
基于改进特征融合和区域生成网络的Mask R-CNN的管件分拣研究
2023-12-08 13:09韩慧妍吴伟州王文俊
应用科学学报 2023年5期
韩慧妍,吴伟州,王文俊,韩 燮
1.中北大学计算机科学与技术学院,山西太原030051
2.机器视觉与虚拟现实山西省重点实验室,山西太原030051
3.山西省视觉信息处理及智能机器人工程研究中心,山西太原030051
管件分拣是工厂对管件进行镀锌、冷却和抛光等处理的前提。手动分拣需要人工进行长时间繁杂无味的工作,效率低下。目前很多公司通过引进机器人代替人工来进行分拣,但由于受到工作环境(如光照、物体反光和拍摄角度等)的影响,传统的基于深度学习的管件分拣方法识别精度低,掩膜效果不理想,易造成机器人漏抓或错抓等问题,从而严重影响了工厂产能。如何在复杂的场景中准确判断管件的位置、类别和尺寸是机器人进行抓取的重要前提。针对以上问题,本文通过改进特征融合与区域生成网络,并引入混合注意力机制,对原始掩膜区域卷积神经网络(mask region-convolutional neural network,Mask R-CNN)进行改进,以提高实例分割精度和管件识别率。实验结果表明,相对于原始Mask R-CNN,改进后的管件识别方法具有更高的分割准确性和鲁棒性,能够满足实际生产中机器人抓取精度的要求。
1 相关工作
实例分割由目标检测和语义分割组成,其目标是得到图像中每个物体的位置及所属类别。实例分割算法一般分为传统视觉算法和基于深度学习的算法[1]。传统视觉算法使用手动或自动调整阈值的方式对物体进行分割,首先将图像转为灰度图,再二值化为黑白图像,进而通过阈值判断对黑白图像的边界轮廓进行平滑处理[2],完成边缘检测。由于受物体材质、光照角度和遮挡的影响,当对不同的图像使用相同的阈值进行处理时,在边缘处会出现过分割和欠分割的情况。因此,传统视觉算法在复杂场景中对物体进行分割时效果较差。
相比较于传统视觉算法,基于深度学习的实例分割算法适应环境能力强、精度高,受到越来越多的重视。文献[3] 提出的SDS (simultaneous detection and segmentation) 是最早的实例分割算法,该算法包括推荐生成候选框、提取特征信息、区域分类以及基于NMS(non-maximum suppression) 的区域改进方法。SDS 算法使用条件随机场对分割结果进行后处理,当实例之间边界不清晰时,分割的准确度易下降。文献[4] 提出的DeepMask 算法分为3 个分支:前背景分割、前景语义分割与前景实例分割,该算法基于全卷积神经网络生成掩膜,对于尺度变化较大的物体算法不稳定。针对尺度变化较大的物体,可以在网络中同时使用不同比例的检测框完成检测。