
FRKDNet:基于知识蒸馏的特征提炼语义分割网络
2023-11-18 12:13:12蒋诗怡李丹杨范润泽
液晶与显示 2023年11期
蒋诗怡,徐 杨,2*,李丹杨,范润泽
(1.贵州大学 大数据与信息工程学院,贵州 贵阳 550025;2.贵阳铝镁设计研究院有限公司,贵州 贵阳 550009)
1 引 言
语义分割的目的是为输入图像的每个像素进行分类,也是计算机视觉中一项基础且富有挑战性的任务,目前已广泛应用到多个领域,如自动驾驶[1-2]、行人分割[3]、遥感监测[4-5]等。近年来,由于深度学习在计算机视觉领域的成功,基于卷积神经网络(Convolutional Neural Network,CNN)的方法大幅提高了语义分割的准确性。然而,基于CNN 的语义分割算法通常具有较高的计算成本,这也限制了网络模型在实际中的应用与部署,特别是在对效率要求较高的现实任务中。
为了解决上述问题,研究人员探索了网络轻量化的方式。Paszke 等人[6]重新设计了网络架构降低模型参数量,提高了推理速度。Zhao 等人[7]提出级联特征融合单元和级联标签指导策略整合中等和高分辨率特征,提炼了粗糙的语义预测图。尽管研究人员已经设计了优秀的网络来减少计算成本,但很难在精度和模型大小之间达到令人满意的效果。针对这一问题,我们采用知识蒸馏(Knowledge Distillation,KD)[8]的策略,通过在训练过程中蒸馏较大模型(教师网络)的知识来提高高效轻量模型(学生网络)的性能。
KD 作为一种模型压缩的方法,最初用于图像分类任务中,其能够显著简化繁琐的模型。由于KD 的优势,一些语义分割方法使用KD 来减小模型的大小。这些方法让学生网络从教师网络学习像素特征和类内特征的变化,具有代表性的是类内特征方差蒸馏(Intra-class Feature Variation Distillation,IFVD)[9],侧重于将类内特征的差异从教师网络转移到学生网络。通道知识蒸馏(Channel-wise Knowledge Distillation,CD)[10]强调在每个通道中提取最重要的区域。值得注意的是,语义分割是一项包含各种类别的像素级类别预测任务,因此在语义分割中,特征空间中的类间距离是普遍存在的。教师网络借助众多参数和复杂的网络结构,在特征空间中具有较强的分类能力和较大的类间距离。但以往方法仍存在一定的问题:(1)以往的语义分割KD 方案忽略了将教师网络特征空间中的类间距离与类内距离转移到学生网络;(2)由于学生网络结构简单,参数量较少,学生网络不能像教师网络那样编码丰富的位置特征信息;(3)教师网络结构复杂,参数量大,输出内容包括前景知识内容和背景噪声,对学生网络来说伪知识的判别也是知识蒸馏过程中的一大难题。