
基于YOLOv4-Tiny 与显著性检测的安全帽佩戴检测*
2023-12-09 08:50李岳阳罗海驰
计算机与数字工程 2023年9期
兰 天 李岳阳 罗海驰
(1.江南大学江苏省模式识别与计算智能工程实验室 无锡 214122)
(2.江南大学物联网工程学院 无锡 214122)
1 引言
安全帽作为一种最常见和实用的个人防护用具,能够有效地防止和减轻外来危险源对人们头部的伤害。根据公开的网络数据来看,由于施工人员的不安全行为造成的安全事故占到了所有事故总类的88%以上[1],保证工人佩戴安全帽是安全生产的重中之重。
近年来,基于深度学习的目标检测技术得到了快速发展,主要可分为二阶段和一阶段两种策略。在二阶段方面,具有代表性的是从2014 年开始的R-CNN 网络[2];之后又在2015 年提出该网络模型的改进版Fast R-CNN[3]与Faster R-CNN 算法[4]。在一阶段方面,具有代表性的是YOLO 系列网络模型和SSD 算法[5]。对于YOLO 系列网络模型,2015年由Joseph Redmon 提出YOLO 算法[6],又在2016年与2018 年分别提出了YOLOv2[7]与YOLOv3[8]算法,2020 年Alexey Bochkovskiy 提出了YOLOv4[9]的网络结构。与R-CNN 系列模型相比,YOLO 系列目标检测的方法检测精度略低,但其检测速度更快,检测效率有很大提升,能够应用于实时目标检测任务中。
目前已有很多将上述网络模型应用于解决实际问题的案例。例如,文献[10]提出基于YOLOv4的乒乓球识别算法,文献[11]提出棘突YOLOv4 辅助机器人巡检算法,文献[12]提出的基于YOLOv4的障碍物实时检测算法。在安全帽检测领域也有很多先例,例如文献[13]提出基于轻量化网络的安全帽检测,文献[14]一种基于高精度卷积神经网络的安全帽识别算法,文献[15]提出基于YOLOv3 的安全帽检测算法。
综合考虑不同检测算法的优点,以及本文所要解决的工人安全帽佩戴实时检测的任务,我们通过优化YOLOv4-Tiny和显著性检测模型,并将两者有效融合,提出实时检测工人安全帽佩戴的方法。所提出的方法主要有以下3个创新点。
1)为兼顾目标检测的速度与准确率,我们采用YOLOv4-Tiny 算法对安全帽佩戴进行实时检测。同时利用K-means聚类算法得到合适的先验框,使模型检测结果更为精准。
2)增加动态显著性模型输入的时间跨度,增强输入数据的时序特征,更好地排除背景因素的影响,得到更为准确的显著性检测结果。