文献[5] 在Faster R-CNN[6]基础上提出了Mask R-CNN 算法,增加了一个分割分支,对Faster R-CNN 产生的每个候选框进行像素分类,将像素分割任务和目标检测任务同步进行,相互促进,从而达到较高的准确率。由于检测框缺乏更小的感受野以提取局部特征,且固定大小的滑动窗口难以被感兴趣区域(region of interest,ROI)池化采样到足够的特征点,因此需要对Mask R-CNN 进行有针对性地改进,以更好地适用于管件实例分割任务。
机器人自动分拣系统基于机器视觉对物体进行检测,并将检测后的位置与姿态信息发送给机器人,机器人获得指令后对物体进行抓取及码放[7]。由于受到机器视觉技术以及计算机计算能力的限制,基于传统视觉算法只能依靠分析颜色或轮廓等较为简单的特征来识别和抓取。如果目标物体较为复杂,该算法将无法对其进行分析。
随着计算机硬件及算法的快速提升,基于深度学习的视觉计算被广泛使用。文献[8] 提出的分拣系统将传统视觉算法与深度学习算法相结合,使用深度学习CNN 算法对目标物体进行类别判断,再通过传统的视觉算法对目标物体的位置信息进行判断。文献[9] 提出了一种新的弱匹配多通道数据融合框架,以提升目标的匹配结果。基于深度学习的算法也可以对三维物体进行判断,文献[10] 提出PointNet++算法,即基于点云数据对目标物体进行分类分割。基于深度学习的算法也可以计算合适的抓取点,文献[11] 提出PointNetGPD (grasp pose detecting from PointNet),将点云作为输入,进而获取目标物体的抓取点。基于深度学习的机器人自动分拣系统使用点云作为输入源,数据处理量大,实时性水平较差。此外,点云数据可能存在噪声和不完整的情况,也会影响算法的鲁棒性,因此有必要提出一种基于二维图像的机器人自动分拣系统,以更快、更稳定地完成分拣任务。在对管件进行实例分割时,原始Mask R-CNN 容易丢失低层特征且过度关注无关目标,从而导致实例分割不精确、管件识别精度不高的问题。本文引入注意力机制模块,通过改进特征融合与区域生成网络来提高其检测性能。
2 改进特征融合与区域生成网络的Mask R-CNN 算法
2.1 Mask R-CNN 原理概述
Mask R-CNN 在Faster R-CNN 的基础上增加了一个分支,用于输出实例的掩膜,其骨干网络由残差网络ResNet 及特征金字塔网络(feature pyramid network,FPN)构成[12]。将待分割图像输入到网络,由骨干网络提取多尺度特征图(feature map),而区域生成网络(region proposal network,RPN)[13]产生不同比例的目标框以检索目标[14]。Mask R-CNN 的网络结构如图1 所示。
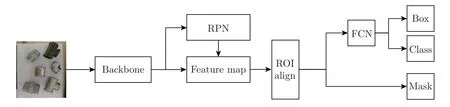
