
融合自注意力机制与生成对抗网络的DEM 空洞填充
2023-12-08 13:09张春森朱江乐张学芬刘旭东
应用科学学报 2023年5期
张春森,朱江乐,张学芬,刘旭东,史 书
1.西安科技大学测绘科学与技术学院,陕西西安710054
2.武汉大学测绘遥感信息工程国家重点实验室,湖北武汉430079
数字高程模型(digital elevation model,DEM)数据产品是对地球表面的高低起伏信息的数字化表达,具有广泛的应用领域和重要的应用价值,是重要的基础测绘成果[1],为相关行业研究提供了重要的地理空间参考信息[2]。然而,不同的数据采集方式会导致DEM 数据存在大小不同、形状不一的空洞[3]。例如,光学立体摄影测量采集的地表信息存在航摄死角、区域限制和遮蔽等问题,从而引起信息缺失[4];利用星载合成孔径雷达方法获取的地表信息受到阴影、相位解缠异常和叠掩现象[5]等影响,很难准确提供连续的地表空间信息,从而严重影响DEM 数据的应用[6]。基于空间插值的技术在空洞填充领域得到了广泛的应用,然而,不同空间插值方法的填充精度与插值样本点数量、分布情况具有密切关系。另外,地形起伏、空洞面积大小和插值参数设置等客观因素也会影响填充结果的准确性[7]。
近年来,基于机器学习的生成对抗网络(generative adversarial networks,GAN)技术[8]引起了人们的广泛关注。条件对抗网络模型(conditional adversarial networks,CAN)[9]在发生较大面积空洞且单一分辨率的DEM 数据中取得了较好的填充效果。文献[10] 结合编码器-解码器结构和对抗网络结构特点,对DEM 空间插值的结构性表达进行了分析,证明了条件生成对抗网络在更多地理应用领域研究的潜力。文献[11-12] 考虑了一种基于Wasserstein GAN 的生成模型用于DEM 空洞填充,并使用空间重构损失函数约束网络的训练过程,避免了卷积神经网络存在训练不稳定、梯度消失问题,由于该网络仅基于局部特征信息,因此无法在恢复整体DEM 数据时保持语义信息的完整性,从而使得空洞缺失区域边缘填充效果不连续。现有的填充方法注重DEM 数据纹理特征和视觉感观上的填充效果,只考虑了空洞区域局部特征的信息获取,难以顾及整体DEM 数据高程特征信息的修复结果,并且大多基于单一分辨率的DEM 数据进行模拟空洞填充实验,缺乏对发生真实空洞的DEM 数据填充的相关验证[13]。