3)将优化后的YOLOv4-Tiny 模型目标检测结果和改进后的动态显著性检测结果有效融合,对目标执行复检操作,从而降低误检率。
2 YOLOv4-Tiny目标检测算法与优化
2.1 YOLOv4-Tiny目标检测算法
YOLOv4-Tiny 目标检测算法[16]是在YOLOv4模型的基础之上改进而来的,对其主干网络和特征提取网络进行一定程度的精简,如图1 所示,其网络主要分为主干网络CSPDarknet53-Tiny 与加强特征提取网络。
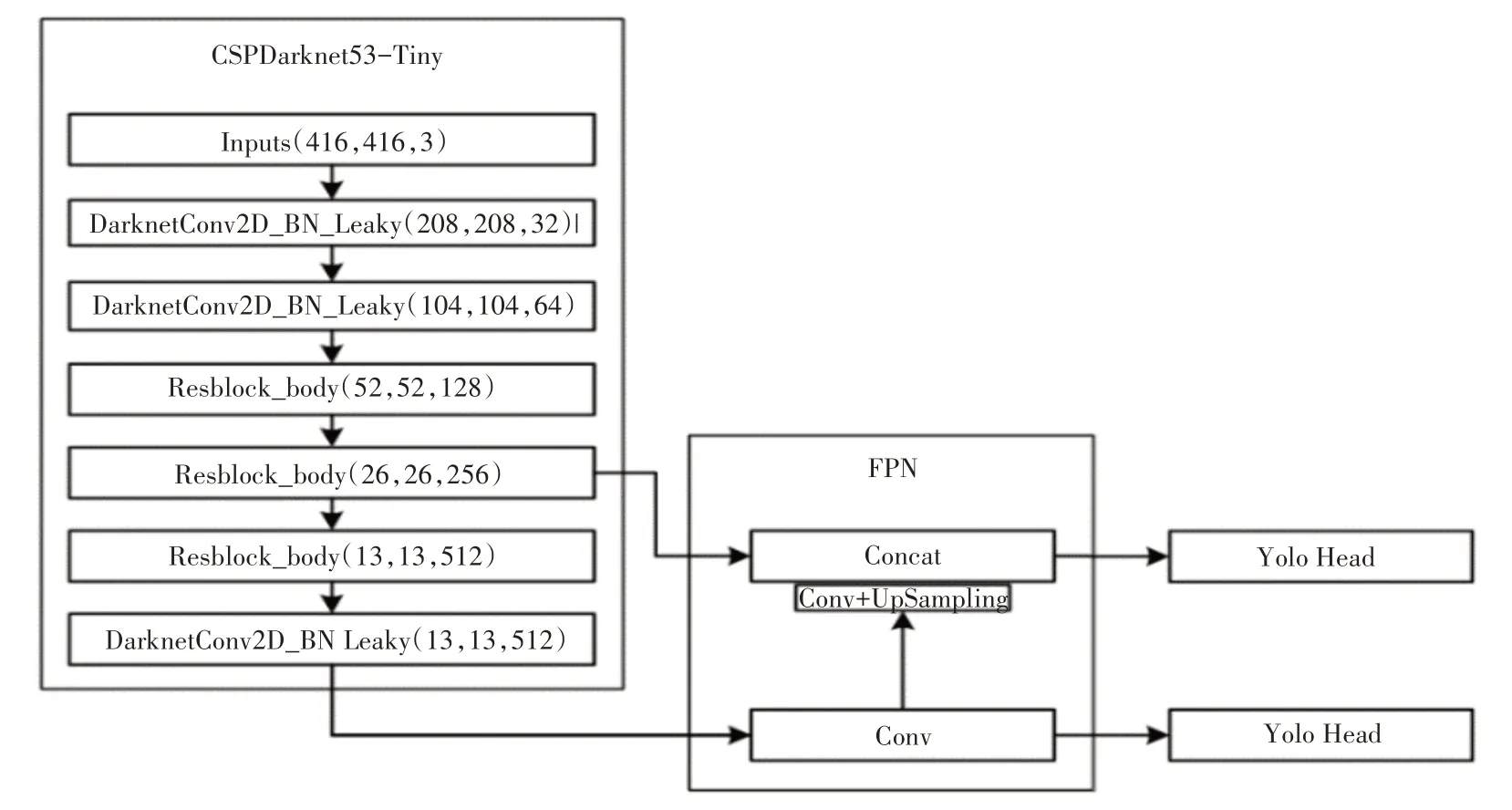
图1 YOLOv4-Tiny网络结构
YOLOv4-Tiny模型只在CSPDarkNet53-Tiny输出两个尺度的特征作为加强特征提取网络(FPN)的输入,其中对最后一个尺度的有效特征层卷积后进行上采样,再与上一个尺度的特征层进行堆叠后卷积,二者分别输出至YoloHead进行预测。
在YOLOv4-Tiny的损失函数的设计中,综合考虑三个方面的误差[8]:预测框与实际框的位置偏差Lloc、预测框与实际框的置信度误差Lconf,以及预测框与实际框的预测种类误差Lcls。损失函数为这三个部分的和,可以用如式(1)表示。
在计算预测框与实际框的位置偏差Lloc时,采用了CIOU[17]这个度量指标。CIOU 考虑了预测框与实际框之间的距离与重叠角度,同时引入二者框体长宽比不同的惩罚因子,使目标框体的回归更加稳定。
2.2 算法优化
为了在模型训练时更加高效,模型中都会预设有不同尺度的先验框,先验框的设置直接关系到模型检测性能的好坏。
为了获得合适的先验框,利用K-means聚类的方法来对数据集中的安全帽目标进行处理。在聚类过程中,首先随机确定6 个初始聚类中心。之后以IOU 为评判标准,计算每个目标框与6 个聚类中心的距离,将该目标分配给最近的聚类中心。将所有目标框分配完毕后,对每个类计算所有属于该类的目标框体的宽高平均值作为新的聚类中心。之后重复分配所有目标框体,直至聚类中心不再改变。具体分类的计算可用式(2)表示:
其中boxi为第i个检测目标框,cenj为当前第j个聚类中心目标框,n为检测目标的个数,k为所需聚类中心的个数。计算时随机设定cenj的初始值,之后每计算一次,cenj为属于第j个类内所有框体的尺寸平均值。
最终得到的先验框与原始先验框对比如表1所示。

表1 先验框尺寸对比
3 动态显著性检测算法与改进
