
基于密集特征推理及混合损失函数的修复算法
2023-11-24 01:40李海燕尹浩林李鹏周丽萍
华南理工大学学报(自然科学版) 2023年9期
李海燕 尹浩林 李鹏 周丽萍
(1.云南大学 信息学院,云南 昆明 650500;2.云南大学 云南大学学报(自然科学版)编辑部,云南 昆明 650500)
图像修复旨在利用合理内容填充缺失区域。传统修复方法大多基于图像块匹配,如Efros等[1]提出了纹理合成方法,其在未缺失图像块中寻找与缺失部分最相似的信息补全缺失区域。该方法仅使用简单的像素块迁移,因此修复处与背景衔接不自然。Criminisi 等[2]提出样例匹配方法,先对缺失区域的像素点分级,优先填充信息丰富的区域,逐步缩小填充范围至完成修复。该方法能修复小面积缺失区域,但修复较大面积的缺失时存在结构失真。Barnes 等[3]提出Patch Match 最近邻样例块匹配方法,将搜索填补范围设定在缺失区域的邻近区域,极大减小了匹配区域的范围,但未能解决修复大面积缺失的结构混乱问题。He等[4]提出统计匹配块的偏移量,得出拥有主导偏移量的匹配块,再用该匹配块引导完成修复。该方法极度依赖区域的相似性,当缺失区域变大时,由于先验信息不足,无法找到与待修复区域相匹配的像素块,因此修复的结构和纹理缺乏完整性和真实性。
为解决传统修复方法的不足,学者们开始探索基于深度学习的修复算法。Mao 等[5]提出基于跳线连接的编码-解码网络修复算法,对细小的受损区域能产生合理的语义内容,但修复大面积缺失区域时,由于修复的数据维度较高,导致先验不足,修复结果出现纹理模糊。Köhler 等[6]提出学习图像块映射推断掩膜区域的修复算法,但该算法同样在修复大面积缺失时因不能捕获远距离背景信息而产生结构失真。为有效修复大面积缺失,Pathak 等[7]提出基于上下文编码器的无监督视觉特征修复算法,可修复较大面积的规则区域,但修复随机不规则缺失区域的性能较差。Li等[8]对上下文编码器算法进行改进,提出一种高效的人脸修复方法以期修复不规则缺失,但是该方法仅能用于背景单一的图像修复,修复纹理细节丰富的自然图像时,修复效果较差。李海燕等[9]提出基于混合空洞卷积的修复方法,扩大了修复网络的信息感受野,能有效完成大面积规则缺失区域的修复,但是修复随机不规则缺失时,不能很好保持细节纹理与全局的一致性。Zhao等[10]以掩码图像为先验信息指导网络进行多元化修复,它主要由条件编码模块、流形投影模块、生成模块组成,以生成多元化图像,但存在结构连贯性差等问题。
对于不规则缺失修复,Cao 等[11]提出两阶段的草图来修复人造场景的图像,刘微容等[12]提出一种多级解码网络利用多尺度信息生成视觉上合理的结果,但这些算法同样存在结构不连贯等问题。Liu 等[13]提出用部分卷积代替常规卷积,该方法不依赖于修复位置或场景复杂度,对不规则缺失有较好的修复效果;Zheng等[14]提出多元图像修复算法,能修复各种形状的缺失图像并得到较合理的结果;Li等[15]添加结构图辅助算法对不规则孔洞进行逐步重建;Guo等[16]以双向连接的形式进行结构约束的纹理合成和纹理引导来重建缺失区域的结构,该算法可生成合理的结构和纹理。然而这些不规则修复算法大都使用批量归一化,依赖大批量进行迭代,在使用小批量输入训练时效果较差。Li 等[17]提出的循环特征推理算法对大型不规则洞孔中心有极强的把控性,能有效修复大型洞孔的完整结构,获得清晰的纹理,然而其连接方式不能有效传递特征信息,特征利用率低;此外,该算法使用单一损失函数计算输出图像与原图的差异,当不规则破损区域面积达30%及以上时,其修复性能急剧下降。
综上所述,现有算法在修复大面积不规则缺失时,存在特征利用率低、修复结果结构连贯性差等不足。为解决这些不足,本文提出基于密集特征推理(DFR)及混合损失函数(ML)的图像修复算法。该方法首先将破损图像输入至特征推理(FR)模块进行边缘重建和内容填充;随后将该模块的输出与初始输入进行通道合并后输入至下一个FR 模块,所有FR 模块采用密集连接,以此对特征信息反复利用,其中包含一个传播一致性注意力机制(PCA)用于将缺失部分信息与未缺失部分信息进行一致性匹配,并使用组归一化(GN)[18],利用小批量进行迭代训练;最后将修复后的特征图经上采样后得到修复图像,使用ML 对其结构进行引导以接近真实图像结构。
1 算法结构
本文提出的基于DFR 及ML 的修复算法如图1所示。首先将待修复图像输入至DFR模块,该模块使用多个FR模块进行推理,每个FR模块都使用前置FR 模块推理出的特征信息来修复图像;其次使用ML 比较输出图像与真实图像的差异以引导网络生成高质量图像。

