
结合transformer 多尺度实例交互的稀疏集目标检测
2023-12-08 13:09阚亚亚张孙杰
应用科学学报 2023年5期
阚亚亚,张孙杰,熊 娟,祖 奕
上海理工大学光电信息与计算机工程学院,上海200093
目标检测[1-2]是计算机视觉领域的重要研究方向,也是其他复杂视觉任务的基础,其目的是在图像中对一组目标进行定位和识别。进入深度学习时代以来,目标检测发展主要集中在二阶段目标检测和一阶段目标检测两个方向。主流的二阶段目标检测器通过候选区域网络使正负样本更加均衡,其中Fast-RCNN[3]、Faster-RCNN[4]、Mask-RCNN[5]为经典的二阶段目标检测器。主流的一阶段目标检测器则直接在网络中提取特征来预测物体的分类和位置,其中SSD[6]网络和YOLO[7-8]网络为经典的一阶段检测器。
随着特征金字塔网络(feature pyramid network,FPN)技术的发展,很多目标检测器的应用方法相继诞生。特征金字塔网络与骨干网络结合后所提取的特征图能同时兼顾高层特征信息与低层语义信息,并呈现出跨越一系列尺度的高级特征映射,因此特征金字塔网络在目标检测、图像分割、图像识别等领域里得到了广泛应用。
在多尺度目标检测网络[9]中,随着特征提取网络层数的加深,图像的高层语义特征信息被充分提取,而低层语义特征信息逐渐稀释。因此,在区域选择过程中感兴趣区域(region of interest,RoI)很难同时兼顾网络中的高层语义特征信息和低层细节信息,从而影响了目标检测的效果。路径聚合网络[10](path aggregation network,PANet)通过自底向上的路径扩展,缩短了底层和顶层特征之间的信息路径,增强了特征层次。ZigZagNet[11]不仅通过密集的自顶向下和自底向上的方式聚合特征,还通过在自顶向下和自底向上层次结构的不同级别之间的锯齿状交叉来丰富多级上下文信息。DeepLabV3[12]、AugFPN[13]和PSP-Net[14]等方法利用多尺度上下文特征融合信息。U-Net[15]和PSP-Net 等编码器-解码器结构融合了中级和高级语义特征,增强了特征图的语义信息。
