
基于Retinex理论的低光图像增强算法
2023-11-18 09:52史宇飞赵佰亭
重庆工商大学学报(自然科学版) 2023年6期
史宇飞,赵佰亭
安徽理工大学 电气与信息工程学院,安徽 淮南 232001
1 引 言
在光照不足、不均或者有阴影遮挡等条件下,采集的图像一般都存在噪声过多和对比度弱等问题,而这些问题不但会对图像的品质产生负面影响,还会妨碍一些机器视觉任务的进行。对低光照图像进行增强,有助于提高高级视觉性能,如图像识别、语义分割、目标检测等;也可以在一些实际应用中提高智能系统的性能,如视觉导航、自动驾驶等。因此,对低光图像增强进行研究是十分必要的。低光图像增强方法可分为以下4类:
基于直方图均衡化的方法[1],其核心是通过改变图像部分区域的直方图来达到整体对比度提高的效果。此类方法可以起到提高图像对比度的作用,但是大多数不够灵活,部分区域仍会出现曝光不足和放大噪音等不好的视觉效果。
基于去雾的方法[2-3],如一些研究人员[4]利用有雾图像和低光图像之间的相似性,通过已有的去雾算法来增强低光照图像。尽管此类方法得到了较好结果,但此类模型的物理解释不够充分,同时对增强后的图像进行去噪可能会导致图像细节模糊。
基于Retinex理论[5]的方法,其将低光图像分解为光照和反射率两部分,在保持反射率一致性的前提下,增加光照的亮度,从而增强图像。此类方法不仅提高了图像的对比度,还降低了噪声带来的的影响,不足之处是要根据经验来人工设置算法的相关参数,并且不能对不同类型图像自适应增强。
基于深度学习的方法,Lore等[6]提出的LLNet通过类深度神经网络来识别低光图像中的信号特征并对其自适应增强;Wei等[7]提出的Retinex-Net结合Retinex理论和神经网络进行图像增强;Wang等[8]提出的GLADNet先通过编解码网络对低光图像生成全局照明先验知识,然后结合全局照明先验知识和输入图像,采用卷积神经网络来增强图像的细节。此类基于深度学习的方法均取得了不错的效果,但是大多数方法在增强过程中并没有对噪声进行有效抑制,从而使得增强后的图像出现噪声大、颜色失真等问题。
为解决这些问题,提出了Retinex-RANet(Retinex-Residuals Attention Net)方法。Retinex-RANet首先在分解阶段采用残差模块与跳跃连接,通过跳跃连接将第一个卷积层提取的特征与每一个RB提取的特征融合,从而得到更准确的反分量和光照分量。另外,还在降噪网络中加入通道注意力模块和空洞卷积,注意力机制可以更好地去除反射分量中的噪声,还原细节;而空洞卷积能获取更多的上下文信息特征。实验结果表明:Retinex-RANet具有更好的低光图像增强效果。
2 模 型
Retinex-RANet模型框图如图1所示。由图1可以看到:整个网络模型由3个子网络组成,即分解网络、降噪网络以及调整网络,分别用于分解图像、降低噪声和调整亮度。具体地说,首先该算法通过分解网络将低光照图像Sl和正常光图像Sh分解为反射分量(Rl、Rh)和光照分量(Il、Ih),然后降噪网络将分解的反射分量Rl作为输入,并使用光照分量Il作为约束来抑制反射分量中的噪声,同时将光照分量Il送入调整网络,来提高光照分量的对比度,最后融合R′和I′得到增强后的图像。

