
Dynamic Task Offloading for Digital Twin-Empowered Mobile Edge Computing via Deep Reinforcement Learning
2023-11-18 08:38YingChenWeiGuJiajieXuYongchaoZhangGeyongMin
China Communications 2023年11期
Ying Chen ,Wei Gu ,Jiajie Xu ,Yongchao Zhang ,Geyong Min
1 School of Computer,Beijing Information Science and Technology University,Beijing 100101,China
2 University of Exeter,Exeter,EX4 4QF,United Kingdom
*The corresponding author,email: chenying@bistu.edu.cn
Abstract: Limited by battery and computing resources,the computing-intensive tasks generated by Internet of Things (IoT) devices cannot be processed all by themselves.Mobile edge computing (MEC) is a suitable solution for this problem,and the generated tasks can be offloaded from IoT devices to MEC.In this paper,we study the problem of dynamic task offloading for digital twin-empowered MEC.Digital twin techniques are applied to provide information of environment and share the training data of agent deployed on IoT devices.We formulate the task offloading problem with the goal of maximizing the energy efficiency and the workload balance among the ESs.Then,we reformulate the problem as an MDP problem and design DRL-based energy efficient task offloading(DEETO) algorithm to solve it.Comparative experiments are carried out which show the superiority of our DEETO algorithm in improving energy efficiency and balancing the workload.
Keywords: deep reinforcement learning;digital twin;Internet of Things;mobile edge computing
I.INTRODUCTION
6G which provides high transmission rate and low latency services has attracted extensive attention from both academia and industry [1,2].The development of 6G greatly promotes the progress of the Internet of things(IoT).Besides,Mobile Edge Computing(MEC)can provide services for massive IoT devices with the help of 6G [3–5].However,with the rapid increase of IoT device number,massive amount of computing intensive tasks generated by IoT devices need to be offload to the edge servers(ES)[6,7].
The complex offloading problems in MEC usually involve multiple IoT devices.Moreover,due to the randomness of task generation and the heterogeneity of ESs,multiple ESs need to coordinate with each other to deal with a large number of bursty tasks[8,9].Therefore,the scheduling of multiple ESs requires a suitable offloading algorithm.Artificial intelligence(AI)has been applied in many fields after years of research and development[10,11].Some scholars have used AI to solve the offloading problem in edge computing [12,13].However,AI needs comprehensive,accurate and real-time system information to make appropriate offloading decisions[14].Thus,how to obtain system information comprehensively and accurately has become a serious challenge in the task offloading of multi-edge servers.
The emergence of digital twin(DT)brings a new solution to this challenge.The DT builds a virtual model for the device through physical models,sensor data,operating history and other data,and updates parameters through real-time sensor data [15].This mapping between the virtual model and the physical device can provide comprehensive and accurate system information[16,17].DT technology can be applied in many fields,for instance,product design,vehicle assisted driving,and intelligent manufacturing[18–21].In vehicle-assisted driving,the vehicle obtains global information through the DT [15].DT can be used to optimize production processes [18].By combining task offloading with DTs,the DTs can be used for providing system information for task offloading and optimize offloading strategies.
Nevertheless,designing an appropriate DTempowered task offloading strategy still faces great challenges.Firstly,limited by resource and battery capacity,the IoT devices can not work as persistently as ESs.The task offloading strategy needs to consider the optimization of energy efficiency [22–25].Secondly,there are differences in computing resource abilities and capacities among ESs,which makes it difficult to balance the workload of all the ESs and make full use of computing resources [26,27].Besides,due to the limitation of storage space and computing power of IoT devices,the AI training deployed on IoT devices is insufficient [28].Therefore,it is difficult to guarantee the effectiveness of AI.The integration of DT and deep reinforcement learning (DRL) can be used to solve these problems.The large amount of data on the digital twin server (DTS) can improve the accuracy of agent training,and the agent can help to provid appropriate offloading strategy for the IoT device.
In this paper,we study the task offloading problem in DT-empowered mobile edge computing.DT techniques are applied to facilitate communication between ES and IoT devices.We consider two optimization objectives of energy efficiency and workload balance.To be more specific,we propose the optimization model to maximize the energy efficiency of IoT devices and minimize the workload deviations of the ESs.Then,we reformulate the task offloading problem as a Markov Decision Process(MDP)problem.In order to solve this problem,we design a DRL-based energy efficient task offloading (DEETO) algorithm.Finally,we evaluate the performance of DEETO algorithm through comparative experiments.The main contributions of this paper as follows.
· We investigate the dynamic task offloading problem in DT-empowered mobile edge computing.DT techniques are applied to enhance the cooperation among IoT devices.Then,we formulate the task offloading problem with the goal of maximizing the energy efficiency and balancing the workload among ESs.The offloading strategy includes determining whether the IoT devices should offload the task,the selection of ES,and the transmission power allcation of IoT devices.