无论是一阶段还是二阶段的目标检测,成熟的目标检测算法都是基于密集的先验框,但会产生很多相似的结果,需要在非极大值抑制(non-maximum suppression,NMS)阶段过滤冗余的候选框。随着transformer[16]在深度学习图像上的广泛应用,DETR(detection transformer)[17]第一个将目标检测任务视为一个集合的预测序列,利用transformer 的编解码特性将检测任务重构为一定数目的序列预测。这个序列预测直接将大量密集的先验框稀疏化为一定数量的目标对象,于是本文把这种稀疏的序列预测称为稀疏集。DETR 采用了一种纯稀疏的端到端目标检测方式,它的输入为100 个目标对象的查询参数,在解码器中并行解码并进行全局图像特征交互,从而改善了模型的检测效果。为进一步提高收敛速度,Deformable-DETR[18]利用可变形卷积,更高效地处理稀疏空间中的信息,缩短了网络的收敛时间,但可变形卷积在利用卷积的多尺度信息时也大大地增加了学习patch 之间上下文关联的参量。Sparse R-CNN[19]提出了稀疏集和稀疏特征的方法进行端到端的目标检测,该方法避免了自注意力在全图上下文的信息交互,提高了收敛速度。但较少的信息交互使得建议框在调整阶段可学习的深层语义信息不足,影响了检测效率。这些稀疏集目标检测算法在利用transformer 的自注意力特性处理图像数据时,所有的空间特征信息均被统一化处理。稀疏集作为建议框提取区域特征时,缺乏重要通道细节信息来补充特征,没有做到全局上下文实例特征交互。因此,如何让建议框学习一个高度保留全局上下文信息交互的特征是稀疏目标检测器要解决的重要问题之一。
为此,本文提出自适应特征增强(adaptive feature augmentation,AFA)模块和实例特征交互(instance feature interaction,IFI)模块,并将AFA、IFI、FPN 和稀疏集检测器结合起来,通过自适应特征增强优化语义信息背景来减少噪声干扰。同时结合transformer 的多层自注意力机制,融合通道注意力网络和动态卷积层来强化建议框的通道信息。该检测器保留DETR 并行解码的检测优势,并利用包含全局上下文丰富语义信息的特征实现建议框的精调。实验表明,该方法可以更好地保留图像的全局上下文特征,在实例特征交互中有效地改善了稀疏目标检测器边缘信息学习不充分的问题,为完善稀疏目标检测器奠定了基础。