图1 Mask R-CNN 网络结构Figure 1 Network structure of Mask R-CNN
2.2 改进特征融合网络
Mask R-CNN 使用ResNet 提取基础特征,采用残差网络进行自上而下的特征融合,在FPN 中,每个stage 之间特征图的尺度比例相差2,经卷积后得到对应尺度的特征。根据特征图的大小ResNet 网络分为5 个stage,Mask R-CNN 中使用Conv2~Conv5 提取特征,忽略了部分低层特征信息,故本文增加Conv1 级别的特征,与Conv2~Conv5 共同进行特征融合,分别定义为C1、C2、C3、C4、C5;将C1~C5的特征图经过1×1 卷积和FPN 前一层上采样的特征图进行残差连接,定义为M1、M2、M3、M4、M5;再对融合后的特征进行3×3 卷积操作,得到多尺度特征图P1、P2、P3、P4、P5。相比较于Mask R-CNN,改进特征融合后的Mask R-CNN 在提取管件大尺度特征的同时,还获取了小尺度特征。改进后的特征提取网络如图2 所示,本文添加的操作用虚线框标注。
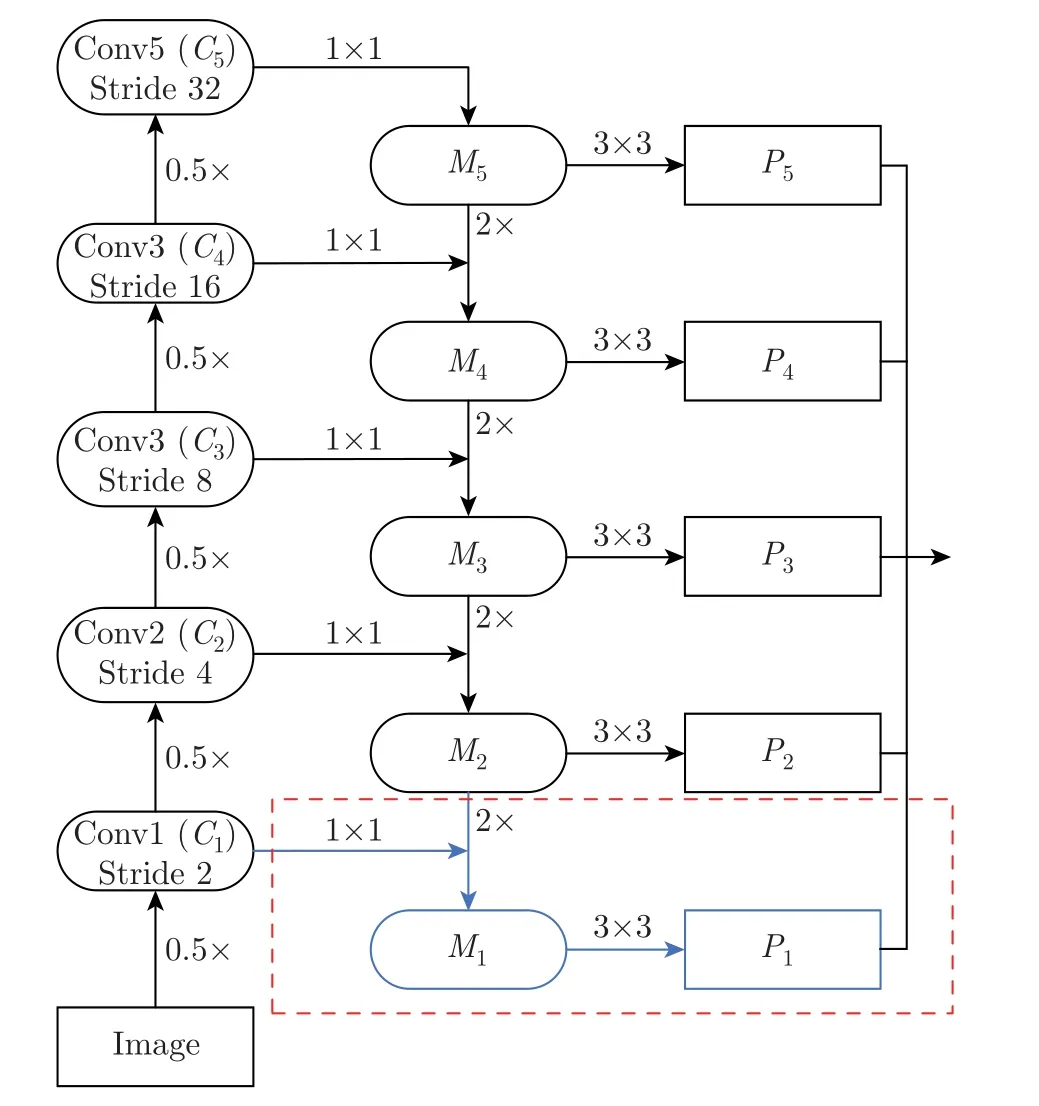
图2 改进的自上而下的特征网络Figure 2 Improved top-down feature network
2.3 改进区域生成网络
区域生成网络RPN 由分类器和回归器组成。利用滑动窗口逐步扫描图像[15],寻找目标区域。滑动窗口的中心点被称为锚点,原始Mask R-CNN 算法包括5 种不同面积的窗口,每种窗口包含3 种不同的横纵比,在特征图中每个像素点生成共计15(3×5)种不同的候选框。管件分拣任务中,三通(ST)、外丝(WS)、内丝(NS)和弯头(WT)这4 类管件的最小外接矩形长轴和短轴如图3 所示,通过实际测量可知其外接矩形长宽比包括两种:1∶0.8 和1∶1。考虑到管件类型和尺寸的特点,本文将滑动窗口的尺寸调整为32×32、64×64 和128×128,并将横纵比修改为0.8∶1、1∶1 和1∶1.25,共生成9 种不同的候选框。此外为了提高管件识别的正确性,将非极大抑制阈值从0.5 提高至0.7。

图3 四类管件最小外接矩形Figure 3 Minimum outer rectangle of four types of pipes
2.4 引入混合注意力机制
注意力机制的基本思想是让模型忽略无关信息,更多地关注重点信息。在得到管件的类型后需要计算掩膜的像素面积以判别管件的尺寸。在对掩膜进行分类时,将通道注意力和空间注意力进行融合以提高实例掩膜的正确性。
具有代表性的通道注意力机制为SENet[16],其网络结构如图4 所示。将特征图平均池化,以完成空间维度上的压缩,得到一维矢量[17],公式为
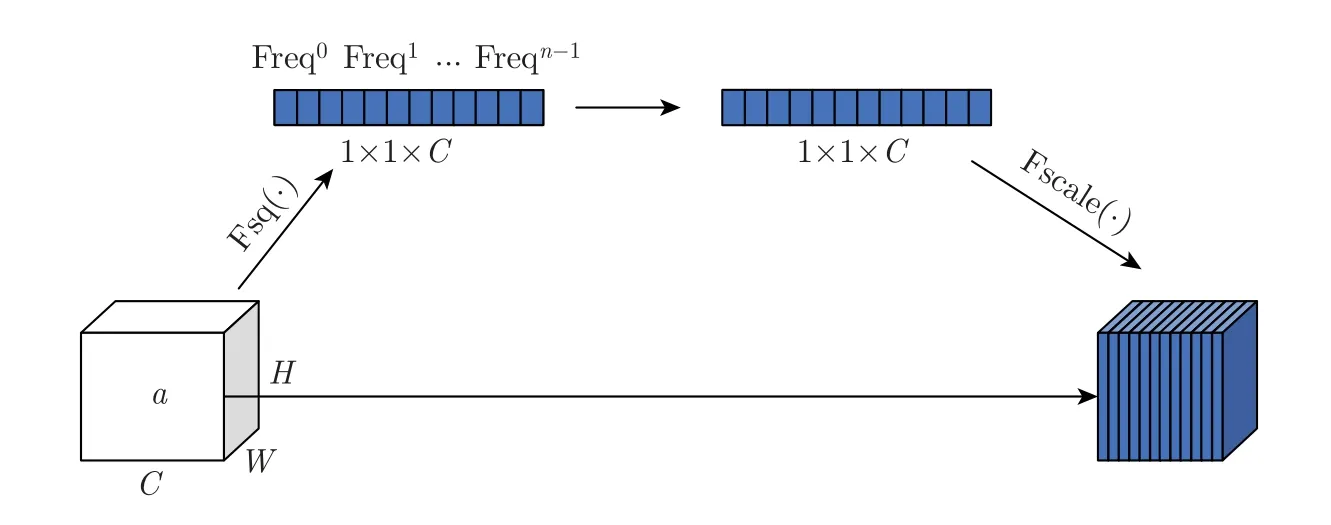
