
椭圆曲线与自适应DNA编码的混沌图像加密算法
2023-11-22 01:19肖定汉禹思敏王倩雪
中国图象图形学报 2023年11期
肖定汉,禹思敏,王倩雪
广东工业大学自动化学院,广州 510006
0 引言
随着计算机网络的飞速发展,数字图像作为信息传输的重要载体之一也在广泛地通过互联网进行传输。图像应用在国家行政、军事国防和商业情报等领域中可能包含一些敏感的隐私信息,在其传输过程中必须要考虑图像安全保密的问题,因此越来越多的研究人员加入了对图像加密算法的研究(Ghadirli等,2019)。
Fridrich(1998)提出图像加密方案应该由两个过程的迭代组成:置换和扩散。置换具有随机分离相邻图像像素的特性,而扩散可以将图像中的微小变化传递到密文图像的所有像素。混沌系统具有遍历性、对初值的敏感性和长期不可预测性等特点(禹思敏 等,2016),许多学者将之应用到图像加密算法的设计中。例如,在置换算法设计方面,有学者提出可以将混沌映射生成的伪随机序列作为密钥对图像进行行列置换(罗海波 等,2018)、块置换(Khan 和Ahmad,2019)与像素级置换(周辉 等,2021);在扩散算法设计方面,梁锡坤等人(2019)将混沌密钥矩阵与像素矩阵进行多轮非线性变换并应用取整运算来实现灰度加密。Hua 等人(2019)使用高效加扰来分离相邻像素,并采用混沌序列随机顺序替换将纯图像中的微小变化传播到密码图像的所有像素。
为了进一步提高图像加密系统的有效性和安全性,还有学者提出将混沌图像加密算法与各个领域的新技术相结合。Chai等人(2020)提出一种将压缩感知技术与混沌结合的图像加密算法,将彩色图像三色分量稀疏化,使用混沌序列对密文进行双随机像素扩散。Yang 等人(2021)提出了一种将哈希散列算法与DNA(deoxyribonucleic acid)编码序列结合的图像加密方案,用散列值建立明文和密文的耦合关系,再分解明文进行加扰与DNA编解码。
这类算法使用相同的密钥加密和解密信息,为了抵抗选择明文攻击往往需要算法密钥或加密过程与明文信息相关,这种一次一密的加密模式意味着每次通信之前需要先将相关密钥通过秘密信道传输给通信对象,随着通信对象与频率的增加,需要保管与传输的密钥数量也会增加,此外,密钥的高频传输也会增加秘密信道暴露的风险。
针对上述问题,有些学者提出将椭圆曲线密码学(elliptic curve cryptography,ECC)与混沌对称加密相结合。椭圆曲线公钥加密是一种非对称的加密方式,基于离散对数难解问题产生公私密钥对,公钥对外公开使用,私钥由自己妥善保管,由私钥可以计算公钥,而根据公钥不能逆推得到私钥。加密时,使用公钥加密,私钥解密。Sasikaladevi 等人(2020)提出一种混合双层超混沌超椭圆曲线的图像加密方案,在第1层中基于超混沌序列进行DNA 编码,在第2层中基于Genus-2 超椭圆曲线进行加密。