图1 Retinex-RANet模型结构图Fig.1 Retinex-RANet model structure diagram
2.1 分解网络
基于Retinex理论方法的关键是在分解阶段如何得到高质量的光照分量和反射分量,而分解后的结果对后续的增强和降噪操作都会产生影响,因此,设计一个有效的网络对低光图像进行分解是很有必要的。分解网络结构如图2所示。

图2 分解网络Fig.2 Decomposition network
在分解网络结构中,为了使深度神经网络在训练阶段更容易优化,使用3个残差块(RB)来获得更好的分解结果。首先使用3×3卷积提取输入低光图像Sl的特征;然后再经过3个RB模块提取更多的纹理、细节等特征,同时为了减少底层颜色、边缘线条等特征的丢失,引入了跳跃连接,即将第一个卷积层的输出连接到每一个RB的输出,保证特征的充分提取;最后通过3×3×4的卷积层和sigmoid函数激活,从而得到3通道的反射分量和1通道的光照分量。
2.2 降噪网络
在对低光图像进行增强的过程中,大多数基于Retinex理论的方法在得到分解结果后都忽略了噪声的影响,这会导致最终的增强结果受到反射分量中噪声的干扰,出现模糊、失真等问题。为了解决这类问题,设计了如图3所示的降噪网络。
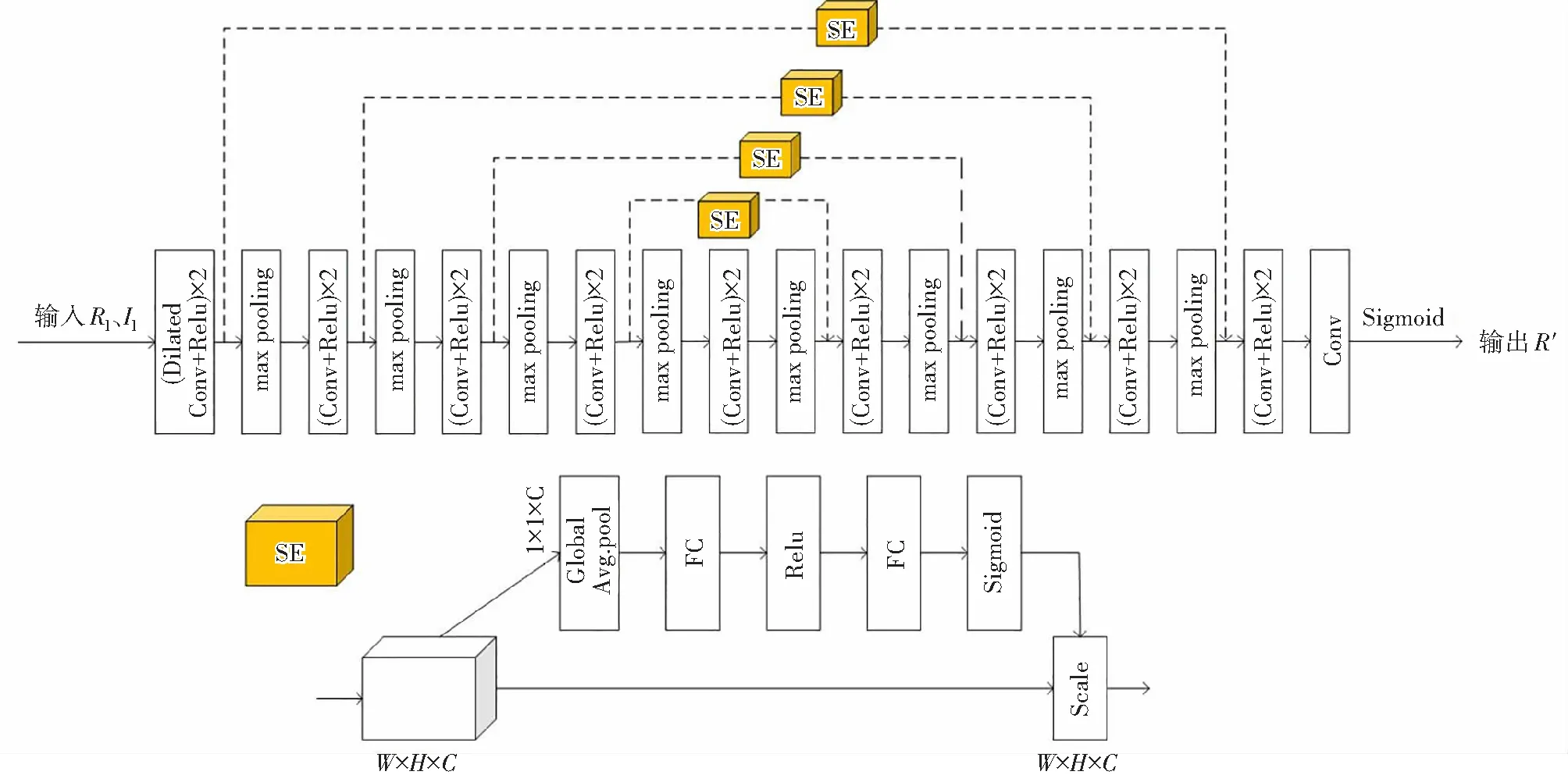
图3 降噪网络Fig.3 Denoising network
在低光增强领域,U-Net网络由于其优秀的结构设计,被大量网络作为其主要架构和部分架构,因此Retinex-RANet也采用U-Net作为降噪网络的基础网络部分。
降噪网络包含编码和解码两个部分。在编码阶段,先融合输入的反射分量和光照分量,然后经过一组由两个3×3的空洞卷积、RELU函数激活和最大池化层组成的编码块,3组均由两个卷积核为3×3的卷积激活层和一个最大池化层组成的编码块来提取特征,从而得到编码阶段的特征图,最后将其送入解码阶段。编码过程中,每次通过一个编码块,图像的通道数会翻倍,但是其尺寸会降低一半。
在解码阶段,由4个相同的解码块组成,结构为3×3的卷积层— RELU函数激活—2×2的反卷积层。受到图像识别中的SENet[9]的启发,将通道注意力模块嵌入到跳跃连接中,以便更好地降低噪声,恢复细节。如图3所示:首先将编码阶段采集到的图像特征进行全局平均池化操作,然后经过两个全连接层和两个激活函数,最后和解码阶段的特征图逐通道相乘,此过程可将更多的权重分配给有用的特征,如颜色、细节和纹理特征等,同时为噪声、阴影快和伪影等特征分配较少的权重;然后融合跳跃连接得到的特征图与反卷积后的特征,之后再进行卷积计算,解码过程中,每次通过一个解码块,图像的通道数会降低一半,但是其尺寸会翻倍;最后使用3×3卷积得到一个3通道特征图,并对其进行sigmoid函数激活,从而得到降噪后的反射分量。
2.3 调整网络
