
Attention-Like YOLO:嵌入类注意力机制的YOLO算法*
2023-12-09 08:50胡朝海李自胜王露明
计算机与数字工程 2023年9期
胡朝海 李自胜 王露明
(1.西南科技大学制造科学与工程学院 绵阳 621000)
(2.制造过程测试技术教育部重点实验室 绵阳 621010)
1 引言
目标检测是计算机视觉领域研究热点和难点之一,广泛应用于人机交互、智能导航等领域[1],其主要任务是精确定位图像中一个或多个目标,并判断其类别[2]。传统的目标检测算法如HOG[3]、SIFT[4]等,主要通过滑动窗口生成大量的候选区域,随后提取每个区域的图像特征,再将提取到的特征传递给(SVM)[5]或Adaboost[6]等传统分类器。虽然这些方法能够取得较好检测效果,但特征提取过程中计算开销大,实时性差,从而在应用场景中受到极大的限制。
近年来,研究人员将卷积神经网络CNN[7](Convolutional Neural Network)应用于目标检测,CNN 强大的特征提取能力大幅度提升了目标检测的检测速度和精度。基于CNN 的目标检测方法主要有两类:基于候选区域的检测方法和基于回归的检测方法。2014 年,Girshick 等[8]将CNN 应用于目标检测,提出了R-CNN(Region with Convolutional Neural Network)算法。R-CNN 算法通过selective search 获取2000 个候选区,随后逐个输入CNN 进行特征提取,因其候选区域多计算开销等,该算法未能得到很好的应用。2015 年,Girshick 等受到SPP-Net[9](Spatial Pyramid Pooling-Net)的启发,将ROI pooling 融入R-CNN 提出Fast R-CNN[10]网络,但该算法仍依赖selective search 来生成候选区域。同年Ren 等[11]将RPN(Region proposal network)网络融入Fast R-CNN 提出了Faster R-CNN,用RPN代替Selective search 生成候选区域,进一步加快了检测速度并提升了精度,使网络达到实时目标检测效果。
基于回归的检测方法,主要代表有YOLO(You Only Look Once)系列和SSD(Single Shot Multi Detector)系列算法。2017 年Liu 等[12]提出了SSD 算法,以VGG-16[13]为Backbone,将具有丰富几何信息的浅层特征用于小目标检测,具有丰富语义信息的深层特征用于大目标检测。2017 年Hu 等[14]提出了DSSD(Deconvolutional Single Shot Multi Detector)网络,此网络在SSD 的基础上加入了Deconvolutional layer 和残差结构提升了精度。2015 年后,Redmon 等[15~16,21]相继提出了YOLOv1、YOLOv2 和YOLOv3 算法,YOLOv1 算法一步完成图像中目标定位、检测和分类,实现实时目标检测。