
结合Graph-FPN与稳健优化的开放世界目标检测
2023-12-08 11:49谢斌红张鹏举
计算机与生活 2023年12期
谢斌红,张鹏举,张 睿
太原科技大学 计算机科学与技术学院,太原 030024
目标检测[1]是计算机视觉领域的重要研究方向,其旨在从图像中定位感兴趣的目标,并准确判断每个目标的类别。随着计算机技术的发展和计算机视觉技术的广泛应用,目标检测算法在准确性和实时性方面已经取得了出色的表现,并广泛应用于智慧安防、无人驾驶以及远程医疗等领域。然而,常规的目标检测方法[1-8]通常设定在封闭世界的假设中,即在特定的数据集上进行训练,学习固定数量的目标类别,并应用于特定场景,这很大程度上限制了目标检测技术的发展和应用。开放世界目标检测突破了主流基准中的封闭假设,将目标检测模型应用到开放领域中。它于2021年由Joseph等[9]首次提出,其主要任务是:(1)图像中可能包含未知类别的目标对象,在无监督信息的情况下,能将未参与训练的类别目标对象识别为“未知”;(2)当未知目标有可用标签信息时,模型可以在不遗忘已知类别也不需要在已知类上重新训练的情况下,能够实现未知类别的目标检测。在现实世界中,由于新目标类别的数量不断增加,并且动态变化,探索OWOD(open world object detection)对机器人、自动驾驶、医疗保健监测等领域具有重要的应用价值和现实意义。
与常规目标检测任务不同,OWOD 在从背景中分离未知目标以及模型持续学习等方面提出了重大挑战。ORE(open world object detection)[9]是Joseph等[9]提出的一种开放世界目标检测的解决方案,它以两阶段的目标检测模型Faster R-CNN(faster regionbased convolutional neural networks)作为基础模型。首先使用自动标注未知类别的RPN网络(auto-labelling unknowns with region proposal network,ALU-RPN)标记出图像中潜在的目标区域,将预测框中对象性分数高且与已知类目标不重叠的目标直接归类为未知目标,并将提取的特征加入到相应的已知和未知队列中。然后在ROI Head中利用对比聚类对特征队列进行特征分离,帮助基于能量的分类头更有效地区分已知和未知实例。之后使用基于能量的分类器(energy based classification models,EBM)对已知类别和未知类别的能量值分布进行Weibull 建模,根据目标特征的已知和未知的能量值将其进行分类。最后,采用两阶段微调策略(two-stage fine-tuning approach,TFA)[10]帮助模型在开放世界目标检测的场景下实现增量学习。
ORE作为首次提出应对具有挑战性的开放世界目标检测任务的解决方案,仍然存在一些问题:(1)RPN依赖单一尺度的Feature Map容易造成未知目标的边界模糊和细节丢失,难以对未知目标进行准确定位,导致未知目标召回率较低。(2)新增类别样本较少导致模型难以很好地学习新任务,并且微调策略不足以克服旧类别的灾难性遗忘,使得模型在增量学习过程中性能严重下降。
针对上述问题,提出一种基于图特征金字塔网络的稳健优化增量学习方法(adjustable robust optimization of ORE based on graph feature pyramid,GARO-ORE),本文的主要贡献是:
(1)采用Graph-FPN 作为特征提取网络,通过其超像素结构和分层设计促使多尺度特征进行交互,获得了丰富的语义信息,优化了未知目标的定位问题。
(2)提出基于平坦极小值的基类学习策略,提升模型的泛化能力,有效缓解了增量学习过程中灾难性遗忘的影响,并利用轻量级锐度感知训练算法进一步降低计算开销。
(3)提出基于知识迁移的分类权值初始化策略,利用旧类的分类权值及新旧类别的特征相似度,对新增类别分类权值进行初始化,帮助网络快速适应新类别。
