
改进的SlimYOLOv3-A 算法在障碍物检测中的应用*
2023-12-09 08:50张宇辰
计算机与数字工程 2023年9期
汪 刚 魏 赟 张宇辰
(上海理工大学光电信息与计算机工程学院 上海 200093)
1 引言
移动物流机器人的出现极大提高了物流仓库的工作效率,快速精准的障碍物检测是安全避障和高效工作的前提。现阶段移动物流机器人上应用的障碍物检测方法分为两种。第一种是利用激光雷达[1]、红外[2]、双目相机[3]等传感器,以及多传感器融合[4]进行检测。这些方法优势在于检测速度快,但是只能模糊检测到障碍物位置,不能精准检测出障碍物,且不能识别出障碍物类别,也容易受到外界环境因素的影响。
随着深度学习[5]的发展,基于图像处理的障碍物检测算法已经能够逐渐替代传统的检测方法,检测的精度、速度和功能性也进一步提高。基于深度学习的检测算法分为两类,第一类是双阶段目标检测算法,先用候选区域生成网络来生成可能包含物体的检测框,再用检测网络对候选框中的物体进行分类和检测,例如R-CNN[6]、Fast R-CNN[7]、Faster R-CNN[8-9]等。第二类是单阶段目标检测算法,这类算法将目标检测视为回归问题,将整张图片作为网络的输入,通过卷积神经网络直接预测物体的位置和类别,属于端到端的检测算法,如SSD[10~12]、YOLO[13]、YOLOv2[14]、YOLOv3[15~17]等,解决了双阶段目标检测算法检测速度慢的问题,但检测精度略有不足。然而上述两类目标检测算法比较复杂,依赖高性能GPU 进行计算,不适用于计算性能有限的嵌入式设备。模型剪枝是解决该问题有效的方法,Redmon J[15]设计了轻量级的Tiny-YOLOv3[18],删减了残差层且只使用两个尺度输出,有效压缩了模型,提高了检测速度。Iandola 等[19]基于fire module,利用1×1 卷积核对特征图进行压缩,提出了SqueezeNet 模型。Howard 等提出MobileNetV1[20]和MobileNetV2[21]采用深度可分离卷积的方法,减少了网络权值参数。