Ye 等人(2022)提出了一种基于压缩感知和公钥椭圆曲线的双图像加密算法,对明文图像进行离散小波变换(discrete wavelet transform,DWT)处理,然后对量化矩阵进行压缩感知并拼接在一起,最后对新矩阵进行椭圆曲线加密。Liang 等人(2021)提出一种公钥图像加密方法,对明文图像导出的用于产生混沌序列的哈希值进行ECC 加密,然后根据不同位所包含的信息量将明文图像分为5 个平面进行置换—扩散加密后再组合。
基于此,本文提出了一种新的椭圆曲线与自适应DNA 编码的混沌图像加密算法。算法通过椭圆曲线公钥加密与混沌系统的结合,使通信双方不需要传输密钥就能达成密钥共识,并通过DNA 自适应编码的中间密文状态反馈的方式提升算法的抵抗选择明文攻击的能力,最后,密文状态可以自适应同步无需额外传输。
1 相关知识
1.1 椭圆曲线
定义(Koblitz 等,2000)p是一个素数且p>3,在素数p的有限域GF(p)上定义的椭圆曲线指的是所有满足Weierstrass 标准形式方程的点(x,y)再加上一个称为零点或无穷远点的元素O构成的集合Ep(a,b)。具体为
式中,x,y,a,b∈GF(p),a,b是常数且满足条件Δ=4a3+27b2≠0。基于椭圆曲线Ep(a,b)定义一个加法运算,用符号“∔”表示,若椭圆曲线的3 个点同在一直线上,则它们的和为O。假设点P=(xP,yP)和Q=(xQ,yQ)是Ep(a,b)中的点,从上面定义出发可以得到椭圆曲线加法的运算规则:
1)O为加法的单位元,对椭圆曲线上的任一点P,有PO=P。
2)点P的负元为P=(xP,-yP),且P(P)=PP=O。
3)要计算坐标不同且不互为负元的两点P和Q之和,即PQ,如图1(a)所示,连接PQ作延长线与椭圆曲线的新交点的负元R=(xR,yR)即为结果。R(xR,yR)=P(xP,yP)Q(xQ,yQ)的代数计算表达式可由上述定义得到,即

图1 加法运算规则Fig.1 Addition operation rules((a)add:P Q;(b)doubling point:2 P)
式中,λ=
4)要计算点P的两倍,即S=PP=2P,如图1(b)所示,作点P切线与椭圆曲线的新交点的负元S=(xS,yS)即为结果。S(xS,yS)的代数计算表达式为
当椭圆曲线EP(a,b)上存在一点G满足
则所有kG(k=1,2,…,n)构成的集合是Ep(a,b)上的一个循环子群F,点G称为该群的一个生成元,n也称为生成元G的阶。对循环子群F里的任意点T,皆满足
已知系数k和生成元G时容易计算得到点T,而已知点G和点T时欲计算得到系数k则非常困难,这个难解问题也称为椭圆曲线离散对数问题(elliptic curve discrete logarithm problem,ECDLP)(Li 等,2012)。
1.2 DNA编码