在得到分解后的光照分量后,需要提高其对比度,因此设计了图1中的调整网络。此调整网络是一个轻量级网络,包含3个卷积激活层、1个卷积层和1个Sigmoid层,同时为了避免底层信息的损失,通过跳跃连接将输入连接到最后一个卷积层的输出。
2.4 损失函数
训练时,3个子网络均单独训练,因此,整个Retinex-RANet的损失由分解损失Ldc、降噪损失Lr和调整损失Li组成。
2.4.1 分解损失
为了更好地从低光图像中分解出反射分量和光照分量,设计了3个损失函数,即重建损失Lrec、反射分量一致性损失Lrs、光照分量平滑损失Lis,如下所示:
Ldc=Lrec+λ1Lrs+λ2Lis
Lrec=‖Sl-Rl∘Il‖1+‖Sh-Rh∘Ih‖1
其中,λ1和λ2分别为Lrs和Lis的权重系数,Sl和Sh为低光条件和正常光条件下的输入图像,Rl、Rh和Il、Ih分别是低光和正常光图像分解后的反射分量和光照分量,“∘”表示逐像素相乘操作,‖‖1表示使用的是L1范数约束损失,‖‖2表示使用的是L2范数约束损失,表示梯度,为水平梯度与垂直梯度之和,ɛ为一个小的正常数,取0.01。
2.4.2 降噪损失
为了保证经过降噪处理后的反射分量和正常光图像的反射分量在结构、纹理信息等方面能够保持一致,同时衡量降噪处理后图像与正常光图像之间的颜色差异,降噪网络的损失函数Lr如下所示:
R′为经过降噪处理后的反射率,SSIM()为结构相似性度量,Lc为色彩损失函数,表达式如下:
其具体含义为先对降噪后的图像R′和正常光图像Sh进行高斯模糊Γ(),再计算模糊后图像的均方误差。
2.4.3 调整损失
为了使调整过后的光照分量与正常光图像的光照分量尽可能相似,调整网络的损失函数Li如下所示:
其中,I′为Il增强后的图像。
3 实验结果和分析
3.1 训练数据集
实验中的训练集为LOL数据集[7],该数据集包含500对图像:其中,训练集含485对图像,验证集为剩余15对图像。在训练过程中,分解模块和增强模块的批量化大小为16,块大小为48×48,训练次数为2 000次,分解网络损失函数的权重系数λ1=0.01,λ2=0.2。降噪模块的批量化大小为4,块大小为384×384,训练次数为1 000次。模型优化方法为随机梯度下降法。整个网络模型在CPU型号为Intel(R)Core(TM)i7-10700K、GPU型号为Nvidia GeForce RTX 2080 Ti的电脑上运行,同时训练框架为Tensorflow1.15,GPU使用Nvidia CUDA10.0和CuDNN7.6.5加速。
为了评估Retinex-RANet的性能,将其与几种传统方法如BIMEF[10]、Dong[11]、LIME[12]、MF[13]、MSR[14]和SIRE[15]等,以及深度学习方法,如R2RNet[16]、Retinex-Net[7]、KinD[17]、Zero-Dce[18]等进行比较,并同时在多个数据集上评估了该算法,包括LOL、LIME、NPE[19]和MEF[20]数据集。在实验过程中,均采用原文献所提供的源代码对图像进行训练和测试。