为了解决上述问题,我们设计了基于知识蒸馏的特征提炼语义分割模型(Feature Refine Semantic Segmentation Network based on Knowledge Distillation,FRKDNet),首先设计了一种特征提炼方法(Feature Refine,FR),来分离蒸馏知识的前景内容与背景噪声,在特征提炼的帮助下过滤伪知识,将更准确的特征内容传递给学生网络。其次考虑在特征空间的隐式编码中提取类间距离与类内距离,从而得到相应的特征坐标掩码,分离相应的特征位置信息,学生网络通过模拟特征位置信息来最小化与教师网络特征位置的输出从而提高学生网络的分割精度。
2 本文模型
2.1 网络结构
本文提出一种基于教师-学生模型的知识蒸馏模型,总体模型架构如图1 所示。整体架构由教师网络、学生网络、特征提炼模块、类内距离计算模块与类间距离计算模块组成。对于教师网络和学生网络,我们使用经典的编码器-解码器结构提取图像特征并输出相应的像素分类概率分布特征图。知识蒸馏一般需要一个强大的教师网络,而要获得更详细的图像特征,就需要一个足够深的教师网络。具体而言,我们将图像分批输入到教师网络和学生网络中进行训练,获得各自的输出特征图。针对以往知识蒸馏方法中教师网络传递的知识复杂、特征与噪声混合的情况,为了排除伪知识对蒸馏的影响,减少背景噪音,我们设计了知识提炼模块将教师网络输出的特征图中的显著知识与背景噪声分离开。在分离过程中,通过计算每个像素分类特征与当前所属类别的信息熵差值并保留信息量大的显著信息,从而得到新的特征提炼矩阵,并分别与教师网络和学生网络的原始输出特征相乘得到含有显著信息的特征图。针对以往方法中忽略特征内部特性,不同类物体之间差别不明显,同类物体之间特征不突出的问题,通过提出的类间距离计算模块与类内距离计算模块分别计算教师网络与学生网络的蒸馏损失,同时计算学生网络的原始输出与实际标签的损失函数,合并作为整个模型的损失函数一起反向传播。

图1 网络模型结构Fig.1 Network structure of model
2.2 特征提炼模块
特征提炼是一种过滤无用信息,提炼显著信息的过程。在教师网络蒸馏的知识中通常含有一些背景噪音,通过特征提炼选择显著且丰富的知识进行蒸馏与距离计算,从而减少在蒸馏与知识传递的过程中噪声的影响。文献[8]表明,可以引入与教师网络相关的软目标来引导学生网络训练。对于语义分割任务来说,每一个像素都会输出一个像素分类概率,基于知识蒸馏的语义分割任务也是最小化像素间的概率误差,因此我们认为网络特征图中像素对应的值与所属类别对应的比例即为当前像素的类别贡献,贡献越大的即为显著特征。将原始网络输出的特征图中的像素值转换为对应的类别预测概率,从而计算该像素点对整个类别预测的贡献值,其中预测贡献值为该像素值除以整个类别像素预测总和,如式(1)所示:
其中p(x)为该像素的输出值。对于教师网络的输出特征Ft∈RC×H×W,其中C为通道数,H与W为空间维度,故先通过Softmax 函数将特征图展开为二维形式并通过式(1)计算当前位置的贡献值,与当前像素值相乘得到对应的显著特征,如式(2)、(3)所示:
其中:xi、xj为像素值,Q(x)为当前像素经过Softmax 函数后的所得值,M(x)为经过特征提炼后的新特征值。通过特征提炼,对特征贡献大的像素点信息保留,对贡献小的像素点剔除置0 处理,得到新的特征矩阵MF,最后将新特征矩阵与师生网络输出的原始特征图相乘,可得显著特征矩阵,如式(4)、(5)所示:
其中:Ft、Fs为教师学生网络的原始输出矩阵,、为新的显著特征矩阵。特征提炼模块如图2 所示。
2.3 距离计算模块
2.3.1 类间距离计算模块
语义分割是基于像素的分类任务,相比于教师网络而言,学生网络的结构相对简单,参数少,对应的识别精度较低,类间距离也会相应的较小。针对特征提炼后的特征图,本文通过对应坐标来编码类间类别距离,类别总数可表示为:
其中:N代表图像语义分割的类别总数;ci表示第i类的相对位置,其是通过特征提炼所得到的平均值。设Di,j为第i类和第j类类别中心的欧氏距离,如式(7)所示:
教师网络的网络深,参数量大。为了使学生网络更好地在类间距离上模拟教师网络,我们设计了类间距离损失函数Linter(T,S),T为教师网络,S为学生网络,如式(8)所示:
2.3.2 类内距离计算模块
不同于分类网络,分割网络往往是区域内的像素通过预测展现分类结果。除了类间距离,对于每个类来说,不同的像素预测值也是包含信息的。从教师蒸馏来的先验信息占有更大比例的数值往往会“引领”对应的类别,而分配在该类中过小的数值有可能在下一轮预测中分配到其他类别中。因此,我们希望能够提取到相应的类内距离信息从而提高分割的准确度。定义类内距离损失函数Lintra(T,S)如式(9)所示:
其中:E为第i类的边缘像素特征点数量,ei表示第i类的边缘特征点,ei0表示特征提炼得到的该类别对应特征点。距离计算模块如图3 所示。
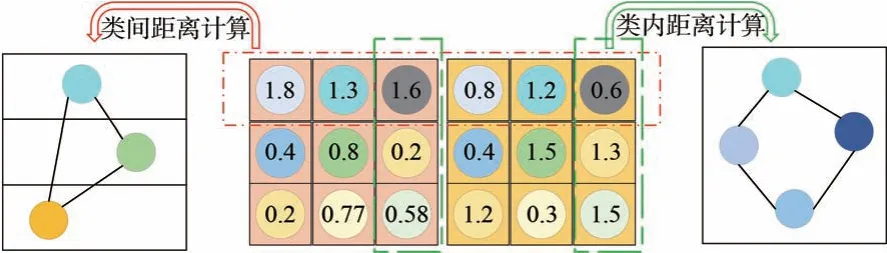
图3 距离计算模块Fig.3 Distance calculation module
2.3.3 知识蒸馏损失函数设计
对于整体知识蒸馏损失函数设计,我们采用与文献[8]相似的计算方式。该方法通过分别计算教师网络和学生网络对应的输出特征图的内积得到自己的相似矩阵,然后使用均方差计算两个相似矩阵,使得教师网络和学生网络在同一类别与不同类别的分类上产生相似的结果输出,同时结合类间距离和类内距离,使学生网络在对应的特征映射上保留与教师网络相似的知识。因此,模型的损失函数由类间损失函数Linter、类内距离损失函数Lintra以及与标签的交叉熵损失函数Lcls3 部分组成,如式(10)所示:
其中:γ为平衡因子,ps为学生网络的原始预测,g为真实标签。整体算法伪代码如算法1 所示。

3 实验结果及分析
3.1 实验设置及数据集介绍
为了验证所提出的基于知识蒸馏的语义分割模型的有效性,我们在两个公开数据集上进行实验:(1)Cityscape[11]是一个包含19 类城市道路场景的数据集,包含了2 975 张训练图像、500 张验证图像以及1 525 张测试图像。(2)Pascal VOC[12]由1 464 张训练图像、1 449 张验证图像以及1 456 张测试图像组成,是一个用来做图像分割与目标检测的数据集。实验环境选择CPU 为AMD Ryzen 9 处理器,内存为64G,GPU 使 用RTX3090,采用梯度下降法训练模型,优化器选择Adam 并动态调整学习率,初始学习率设置为0.002。另外,由于数据集分类数与复杂程度不同,我们设置了不同的平衡因子。对于VOC 数据集,γ设置为0.5;对于Cityscapes,γ设置为0.4。
为了更好地评估模型效果,我们选择平均交并比(Mean Intersection over Union,MIoU)作为结果的评价标准。MIoU 如式(11)所示:
其中:pij表示真实值为i,被预测为j的数量;k+1是类别个数(包含空类别);pii是真正的数量。MIoU 一般都是基于类别进行计算的,将每一类的IoU 计算后累加再进行平均得到基于全局的评价。
对于网络架构,在本文所有的实验中选择DeepLabV3+[13]作为语义分割网络的主体架构。经 过ImageNet[14]预训练 的ResNet101[15]作为教师模型的骨干网络。对于学生模型,我们使用ResNet18 作为骨干网络。
3.2 消融实验
所设计的蒸馏损失共包含3个损失函数:Linter、Lintra以及Lcls。为了验证每一个损失函数的有效性,我们在Cityscapes 验证集上进行了验证实验。教师网络采用ResNet101 作为骨干网络的Deep-LabV3+,学生网络选择ResNet18 作为骨干网络的DeepLabV3+,实验结果如表1 所示。其中,T代表教师网络,S代表学生网络。从表1 中可以看出,特征提炼模块的添加使得分割精度提高至74.33%,类间距离损失函数Linter使模型分割精度由74.33%提高到75.61%,类内距离损失函数Lintra也使网络分割精度提高了近0.7%。使用本文设计的蒸馏模型后,整体的分割精度达到76.53%,接近教师网络77.76%的准确度。实验证明我们提出的特征提炼模块与蒸馏损失函数是有效的;(1)特征提炼模块具有较好的分离特征与背景噪声的能力,并对类内差异与类间距离有着较明显的分割效果;(2)通过类内距离与类间距离分割获得了更丰富的教师网络知识,较基准网络提高了6.17%。综上所述,我们提出的方法提高了教师网络对学生网络的知识输出,改善了师生网络间知识的传递。