DNA 是一种双链结构的高分子化合物,含有4 种碱基:腺嘌呤(A)、鸟嘌呤(G)、胞嘧啶(C)和胸腺嘧啶(T),其中,A 与T 互补,C 与G 互补。一幅原始灰度图像的像素值在0~255 之间,可由8 位二进制数表示,又因为在二进制数中0 与1 是互补的,所以00和11,01和10也对应是互补的,如果用00、01、10、11 分别表示碱基A、G、C、T,那么每一个像素值都对应一条含有4 个碱基的DNA 序列,根据以上的互补规则,DNA 编码规则有8 种(周辉 等,2021),如表1所示。

表1 DNA编码规则Table 1 DNA encoding rules
为了便于DNA 计算在密码学中的应用,对DNA碱基引入了加法运算和减法运算,符号表示为“⊞”与“⊟”,规则如表2和表3所示。
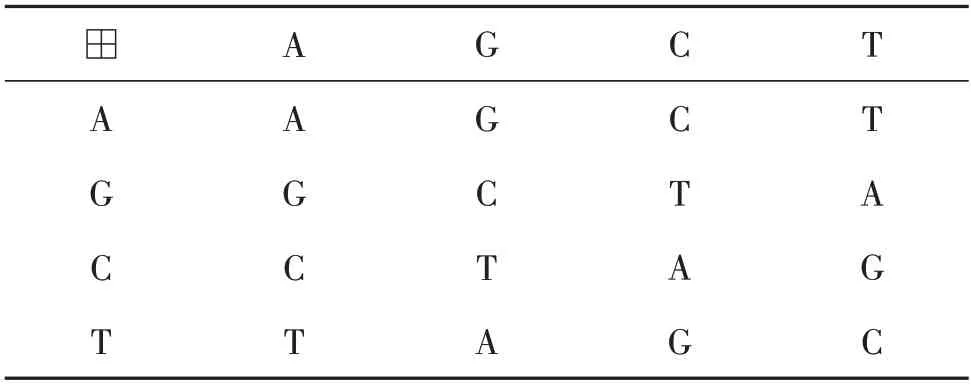
表2 DNA加法运算Table 2 DNA addition operation

表3 DNA减法运算Table 3 DNA subtraction operation
1.3 4维Lorenz超混沌系统
在本文加密算法中,对3 维Lorenz 混沌系统添加并耦合额外的状态变量获得4 维超混沌系统用于生成密钥序列(Lin和Li,2021),其方程定义为
式中,变量上方的“·”表示迭代值。令a=10,b=8∕3,c=28,当-1.52 ≤r≤-0.06 时,该系统为超混沌系统。本文选取r=-1,系统的4个李雅普诺夫指数分别为λLE1=0.338 1、λLE2=0.158 6、λLE3=0与λLE4=-15.175 2。系统的初值范围分别为x0∈(-40,40),y0∈(-40,40),z0∈(1,81)与w0∈(-250,250)。
2 图像加解密算法
本文加密算法设计如图2 所示。首先通信双方分别随机生成自己的私钥并通过椭圆曲线算法产生并对外发布相应公钥,双方取得对方的公钥后与自己的私钥相结合达成密钥共识并生成混沌密钥序列,然后发送者使用共识密钥序列对明文图像进行DNA 自适应编码加密并传输给接收者,接收者接收到密文图像后使用共识密钥进行相应解密操作即可得到解密图像。算法将对称的混沌加密模式转变成非对称形式,通信双方仅需要妥善保存私钥。此算法通过安全的公钥保障保密通信,解决了大量冗余密钥的管理与分发问题。
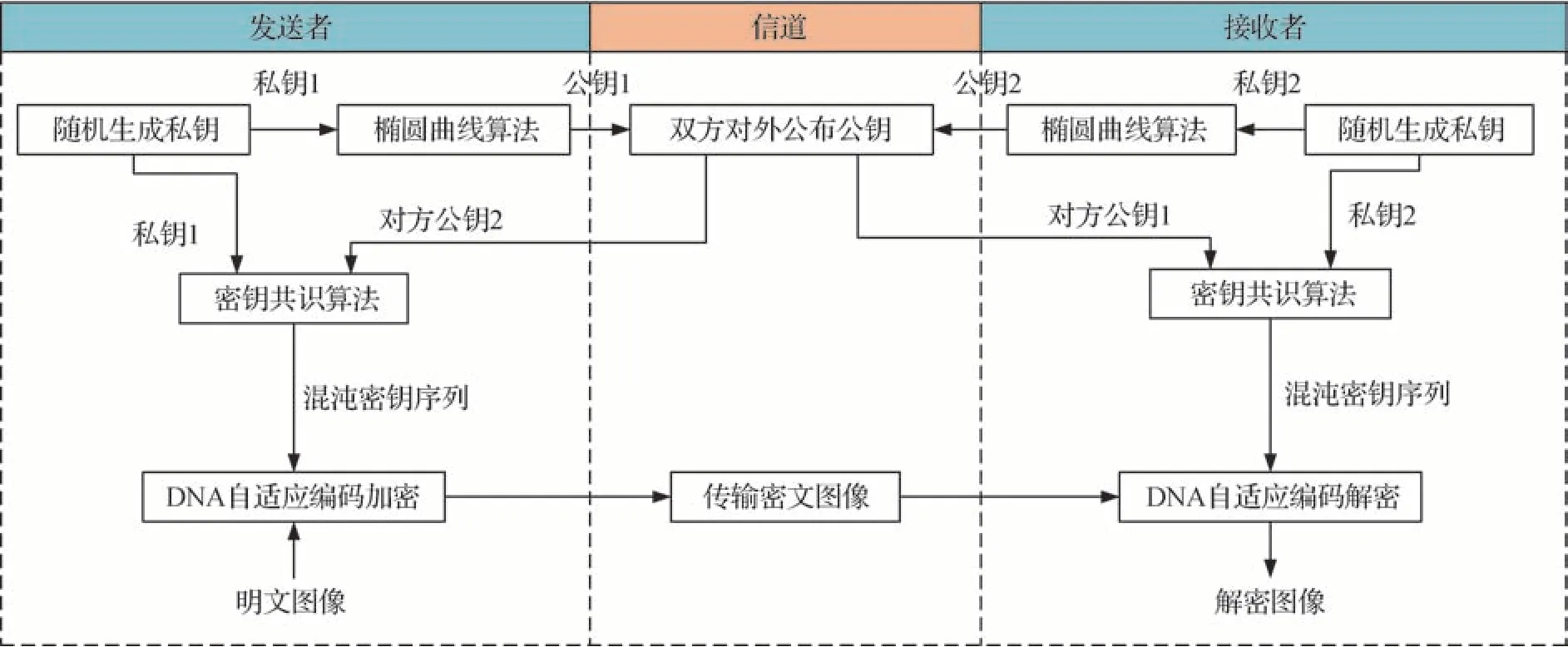
图2 加密算法设计图Fig.2 Design of encryption algorithm
2.1 密钥共识算法
密钥共识算法通过椭圆曲线的公钥密码体制产生混沌系统的初始值,再由混沌系统根据图像尺寸生成相应长度的混沌密钥序列用于DNA 自适应编码加密。
1)产生公私密钥对。记椭圆曲线上的点G的阶n是使得nG=O成立的最小正整数。Ep(a,b)和G是该密码体制种通信各方均已知的参数。发送者与接收者随机生成的私钥分别为ka和kb,应用椭圆曲线算法计算产生相应的公钥Ta和Tb,即