对比上述几种模型剪枝的方法,通道剪枝可以不用特别的库来实现加速训练,并且更节省内存,在工业领域被广泛的应用。YOLOv3 对比其他算法,能够实现多尺度特征检测,并改进了v1和v2的不足,平衡了检测精度和速度,更适合小目标物体的检测。此外,近年来注意力机制的提出[23~24],有效地提高了目标检测模型的性能。因此本文选择YOLOv3 模型进行通道剪枝稀疏化,并添加注意力模块,提出SlimYOLOv3-A 模型。针对移动物流机器人在障碍物检测中,保证检测精度和速度的同时,精简模型体积,减少参数量和计算量。本文的主要贡献如下:
1)在YOLOv3 中引入轻量、高效的PSA 通道注意力模块,更有效地提取多尺度特征信息,并形成远程通道依赖关系,提高小目标障碍物检测精度。
2)利用通道稀疏正则化训练模型,根据特征通道比例因子,修剪模型,得到精简的SlimYOLOv3模型,通过微调来补偿暂时下降的精度。
2 注意力机制
2.1 PSA模块
在检测任务中,存在光线暗、背景复杂、障碍物目标小这些不利于检测的问题。为了通过对网络进行最小的修改来加强检测效果,借鉴注意力机制,引入PSA(Pyramid Squeeze Attention)模块结构,如图1所示。
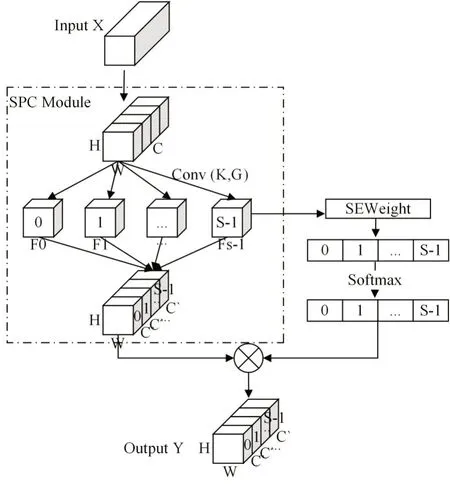
图1 PSA模块结构
2.2 SPC模块
PSA 模块中,最重要的步骤是利用SPC(Split Pyramid Concat)模块进行多尺度特征的提取,结构如图1 虚线框中所示。该模块采用多分支的方式(类似空间金字塔),将输入特征图分成多组,对每个子特征图使用不同的卷积核进行多尺度特征提取:通过压缩输入特征图的通道维数,可以有效地提取每个通道特征图上不同尺度的空间信息;最后将提取的多尺度特征在通道维度进行拼接。
为了降低多分支上的多尺度特征提取带来的计算量,使用分组卷积的方法进行卷积操作。分组数G由卷积核大小k决定:
普通卷积的计算量为
分组卷积的计算量为
Cin和Cout为输入和输出通道数,Cg_in和Cg_out为每个分组卷积核的输入和输出通道数,Cg_in为Cin/G,因此分组卷积的计算量为普通卷积的1/G,有效地降低了多分支上的多尺度特征提取带来的计算量。
2.3 注意力提取
PSA模块的具体过程如下:
1)通过SPC 模块的分组卷积对输入特征图X进行多尺度特征提取:
Fi(i=0,1,…S-1)为每组卷积提取的特征;ki为卷积核大小;Gi为组数;将提取后的特征Fi在通道维度上进行拼接:
2)利用SEWeight模块对Fi提取通道注意力权重信息,得到不同尺度的注意力权重向量:
SEWeight 模块由Squeeze 和Excitation 两部分组成,结构如图2所示。
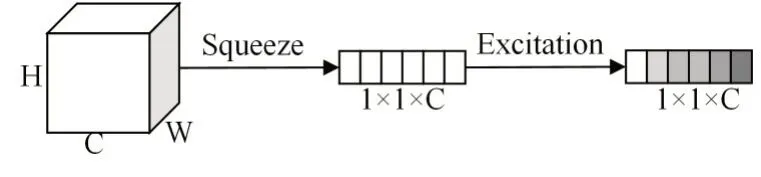
图2 SEWeight模块结构
Squeeze 部分通过在特征图上进行全局平均池化操作,得到当前特征图的全局压缩特征向量:
Excitation 部分先将特征向量进入全连接层,然后进行Relu 激活,再进入全连接,最后再进行Sigmoid 激活,以提取更重要的通道信息,得到注意力权重向量:
H、W、C分别为特征图的高、宽,通道数;δ为Relu激活函数,σ为Sigmoid 激活函数;W0和W1代表全连接层的参数。
在不破坏原有通道注意向量的前提下,为了更好地实现注意力信息交互并融合跨维度信息,将Zi也进行拼接:
3)利用softmax对注意力权值Z重新标定:
4)将特征图F和注意力权重att相乘,得到最终输出的特征图Y:
通过PSA 模块的输出具有更丰富的多尺度特征信息,同时该模块的使用比较便携且没有增加过多的计算量,因此在YOLOv3 的backbone 尾端添加PSA 模块,以此来提升模型在复杂场景对小目标障碍物的检测效果。
3 Slim YOLOv3
本文目标是在YOLOv3 的基础上提出一种更紧凑高效的目标检测模型,按照图3 所示的过程,对YOLOv3进行精简。
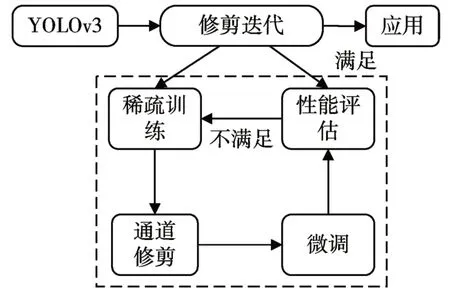
图3 模型修剪的迭代过程
3.1 稀疏训练
将YOLOv3 网络中随着训练逐渐降低重要性的通道进行修剪,可大幅度精简网络,且不改变网络结构。在修剪之前,需要评估通道的重要性。为每个通道引入一个比例因子γ,| |γ表示通道的重要性,并乘以该通道的输出。然后联合训练网络权值和这些比例因子,并对后者进行稀疏正则化。训练目标公式如式(12):
其中f(γ)= |γ|表示γ的L1 正则化。将YOLOv3 的损失函数和γ的正则化相结合,用惩罚因子α平衡这两个损失项。f(γ)是非平滑函数,采用次梯度法进行优化。将式(3)用于稀疏训练,利用反向传播算法不断更新γ,即可得到每个通道的重要性。在YOLOv3 中,除检测层外,每个卷积层后都连接BN层,对卷积层输出的特征进行标准化,加快模型收敛速度,提高泛化能力。如式(13)~(16):