表1 消融实验Tab.1 Ablation experiment
调整损失函数中的平衡因子γ是提高整体网络性能的关键。在针对平衡因子的消融实验中,在Pascal VOC 数据集 中,将γ设置为0.3、0.4、0.5 和0.6;在Cityscapes 数据集中,将γ设置为0.3、0.4、0.5。实验结果如图4 所示,可以看出,在Pascal VOC 数据集上的实验中,γ=0.3 时,整个知识蒸馏的提升效果并不显著;而当γ=0.6时,知识蒸馏的权重过高,自身预测结果对比真实标签的损失函数影响过低,忽略了真实值对整体模型的监督。Cityscapes 数据集的表现同样如此,γ=0.4 时的效果最好。
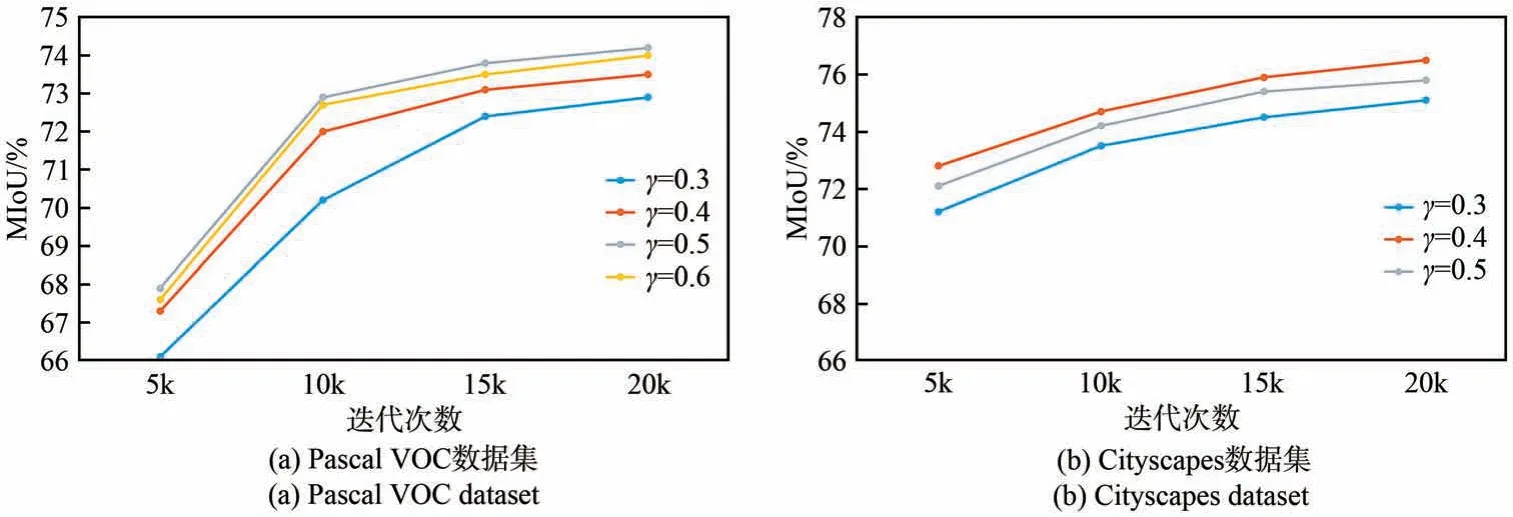
图4 超参数消融实验结果Fig.4 Results of hyperparameter ablation experiment
3.3 对比实验
3.3.1 针对Cityscapes 数据集的对比实验
为了进一步验证本文提出方法的有效性,我们与主流的蒸馏方法进行对比,如SKD(Knowledge adaptation for efficient semantic segmentation)[16]、SKDD(Structured knowledge distillation for dense prediction)[17]、IFVD[9]以及CD[10],实验在相同的网络主架构上进行,实验结果如表2 所示。由于不同的知识蒸馏方法均不改变原始原生网络架构,故学生网络对应不同方法的参数量与计算量均为14.07M 与270.5G。

表2 不同方法的对比实验Tab.2 Comparison of experimental results of different methods
从表2 可以看出,学生网络的分割结果与教师网络相差甚微,其中模型参数量与每秒浮点运算次数(FLOPs)差别明显,在知识蒸馏后学生网络的分割效果得到了提高。与主流的知识蒸馏方法相比,我们所提出的方法的分割效果在原始的学生模型中有着显著的提高,在Pascal VOC 与Cityscapes 数据集上分别有2.04%与4.45%的提升,由此能够证明我们提出的方法在多个数据集中有着更好的分割性能。
我们在Cityscapes 测试集上对比了一些轻量化网络模型,实验结果如表3 所示。
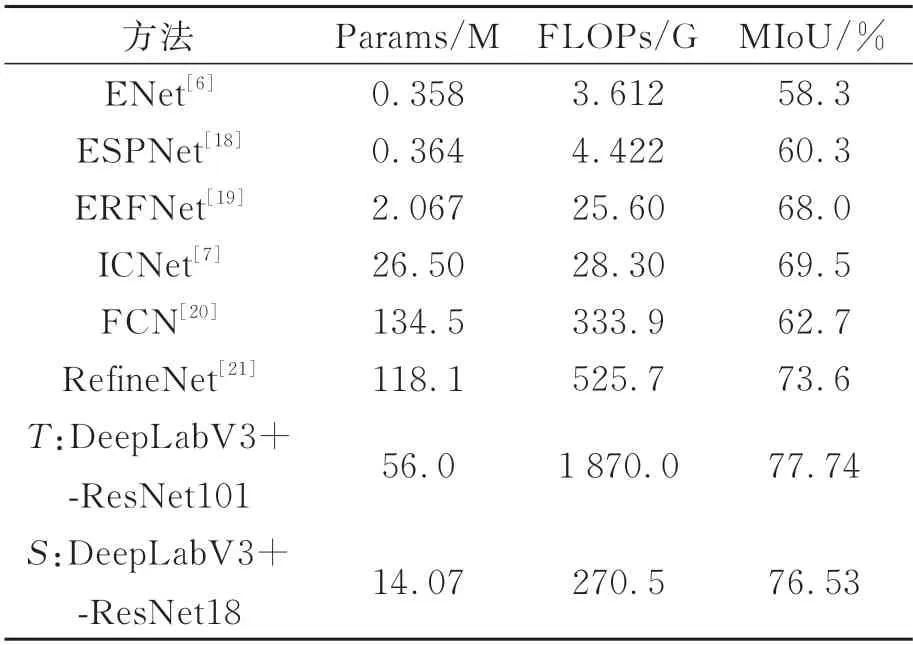
