
基于压缩激励残差分组扩张卷积和密集线性门控Unet 歌声分离方法
2023-12-08 13:09张天骐
应用科学学报 2023年5期
张天骐,熊 天,吴 超,闻 斌
重庆邮电大学通信与信息工程学院,重庆400065
音乐源分离(music source separation,MSS)是音乐信号处理的基础研究领域之一。而单通道歌声分离(monaural singing voice separation,MSVS)是MSS 的一个重要方向,旨在从单通道混合音乐信号中分离出歌声和背景伴奏。歌声分离方法的改进与实现对于歌手识别、音乐信息检索和歌词识别等领域具有重大意义。
早期的歌声分离通常采用的是一些传统方法,例如反复模式提取技术(repeating pattern extraction technique,REPET)、鲁棒主成分分析(robust principal component analysis,RPCA)方法以及非负矩阵分解(non-negative matrix factorization,NMF)方法等[1-3]。这些传统方法缺乏灵活性,不能很好地适应不同类型的歌曲,也不能将歌声与背景伴奏彻底分离开来,分离性能并不理想。近年来,深度学习在歌声分离方面的研究受到了广泛关注。深度学习方法有着强大的非线性建模能力,它通过神经网络结构自动地学习和寻找特征以及拟合输入输出之间的关系,表现出了很好的分离性能。文献[4] 利用深度神经网络(deep neural network,DNN)模型学习目标源,并成功地将歌声从多种乐器混合演奏的声源中分离出来。但是基于DNN 的神经网络不能充分利用音频的时序信息。为此,文献[5] 提出了一种区分性训练的循环神经网络(recurrent neural network,RNN),该网络利用RNN 能够处理当前时刻和之前时刻信息的特性来加强网络对时序特征的利用,然后将分离前后音乐信号中歌声和背景伴奏幅度谱之间的差异性与损失函数进行有机结合,进一步提升歌声分离性能。但是RNN只能够处理短期依赖问题,并且在训练过程中容易出现梯度爆炸和消失的现象。文献[6] 提出了长短时记忆(long short-term memory,LSTM)网络,与RNN 相比,LSTM 加入了记忆模块,能通过神经细胞状态来记忆信息并且采用门控的方式来减少梯度消失和爆炸的可能性。文献[7] 使用LSTM 代替了常规的RNN 模型用于单通道语音分离,并且取得了比RNN 更好的分离效果。此外,还有学者研究出了一种双向长短时记忆(Bi-directional long short-term memory,Bi-LSTM)网络,它由前向LSTM 和后向LSTM 拼接而成,可以更好地保留序列信息。文献[8-9] 将Bi-LSTM 成功地应用在歌声分离领域,取得了很好的分离效果。
但是上述神经网络还有一个共同的问题:参数数量膨胀问题。网络参数量增加会导致网络训练占用大量资源。随着卷积神经网络(convolutional neural networks,CNN)在图像处理领域的广泛应用,越来越多的学者将其应用到了音乐源分离领域。CNN 中的每一层是通过共享的卷积核在特征图上进行滑动来提取特征,因此它能够有效获取一定的上下文特征,且大幅度地减少网络参数量。文献[10] 首次使用CNN 成功地从混合音乐中提取歌声。文献[11]将用于医学图像领域的编码器-解码器结构Unet(U-shaped neural network)首次应用于MSVS 任务之中,其中用到的Unet 结构是一种全卷积模型,通过预测目标源掩蔽来达到分离的目的。但是基于谱图的分离模型,Unet 忽略了相位信息从而对源分离性能产生影响。