其中m为mini-batch 的样本数,xi为卷积层的输出,μB和为xi的均值和方差,均由统计得到,ε是为了防止除0出错设置的极小数,x̂为xi标准化之后的值,γ和β为可训练的比例因子和偏差,分别对x̂进行缩放和平移,由反向传播算法自动优化更新,y为BN 层的输出。本文直接利用BN 层中的γ参数作为通道修剪所需的比例因子,可以避免引入新参数。
3.2 通道修剪
在经过稀疏训练得到通道的重要性后,接下来进行通道修剪。为了控制修剪比例,引入全局阈值γ̂来决定是否要进行修剪和修剪哪些特征通道,γ̂设为所有γ的百分之n。再引入局部安阈值π,防止卷积层的过度修剪的同时保持网络的完整性,π设为当前卷积层中所有γ的百分之k。修剪比例因子同时小于γ̂和π的特征通道。修剪之后的模型中每层的通道数C'为原通道数C的( )1-p%(p为剪枝率),特征图参与训练的通道数减少p%,因此最终模型的参数量和体积会精简很多。
在修剪过程中,对池化层、上采样层、route 层和shortcut层进行特殊处理。因最大池化层和上采样层与通道数无关,直接忽略。根据全局阈值γ̂和局部阈值p为各卷积层构造修剪掩码Mask,本文是对通道维度进行修剪,Mask 为一维向量,长度和对应层的通道数相等,需要修剪的通道在Mask 向量中对应的值为0,不需要修剪的为1。对于route层,按顺序合并其输入层的掩码,并将合并的掩码作为其修剪掩码。对于shortcut 层,将所有与其相连层的修剪掩码,进行or运算,运算后的结果作为shortcut层的修剪掩码。具体操作如图4所示。
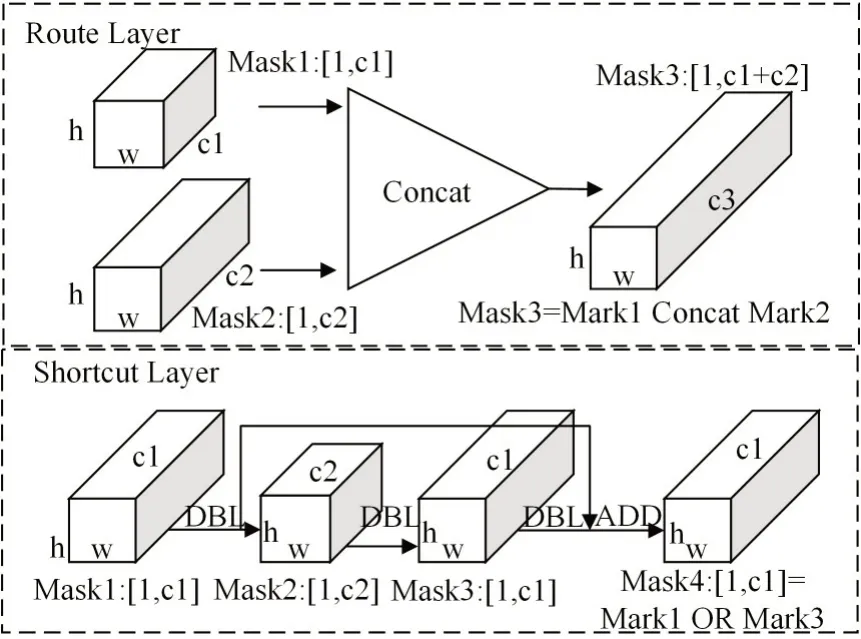
图4 Route与Shortcut层的修剪掩码构建
3.3 微调
在通道修剪之后,模型的检测精度可能会有暂时的下降,尤其是在对小目标物体进行检测时,对通道剪枝更加敏感,通过对修剪后的模型进行微调操作,以恢复损失的检测精度。在实验中,使用与YOLOv3-A 正常训练相同的超参数重新训练SlimYOLOv3-A,以达到微调的效果。
4 实验结果与分析
实验环境为i7-8700K 处理器,32G 内存,GTX2080Ti显卡。
4.1 实验数据集、基准和评价指标