在评估过程中,采用峰值信噪比(RPSNR[21])、结构相似性(RSSIM[22])和自然图像质量评估(RNIQE[23]) 这3个指标来进行定量比较。RPSNR和RSSIM值越高,RNIQE值越低,则增强后图像的质量越好。
3.2 消融实验
为了确定Retinex-RANet的有效性,在KinD网络的基础上进行消融实验。该实验使用LOL数据集进行验证,同时采用RPSNR、RSSIM指标来评估增强后图像的质量。结果如表1所示,表中RB表示残差模块,SC表示跳跃连接,SE表示注意力模块。
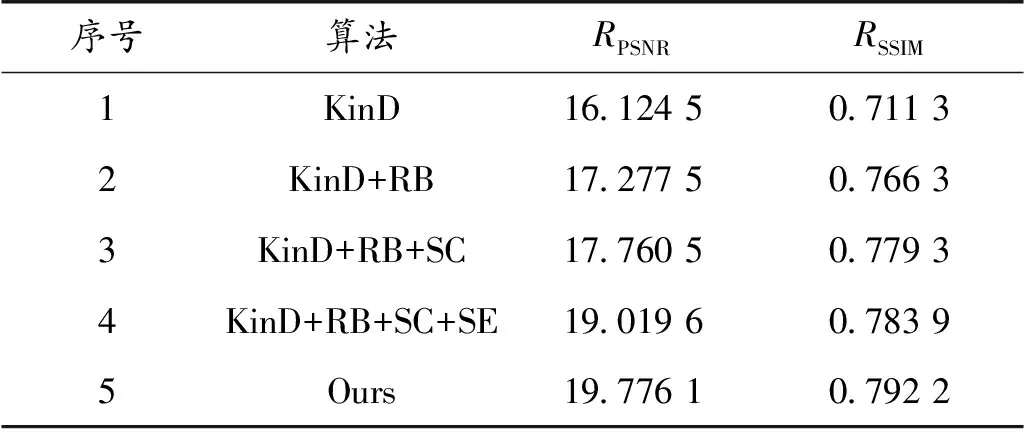
表1 各改进模块的消融实验结果Table 1 Ablation experimental results of each improved module
表1中序号2给出的是在KinD网络基础上,使用残差模块作为分解网络时的结果。相比于KinD网络,RPSNR和RSSIM均有显著的提升。在此基础上加入跳跃连接,见序号3,相较于序号2的结果又有了小幅提升。说明在使用残差模块和跳跃连接作为分解网络的情况下,得到了质量更高的分解结果,从而验证了残差模块和跳跃连接的有效性。
由于3个子网络是单独进行训练的,确定改进的分解网络有用后,在此基础上确定在降噪网络中加入空洞卷积和注意力机制的有用性。从序号4的结果可以看出,在加入注意力机制后,图像指标明显上升,这是因为注意力模块能集中学习有用特征,如颜色、细节等,从而降低图像中的噪声,阴影等。为了获取更多的上下文信息,同时在降噪网络中加入空洞卷积(序号5),相较于序号4的结果有了小幅提升。从而确定了Retinex-RANet的模型即为序号5的模型。
3.3 实验评估
各算法在不同数据集上的视觉对比如图4、图5所示。

图4 LOL数据集上各算法的视觉效果Fig.4 Visual effects of each algorithm on the LOL dataset

图5 其他数据集上各算法的视觉效果Fig.5 Visual effects of each algorithm on other datasets
图4的输入来自LOL数据集,是非常低亮度的真实世界图像。可以看出:Dong、Retinex-Net、Zero-Dce、MSR、LIME的增强结果中存在明显的噪声、色差等问题,特别是对Retinex-Net来说,看起来不像真实世界的图像;SIRE、MF和KinD对图像的增量程度有限,增强结果偏暗;R2RNet的增强结果在整体上偏白,存在饱和度过低等问题;相比之下,Retinex-RANet增强后的图片更接近于真实世界图像,有效抑制了噪声,同时能很好地还原图像原有的色彩。
此外,还在其他数据集上对本模型进行了测试,如图5所示。从左上角的细节图像中可以看到:虽然大多数方法都能在一定程度上改变输入图像的亮度,但仍然存在着一些严重的视觉缺陷,比如Dong和Retinex-Net存在噪声和颜色失真问题;Zero-Dce、R2RNet和MSR增强后的图像整体偏白,无法看清左上角图像的背景;SIRE和KinD增强后的图像总体偏暗,无法观察脸部细节;Retinex-RANet、LIME、MF和BIMEF能相对清晰地观察到脸部细节,但比较左下角图的可知,Retinex-RANet相较于其他算法,增强的亮度适中,轮廓细节更加清晰,色彩更为真实。