文献[12] 提出一种端到端的Unet 网络,该网络为之后的主流端到端模型提供了一种基本模型,其输入端是混合音乐信号的时域波形,输出端是歌声和伴奏的时域波形,并且取得了不错的分离效果。在此基础上,文献[13] 提出了一种端到端音乐源分离模型Demucs,它在编解码层中加入了线性门控单元(gated linear unit,GLU),加强了网络对语音时序特征的利用;在传输层还使用了Bi-LSTM,进一步加强了在特征传递过程中网络对音乐源信号长时相关性信息的利用,并取得了超过基于谱图Unet 模型的分离性能。同样地,文献[14-15] 在Wave-U-Net 基础上对网络结构进行优化从而提升网络分离的性能。
目前,频域分离模型Unet 在语音处理任务中存在以下两个问题:
1)由于Unet 神经网络最初用于医学图像分割领域而非歌声分离领域,所以Unet 捕获音乐信号时序相关信息比较困难。
2)Unet 通过直接跳跃连接的方式将浅层低级特征与深层高级特征进行融合,该融合方式直接通过通道连接来实现。但是这两种特征之间存在一定的语义差异,直接通道连接的方式可能会导致网络在整个学习过程中出现差异,进而对预测过程产生不利影响。
针对上述问题,本文将GLU 引入到了Unet 网络中间层,以并行处理各时刻的信息,同时加强网络对语音时序信息的获取;使用GLU 取代了原始的直接通道连接,以缩小浅层低级特征和深层高级特征之间的语义差距,同时还可以加强网络对浅层低级特征的利用。此外,本文还提出了一种压缩激励分组扩张卷积块,并将其添加到编码器的每层复合卷积层之后(即在两个扩张卷积和普通卷积交替连接之后加入压缩激励模块),使得网络可以进一步学习通道维度特征,在抑制无用特征的同时自适应地增强了有用特征,减少了网络参数量。改进Unet音乐分离网络旨在减少参数量的同时扩大网络的感受野,获取更多的局部特征,进而有效地提升音乐分离效果。
1 基线Unet 网络歌声分离
本文将Unet 作为基线网络,该网络类似于卷积编解码网络(convolution encoder-decoder,CED),结构如图1 所示。Unet 主体是由卷积层组成,与传统CNN 相比,它去除了上下采样层和全连接层。网络的输入为混合音乐信号的幅度谱,输出为歌声信号的幅度谱,最后结合混合音乐的相位谱得到预测歌声信号。Unet 网络的各个结构功能具体如下所述:
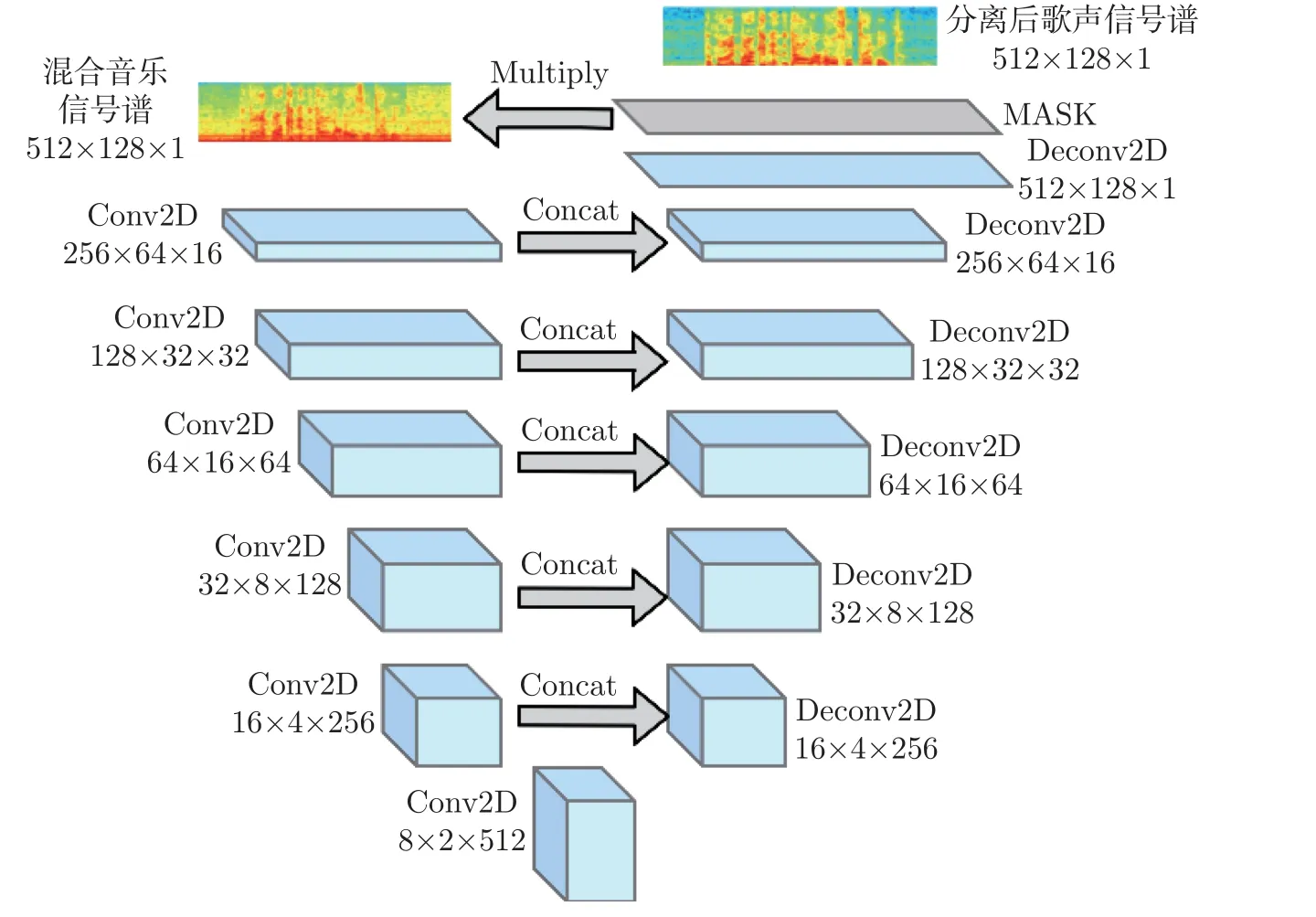
图1 基线Unet 歌声分离模型Figure 1 Baseline Unet singing voice separation model
1)编码层 编码层有5 个二维卷积层组成,在特征传递过程中每经过一个二维卷积层后时间和频率维度减半,通道数加倍。每个二维卷积层是一个复合层,包括二维卷积(twodimension convolution,2D-Conv)、批量归一化(batch normalization,BN)和泄漏修正线性单元(leaky rectified linear units,LReLU)。二维卷积使输入特征图维度成倍减少,且通道数成倍增加;批量归一化的作用就是将卷积后的数据特征的均值变为零,方差变为1,从而使数据特征分布都相同,有助于加快网络收敛且防止梯度爆炸和消失;激活函数为LReLU,与ReLU 激活函数不同,它在负值处的斜率不为0,从而保证训练过程中负值特征不丢失。
2)中间层 中间层由一个二维卷积层组成。该层也是一个复合层,与编码层中的二维卷积层相同,该层主要是起到特征传递的作用。