1 本文模型模块介绍
1.1 自适应特征增强
由于目标检测网络对于图像大、中、小目标检测尺度的不同要求,本文将ResNet50 结合改进的FPN 网络作为新的特征提取网络,用来提取目标图像的特征。本文的自适应特征增强模块依托于特征金字塔结构,但在目标检测中的效果优于特征金字塔结构。特征金字塔结构如图1 所示。
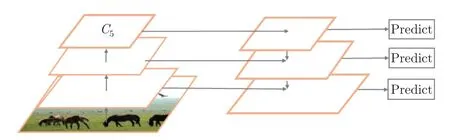
图1 特征金字塔结构图Figure 1 Structure of feature pyramid
在特征提取的过程中,特征金字塔的低层特征保留更多的语义细节信息,而高层的语义信息逐渐丢失,保留了更多的空间信息。为了减小高层语义信息的损失,同时保留最后一层特征图中的空间信息,本文提出了AFA 模块。如图2 所示,将特征金字塔融合后的顶层残差块特征图C5按照比例为Pi=(0.1,0.2,0.3,0.4) 进行自适应池化,并在后续的消融实验中证明了自适应池化的最佳比例。池化后的特征图与原特征图比例为Pi,从而得到不同维度下不同尺度的特征图,为减小信息丢失,将这些不同尺度的特征图全部使用双线性插值按照相邻比例Ui池化后的特征图大小进行上采样,最终采样到与C5残差块输出特征图相同的尺寸,进行相邻维度的通道拼接。为了保留高层空间信息和语义信息,本文将拼接后的特征图进行特征提取,采用1×1 的卷积进行通道压缩,压缩后的特征图与C5进行特征融合,得到与C5相同维度和尺寸的特征图A5,并用A5代替特征金字塔中的P6层,与相邻层进行逐层特征融合。
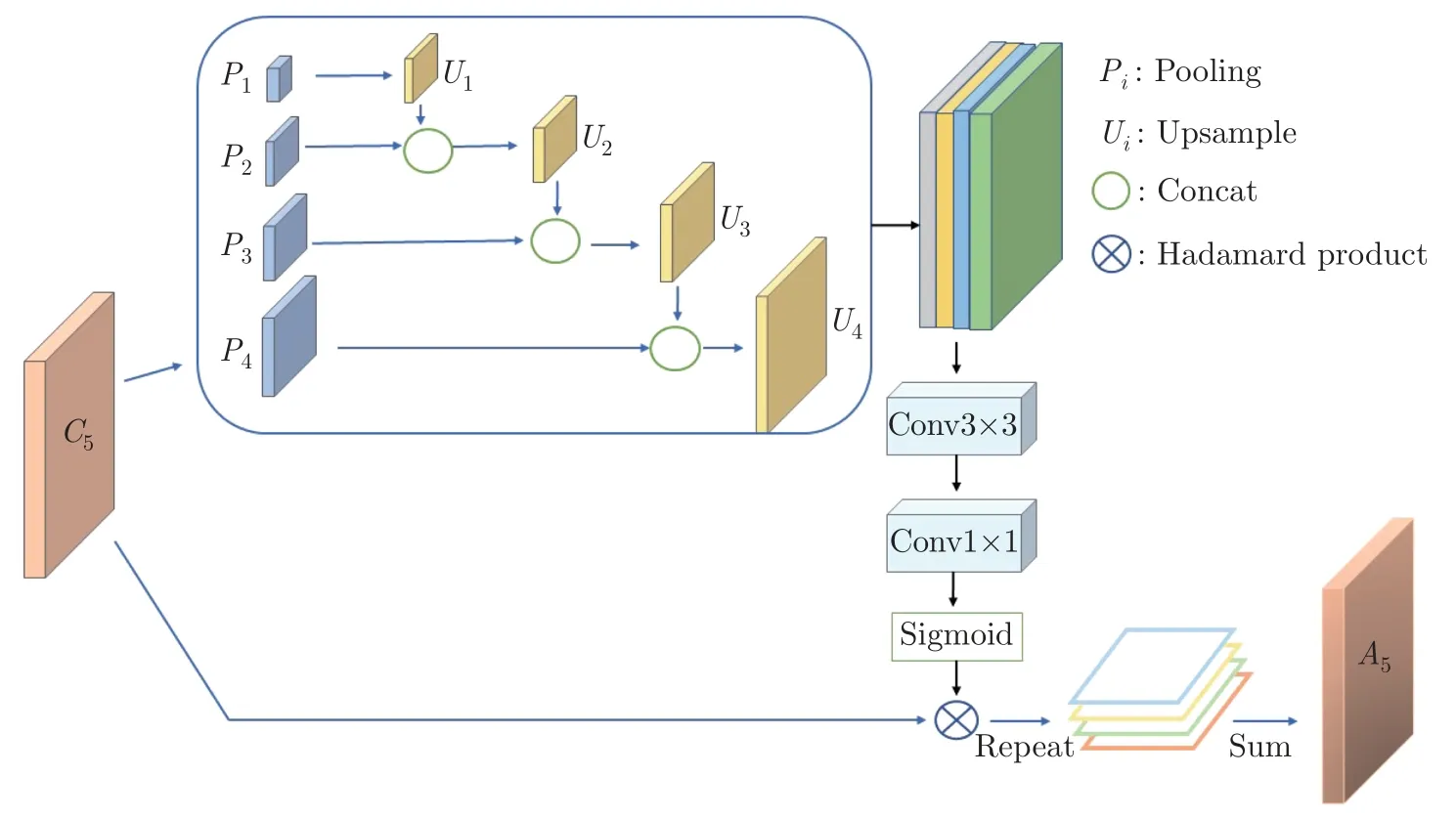
图2 自适应特征增强Figure 2 Adaptive feature augmentation
1.2 实例特征交互
一组图像经卷积神经网络提取特征后,每个RoI 的特征是通过池化某个特征级别获得的。本文网络在结合特征金字塔结构的语义信息交互方式后,首先通过RolAlign 算法生成固定稀疏数目的建议框,然后将这些建议框送入实例特征交互模块生成目标特征,并将目标特征送入前馈神经网络层中,得到目标检测的分类和回归结果。