2)公布公钥并达成元点共识。通信双方通过公共信道公布公钥,将对方的公钥与自己的私钥相结合得到共识元点(kx,ky)。即
3)计算混沌系统初值。本算法中的椭圆曲线密钥长度为256 bit,故共识元点(kx,ky)的坐标值长度亦为256 bit,将kx与ky分割( | )成4 块64 位二进制数,具体为
然后,纠缠量化成混沌系统初值,具体为
式中,符号⊕表示异或运算。
4)生成混沌密钥序列。假定原始明文图像P0的像素数为m×n,将初值代入式(6)的混沌系统中进行迭代,舍去前300 个值避免瞬态效应,迭代4 ×m×n次生成4个伪随机序列X、Y、Z和W,变换生成密钥序列X′、Y′、Z′和W′,具体为
2.2 DNA自适应编码
DNA 自适应编码流程如图3 所示,共识混沌密钥序列作为加密密钥,在DNA 编码与解码的扩散过程中嵌入动态扩散—自适应置换环节,其中动态扩散环节具有密文反馈与掩码动态选择扩散规则的特点,自适应置换环节通过提取扩散密文特征因子来对密钥进行自适应加扰。

图3 DNA自适应编码流程图Fig.3 Flow chart of DNA adaptive coding
1)DNA 编码。将密钥序列X′作为编码规则密钥,每4 个密钥对应将1 个明文像素值编码生成4 个DNA 碱基,像素数为m×n的明文图像P0经过DNA编码后得到像素数为m× 4n的编码矩阵Ecode,即
式中,encode(·)表示DNA编码运算。
2)生成掩码矩阵Mcode。按式(12)将密钥序列Y′按光栅扫描顺序变换成m× 4n的DNA 掩码矩阵Mcode,即
3)动态扩散。将掩码矩阵Mcode元素作为扩散因子与规则动态选择因子,同时将前一个像素加密的结果反馈到下一个像素的加密过程中。对编码矩阵Ecode进行动态扩散得到扩散密文Ediff,具体为
式中,i=1,2,…,4 ×m×n,“⊞”和“⊟”运算为表2和表3 所示的DNA 碱基加减法运算。且当i=0 时,Ediff(0)=Ecode(4 ×m×n)。
4)自适应置换。统计扩散密文Ediff中4 种DNA碱基的个数nA,nG,nC,nT,并量化为特征密钥因子。具体为
然后,应用特征密钥因子对密钥序列Z′进行自适应加扰:将密钥序列Z′重排成m× 4n的矩阵,将第1行到第r1行元素每行循环左移t1位;将第r2行到最后一行元素每行循环右移t2位;将第1列到第c1列元素每列循环上移t3位;将第c2列到最后一列元素每行循环下移t4位。将加扰后的密钥矩阵Z″元素作为置换因子对扩散密文Ediff进行自适应置换得到置换密文Escra,具体为
此置换过程仅改变了扩散密文中各元素的位置而不改变其值,在解密时可以从密文中获得同样的特征密钥因子,故称为自适应置换。
5)DNA 解码。将密钥序列W′作为解码规则密钥,对置换密文Escra进行DNA 解码得到密文图像C,尺寸恢复为m×n,具体为