3)解码层 解码层可以看成编码层的逆过程,只不过在输出端添加了一个掩蔽层。解码层由5 个二维反卷积(two-dimension deconvolution,2D-Deconv)组成。每个反卷积层也是一个复合层,由二维反卷积、批量归一化和ReLU 激活函数组成。通过最后的反卷积层后将特征图维度和通道维度恢复至原始输入相同的维度,随后添加一层掩蔽层,通过掩蔽层与其输入相乘得到最终预测输出幅度谱,最后将该输出幅度谱与混合音乐信号相位谱结合进行逆短时傅里叶变换(inverse short-time fourier transform,ISTFT)得到分离后歌声时域波形。
4)跳连接 将维度和通道数相同的卷积编码层和反卷积解码层输出的特征图进行拼接,这使得低级特征信息直接从低分辨率输入得到高分辨率输出。
2 压缩激励模块
压缩激励模块[17](squeeze-and-excitation,SE)是一种通道注意力模块,主要包含压缩和激励两部分。它通过建模通道之间的相互依赖关系来自适应地重新校准通道特征响应,同时它可以学习使用全局信息来选择性地强调有用信息特征并抑制无用特征。具体结构如图2所示。
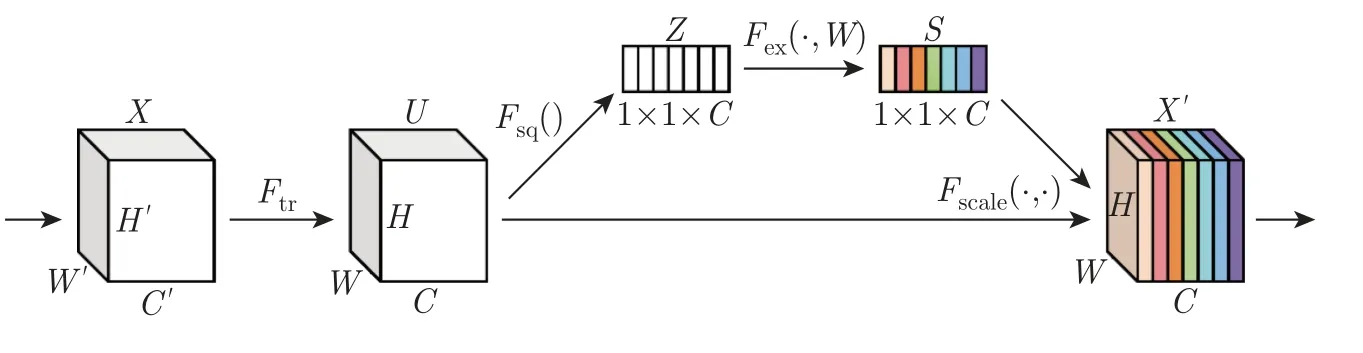
图2 压缩激励模块Figure 2 Squeeze-and-excitation model
图2 中:X为SE 模块的输入;W和W′分别表示混合音乐信号谱图经过卷积后得到特征图的时间维度;H和H′分别为频率维度,C和C′分别表示通过卷积层后的通道数;Ftr()、Fsq()、Fex() 以及Fscale() 分别表示对输入的转换(即二维卷积变换)、压缩、激励以及乘的操作;Z、S和X′分别表示压缩输出、激励输出以及SE 模块最终的输出。
输入X经过Ftr() 操作就得到新的特征U。由于U中每个通道的滤波器都使用局部感受域进行操作,因此U中每个通道单元就无法利用该区域以外的上下文信息。为解决此问题,这里通过全局平均池化将时间和频率维度信息压缩到通道描述符中,变成一维矩阵Z,Z中第c个元素为
然后将特征矩阵Z通过激励操作Fex() 来得到各个通道的权重向量S,激励操作主要是由两层全连接层和激活函数组成,具体计算数学式为
式中:δ为ReLU 激活,σ为Sigmoid 激活,,r为降维系数。
第1 个全连接层通过调整降维系数r的值i来起到降维的作用,随后就是ReLU 激活。接着通过第2 个全连接层,该层起到的是升维的作用,将通道数恢复至与输入相同,最后通过Sigmoid 激活得到的输出权重矩阵S的维度为1×1×C。
最后将权重矩阵S与输入特征矩阵U在通道上进行相乘(即Fscale() 操作)来进行权重分配,最终得到在通道上对声源特征进行加权后的特征矩阵X,具体计算数学式为
3 注意力门控机制
基线Unet 网络是通过将编码层输出特征与解码层输出特征直接进行拼接来实现对底层特征的提取和融合。然而这种直接拼接方式并没有考虑到音乐信号底层低级特征和深层高级特征之间的差异。为解决该问题,本文使用注意力门控机制来代替通道连接,该注意力门控机制能有效增强编码层输出的低级特征和解码层输出的高级语义特征之间的相关性。
本文采用的注意力门控结构如图3 所示。其中W1、W2、W3和Wa均为卷积核大小为1×1,步长为1 的二维卷积,且Wa为最终的注意力权重;c1、c2和c3分别为W1、W2和W3的输出通道数,BN 表示批量归一化,⊕和⊗分别表示逐点相加和相乘。在注意力门控结构中一个分支是将编码层特征和解码层特征分别经过两个二维卷积层后进行特征合并,经过LReLU 激活,随后再经过一个二维卷积层,最后通过Sigmoid 非线性激活得到注意力权重系数Wa;另一个分支就是将编码层输出e和注意力权重Wa逐点相乘,得到注意力门控单元的输出Oattention。
