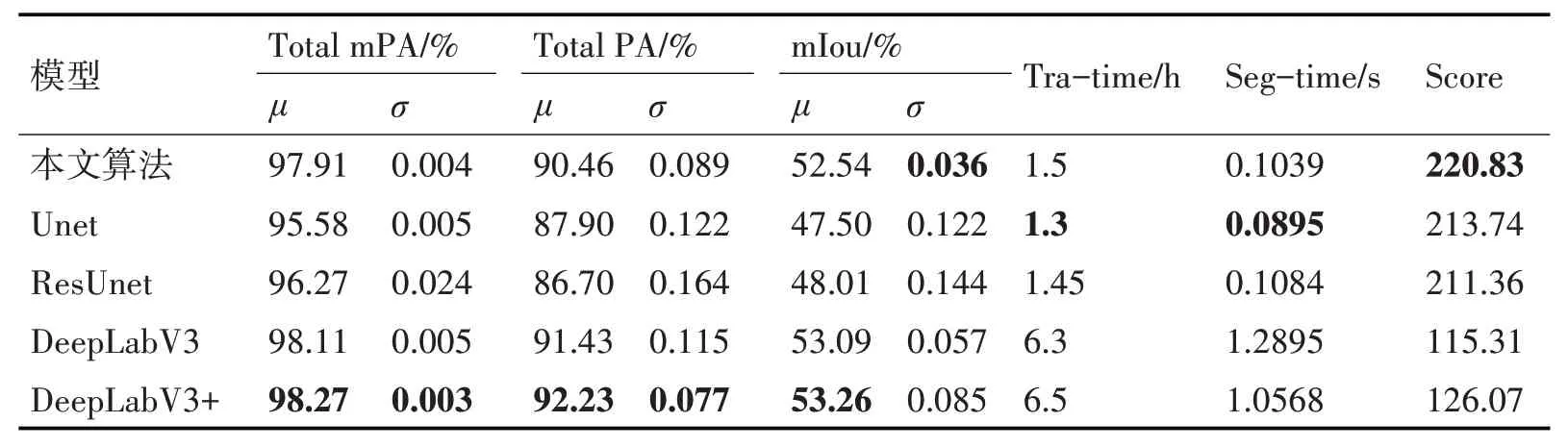
表3 不同模型的分割性能评比
可以看出,虽然DeepLabV3 模型和Deep-LabV3+模型虽然在分割精度上有优势,但是由于其庞大的网络结构和巨大的参数量,其训练时间几乎是其他模型的4倍~5倍,每张图片的分割时间甚至达到了其他模型的10 倍以上。而本文改进后的模型,精度几乎与DeepLabV3+模型的精度持平,同时训练时间和分割时间相比于DeepLabV3+模型,分别提升了76.92%和90.17%,保证了很好的精度和实时性。
最后,图7 展示了不同模型的漆面分割效果。可以看出,当背景存在与漆面颜色较为接近的区域时(图7 前3 行),其他集中未引进注意力模块的分割模型存在误分割的情况(图中白色选框标注),而本文引入注意力模块改进后的U-net 模型在非漆面区域没有出现误分割的情况。当漆面的背景比较简单且与漆面差异较大时,本文改进的算法和DeepLabV3+模型的分割效果均比较理想,在细节部分本文改进后的模型甚至分割的更加精细(图中灰色选框标注)。

图7 不同模型分割结果对比
5 结语
本文提出了一种串行双注意力机制的U-net分割模型,应用于自动除漆小车的视觉导航漆面分割任务。该方法在对数据集进行预处理之后,利用改进后的U-net 模型对漆面进行分割。通过引入Efficientnet-B0 编码器,加强了网络对于浅层特征的提取,减少了模型的参数数量。随后引入Focal Loss 损失函数,提高模型的分割准确率,最后嵌入串行双通道注意力模块,提高模型对于漆面区域的关注比重,降低来自非漆面区域的特征干扰,同时通道注意力模块还减少了网络在特征融合后的冗余通道数,提升了模型的分割时间。实验证明,本文改进后的算法在保证精度的同时,具有更好的泛化能力和实时性较少的。
虽然本文改进的U-net 模型能够在训练样本数量较少的情况下依然能够达到良好的精度和实时性,但是对于神经网络模型来说,大量的训练样本能大幅提高其分割精度(这一点在本文中也得到了验证)。因此,在后续的研究过程中,找到解决样本数量不足的办法,是本文可以继续研究的方向,目前较为常用的方法是利用生成对抗网络(GanU-net)以图生图[15]。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09
高技术通讯(2021年3期)2021-06-09
智族GQ(2021年4期)2021-05-13
汽车维护与修理(2020年14期)2020-08-05
电测与仪表(2017年24期)2017-12-19
传媒评论(2017年3期)2017-06-13
北京航空航天大学学报(2017年12期)2017-04-23
汽车维护与修理(2016年6期)2017-01-18
人民交通(2016年6期)2017-01-07
第二课堂(课外活动版)(2016年2期)2016-10-21