式中,decode(·,·)表示DNA解码运算。
DNA 自适应编码加密过程具有对称性,它的解密过程就是加密的逆过程。首先,将加密过程中的解码密钥序列W′作为编码规则密钥对密文图像进行DNA 编码。统计各碱基个数获得特征密钥因子对密钥序列Z′加扰并进行逆置换。然后使用密钥序列Y′同样地生成掩码矩阵Mcode进行逆扩散,逆扩散过程为
式中,i=4 ×m×n,4 ×m×n-1,…,1,当i=0时,Ediff(0)=Ecode(4 ×m×n)。最后将加密过程中的编码密钥序列X′作为解码规则密钥进行DNA 解码即可获得解密图像。
3 仿真结果及安全性分析
使用算法对USC-SIPI“Miscellaneous”图像数据集中的3 幅像素数分别为256 × 256、512 × 512 和1 024 × 1 024 的灰度图像“5.1.09”、“5.2.09”与“5.3.01”进行加密仿真,仿真实验在MATLAB R2018b 软件中进行实现,仿真环境为Intel Core i7-7700 @ 3.60 GHz CPU、8 GB 内存和Windows 10 操作系统。椭圆曲线参数{p,a,b,G(Gx,Gy)}与双方私钥sa和sb设定如下:
加密效果如图4所示,可以观察到3幅图像均被加密为杂乱无章的密码图像,又由于算法的每一步都是完全可逆的,可以从相应的密文图像中完全解密恢复原始图像。
实验仿真的算法运行时间如表4 所示,算法的实际运行效率受计算机硬件、仿真环境与编程代码等因素影响。

表4 算法运行时间Table 4 Algorithm running time
为了评估该算法的总体性能,下面分别从密钥空间、抗统计攻击和抗差分攻击等方面进行分析。
3.1 密钥空间
一般情况下,一个好的加密算法的密钥空间应该大于2100,才能抵御穷举攻击(杨宇光和裴帅康,2022)。本算法的密钥为通信双方的长度为256 bit的私钥,攻击者只有破解出通信两端之一的完整私钥才可以从信道中获取到有效信息,故算法密钥空间为2256,显然本文算法的密钥空间足够大,完全能够抵抗穷举攻击。此外,加密算法应该对其密钥极其敏感。否则,具有微小差异的不正确密钥也可能正确解密原始图像的信息,这可能使实际密钥空间小于理论密钥空间。
比特变化率数(number of bit change rate,NBCR)可用于测试算法的密钥敏感性(Castro 等,2005)。对于两个尺寸一样的图像的像素以光栅扫描顺序二进制编码X1和X2,NBCR定义为
式中,Ham(X1,X2)表示X1和X2的汉明距离,Len表示图像的位长度,当NBCR 接近50% 时可以认为图像X1和X2完全不一样。
加密算法的密钥敏感性测试步骤如下:
先设定一个原始密钥K1,改变其256 位数据中的一位得到差异密钥K2,在加密端分别使用K1和K2对测试图像“5.1.09”进行加密,得到两幅密文图像C1和C2,计算C1和C2的NBCR;在解密端分别使用K1和K2对同一密文图像C1进行解密得到两幅解密图像D1和D2,计算D1和D2的NBCR。依次单一改变密钥256 位数据进行测试,得到密钥敏感性分析结果,如图5 所示,当密钥的任何一位发生变化时,得到的两个密文图像和解密图像是完全不同的,这意味着本算法对密钥极其敏感。
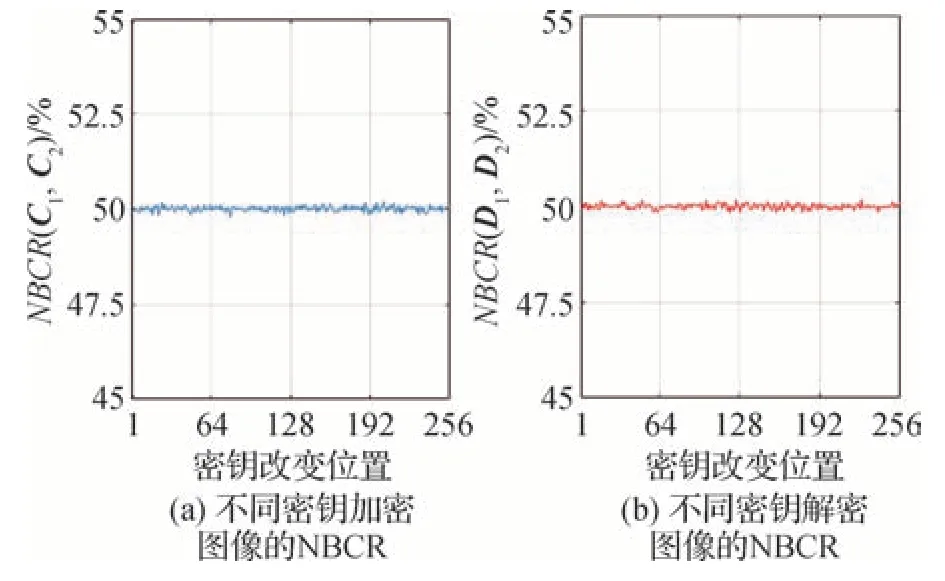
图5 密钥敏感性分析Fig.5 Key sensitivity analysis((a)NBCR of images encrypted with different keys;(b)NBCR of images decrypted with different keys)
3.2 抗统计攻击分析
3.2.1 相关性分析
相邻像素相关性描述图像中相邻像素之间的相关性程度,对于有视觉感知意义的图像,相邻像素之间的相关性通常非常高,因为它们的值彼此接近,而通过图像加密算法处理获得的加密图像应当呈现弱相关性。如图6所示,随X轴分别表示3幅测试图像的明密文,在Y-Z平面绘制相应方向上的相邻像素值的分布情况。可以看到,明文图像在各个方向上的相邻像素分布均集中在对角线附近,表现出强相关性。而密文图像在各个方向上的相邻像素都均匀分布在整个区间,表现出弱相关性。
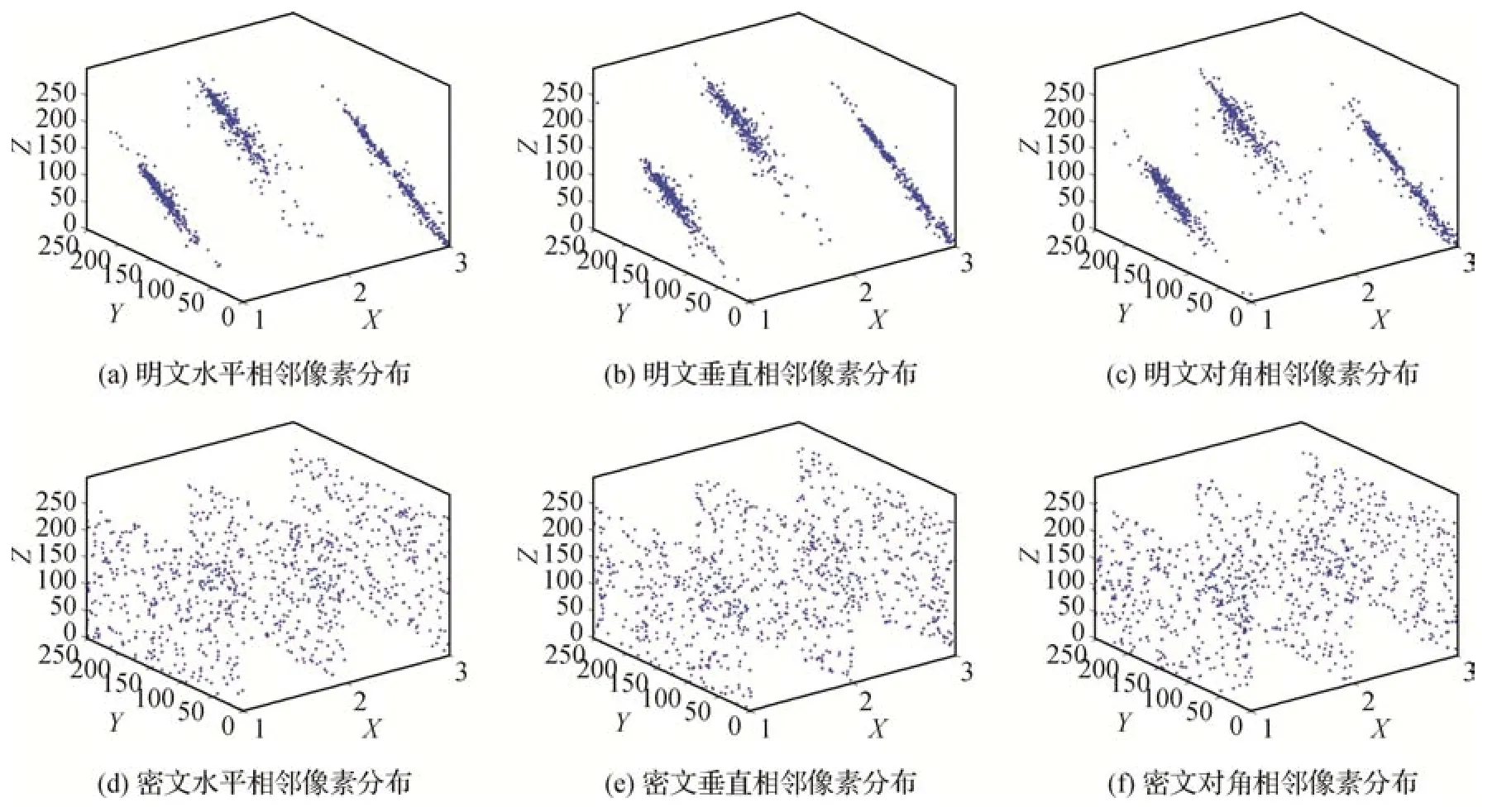
图6 相邻像素值分布情况Fig.6 Distribution of adjacent pixel values((a)horizontal adjacent pixel distribution of plaintext;(b)vertical adjacent pixel distribution of plaintext;(c)diagonal adjacent pixel distribution of plaintext;(d)horizontal adjacent pixel distribution of ciphertext;(e)vertical adjacent pixel distribution of ciphertext;(f)diagonal adjacent pixel distribution of ciphertext)
通常,还通过计算不同方向上的相关系数来评价图像相邻像素相关性,具体为
式中,xi与yi表示水平、垂直与对角方向上的相邻像素采样点的像素值,E(x)表示样本的期望值,D(x)表示样本的方差,N为样本总数。
表5 列出了3 幅测试图像加密前后的相关性系数,可以看到,密文图像各个方向上的相关系数均接近于零,与明文图像相比显著降低,说明加密算法很好地破坏了相邻像素的相关性。

表5 相邻像素相关性分析Table 5 Correlation analysis of adjacent pixels