图4 SENet 网络结构图Figure 4 Network structure diagram of SENet
式中:σ为sigmoid 激活函数,fc 为卷积的映射函数,AvgPool 表示平均池化,X ∈RC×H×W为网络中的图像特征,C为通道数,H和W分别为特征的高度和宽度,~X为注意力机制的输出,atti为注意力向量中的第i个元素,X:,i,:,:代表第i个通道。
SENet 注意力机制基于空间维度的特征图计算而得,但其忽略了频域维度上的信息。这意味着SENet 可能无法对图像中的纹理、边缘等高频信息进行准确的建模和捕捉。离散余弦变换(discrete cosine transform,DCT)[18]与傅里叶变换相似,用来无损压缩图像或视频,将空域信号转换到频域上,具有良好的去相关性,二维DCT 的公式为
式中:f2d∈RH×W为二维DCT 频谱,x2d∈RH×W为输入,H为x2d的高度,W为x2d的宽度。
由式(1) 可以看出,SENet 在通道注意力之前将通道分成c段,并对其进行预处理,DCT可以看作输入的加权和[19]。式(2) 中h、w均为0 时可得到二维DCT 的最低频率分量其结果与全局平均池化gap 成正比,如式(3) 所示,因此gap 为二维DCT 的一种特例。
通道注意力机制只使用了最低频率分量,从而导致输入注意力机制通道信息单一,来自其他频率的所有分量都被丢弃,本文引入二维DCT 分量对信道的有用信息进行编码,以此增加更多信息,公式为
将每次的预处理结果相连得到改进后的通道注意力机制Freq,如式(5) 所示。添加DCT后的SENet 结构如图5 所示。
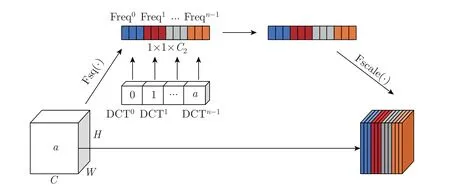
图5 添加离散余弦模块的SENetFigure 5 SENet with discrete cosine module
注意力机制在空间层面上也需要明确特征图的哪些部分应该得到更高的响应。对特征图进行平均池化和最大池化并在通道层面上进行压缩处理,最终得到二维的特征,将其按通道维度拼接在一起得到一个通道数为2 的特征图,再使用一个包含单个卷积核的隐藏层对其进行卷积操作,保证最终得到的特征图在空间维度上与输入保持一致[21]。使用7×7 卷积核进行最大池化和平均池化后的特征图经过激活得到空间注意力机制,公式为
式中:AvgPool 表示平均池化,MaxPool 表示最大池化。
将通道注意机制模块提取的特征输入到空间注意力模块,使用最大池化和平均池化进行特征压缩后,得到具有通道注意机制和空间注意机制的特征信息目标框,再使用全连接层对每个像素点进行分类,得到具有混合注意力的特征图。空间注意力模块结构如图6 所示,添加混合注意力机制模块的预测框架如图7 所示。
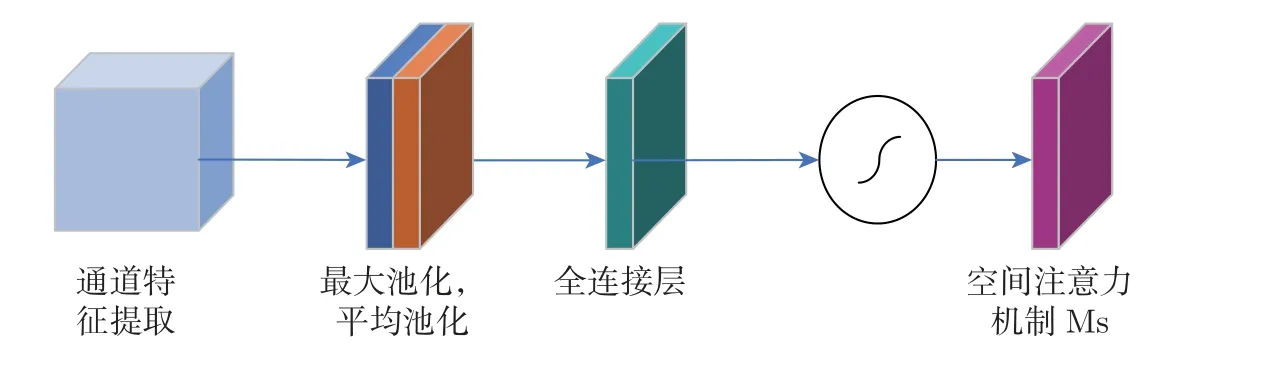