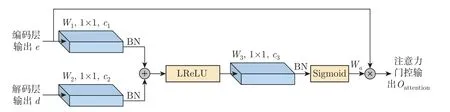
图3 注意力门控结构Figure 3 Attention gating unit
1)注意力权重分支
2)注意力门控输出
4 压缩激励残差分组扩张卷积模块
残差连接不仅能加强信息流和梯度流在网络中的传递,而且还能防止梯度消失。扩张卷积和普通卷积相比在同一层能够获得更大的感受野。在文献[17] 和[18] 的启发下,本文提出了一种压缩激励残差分组扩张卷积模块,具体结构如图4 所示。这里采用分组卷积以及卷积分解的目的是降低网络参数量,但不降低网络的精度。
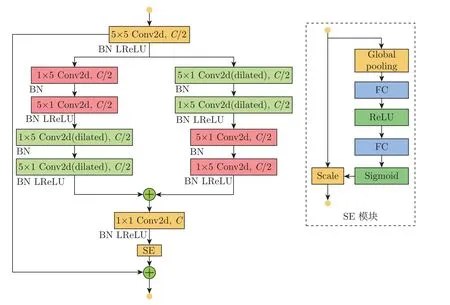
图4 压缩激励残差分组扩张卷积模块Figure 4 Residual group dilated convolution combined with squeeze-and-excitation module
该模块将通过一个核大小为5×5,步长为1,通道数为C/2 的复合卷积层,然后分两个支路进行特征传递,在两个支路中分别使用普通卷积、扩张卷积进行交替连接。文献[19] 中也同样利用这种交替连接,使得在扩张卷积中没有被利用的采样信息可由普通卷积进行弥补。同时,将核大小为5×5 的卷积分解为1×5 和5×1 的两个卷积来减少网络参数量,其中该模块之中的所有卷积的步长均为1,块内扩张卷积的扩张率保持一致。文献[17] 指出压缩激励模块可以集成在非线性激活操作之后,因此本文也将SE 模块集成在恢复通道、核大小为1×1 的二维卷积的非线性激活LReLU 之后,以加强通道之间的相互依赖关系。
5 密集线性门控单元模块
2017 年,文献[20] 将门控卷积单元应用到卷积网络之中,对语言进行建模,目的在于加强网络对语言时序上下文信息的捕捉。文献[21] 将线性门控单元、一维扩张卷积和残差连接结合起来,搭建了一种一维门控残差模块,用于语音增强。在此基础上,本文将线性门控单元引入到基线网络的中间层,增强了网络在特征传递过程中对时序信息的获取和利用,同时结合扩张卷积,就可以获取比标准卷积更广泛的上下文信息。具体结构如图5 所示。
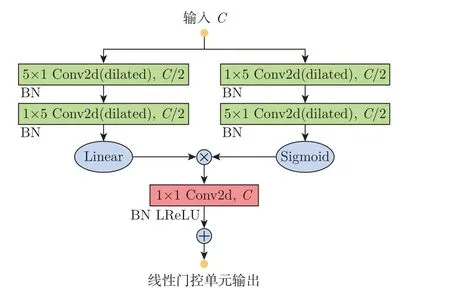
图5 门控线性单元模块Figure 5 Gating linear unit module
受到文献[22-23] 的启发,本文在基线Unet 网络的中间层运用了8 个线性门控单元,它们按照不同扩张率进行堆叠,并且块间采用密集求和方式进行不同层级之间的特征融合。虽然感受野随着堆叠的层数线性增长,但是全局建模却需要很多普通卷积层才能覆盖足够大的输入域,因此网络训练会变得很困难。此时,使用扩张卷积块堆叠就成了有效的应对方法,已经证明其对音频生成和MSS 任务有效[23]。同时为了防止网格效应,扩张率依次设置为1,2,5,9,2,5,9,17。
为了尽可能减小模型参数量,节约计算资源,在密集连接时采用相加操作取代通道连接。这是因为通道连接会造成通道数成倍增加,从而导致模型参数量增加,相加操作则可以使得输入输出维度相同,在堆叠过程中不需要降维操作,因此提升了模块的可移植性。同时,随着卷积层中扩张率的增加,模型可能会较少关注相邻位置,这里采用块间密集相加来解决此问题。密集门控线性单元具体结构图如图6 所示。
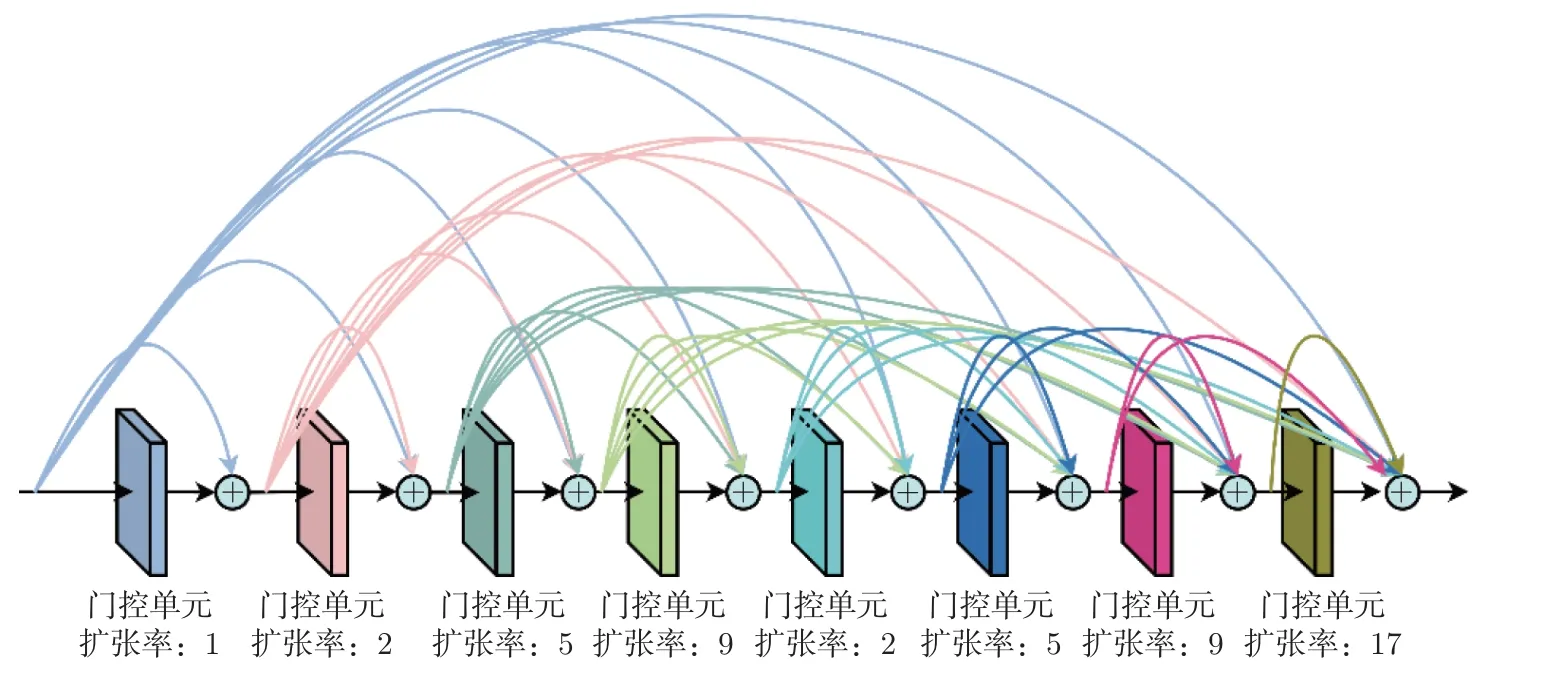
图6 密集门控线性单元Figure 6 Dense gating linear unit
6 改进后的网络结构以及参数