注意力机制[14]加深了网络对图像语义和全局结构特征的理解,可以有效提升图像纹理细节和高级语义特征的提取效果。基于此,文献[15] 提出了具有自注意力机制的生成对抗网络(self-attention GAN,SAGAN),网络中的自注意力层在图像生成过程中能够捕捉像素之间特有的几何与结构特征,因此能取得很好的图像修复效果。
本文提出了一种基于SAGAN 的DEM 数据填充网络(DEM void-filling with SAGAN,DSAGAN),以实现DEM 空洞填充任务。网络以不带有空洞的DEM 数据作为输入,通过学习DEM 数据空间分布统计特征以及相关计算参数,随机生成具有中心缺失的空洞模拟数据来测试DSAGAN 模型的空洞填充能力,最后在真实空洞数据上进行空间预测得到填充后的无空洞DEM。
1 本文方法
1.1 DSAGAN 框架
受残差网络、混合空洞卷积、Content 内容感知损失函数与Huber 损失函数启发,本文以SAGAN 为基础提出一种改进的生成对抗网络DSAGAN 以实现DEM 空洞填充。与SAGAN相比DSAGAN 有以下改进:1)在生成器中,使用残差网络以及混合空洞卷积(hybrid dilated convolution,HDC)[16]构造自注意力机制模块,增强深层特征对感兴趣区域的建模能力。2)使用对称结构的卷积与反卷积层填补空洞区域缺失部分,将Relu 和Tanh 激活函数换成拟合效果更好的PRelu 激活函数,同时使用谱范数归一化(spectral normalization,SN)来稳定网络训练。3)在SAGAN 损失函数的基础上,加入了Content 内容感知损失函数与Huber 损失函数以获得更多的参数,进而得到更好的拟合效果。
网络训练流程如图1 所示。首先,以真值DEM 数据作为输入,在训练前随机生成具有空洞的DEM 数据,以此保证训练后的模型能够满足不同空洞填充任务的感知性。自注意力机制中的卷积层、残差层、HDC 和上采样使用给定的卷积核和步长执行特征提取,Softmax函数用于自注意力模块与生成器网络的输出层。之后,使用给定的卷积核进行卷积和反卷积采样,以捕捉注意力特征图与真值DEM 数据之间的关系,预测空洞区域的空间数据与图像纹理特征,以生成“假样本”供判别器判断。判别器类似于典型的图像分类模型,将上一步的输出与真值DEM 数据作为输入,预测生成样本为真实数据的概率值。根据文献[17] 中的设定,Sigmoid 函数用于判别器网络的输出层,判断输入是否为正确的空洞填充结果。