表3 不同方法在Cityscapes 测试集上的对比实验Tab.3 Comparative experiment of different methods in Cityscapes
本文设计的特征提炼模块细化了内部特征,充分分离了前景特征与背景噪声,不额外添加网络计算量。与教师网络相比,我们的参数量与FLOPs 大幅降低,分割精度仅降低了1.21%。与其他轻量化模型相比,我们所设计的模型有着显著优势。类内距离计算模块与类间距离计算模块使得蒸馏传递的知识更加细化,特征内部特性更加清晰,经过知识蒸馏后的网络模型分割精度比绝大部分轻量化模型都更高。与ICNet相比,我们的参数量只有其1/2,分割精度却比ICNet 高7%;与RefineNet 相比,参数量大幅降低。学生网络在分割精度相对较高的同时,参数量与FLOPs 都明显更轻量化。
为了更直观地对比图像分割的性能差异,我们对原始学生网络,CD[10]以及所提出的模型进行分割可视化,结果如图5 所示。

图5 Cityscapes 分割结果可视化Fig.5 Segmentation results of Cityscapes
根据分割结果可以看出,由于本文提出特征提炼的方法,分离了蒸馏知识的前景内容与背景噪声,同时在特征空间的隐式编码中提取类间距离和类内距离作为蒸馏损失,在图像类别相近或内容重叠的部分相比于CD 分割的效果更好,如Cityscapes 中第三行的路边栏杆所示,有着更清楚的划分。
另外,我们还在Cityscapes 验证集上对比了不同类别的MIoU,实验结果如图6 所示。
从图6 中可以看到,所设计的方法对于每个小类别有着更好的分割表现。得益于对类间距离、类内距离知识蒸馏效果的提升,所设计的方法对一些重叠位置信息的内容有着更好的表现,如骑手、小汽车、自行车等。骑手的分割精度相比于IFVD 提升近7%,比CD提高了1.8%;自行车的分割精度比IFVD 提高了5%,比CD 提升了4.3%。
3.3.2 针对Pascal VOC 数据集的对比实验
我们在Pascal VOC 验证集上对比了不同网络的参数和精度,如OCRNet(Object-contextual representations for semantic segmentation)[22]、DeeplabV3+[13]、FCN(Fully Convolutional Networks)[20]、ANN(Asymmetric non-local neural networks)[23]和PSPNet-ResNet101[24]。通过知识提炼以及类间与类内距离的蒸馏损失函数设计,DeeplabV3+-ResNet18 分别比FCN 和ANN 提高了7.81%和1.03%。实验结果如图7 所示。