YOLOv2是YOLOv1 的改进版,受到ResNet[17]启发,该算法重新设计特征提取网络DarkNet-19 网络。YOLOv3 改进YOLOv2 的DarkNet-19 网络,设计了DarkNet-53 网络作为YOLOv3 的特征提取网络。得益于DarkNet-53 和多尺寸训练,使得目标检测性能得以提升。YOLOv3 由于检测速度快和精度高的优势在各个行业中被广泛使用,然而在精度要求更高的目标检测任务中,YOLOv3 精度还有待提升。
嵌入注意力机制是改进目标检测算法性能常用方法之一。Hu 等[18]提出了SENet(Squeeze and Excitation Net)网络,该算法将特征图的高和宽都压缩为1,得到(C×1×1)的特征数据,再与原维度的特征数据相乘实现注意力机制,即通道注意力机制。Woo 等[19]提出卷积注意模块CBAM(Convolutional Block Attention Module),和SENet 相比,增加了实现空间注意力的功能。向YOLOv3 嵌入注意力机制后取得较好的效果,如2019年Xu等[20]将Attention 嵌入YOLOv3 算法提出了Attention-YOLO算法,但Attention 权值较为单一,注意力效果有限。本文提出了类注意力机制(Attention-Like),在YOLOv3 的DarkNet-53 中嵌入Attention-Like 类注意力,实现了AL-YOLO(Attention-Like YOLO)算法。实验表明,嵌入此Attention-Like后YOLOv3的性能得到了一定的提升。
2 YOLOv3检测算法概述
YOLOv3 模型的特征提取网络是DarkNet-53网络。其结构如图1 所示。图中Conv 表示卷积层(Convolutional layer),BN 表示BatchNorm,对数据进行批正则处理,LeakyRelu 表示激活函数。YOLOv3的预测结构如图2所示,将特征提取网络的后三个不同尺寸的特征图用于目标检测,图中的(n×c×13×13),其中n表示batch size,c表示通道数,13和13 分别表示特征图的高和宽。Conv 表示卷积层,对特征图进行卷积操作,Concat 表示将两条支路上的特征图在c维度上进行堆叠。对Concat 操作后的特征图分别进行卷积操作调整其通道数为(256,512,1024)。

图1 DarkNet-53网络结构
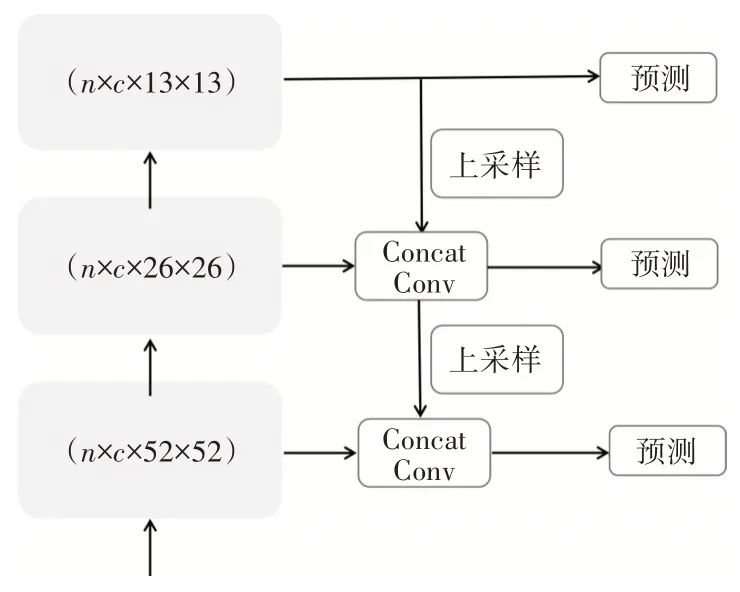
图2 YOLOv3 预测结构
3 AL-YOLO网络模型
3.1 Attention-Like网络结构
Attention-Like 能更好地关注图像中有目标存在的区域,抑制没有目标的区域。本文提出的Attention-Like 是将前一个特征图上的几何信息在后一个特征图中凸显出来,通过学习,增强有目标部分的特征图权重,抑制没有目标的特征图权重,来降低没有目标部分特征图对目标检测造成的影响。如图3 所示,Attention-Like 模块的输入为FA和FB。