图3 展示了实例特征交互模块。本文把经过特征提取后的稀疏图像特征集合、建议框和建议特征部分输入到实例特征交互模块中。其中建议特征部分和骨干网络没有关系,此时是把建议特征作为目标物体潜在位置的统计概率,并通过更新参数获得。对于输入的N个建议框,每个建议框使用i个的建议特征,其中建议特征是通过学习获得的一个维度为256 的潜在表示向量。学习到的建议特征被送入transformer 中的多头注意力层,将增强后的特征输入到该建议特征的分类和回归的前馈神经网络中。学习到的建议框则作为一个合理的统计量来执行后面的细化部分。
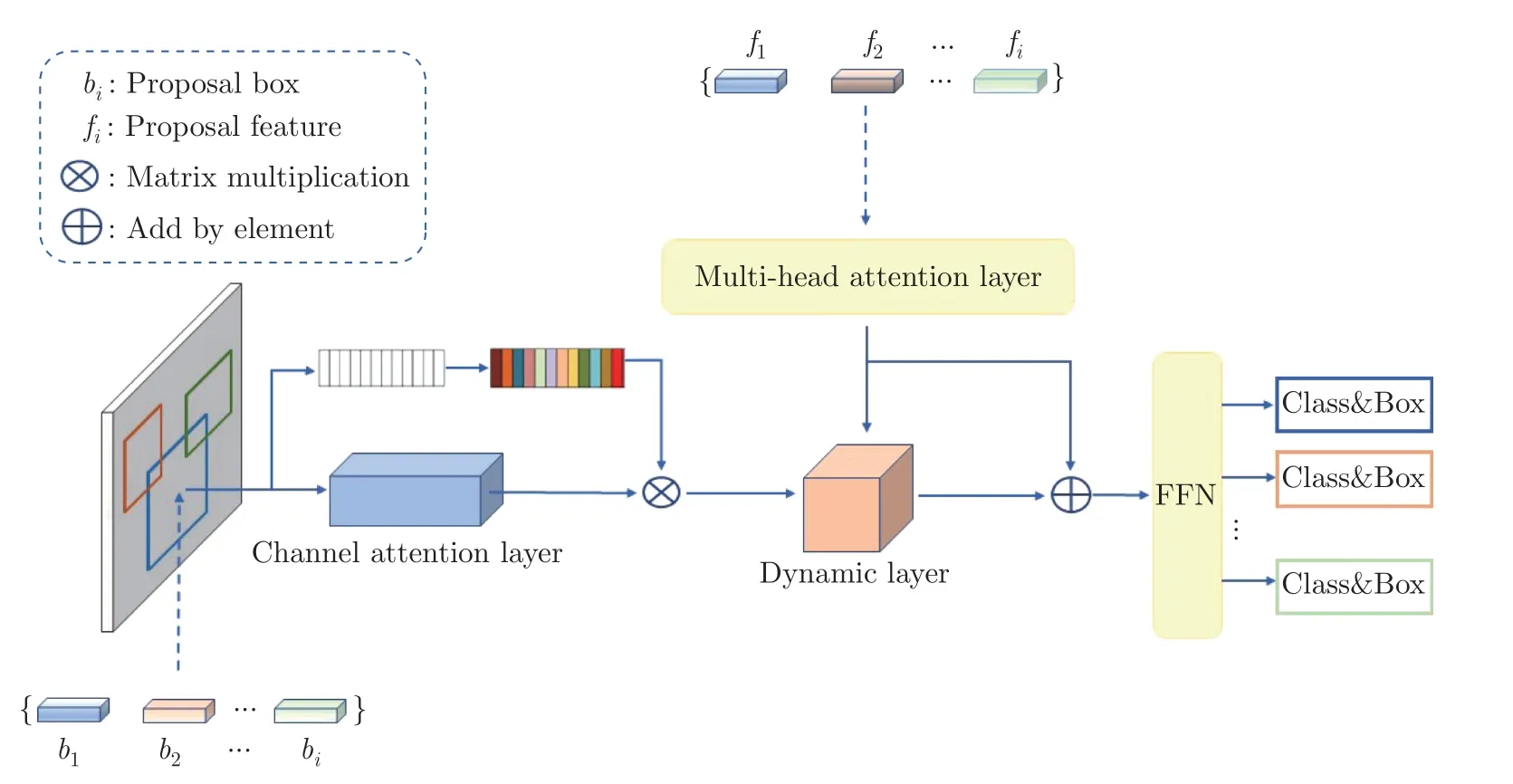
图3 实例特征交互Figure 3 Instance feature interaction
在IFI 的设计中,为了减少对外部信息的依赖,使建议特征更利于捕捉内部特征的相关性,本文在建议特征与RoI 特征进行实例交互前,首先将建议特征送入transformer 的多头注意力层中,用于关注RoI 建议框的中心坐标(x,y) 和宽高参数(h,w)。因此,在经过实例交互后,建议框经过多头注意力增强了显著特征,补充了目标的形状和姿态信息,从而得到一个更具有判别性的特征。本文在实验中还尝试堆叠多头注意力的层数以进一步提升性能。为了使建议框的语义信息和边缘信息得到补充,本文在实例特征交互模块中融合了通道注意力[20]与动态卷积[21]层,同时为卷积核和特征通道赋予注意力,使得建议特征的通道信息进行自适应增强,从而补充了目标的边缘信息。在目标特征进行实例特征交互后,通过一个前馈神经网络层得到分类结果,该前馈神经网络由两个全连接层和一个跳跃连接层组成。同时在边框的回归预测中,IFI 在ReLU 激活函数后进行了连续的1×1 卷积操作,最终实现目标的精确定位。
1.3 稀疏集预测损失
本文的算法摆脱了对以往大量密集建议框的依赖,根据transformer 中预测序列集合的思想,将大量建议框预测改为稀疏建议框预测,由此产生的损失经最优二部匹配算法来优化,具体公式为
式中:Lcls为预测目标与真实目标之间的类别损失,LL1为回归预测框中心坐标、预测框宽、高的L1 损失,Lgiou为采用最优二部匹配算法来优化的广义IOU 损失,αcls、αL1、αgiou分别为相应的损失权重。最终的损失是训练过程中稀疏预测框中所有损失的总和,其中αcls=2,αL1=5,αgiou=2。式(1) 中,参数的设置和训练策略主要采用DETR 的参数分配。