为提高安全帽检测的准确率,基于文献[18],本文提出改进后的动态显著性检测算法。
3.1 动态显著性检测算法
基于全局对比度图像显著性检测方法(LC)[19]是计算每个像素与图片中其他所有像素在颜色上的距离之和,将该值作为该像素的显著性值。该方法只是单纯地比对像素颜色,故检测效果较差。
为了能够更好地检测出图片中的高显著性区域,基于全卷积网络,文献[18]提出了一种显著性检测算法,具体结构如图2所示。
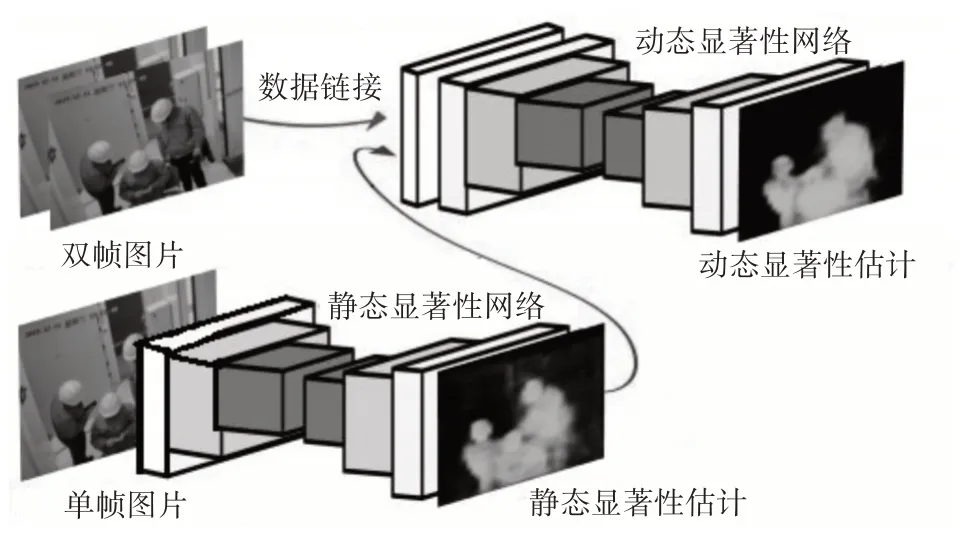
图2 基于全卷积网络的显著性模型结构
该显著性检测结构主要分为静态显著性检测与动态显著性检测两部分。其中静态显著性检测网络,会首先将图片进行5 步共13 次的卷积,之后再利用对应的反卷积网络得到静态显著性检测结果。静态显著性检测网络的整体运算公式为
其中Y为输出,I为图像输入,FS为卷积层产生的特征输出,DS为反卷积操作,确保输出Y与输入图像I相同大小,ΘF与ΘD代表卷积与反卷积时的参数。
如图2 所示,动态显著性检测将静态显著性检测网络的输入图片It、该图片的下一帧图片It+1,以及静态显著性检测结果Pt,三者在通道上连接作为输入,该输入通过如下公式进入第一层的卷积运算:
其中W为卷积权重,b为偏置项。It和It+1为相邻两帧图像,Pt为It对应的静态显著性检测结果。
该模型利用光流图像对视频相邻两帧的时间信息进行直接推断,获得了较高的计算效率与精度。
3.2 算法改进
在文献[18]的基于全卷积网络的显著性检测算法中,其输入数据为t时刻与t+1 时刻两张相邻帧的原图It与It+1,以及t时刻对应的静态显著性检测结果Pt。使用这种方法只利用到了两帧的时序信息。
为了拓宽输入帧的时序宽度,同时避免由于时序跨度过大而影响对移动目标检测效果,我们把基于两个时序输入的方法拓展为基于三个时序输入的方法,第一卷积层的计算公式修改如下:
其中W为卷积时的权重,b为偏置项。It+1和It+2为后续两帧图像,Pt为It对应的静态显著性检测图像。这种利用了三个时序特征的输入可以进一步缓解图像中背景因素影响。
4 安全帽佩戴检测算法
对于一帧图片,得到其目标检测结果和动态显著性检测结果以后,可将两者有效融合,得到最终的安全帽佩戴检测结果。
具体操作为将目标检测结果图和显著性检测结果图缩放至相同大小,这样目标检测结果中的目标框体位置,与显著性检测结果图中的目标位置是相对应的,故可对目标检测得到的每个目标,使用显著性检测结果进行复检操作。