图7 Pascal VOC 验证集分割结果对比Fig.7 Comparison of segmentation results of Pascal VOC validation
同时,我们采用ResNet18 与MobileNetV2 作为学生网络在验证集上验证了所设计方法的有效性,实验结果如图8 所示。

图8 不同骨干网络对比Fig.8 Comparison of different backbone networks
当以MobileNetV2 作为学生网络的骨干时,本文方法比知识蒸馏的原始网络模型的分割准确率提高了4%,比IFVD 和CD 分别提高了2.1%和0.7%。在以ResNet18为骨干网络的模型中,对比原始网络,本文方法提高了2.03%;对比IFVD与CD,本文方法分别提高了1.52%与0.12%。我们同样也对分割结果进行了可视化对比,如图9所示。
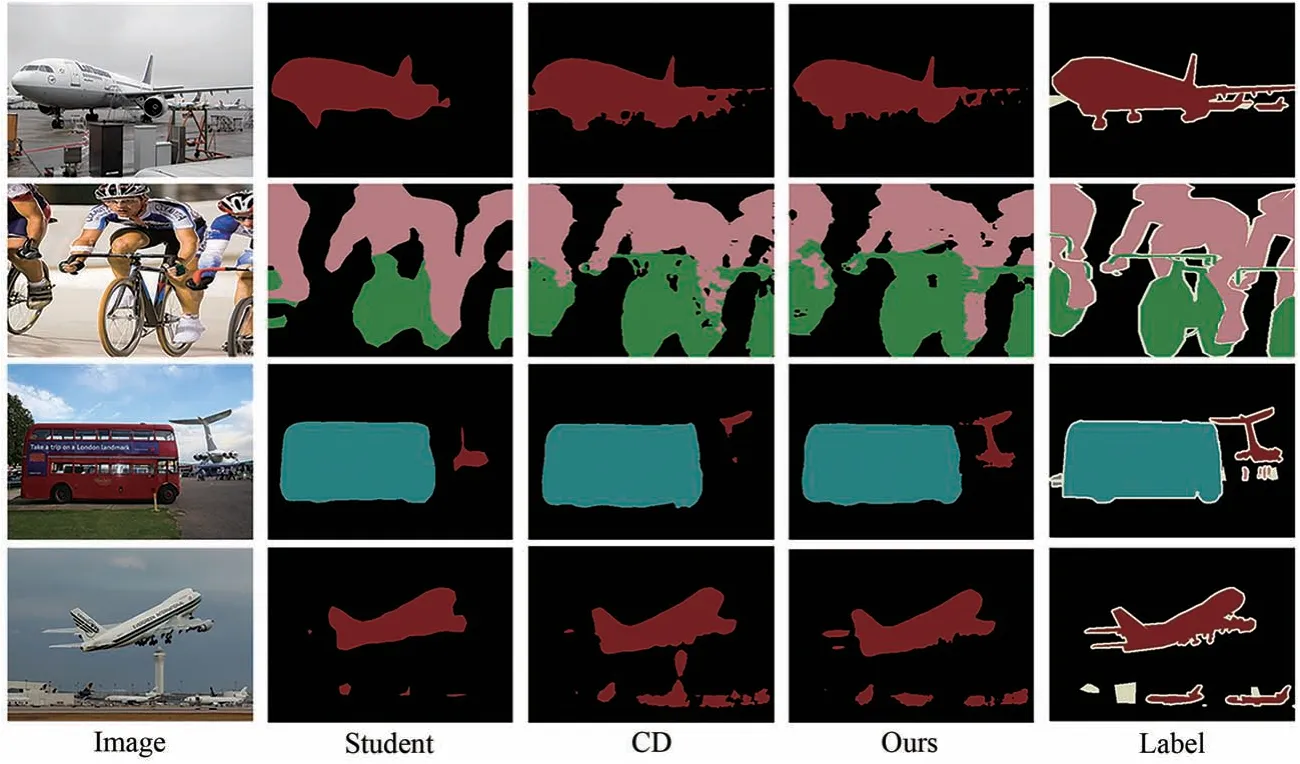
图9 Pascal VOC 分割结果可视化Fig.9 Segmentation results of Pascal VOC
可以看到,由于使用了类间距离与类内距离作为蒸馏损失,在空间位置相近的物体分割中,本文方法表现得更加优秀,如第二行自行车与人体边界的划分,第三行中远处建筑物的分割。
4 结 论
本文提出的基于知识蒸馏的特征提炼语义分割模型能够更好地分离蒸馏知识的有效内容和噪声,更准确地将特征信息传递给学生网络。同时,本文网络在特征空间的隐式编码中提取类间距离与类内距离,从而获取到相应的特征位置信息,之后学生网络通过模拟特征位置信息来最小化与教师网络特征位置的输出,从而提高了学生网络的分割精度。实验结果表明,本文提出的方法在Pascal VOC 数据集上的MIoU 达到74.19%,在Cityscapes 数据集上的MIoU 达到76.53%,分别比原始学生网络提高了2.04%和4.48%,具有较好的语义分割效果,证明了本文方法的有效性。
猜你喜欢
无线互联科技(2020年22期)2021-01-11 13:52:34
弹箭与制导学报(2020年2期)2020-09-01 02:08:56
开放教育研究(2020年2期)2020-03-31 01:54:14
传感器与微系统(2018年7期)2018-08-29 00:44:42
自动化学报(2017年4期)2017-06-15 20:28:55
现代语文(2016年21期)2016-05-25 13:13:44
新校长(2016年8期)2016-01-10 06:43:59
大连民族大学学报(2015年2期)2015-02-27 08:28:11
商事法论集(2014年1期)2014-06-27 01:20:42
中国中医药现代远程教育(2014年16期)2014-03-01 04:28:46