图6 空间注意力模块Figure 6 Spatial attention module
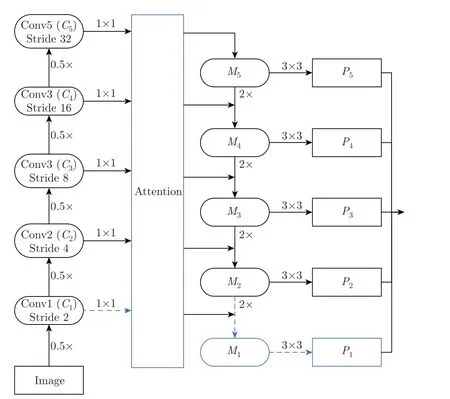
图7 添加混合注意力机制模块的预测网络结构Figure 7 Predictive network architecture with the addition of a hybrid attention mechanism module
3 实验
3.1 数据集制作及尺寸判断方法
鉴于目前没有公开的管件数据集,本文使用维视工业相机对工厂中的4 类管件进行垂直拍摄共得到700 幅图像,统一裁剪为512×512 像素大小。由于拍摄的图像相对较少,因此,为了提高实例分割的鲁棒性,通过旋转、镜像、调整亮度、对比度、饱和度和色相完成数据增强,将数据集扩充至2 800 幅,其中训练集和测试集数据比例为3∶1。利用中值滤波[22]对图像进行降噪处理,使用labelme 软件标注管件的类别、位置信息和掩膜信息,标注所生成的*.json 文件作为网络的训练集。
当相机高度固定时,同类别和尺寸的管件掩膜面积相近。预测掩膜轮廓点所围成的面积,并与人工标注的同类别管件面积进行对比,选择面积最接近的尺寸作为该管件预测尺寸。
3.2 实验环境
实验平台CPU 为i9-9900K,显卡为两张24 G 的RTXTITAN,内存为64 G。采用Pytorch1.4 框架搭建网络模型,算法中的参数Batch size 为3,训练类别为5 种,其中包括4类管件和1 类背景,学习率为0.000 1。
3.3 评价指标
本文使用mAP 和mRecall 两类评价指标,计算方式如下所述。
1)准确率PPrecision准确率是被正确预测的样本数与被预测为样本的总数之比,公式为
式中:TP 为真阳性数量,FP 为假阳性数量。
由准确率可以计算出第i类的平均精度APi,公式为
式中:n为第i类中的样本总数。
2)召回率RRecall召回率是被正确预测的样本数与本应该被预测为样本的总数之比,公式为
式中:FN 为假阴性数量。
以上两个指标使用IoU 作为判断阈值,IoU 为预测边框和真实边框的交集和并集的比值,公式为
实验中使用平均准确率mAP 和平均召回率mRecall 来衡量算法的优劣,公式为
式中:K为类别总数。
3.4 实验结果与分析
3.4.1 特征融合实验
原始网络及改进特征融合的Mask R-CNN 网络的目标检测和掩膜检测结果如表1 所示。从表1 可以看出,改进特征融合后目标检测的mAP 和mRecall 分别提高了1.2% 和2.4%,掩膜检测的mAP 和mRecall 水平分别提高了1.6% 和0.8%。显然,网络模型在改进特征融合后,可以识别出更多的小目标管件信息,且检测精度以及掩膜效果均有不同程度的提高。