图7 是本文对基线Unet 网络进行改进后得到的网络结构图。网络编码层有4 层二维卷积复合层,在前3 个复合层之后,加入压缩激励残差分组扩张卷积块,总共3 层:扩张率依次为1,2,5。混合音乐信号特征图经过第4 层——二维复合卷积层之后进入到中间传输层,中间传输层采用8 个线性门控单元堆叠。为了尽可能减少参数量,采用密集相加操作方式进行块间连接。
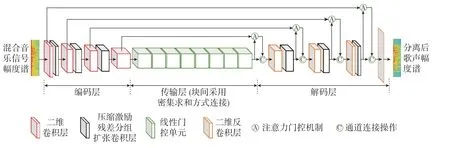
图7 改进后的网络结构Figure 7 Improved network structure
网络解码层有4 层反卷积复合层,其激活函数为LReLU 函数。在前3 层二维反卷积层之后加入压缩激励残差分组扩张卷积块,总共3 层:每层扩张率和网络编码层设置相同。信号特征图经过第4 层——二维反卷积复合层后,将时间与频率维度、通道数恢复至与初始输入相同。
跳跃连接部分使用注意力门控机制代替基线网络中的通道连接操作。这使得鲁棒性更高的高分辨率特征与维度以及通道数相同的低分辨率特征进行融合,缩小了低级特征和高级特征之间的语义差距,同时提升了解码过程中对特征恢复的效果,加强了网络对底层特征的利用,提升网络性能。
表1 为改进后的网络各层参数设置、输入和输出维度。其中BN 为批量归一化,LReLU表示泄漏修正线性单元,K为二维卷积与二维反卷积核大小,S为二维卷积与二维反卷积步长,C为二维卷积与二维反卷积层通道数,α为漏修正线性单元负值斜率,D为扩张卷积的扩张率,Block1-Block6 表示压缩激励残差分组扩张卷积模块,DAGLU 表示采用8 个不同扩张率的块间密集相加堆叠而成的线性门控单元。
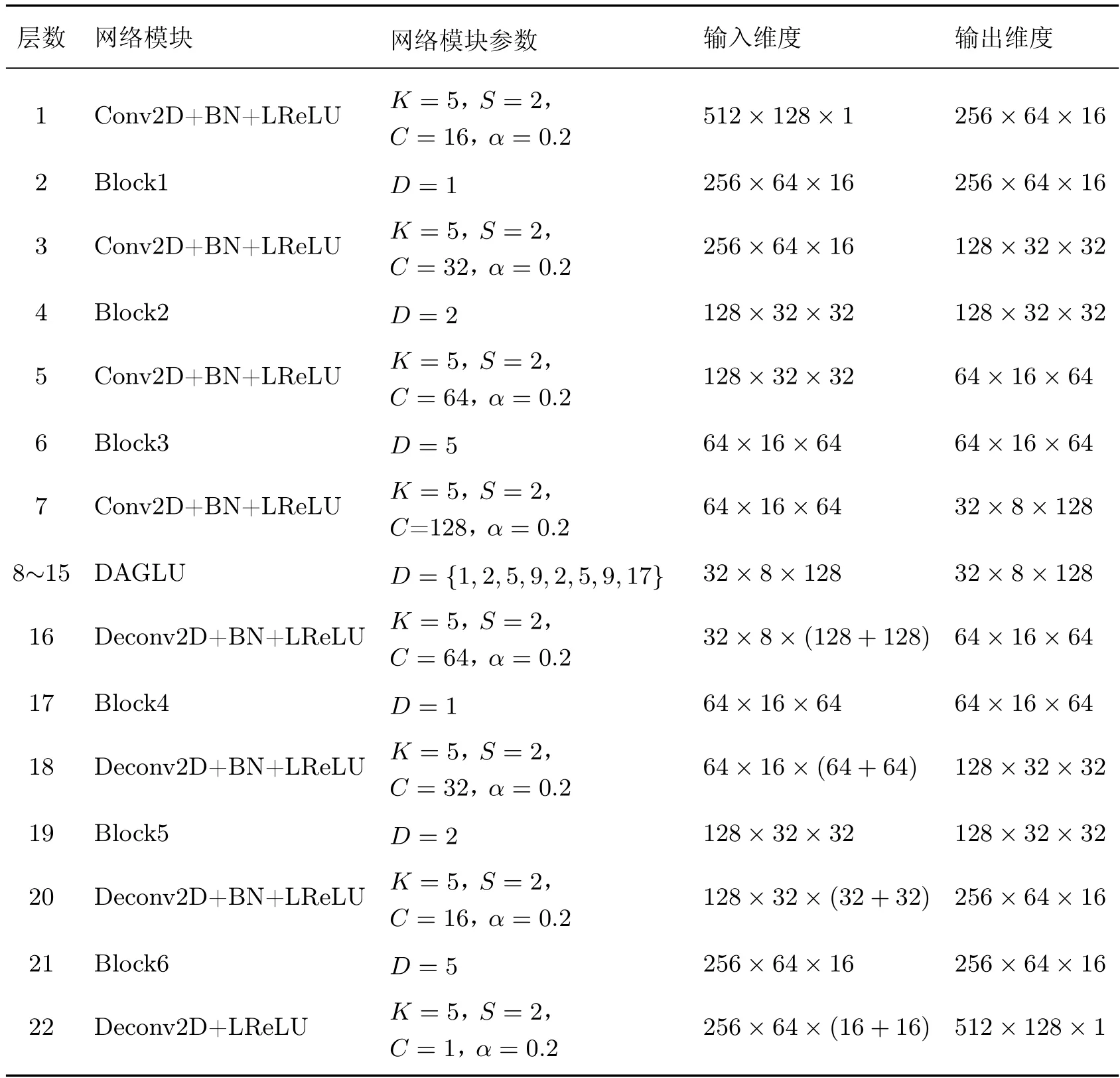
表1 改进网络结构各层参数以及输入输出维度Table 1 Each layer parameters,input and output dimensions of improved network structure
7 实验结果及分析
7.1 数据集及训练参数设置
实验数据主要来自于包含50 首完整歌曲的CCmixter 数据集,另外从MUSDB18 数据集中随机选取50 首完整歌曲来扩充数据集,平均每首歌曲时长为2~6 min。对于CCmixter 数据集中每首歌曲有3 个分支,即混合音乐信号、纯净歌声以及纯净背景音乐,是专门的歌声分离数据集;对于MUSDB18 数据集中每首歌曲有7 个分支,它主要用于音乐源分离领域,本文只取其中3 个分支,即混合音乐信号、纯净歌声以及纯净背景伴奏。取扩充后数据集中的75首歌曲组成训练集,25 首歌曲组成测试集,取训练集75 首歌曲中的15 首作为训练过程中的验证集。考虑到训练这样一个模型的大量计算要求,首先将输入音频下采样到8 192 Hz 以加快处理速度,然后计算窗口大小为1 024 且跳跃长度为768 帧的短时傅里叶变换(short-time Fourier transform,STFT),最后形成网络的输入:取STFT 后的幅度谱,并提取其中的128帧,每帧的频率维度取为512,因此网络的输入维度为512×128×1。
训练时采用Adam 作为优化器,通过反向传播进行训练。初始学习率设置为0.001,每经过10 个epoch 后学习率下降到原来的1/10。epoch 值设为100,batchsize 设置为8。
7.2 损失函数
网络训练时的损失函数为平均绝对误差函数(mean absolute error,MAE),它是计算模型预测值与样本真实值之间距离的平均值,其公式为
式中:M为批处理的大小,‖·‖1表示1 范数,与Yi分别表示预测歌声与纯净歌声第i帧的幅度谱向量。网络的权值迭代更新是由损失函数的梯度乘以学习率得到。