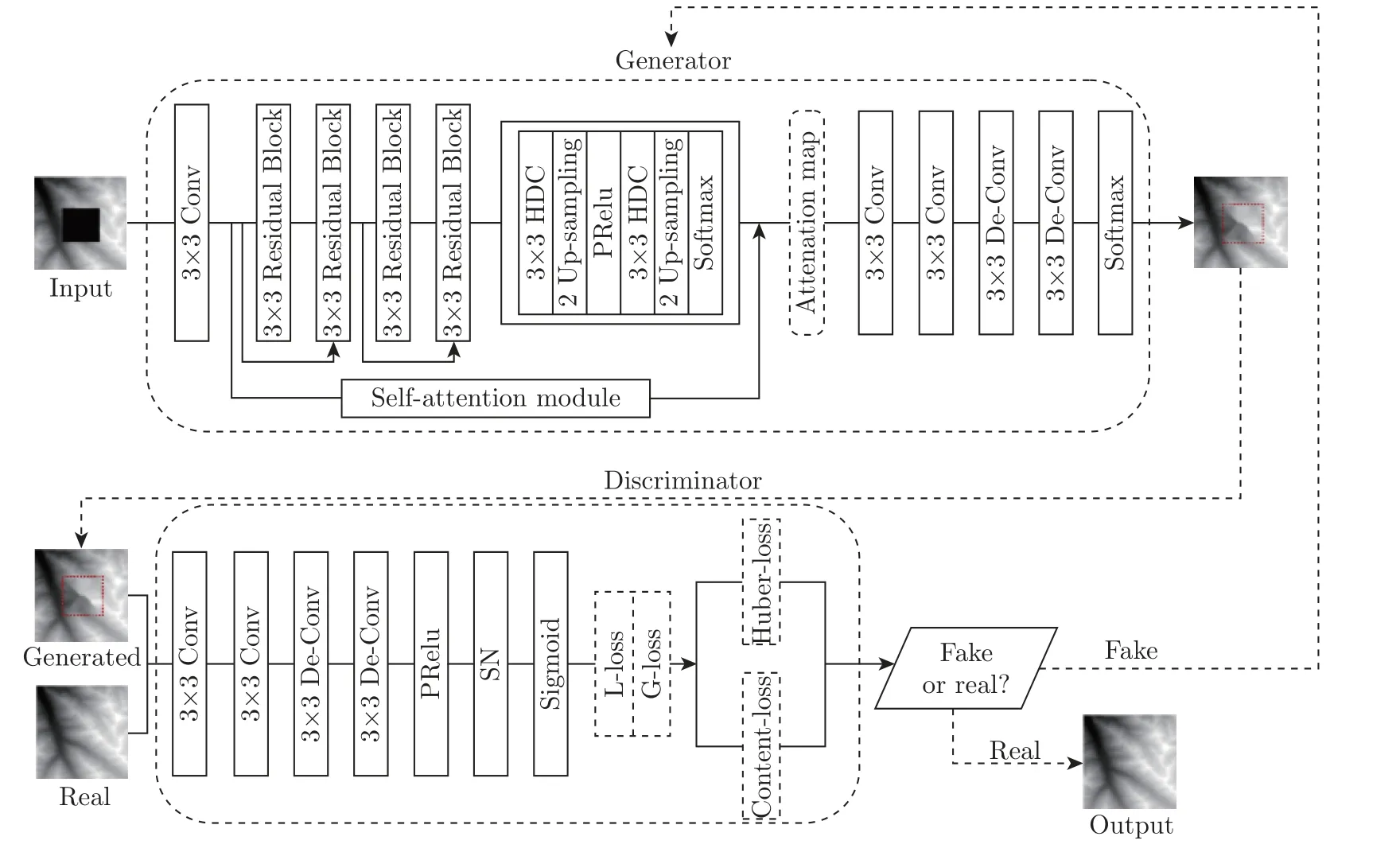
图1 DSAGAN 模型总体框架Figure 1 Overall framework of DSAGAN model
1.2 自注意力机制
注意力机制模仿输入进人脑信息的处理流程,首先关注任务中的关键信息,实现对输入信息的合理分配和利用,不用通过多层卷积循环而直接建立输入与输出之间的依赖关系,使得网络模型并行化程度增强,运行速度有了很大提高,因此常被应用在模式识别、图像处理等领域[18]。在SAGAN 网络的注意力机制中,考虑到所有卷积层均为规则化的3×3 卷积核操作,增加了网络深度以及计算的复杂度。空洞卷积虽然在不改变卷积核大小的同时可以获取更大的感受野,但存在感受域不连续的情况,而HDC 通过设置不同的空洞率,弥补了空洞卷积的感受野不连续造成的信息缺失,可极大增强对所提取目标特征的适应性与建模能力,因此在自注意力机制中使用HDC 代替部分卷积。空洞卷积与混合空洞卷积的采样示意图如图2所示。
设Ri为第i层的空洞率;Li和Li+1分别为第i层和第i+1 层的最大空洞率,其混合空洞卷积操作定义如下:
将输入影像转换成注意力特征图的过程如图3 所示,具体过程如下:首先根据式(1) 设置空洞率分别为1、2、5 且卷积核为3 的混合空洞卷积,并将输入数据转换成查询层(Query layer)、键层(Key layer)和值层(Value layer)的特征向量X ∈RC×N,其中C为通道数,N为前一隐含层特征的数量;然后通过步长为2 的上采样操作将X转换为2 个特征矩阵,分别为空洞缺失区域以及全局区域特征空间,其中∈RC′×N,C′=。利用式(2) 计算相似性矩阵
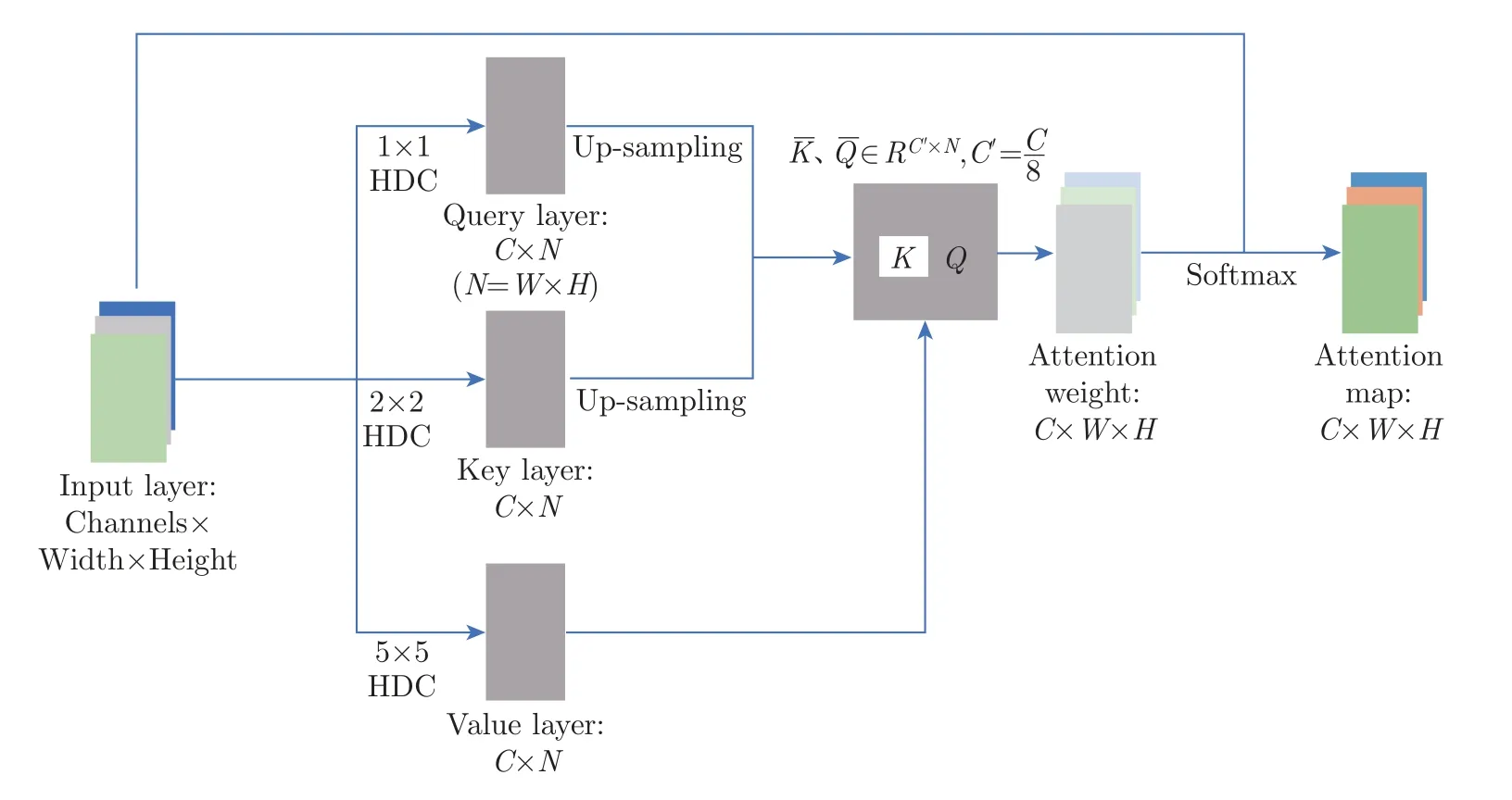
图3 自注意力特征图生成过程Figure 3 Generation process of self-attention feature graph
