
基于分组和信用分级的PBFT 共识算法改进方案
2023-11-18 03:32刘陕南张荣华刘长征
计算机工程 2023年11期
刘陕南,张荣华,刘长征
(石河子大学 信息科学与技术学院,新疆 石河子 832000)
0 概述
区块链技术起源于比特币,2008 年由中本聪提出。区块链本质上是一个分布式数据库,具有去中心化、防篡改、可编程、可追溯等特点[1-2]。根据节点准入机制的不同,区块链一般分为公有链、私有链和联盟链[3-4]。
公有链如比特币[5]和以太坊[6],对所有节点开放,是完全去中心化的。公有链上的节点可以自由地加入或退出[7],但随着应用场景的不断扩展,越来越多的领域需要区块链来实现不完全的去中心化,因此,出现了私有链和联盟链。私有链供个人使用,一般不对外开放,存在一定程度的中心化特点,具有访问权限可控、交易速度快、成本低等优点[8-9]。联盟链由一些组织共同维护,通常每个节点都有一个相应的实体组织,经过身份验证和授权后,可以连接、访问和提交信息,每个成员也可以赋予不同的数据权限,以实现多家公司或机构的合作[10]。联盟链具有成本低、效率高等优点,是当前区块链发展的主流方向。
在区块链系统中,如何通过一定的规则使每个节点保持数据一致是一个核心问题,解决方法就是开发一种共识算法[11]。实用拜占庭容错(Practical Byzantine Fault Tolerance,PBFT)算法是联盟链中应用较广泛的共识算法,算法基于少数节点服从多数节点的原则,主节点发起提议,其他节点进行确认,当超过2/3 的节点确认时,该提议通过[12]。这一方法的优点是共识效率相对较高,容错率接近1/3,然而,因为其使用C/S 架构,不能动态感知节点的数量,所以随着节点数量的增加,性能急剧下降,不适用于大规模的动态网络,限制了区块链技术在金融服务、供应链管理、物联网(IoT)[13]等领域的应用。对此,很多学者提出了PBFT 的改进算法。
在PBFT 改进算法中,共识节点按类型分组,形成具有相同特征的节点结构,更利于数据存储和节点管理[14-16]。同时,将大量的节点划分为多个共识集,能够减小节点的规模,简化共识的复杂性。文献[17]提出了一种基于位置、可扩展的PBFT 共识算法。固定节点比移动节点具有更强的计算能力,而且成为恶意节点的可能性非常小。该算法通过选择一个固定可信的节点作为共识参与者,降低了共识开销,保证了系统的安全性,但去中心化程度也大幅削减。文献[18]提出了一种基于信用改进的PBFT 共识算法CPBFT。该算法将原来的C/S 体系结构更改为P2P 体系结构,减少了共识步骤,并引入了信用系数,用投票方法来选择主节点,使节点被选为主节点的概率受到过去行为的影响。实验表明,与PBFT 算法相比,CPBFT 算法减少了数据传输量,提高了吞吐量。文献[19-20]使用散列算法对一致性节点进行分组,从而避免节点间的大量通信,降低网络的通信复杂度,提高网络的可扩展性,但这一方法无法识别拜占庭节点。文献[21]针对传统拜占庭容错算法通信开销大、算法效率低等问题,提出了一种实用的拜占庭容错算法S-PBFT。该算法增加了节点评分机制,将所有节点分为共识节点、候选节点和早期节点,同时为了确保节点的可靠性,根据每个节点的行为动态改变节点评分。文献[22]在PBFT 算法基础上,添加了基于可验证随机函数(VRF)的共识节点选举算法,提出的EPBFT 更适用于动态网络。虽然这些算法具有比PBFT 算法更好的性能,但它们都忽略了共识网络的容错性,而在实际应用中,容错能力越强,算法的适用性就越强。