2 实验结果与分析
2.1 数据集和评价指标
本文在含有80 个类别的MS COCO2017[22]检测数据集上和20 个类别的PASCAL VOC数据集上分别进行实验,并采用目标检测的标准评价指标来评估检测器性能。对于COCO 数据集,本文在COCO Train2017(约118 000 幅图像)图像上进行训练,并使用了Val2017(约5 000 幅图像)进行评估,实验的结果都采用COCO 数据集的平均精度(average precision,AP)指标。随后本文使用了PASCAL VOC 公共数据集来验证算法的合理性。由于VOC2007和VOC2012 是互斥的,本文使用了VOC2007 和VOC2012 的Train+Val 进行训练,共训练16 551 幅图像,然后在VOC2007 的测试集Test(4 952 幅图像)上进行测试,实验采用PASCLA VOC 数据集的平均精确度的(mean of average precision,MAP)指标。
2.2 模型训练细节
本文模型在COCO2017 数据集和PASCAL VOC 数据集上训练,所有的实验是基于PyTorch 的框架,并在NVIDIA GeForce GTX1080 设备上进行。经过迭代后的模型作为预训练的模型再次训练。优化器采用AdamW,权值衰减值设为0.000 1,初始学习速率设置为2.5×10-5,参数更新方法为引入动量的梯度下降法。骨干网络的权重在ImageNet 上预先进行初始化训练,数据增强方式为随机调整输入图像大小,COCO 数据集设置图像大小为最短边800 像素,最长边1 333 像素,PASCAL VOC 数据集设置图像大小为最短边600 像素,最长边1 000 像素。建议框、建议特征和迭代的数量分别为100、100 和8。经过12 个Epoch 迭代得到如图4 所示的损失函数变化图,可以看到网络的收敛效果较好。
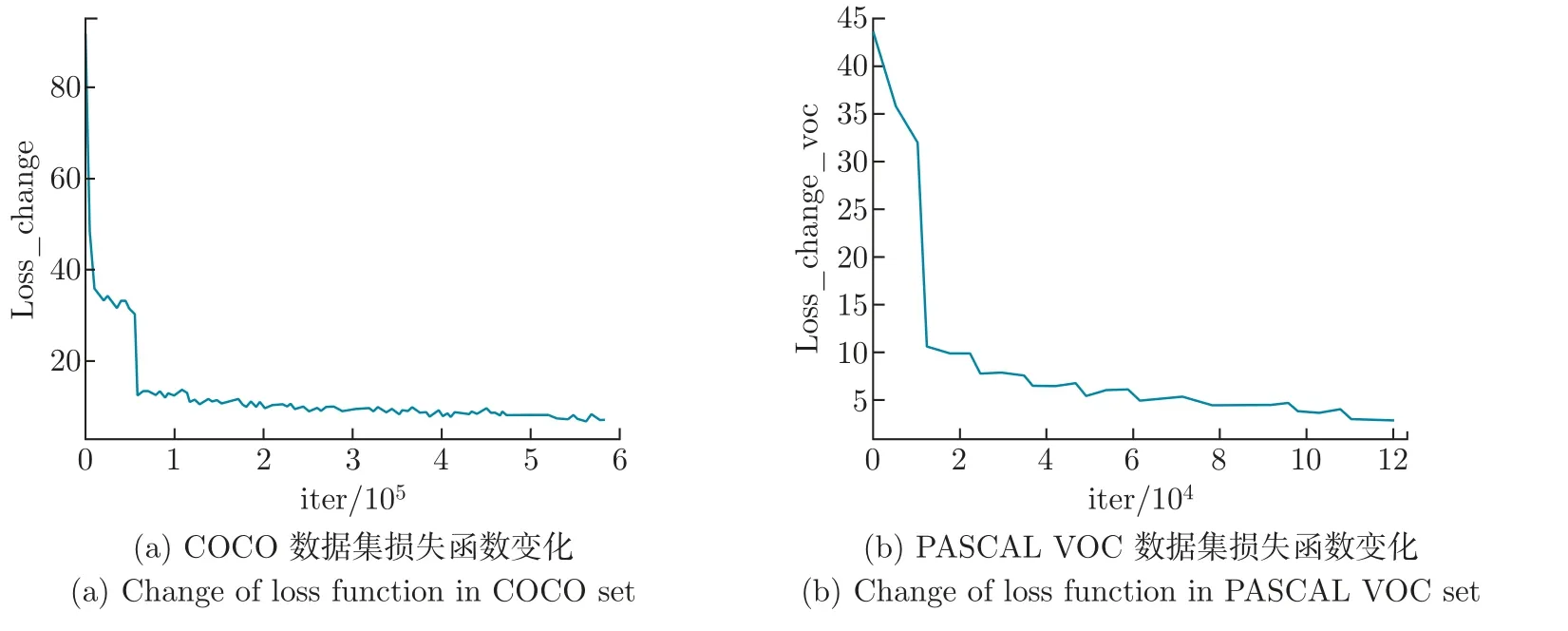
图4 损失函数变化Figure 4 Change of loss function
2.3 方法有效性分析
2.3.1 验证算法的有效性