式中:矩阵Aj,i表示模型在第i个位置,生成第j个区域时的关注程度;Sij为(xi)T×(xj)。由于自注意力模块直接嵌入到深度生成网络模型中,并参与整个模型的网络参数迭代更新,因此,随着网络模型的不断训练,来自于每一层的权重矩阵Wl也会不断优化并逐渐收敛得到最优权重矩阵。基于此训练得到自注意力聚焦区域的权重矩阵Wk与相似性矩阵A进行矩阵乘法,在每列中应用一个Softmax 函数将多个网络层的输出映射到(0,1)区间之内,以生成待填充区域的特征图o,计算公式为
因此,自注意力机制获取得到的局部特征输出可表示为:o=(o1,o2,···,oj,···,oN)∈RC×N,全局自注意力特征图Y计算公式为
式中:γ为尺度参数,本文初始化为0。
1.3 谱范数归一化
GAN 模型在训练时易出现模型不稳定以及梯度下降困难等问题,为此,文献[19] 通过约束GAN 判别器的每一层网络l=1,2,···,L的权重矩阵Wl的谱范数满足Lipschitz 常数,从而增强GAN 网络在训练过程中的稳定性
当权重矩阵W使Lipschitz 约束矩阵满足σ(W)=1,则有
1.4 重构损失函数
本文所提模型在SAGAN 判别器损失函数LD和生成器损失函数LG基础上,针对DEM输入数据特点,将每个待填充点看作一个目标,加入了Huber 损失函数LHub以及Content内容感知损失函数LCon。Huber 损失函数首先创建一个标准阈值δ,然后结合平方项误差和线性误差损失函数两者的优点,使得该函数对异常值更具有鲁棒性,采用Huber 损失函数是为了保证判别器与生成器之间的“对抗”训练过程更加稳定和高效。Huber 损失函数为
式中:xn、yn分别为真实数据和生成数据的像素值,δ值在本文中初始化为1,并且在训练过程中该值会得到更新。Content 内容感知损失函数基于输入网络层l,通过最小化真实图像p与生成图像x在内容特征表示上的差异,控制生成器的填充误差。若用Pl和Fl分别表示真实图像和生成图像之间的内容特征,则内容损失计算函数定义为
训练网络时采用混合损失函数,公式为
