
贝叶斯基准剂量统计软件*
2023-11-30 01:40王青青彭雯洁周小林余红梅
中国卫生统计 2023年5期
王青青 彭雯洁 崔 靖 张 婷 周小林,3△ 余红梅,4,5△
【提 要】 目的 本文通过对贝叶斯基准剂量估计软件(bayesian benchmark dose,BBMD)进行剖析,为进一步理解和掌握该软件奠定一定的理论基础。方法 从特性、功能以及运行3个方面对BBMD软件进行了介绍,以连续性剂量-反应模型为例结合中国辐射防护研究院的数据实现了基准剂量估计的分析。结果 BBMD以图形和表格的形式输出模型参数估计、后验概率p值、模型权重、剂量-反应曲线、模型参数相关系数矩阵、基准剂量反应、模型的BMD估计值等结果,与BMDS或PROAST相比,BBMD具有基于最新研究的BMD分析附加功能、计算效率更高、剂量反应建模更加可靠的优点。结论 BBMD可以提供概率估计,极大地满足了当前概率风险评估的需求。
过去几十年里,关于人类健康风险评估中剂量-反应(dose-response)关系的评定,通常采用无可见有害作用水平(no observed adverse effect level,NOAEL)。但传统的NOAEL在评估剂量-反应关系时存在一定缺陷。譬如,结果过分依赖于实验剂量的选择;受样本量大小的影响;NOAEL基于一个点的数据,未考虑到剂量-反应关系的斜率(曲线);当一个实验未能发现NOAEL时,安全阈值剂量只能基于最低可见有害作用水平(lowest observable adverse effect level,LOAEL),然后乘以10倍的不确定系数加以外推;由于不同实验提供的反应水平上的作用剂量未必相同,所以NOAEL在可比性方面存在缺陷[1]。基于NOAEL的缺陷,1984年美国科学家Crump[2]提出了基准剂量估计(benchmark dose,BMD),指引起预定频率的不良健康剂量的统计学下限值。基准剂量估计克服了NOAEL的不足,与NOAEL方法相比,BMD方法具有许多重要优势,但它需要更复杂的回归算法将各种剂量反应模型拟合到输入数据中。因此,有必要利用完善的软件来促进BMD方法的实施。
目前已有两大成熟的软件用于基准剂量的估计,一个是由美国环境保护署于2000年研发的基准剂量软件BMDS(Benchmark Dose Software,2.6.0.1)。另一个软件是PROAST(Programme for Analysing Dose-Response Data),由荷兰国家公共卫生与环境研究所(RIVM)推行,采用R软件编程可应用于各种系统(Windows、Mac OS、UNIX、Linux),并于2014年初更新至最新版本。BMDS和PROAST都有各自的优势,在一些技术细节上也大多不同。譬如,两种软件对剂量-反应模型和连续数据分布的默认假设不同,BMDS默认变量服从正态分布、而PROAST则默认变量服从对数正态分布;BMDS适用于Window系统下,具有良好的操作界面能够分析多种类型的剂量反应关系,包括最常用的计数资料和连续性资料。PROAST不仅可以分析计数资料和连续性资料,还可以分析等级资料。总的来说,这两个软件包都适用于剂量反应分析和推导BMD及其统计下限(lower confidence limit of the benchmark dose,BMDL),然而这两种软件方法都基于概率论的统计方法(即极大似然估计)进行剂量反应模型拟合和参数估计。
2009年美国国家研究委员会(United States National Research Council,NRC)实现了一项里程碑式的工作——发表了《科学与决策:推进风险评估》[3],强调了在风险评估中以概率的形式量化特定风险剂量以支持监管决策的重要性。2014年,世界卫生组织(World Health Organization,WHO)发布了一份关于使用概率框架来协调风险表征方法的指导文件(IPCS 2014)[4]。2015年Fang[5]提出了贝叶斯基准剂量估计(bayesian benchmark dose,BBMD),2018年Shao与Shapiro[6]一同开发了贝叶斯基准剂量估计软件,该软件实现了基于贝叶斯推理的基准剂量估计。
BBMD软件是在BMDS软件的基础上新开发的一款网页版本的贝叶斯基准剂量分析系统。BBMD软件建立在贝叶斯框架上,通过模型参数的先验分布来合并先验信息等特点,使得BBMD系统与当前流行的BMD估计软件(如BMDS/PROAST)有着根本的不同。BBMD除了估计连续数据、计数资料的传统BMD外,同时还能进行批量的BMD分析。它属于开源软件,可以免费使用,网址:https://benchmarkdose.org,或者https://benchmarkdose.com。
BBMD软件介绍
1.特性方面
BBMD包括两个模块,负责计算和数据存储的后端模块和通过web浏览器与用户交流的前端模块。BBMD的内部网站组件是由Python网络框架(django)自动生成的,设计简洁且实用。限制存储在数据库中的个人身份识别信息(personally identifiable information,PII)的数量,用户的电子邮件是BBMD网站中唯一存储的个人身份识别信息。
(1)基本原理:通过马尔可夫链蒙特卡罗迭代拟合生成模型,并产生相应的后验样本,用户给定基准剂量反应后可估计BMD。
(2)分布类型:BBMD软件根据数据类型分别提供了8种模型。计数资料和连续资料一共16种模型分布。
计数资料的8种剂量-反应模型分布:
①Quantal-linear model:f(dose)=a+(1-a)×(1-e-b×dose);0≤a≤1,b≥0