· We reformulate the task offloading problem as an MDP problem.Then,we design the DEETO algorithm based on DRL to solve it.Digital twin provides ESs status information and network environment information for DEETO algorithm.Through the DTS,agents deployed on IoT devices can share training data and use the massive training data on the DTS.
· We carry out a series of comparative experiments with both DRL and non-DRL algorithms to evaluate the performance of DEETO algorithm.The results demonstrate that our DEETO algorithm can effectively improve the energy efficiency and balance the workload among the ESs.
The rest of this paper is organized as follows.The system model and problem formulation of task offloading in DT-empowered MEC are presented in Section II.We propose our DEETO algorithm in Section III.We evaluate the performance of DEETO algorithm in Section IV.Section V concludes this paper.
II.SYSTEM MODEL AND PROBLEM FORMULATION
2.1 Digital Twin-Empowered Network Model
As shown in Figure 1,we consider a digital twinempowered system consisting of multiple IoT devices(IoTDs),a set of base stations(BSs)and digital twins.Each BS is equipped with an Edge Server (ES),and each BS can communicate with other BSs through fibre-optical.SetK={1,2,...,k,...,K}andC={1,2,...,c,...,C}represent the BSs and ESs,respectively.For each BSk,there are multiple channels represented by a setMk={1,2,...,mk,...Mk}.We adopt the NOMA-enabled tranmission techniques and each channel of the BS can be accessed by multiple IoTDs at the same time.Thus,we denote the set of IoTDs that communicate with BSkthrough channelmkas.The corresponding channel gain from IoTDto BSkis denoted as.
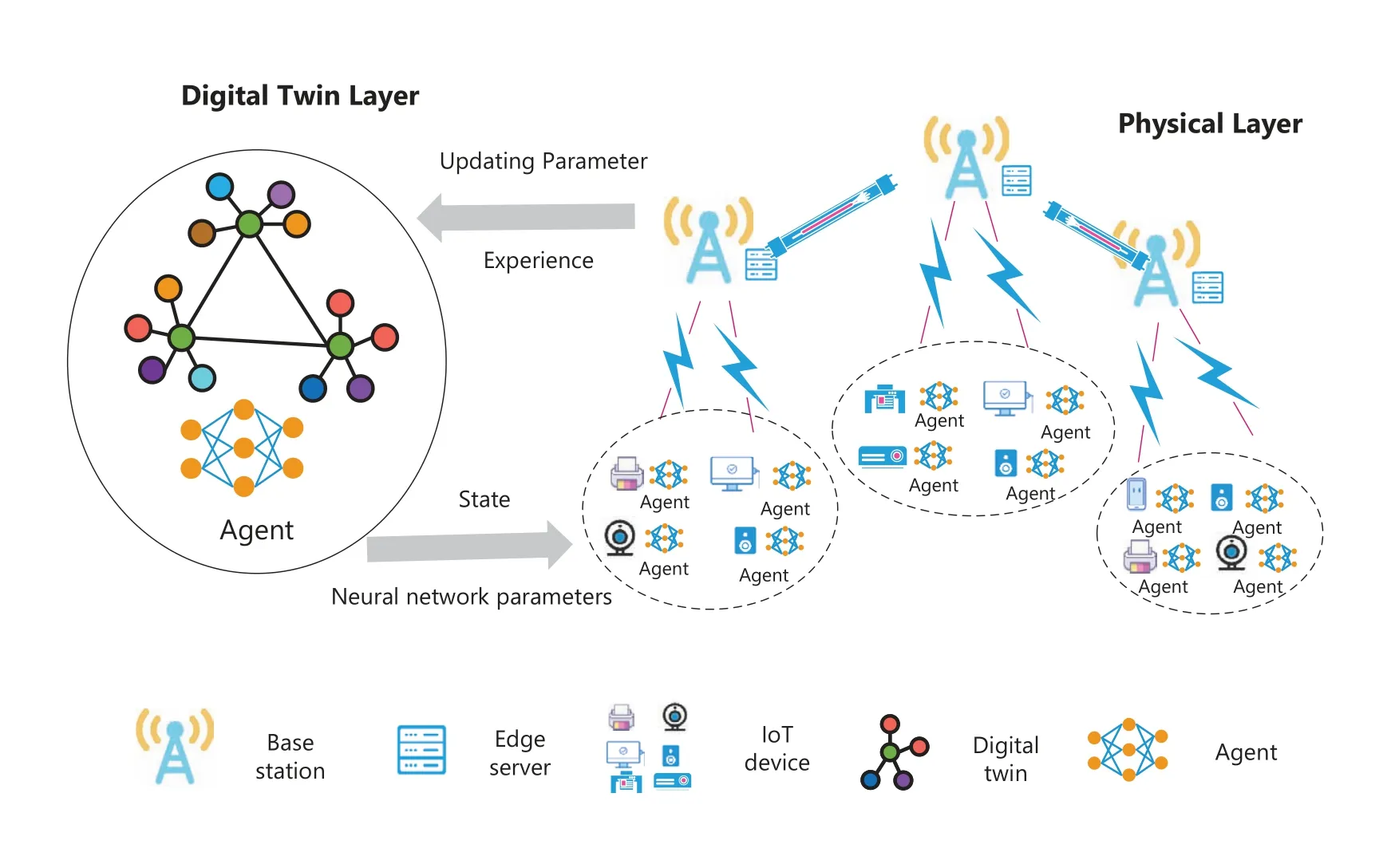
Figure 1. Digital twin-empowered network.