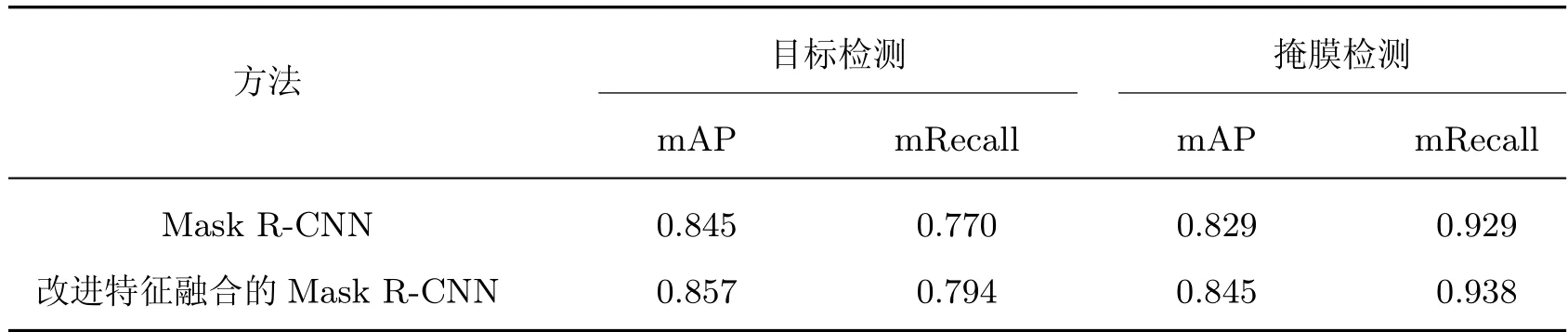
表1 改进特征融合前后模型性能比较Table 1 Comparison of model performance before and after improved feature fusion
3.4.2 区域生成网络实验
改进网络模型与原始Mask R-CNN 模型的收敛情况如图8 所示,其中橙色、蓝色分别为改进前后模型的损失值动态曲线,可以看出,改进后的模型能够更好地收敛。图9 中橙色、蓝色分别为改进前后模型的训练时间对比,可以看出,改进后的模型训练时间比原始模型缩短了0.5 s。
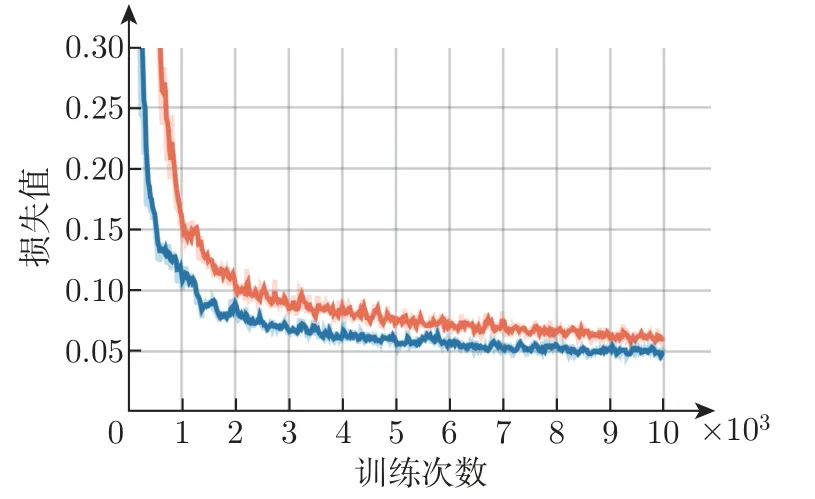
图8 改进前后模型的收敛情况对比Figure 8 Comparison of the convergence of the model before and after the improvement
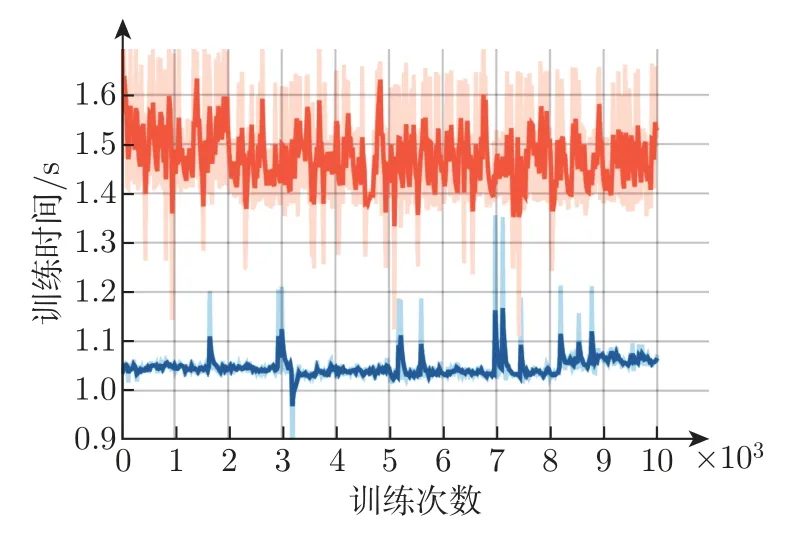
图9 改进前后模型的训练时间对比Figure 9 Comparison of training time of models before and after improvement
3.4.3 混合注意力机制实验
与原始Mask R-CNN、添加通道注意力模块的模型(Mask R-CNN-Channel)及添加混合注意力模块的模型(Mask R-CNN-Fusion)进行检测比对,结果如图10 所示,3 个管件的标号已在原图中标注,3 类方法的识别结果及置信度的比较如表2 所示。相较于Mask R-CNN 以及Mask R-CNN-Channel 模型,Mask R-CNN-Fusion 模型检测出的管件的置信度更高,并且掩膜轮廓更加平滑,本文在通道注意力机制中引用DCT 后,管件识别精度更高,同时识别结果与实际管件轮廓更加贴合。目标和掩膜检测性能评估如表3 所示,Mask R-CNN-Channel比原始Mask R-CNN 模型的目标检测mAP 和mRecall 值分别提高了1.2% 和1.3%,掩膜检测mAP 和mRecall 值分别提高了0.5% 和0.4%。Mask R-CNN-Fusion 相比较于原始Mask R-CNN 模型的目标检测mAP 和mRecall 值分别提高了2.3% 和2.1%,掩膜检测mAP 和mRecall 值分别提高1.5% 和1.1%。
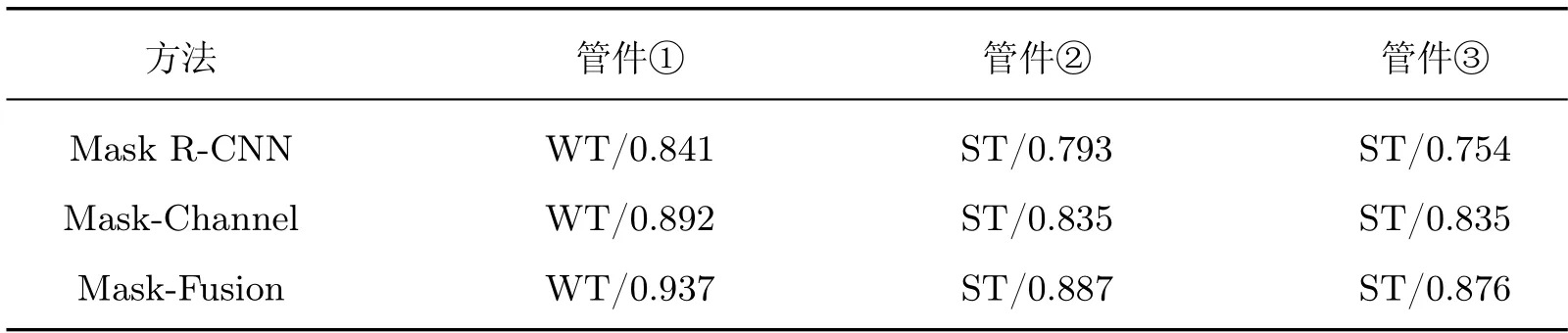
表2 改进前后管件模型置信度预测值Table 2 Predicted confidence probabilities of pipe models before and after improvement