(4)在OWOD 数据集上进行的大量实验验证了GARO-ORE方法的有效性。
1 相关工作
Joseph等[9]发现人类具有识别环境中未知对象实例的自然本能,并根据当前开集识别和增量学习等技术提出了开放世界目标检测(OWOD)这样一个新的计算机视觉任务。由于OWOD的设定比现有的封闭世界静态学习设置更贴近实际场景,受到了研究学者的广泛关注。下面将从开集识别和增量学习两方面对相关工作进行阐述。
1.1 开集识别
开集识别(open set recognition,OSR)[11-14]认为通过训练集获得的知识是不完整的,即在现实应用过程中可能会遇到新的未知类。针对该问题,相关学者研究探索了利用自监督学习[15]和基于重构的无监督学习[16]方法用于开集识别。虽然这些方法可以识别未知类别,但这些网络在训练过程中不能以增量方式动态更新。Bendale等[17]提出开放世界设置中的图像分类任务,这是首个基于深度学习的开集OSR方法,并能够实现分类网络中的增量学习方法。本文的研究内容与此方法[17]更加贴近,不同的是,此方法[17]应用于图像分类任务,不需要对未知目标定位,而本文的研究内容以端到端的方式在开放世界场景下对图像中的已知和未知目标进行检测。
1.2 增量学习
增量学习[18-20]是一种通过从新数据中学习来增加现有知识的范式。然而,增量学习长期存在一个严重的问题,即灾难性遗忘,它是指由于当前训练中无法访问旧数据,从而导致旧类别的测试性能急剧下降。随着近年来深度学习的发展,提出了许多增量学习的方法用以解决灾难性遗忘问题。当前主要包括三类方法:基于样本回放的方法、基于参数隔离的方法和基于正则化的方法。其中,基于样本回放的方法[21],是根据一系列筛选标准,从旧数据集中抽取一些具有代表性的原始样本,将它们和新任务的样本进行联合训练来达到记忆目的;基于参数隔离的方法[22]通常是在新任务上扩大旧模型,并针对不同任务分配不同的模型参数,进行不同程度的隔离,以防止后续任务对之前学习的知识产生干扰;基于正则化的方法[23]通过在损失函数上引入额外的正则项来对权值调整进行约束。而本文提出了基于平坦极小值的基类学习策略,有效缓解增量学习过程中灾难遗忘问题。
2 基于稳健优化的开放世界目标检测
本章主要针对ORE 算法存在的未知类召回率低,以及增量学习中灾难性遗忘等问题提出了改进后的GARO-ORE模型。
针对ORE 模型未知类召回率低的问题,在2.3 节中提出了利用Graph-FPN优化特征提取,帮助模型提高未知类的召回率。首先,由于OWOD 任务中无法利用监督信息对未知目标进行回归处理,对图像进行超像素分割,并将其作为Graph-FPN 的输入,以更强的语义表征目标边界,从而有助于获取更高质量的候选区域。其次,利用部分-整体的层次结构(partwhole hierarchies)弥合了像素与对象之间的语义差距,增强了目标的语义特征。
为了有效缓解模型在增量学习过程中造成的灾难遗忘问题,在2.4 节中提出了基于平坦极小值的基类学习策略,更有效地保留旧类别检测性能。此外,为了在模型容量固定条件下,提高增量学习的持久性,在2.5 节中提出了基于知识迁移的新增类别权值初始化策略,更有效地提升模型的持续学习能力。
2.1 任务定义
在Joseph 等[9]定义的OWOD 中,模型Mt在t时刻除了需要检测已知类Kt={1,2,…,C}之外,还需要将先前未学习到的目标实例检测为未知类U={C+1,C+2,…}(由标签0 表示)。然后,用户可以选择性地标记n个感兴趣的新类并标注相应未知实例训练模型,将这组新类别添加到已知类别中,即Kt+1=Kt+{C+1,C+2,…,C+n} 。最后,模型Mt在Kt+1上进行增量学习,不需要在整个数据集上进行训练,便可检测Kt+1中所有的目标类别。这种循环在模型的生命周期中持续进行,促使模型自适应更新。
2.2 GARO-ORE网络结构