DTs for IoTDs and ESs are deployed on the DTS.IoT devices and ESs can communicate with the DTS and update their parameters.Through communication with the DTS,each IoTD can also obtain the information it wants from the global information,including the status of ESs and the current network status.Agents deployed on IoTDs make offloading decisions on tasks based on the acquired information.In order to reduce the communication consumption between IoTD,ESs and the DTS,we use key data for digital twin modeling.For the IoTDs,DT builds the virtual model for the IoTD by collecting IoTDs battery level,the queue length of IoTDs,and the channel gain information from the IoTD to the BS.It can be represented as
whereBdis the energy state of battery,Qdrepresents the queue length of IoTD andGdis the channel gain from the IoTD to the BS.As for ESs,the virtual model is established by collecting the computing resources of ESs and the current queue length of ESs.It can be represented as
whereFsis the computing resource of ESs andQsis the queue length of ESs.Besides,an agent is deployed on the DTS.Through the DT,IoTDs can share their own training data,and the agents deployed on the DTS can use this data to update network parameters and synchronize to the agents on the IoTDs.The main symbols used in this paper are listed in Table 1.

Table 1. Notations.
2.2 Task Offloading Model
We consider a time-slotted system with energy harvesting techniques.In each time slott,IoTDmay generate task denoted bywhererepresents the size ofandfis the required computing resource (i.e.,the required CPU cycles per bit).Limited by the energy and computing resource of IoTD,the task needs to be offloaded to the ES for processing.At the beginning of each time slott,the IoTD makes a decision between harvesting energy and offloading task.We defineto represent the decision,which is expressed by
whereis the transmission power of,σ2is the noise power.The channel gains have been sorted.Then,we can calculate the transmission speed ofas
whereτis the length of the time slot andis the queue length ofin time slott.Therefore,the queue length ofupdates as
We can calculate the task size processed on the ES in time slottas follows
whereQc(t) is the queue length of EScin time slott,Fcis the available computing resource (i.e.,CPU frequency) andfis the required computing resource of task.Considering the difference of computing resources among the ESs,the IoTD needs to select the appropriate ES to offload the task.=1 represents thatoffloads the task toc.Then,we can obtain the size of task offloaded tocas
Thus,we can update the queue length ofcas
2.3 Energy Model
For the IoTD,there is a battery to provide energy for working.Besides,we consider that BS can charge IoTDs within its coverage [29].Thus,the harvested energy ofin time slottcan be denoted as
whereη ∈(0,1) denotes the charging-efficiency,pkrepresents the charging power ofk,is the channel gain fromkto,Bmaxis the maximum battery capacity andrepresents the current battery capacity of IoTD.When IoTD decides to offload the task,we can calculate the transmission time according to(5),(6).The transmission time is
Therefore,the energy consumed by offloading task can be calculated as
The battery state ofin time slott+1 can be formulated by
2.4 Problem Formulation
In this paper,IoTD generates task and offloads it to the ES for processing.In the process,the IoTD consumes transmission energy.In order to reduce the energy consumption of offloading task,we focus on the optimization of energy efficiency that is expressed by
Besides,there are differences in computing resource and the workload among ESs.To enable that the ES handle the corresponding amount of tasks according to its current working status,we adopt the queue length of ES to represent the workload and defineLcas the expected workload,
Then,we adoptVto evaluate the standard deviation of workload expressed by
We jointly design two optimization objectives.For IoTDs,our goal is to maximizeZ.For ESs,our goal is to minimizeV.Then,we formulate the joint optimization problem as follows
C1 limits the range of transmission power of IoTDs.pminandpmaxrepresent the minimum transmission power and maximum transmission power,respectively.C2 is the offloading decision of IoTDs.C3 indicates constrain of the computing resource of ESs.C4 limits the energy that the IoTD can consume to transmit task in each time slot.C5 represents the maximum energy that can be harvested in each time slot.
III.INTELLIGENT TASK OFFLOADING FOR DIGITAL TWIN-EMPOWERED MOBILE EDGE COMPUTING
In this section,we transform the joint optimization problem to MDP problem.Each IoTD can get the state information of other IoTDs through DTs.Besides,training data can be shared among IoTDs through DTs.Then,we design a digital twin-empowered algorithm based on DRL.