图1 本文所提算法的结构示意图Fig.1 Schematic diagram of the proposed algorithm structure
1.1 密集特征推理模块
Huang 等[19]提出DenseNet,即任何网络层都可以和所有后续层进行直接连接。第l层接收前面所有层的特 征映射x0,x1,…,xl-1作 为输入:xl=Hl([x0,x1,…,xl-1]),其 中[x0,x1,…,xl-1] 是 在0,1,…,l-1 层中产生特征映射的连接。这种密集连接模式因为不需要重新学习冗余的特征映射,所以比传统的卷积网络[20]需要的参数更少。除了高效外,DenseNet 改进了整个网络的信息流和梯度,易于训练。其每一层都可以直接从损失函数和原始输入信号中访问梯度,有助于训练更深层次的网络架构。
借鉴DenseNet的思想,DFR模块将多个级联的特征推理模块进行密集连接,提升特征复用率,每个推理模块修复时能够充分利用前置推理模块填充的特征信息,以此提高修复性能,如图1所示。下面详细介绍DFR模块中的各个部分。
1.1.1 特征推理模块
FR模块建立在编码解码结构上,借鉴U-Net[21]的思路,使用跳线连接桥接编码层和解码层。其中编码器由部分卷积[13]与标准卷积组成,解码器由标准卷积组成,另外包含一个传播一致性注意力机制,如图2所示。
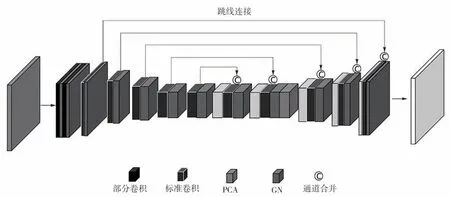
图2 FR模块Fig.2 FR module
FR 模块的目的是用尽可能高质量的特征值填充已损坏的区域。高质量的特征有利于后续特征推理模块填充内容。
1.1.2 传播一致性注意力机制
现存注意力机制[17]不能够较好匹配缺失区域像素块与已知区域像素块,容易导致细节纹理扭曲,精密度低,为解决此问题,借鉴Li等[17]提出的注意力机制KCA,在其中引入注意力传播,提出传播一致性注意力机制(PCA),其计算流程图如图3所示。