本文在设计中考虑PBFT 算法的容错性,提出节点分组策略和信用分级模型,以期在分布式网络环境下,整个网络仍然能达成正确和一致的共识,从而减少系统的通信开销,同时,使用信用分级机制检测拜占庭节点,提高系统安全性。本文主要工作如下:
1)优化一致性协议,提出节点分组模型。以联盟链的节点对管理节点的响应速度作为分组依据,先进行组内共识,管理节点带着组内共识的结果再参与组外共识,从而减少节点间的通信量,提高共识效率。
2)提出一种信用分级机制。通过引入信用模型,对网络中的共识节点分类,将节点划分为管理节点、候选节点和普通节点,提高信用值高的节点成为主节点的概率,从而减少恶意节点对系统的破坏,提高整个网络的效率。
3)搭建基于该改进方案的仿真模拟与性能测试系统,通过模拟实验证明方案的有效性以及可用性。
1 PBFT 算法
PBFT 算法被认为是解决拜占庭问题的最佳算法之一,它有3 个角色:客户端,主节点,从节点。客户端提交事务请求后立即发送到主节点,主节点在全网发起事务投票,从节点和主节点共同维护事务投票的有效性,主节点失效时将触发视图更改程序,选择一个新的主节点。
1.1 一致性协议
PBFT 算法流程如图1 所示。首先,客户端C 向主节点0 发送一个消息m,主节点启动PBFT 的5 段协议,即请求、预准备、准备、提交和回复。在图1中,C 表示客户端节点,0~3 为共识节点,其中,0 表示主节点,3 表示故障节点。
1)请求阶段。客户端节点生成消息摘要,添加请求操作o、时间戳t构造请求。完成签名后,将
2)预准备阶段。主节点接收到消息后,构造<
3)准备阶段。从节点接收预准备信息,进入准备阶段,向其他节点广播消息
4)提交阶段。提交阶段需要广播
5)回复阶段。当前节点收到2f+1 个(包括其自身)提交后,将消息记录到本地日志中并回复客户端。客户端C 收到回复后,整个网络达成共识,消息提交到本地数据库。
1.2 PBFT 算法容错性
PBFT 算法可以容忍不超过(N-1)/3 个恶意或故障节点(N为节点总数),式(1)如果有f个恶意节点,正常节点的数量至少为f+1 个,节点总数至少为2f+1 个,才能让系统正常运转。式(2)如果存在极端情况,有f个恶意节点以及f个故障节点,要保证系统能顺利达成共识,节点总数至少为3f+1 个。
1.3 PBFT 算法存在的缺陷
虽然PBFT 算法在联盟链中得到了广泛的应用,但是仍然存在很多问题[23],例如:主节点的选取存在安全风险。如果多次选择恶意节点作为主节点,共识效率将显著降低,从而浪费系统资源,降低系统的稳定性和可靠性;客户端只向主节点发送请求,当请求太多时会给主节点带来太多的负担,不适合区块链的P2P 网络环境;算法可伸缩性较差,网络通信开销较高,需要进行3 次广播通信来实现异步模式下的安全性,消耗了大量的资源;算法动态性较差,没有完善的节点加入和退出机制,节点加入和退出时,整个网络需要重启,开销较大。