本文算法与近年来经典的目标检测算法及稀疏集目标检测算法对比,其中包括RetinaNet[23]、FCOS[24]、Faster R-CNN、Libra R-CNN[25]、Mask R7、DETR、ATSS[26]、DyHead[27]等,结果如表1 所示(带“*”为引用结果,无“*”为本文实验设备运行结果)。该算法的结果与结合了ResNet101+FPN 的Faster R-CNN 算法相比具有显著优势;在大目标的检测上,本文算法的AP 比结合了ResNext-101-32x4d+FPN 的Faster R-CNN 算法要高出11.6%。在采用36 个Epoch 的训练计划后,本文方法的AP 比DETR 的检测结果高2.9%,比Sparse R-CNN 的结果要高2.1%。本文在消融实验中验证了检测模块的有效性,证明了所提方法能提高网络训练的整体效果,也能提升网络的准确率。
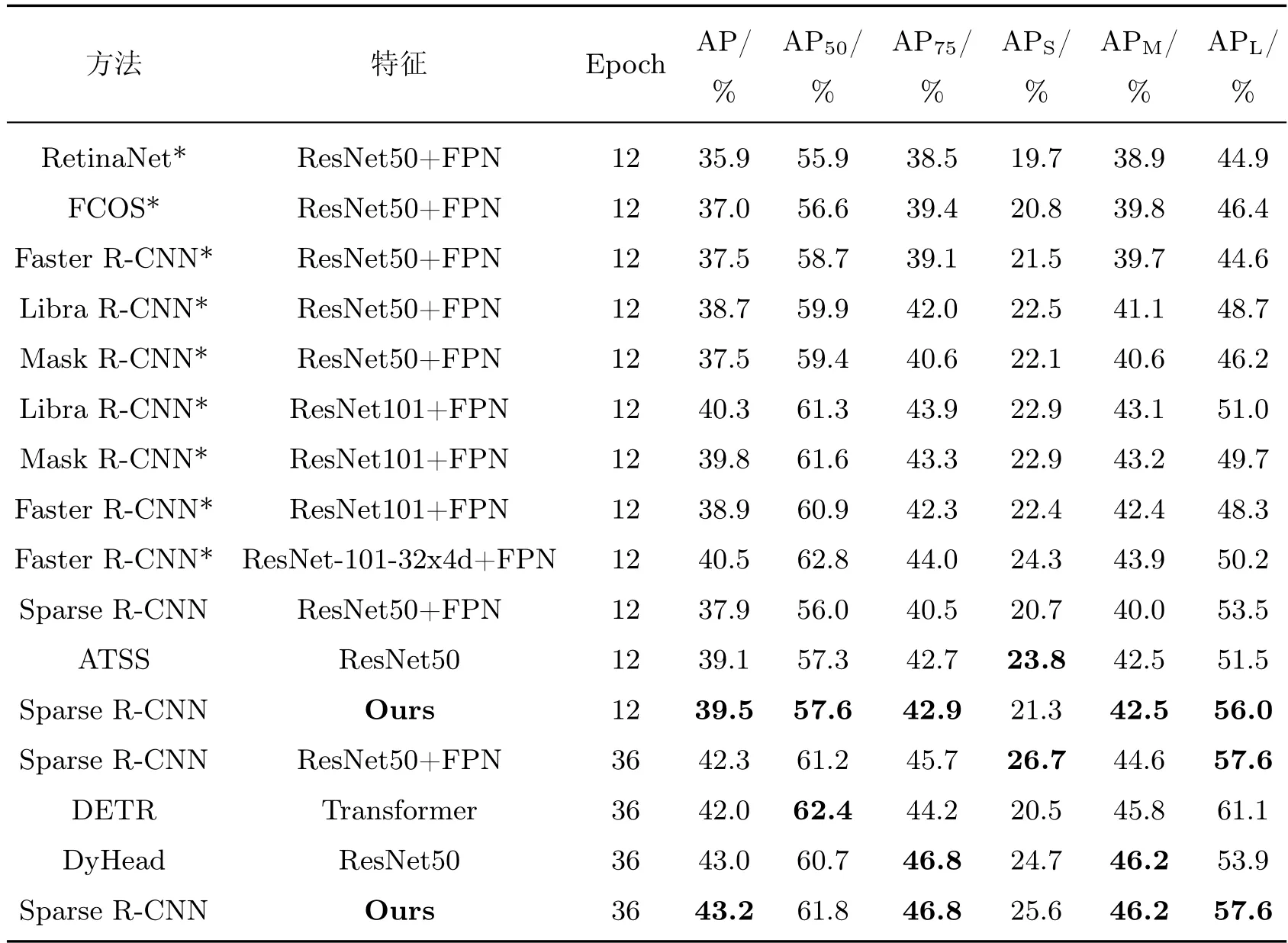
表1 各个模型在COCO 数据集上的比较Table 1 Comparison of various models on COCO dataset
为了进一步验证算法的泛化性,本文在数据集PASCAL VOC 07+12 上进行了训练和测试,分别与Resnet50 结合FPN 的Faster R-CNN 算法、基线Sparse R-CNN 算法进行对比,并将数据集中的20 类目标进行定性对比,实验结果如表2 所示。明显地,本文所提的模块方法在目标检测任务上获得了较好的表现,MAP 值比原有的基线任务提高了2.7%。
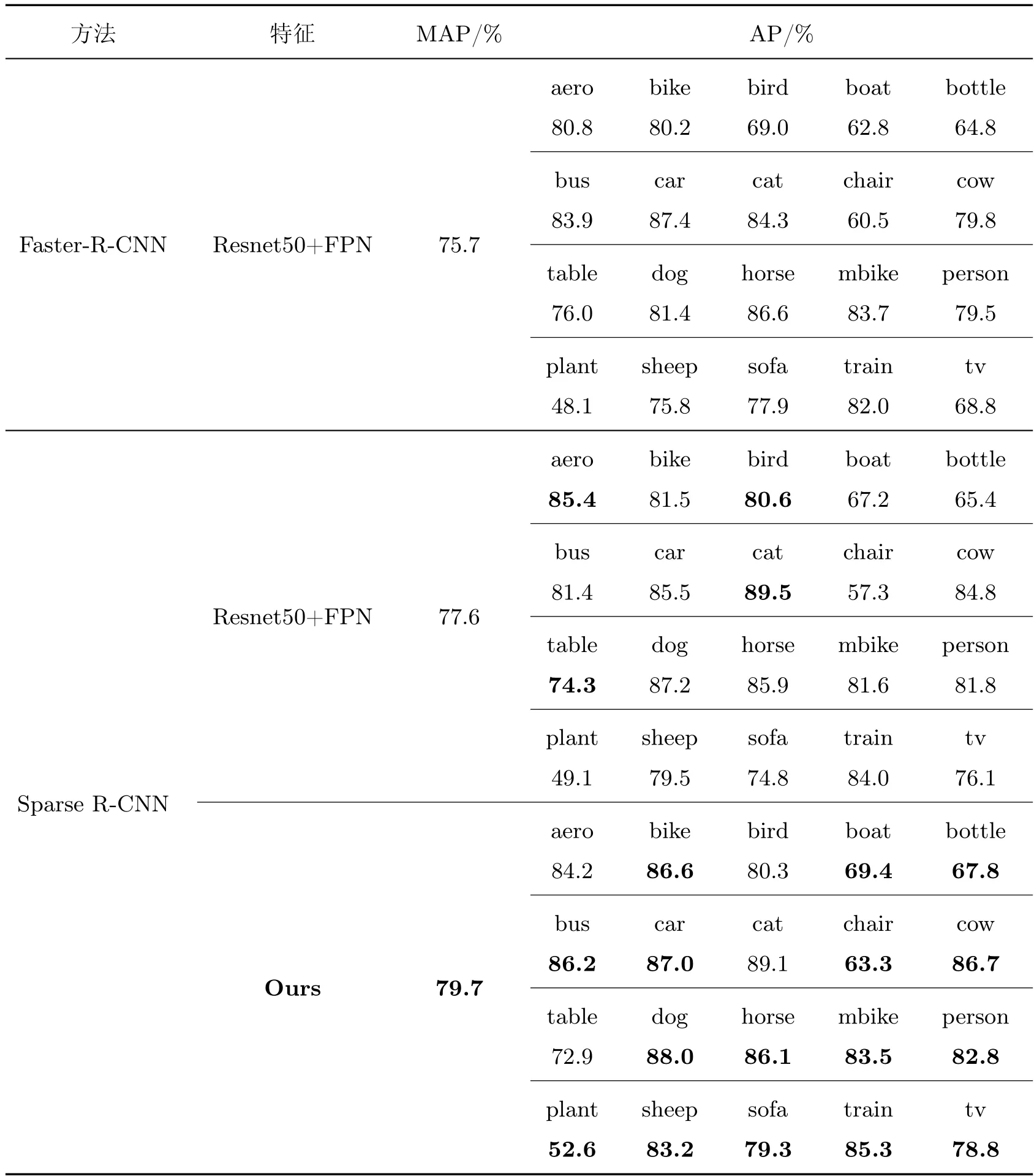
表2 PASCAL VOC 数据集实验结果Table 2 PASCAL VOC dataset experimental results
2.3.2 模型消融实验
本文选择主干网络Resnet50+FPN 的sparse R CNN 目标检测器为实验基线。考虑到所加模块对检测器性能的影响,本文对各模块进行了消融实验。如表3 所示,AFA 和IFI 对稀疏集目标检测器均有改善:AFA 的模块使得本文目标检测的AP 提升了2.9%;加入IFI 模块后,本文的AP 进一步提高了4.2%。
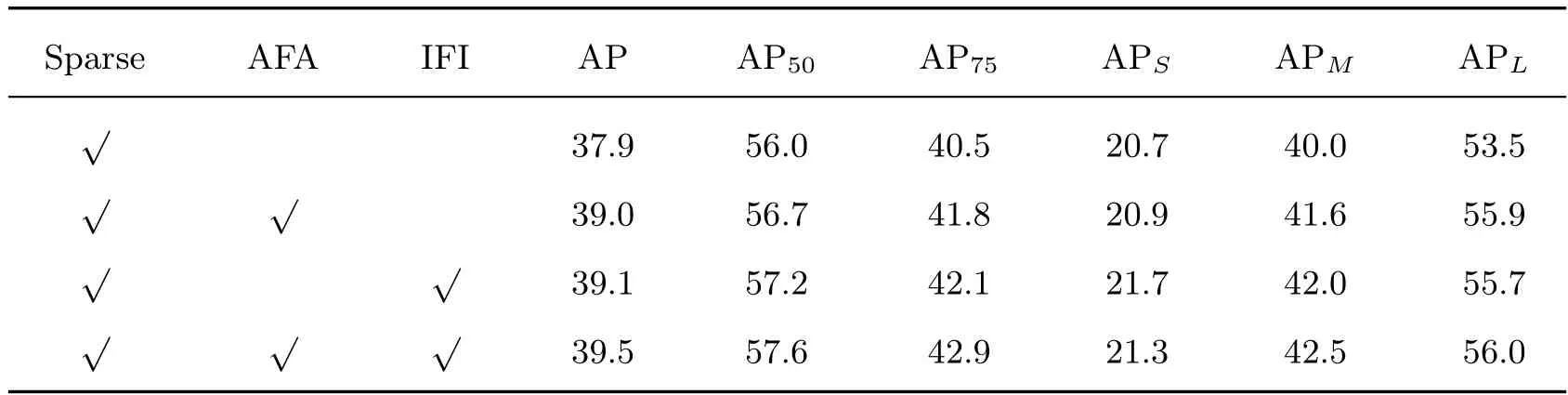