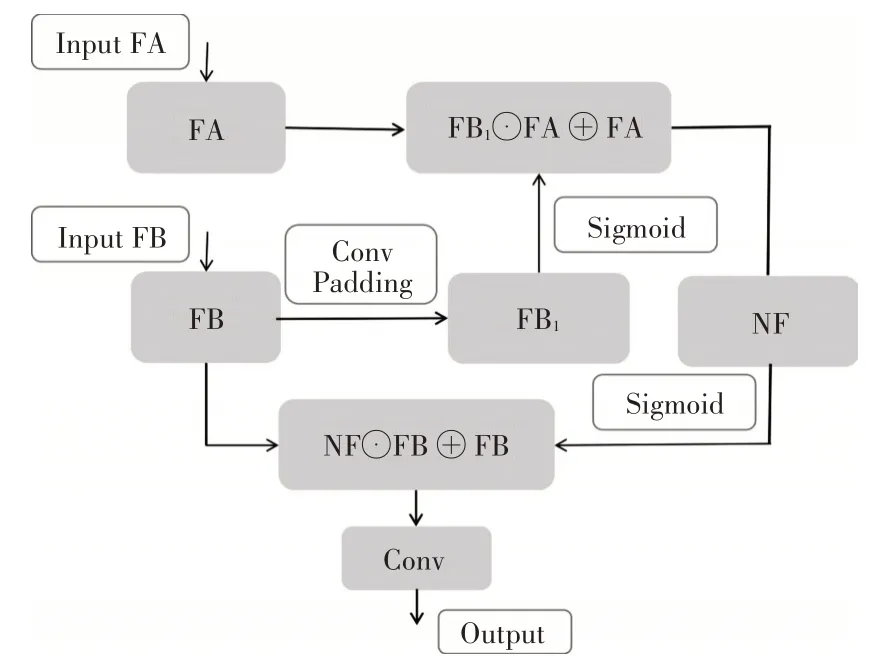
图3 Attention-Like网络结构
其中C*、H*、W*分别表示特征图的通道数、高度和宽度。
C'=2C'',H'=2H'',W'=2W'',令ω=[ω1,ω2,…,ωc],c表示第c个特征图通道,ωc表示第c个特征图通道上的卷积核参数,⊗表示卷积。整个卷积过程可由下式(5)表示:
在卷积过程中,进行Padding 补0,使得FB1和FA的高度和宽度相等。紧接着将卷积后的特征图通过Sigmoid 函数,再与FA特征图逐元素相乘再相加,可由如下公式表示:
上式中⊙表示逐元素相乘,⊕表示逐元素相加,下同。得到NF后,对NF进行步长为2 的卷积操作,使特征图的高和宽为原来的一半。将NF通过Sigmoid 函数,再将NF与特征图FB逐元素相乘和相加,最后输出可由如下公式表示:
3.2 AL-YOLO网络模型
YOLOv3 将原图和标注进行训练,很大幅度上提升了网络的训练速度和预测速度。该网络模型又为全卷积网络,且采用回归算法,进一步提升了该算法的训练和预测速度。本文提出的Attention-Like需要两个输入值,可嵌在任意两个或多个卷积操作之后。向DarkNet-53 中嵌入Attention-Like,如图4 所示,分别在DarkNet-53 的第一个模块和第二个模块之后嵌入Attention-Like,得到AL-YOLO 算法。其中第一个Attention-Like 的输入分别为DarkNet-53 的第一个模块的Con(3,1,1)的输出和Con(3,2,1)的输出,Con(3,1,1)的输出对应图3的FA,Con(3,2,1)的输出对应图3中的FB。第二个Attention-Like 的输入分别为第一个Attention-Like 的输出和DarkNet-53 的第二个模块Con(3,2,1)的输出,分别对应图3中的FA和FB。
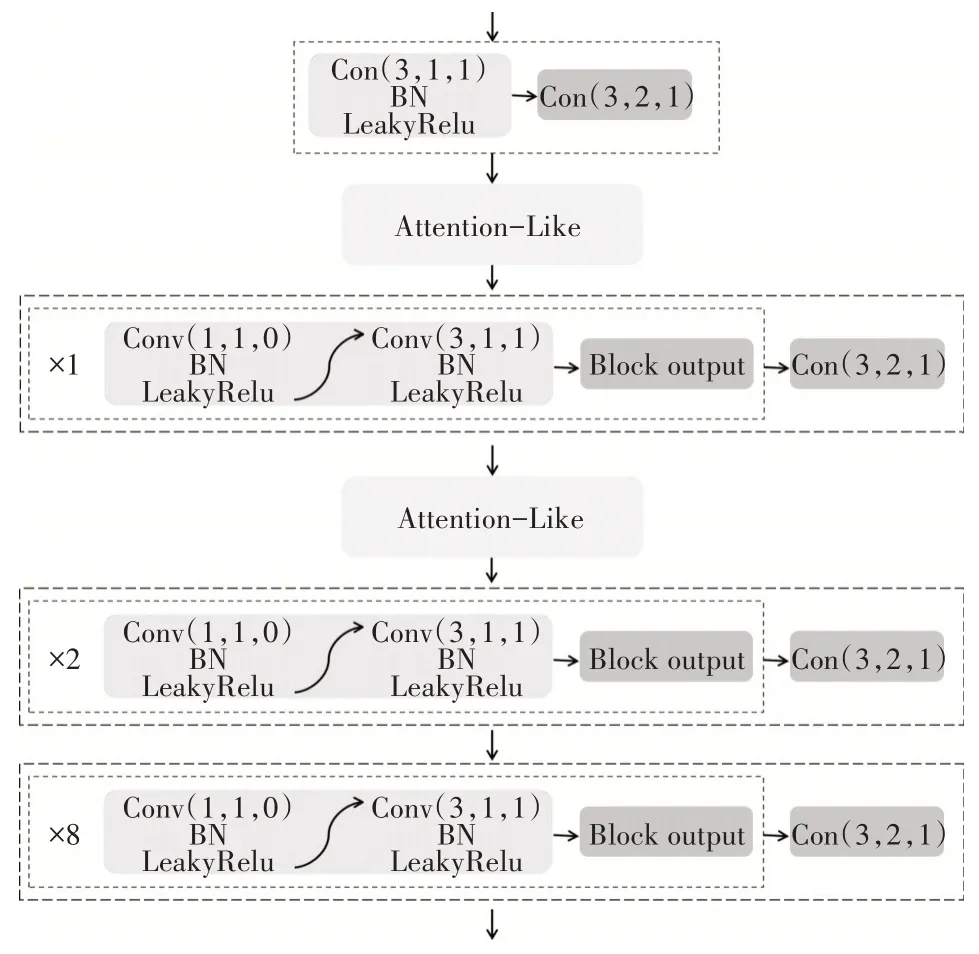
图4 Attention-Like嵌入DarkNet-53
YOLOv3 将DarkNet-53 网络的后三个模块的输出用于检测,以分辨率为416×416 的输入图像为例,后三个大小不同的特征图经过Concat和卷积以后,分别得到(13×13×75)、(26×26×75)和(52×52×75)的特征图,特征图的高和宽取决于输入图像的大小,75 取决于数据集有多少个目标类。75=3×(4+1+20),其中3表示特征图的每个网格上生成三个检验框,4 表示每个检测框的中心位置坐标值和高宽值的数目个数,1 表示每个检验框中包含目标的置信度,20 表示数据集PASCAL VOC 数据集中的20个类,AL-YOLO沿用此检测方法。
3.3 检测过程