3.1 MDP Model for Task Offloading
In this paper,we consider that an agent runs on each IoTD.Agent obtains the key information of environment thorugh DTs and formulates it as stateS.Then,agent of IoTD generates actionAaccording toS.The IoTD executes the action and environment generates rewardRfor the action.Meanwhile,the information of environment updates to next state.Then,we can get three key elements of MDP model and denote them as a 3-tuple{S,A,R}.Next,we can train the agent to get better action based on these data.More detailed MDP model is described as follow.
3.1.1 State
The state of IoTD in time slottcan be divided into three parts,including the device itself,channel and ESs.Agent neets to know the information of the IoTD when making decisions.Therefore,S(t)contains current energy of battery and queue length of IoTD.Besides,the transmission speed of IoTD is affected by channel state according to (4) and other IoTDs in the same channel.Considering the optimization objective(17),forS(t),we need to know the queue length of ESs.S(t)can be formulated as
3.1.2 Action
In time slott,the agent needs to make decisions between harvesting energy and offloading task.Meanwhile,the agent needs to control the transmission power and select an ES for offloading when IoTD decides to offload.Thus,we can denote the action ofas
3.1.3 Reward
The goal of agent is to get higher reward.Therefore,it is vital to design an appropriate reward function.In our model,reward function needs to take energy efficiency optimization and load balance of ESs into account.In order to keep the IoTD queue stable,we integrate the queue difference.To reduce the energy consumption,we should consider the effect of transmission power.Besides,ESs load balance requires cooperation among IoTDs.The reward function should consider the impact of the selected ES on the IoTD and the overall goal.Considering the above criteria,we design the reward function as follows
whererepresents the queue difference,represents the reward of selecting the ES,denotes the transmission power andVis the standard deviation of workload.
3.2 DRL-Enabled Task Offloading Algorithm
Reinforcement Learning (RL) has been widely used to solve MDP problems.RL can generate appropriate strategy through accurate value function.Meanwhile,this also leads to the deficiency of traditional RL in complex high-dimensional environment and continuous action.With the development of deep neural network(DNN),RL has been combined with DNN.Benefiting from the powerful function fitting ability of DNN,we can use DNN as value function and policy function.In our model,the dimensional state space of the environment is high,and action is a mixture of discrete and continuous action.In this paper,we adopt soft actor-critic (SAC) algorithm to solve the MDP problem.The goal of SAC is to maximize reward and entropy.Comparing with proximal policy optimization algorithm(PPO),SAC has better stability and can do well in dealing with continuous action.
Similar to PPO algorithm,actor network outputs parameters of normal distribution according to the state of input.We adoptμandσto represent the mean and variance,respectively.Then,we can sample to generate action based on probability density function.Thus,comparing with deep deterministic policy gradient (DDPG) algorithm,SAC algorithm can explore the environment better.SAC algorithm has four evaluate networks,including two action ctiric networks and two state critic networks.We can get the action value and state value through them.Besides,SAC is an offpolicy algorithm,and there is a reply buffer for reusing the experience.
Actor network with parameterθpgenerates actionatto interact with the environment.Then,we can get rewardrtand next statest.The experience can be expressed as a 4-tuple{st,at,rt,st+1},and the experience needs to be saved in reply bufferR.When we collect enough experience,we can update networks according to the experience.When we start training,we sample a batch of experience fromR.According to Bellman equation,we can calculate the value of action as
Thus,we can calculate the loss value ofQnetworks according to
Then,action value is calculated throughQnetwork andQ′network.It is expressed by
We adopt the minimumQvalue to avoid excessiveQvalue.We evaluate the value of state throughQvalue,it can be expressed as follow
whereπis the action policy.Then,we can calculate the loss value of state critic network by
For the action network,we can calculate the loss value by
We design a DRL-based energy efficient task offloading algorithm (DEETO).SAC is an algorithm with continuous action.However,the action is continuous and discrete mixed decision in our model.Thus,we adjust the output range of actor network from 0 to 1 and make further adjustment.In each time slott,we need to make binary decisions about whether to offload task.We define binary decisions=1 if the action>0.5,otherwise=0.Similar to offloading decision,the choice of ESs is also a discrete action.We adjust the actionaccording the number of ESs,and it can be expressed by
wheredenotes the output value of server decision of actor network.Crepresents the number of ESs.
At the beginning of time slot,the agent deployed in the IoTD can obtain the information of environment through DTs,which includes the queue length of ESs and channel gain from IoTD to BS.We can formulate it asS(t)=.We input the state into actor network with parametersθa.Then,the actor network outputs the actionA(t),and it is transformed into an action suitable for our MDP model through above method.According to the action,the IoTD decides whether to offload the task.If IoTD decides to offload task,IoTD controls the transmission power and chooses the ES based on action.After the time slott,the environment will be transformed into a new stateS(t+1).The calculation of reward should not only consider the impact on itself,but also consider the impact on the overall system.Through DTs,we can dynamically obtain the change of environment.Thus,we can calculate the reward according to (21).After that,we can get the experience and save it into the reply bufferR.