图3 PCA计算流程Fig.3 PCA calculation process
首先计算前景区域与背景区域的相似度分数s:
式中,f(x,y)表示前景在(x,y)处的像素值,b(x',y')表示背景在(x',y')处的像素值。
因前景特征块偏移时,相应的特征块也进行相同的偏移,会造成前景区域与背景区域匹配不一致,因此设置注意力传播的卷积核进行上下与左右传播,以增加匹配一致性。新的注意力分数为
式中,k为卷积核的大小。新的注意力分数使修复网络拥有更丰富的梯度,提升了修复细节的一致性。
根据相似度的值,用softmax 函数对其进行归一化,得出注意力分数:
式中,a'为softmax函数沿通道方向计算在位置(x,y)处的注意力分数,表示PCA 模块产生的第i'次的注意力分数。
将上一个PCA模块产生的最终分数与本次特征推理的PCA 计算的注意力分数加权组合得到最终得分:
式中,λ为可学习的参数,ai'-1为上一个PCA 模块计算的注意力分数。
最后利用反卷积进行特征重建:
特征图重建后,输入到注意力机制的特征图F*和重建后的通道合并,卷积得到最终结果:
式中,ϕ为逐像素卷积,|·|表示通道合并。
1.1.3 特征合并
特征图经所有FR 模块推理后,若仅使用最后一个推理模块输出的特征图,则会出现梯度消失、特征图信息损坏等问题。因此,利用RFR[17]中的方法,将所有特征推理模块合成的特征图进行合并,即输出特征图中的值仅根据对应位置已被填充的值(被填充后的像素值为有效值,其对应的掩膜值为1)进行计算,用Fi'表示特征推理模块产生的第i'张特征图,Mi'表示Fi'对应的二进制掩膜。输出特征图F的特征值可表示为
式中,fi'(x,y,z)为第i'张特征图在位置(x,y,z)处的特征值,mi'(x,y,z)为其对应的二进制掩膜,N为特征图的输入数量。
1.1.4 组归一化
现有修复算法大都使用BN 进行归一化,需大批量数迭代才能获得较好的修复效果,但大批量训练需要较高的GPU显存。为解决此问题,提出使用组归一化(GN)[21]替换BN进行归一化。该归一化方式不受输入批量数影响。
GN 将输出特征图通道分组并在每个组内将特征值归一化:
式中,ε为常量,Si''为像素集合,m为集合的大小。Si''定义为
式中,G为组数,默认G=32,C/G表示每组的通道数,表示索引i''和k'在同一组通道中,沿通道轴C轴按顺序分组。
本文利用GN,可在使用小批量数训练时达到优异的效果,并且训练模型的收敛时间也不会增加。GPU一般来说显存越高则价格越贵,使用该归一化方式可以使用小显存的GPU,节约研究成本。
1.2 混合损失函数
结合亮度、对比度与结构的指标,即结构相似度损失函数(SSIM)可更好引导修复网络生成符合人类视觉感知的内容[22],结构连贯性和合理性也更高。因此提出结合l1损失函数与SSIM的优点组成混合损失函数(ML)。l1损失函数定义为
式中:p为像素值的索引;P为像素块的集合;yreal(p)与ypred(p)为以p为索引的原图与合成图像的对应像素值;N'为像素块集合的大小。SSIM 可以让修复网络产生符合人眼视觉特性的图像,像素p点的SSIM表示为
式中:μypred与μyprede分别为原图与预测图像的平均值;σyreal与σypred分别为原图与预测图像的标准差;σyrealypred为协方差;C1与C2为常量,避免分母为零造成的不稳定性。因局部求SSIM 指数的效果好于全局,故用标准差为1.5、加权窗口大小为11 × 11的高斯滤波器进行卷积,得到SSIM指数映射的像素矩阵,最后对整个SSIM 像素矩阵求均值得到最终结果。SSIM在像素p点的损失函数可写为
本文所提算法结合l1损失函数与SSIM 的优点组成混合损失函数ML,对比网络输出图像与原图的差异:
式中,γ为权重,设为0.25。
此外,本文所提算法还使用了其他图像修复常用的损失函数:采用感知损失函数(perceptual loss)与风格损失函数(style loss)比较预测图像与原图的深度差异:
式中,ϕpooli'为第i'层池化层,Hi'、Wi'、Ci'分别为池化层第i'层输出特征图的高、宽及通道数,gt代表标签值(原图),pred代表预测值(预测图像),style代表风格损失,perceptual代表感知损失。
Lvaild与Lhole使用l1损失函数分别计算掩膜区域与非掩膜区域生成图像ypred和原图yreal之间的差值:
式中,m'为二进制掩膜(洞孔处像素值为0),⊙为点乘。
本文所提算法用Total Variation Loss(Ltv)加强生成图像的空间平滑性:
最后,总的损失函数为
式中,各参数设置为λstyle=120,λpreceptual=0.05,λtv=0.1,λvaild=1,λhole=6。
2 实验结果与分析
使用国际公认的Paris StreetView 巴黎街景数据集和CelebA 人脸数据集验证本文所提算法的有效性,前者训练集有14 900 张,测试集有100 张,主要由城市建筑构成。后者训练集有180 000张左右,由人脸构成,另外选取100张图像作为测试集。
训练时设置输入批量为2,输入图像大小为256 × 256,优化器函数为Adam。学习步长为2 ×10-4,训练到一定次数时进行微调,微调时将学习步长设置为5 × 10-5。在训练Paris StreetView 巴黎街景数据集时,迭代总次数为600 000,迭代到400 000次进行微调;在训练CelebA人脸数据集时,迭代总次数为500 000,迭代到350 000次进行微调。
所有实验环境均使用Python3.75、Pytorch 1.7、Windows10 操作系统、CPU i9-10900k 和GPU 24GB NVIDIA RTX3090。
2.1 对比实验
将本文所提算法与PIC[14]、PRVS[15]、RFR[17]、CTSDG[16]对比,验证其有效性。PIC 是2019 年Zheng 等[14]提出的基于并行生成对抗网络的不规则洞孔修复算法;PRVS是2019年Li等[15]提出的基于视觉结构的渐进式重建方法,对大规模洞孔有较好的修复效果;RFR 是2020 年Li 等[17]提出对图像特征循环推理,逐步提高修复能力的修复算法;CTSDG 是2021 年Guo 等[16]提出的一种双向结构,通过结构约束纹理合成和纹理引导结构重建,以构建精细的细节和合理的结构。
设置了小型到超大型的各种掩膜对比实验,掩膜率范围分别为30%~40%、40%~50% 和50%~60%,修复结果如图4和图5所示。