③Probit model:f(dose)=Φ(a+b×dose);50≤a≤-50,b≥0
④Weibull model:f(dose)=a+(1-a)×(1-e-b×doseg);0≤a≤1,b≥0,g≥restriction
⑤Multistage-2ndmodel:f(dose)=a+(1-a)×(1-e-b×dose-c×dose2);0≤a≤1,b≥0,c≥0

0≤a≤1,b~Uniform(restriction,15),-5≤c≤15
⑦LogProbit model:f(dose)=a+(1-a)×Φ(c+b×log(dose));
0≤a≤1,b~Uniform(restriction,15),-5≤c≤15

0≤a≤1,b~Uniform(restriction,15),-5≤c≤15,0≤g≤1
连续变量的8种剂量-反应模型:
①Linear model:f(dose)=a+b×dose;a≥0,b~Uniform(blower,bupper)②Power model:f(dose)=a+b×doseg;a≥0,b~Uniform(blower,bupper),g≥restriction


⑤Exponential 2 model:f(dose)=a×eb×dose;a≥0,bI~Unifrom(0,50);bD~Uniform(-50,0)
⑥Exponential 3 model:f(dose)=a+eb×doseg;
a≥0,bI~Unifrom(0,50);bD~Uniform(-50,0),g≥restriction
⑦Exponential 4 model:f(dose)=a×[c-(c-1)×e-b×dose];a≥0,b≥0,c≥0
⑧Exponential 5 model:f(dose)=a×[c-(c-1)×e-(b×dose)g];a≥0,b≥0,c≥0,g≥restriction
其中,参数“a”表示背景剂量水平下的效应;参数“b”表示效力,bI表示数据存在上升趋势、bD数据存在下降趋势;数据存在上升趋势时blower=0、bupper=[(效应指标最大最小值之差)/(效应指标最大最小值所对应的剂量水平之差)]×5;数据存在下降趋势时blower=[(效应指标最大最小值之差)/(效应指标最大最小值所对应的剂量水平之差)]×5,bupper=0;参数“c”表示渐进项;参数“d”表示剂量;参数“g”表示与剂量有关的功率参数,其中restriction为用户定义值可取0、0.5、1。
2.功能方面
BBMD软件可以对连续型变量、计数资料进行贝叶斯基准剂量估计、概率参考剂量估计以及处理批量的BMD分析。BBMD软件输出结果以文本和图形两种形式呈现,输出内容包含相关的统计学描述、原始剂量响应数据和90%置信区间的拟合曲线图等。
3.运行/操作方面
(1)BBMD软件基本分析步骤
①输入一个剂量-反应数据集、设定马尔可夫链蒙特卡罗算法和选择剂量-反应模型;
②完成第一步的操作后系统会进行模型拟合并生成模型参数的估计值、拟合分布图、并进行交叉模型的比较;
③BMR设定、先验模型权重的设定;
④输出结果。操作步骤如图1。