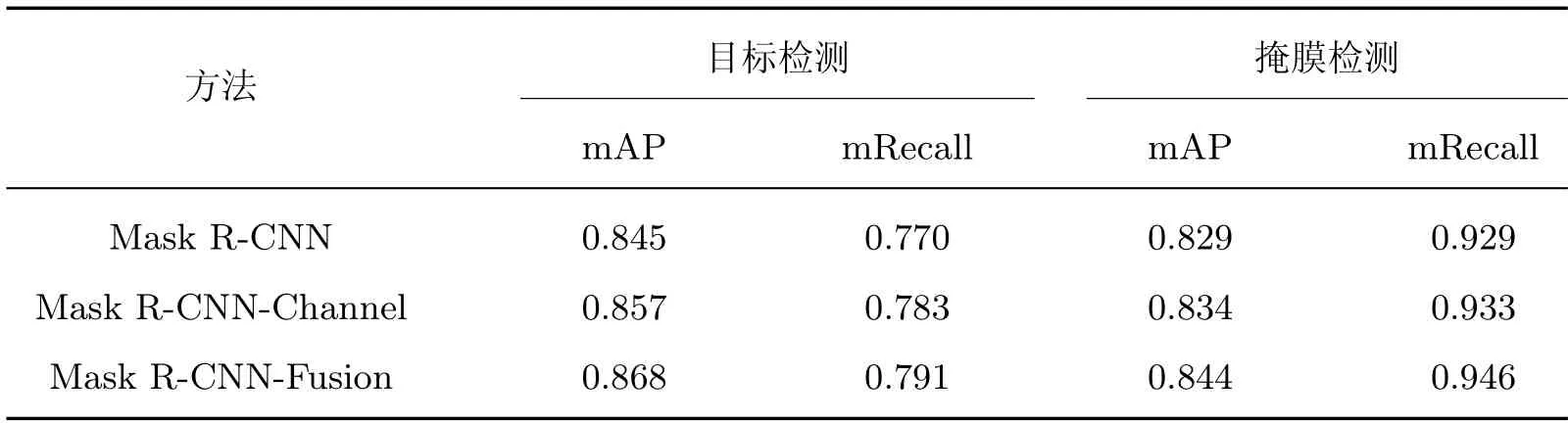
表3 改进前后模型性能评估对比Table 3 Comparison of model performance evaluation before and after improvement

图10 三类网络模型分割结果Figure 10 Segmentation results of three types of network model
3.4.4 实例分割结果
随机选取6 个管件,基于改进后的Mask R-CNN 对管件进行实例分割,如图11 所示,左图为标注后的原始图像,右图为分割后的结果,包括管件的类别、掩膜及置信度,具体识别结果如表4 所示,可以看出,所提方法的类别识别率较高、掩膜与管件的边缘基本对齐、置信度保持在0.790 以上。
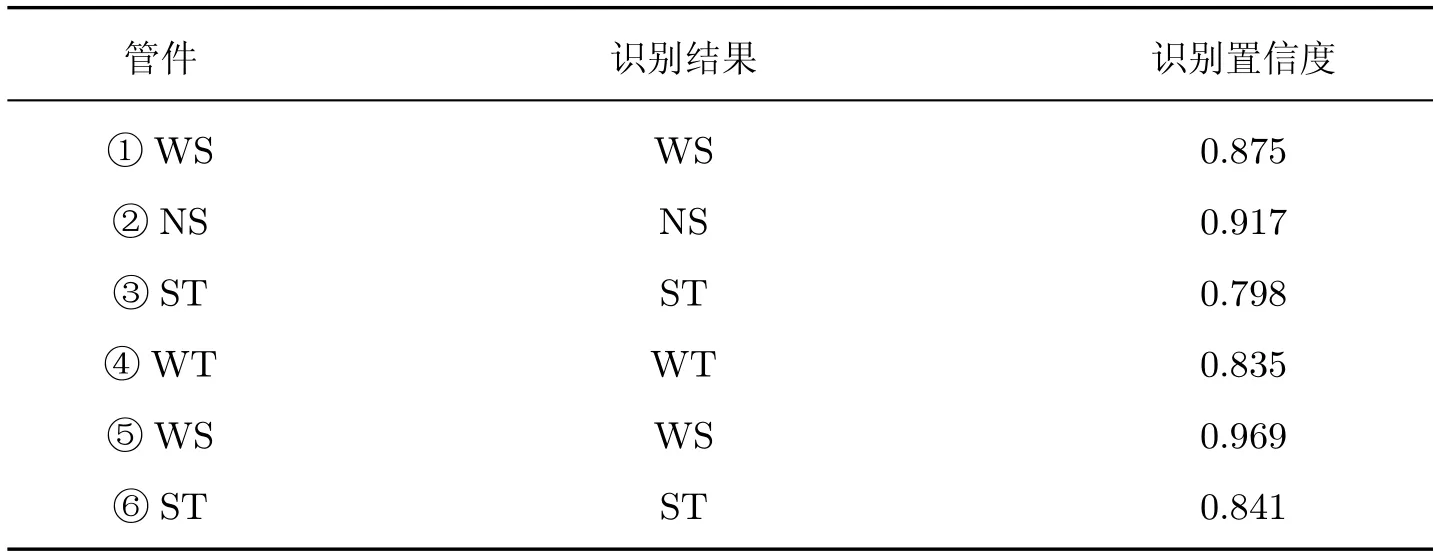
表4 网络模型识别结果Table 4 Recognition results of network model

图11 原图与分割结果Figure 11 Original images and segmentation results
3.4.5 骨干网络实验
本算法的基础特征提取部分使用Resnet101+FPN 网络结构,通过添加小尺度特征、改进区域生成网络和添加注意力模块对Mask R-CNN 进行改进,并与主流的实例分割网络DeepMask[4]、Solo[23]、原始Mask R-CNN 模型及添加了通道注意力机制的SENet Mask R-CNN 进行对比。其中Solo 和Mask R-CNN 的骨干网络与本文相同,DeepMask 骨干网络为VGG16,每幅图像最多检测数目(maxDets)为10。5 类算法识别结果如图12 所示,具体数据如表5 所示,有灰色底纹的表示类型识别错误(例如Solo 错将管件①ST 识别为WT),“–”表示识别失败。可以看出,本文方法类型识别正确率和置信度较高,其他算法存在漏检、错检和置信度较低的问题。本文方法引入了低层特征以改进特征融合网络、增加混合注意力机制,使得模型能够更多地关注管件所在区域并提取其深层和浅层特征,从而使其识别精度明显提高,掩膜与管件的边缘更加贴合。
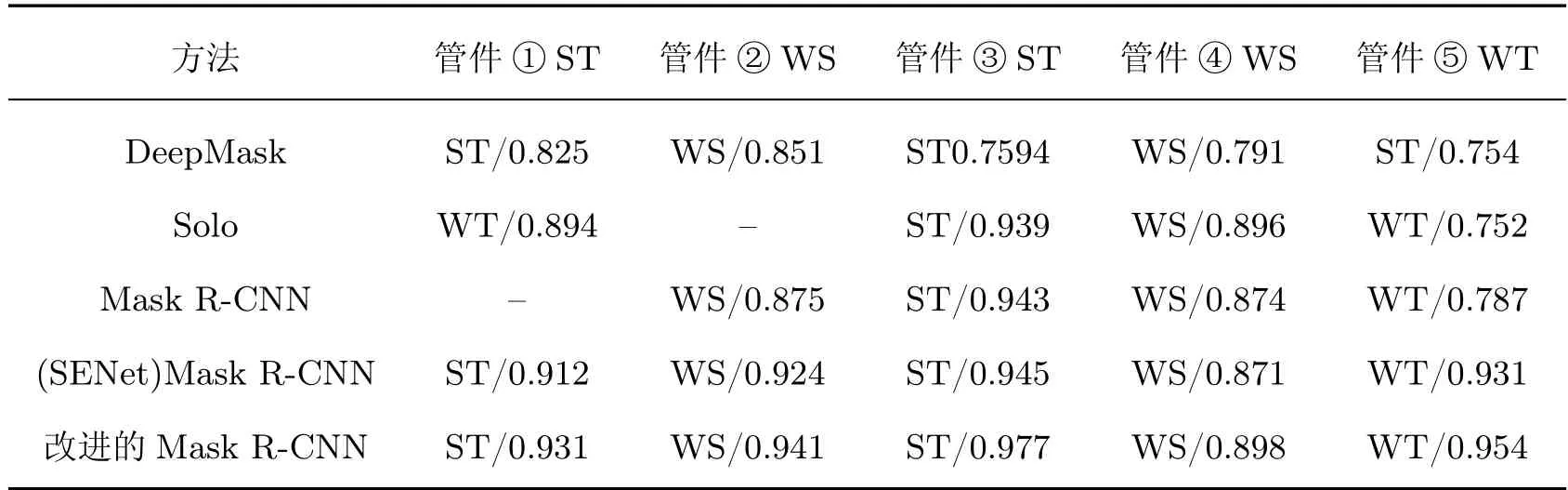
表5 不同模型检测结果Table 5 Detection results of diffierent models

图12 不同模型检测结果对比Figure 12 Comparison of prediction result of diffierent models