本文使用VisDrone2018 数据集测试模型的修剪效果,使用自制物流仓库常见障碍物数据集测试修剪后的模型障碍物检测效果。VisDrone2018 数据集包括人、汽车、货车、摩托车等共十类目标;障碍物数据集包括物流箱、叉车、货架、机器人、垃圾桶、警示牌共六种大小,远近不同的障碍物,对障碍物数据集进行旋转、缩放、翻转等操作实现数据扩充。选取Tiny-YOLOv3 和YOLOv3 作为基准模型,与不同剪枝率的SlimYOLOv3-SPP3 进行对比实验,评价指标有精准率、召回率、F1、mAP、FPS、参数量、模型体积。
4.2 模型训练
在VisDrone2018 和障碍物数据集上,对YOLOv3 和YOLOv3-A 进行训练,网络输入的图片尺寸为416×416,mini-batch 为64,动量系数为0.9,权重衰减为0.0005,初始学习速率为1-3,分别在迭代到7 万次和10 万次时,学习率下降到1-4和1-5。对YOLOv3-A 迭代100 次稀疏训练,使用三个不同的惩罚因子,α分别为0.01、0.001、0.0001,全局阈值γ̂设为所有比例因子的50%、90%和95%,局部阈值p设为各卷积层中所有比例因子的90%,以保证每层至少有10%的通道未被修剪,其他参数与上文一样,修剪过后的模型为三种不同剪枝率的SlimYOLOv3-A。为恢复因通道剪枝造成的检测效果下降,用训练YOLOv3-A相同的超参数重新训练SlimYOLOv3-A。
4.3 结果与分析
4.3.1 实验1
利用YOLOv3 和YOLOv3-A 在VisDrone2018数据集上进行对比实验,分析PSA模块对检测效果的影响,结果如表1所示。
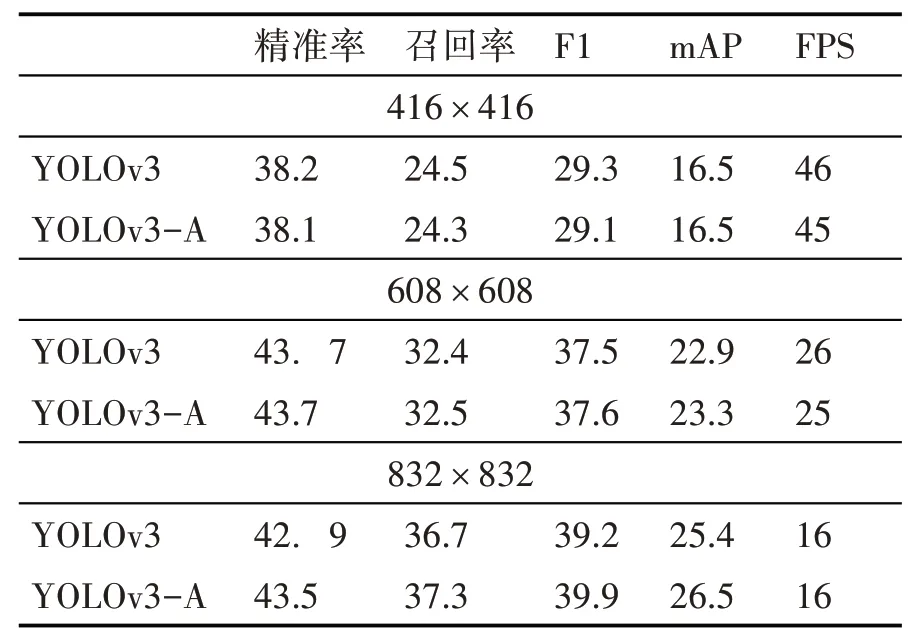
表1 PSA模块对检测效果的影响
由表1 可看出,输入尺寸为416×416 和608×608 时,YOLOv3 和YOLOv3-A 检测性能相当。当输入尺寸增大到832×832 时,YOLOv3-A 比YOLOv3 在精准率、召回率上提高了0.5%左右,F1 提高了0.7%,mAP 提高了1.1%,FPS 保持不变。说明随着输入图片尺寸的增大,PSA 中SPC 模块使用的空间金字塔卷积结构,可以更好地整合输入特征图的空间信息,在细粒度的水平上提高多尺度的表达能力,并形成远程通道依赖关系;检测器从而能通过高分辨率输入图像中不同大小的感受野提取更多有用的多尺度深层特征信息。因此增加注意力模块的的YOLOv3-A模型对比YOLOv3模型在Vis-Drone2018数据集上,对背景复杂、特征不明显的小目标物体有更好的检测效果。