GARO-ORE 网络结构如图1 所示,包含Backbone、ALU-RPN、ROI Pooling 和分类回归网络四部分。GARO-ORE 首先通过Graph-FPN 提取图像特征。然后,利用ALU-RPN 获取已知和未知目标的潜在区域,并且将对象性得分Topk的背景区域建议框作为候选未知对象。之后,在ROI Pooling 层将ALURPN 的输出进行池化,生成大小一致的特征图。最后,在分类回归网络中,为了更好地区分已知和未知对象,在潜在空间中对池化后的特征进行对比聚类。利用基于能量的分类头学习已知和未知类的能量分布,促进模型更有效识别未知目标。分别预测目标边界框和目标类别。
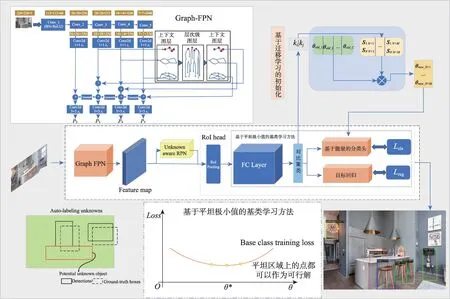
图1 GARO-ORE网络结构Fig.1 GARO-ORE network structure
此外,在本文中,为了缓解基类的遗忘问题,采用基于平坦极小值的基类学习方法对分类回归网络进行训练,并在后续的增量学习过程中钳制模型参数处于平坦区域(flat region)内,使其在增量学习过程中保持旧类别性能的稳定性。另外,在学习新增类别时,采用基于知识迁移的新增类别权值初始化策略,更有效地发掘模型的持续学习能力。
2.3 图特征金字塔网络
ORE 算法使用ResNet50 作为模型特征提取网络,虽然ResNet 具有较强的特征表达和逐层学习能力,但由于其容易造成目标的特征边界模糊和细节丢失,导致模型对未知目标定位不准确,目标框存在偏大或偏小等情况,并且单一的分辨率通常会丢失部分图像信息,继而影响后续目标检测和增量学习性能。针对上述问题,本文在Backbone 模块采用Graph-FPN[24]作为特征提取网络,其结构如图2 所示。首先利用基于全卷积编解码器网络的轮廓检测算法(convolutional oriented boundaries,COB)[25]将原始图像分割成符合目标物体边界语义区域的超像素图像结构,并在图神经网络中利用部分-整体层次结构判断二者之间对象特征语义一致性,进一步提高每个显著对象微观层面的完整性,从而帮助模型对目标准确定位,并快速生成定位质量较高的候选区域。之后,利用上下文层和层次层的分层设计,将多尺度特征进行跨空间和跨尺度的特征交互,并引入局部通道注意力机制增强目标特征的表达能力,为目标检测和新类别学习提供更加丰富的语义信息,从而在有效提升未知目标的召回率的同时,也提升了模型的学习能力。
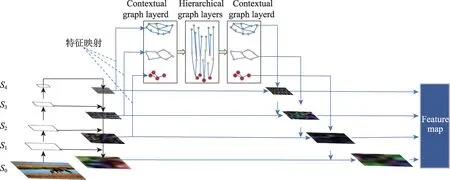
图2 Graph-FPN特征提取网络Fig.2 Graph-FPN feature extraction network
具体来讲,如图2所示,Graph-FPN 包含4个步骤进行特征提取:
步骤1如图3 所示,首先利用COB 超像素算法对图像进行分割,这种超像素图像不仅能防止背景和目标之间的特征混合,而且能有效保留目标的边界信息。然后利用分层分割技术获取图2 中超像素图像的金字塔层级结构S={S0,S1,…,S4},以此来表达图像的局部到整体的层次结构,其中Si+1的超像素数目是Si中的1/4。

图3 COB算法生成超像素Fig.3 Superpixel generation by COB algorithm
步骤2利用S2、S3、S4分别构建图特征金字塔(Graph-FPN)。其中,Si中的每个超像素点与Graph-FPN中的节点对应,并为每个节点构建上下文交互边和层次交互边,通过图神经网络对同一尺度内和不同尺度之间的特征进行融合。
步骤3Graph-FPN 通过空间和通道注意力机制进一步增强特征的表达能力。其中,空间注意力采用式(1)对图中的节点特征进行更新:
其中,M表示图注意力机制[26],hj∈Νi是节点i的邻居节点特征向量,hi和hi′分别是节点i更新前后的特征向量。
通道注意力是由平均池化的局部通道注意力模块和局部通道自注意力模块组成。平均池化的局部通道注意力模块特征更新如式(2)所示:
其中,σ表示sigmoid 函数,W1∈RC×C为全连通层可学习权重矩阵。ai′ ∈RC表示节点i及其邻居的特征向量进行平均得到特征向量。局部通道自注意力模块特征更新如式(3)所示:
其中,β表示初始化为0的可学习权值。X=AT*A表示通道相似矩阵,A表示节点i及其邻居的特征向量集合。
步骤4将经过融合后的特征由图神经网络映射到特征金字塔网络。
总之,利用Graph-FPN 作为特征提取网络,不仅优化了模型的特征表达能力,提高了模型在开放世界环境中的未知目标的检测精度,同时也能帮助模型更好地完成后续的目标检测和增量学习等任务。本文的对比实验也验证了该网络在提高对未知目标检测和增量学习的有效性。
2.4 基于平坦极小值的基类学习策略
灾难性遗忘是增量学习长期存在的一个严重问题,如相关工作中所述,解决该问题对开放世界目标检测任务尤为重要。众所周知,深度神经网络的泛化能力一般与其极小值附近的平坦度[27]有关,并且较为平坦的最优解通常具有更好的鲁棒性,因此,本文提出了基于平坦极小值的基类学习策略,即:在平坦极小值附近对模型参数随机扰动,使其损失移动更加稳健,以此能够更好地解决模型的灾难性遗忘问题。
基于上述动机,本文利用式(5)计算模型的平坦极小值θ*。
其中,式(4)表示Faster R-CNN 的分类和回归损失之和。分别为模型的分类和回归损失,Ki和Pi分别为模型预测的类别和目标框位置,Ki*和分别为训练样本的类别和目标框位置,Ncls和Nreg表示分类和回归的样本数。式(5)中Rs(fθ)表示模型的锐度度量损失,近似于Ls(f(θ+ε))-Ls(fθ)的最大值,s表示训练集数据,θ表示GARO-ORE的模型参数,ε是将Ls(f(θ+ε))的一阶泰勒逼近在θ附近最大化问题的一个近似解,即ε:||ε||2≤ρ,其中ρ表示约束邻域半径的预定义常数。
使用基于平坦极小值的基类学习策略时,首先需要在t=1 的训练阶段,按式(5)求解模型的平坦局部极小值点θ∗作为模型的最优解,然后在t≥2 的持续学习过程中,在平坦区域内钳制模型参数(Fast RCNN 网络的全连接层参数)进行微调,即θ∗-ρ≤θ≤θ∗+ρ。如图4 所示为现有技术(尖锐极小值)和本文方法(平坦极小值)的解释说明[28],其中图4(a)表示模型在引入新类别参数后直接微调模型导致旧类别的检测性能严重下降,图4(b)表示通过引入平坦极小值微调参数可以有效地缓解灾难性遗忘。
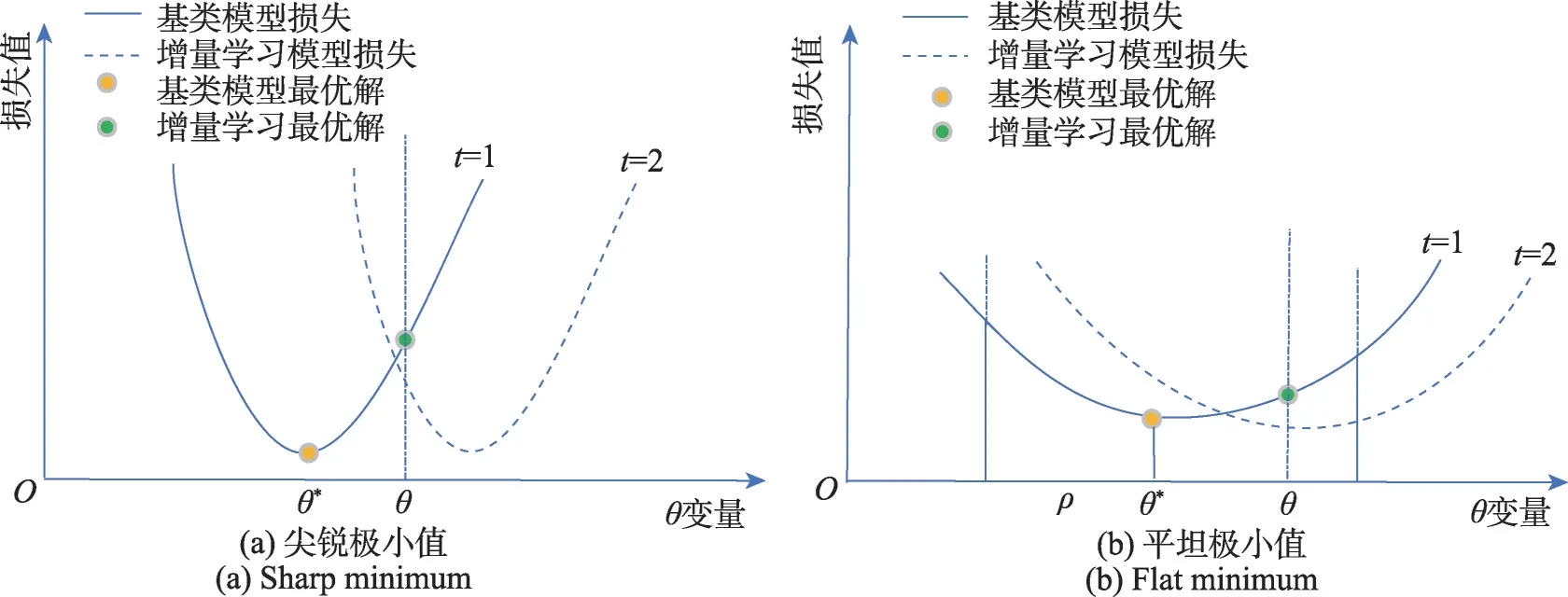
图4 尖锐极小值与平坦极小值的权值变化Fig.4 Weight change of sharp minimum and flat minimum
2.4.1 寻找基类训练阶段的平坦局部极小值
本文采用添加随机噪声的方法来定位目标函数的平坦局部极小值。具体来讲,在Faster R-CNN 全连接层网络参数中通过多次添加随机噪声ε,获取相似但不同的损失函数,并将这些损失函数联合优化以定位平坦局部极小值,具体计算如式(5)所示。由于额外的Rs(fθ)计算增加了模型的计算成本,从而导致在COCO2017、VOC2007 等大型数据集训练时极大降低了模型训练速度。针对该问题,本文采用一种计算开销较小的轻量级锐度感知算法(sharpnessaware training for free,SAF)[29]替换锐度损失Rs(fθ)来寻找基类训练阶段的局部极小值,SAF算法具体计算过程如下。
首先按式(6)计算锐度度量损失Rs(fθ)的一阶泰勒展开式。
如式(6)所示,最小化锐度损失Rs(fθ)等价于最小化梯度∇θLs(fθ)的L2范数,这与最小化Ls(fθ)的梯度相同。另外,由于常规训练(SGD优化器)的学习率μ一般小于ρ,模型在两个连续小批量(mini-batch)数据集迭代中更新权值的训练损失变化如式(7)所示:
由此可知,权重更新后训练损失的变化与Rs(fθ)2成正比,因此,最小化损失差近似于最小化锐度损失,于是本文引入了一种新的轨迹损失,即用标准训练过程中学习到的权值轨迹代替锐度损失,以此降低锐度度量损失的计算开销。