表3 模块消融实验Table 3 Module ablation experiment %
2.3.3 池化比例实验验证
在AFA 模块中,为了获得最佳的池化比例,本文首先将池化比例设置为0.1;0.1,0.2;0.1,0.2,0.3;0.1,0.2,0.3,0.4,实验发现最后一种比例组合的效果与前者相比获得了更好的精度提升。增多参数并没有提升检测效果,因此本文实验选择设置最后一种池化比例。实验结果如表4 所示。
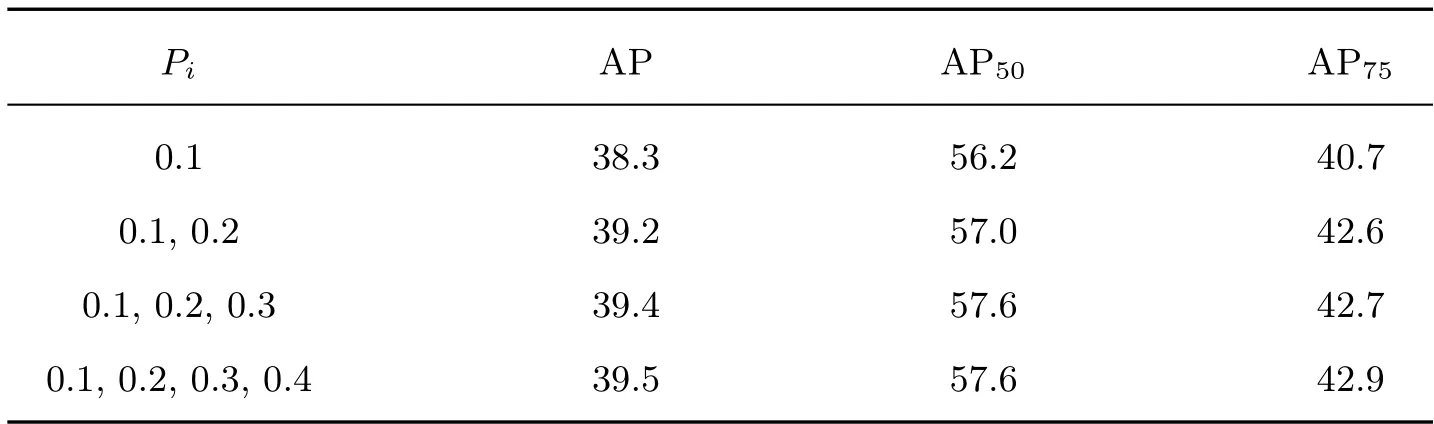
表4 池化比例分析Table 4 Analysis on pooling ratio %
2.3.4 注意力层数目
本文尝试堆叠注意力层来为实例特征交互模块提供更具有分辨能力的特征,结果如表5所示。通过逐渐堆叠注意力层,检测效果得到了进一步改进。当构建4 层注意力网络时,训练的检测精度AP 为35.8%;当进一步构建8 层注意力网络时,训练的检测精度AP 提升了10.3%;当增加注意力层数至12 层时,训练精度仍能获得近0.5%的提升。为保证模型整体的训练时间,本文选择堆叠8 层注意力。
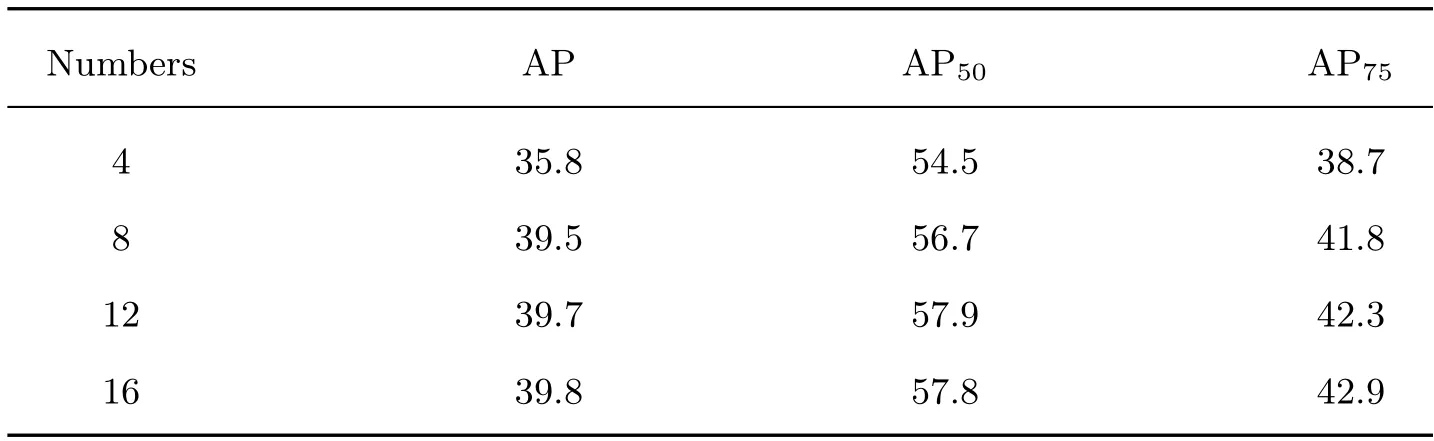
表5 注意力层数目Table 5 Numbers of attention layers %
2.3.5 结果可视化分析
本文在基线算法上加入AFA 模块后,与原基线算法进行可视化对比,图5 为本文的可视化网络效果图。AFA 模块在一定程度上缓解了多尺度目标的漏检、错检情况,提升了网络的精度。图5(a) 为本文基线算法处理的大象图像,虽然框选出了大象的位置,但大象下方的石头存在误检的问题;图5(d) 为添加AFA 模块后处理得到的大象图像,可以看出该方法能够精确地检测出大象的位置;图5(b) 为本文基线处理的钟表图像,不仅错误地框选了柱子,还漏检了小钟表;图5(e) 为加入AFA 模块后处理的钟表图像,该方法不仅检测到了同类别的大小两个钟表的位置,还减少了错检目标的发生;图5(c) 为本文基线算法,显然漏检了椅子目标;图5(f) 为添加AFA 模块后框选出了所有的检测目标,改善了漏检发生的情况,进一步提升了网络的效果。

图5 可视化网络效果图Figure 5 Visualize network renderings