2 CBFT 共识算法
CBFT 算法是一种安全高效的拜占庭容错共识算法,其相比PBFT 算法主要引入了2 个新的阶段:一个是分组策略,另一个为信用模型。分组策略将大量节点划分为多个组,以减少共识节点的规模,简化共识的复杂性;信用模型选择节点信用值作为主要参考,将信用值较高的节点作为管理节点,可以有效降低管理节点是拜占庭节点的概率,从而减小系统开销,提高共识效率。CBFT 共识流程如图2所示。
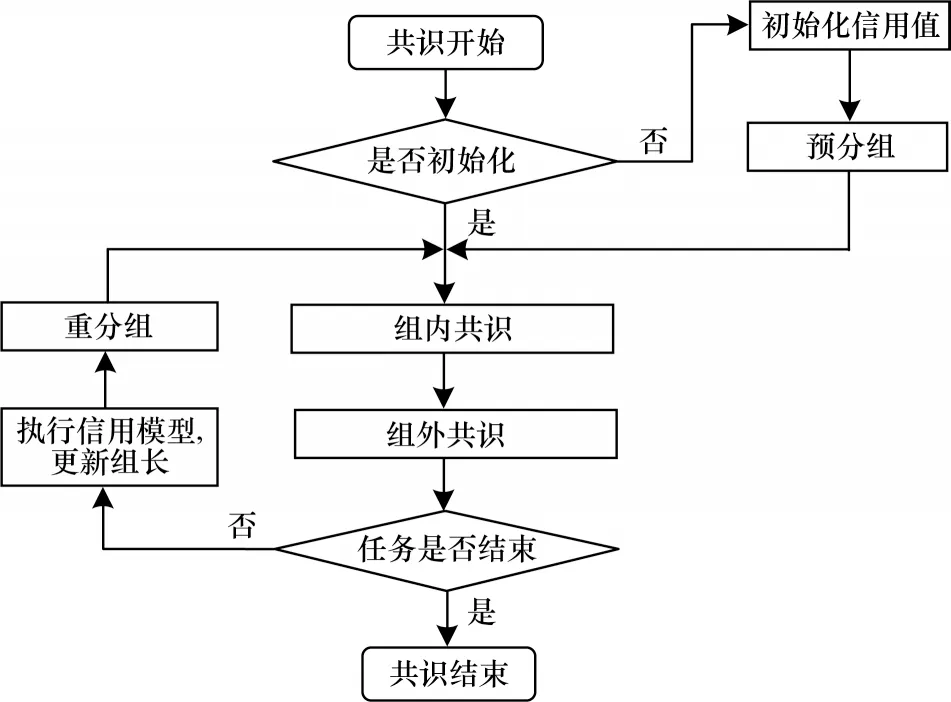
图2 CBFT 共识流程Fig.2 CBFT consensus procedure
2.1 分组策略
基于节点之间的响应速度设计分组策略,以最大限度地提高各节点间的通信效率。具体步骤如下:
1)利用节点加入联盟链的身份验证机制,随机选取m个节点作为初始管理节点,以其余节点对管理节点的响应速度作为分组依据,将节点划分为G个共识集。
2)管理节点i检查组内成员列表Gi,判断节点数量是否大于Nmax:若节点数量大于Nmax,则不再允许组内加入新节点;若节点数量小于Nmax,则广播接收成员消息
3)节点x收到管理节点的广播消息后,验证消息签名是否正确,无误则向管理节点发起入组申请
4)管理节点收到入组申请,验证无误,将节点x加入组内成员列表Gi并向其发送消息确认
5)分组结束,管理节点广播各自的小组列表Gi,若验证无误,将该信息下发至各组内成员,完成分组确认。
管理节点是组内信用值最高的节点,其作为本组的委托代理节点参与全局共识。因此,经过一轮共识后,更新节点信用值,根据节点的新信用值选择一个新的管理节点,并按上述流程重新分组。
针对PBFT 中节点不能动态连接的问题,CBFT建立了节点准入与退出机制。准入与退出机制可以使授权节点在不影响系统结构的情况下动态加入共识网络,如图3 所示。
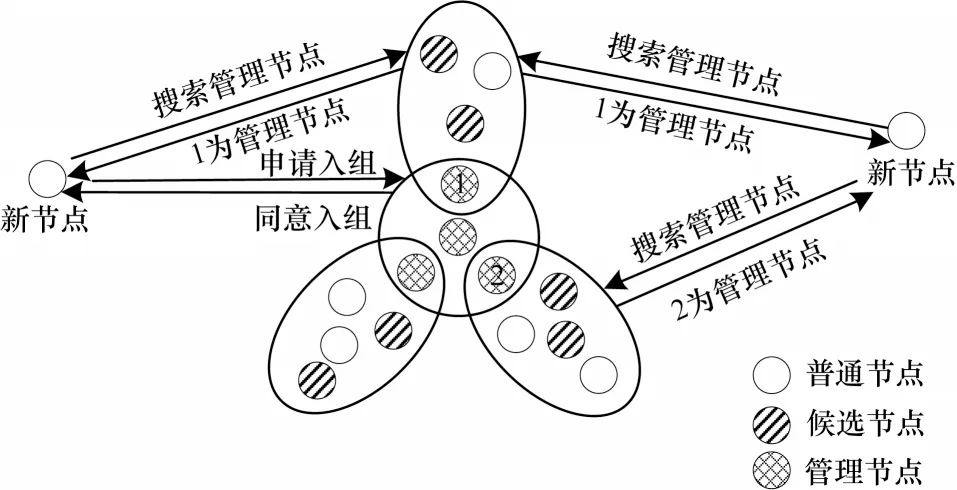
图3 新节点入组过程Fig.3 New node entry process
1)节点准入机制。当新节点要加入网络时,首先寻找最近的管理节点,向周围节点发送搜寻请求,节点将管理节点的信息转发给新节点并附带时间戳,对比时间戳,向先收到回复的节点的管理节点发送入组申请,管理节点需要将新节点信息添加至组内成员列表,并向新节点提供组内其他节点的信息,则新节点加入网络完成。新节点进入网络后为普通节点,不参与共识,只接收共识结果。
2)节点退出机制。若退出网络的为管理节点,首先要广播消息将身份降为候选节点,等待新的管理节点选举成功,然后向管理节点报告退出;若是候选节点或普通节点退出网络,则直接向管理节点提出申请即可。
2.2 信用模型
PBFT 算法根据公式p=vmodN按顺序确定主节点,异常节点很可能被选为主节点,影响系统的安全[14]。在改进的CBFT 算法中,引入信用模型评估节点的信用状态,对网络中的共识节点分类,优化主节点的选举,提高信用值高的节点成为主节点的概率,减少恶意节点对系统的破坏,从而提高整个网络的效率。