图8 为仅使用CCmixter 数据集,以及在CCmixter 数据集基础上使用MUSDB18 数据集进行扩充后的数据集,分别对网络进行训练时的训练误差(train loss)以及验证误差(val loss)收敛曲线。
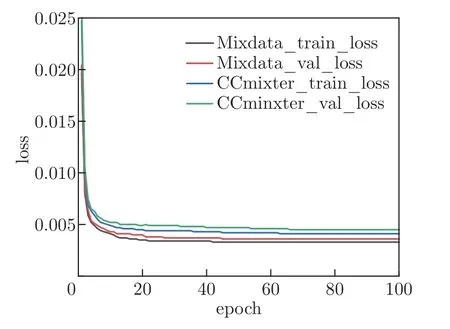
图8 CCMixter 数据集和扩充数据集的训练误差和验证误差收敛曲线对比Figure 8 Comparison of training error and verification error convergence curves between CCMixter data set and expanded data set
7.3 实验性能评价指标
7.3.1 客观评价指标
本文使用的是mir_eval 工具包来测试分离性能,具体指标包括:信号失真比(signal distortion ratio,SDR)、信号干扰比(signal interference ration,SIR)以及系统误差比(source artifacts ratio,SAR)。SDR、SIR 以及SAR 分别反映了算法的分离度、噪声性能和鲁棒性,3个指标对应的计算公式分别为
式中:starget(t) 为目标信号源,einterf(t) 为其他信号源引起的估计误差,eartif(t) 为系统本身产生的系统噪声误差。
7.3.2 主观评价指标
主观评价标准(mean opinion score,MOS)是一种以主观的形式评价语音质量的标准。它是由被选取的听众对每一段分离出的音乐所给出分数的算术平均数,表达式为式中:N为所选听众的总数,Rn为指定音乐(分离的背景伴奏或歌声)所得的分数。采用的是满分为5 分制的打分形式:5 分表示听感优秀;4 分表示听感良好;3 分表示听感尚可;2 分表示听感较差;1 分表示听感劣质。
7.4 实验结果与分析
7.4.1 消融实验
本实验是为了验证在基线网络中添加的各个模块对歌声分离效果的提升,在数据集上进行的消融实验结果如表2 所示。Unet-Attention 表示只使用注意力门控机制代替Unet 中的跳跃连接部分后的网络;Unet-Block 表示只是在Unet 的编码和解码层中嵌入压缩激励残差分组扩张卷积块后的网络;Unet-DAGLU 表示只在Unet 的中间层添加密集相加的线性门控单元后的网络;Proposed 表示本文改进后的网络。
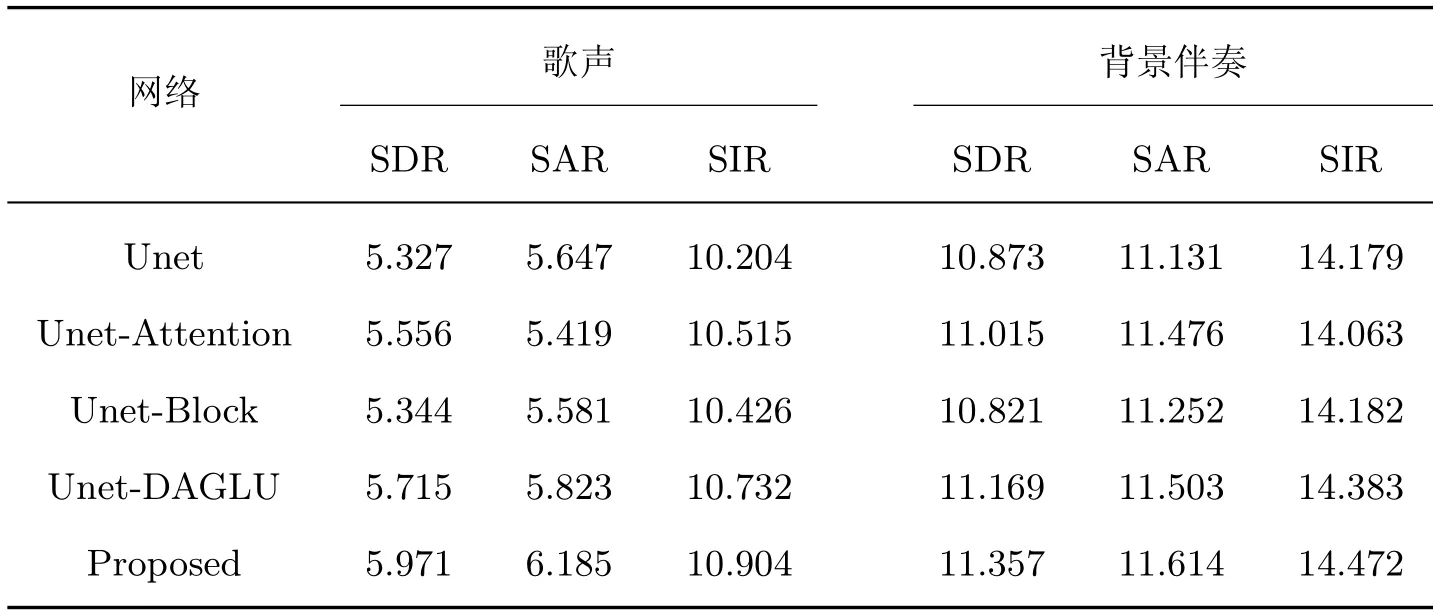
表2 引入不同模块后对基线网络的分离性能对比Table 2 Comparison of separation performance of baseline network after introducing diffierent modules
从表2 可以看出,不同模块加入到基线网络之后,分离指标整体上比基线网络有所提高。不管对于歌声还是背景伴奏,本文提出的方法要比单一模块加入到网络后的分离效果更佳。对于单一模块之间的比较,在中间层加入了8 层不同扩张率的密集相加线性门控单元模块后,分离性能指标要比其他两个单一模块嵌入网络的有所提高,这说明:加深的网络、使感受野增大的模块堆叠扩张卷积、能捕获时序特征的线性门控单元以及利用不同层特征的密集相加连接方式,这些手段都能较好地提升网络的分离性能。
7.4.2 中间层模块不同扩张率对分离性能的影响
虽然扩张卷积要比普通卷积在同一层能够获得更大的感受野,但是在多个扩张卷积块进行堆叠时可能会引起网格效应的出现,从而影响网络的分离性能[24],此时通过设置适当的扩张率就能够减小网格效应。