In our model,there is a reply bufferRdeployed in the DTS.After obtaining the experience,IoTDs will send it to the DTS.Then,the DTS randomly sample a batch of experience and save it to theRthat is deployed in the DTS.IoTDs can share the experience through thisR.Besides,it also speeds up the collection of training data.At the beginning of training,a batch of experience is sampled fromR.The agent deployed in the DTS updates networks parameters.Then,the trained network will be sent to each IoTD,and the agent that has updated the network parameters will continue to interact with the environment.The detailed process of DEETO algorithm is showed in Algorithm 1.

IV.PERFORMANCE EVALUATION
In this section,we design comparative simulation experiments to assess the performance of DEETO algorithm.First,we compare with different algorithm to evaluate the convergence of DEETO algorithm.Then,we analyze the effects of different parameters on energy efficiency and ESs load balance.
4.1 Experiment Setting
In this paper,we consider the scene of multi BSs.The number of BS is 3.Each base station is equipped with an ES.The computing resource of ES range from 15GHzto 25GHz.The bandwidth of BS is 10MHz,and each BS is divided into 4 channels.The bandwidth of each channel is 2.5MHzand provides services for 8 users.The battery capacity of each IoTD is 4J.The transmission power of each IoTD is constrained in the range of 1mWto 100mW[30].The power of noise is 10-16W[31].The task size generated by each IoTD is randomly generated between 0.05Mband 0.1Mb.The computing resources required by task are 1000 CPU clock cycles per bit.The experimental parameters are given in Table 2.
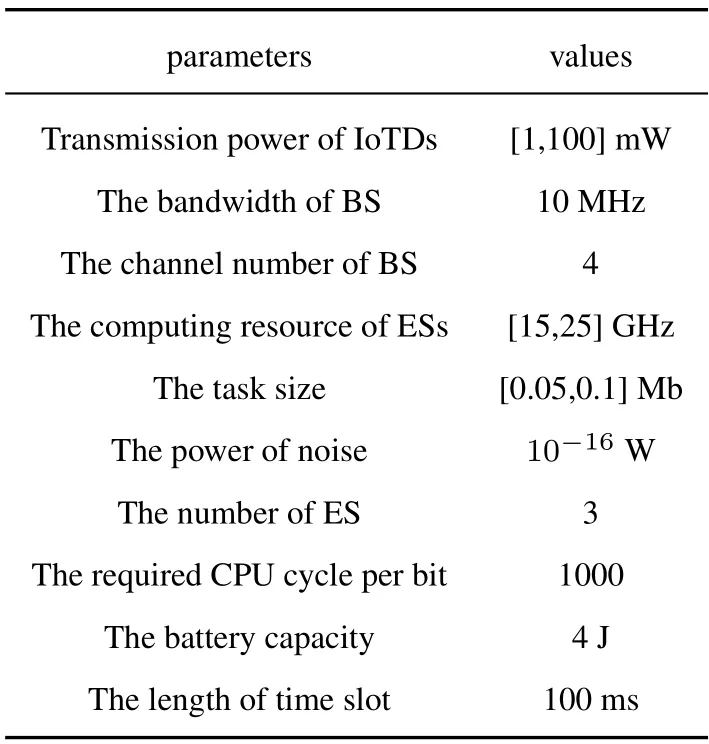
Table 2. Parameters setting.
4.2 Parameter Analysis
In this part,we analyze the impact of different parameters.
4.2.1 Impact of Transmission Bandwidth
As shown in Figure 2,we analyze the impact of bandwidth on energy efficiency.The bandwidth of the BS ranges from 8MHzto 17MHz.With the increase of bandwidth,the energy efficiency increases steady.According to equation (5),the larger bandwidth will get larger transmission speed with the same signalto-interference-plus-noise ratio.Thus,it can transmit more task and get higher energy efficiency.