如图5 所示,红色线条表示常规的训练损失Ls(fθ),蓝色箭头表示模型训练轨迹。可以看出,尖锐的局部极小值往往具有较大的轨迹损失,而平坦极小值具有较小的轨迹损失。其中表示E个阶段的轨迹损失大小。
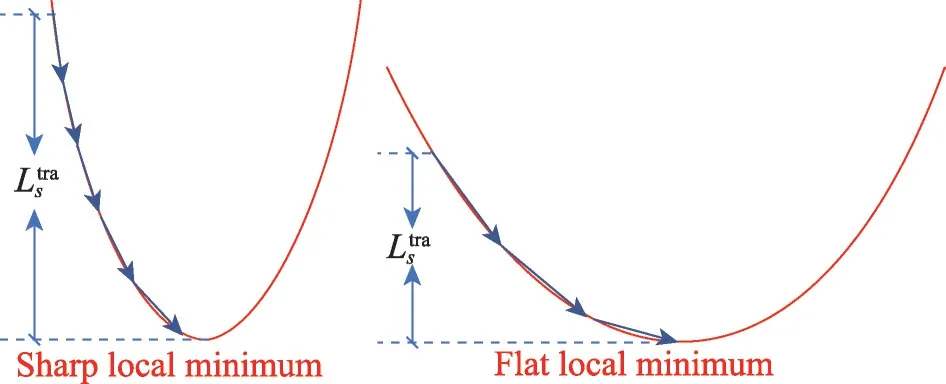
图5 尖锐及平坦极小值的轨迹损失Fig.5 Trajectory loss of sharp and flat minimum
在计算权值轨迹时,首先用Θ={θ1,θ2,…,θt}表示迭代过程中的权值轨迹,其中θt表示第t次迭代权值,则θt+1的迭代权值可表示为θt+1=θt-μ∇θtLSt(fθ)。对于t时刻的锐度损失,可以由式(8)表示:
由式(6)可知,最小化损失差Rs(fθ) 等价于[Lst(fθi)-Lst(fθi+1)],表明轨迹损失可以替代锐度度量损失Rs(fθ),并且能极大降低训练损失计算开销。
另外,为了进一步精确估计锐度损失,只考虑过去E次迭代的模型更新轨迹,其中E为训练的超参数。然而,当同时最小化分类损失和锐度度量损失时,式(9)中的Lst(fθi+1) 交叉熵损失与式(4)中的Lcls(Ki,Ki*)交叉熵损失相抵消。因此,本文将交叉熵损失替换为KL 散度损失以解耦回归损失。另外,受知识蒸馏的启发,本文还使用温度τ来软化KL 散度损失。因此,第e次迭代的轨迹损失定义如下:
2.4.2 持续学习阶段模型微调
在进行增量学习时,对平坦区域内微调分类权值和定位权值以学习新类。值得注意的是,虽然平坦区域可能相对较小,但是足以很好地完成增量学习。
更新全连接层网络参数后,通过对参数进行钳制,以确保其位于平坦区域内,即θ∗-ρ≤θ≤θ∗+ρ。
2.5 基于知识迁移的新增类别权值初始化
在增量学习时,模型首先需要为每个新类别的权值进行初始化。ORE 使用了一组随机值进行初始化,该方法容易导致模型以较慢速度收敛于尖锐极小值,从而往往无法达到期望的学习效率。因此,为了解决ORE 中随机初始化参数方法的缺陷,提出了一种基于知识迁移的新增类别权值初始化方法,其核心思想是利用特征相似度从旧类中学习新类的特定信息,实现新旧类之间知识迁移,从而为分类头提供有效的初始值,并有利于使用少量数据进行微调。
具体来讲,首先采用类别的特征分布表示知识,并通过使用ORE 论文中的对比聚类方法将每个基类的高维特征聚合成多个特征簇,然后将每个特征簇中特征均值作为该类别的知识,如式(11)所示:
其中,kc表示类别c的特征均值,Ni表示该簇内的特征总数,fθ(xk)表示该簇内的第k个样本的特征向量。然后,利用余弦相似度计算新增类别特征均值与旧类别的特征均值相似度并归一化处理,具体计算如式(12)、式(13)所示,其中ki,i∈{1,2,…,C},与kj,j∈{C+1,C+2,…}分别代表n维空间中旧类别与新类别两个特征簇的特征均值。
最后,利用式(14)获取分类权值的初始值,利用得到的初始化权值对模型进行训练。
其中,θold_i,i∈{1,2,…,C}表示模型学习的旧类别参数,sij,i∈{1,2,…,C}表示新类别与旧类别的归一化的相似度,θnew_j表示经过基于知识迁移的新增类别权值初始化得到的新类别参数。通过知识迁移的分类权值初始化,可以有效地将知识从旧类传播到新类,为分类头提供有效的初始值,帮助模型更有效地对新类别建模,使得模型更快地适应新类别,提高模型的检测精度。其实现过程如图6所示。
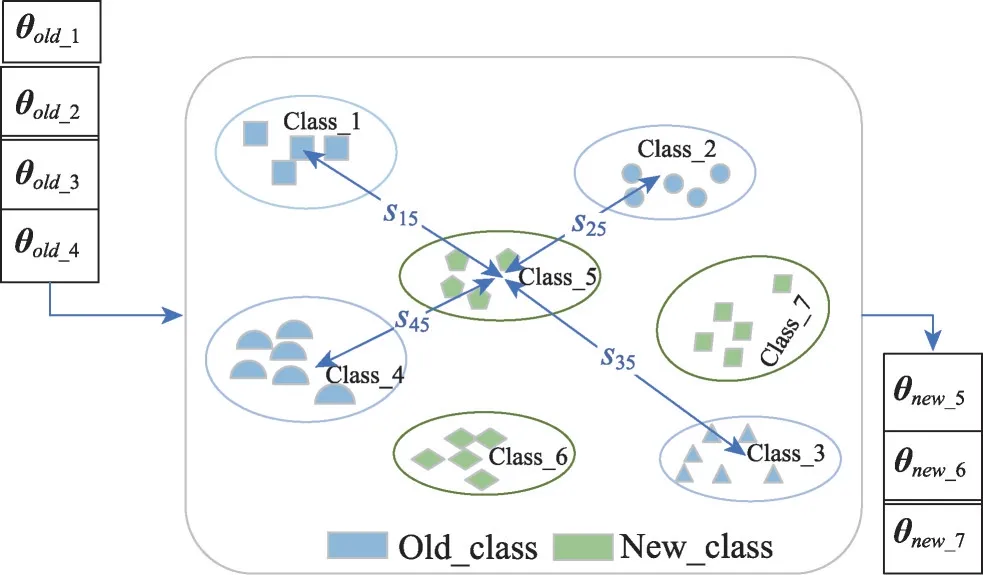
图6 基于知识迁移的权值初始化Fig.6 Weight initialization based on knowledge transfer
通过上述基于知识迁移的新增类别权值初始化,结合在平坦区域内钳制模型参数微调的方法,模型能够有效地避免灾难性遗忘,同时增强其对新类别检测的适应能力。
3 实验
3.1 数据集和评价指标