表3 为不同扩张率对网络分离歌声性能的影响。可以看出,当扩张率分别设置为1,2,5,9,2,5,9,17 时,SDR、SAR、SIR 的值最大,网络分离性能最好。当扩张率为1,2,4,8 或2,4,8,16 的倍数时,网络的分离性能会由于卷积核不连续出现网格效应,从而对网络分离性能造成影响。
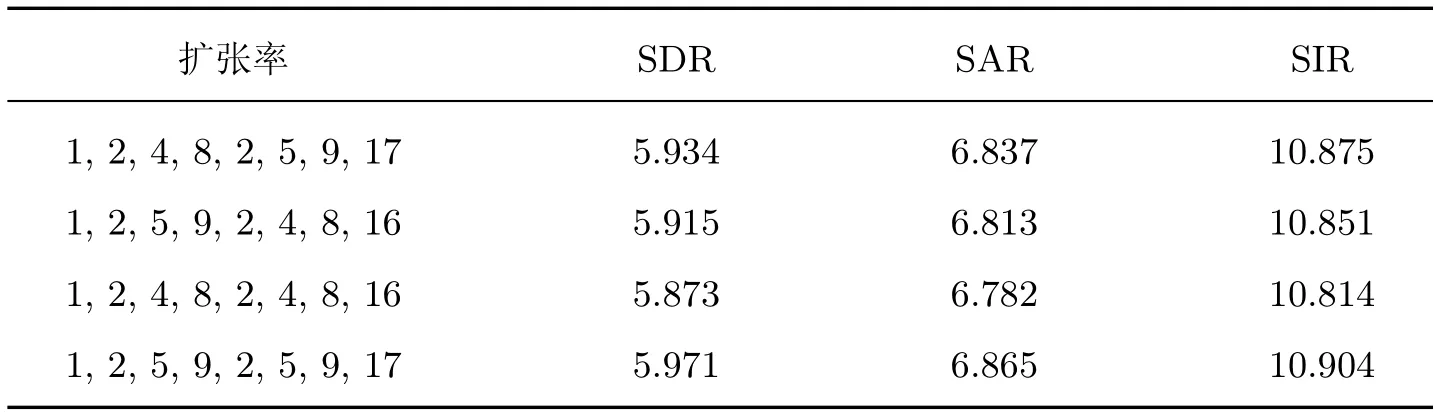
表3 不同扩张率对歌声分离性能的影响Table 3 Effiects of diffierent dilated rates on song separation performance
7.4.3 本文模型与其他方法分离性能的比较
为了说明改进后的网络在分离性能上的优越性,本节将改进后的网络和基线Unet、卷积神经网络CNN、Unet-Attention 以及传统的RPCA 方法在数据集上进行分离性能的比较,结果如表4 所示。其中CNN 网络包括5 层二维卷积层、5 层最大池化层以及两个全连接层;Unet-Attention 网络为注意力门控引入跳跃连接[25];RPCA 为传统的鲁棒主成分分析方法。
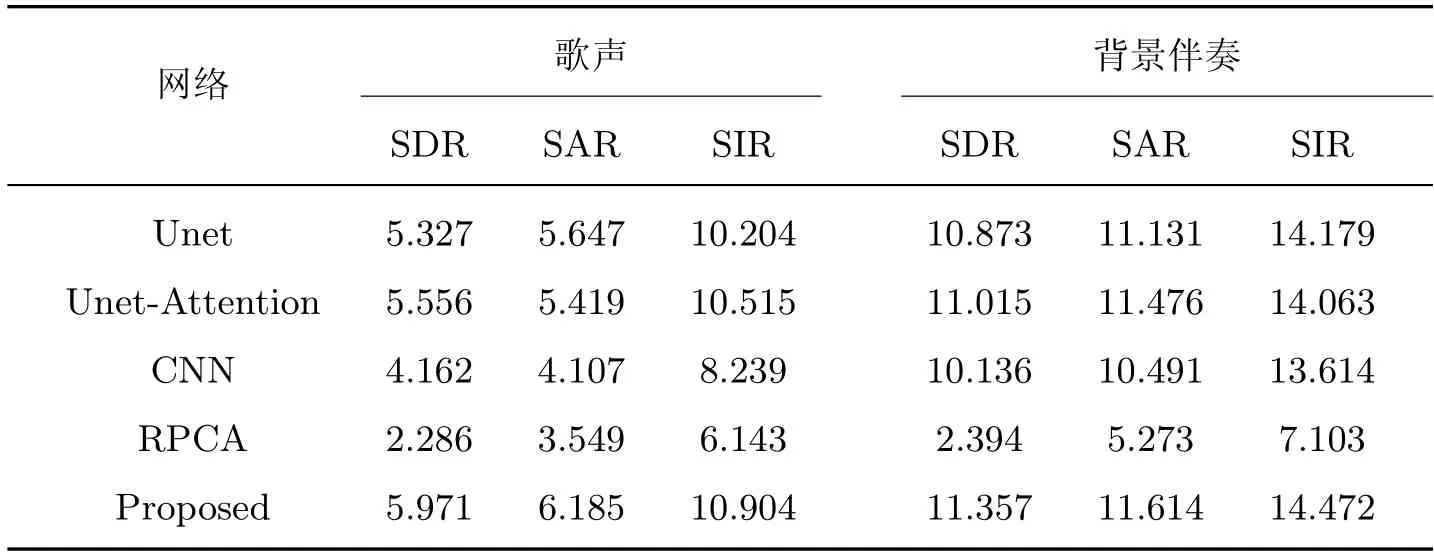
表4 不同网络分离性能指标的比较Table 4 Comparison of diffierent network separation performance indexes
如表4 所示,不论是分离歌声还是背景伴奏,本文提出的方法比对比方法的分离性能指标值都高,这也说明本文网络的分离度、噪声性能以及鲁棒性是最好的。
7.4.4 分离性能主观评价
为了说明分离后的歌声与背景伴奏在主观听感上的差异,本文进行了主观听感测试,选取12 个人并分为2 组,一组为6 个男生,另一组为6 个女生。在数据集中随机抽取5 首歌曲,2 组人员对分别使用Unet、Unet-Attention、CNN、RPCA 以及本文方法分离得到的歌声与背景伴奏进行主观评价打分取平均,最后计算男生与女生得分的平均值(MOS),结果如表5 所示。
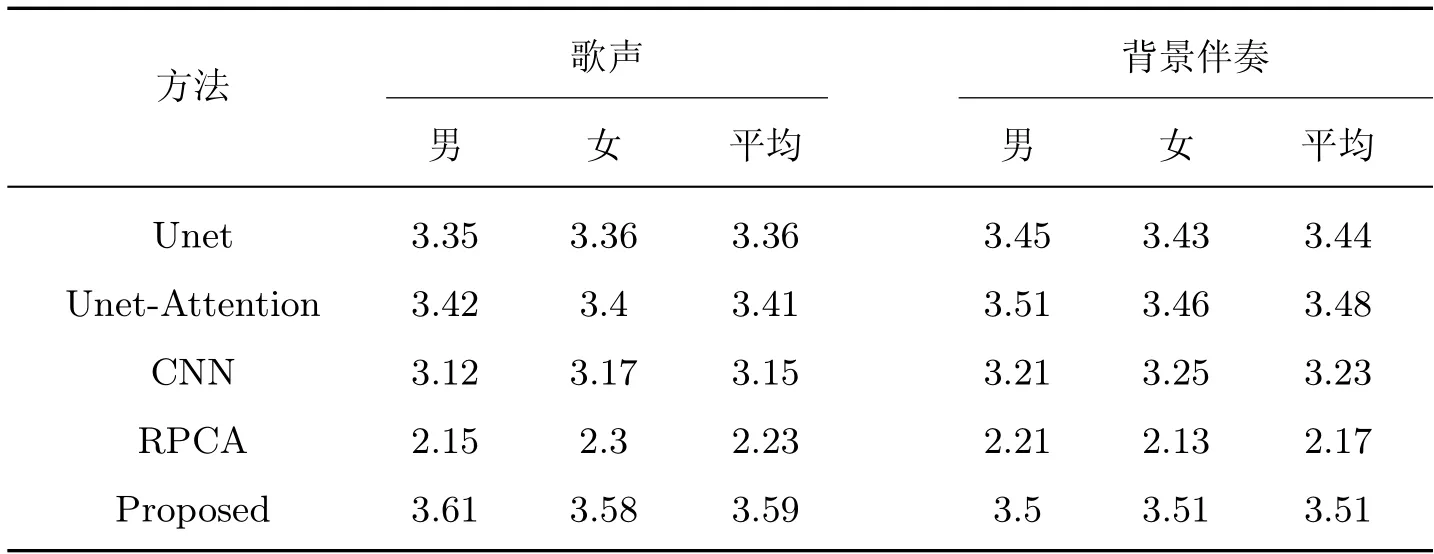
表5 不同方法的MOS 得分对比Table 5 Comparison of MOS scores of diffierent methods
由表5 可以看出,基于深度学习方法分离后的歌声与伴奏的听感都要远优于传统RPCA方法,这也说明深度学习方法的优越性。在基于深度学习的方法中,本文方法的听感得分是最高的,这说明了本文方法能够有效地将歌声与背景伴奏分离开来。但是从听感上来看,对于分离后的歌声依然不够纯净,伴有微小的音乐噪声且包含残留的部分乐器音源。
7.4.5 本文模型与目前部分主流音乐源分离模型的比较
在MUSDB18 数据集上,将本文方法与一些开源的音乐源模型进行了分离性能指标以及分离性能指标中值的比较。对比模型有端到端模型WAVE-U-NET 和Demucs;非端到端模型Open-Unmix。WAVE-U-NET 结构与传统的跳跃连接的卷积编解码器相同,Open-Umix 是基于双向LSTM 网络开发的,Demucs 在WAVE-U-NET 的编解码层加入了GLU 以及在中间传输层添加了双向LSTM 网络。
对比结果如表6 所示。可以看出:所提方法相比WAVE-U-NET 网络,歌声分离指标平均提高了1.394 dB,但是与Open-Unmix 以及Demucs 网络进行比较,歌声分离性能指标不够好。
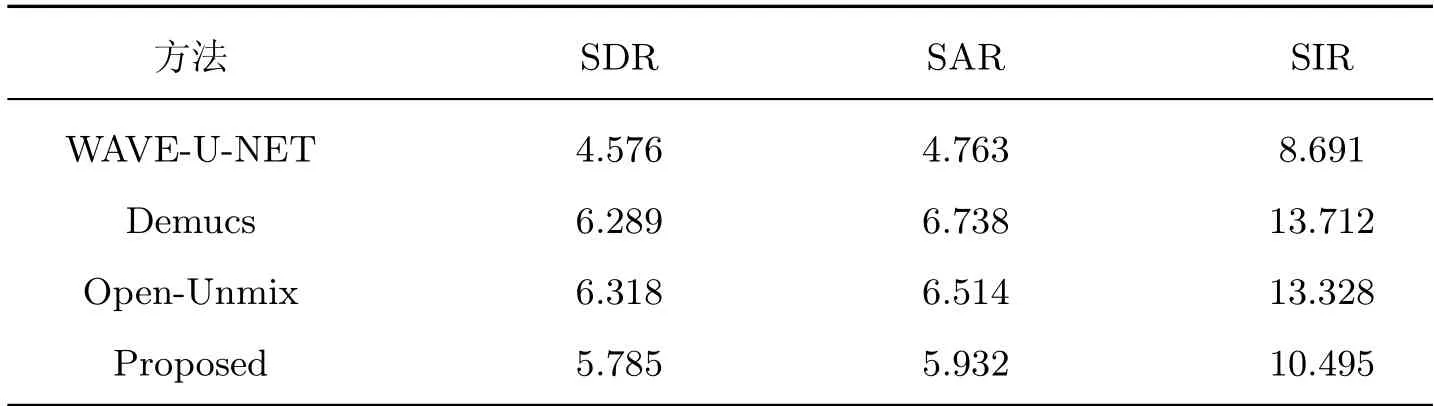