4.3.2 实验2
在实验1 的基础上,对检测效果更好的YOLOv3-A模型使用大小不同的惩罚因子进行稀疏训练,损失函数如图5(a)、(b)、(c)所示。
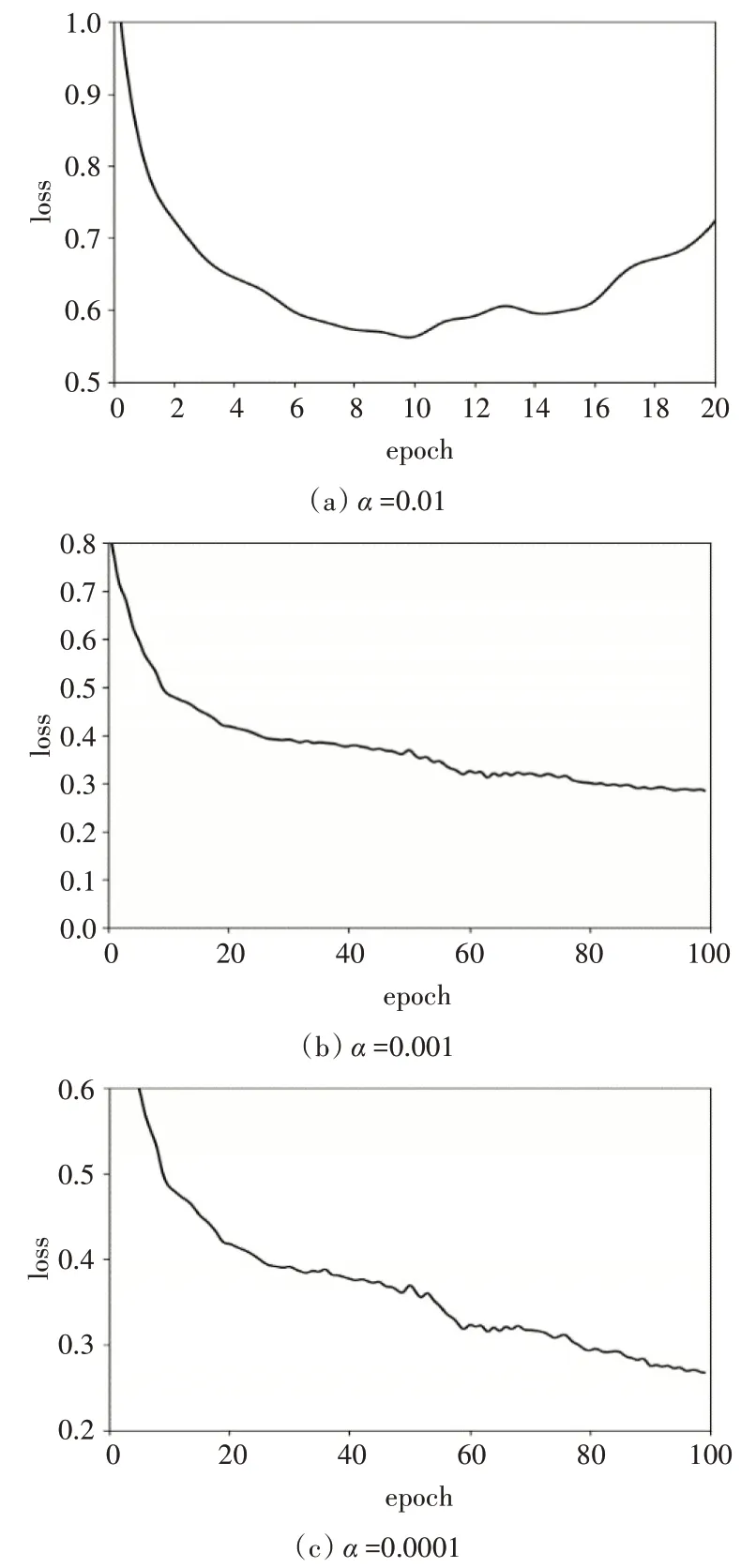
图5 不同惩罚因子α 的模型的损失函数
图5 分别对应稀疏训练时惩罚因子α为0.01、0.001 和0.0001 的模型迭代次数和损失曲线。模型训练时,较小的通道比例因子数量增加,较大的数量减少。图5(a)中模型出现过拟合现象,通过观察发现,因为α过大,增加了稀疏部分的权重,稀疏训练时通道比例因子衰减的十分剧烈,从而导致该现象;调整α的值,发现随着α的降低,通道比例因子衰减逐渐平缓,过拟合现象随之消失。后续实验中,使用α为0.0001训练的YOLOv3-A 模型来进行通道修剪。
选取Tiny-YOLOv3、YOLOv3-A、三种不同剪枝率的SlimYOLOv3-A,共五种模型,输入尺寸为832×832,分析稀疏训练和模型剪枝的效果。实验结果如表2所示。
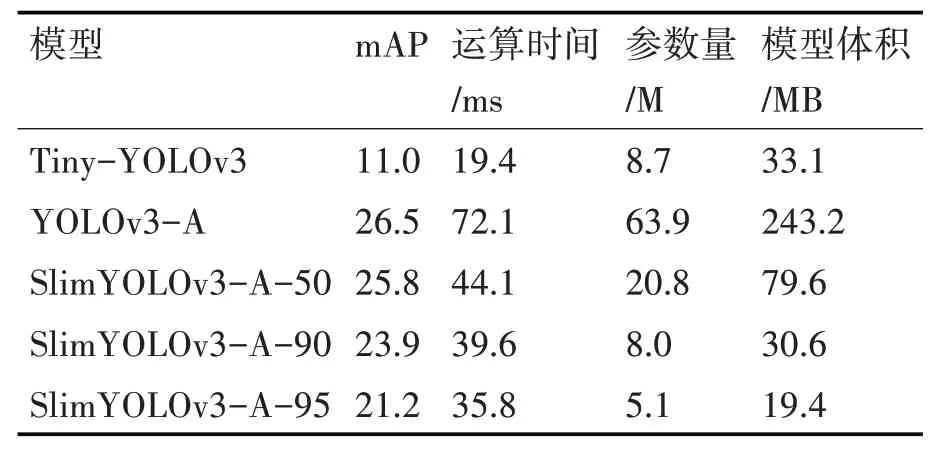
表2 通道剪枝的效果
根据表2 的结果,与YOLOv3-A 相比,通道剪枝后的三个模型在检测精度小幅提高的情况下,参数量分别减少了67.4%、87.5%和92.0%,模型体积分别缩小了67.5%、87.4%和91.9%。虽然剪枝后的模型在运算时间上不如Tiny-YOLOv3,但是达到了35ms~40ms,能够满足实时性的要求,且检测精度提高了105%~135%,更适合实际应用场景。综上结果,SlimYOLOv3-A 模型的可训练参数甚至比Tiny-YOLOv3 更少,检测效果也与YOLOv3-A 相当,这样的结果意味在同等的可训练参数下,一个更深更窄的YOLOv3 模型可能比一个更浅更宽的YOLOv3 模型更有效。此外通过比较三个不同剪枝率的模型可以得出,剪枝率的提高,参数量和模型体积会相应地减少,但是检测精度有一定幅度的下降,剪枝率为90%的模型的综合性能最好。
4.4 检测结果分析
为了进一步体现改进后模型的检测性能,选取上文中性能最优的SlimYOLOv3-A(90%剪枝率)模型,随机从移动物流机器人拍摄的的视频中截取四帧图片进行检测,结果如图6、图7 所示。图6 是利用YOLOv3和SlimYOLOv3-A对大小不同的障碍物进行检测,图7是对远近不同的障碍物进行检测。