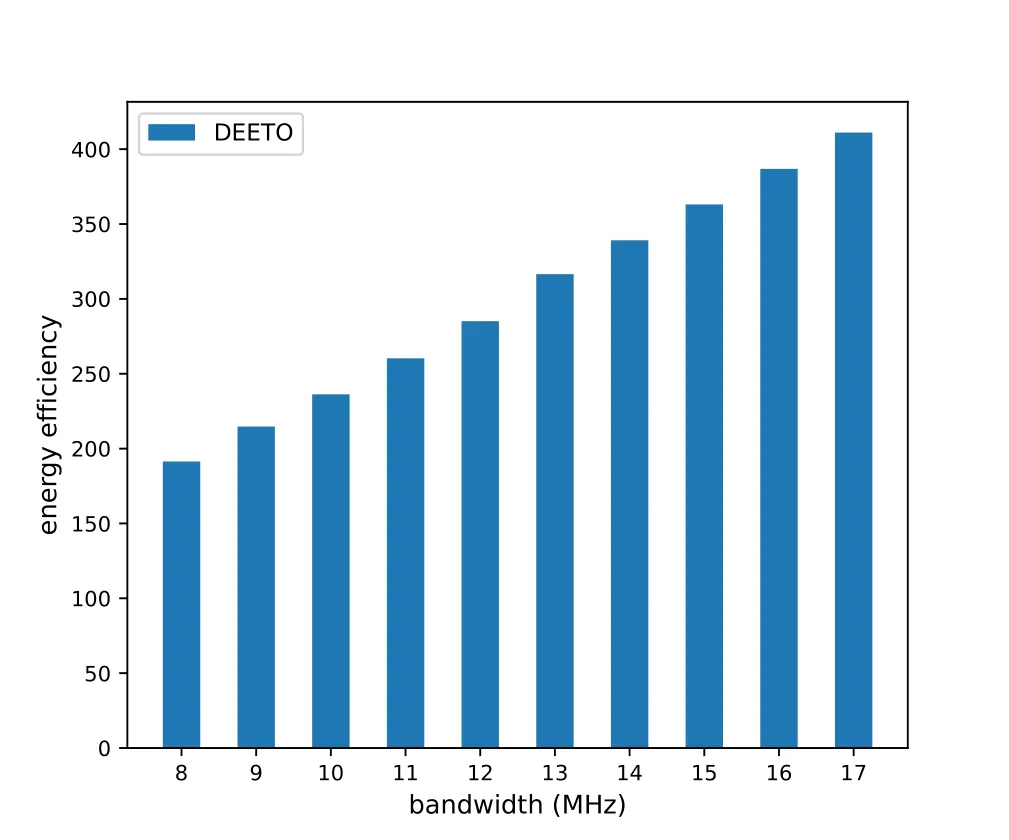
Figure 2. Impact of bandwidth on energy efficiency.
4.2.2 Impact of Device Number
Figure 3 shows that energy efficiency decreases as the number of devices increases.However,the decline rate of DEETO algorithm decreases gradually.According to equation (4),the signal-to-interferenceplus-noise ratio of IoTD is interfered by other IoTDs.With the increase of the number of IoTD,the interference also increases.Thus,the energy efficiency gradually decreases.
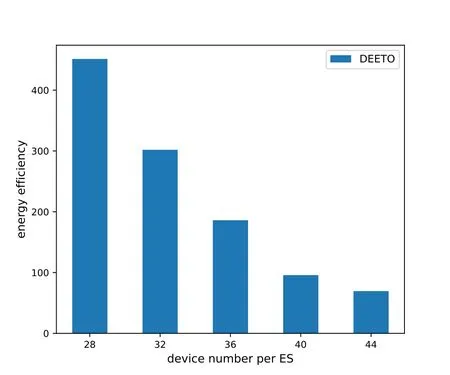
Figure 3. Impact of device number on energy efficiency.
4.2.3 Impact of Computing Workload
Figure 4 describes the changing trend of workload deviation with the increase of workload load.With the increase of required computing resource,the standard deviation of DEETO algorithm increases too.The more computing resources required for tasks of the same size,the more backlog tasks.Thus,the standard deviation increases gradually.
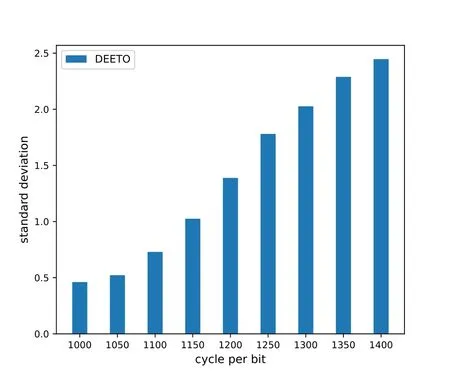
Figure 4. Impact of computing workload on ES load gap.
4.3 Convergence Analysis
We compare the PPO algorithm and random algorithm with DEETO algorithm and analyze performance in the energy efficiency and load balance.
· Proximal Policy Optimization algorithm (PPO):PPO algorithm is a DRL algorithm based on actor-critic algorithm.Similar to SAC algorithm,the output of actor network is parameters of normal distribution.The action is obtained by sampling according to normal distribution.
· Twin Delayed Deep Deterministic policy gradient algorithm (TD3): Similar to Deep Deterministic policy gradient(DDPG)algorithm,it uses the actor network to generate actions directly.Besides,it adopts two critic networks to solve the problem of excessive Q value.Compared with DDPG algorithm,it has better stability.
· Random algorithm(Random): The offloading decision whether to offload is generated randomly.Meanwhile,IoTDs randomly select the ES to offload the task.The value of transmission power is randomly generated within the limited range.
· Non-Cooperative algorithm (Non-Cooperative):Each IoT device can only be offloaded to its own corresponding ES and cannot be offloaded to other ESs.Transmission power and whether to offload task decisions are randomly generated.