为了验证GARO-ORE 模型的可行性和有效性,以及比较的公平性,本文遵照ORE[9]实验中的设定,选用OWOD 数据集对模型进行评估。OWOD 数据集由标准数据集VOC2007和COCO2017数据集合并而成,共包含80 种目标类别。同时参考ORE 的实验设置,将这80 个类别划分为4 组不重叠的数据集{D1,D2,D3,D4}进行实验分析。如表1 所示,每个数据集含有20 个不同类别,其中,数据集D1包含VOC-2007 数据集所有类别及其相应类别的训练及测试数据,D2、D3、D4数据集是将剩余60 个类别对应的训练和测试数据划分成具有语义漂移的连续数据集。

表1 实验数据集Table 1 Experimental dataset
本文采用了标准平均精度(mean average precision,mAP)和未知类别召回率(U-Recall)两个指标验证模型在OWOD 任务上的性能。对于每个指标,其值越大表示性能越好。
本实验使用mAP@0.5(IoU 阈值取大于0.5)作为已知类别目标检测的度量指标,其准确率(Precision)、召回率(Recall)和平均准确率AP值和平均准确率均值mAP的计算过程如下式所示:
其中,TP为真正例,FP为假正例,FN为假负例,准确率(Precision)表示模型识别出的正样本占真实正样本的比值,召回率(Recall)表示模型正确识别为正样本的比值,AP值表示Precision和Recall曲线下的面积。mAP表示所有类别AP@0.5的平均值。
未知类别召回率U-Recall作为未知对象检测的评估指标,表示模型预测的未知类别的正确目标占总未知目标的比例。U-Recall计算如式(19)所示:
其中,U_TP表示未知类别预测正确的实例数量,U_FN为未预测出的未知实例数量。
3.2 参数设置
在Graph-FPN 模块中,为了提高其性能,首先利用ImageNet 数据集对该网络进行监督预训练。然后,在GARO-ORE 的训练过程中利用图卷积神经网络对Conv3 到Conv5 提取的多尺度特征充分融合获取更丰富的语义信息。
在Unknown Aware RPN 模块中,本文参考ORE的实验设置,设置伪标签(未知目标)的个数最大为5;在基于平坦极小值的基类学习策略中将式(4)中的平衡系数λ从{0.1,1,10,100}中选择10,将式(6)中的超参数ρ设置为0.05,将式(10)中的超参数E和温度τ分别设置为5来提高轨迹损失的精度。
在优化方面,使用动量为0.9 的随机梯度下降(stochastic gradient descent,SGD),其初始学习率设置为0.02,随后降低到0.000 2。mini batch是从{8,16,32}中选择的16,NMS(non-maximum suppression)阈值设置为0.4。本文在{D1,D2,D3,D4}数据集中对每个任务进行100 000 次迭代训练。在1 000 次迭代后启动聚类和执行分类权值初始化方法对增量学习参数进行初始化(基类学习不进行权值初始化),每3 000次迭代之后更新聚类原型。
3.3 实验结果与分析
实验环境:Intel®Xeon®Silver 4310 CPU@2.10 GHz,64 GB 内存,CentOS7,GPU 处理器为4 块NVIDIA TESLA T4 的独立显卡,本文在detectron2 框架下完成对GARO-ORE 网络模型训练和验证。为了验证GARO-ORE 模型的有效性,首先与当前性能最优的ORE 方法进行了对比实验,然后进行了3 组增量学习实验和时间代价实验,最后进行消融实验,以全面考察本文方法对模型性能的贡献,具体实验结果如下。
(1)OWOD对比实验
本文在{D1,D2,D3,D4}数据集上与ORE 及其他算法进行了对比实验,其中任务T1表示GARO-ORE 模型基类学习D1数据集上的所有类别,T2、T3和T4分别表示将D2、D3、D4数据以增量学习的形式引入模型中,实验结果如表2所示。

表2 GARO-ORE在OWOD设定下的对比实验结果Table 2 Comparative experimental results of GARO-ORE under OWOD setting 单位:%