主体的损失函数沿用了SAGAN 的损失函数,LHub与判别器损失函数LD相结合是为了降低判别器对异常点的惩罚程度,增加损失回归过程的鲁棒性。内容感知损失函数LCon结合生成器损失函数LD,目的为了在填充过程中产生更加真实的图像,在式(9) 中,取λ1为1.0,λ2为0.1。如图4 所示,使用SAGAN 损失函数和本文方法损失函数填充效果进行对比,可以发现SAGAN 网络填充效果具有较多的噪声且存在一定的色差,本文方法有效避免了这种情况的出现,填充效果更加接近真值DEM 数据。

图4 SAGAN 损失函数和本文方法损失函数填充效果对比Figure 4 Comparison of loss function filling effiect with SAGAN and the proposed method
2 实验与分析
2.1 数据及评价指标
实验选取SRTM DEM 数据,为了保证网络可以满足不同分辨率的DEM 数据空洞填充任务需求,分别选择了10 块SRTM-1 和10 块SRTM-3 DEM 数据作为本文的实验数据,数据信息如表1 所示。为了训练网络模型捕捉到不同的地形纹理,并且防止模型过拟合现象的发生,选取区域分布范围较广且地形起伏变化较大,实验数据高程统计如图5 所示。模型训练中,由于原始DEM 数据尺寸较大,且真实数据空洞的大小和形状不同,因此需要对输入网络的DEM 数据进行裁剪处理,生成10 000 个128×128 像素大小和36 000 个64×64 像素大小的训练数据集,从中随机抽取9/10 作为训练样本集,剩余1/10 作为测试样本。网络训练及测试硬件均为NVIDIA GeForce RTX 2080 SUPER 和Intel®CoreTMi7-9700K CPU 3.60 GHz,运行内存16 GB,选用Pytorch 深度学习框架,借鉴文献[20] 的学习速率建议,DSAGAN 网络中的判别器学习速率设置为0.000 4,生成器的学习速率设置为0.000 1,自适应矩阵估计优化器参数Beta 1=0.5、Beta 2=0.999,整个训练过程大概需要18 h。

表1 实验数据介绍Table 1 Introduction to experimental data
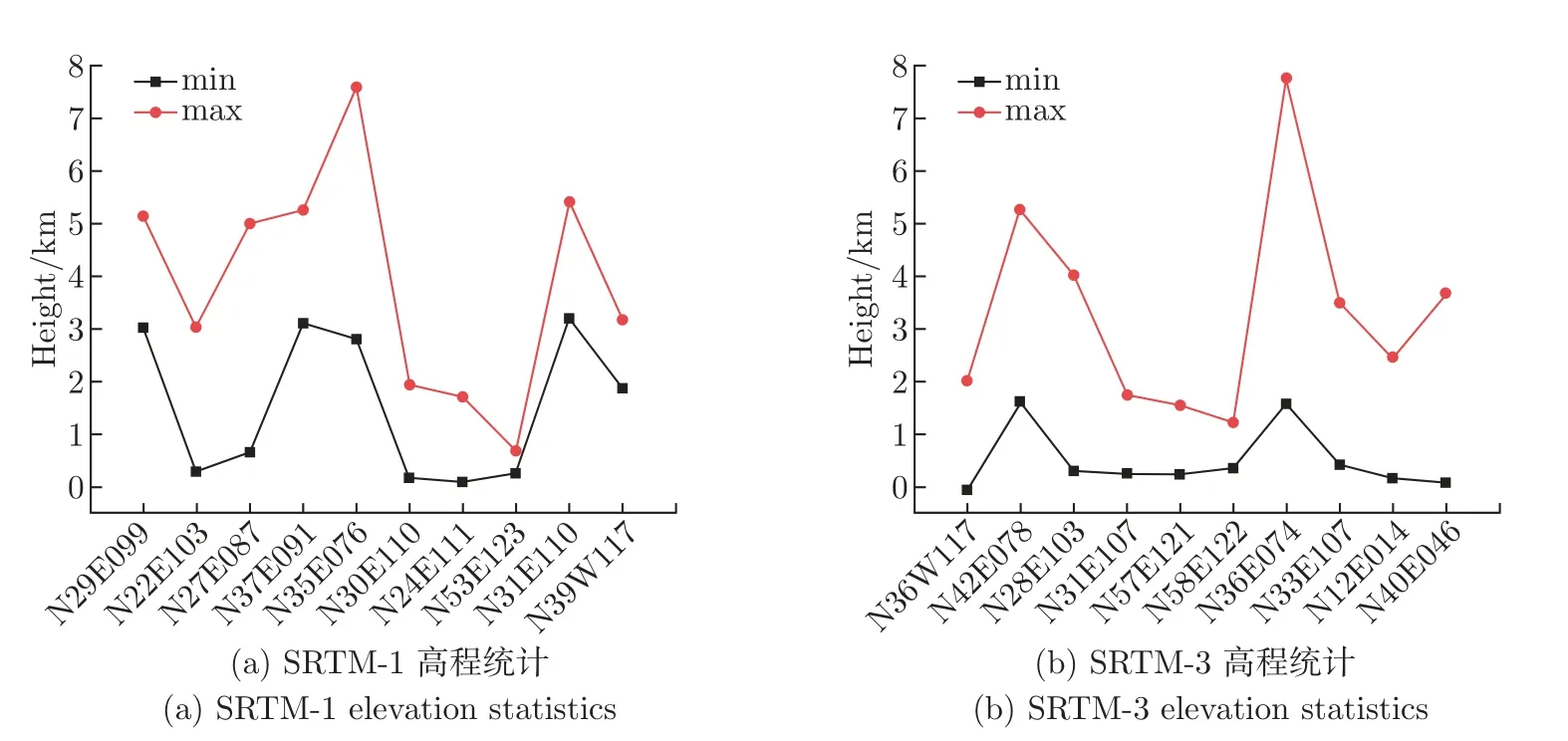
图5 SRTM-1 和SRTM-3 实验数据高程值范围统计Figure 5 SRTM-1 and SRTM-3 experimental data elevation value range statistics