Figure 5 and Figure 6 show the performance of our algorithm in two optimization objectives.Figure 5 shows that the energy efficiency of our algorithm fluctuates in the range of 200 to 350.The energy efficiency of Non-Cooperative algorithm,PPO algorithm and Random algorithm is between 30 and 50.TD3 algorithm floats between 90 and 150.Comparing with other algorithms,the energy efficiency of our algorithm has been improved.Figure 6 shows the workload deviation among ESs.Comparing with other algorithms,the workload deviation of DEETO algorithm is the samllest and most stable.The Non-Cooperative algorithm cannot coordinate the computing resources of the ESs.Thus,ES with few computing resources are easy to excessive load,resulting in an increase in standard deviation.TD3 algorithm can keep the workload deviation stable,but the value is larger than DEETO algorithm.PPO algorithm and Random algorithm can not keep stable.
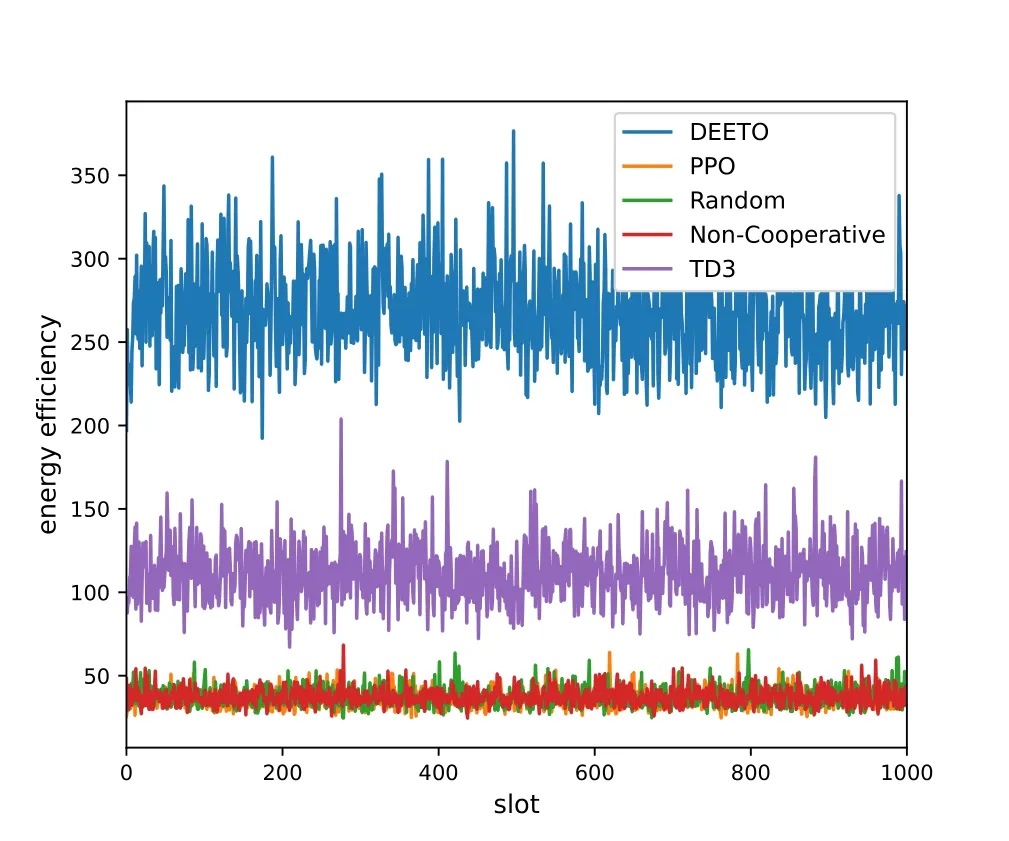
Figure 5. Energy efficiency of different algorithm.
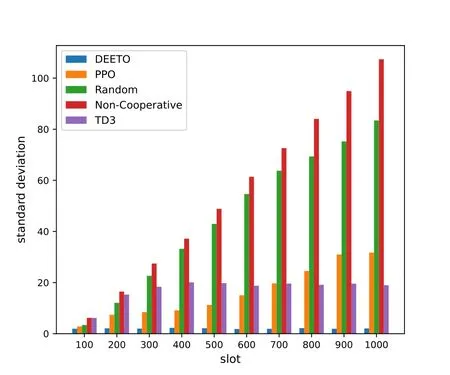
Figure 6. Workload deviation of different algorithm.
Figure 7 describes the change of IoTD queue length.Comparing with other algorithms,the queue length of DEETO algorithm is the samllest.Besides,our algorithm can converge faster and keep the fluctuation in a small range.Figure 8 shows the advantage of DEETO algorithm on the ES queue.With the increase of time slot,the queue length of Random algorithm and Non-Cooperative algorithm increase rapidly.The queue length of PPO algorithm increases slowly.However,it can not keep the queue stable.The TD3 algorithm can keep the queue stable.However,the queue length of TD3 is larger than DEETO algorithm.