从表2的实验结果可以看出,本文方法在OWOD任务上取得了最好的结果,无论在旧类别性能的保留还是新类别的检测性能上都有较好的提升。特别地,在数据集{D1,D2,D3}上,GARO-ORE 比最先进的ORE 在U-Recall 指标上分别提升了0.84 个百分点、0.66个百分点和0.64个百分点,在{D1,D2,D3,D4}数据集上,GARO-ORE 在mAP 指标上分别获得0.65 个百分点、1.74 个百分点、1.15 个百分点和1.59 个百分点提升。这说明本文方法不仅能有效增强模型对未知目标的检测效果,并且还可以持续高效地学习到新类别知识,同时保持较好的已知类别识别性能。
(2)增量学习对比实验
本文在D1数据集上模拟增量学习场景。根据开放世界目标检测的设定,模型在t=1 时学习基类Classbase,在t=2 时模型以增量学习方式引入其余类别Classnext。在实验中本文按照难度递减的方式设置了3 种不同的增量学习实验:①在t=1 时刻,模型学习D1数据集上前10个类别,t=2时刻学习剩余10个类别。②在t=1 时刻,模型学习D1数据集上前15 个类别,t=2 时刻学习剩余5 个类别。③在t=1 时刻,模型学习D1数据集上前19 个类别,t=2 时刻学习剩余的1个类别。通过上述3种不同的实验对模型的目标检测增量学习(incremental learning for object detectors,iOD)能力进行评估,实验结果如表3~表5所示。
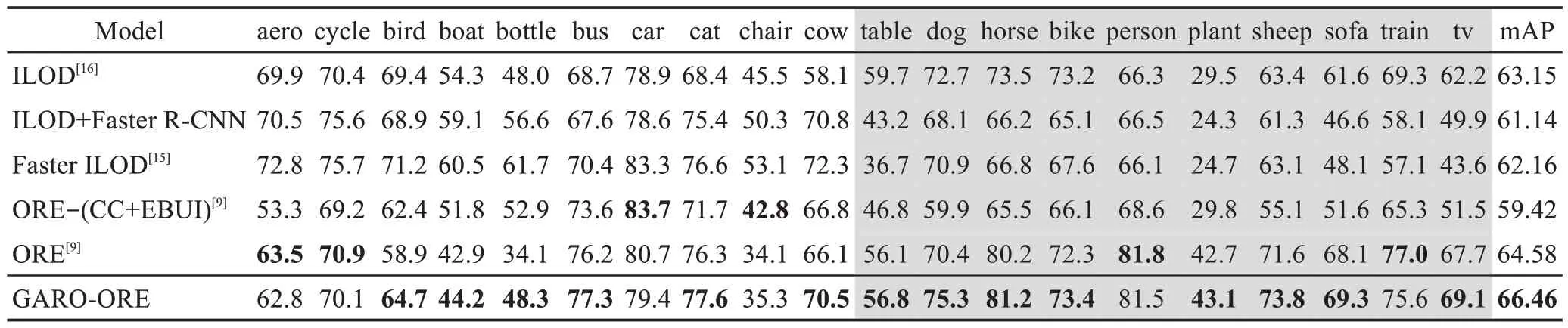
表3 GARO-ORE增量学习的对比实验(10+10)Table 3 Comparative experiment of GARO-ORE on incremental learning(10+10) 单位:%
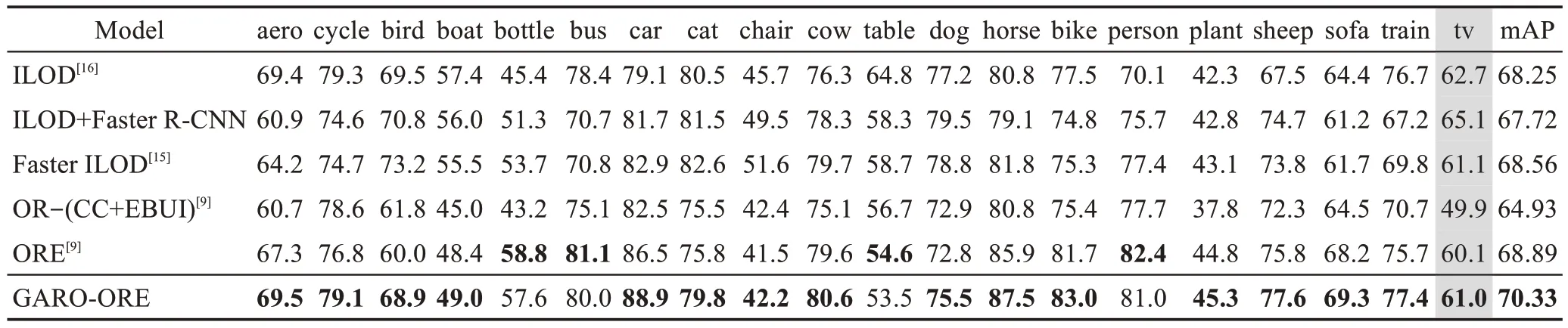
表5 GARO-ORE增量学习的对比实验(19+1)Table 5 Comparative experiment of GARO-ORE on incremental learning(19+1) 单位:%
表3~表5 的实验结果表明,GARO-ORE 在增量目标检测(iOD)任务中表现良好,在大多数旧类别和新类别的AP 值有较大的提升,并且在10+10、15+5、19+1 的增量学习任务中,其mAP 指标分别提升了1.38、1.42和1.44个百分点。从旧类别的AP值可以看出,绝大多数旧类别AP 值都有一定的提升,验证了GARO-ORE 通过求解基类模型平坦极小值,并在其附近的平坦区域内微调参数可有效缓解灾难性遗忘。此外,通过学习的新类别的AP值结果可以看出,引入基于知识迁移的新增类别权值初始化的方法,能够有效增强对新增目标类别的建模能力,帮助模型有效保留旧类别性能的同时还能促进后续任务的学习。
(3)时间代价实验
为了验证GARO-ORE 算法的检测效率,本文与Faster R-CNN、ORE 两个基线模型进行对比,测试图像尺寸统一为800×800,其参数量和推理速度测试结果如表6所示。
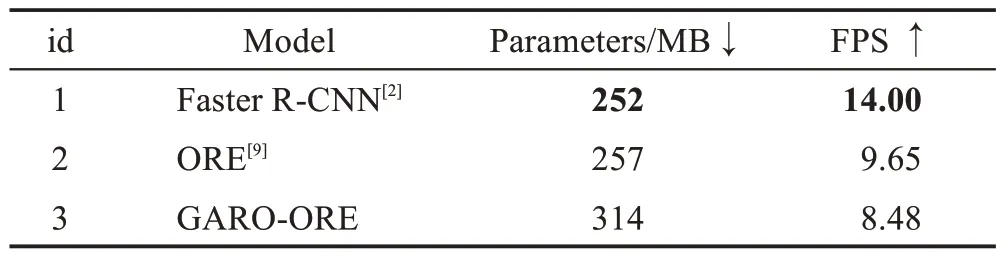
表6 参数量及推理速度对比Table 6 Comparison of parameters and reasoning speed
从表6 实验结果表明,GARO-ORE 相对于ORE模型推理速度由原9.65 FPS 下降到8.48 FPS。其主要原因是为了优化未知目标的检测和增量学习,本文引入Graph-FPN作为特征提取网络,导致模型参数增加,推理速度下降。相较于Faster R-CNN 以及ORE,尽管GARO-ORE模型的推理速度有所下降,但是该模型在处理开放世界目标检测问题上实现了较大的性能提升。
(4)消融实验