本文提出的信用模型将节点信用值区间设置为[0,100],初始值为30,并根据信用值的大小,将参与CBFT 共识的节点分为管理节点、候选节点、普通节点等3 类。管理节点和候选节点都是共识节点,普通节点信用值偏低,只接收共识结果,不参与共识过程。不同区间的信用值划分的节点类别如表1所示。

表1 不同节点信用值划分的节点类别Table 1 Node categories devided by different node credit value
为了评估节点当前的信用值,以节点的响应性能、历史信用值、选举投票的完成情况和达成交易共识的正确率等数据作为衡量指标[24-26],对节点可信度进行测量。
定义1延迟指数指对各种消息响应过程中的延迟,表达式如下:
其中:dij表示节点i第j笔交易的延迟;dmax表示交易所允许的最大延迟,如果超过最大延迟,则表示节点未能执行该交易。
定义2带惩罚机制的交易完成率指进入网络后节点成功参与各交易的比例,表达式如下:
其中:n为系统交易总数;m表示节点i完成的交易数量;μ为交易是否成功的标识符,交易成功μ=1,交易失败μ=-1,这样既考虑了成功完成交易对节点的促进作用,又考虑了影响交易正常进行对节点的不良影响,能够更好地区分节点的信用值。
定义3历史信用值的影响指当前节点的信用状态受历史信用值的影响,表达式如下:
其中:系数z表示历史状态影响的程度。
定义4 节点的最终信用分数计算公式如下:
其中:x为节点交易延迟的权重;y为节点自身完成交易的权重;x+y+z=1。信用模型直观地反映了节点在共识中的性能。如果节点延迟小,交易完成率高,历史信用值好,则可信度高;反之,节点延迟大,交易完成率低,历史信用值差,则可信度低。
2.3 CBFT 改进共识流程
CBFT 共识算法包含组内外共识,主要实现参与共识的节点之间的共识。组员节点接收管理节点广播,在组内准备和确认阶段,管理节点接收到足够的建议信息,当组外准备阶段完成时,意味着已经有足够多的节点验证并通过了客户端发起的提议,组外的确认阶段仅是对提议在准备阶段通过的确认,确保有足够的节点完成对提议的验证。因此,组外的三阶段协议可以优化为2 个阶段,如图4所示。
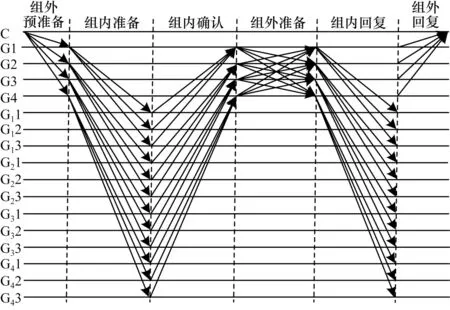
图4 CBFT 改进共识流程Fig.4 Improved CBFT consensus procedure
具体共识流程如下:
1)组外预准备阶段。收到来自客户端的请求后,管理节点对请求进行验证和排序,并向组员广播预准备消息
2)组内准备阶段。组员接收预准备消息并进行验证,此时网络中的所有节点已接收预准备消息。
3)组内确认阶段。组员验证提议,若无误则将对提议的回应
4)组外准备阶段。管理节点收到足够数量组员的回应,开启全局共识,向所有管理节点广播组内共识的结果
5)组内回复阶段。若管理节点收到超过2f个相同的消息,则向组内成员发送请求确认
6)组外回复阶段。同时,管理节点回复客户端
3 实验与结果分析
3.1 实验环境