图1 BBMD软件基本分析步骤流程图
(2)BBMD软件选项卡
注册并登录个人账户后,点击右上角的“New analysis”选项,进入分析编辑界面,会话界面有9个选项卡。
①Dataset:Dataset子窗户包括:dataset type和dataset两个小部分。Dataset type包含连续型变量、计数资料两大类,每一大类又分别细分为个体数据、汇总数据;dataset(数据录入模块),包括剂量(dose)、研究对象(n)、发病率(incidence),单击save dataset,可以保存当前数据集。数据集保存成功后,数据将以图形和表格的形式显示在子对话框的右边。
②MCMC setting:包含四个子模块,迭代次数(markov chain iterations/per chain)、马尔可夫链数(number of markov chains)、预热百分比(warmup percent,%)、种子数(random seed)。
Markov chain iterations/per chain指MCMC链的长度,即每个MCMC链中的后验样本的数量,默认值为30,000,允许范围:10000到50000之间的任意整数。Number of markov chains,要采样的马尔可夫链数,默认值为1,允许的范围为1~3条。warmup percent,将放弃每个马尔可夫链中的样本百分比,默认值为50%,允许的范围为10%~90%。random seed,MCMC算法中使用的随机种子数,随机生成允许范围:0~99,999。
根据迭代次数、链数、预热百分比可以算出最终的后验样本数:
30000×1×(1-50%)=15000
最后单击save run setting,保存MCMC设置。
③Model settings:包含create a model和add standard models两大模块,其中create a model包含model type和model name两个小模块。model type中有8个模型类别可供选择,对于具有power参数的模型,需要对power选择一个限制值。当前系统中有5个选项:0、0.25、0.5、0.75和1。
④Execute model fit:模型运行的3个先决条件:数据创建完毕、MCMC设备已保存、至少选择了一个模型。
⑤Model fit result:模型运行后,输出模型的相应结果。
⑥Risk at dose:根据第一步dataset中设定的dose的剂量组,分别估计每个剂量组的风险。
⑦BMD estimates:设定BMR的值(通常为5%、10%),分别估计BMD、BMDL。
⑧RfD estimates:运用BMD estimates估计得到BMDL后,根据BMDL估计参考剂量(reference dose,Rfd)值。
⑨Report:通过Email以word、excel格式将结果传送至用户。
应用实例
1.数据来源
目前国内关于运用BBMD软件估计BMD的相关报道较少,本文利用中国辐射防护研究院山西省洪洞县数据,研究2-羟基芴与红细胞分布宽度(red cell volume distribution width,RDW)之间的剂量-反应关系。
在该数据中,选取部分成年居民的暴露信息,将2羟基芴作为暴露变量(dose),红细胞分布宽度标准差(RDW-SD)作为反应变量(response)。选用BBMD软件估计2-羟基芴与红细胞分布宽度之间的剂量-反应关系。详见表1。

表1 暴露资料分布表
(1)数据输入
单击dataset选项卡,选择continuous(individual)数据类型,依次输入dose和response的数值。
(2)MCMC设定
默认系统的设定:迭代次数30000次,预热百分比50%,马尔可夫链1条,随机种子数21624。
(3)模型的选择
单击add standard models后,系统默认选择连续变量的8个标准模型。
(4)基准反应的设定
在 BMD estimation method里选择混合方法估计(Hybrid method(tails)),adversity measure框里选择对照组百分比(control group percentile),adversity value框里输入0.56,Benchmark response value设置为0.1。最终BBMD软件根据模型权重对8个模型进行权重均衡后计算2-羟基芴的健康指导值[7]。
2.结果呈现
BBMD系统以图形和表格的形式输出相应的结果。本文演示了连续变量的剂量-反应关系,软件输出如下结果:模型参数估计、后验概率p值、模型权重和剂量-反应曲线(图2)、模型参数的分布、后验样本描绘、模型参数相关系数矩阵、基准剂量反应(图3);BMD估计的概率分布图(图5)和模型的BMD估计值、额外风险和附加风险值(图6)。