表2显示了在LOL数据集上各算法的评估对比,其中,加黑数字为最优数值。LOL数据集中的图像为成对的低光/正常光图像,因此可使用RPSNR和RSSIM来衡量算法的优越性,同时还引用了RNIQE指标。从表中可以看出:在RPSNR和RSSIM指标上,Retinex-RANet相较于其他算法都取得了最高的值,而在RNIQE指标上,所取得的值略高于KIND和R2RNet算法得到的值。
因为LIME、NPE和MEF数据集只包含低光图像,无对应的正常光图像,所以只使用RNIQE指标来比较各算法之间的差异。从表3可以看出:在LIME和NPE数据集上,Retinex-RANet取得了最优值,而在MEF数据集上,所取得的值略高于SRIE算法得到的值。

表2 LOL数据集上各算法的结果对比Table 2 Comparison of the results of each algorithm on the LOL dataset

表3 不同数据集上的RNIQE对比Table 3 Comparison of RNIQE on different datasets
综上所述,虽然Retinex-RANet并没有在上述数据集上都取得最好的结果,但仍有一定优势。同时,在客观评判指标RSSIM和RPSNR上均取得了最高值。因此,Retinex-RANet相较于其他算法,对低光照图像增强后的效果更优。
4 结束语
针对低光图像在视觉效果上存在亮度低、噪声大以及对比度弱等问题,设计了Retinex-RANet网络模型。此模型在分解网络中结合残差模块(RB)和跳跃连接,充分提取图像特征和细节信息;在降噪网络中嵌入空洞卷积和注意力机制,可以获取更多的上下文信息,降低图像中的噪声、阴影等;最后将降噪网络去噪后的反射分量和亮度调整网络增强后的光照分量融合,得到最终的增强结果。实验表明:与LIME、Zero-Dce和R2RNet相比,Retinex-RANet在客观指标RPSNR和RSSIM上均取得了最高的数值, Retinex-RANet在增强图像的视觉对比上,不仅提高了图像的对比度、抑制了噪声,而且明显消除了退化问题,达到了更好的视觉效果。
猜你喜欢
中国机械工程(2022年8期)2022-05-09
数学小灵通·3-4年级(2021年5期)2021-07-16
基层中医药(2021年12期)2021-06-05
中国机械工程(2021年8期)2021-05-07
音乐教育与创作(2019年8期)2019-05-16
今日农业(2019年15期)2019-01-03
英美文学研究论丛(2018年1期)2018-08-16
纺织科学研究(2017年6期)2017-07-03
广西民族大学学报(自然科学版)(2015年3期)2015-12-07
读者·校园版(2015年19期)2015-05-14