对测试集中的所有图像(共700 幅)进行检测,使用mAP 和mRecall 对5 种算法进行评价,目标、掩膜检测定量评估如表6 所示,可以看出,本文方法在目标检测、掩膜检测的mAP和mRecall 值较其他模型都有显著提高,相比较于DeepMask 的mAP 和mRecall 分别提高5.3% 和7.5%,与Solo 相比分别提高了3.5% 和7.1%,在Mask R-CNN 的基础上分别提高了2.9% 和3.9%。这说明本文改进了特征融合与区域生成网络,并在此基础上引入了混合注意力机制,可以提高管件识别性能。
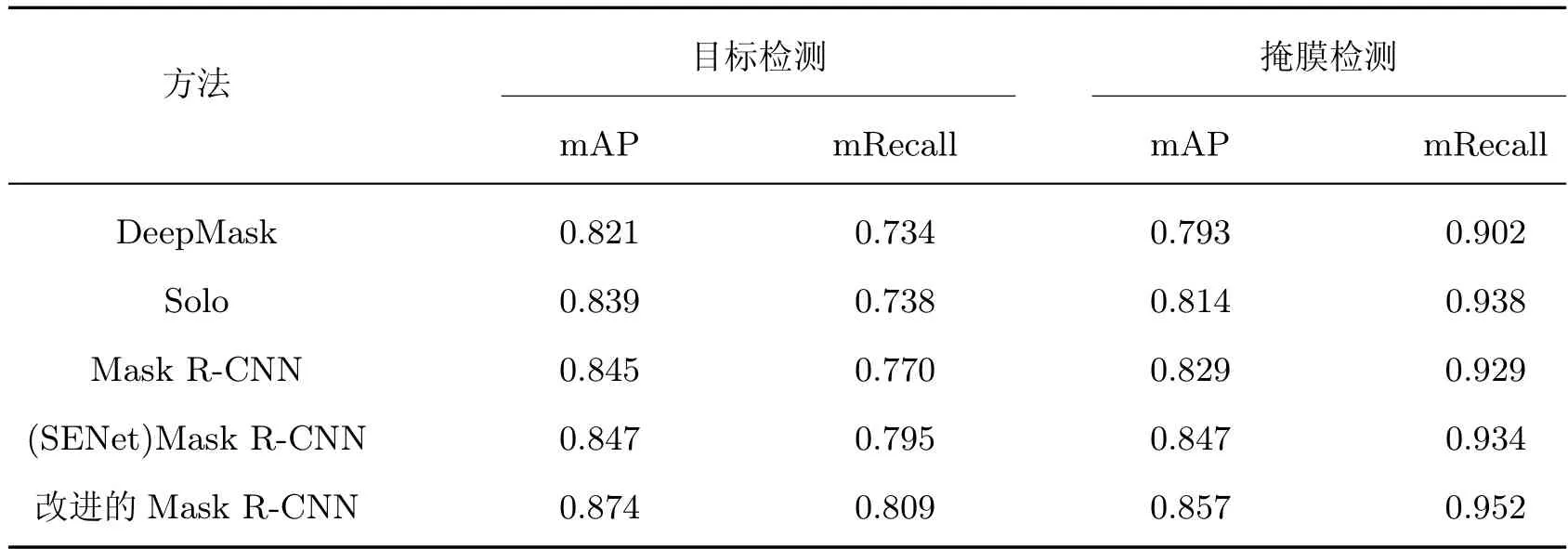
表6 不同骨干网络模型检测性能定量比较Table 6 Quantitative comparison of detection performance of diffierent backbone network models
为了验证本文方法对管件尺寸的检测性能,在同一视点对ST 管件进行检测,并计算掩膜面积,检测掩膜与真实尺寸的像素数量定量对比如图13 所示,图中ST 管件①、②、③、④对应的尺寸分别为20 mm、25 mm、30 mm、40 mm。结果表明,改进后的Mask R-CNN 对各类尺寸ST 管件的掩膜检测面积更加接近于标注值,因此本文方法通过计算掩膜面积可以准确地判断管件尺寸。
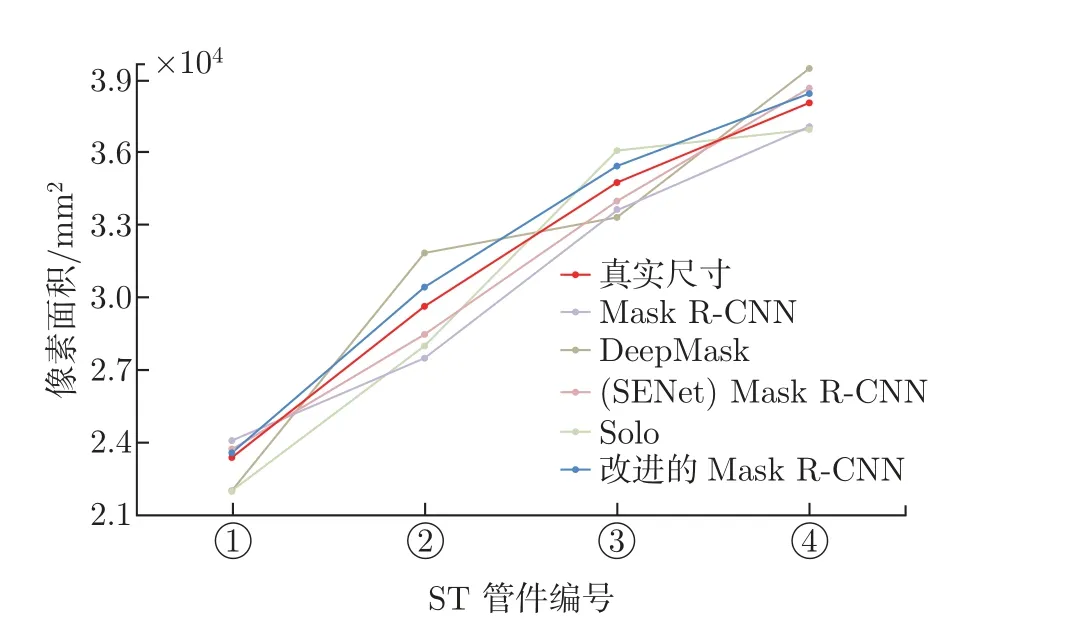
图13 ST 管件检测像素面积Figure 13 Detect pixel area of ST pipes
4 结语
针对管件类型、位置和尺寸的检测不精确问题,本文改进特征融合与区域生成网络,通过引入混合注意力机制以改进Mask R-CNN 算法,提高了管件检测和掩膜分割的准确度。针对管件数据集不足的问题,采用不同的数据增强方式对其进行数据扩充。自制数据集实验结果表明,添加低层特征图以改进特征融合网络,可以提高目标识别率;针对管件的实际情况,修改候选框的长宽比、尺寸和NMS 参数以改进区域生成网络,可以加快模型的收敛速度;添加混合注意力机制后可以提高管件掩膜的精确度。所提方法在管件的检测和分割任务中比原始Mask R-CNN 模型有更好的效果,可应用于机器人管件抓取和码放等领域。
猜你喜欢
导航定位学报(2022年5期)2022-10-13
中国体视学与图像分析(2021年3期)2021-11-24
经济技术协作信息(2018年11期)2019-01-14
制造技术与机床(2017年10期)2017-11-28
制造技术与机床(2017年10期)2017-11-28
科技资讯(2016年21期)2016-05-30
中国塑料(2015年7期)2015-10-14
产业与科技论坛(2015年14期)2015-03-19
高中生学习·高三版(2014年3期)2014-04-29
高中生学习·高三版(2014年3期)2014-04-29