图2 模型拟合结果

图3 模型参数分布图

图4 模型估计结果
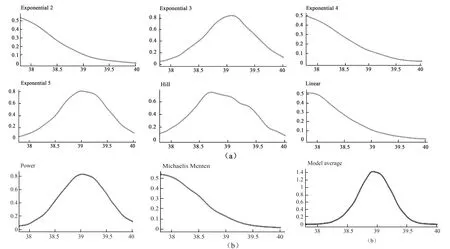
图5 模型概率分布函数图

图6 风险概率分布函数图
2-羟基芴暴露发生红细胞分布宽度偏低的8个模型拟合的BMDL分别为0.31 μmol/mol、4.40 μmol/mol、0.18 μmol/mol、4.32 μmol/mol、2.34 μmol/mol、4.72 μmol/mol、0.25 μmol/mol、0.28 μmol/mol;BMD分别为0.45 μmol/mol、7.01 μmol/mol、0.38 μmol/mol、6.85 μmol/mol、6.51 μmol/mol、7.08 μmol/mol、0.40 μmol/mol、0.42 μmol/mol。通过对8个模型进行权重均衡,最终得到的BMDL的平均值为1.80 μmol/mol,BMD的平均值为6.91 μmol/mol。详见图4。
讨 论
本文通过特性、功能以及运行3个方面对BBMD软件进行了介绍,利用中国辐射防护研究院收集的数据,利用BBMD软件实现了基准剂量估计的分析,使读者对BBMD有一个初步的认识,对理解和掌握该软件的基本操作及其性能有重要的意义。
迄今为止,已有不少软件可以进行基准剂量估计。譬如,世界公认的两大基准剂量估计软件BMDS和PROAST,还有@Risk[8]等其他专业软件。BBMD属于一种新兴的基准剂量估计软件,它提供了一种通过先验分布整合先验信息的方法建模并进行后续的基准剂量估计,这对于提高数据的质量,建模的可靠性和鲁棒性具有一定帮助,同时也可能是风险评估人员唯一可用的方法。与其他基准剂量估计软件(如BMDS/PROAST)相比,BBMD软件的亮点在于:第一,具有基于最新研究的BMD分析附加功能。第二,将模型拟合和BMD分析的步骤解耦,使得系统计算效率更高[5-6]。第三,允许更大的分析灵活性。最重要的是,BBMD采用贝叶斯估计,结合先验信息,使剂量反应建模更加可靠,并且可以为剂量反应评估中重要的参数提供分布估计,这极大地促进了概率风险评估的发展[9-10]。因此,关于剂量-反应关系评定方面,BBMD是一种有效的替代工具,并且BBMD软件代表了剂量-反应评估领域的最新科学方法和技术[5,7]。
不同于其他基准剂量估计软件采用极大似然法估计模型参数,BBMD基于贝叶斯理论框架,通过模型参数的先验分布合并先验信息进行模型参数估计[6,11-12]。BBMD不局限于单一模型结果,而是以各模型的后验概率为权重,对单一模型的预测值进行加权平均得到一个综合的模型估计值。BBMD估计结果合理之处在于,将不同模型的不确定性考虑在内,待估计量是基于备选模型后验概率的加权平均,能给予拟合良好的模型更大的权重,拟合不好的模型较小的权重。此外,BBMD可以通过设置不同的先验概率分布,将模型选择的外部信息结合到数据分析中,既考虑了模型的先验信息,又提供数据的样本信息,分析更具科学性,在一定程度上可消除剂量-反应关系模型的不确定性。再者,包括美国国家研究委员会、WHO等机构均提倡运用贝叶斯框架协助概率风险评估[3-4]。除此之外,BBMD软件还在不断更新与升级,它的开发是为了支持人类健康风险评估中剂量-反应的估计,促进BMD方法的实现。相信在未来,会有越来越多的科研工作者将贝叶斯基准剂量估计应用于危险度评价,BBMD软件也将成为基准剂量估计的主流软件。
猜你喜欢
工程数学学报(2020年3期)2020-07-06
成都信息工程大学学报(2019年3期)2019-09-25
长治学院学报(2019年2期)2019-07-24
自动化学报(2017年5期)2017-05-14
数理化解题研究(2017年4期)2017-05-04
雷达学报(2017年6期)2017-03-26
铁道通信信号(2016年6期)2016-06-01
电子器件(2015年5期)2015-12-29
探测与控制学报(2015年4期)2015-12-15
东南法学(2015年2期)2015-06-05