3.2.2 直方图分析
直方图表示的是图像所有可能像素值的频率分布。对于正常图像,某些像素值的频率分布会较高,而另一些像素值的频率会较低,因此,直方图是不规则的,反映图像的某些特征。而加密图像的直方图应该是平坦均匀的,攻击者无法从中获取任何有效信息。图7给出了3幅测试图像的直方图分析结果。可以看出,密文图像的直方图是均匀分布的,与明文图像截然不同,可以抵抗直方图攻击。
3.2.3 信息熵
信息熵是检验图像随机性的重要指标,若图像的信息熵接近理想值8,则表示图像具有优异的随机性,能抵抗统计攻击,图像信息熵的计算式为
式中,si表示0~255的像素值,P(si)表示像素值si在图像中出现的概率。表6 列出了3 幅测试图像加密前后对应的信息熵的值。可以看出,所有明文图像的信息熵都相对较小,而密文图像信息熵非常接近理想值。
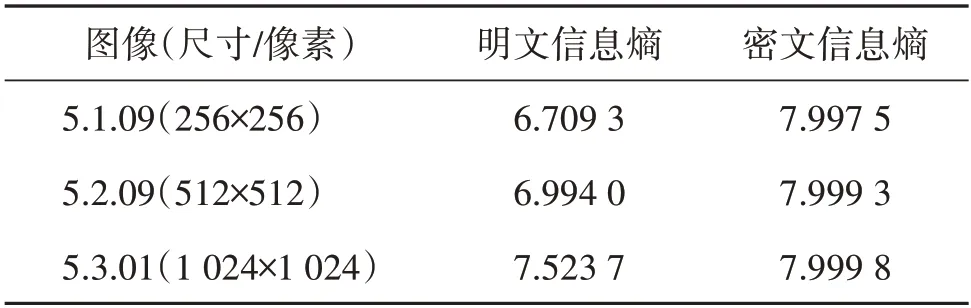
表6 信息熵分析Table 6 Information entropy analysis
3.3 抗差分攻击分析
差分攻击是一种常用且有效的攻击方式,通过研究明文图像中的差异对密文的影响,建立明文与密文之间的关系。像素变化率(number of pixels change rate,NPCR)和统一平均变化强度(unified average changing intensity,UACI)是测试加密算法是否能够抵抗差分攻击的两个重要指标。假设C1和C2是由两个只有一个位差的明文图像使用同一密钥加密得到的密文,它们的NPCR和UACI值的计算式为
式中,N表示图像的像素数,C(i)表示图像第i个像素的像素值,D(i)表示两幅图像的第i个像素是否一样。根据定义可知NPCR 与UACI 分别统计了明文的微小差异所导致的密文的像素变化概率以及变化程度,反映了加密算法对明文的敏感性。根据Hua等人(2019)给出的显著性水平为0.05时的不同大小图像的NPCR与UACI的置信区间,表7与表8列出的3幅测试图像的NPCR 与UACI测试结果均在置信区间内,意味着本文算法能够有效的抵抗差分攻击。

表7 NPCR测试结果Table 7 NPCR test results

表8 UACI测试结果Table 8 UACI test results
3.4 NIST随机性测试
NIST SP800-22 是测量数据序列随机性的既定标准。使用本文算法对USC-SIPI“Miscellaneous”与“Aerials”图像数据集进行加密,然后将多个密文图像用做二进制序列输入进行随机性测试。实验中,NIST 测试了100 个1 000 000 位的二级制序列。如果任何测试的值 P-value 小于 0.000 1,则认为序列随机性不够好(Wang 等,2015)。表9 列出了测试结果。本文算法通过了所有的子测试,这表明本文算法加密得到的密文图像具有高度的随机性。