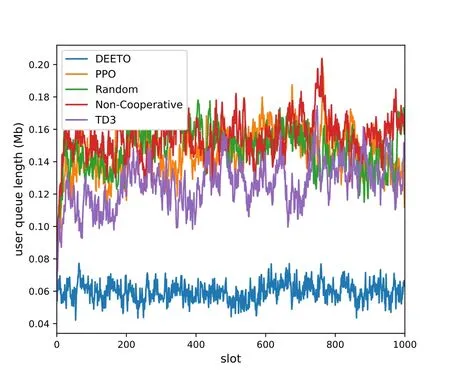
Figure 7. IoTD queue length of different algorithm.
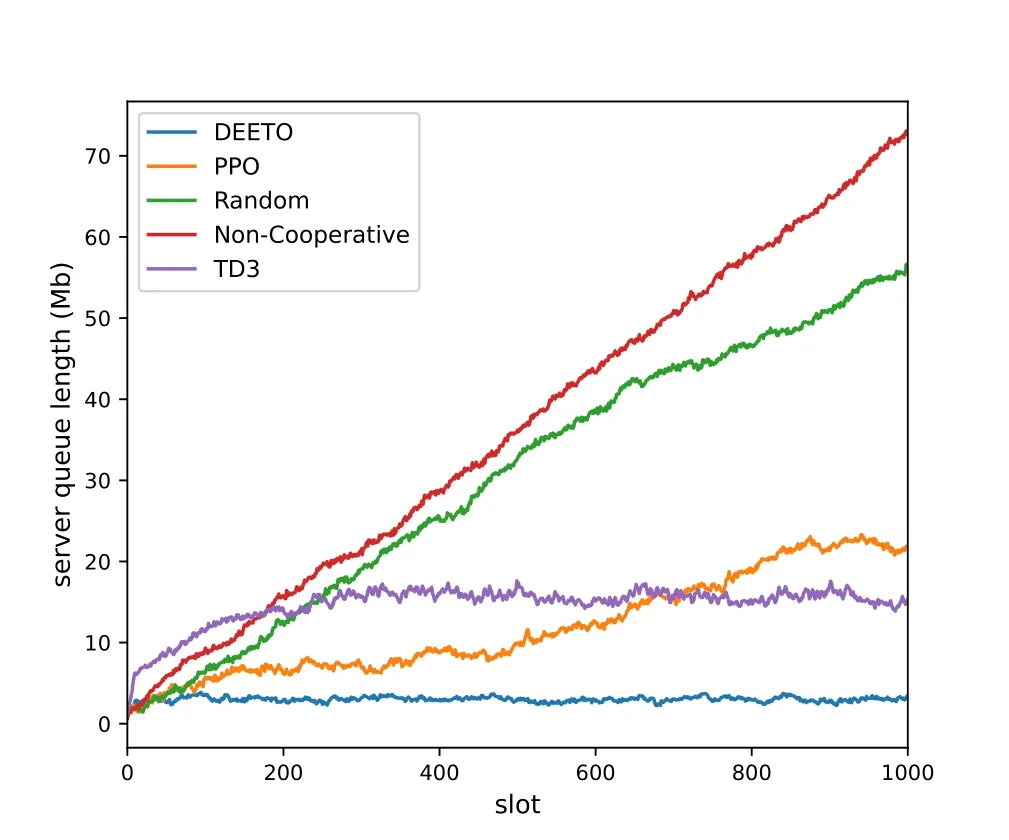
Figure 8. ES queue length of different algorithm.
V.CONCLUSION
In this paper,we study the task offloading for DTempowered MEC.We jointly design two optimization objectives.Our goal is maximize the energy efficiency of IoTD and minimize the workload deviations of the ESs.Then,we reformulate the task offloading problem of multiple ES as MDP problem and propose DEETO algorithm based on DRL to solve it.Experimental results show that DEETO algorithm can effectively improve energy efficiency of IoTD and minimize the workload the workload deviations of the ESs.
ACKNOWLEDGEMENT
This work was partly supported by the Project of Cultivation for young top-motch Talents of Beijing Municipal Institutions (No BPHR202203225),the Young Elite Scientists Sponsorship Program by BAST(BYESS2023031),the National key research and development program(No 2022YFF0604502).

- China Communications的其它文章
- PowerDetector: Malicious PowerShell Script Family Classification Based on Multi-Modal Semantic Fusion and Deep Learning
- A Rigorous Analysis of Vehicle-to-Vehicle Range Performance in a Rural Channel Propagation Scenario as a Function of Antenna Type and Location via Simulation and Field Trails
- Intelligent Edge Network Routing Architecture with Blockchain for the IoT
- Privacy-Preserving Deep Learning on Big Data in Cloud
- Temporal Convolutional Network for Speech Bandwidth Extension
- Resource Trading and Miner Competition in Wireless Blockchain Networks with Edge Computing