图4 人脸缺损图像对比Fig.4 Comparison of facial defect images

图5 街景缺损图像对比Fig.5 Comparison of street view defect images
图4(a)中,输入图像为掩膜率30%~40%的缺损图像,PIC、PRVS 和CTSDG 因使用BN 进行归一化,所以在小批量训练时,估算不够准确,导致修复效果较差;RFR算法使用循环特征推理将破损图像逐步修复,但是每个推理模块仅使用前一个推理模块的推理信息,没有对前面所有的信息进行复用,且没有充分利用特征信息,此外还由于其注意力机制与损失函数的设置欠佳,故该算法在细节的精细修复上还有较大欠缺;本文所提算法能复原出清晰合理的结构和完整的人脸五官。
图4(b)中,输入图像为掩膜率40%~50%的缺损图像,PIC 算法因错误填充,导致修复结果的眼睛较模糊;PRVS算法能够隐约填充出眼睛的结构,但未填充出正确的内容,修复得仍不够彻底;RFR算法能还原眼睛纹理,但因其在纹理细节上的修复不够恰当,所以在眉毛处出现小范围的纹理扭曲;CTSDG修复结果的双眼中间处较为模糊;本文所提算法的修复结果没有模糊感,口鼻眼纹理与全局具有较高的一致性。
图4(c)中,输入图像为掩膜率50%~60%的缺损图像,因PIC 在大面积修复上的困难,其修复的结果整体很模糊;PRVS 修复结果在下巴处出现较多重叠和大量冗余波纹;RFR算法虽只呈现出少量波纹,但波纹轮廓明显,几乎不能还原人脸细节,很难分辨鼻子与嘴;CTSDG 算法基本能修复出五官,但纹理出现较多扭曲;本文所提算法的修复结果语义完整,细节较精细。
图5(a)中,输入图像为掩膜率30%~40%的缺损图像,PIC的修复结果出现了明显的错误填充,墙壁处显然不符合全局结构;PRVS与RFR算法在墙面的填充结果较模糊,结构也不合理;CTSDG算法修复的墙面存在较多的失真现象;相对而言,本文所提算法能用合适内容修复缺失区域,与背景信息衔接较自然。
图5(b)中,输入图像为掩膜率40%~50%的缺损图像,PIC 算法在上方墙壁处填充了冗余特征,纹理的整体一致性差,下方的纹理也非常模糊;PRVS、RFR、CTSDG 修复的下方墙壁均不清晰,纹理错乱;本文所提算法修复的墙壁区域结构较连贯,符合人眼视觉特性。
图5(c)中,输入图像为掩膜率50%~60%的缺损图像,PIC 对大面积的缺失修复出现了较为严重的错误填补,结构凌乱;PRVS算法仅能修复出上方窗户的大概轮廓,左下方出现了一些噪声;RFR算法在窗户内填充的纹理不够合理,下部出现纹理重叠;CTSDG算法未能呈现窗户的明晰结构;本文所提算法能够得到较多的清晰纹理细节和完整结构。
为客观比较本文所提算法与对比算法的性能,对各种算法的平均峰值信噪比(PSNR)、平均结构相似度(SSIM)、均方误差(MSE)、弗雷歇距离(FID)及学习感知图像块相似度(LPIPS)进行对比,表1 展示了在CelebA 与Paris StreetView 测试集上不同掩膜占比的修复性能指标对比。