采用均方根误差(root mean square error,RMSE)和预测吻合度(R2)作为检测DEM空洞填充精度的主要指标。RMSE 定义为观测值与真值偏差的平方和与观测次数n比值的平方根,用来衡量观测值同真值之间的偏差。RMSE 值越小,预测高程值越接近实测高程值,R2的值越接近1,填充精度越高。公式为
式中:Zi为待插点i的预测高程值,zi为待插点i的实测高程值,n为待插点总数,¯z为所有参与计算的待插点实测平均值。
2.2 实验分析
选择SAGAN 和DSAGAN 作对比实验,实验数据随机选择真实带有空洞的30 m 分辨率SRTM-1 和90 m 分辨率SRTM-3 DEM 数据,分别将其裁剪为128×128 像素和64×64 像素大小,用于网络输入。测试样本数据集中,最大待填充面积占比约为61.27%,最小待填充面积占比约为0.006%。SAGAN 与DSAGAN 的填充总体精度结果统计如表2 所示,统计结果表明,DSAGAN 网络填充结果RMSE 值分别为6.076 1 和4.437 8,R2值分别为0.954 2 和0.965 5,均优于SAGAN 网络结果,充分说明本文方法的填充效果更好。
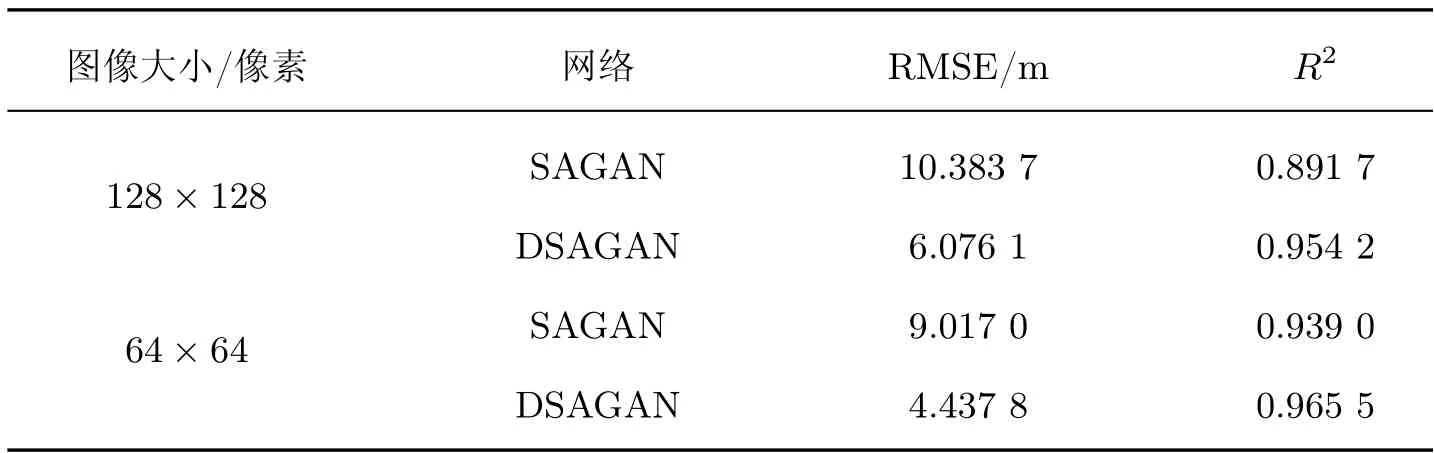
表2 SAGAN 和DSAGAN 的空洞填充精度对比Table 2 Comparison of SAGAN and DSAGAN void filling accuracy
如图6 所示,使用真值DEM 作为SAGAN 和DSAGAN 网络模型空洞填充准确性参考。其中,第1 行和第2 行分别为输入数据为128×128 像素和64×64 像素大小的空洞填充结果,从图中可以看出,由于SAGAN 和DSAGAN 都是基于自注意力机制建立的模型,能够较好地还原空洞缺失区域,但是SAGAN 填充效果较为模糊,在空洞面积较大的区域图像细节较少,这说明生成的细节部分没有真实还原真值数据的特征。本文方法填充结果有效避免了数据信息的丢失,在空洞缺失面积较小的区域,填充生成的数据与真值DEM 数据高度相似;在空洞缺失面积较大的区域,填充生成的数据虽然与参考数据存在一定差异,但是填充结果整体图像纹理特征保持一致,且能较好地符合其空间特征分布。
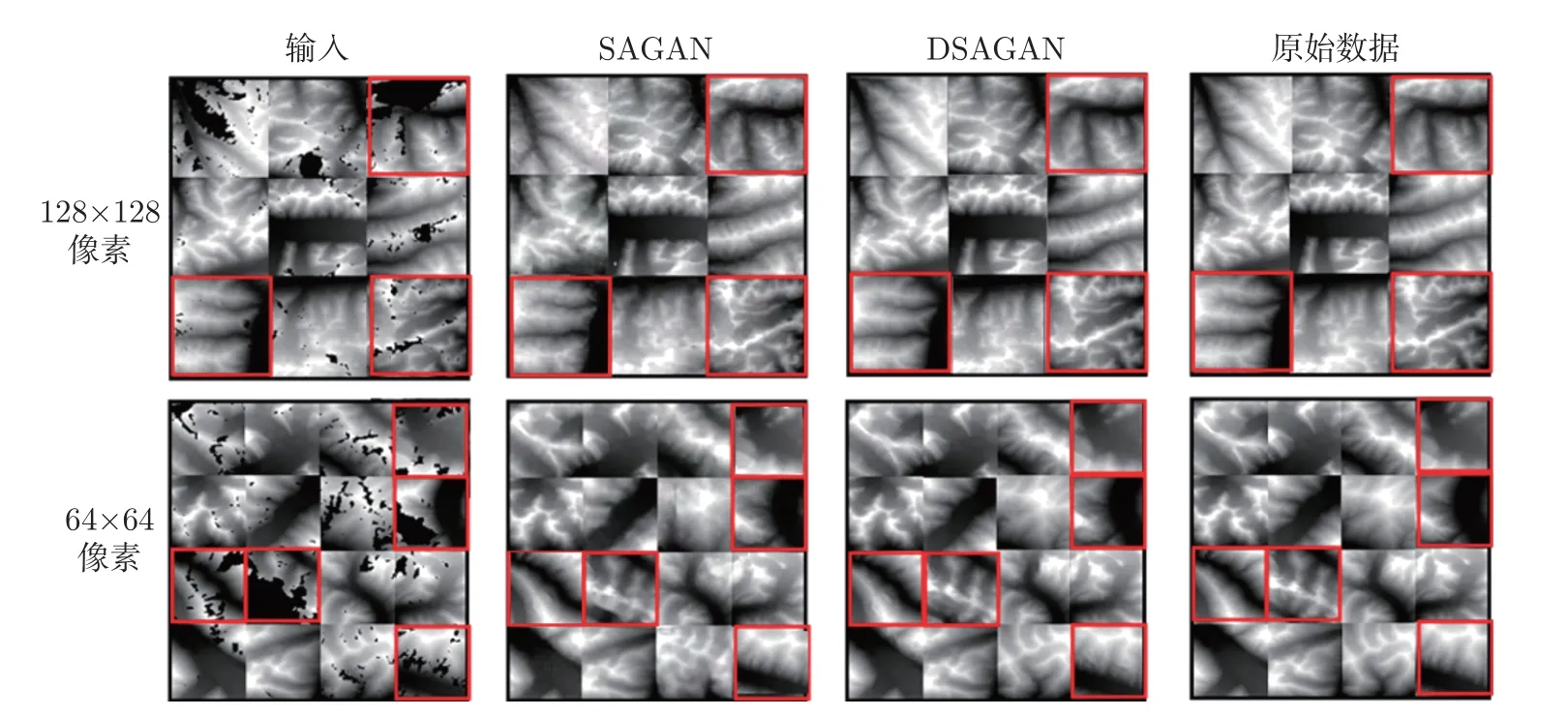