表6 本文方法与部分主流方法性能指标对比Table 6 Comparison of performance indicators between the proposed method and some mainstream methods
7.4.6 网络参数量对比
为了说明所提模型在参数量方面的优势,本节进行了网络的参数量对比,结果如表7所示。

表7 不同网络参数量对比Table 7 Comparison of diffierent network parameters 106
由表7 可以看出,本文所提方法的参数量约为基线网络的1/5,与目前较为主流的神经网络相比,参数量明显减少。根据上述实验可知,相比于基线网络以及端到端的WAVE-U-NET网络,所提方法的分离性能指标有一定的提升;虽然所提方法的分离性能指标不及Open-Unmix 以及Demucs 网络,但是在网络参数量上有着明显优势。可见所提方法在网络参数量大大减少的情况下,仍然有着不错的分离性能,在参数量和分离性能之间取得良好的折中。
7.4.7 语谱图分析
本节比较了歌声语谱图。选取测试集中的Amy_Winehouse_Blues 歌曲前6 s 的片段进行测试,分离歌声语谱图结果如图9 所示。
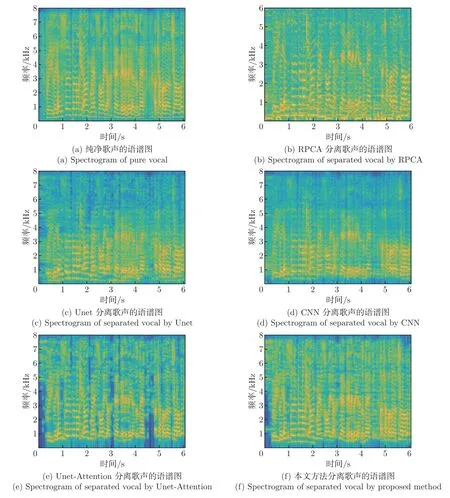
图9 语谱图Figure 9 Spectrogram
由图9 可以看出,RPCA 分离方法进行歌声分离并不彻底,尤其在低频处分离的歌声中含有大量的残余背景伴奏;CNN 则能够较好地将歌声分离开来,Unet 比CNN 则有着更好的歌声分离效果,有效地减少了歌声中残留的背景伴奏和音乐噪声,但是Unet 和CNN 在高频处的歌声分离效果都较差;而Unet-Attention 比Unet 对高频处的歌声精细特征有着较好的恢复能力;本文所提方法分离出的歌声有着更加精细的高频特征,并且保留了更多的歌声谐波特性,能够较好地将歌声恢复出来。
8 结语
本文提出了一种较基线网络歌声分离性能更好的参数量更小的卷积神经网络,提出了一种密集门控线性单元模块,它能够很好地对语音的时序信息进行获取和传递,并且通过块间密集相加的方式在减少参数量的同时,增强了网络对语音上下文信息的聚合,其中还结合了扩张卷积以便让网络能获得更多的局部特征。本文将注意力门控机制引入网络的跳跃连接部分,解决了通道连接没有考虑到低级特征与高级特征之间的语义差距而使得网络在学习出现差异的问题,进一步加强了网络对底层低级特征的利用。本文还提出了一种压缩激励残差分组扩张卷积模块,使网络能够自适应学习不同通道的重要特征。
在CCmixter 数据集和MUSDB18 数据集上的实验也说明了本文方法的性能指标比基线网络的高,参数量却只有基线网络的1/5。相比于Open-Unmix 以及Demucs 网络,虽然分离性能指标略有下降,但是网络参数量要小很多。可见,本文提出的网络在歌声分离性能和参数量之间取得了较好的折中。
猜你喜欢
数学物理学报(2022年4期)2022-08-22
北京航空航天大学学报(2021年9期)2021-11-02
高技术通讯(2021年3期)2021-06-09
中学生数理化·高一版(2021年2期)2021-03-19
科学(2020年5期)2020-11-26
电子制作(2019年11期)2019-07-04
中央民族大学学报(自然科学版)(2018年3期)2018-11-09
北京航空航天大学学报(2018年1期)2018-04-20
舰船电子对抗(2016年5期)2016-12-13
航天器工程(2014年5期)2014-03-11