通过DarkNet-53 网络对输入图像提取特征后,将最后三个大小不同的特征图用于目标检测,若输入图像的分辨率为416×416,最后三个特征图的分辨率分别为52×52、26×26、13×13。在检测阶段,根据特征图的大小生成网格,再在每个网格中生成三个边界框,共生成(52×52+26×26+13×13)×3=10647 个边界框,其中3 表示每个网格上生成3个检测框。在每个网格上,网络预测了25 个值,其中前两个值是边界框的中心坐标,用tx和ty表示,第三和第四个值表示边界框的宽度和高度,用tw和tℎ表示,第五个值表示边界框中有无目标的置信度,用t0表示。用(cx,cy)表示边界框相对于图像左上角的偏移量,在图像坐标中,设置左上角为图像的坐标原点。用pw和pℎ表示先验边界框的宽度和高度。目标的边界框预测值可如下表示:
其中Pr(object)表示目标是否处于预测框中,若有目标存在,则Pr(object)=1,反之Pr(object)=0,表示预测框和真实框之间的交并比,其中gt表示真实框,object表示预测框。剩余的20 个值用来预测框中目标的类别,最大值对应的索引即为目标所属类别。
4 实验结果
4.1 数据集与训练模型
实验采用公开的PASCAL VOC数据集,该数据集由20 个类别的图像组成,如aero、bike、bird、boat等。使用VOC2007 train+val 和VOC2012 train+val(共计16551 张图像)训练模型,使用VOC2007 test(共计4952张图像)测试模型。
实验硬件配置:双核Intel(R)Xeon(R)CPU Gold 5115,内存大小为32GB,一块Quadro P4000显卡,显存为8GB。软件配置为Windows10,编程语言为Python3.7,使用Pytorch-1.7.1+cu101 框架构建网络。在训练过程中,先将DarkNet-53在ImageNet上进行预训练,嵌入Attention-Like 模块后加载预训练好的网络模型。训练160 个epoch,每个epoch从(320~640)中以32 为间隔随机抽取一个数作为输入图像的高和宽,实现多尺寸训练。本文设置初始学习率为0.001,动量momentum 为0.9,权重衰减系数为0.0005,batch size 为4,交并比阈值为0.5。通过水平翻转、随机裁剪和随机仿射实现数据增强。
4.2 评价方法
在测试阶段,采用mAP(mean Average Precision)平均精确率均值评价检测性能。交并比IOU的阈值为0.5,通过IOU 计算出精准率P(Precision)和召回率(Recall),然后画出PR 曲线图(Precision-Recall),在峰值点向左画一条线和上一个峰值的垂线相交,与横轴和纵轴形成封闭的图形,计算出此面积即为AP(Average Precision)。用此方法计算出所有类别的AP,然后求其均值即为mAP,可由如式(13)表示:
其中C为类别数,本文C=20。