图6 SAGAN 与DSAGAN 网络DEM 真实空洞填充效果对比Figure 6 Comparison of filling results between SAGAN and DSAGAN in true type DEM voids
为进一步说明本文方法的有效性,将本文DSAGAN 方法与传统空间插值方法进行比较,插值方法包括反距离权重法(inverse distance weight,IDW)、经验贝叶斯克里金法(experience Bayes Kriging,EBK)和三次样条插值法(cubic spline interpolation,CSI)。本实验选择了两幅SRTM-3 DEM 数据进行测试,数据编号分别为N36E073 和N36E075(见图7 和8)。在这些数据中,首先标记具有空洞待填充的区域,用红色框表示。随后对这些区域进行局部放大,并采用不同的方法对数据中的空洞进行填充,实验效果如下。
由图7 和8 可以看出,IDW、EBK 和CSI 空间插值法在空洞填充过程中数据信息丢失过多,产生的效果往往过于平滑,特别在对空洞面积较大的区域进行填充时,图像失真严重,在空洞缺失区域面积较大的情况下填充效果整体不连续,边缘锯齿状较为明显,主观感觉较差。本文方法在空洞面积较大的区域填充结果与原始图像高度接近,不会受到插值采样点、权重和模型的多重影响,相比于其他方法具有较强的纹理特征表现力。表3 统计了不同方法填充前后DEM 数据高程的最小、最大以及平均值,结果显示本文方法填充结果的高程分布更加接近原始DEM 数据的高程分布,精度评定如图9 所示。

表3 不同空洞填充方法获取的高程值信息统计Table 3 Elevation value information statistics of diffierent void filling methods m
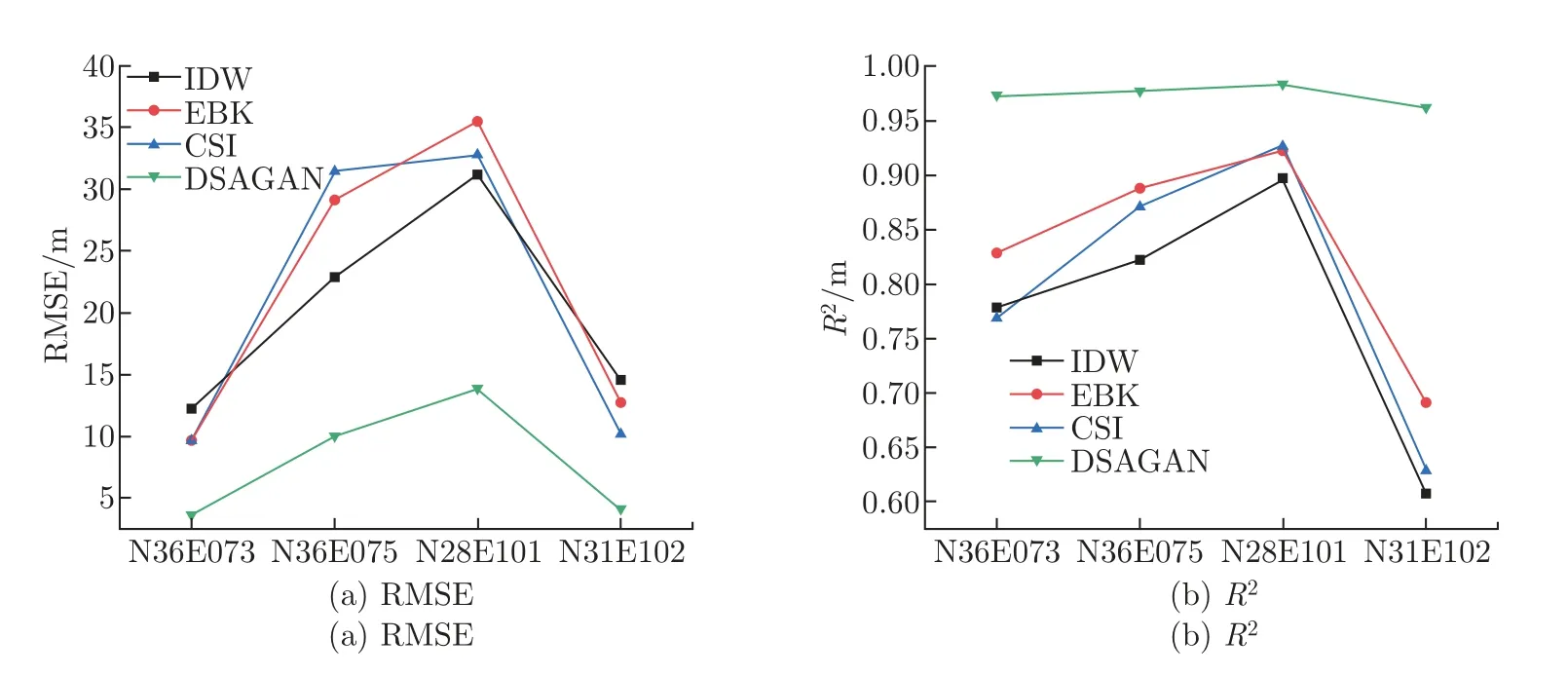
图9 IDW、EBK、CSI 和DSAGAN 空洞填充结果精度评定Figure 9 Accuracy evaluation of void filling results by IDW、EBK、CSI and DASGAN