表9 NIST随机性测试Table 9 NIST randomness test
3.5 对比与分析
使用本文算法对图像Lena 进行加密与性能测试,并与其他加密算法进行对比,其他算法的测试结果直接从相应的论文中引用,对比结果如表10 所示,其中。可以观察到,各算法相邻像素相关性分析的性能差异较小,而在信息熵与抗差分攻击分析方面,本文算法性能更优异,表明本文算法具有更好的安全性。
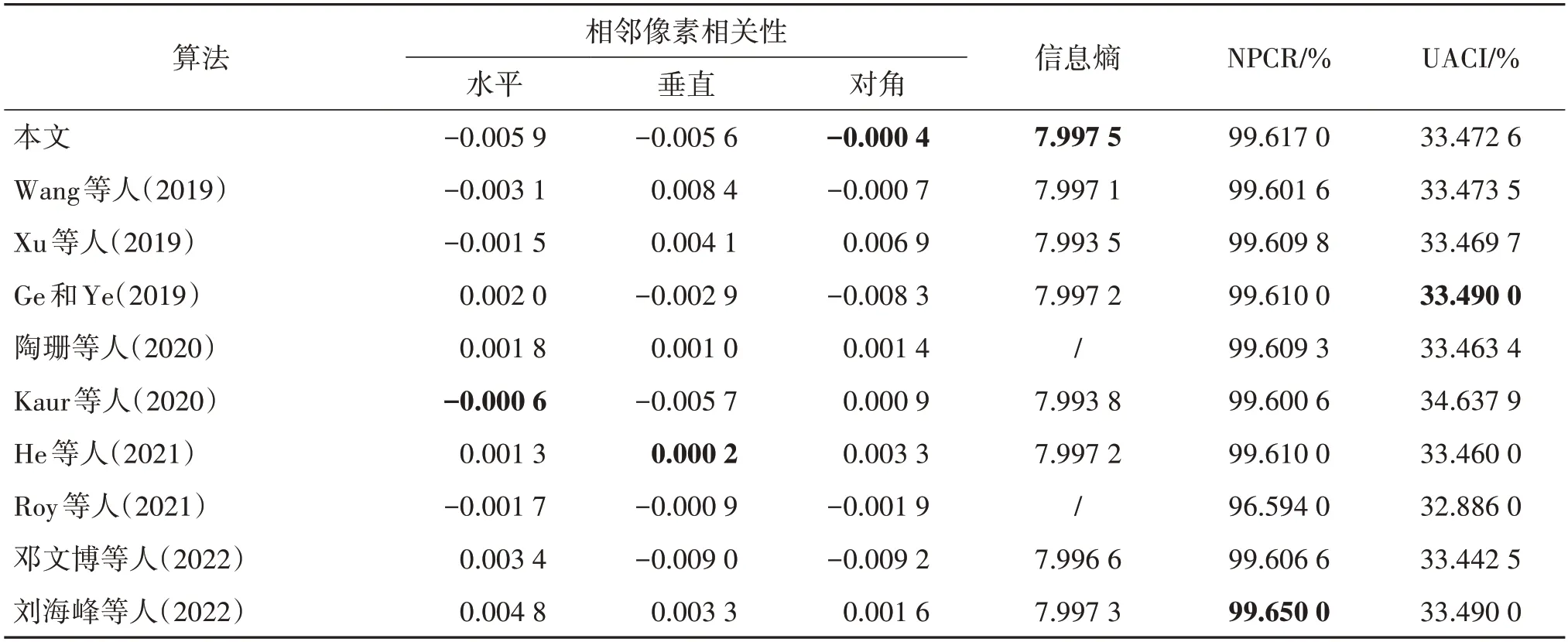
表10 与其他算法性能对比结果Table 10 Results comparison with other algorithms
本文算法采用非对称的密钥生成与分发方式,暴露的公钥基于椭圆曲线离散对数的难解问题使攻击者无法逆向推导私钥,同时足够大的私钥空间可以抵抗穷举攻击,解决了冗余密钥的管理与分发问题的同时密钥安全性足以得到保障。对图像的DNA 自适应编码加密过程通过DNA 编解码内嵌动态扩散—自适应置换结构将扩散与置换环节互相紧密联系,使得攻击者无法通过分割攻击逐一破解,同时动态扩散过程与自适应置换过程都与中间密文相关,当采用不同的明文进行加密时,中间密文也会随之变化,杜绝了选择明文攻击的可能性。
4 结论
针对当前大多数一次一密模式的混沌图像加密算法存在的密钥冗余的问题,本文提出了椭圆曲线与自适应DNA 编码的混沌图像加密算法。算法由密钥共识算法与自适应DNA 编码加密两个部分组成,前者让使用者无需传输私钥便可达成密钥共识,后者将具有中间密文状态反馈的动态扩散—自适应置换结构嵌入DNA 编码的扩散过程中,使置换与扩散过程相互紧密联系以抵抗分割攻击和选择明文攻击,同时,加密过程的密文状态可以在解密端自适应同步,避免了密钥冗余的问题。对测试图像的实验仿真与安全性分析的结果表明,本文算法在对各种尺寸的图像的加密中都表现出优异的性能,对主流的几种攻击方式都有较高的抵御能力,并且通过与近年的其他算法的对比体现了本文的优越性。由于密钥共识算法是基于椭圆曲线上的离散对数难解问题而设计,具有高复杂度,低加密效率的特点,产生共识密钥序列的计算速度需要进一步优化,这将成为下一步研究的核心问题。
猜你喜欢
电子与信息学报(2023年9期)2023-10-17
黑龙江大学自然科学学报(2022年1期)2022-03-29
计算机仿真(2021年10期)2021-11-19
阅读(低年级)(2019年2期)2019-04-19
民间故事选刊·上(2018年1期)2018-01-02
小小说月刊·下半月(2016年6期)2016-05-14
火控雷达技术(2016年1期)2016-02-06
中国资源综合利用(2016年11期)2016-01-22
深圳大学学报(理工版)(2015年5期)2015-02-28
四川师范大学学报(自然科学版)(2015年1期)2015-02-28