显著性检测结果图为灰度图,其中较亮的区域为高显著性目标区域,较暗的区域为低显著性背景区域。根据显著性检测结果,就可以判断目标检测框区域是否为高显著区域,从而执行复检操作。
利用动态显著性检测结果,对每一个YOLOv4-Tiny 模型检测到的目标执行复检,进一步判断其是否为真实目标。如图3 所示,图3(a)、(b)和(d)分别为原图、YOLOv4-Tiny 模型目标检测结果图和改进后的动态显著性检测结果图,图3(c)中三个小图分别为根据图3(b)中三个目标检测的结果在图3(d)中得到的对应三个显著性检测裁剪结果。

图3 利用显著性检测结果进行复检
对图3(b)中每一个目标检测结果执行复检操作的步骤如下:
1)对于图3(c)中每一个显著性检测裁剪小图,检测每一像素,如果其像素灰度值小于设定阈值T1,则判定为背景像素;否则,判定为目标像素。
2)预先设定一个占比阈值T2,对于图3(c)中当前复检的显著性检测裁剪小图,如果在该显著性检测裁剪小图中,背景像素占比小于阈值T2,则判定该显著性检测裁剪小图对应的图3(b)中的目标检测结果为有效目标,复检通过;反之,则对应的图3(b)中的检测结果为背景区域,目标检测结果为误检。
在本文的实验中,阈值T1设定为15(假设显著性检测结果图中像素灰度值的范围为0~255),阈值T2设定为70%。
5 实验结果与分析
5.1 实验平台
本实验在Windows10 操作系统环境下完成,实验所采用的硬件设备配置为NVDIA GeForce GTX 1060 6GB 显存的GPU,内存16GB。所使用的编程语言为Python,模型开发框架为Tensorflow。
5.2 优化后的YOLOv4-Tiny模型目标检测性能
对于优化后的YOLOv4-Tiny模型,其初始权重为基于COCO 数据集得到的预训练模型权重。训练与测试使用的数据集为从网络中搜索得到共3645张图片的安全帽数据集,按照7∶1的比例划分为训练集与测试集,这些图片为单独的照片,内含有佩戴安全帽的人员hat 与未佩戴安全帽的人员person。
针对安全帽佩戴检测任务,本文采用K-means聚类方法得到适合安全帽数据集的先验框,最终得到的先验框大小如表1 所示。改进后先验框尺寸相对较小,能够更适合当前安全帽检测任务。
对于450 张测试集,本文所提出的优化后的YOLOv4-Tiny 模型与原始模型在安全帽佩戴检测任务中检测结果对比如图4 所示,其中图4(a)显示的是原始模型检测结果,而图4(b)显示的是本文所提出的优化后的YOLOv4-Tiny模型检测结果。