与传统空间插值方法对比实验可以得出,本文方法的填充结果具有更小的平均误差和均方根误差,与原始DEM 数据相比预测吻合度平均值大于0.95。因此,本文方法在DEM 空洞区域高程特征和图像语义特征恢复都取得了更好的填充效果。此外,选取存在真实空洞的两幅SRTM-1 DEM 为实验数据,将本文方法与文献[12] 中提出的空洞填充网络模型(deep generation model,DGM)进行对比实验。实验结果如图10 所示,通过对比图中绿框标出的部分可以发现,DGM 方法产生的填充效果较好地还原了DEM 数据的纹理特征,但是在空洞缺失面积较大的区域填充效果过于平滑,相比于DGM 方法,本文方法填充结果在真实空洞区域与其周边地形之间具有更好的协调性,且具有更多的纹理细节特征。
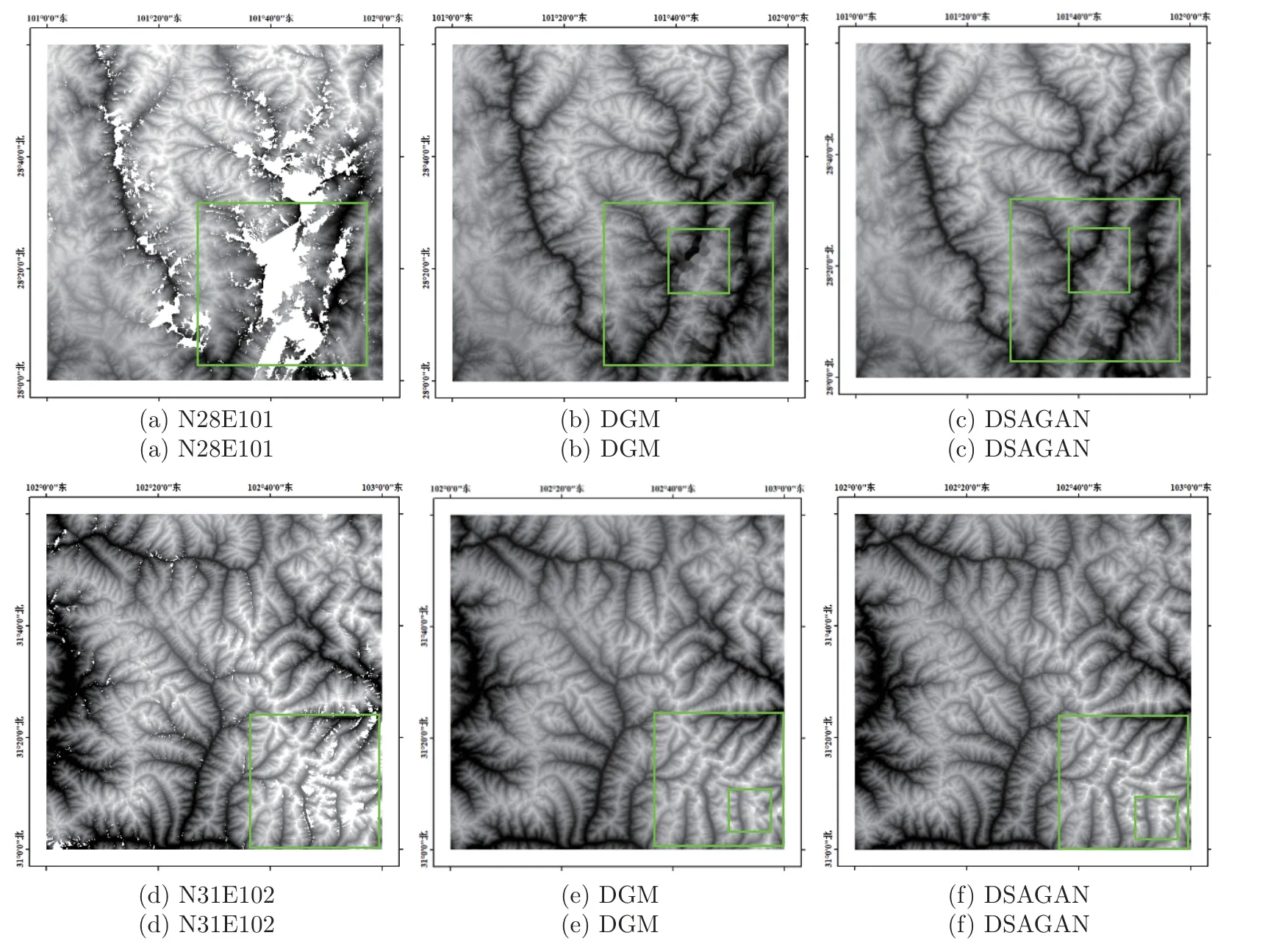
图10 DSAGAN 和DGM 空洞填充结果对比Figure 10 Comparison of void filling results between DSAGAN and DGM
3 结语
本文提出了一种融合自注意力机制生成对抗式的DEM 数据空洞填充方法,为了验证模型的有效性和泛化能力,选取不同地区、不同分辨率DEM 数据,分别与SAGAN、DGM 网络以及经典的插值方法进行对比,实验结果表明本文方法更容易把握DEM 数据局部与全局高程信息特征,填充结果与DEM 真值数据具有较高的吻合度,可以真实还原更多的纹理细节特征,并且具有更好的评价精度,是一种可靠性较高、适应性较强的填充方法。此外,该模型还可用于遥感影像云的去除、地面模型的异常点检测等应用,具有一定的推广能力。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09
数学小灵通·3-4年级(2021年5期)2021-07-16
今日农业(2019年15期)2019-01-03
传媒评论(2017年3期)2017-06-13
故事作文·高年级(2017年2期)2017-03-01
第二课堂(课外活动版)(2016年2期)2016-10-21
广西民族大学学报(自然科学版)(2015年3期)2015-12-07
新闻传播(2015年20期)2015-07-18
读者·校园版(2015年19期)2015-05-14
世界科学(2013年11期)2013-03-11