4.3 实验结果
4.3.1 Faster-RCNN、SSD512和AL-YOLO对比
将AL-YOLO 和主流的目标算法进行对比,Faster-RCNN[11]、SSD512[12](输入图像高和宽为512)以及AL-YOLO的实验结果如表1所示。

表1 三种算法在PASCAL VOC测试集上的检测精度(单位:%)
从检测结果可以看出,AL-YOLO 在每个类别上的检测精度几乎都高于另外两个算法每个类别上的检测精度,三个算法对比如图5所示。
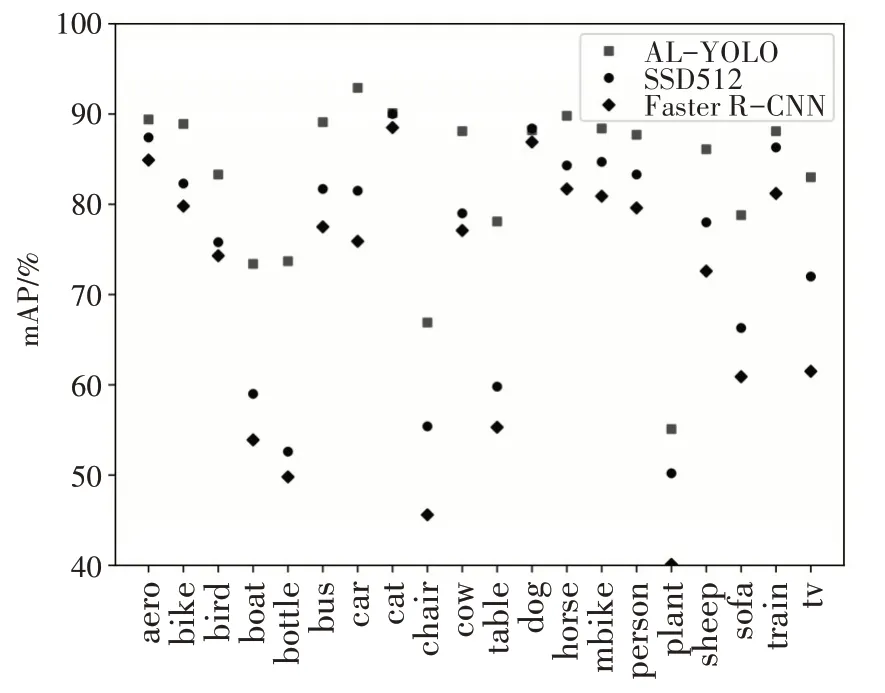
图5 三种算法在PASCAL VOC测试集上每个类别的检测精度对比
三种算法在PASCAL VOC 测试集上的mAP 对比如表2 所示,AL-YOLO 算法精度均高于其余两种算法,分别高出12.4%和7.9%。

表2 三种算法在PASCAL VOC测试集上的平均精确度均值(mAP)对比
4.3.2 AL-YOLO和其他改进的YOLO算法对比
AL-YOLO 和其他基于YOLOv3 改进的算法进行对比,如表3 所示,AL-YOLO 精度均高于该两种算法,分别高出1.1%和0.9%。
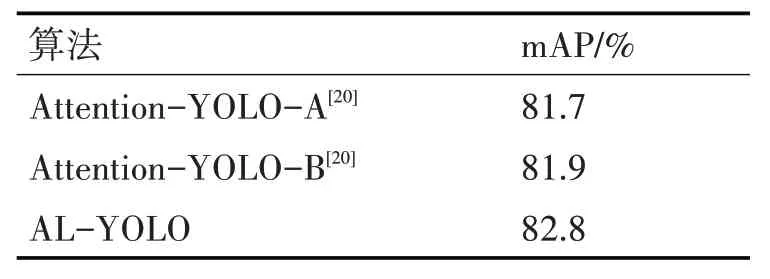
表3 AL-YOLO与其他基于YOLO v3改进的算法在PACSCAL VOC测试集上对比
AL-YOLO 和Attention-YOLO-A 和Attention-YOLO-B 相比较,AL-YOLO 的权值在数量上远大于Attention-YOLO的权值数量,更能关注图像中每个目标存在的位置及目标的语义信息和几何信息,从而提升目标检测精度。
5 结语
本文提出了Attention-Like 类注意力机制,将之嵌入到YOLOv3 的骨干网络DarkNet-53 中实现了AL-YOLO 算法。实验结果表明,Attention-Like不断学习特征图中有目标存在区域的权重,增强了小分辨率特征图的几何信息,从而提升了模型目标检测的性能。由于设计的模型结构简单,嵌入Attention-Like 后网络复杂度和浮点运算量的增量分别不超过1%,实时性能和YOLOv3 相当。下一步工作将研究更进一步优化Attention-Like,力求再次提升模型的目标检测性能。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09
北京航空航天大学学报(2021年9期)2021-11-02
电子制作(2019年11期)2019-07-04
电子制作(2018年19期)2018-11-14
北京航空航天大学学报(2018年1期)2018-04-20
传媒评论(2017年3期)2017-06-13
自动化学报(2017年11期)2017-04-04
第二课堂(课外活动版)(2016年2期)2016-10-21
噪声与振动控制(2015年4期)2015-01-01
电视技术(2014年19期)2014-03-11