基于Java 编程语言模拟实现一个区块链系统,实验的初始条件如下:硬件条件为CPU AMD R7 5800H,内存为16 GB,操作系统为Windows 10 64 位,软件环境为Eclipse 4.21。在该系统中对CBFT 算法进行验证,分别对20、25、30、35、40、45、50 个节点从安全性、时延、通信开销、吞吐量等4 个方面来评估算法的性能。实验进行1 000 次,每次客户端发送200 个请求消息,取1 000 次的平均值作为测试结果。
3.2 安全性
CBFT 算法基于实用拜占庭容错机制改进,由于算法没有改变PBFT 的核心容错机制,因此组长间的共识容错性与PBFT 的拜占庭攻击容错性相同,但CBFT 算法基于分组策略与信用模型,使组内可以容忍更多的拜占庭节点,例如,若组内全为拜占庭节点,组长参与组外PBFT 共识,仅代表一个拜占庭节点;若组内拜占庭节点数小于50%,组外组长则作为正常节点参与共识,因此,CBFT 算法能容忍的最大拜占庭节点数为1/3 组内节点全为拜占庭节点与2/3 组内拜占庭节点占比小于50%的数量之和。综上,在同等条件下采用CBFT 共识协议容错性更高,且区块链网络会在一段时间的共识后提高容错性,提高共识效率和系统整体可信度。
图5 为不同数量节点下PBFT、GRBFT[27]、CBFT算法最大可容忍恶意节点数的变化情况。从图中可以看出,随着节点数量的增加,CBFT 算法比PBFT、GRBFT 算法可以容忍更多的恶意节点数,因此CBFT 算法具有更好的安全性。
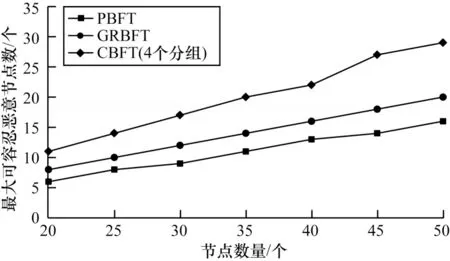
图5 PBFT、GRBFT 和CBFT 算法最大可容忍恶意节点数Fig.5 Maximum number of malicious nodes tolerated by PBFT,GRBFT,and CBFT algorithms
3.3 共识延迟
共识延迟是指从交易开始到交易结束所经历的时间,是共识算法运行速度的一个重要指标,较低的共识延迟可以使交易迅速得到确认,使系统更加安全和实用。共识延迟公式表示如下:
其中:Tc表示交易确认时间;Tr表示交易生成时间。从图6 中可以看出,共识延迟随着节点的增加而逐渐增加,但CBFT 的共识延迟明显低于PBFT 和GRBFT 算法,随着节点数的增加,PBFT 的延迟迅速增加,而CBFT 的延迟增加相对较缓慢。产生上述结果的主要原因是CBFT 的分组策略减少了参与共识的节点数量和节点间相互发送的信息量。因此,当参与共识节点数量较多时,CBFT 仍然可以保证较高的共识度。
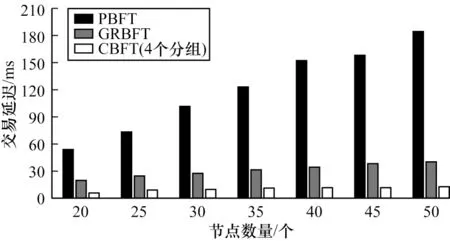
图6 PBFT、GRBFT 和CBFT 算法共识延迟Fig.6 Consensus latency of PBFT,GRBFT,and CBFT algorithms
3.4 通信开销
通信开销是指系统中的节点执行共识算法时所产生的通信次数。假设每个共识集的节点数量是相同的(不少于3 个),共识集的数量应该不少于4 个,系统总节点数为N个(N>12)。在PBFT 中有3 个阶段需要发送消息以进行通信。首先,客户端将请求发送到主节点,主节点将预准备消息发送到所有从节点,预准备阶段的通信开销为(N-1)次;然后,节点接收到消息后,验证并发送准备阶段的消息,此阶段的通信开销为(N-1)2次;最后,在确认阶段,节点接收准备消息,当验证结果一致时,提交的消息将被发送给所有节点,此阶段的通信开销为N(N-1)次。根据上述3 个阶段的通信开销,简化得到PBFT 算法完成一致性协议的通信开销T1计算式如下:
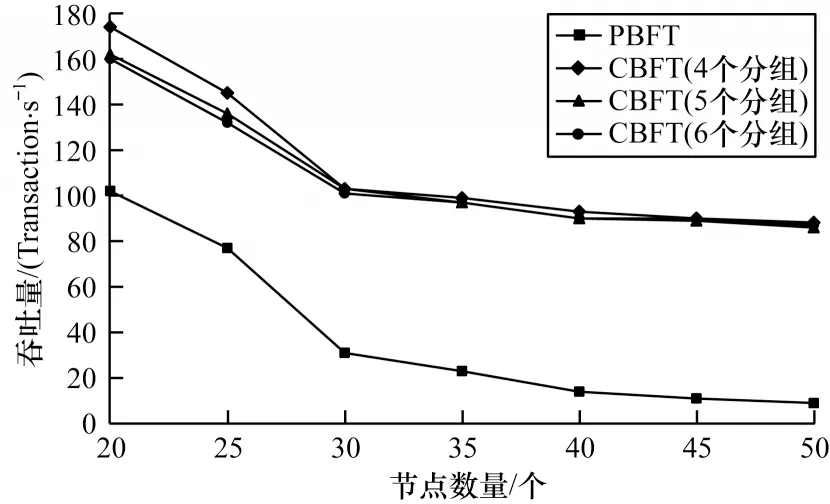
当N>12 时,T4 图7 显示了CBFT、GRBFT 和PBFT 共识算法通信开销的比较。可以看出,在整个区块链网络中,CBFT的通信开销要小得多且随着共识节点数量的增加,通信开销增长缓慢。例如,当网络节点数量为30 个时,PBFT 的通信开销为1 916 次,CBFT 的通信开销为897次(4个分组),通信开销较PBFT 降低了53.2%。 图7 PBFT、GRBFT 和CBFT 算法通信开销Fig.7 Communications overhead of PBFT,GRBFT,and CBFT algorithms 在区块链系统中,吞吐量是指系统在单位时间内处理的事务数,是衡量系统并发处理能力的重要指标。吞吐量计算公式如下: 其中:TTransactions,Δt表示Δt时间内处理的事务数。 为了验证分组策略,分别设置分组数为4、5、6,测试CBFT 算法在不同节点数量下的系统吞吐量,从图8 中可以看出,CBFT 共识算法的分组数量对系统吞吐量的影响很小,其吞吐量始终高于传统的PBFT 共识算法。PBFT 算法在节点数超过25 个后,吞吐量迅速下降,但即使节点数超过40 个时,CBFT依然保持较高的吞吐量。随着节点数量的增加,2 种算法的吞吐量均呈下降趋势,但CBFT 算法具有更高的吞吐量,并且随着节点数量的增加,优势更加明显,因此,在一个大型的联盟链中,CBFT 算法可以保持高效率和稳定性。 图8 PBFT、CBFT 算法吞吐量Fig.8 Throughput of PBFT,CBFT algorithms PBFT 算法所支持的网络规模有限,不利于大型联盟链的发展。针对该问题,本文提出基于分组和信用分级的改进CBFT 算法,将大规模网络节点划分为不同的共识集并基于信用值选择共识节点。仿真结果表明,与PBFT、GRBFT 算法相比,CBFT 在安全性、时延、通信开销和吞吐量等方面都有显著改善,提高了系统的性能以及可靠性。在未来的工作中,将研究如何进行节点身份认证,以进一步提高系统安全,促进区块链的发展。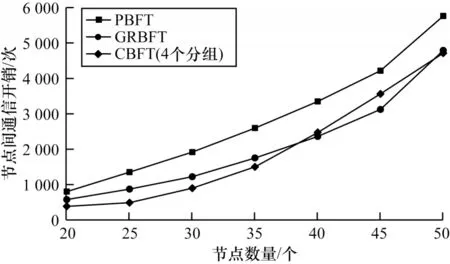
3.5 吞吐量
4 结束语
猜你喜欢
小学生学习指导(当代教科研)(2021年6期)2021-05-23
马克思主义哲学研究(2020年1期)2020-11-26
内蒙古民族大学学报(社会科学版)(2020年1期)2020-11-03
课程教育研究(2020年7期)2020-04-21
人大建设(2019年12期)2019-11-18
中学历史教学(2018年1期)2018-04-04
古代文明(2016年1期)2016-10-21
凤凰生活(2016年2期)2016-02-01
现代教育科学·中学教师(2015年2期)2015-10-21
现代教育科学·中学教师(2015年3期)2015-10-21