表1 本文所提算法与对比算法的定量指标对比Table 1 Comparison of quantitative indicators between the proposed algorithm and comparison algorithms
从表1可看出,本文所提算法的客观指标高于对比算法,说明本文所提算法的修复性能优于对比算法。
图6 与图7 主要对比了算法复杂度,其中图6对比了各个算法的推理时间,可以看出本文所提算法的程序执行时间较低,效率较高。图7对比了各个算法的模型参数量,可以看出本文所提算法参数量仍处于较低水平,虽然PIC 算法参数量非常低,但是其修复性能却较差。

图6 本文所提算法与对比算法推理时间对比Fig.6 Comparison of inference time between the proposed algorithm and comparison algorithms

图7 本文所提算法与对比算法模型参数量对比Fig.7 Comparison of the number of model parameters between the proposed algorithm and comparison algorithms
2.2 消融实验
消融实验主要比较密集连接、PCA、ML 及GN对修复效果的影响,所有实验均在CelebA 数据集上进行。
(1)密集连接的有效性
图8比较了不使用密集连接与使用密集连接的修复效果,可以看出两者利用同等大小数据集训练时,基于密集连接模式的模型因其能够充分利用特征而重建效果更优。

图8 有无密集连接的效果对比Fig.8 Contrast effect with and without dense connection
(2)PCA的有效性
图9 比较了PCA 与现存注意力机制的修复效果,可以看出现存注意力机制[17]嘴唇与眼睛处出现失真。本文所提算法使用了PCA,合成的嘴唇及眼睛的纹理细节更加能够与整体保持一致性。

图9 PCA与现存注意力机制的效果对比Fig.9 Comparison of PCA and existing attention mechanism
(3)ML的有效性
图10比较了使用ML与单一损失函数的修复结果。未使用混合损失函数的修复结果中,嘴唇处修复的结果较扭曲,上嘴唇和下嘴唇衔接较差。本文所提算法使用了混合损失函数ML,在嘴唇处的结构连贯性更好。

图10 单一损失函数与ML的效果对比Fig.10 Comparison effect of a single loss function and ML
(4)GN的有效性
图11 比较了同等批量数训练时BN 与GN 两者的效果,在鼻子与嘴唇处可以明显看出本文所提算法使用GN时效果优于BN。

图11 BN与GN的效果对比Fig.11 Contrast effect of BN and GN
表2 定量对比了消融实验的PSNR、SSIM、MSE、FID、LPIPS等指标。综合这些指标可以看出密集连接、注意力传播、混合损失函数以及组归一化改善了网络的修复性能。

表2 消融指标对比Table 2 Comparison of ablation metrics
3 结论
本文提出一种基于DFR 及ML 的修复算法,首先将待修补图像输入至密集连接的FR 模块,逐步修复破损图像,并对特征多次重复使用,随后将所有FR 模块输出图像进行特征合并,上采样得到修复图像,最后使用ML 计算生成图像与原始图像的差异。与现有的4种经典同类算法进行定量与定性对比,结果表明本文所提算法在修复复杂场景的大面积不规则缺失时,修复的结果结构连贯性更好,纹理细节更能与全局保持一致。
猜你喜欢
艺术家(2023年8期)2023-11-02
导航定位学报(2022年5期)2022-10-13
小哥白尼(军事科学)(2022年2期)2022-05-25
中国体视学与图像分析(2021年3期)2021-11-24
软件(2020年3期)2020-04-20
红领巾·萌芽(2019年8期)2019-08-27
摄影之友(影像视觉)(2018年12期)2019-01-28
制造技术与机床(2017年10期)2017-11-28
Coco薇(2017年8期)2017-08-03
科技资讯(2016年21期)2016-05-30