图4 优化后的YOLOv4-Tiny模型与原始YOLOv4-Tiny模型检测结果对比
图4 中分别显示了对hat 与person 两个目标检测正误的数量。图4(a)为原始模型检测结果,图4(b)为优化后YOLOv4-Tiny检测结果。
在本文的实验中,使用准确率和mAP 作为评价指标。其中,准确率Precision的计算公式为
其中,TP(True Positive)为模型判定为正样本且实际标签也为正样本的数量,FP(False Positive)为模型判定为正样本但实际标签为负样本的数量。
表2 所示的是本文所提出的优化后的YOLOv4-Tiny 模型与原始模型在安全帽佩戴检测任务中检测准确率以及mAP 对比结果。可以看出,优化后YOLOv4-Tiny 模型识别准确率和mAP 均有提升。

表2 本文所提出的优化后的YOLOv4-Tiny模型与原始YOLOv4-Tiny模型性能对比
在速度方面,相比于YOLOv4 网络中六千四百万的参数量,本文使用的YOLOv4-Tiny的参数量仅有不到六百万,可以很好满足对安全满检测的实时性要求。在本文的环境中,使用该模型可以达到平均每秒22帧,满足对实地安全帽实时检测需求。
5.3 采用显著性检测复检后的检测性能
由于动态显著性检测的输入数据必须为连续的多张视频帧,上述实验使用的独立图片集在此实验中不适用。故在测试显著性检测性能的实验中,我们自建一组内含100帧连续图片的视频测试集。
图5 所示的是视频测试集中三帧连续图片的四种显著性检测模型的检测结果对比。其中图5(a)为三帧连续图片,图5(b)为采用优化后的YOLOv4-Tiny 模型目标检测结果,图5(c)为真实显著性图,图5(d)~(g)分别为LC检测结果、静态显著性检测结果、原始动态显著性检测结果和改进后动态显著性检测结果,图5(h)为对应图5(b)的检测到的多个目标,在改进后动态显著性模型的检测结果图中裁剪得到的小图。
如果只是采用优化后的YOLOv4-Tiny模型,有时会将图5(b)所在行中第一帧图片中的一个没有佩戴在工人头上的安全帽误检为hat(工人佩戴安全帽)。之后进行复检,我们可以得到在图5(h)所在行的第一帧图片的中间一个裁剪小图,因其背景像素占比大于阈值T2,则判定该目标检测结果为背景区域,即为误检目标,复检不通过。
为了验证显著性检测的效果,本文采用平均绝对误差MAE(Mean Absolute Error)作为评判显著性检测的标准。MAE的计算方法如式(7)所示:
其中h和w表示图片的高和宽;P(xi)和G(xi)分别表示像素的预测灰度值与真实灰度值,在计算时二者都会被归一化到区间[0,1]。
表3 所示的是四种显著性检测的对比结果。其中传统LC 方法效果最差,静态显著性检测结果仍会有较多干扰区域,改进后动态显著性检测模型检测结果最为准确。
实验结果表明,如果使用静态显著性检测方法进行复检,无法剔除误检目标。利用改进动态显著性检测方法则可以有效检测出图5(b)中目标检测得到的误检目标,从而将误检目标剔除。
表4 所示的是安全帽佩戴检测的消融实验结果。首先,从表中可看出,如果只是采用目标检测模型,与原始YOLOv4-Tiny 模型对比,优化后的YOLOv4-Tiny模型检测准确率会提升较多。
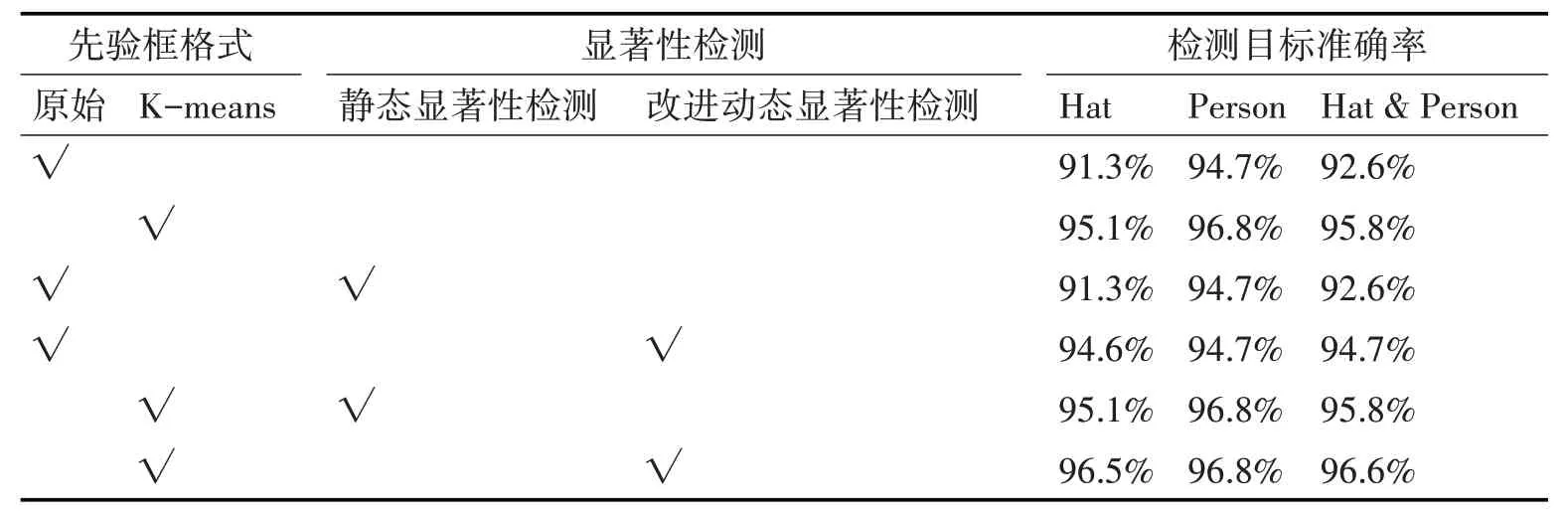
表4 安全帽佩戴检测消融实验结果
其次,不论目标检测模型采用原始YOLOv4-Tiny模型还是优化后的YOLOv4-Tiny模型,静态显著性检测模型没有起到复检效果。使用静态显著性检测进行复检,对应的检测准确率没有提升。
最后,不论目标检测模型采用原始YOLOv4-Tiny模型还是优化后的YOLOv4-Tiny模型,改进后的动态显著性检测模型能够起到复检作用,可有效提升检测准确率。
6 结语
在本文中,对YOLOv4-Tiny 模型进行优化,再与改进的动态显著性检测算法相结合,应用于工人安全帽佩戴检测。首先针对安全帽佩戴检测数据集,利用K-means 聚类的方法选择合适的YOLOv4-Tiny 模型目标检测先验框,有效提升目标检测的准确率。在动态显著性检测算法中,使用连续三个时序图片的信息作为输入,得到更为准确的高显著性区域检测。最终,使用动态显著性检测结果,对优化后的YOLOv4-Tiny模型检测到的每一个目标执行复检操作,有效剔除误检目标,从而提高安全帽佩戴检测准确率。
猜你喜欢
星星·诗歌原创(2023年12期)2024-01-06
机电安全(2022年4期)2022-08-27
北京航空航天大学学报(2021年9期)2021-11-02
电子制作(2019年11期)2019-07-04
电子制作(2019年24期)2019-02-23
西南交通大学学报(2018年5期)2018-11-08
北京航空航天大学学报(2018年1期)2018-04-20
苏州科技大学学报(自然科学版)(2017年1期)2017-03-20
知识产权(2016年8期)2016-12-01
电视技术(2014年19期)2014-03-11