AFA 模块虽然改善了目标经特征提取后高层语义信息不足的缺点,但在目标检测中,目标的边缘信息也不容忽视。加入IFI 模块后,通道注意力融合动态卷积后有效地补充了目标被忽视的边缘信息。图6(a) 为本文基线处理得到的鸟图像,虽然取得了较高的分类得分,但目标的边缘信息没有保全;6(d) 是加入IFI 后处理得到的鸟图像,可见鸟头部的边缘信息得到保留。图6(b) 为本文基线摩托车图像,可见其车轮信息不完整;图6(e) 为加入IFI 模块后处理的摩托车图像,可以看出摩托车前后车轮的边缘信息得到了补充,从而完整地框选出整个摩托车的位置。图6(c) 为本文基线处理的火车图像,由于尾部较长,没有框选出完整的位置;图6(f) 为加入IFI 后处理得到的火车图像中,火车虽尾部较长,但仍完整地框选出了火车的位置,进一步提升了网络的检测效果。

图6 边缘信息保留效果图Figure 6 Edge information retention renderings
3 结语
本文提出了一种有效的多尺度实例交互的稀疏集目标检测算法,将目标检测器结合自适应特征融合AFA 模块和实例特征交互IFI 模块,并将其运用在纯稀疏的图像目标检测方法上,保留了稀疏检测器中transformer 的自注意力优化全局语义信息的优点。自适应特征AFA模块有效地结合了特征金字塔网络,既能结合高层次的语义信息又增强了低层特征图细节信息,从而自然地赋予其多样化的上下文信息。在实例特征交互IFI 模块中,将通道注意力层与动态卷积层相结合,有效改善了目标经特征提取后边缘信息不足的缺点,提高了模型的准确性,加快了模型的收敛速度。本文的改进可以为后续稀疏目标检测器的改进提供思路。
猜你喜欢
开放教育研究(2020年2期)2020-03-31
疯狂英语·新策略(2019年10期)2019-12-13
当代陕西(2019年10期)2019-06-03
数学小灵通·3-4年级(2017年9期)2017-10-13
中国交通信息化(2017年9期)2017-06-06
现代语文(2016年21期)2016-05-25
工业设计(2016年11期)2016-04-16
大连民族大学学报(2015年2期)2015-02-27
河南科技(2014年23期)2014-02-27
河南科技(2014年22期)2014-02-27