为了验证GARO-ORE 每个关键模块的有效性,本文基于数据集{D1,D2,D3,D4}设计了一组消融实验,以详细考察各模块对OWOD的影响。实验结果如表7 所示,其中“√”表示引入相应模块,“×”表示暂不使用相应模块。其中BLFM(baseclass learning strategy based on flat minima)表示基于平坦极小值的基类学习策略,WIKT(weight initialization based on knowledge transfer)表示基于知识迁移的新增类别权值初始化,Pre_Known为先前类别的mAP值,C_Known为新增类别的mAP值。
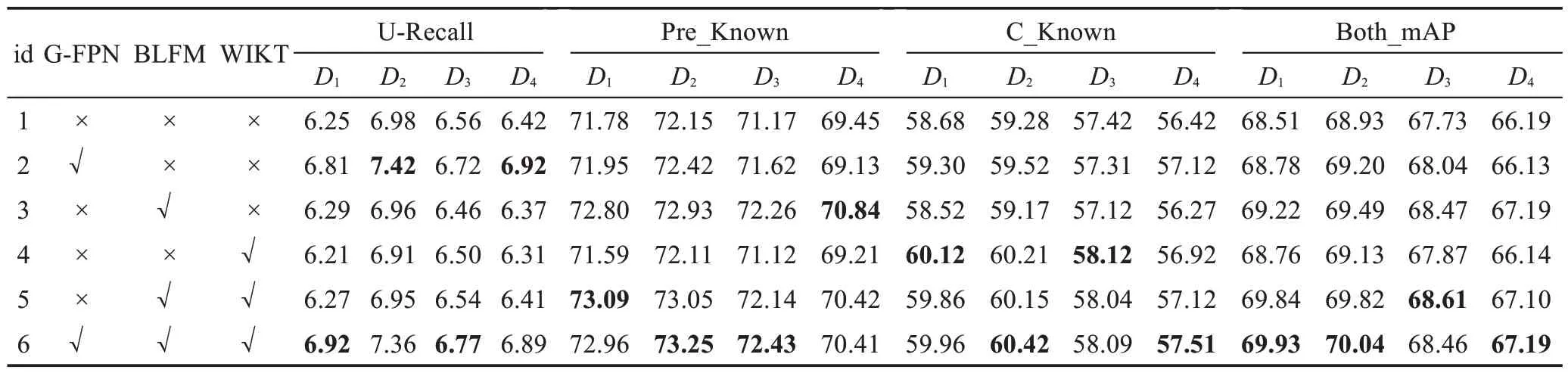
表7 消融实验结果Table 7 Ablation experimental results 单位:%
从表7 实验结果可以看出,GARO-ORE 在{D1,D2,D3,D4}数据集上均获得了较好的性能,其余不完整的模型的性能有不同程度的下降,证明了每个关键模块的重要性,表明所有关键模块都对整体性能有着积极的贡献。以具有代表性数据集D1为例介绍模型各模块实验效果,通过对比实验1 和实验2 可以看出,使用Graph-FPN 代替ResNet 网络能够有效优化未知目标的检测问题。在基类学习过程中,其未知目标的召回率有0.56 个百分点的精度提升,并且在新增类别目标检测中实现了0.62 个百分点的mAP 精度提升,很好促进模型进行了增量学习。对比实验1 和实验3 可以看出,通过引入基于平坦极小值的基类学习策略能够较好地保留旧类别的检测性能,相较于ORE,在旧类别的检测中mAP指标提升了1.02 个百分点。对比实验1 和实验4 可以看出,该方法能够有效地帮助模型进行增量学习。在增量学习中,新类别的mAP指标提升了1.44个百分点。实验6结果表明本文方法达到了最佳性能。在未知目标召回率达到了6.92%,通过增量学习后的目标检测mAP达到了69.93%。
3.4 可视化分析
为了更直观地展示算法的实验效果,如图7 所示,本文选取了三组典型场景图像来对ORE 和GARO-ORE做定性比较。

图7 ORE与GARO-ORE检测效果对比Fig.7 Comparison of detection results between ORE and GARO-ORE
从第一组实验结果中可以看出,与ORE 算法相比,GARO-ORE 检测到了图像左侧的吊灯和中间的餐桌,并正确识别出右侧的椅子。在第二组实验结果中显示,GARO-ORE 将书架中间位置未学习的罐子和书架识别为未知物体。在第三组对比中,ORE错误地将楼层检测成火车,而GARO-ORE 并没有出现类似的误判目标。这些结果表明,GARO-ORE 模型在OWOD 任务上取得了良好的性能,验证了模型的可行性,达到了预期效果。
4 结束语
针对开放世界目标检测任务,提出了一种提升OWOD 检测性能的模型GARO-ORE,该模型由包括Graph-FPN、基于平坦极小值的基类学习策略和基于知识迁移的新增类别权值初始化方法等专用组件组成,用于处理开放世界设置下的目标检测,提升了ORE 模型在OWOD 设定中的检测性能。本文在OWOD 数据集上进行了大量实验,对于该数据集上的所有任务设置,GARO-ORE 均优于当前性能最优的模型ORE。然而,GARO-ORE提升性能的同时,也导致模型结构更加复杂、庞大。因此在下一步工作中,考虑设计一种轻量化模型进一步提高检测效率和性能。
猜你喜欢
成都信息工程大学学报(2022年3期)2022-07-21
当代陕西(2022年6期)2022-04-19
沈阳师范大学学报(教育科学版)(2021年2期)2021-02-01
中学数学研究(江西)(2020年5期)2020-07-03
中学数学研究(江西)(2019年11期)2019-12-31
中学生数理化·中考版(2019年9期)2019-11-25
科技风(2018年19期)2018-05-14
自动化学报(2017年7期)2017-04-18
自动化学报(2017年1期)2017-03-11
电信科学(2016年9期)2016-06-15