图6 两种算法对大小不同障碍物的检测结果

图7 两种算法对远近不同障碍物的检测结果
图6 和图7 两组图片,分别是对大小不同的障碍物和远近不同的障碍物的检测效果。每张图片的场景复杂,光线暗,有三个大小不同或远近不同的障碍物。从检测结果可以看到,YOLOv3 可能因为昏暗的背景,最小的障碍物特征不明显,有两张漏检了小目标障碍物,另外两张只检测出一部分;而改进后的SlimYOLOv3-A 算法有效地检测出了三个障碍物。对于存在多个大小不同的障碍物的复杂场景,改进的SlimYOLOv3-A 中的PSA 模块,可以帮助检测器通过输入图像中不同大小的感受野提取有用的多尺度深层特征。因此改进后的检测算法能够提高对特征不明显的小目标障碍物的检测准确率,降低漏检率,另两个检测结果中,大目标障碍物的检测准确率,也有2%~5%的提高。
5 结语
本文提出一种改进的SlimYOLOv3-A 障碍物检测算法:在YOLOv3 的backbone 后添加PSA 注意力模块,用最小的修改丰富深度特征;通过用L1 正则化施加再通道比例因子上,来加强卷积层的通道稀疏性,删去通道比例因子较小的通道,从而获得更加精简的Slim YOLOv3-A模型。实验证明,改进的算法能够在保证检测精度略有提升的情况下,参数量和模型体积都大幅度下降。改进后的算法,在保证检测速度的前提下,更精准的检测目标,也能够满足移动物流机器人设备性能,在低功耗下快速准确的检测出障碍物。在未来可以配合相关避障算法,实现完整的避障操作,提高物流仓库的工作效率和安全性。
猜你喜欢
保健医苑(2022年5期)2022-06-10
北京航空航天大学学报(2021年9期)2021-11-02
成都信息工程大学学报(2021年6期)2021-02-12
动漫界·幼教365(中班)(2020年3期)2020-04-20
铁道通信信号(2020年9期)2020-02-06
电子制作(2019年11期)2019-07-04
北京航空航天大学学报(2018年1期)2018-04-20
天津诗人(2017年2期)2017-03-16
电视技术(2014年19期)2014-03-11
计算机工程(2014年6期)2014-02-28
