
Temporal Convolutional Network for Speech Bandwidth Extension
2023-11-18 08:35ChundongXuChengZhuXianpengLingDongwenYing
China Communications 2023年11期
Chundong Xu ,Cheng Zhu ,Xianpeng Ling ,Dongwen Ying,2
1 School of Information Engineering,Jiangxi University of Science and Technology,Jiangxi 341000,China
2 School of Electronic,Electrical and Communication Engineering,University of Chinese Academy of Sciences,Beijing 100049,China
*The corresponding author,email: xuchundong@jxust.edu.cn
Abstract: In the field of speech bandwidth extension,it is difficult to achieve high speech quality based on the shallow statistical model method.Although the application of deep learning has greatly improved the extended speech quality,the high model complexity makes it infeasible to run on the client.In order to tackle these issues,this paper proposes an end-toend speech bandwidth extension method based on a temporal convolutional neural network,which greatly reduces the complexity of the model.In addition,a new time-frequency loss function is designed to enable narrowband speech to acquire a more accurate wideband mapping in the time domain and the frequency domain.The experimental results show that the reconstructed wideband speech generated by the proposed method is superior to the traditional heuristic rule based approaches and the conventional neural network methods for both subjective and objective evaluation.
Keywords: speech bandwidth extension;temporal convolutional networks;time-frequency loss
I.INTRODUCTION
Due to the channel bandwidth limitation of the digital public switched telephone network (PSTN),the speech bandwidth on telephone communication ports is limited to a narrowband scope of 0Hz-4kHz,This kind of speech,with loss of highfrequency(4kHz<f<8kHz)spectrum,presents muf
ed sound,which shows low identification speaker and poor auditory quality.Speech bandwidth extension (BWE) can improve the intelligibility,clarity,and naturalness of narrowband speech.Previous research in BWE shows their great potential of improving speech quality in telecommunication and advancing system performance,such as speech recognition[1].speaker recognition[2],speech synthesis[3] and speech enhancement[4].In earlier BWE technologies,source-filter model of speech production mechanism is widely used.It divides the wideband speech generation tasks into excitation signal generation[5] and wideband spectral envelope estimation[6],a method for describing channel models.The BWE methods that are based on the source filter model include codebook mapping[7],Gaussian Mixture Model(GMM)[8]and Hidden Markov Model(HMM)[9–12],etc.In recent years,the heavily use of high speed computer with GPUs and the development of deep neural networks have given a ground for many advanced neural network models to achieve great successes in BWE[13–15].Li et al[16].introduced a BWE model which was constructed by a denseconnected neural network (DNN).In their work,the log power spectrum features of the speech signals were used as the training data,and better than GMM performance was achieved for both subjective and objective evaluation.However,the expanded wideband speech with this approach had a spectrum loss between the low and the high bandwidth,which resulted in a distinct intermittent and unnatural sound.Therefore,Li et al[17].proposed a DNN based model with the trait of smooth output,which generated all wideband spectrum at its last layer.This method effectively eased discontinuity between the narrowband and the wideband spectrum.Kuleshov et al[18].introduced an end-to-end BWE model,AudioUNet,which was formed by a convolutional neural network.In its pretreatment stage,narrowband speech signals were upsampled by a cubic spline interpolation.Afterwards,these speech signals were applied as the input to train the model,where the reconstructed wideband speech signals were outputed.Because AudioUNet was designed as extreme-belief input,speech signals upsampled by the cubic spline interpolation restored part of high-frequency spectrum and tampered their lowfrequency spectrum.Although this model achieved positive signal-to-noise ratio,the spectrum distortion was severe.Furthermore,AudioUNet required large training resources and lacked generalization ability of different audios.Ling et al[19].proposed a recurrent neural network (RNN) with bottleneck structure for bandwidth extension.In their method,training data for the proposed model were the extracted mel-frequency cepstral coefficients features.With the excellent ability to deal with sequence data,this RNN based approach achieved better performance than the DNN based methods.However,the temporal dependency property of the RNN model caused the low training efficiency,which limited its application.Moreover,the gradient vanishing or gradient exploding problem is another issue for the RNN based model.
Although previous studies in speech bandwidth extension have made profound achievements,time domain waveform modeling using deep learning had achieved even better results than source-filter models.Aiming at solving the problems existing in the aforementioned models for speech bandwidth extension,this paper made following contributions.First,an end-to-end temporal convolutional network(TCN)with residual structure is presented to overcome the problem of spectrum discontinuity and avoid training difficulties that RNN encounted.Second,a timefrequency loss function is introduced,where the model can be trained in time and frequency domain at the same time to generate accurate waveforms and real spectrum.Both subjective and objective evaluation show that the method proposed in this paper achieves better results than some baseline methods.It is of less complexity and has a more accurately fitting nonlinear relation.Wideband speech signals produced by the proposed method are more natural.
The contents of this paper is as follows: Section II is an introduction of the BWE algorithm using TCN;Section III presents the time frequency loss function;Section IV shows subjective and objective evaluations,conducted on reconstructed wideband speech signals generated by the proposed method and those by cubic spline interpolation,Bachhav’s GMM [8],Li’s DNN[17] as well as Kuleshov’s AudioUNet[18] baselines respectively;Section V is a conclusion.
II.TEMPORAL CONVOLUTIONAL NETWORK FOR BANDWIDTH EXTENSION
Considering that the Fast Fourier Transform (FFT) is a simply linear operation,and the deep neural networks can implicitly map the raw narrowband speech signals from the time domain into a high dimensional feature space without heuristic rule based feature extraction,the FFT is no longer a necessary step in TCN based bandwidth extension framework.Compared to the conventional FFT based bandwidth extension approaches,the reconstructed wideband speech signal maintains the useful acoustic information under this TCN framework,where the generated speech signal integrity is ensured and the discontinuity between narrowband and high frequency part can be avoided.
TCN was first proposed by Pandey et al.[20],where the dilated causal convolution[21] and residual network[22] were used to enhance the modeling of time-series data context.In Figure 1 the diagram of BWE based on TCN is shown.In order to reduce the dimensions of feature space and computational complexity,and speed up the training convergence of the proposed model,the first layer of the proposed model is the subsampling module,which is designed as a series of one-dimensional convolution and LeakyReLU activation functions.The stride of this layer is 2 and the number of filters is 64.Followed by the subsampling layer in the proposed model are 5 layers of TCN blocks.In our implementation,the TCN is modified in combination with the speech bandwidth extension task,as shown in Figure 2.The modified TCN structure consists of two residual subblocks,the first of which uses a dilated causal onedimensional convolution,batch normalization and the LeakyReLU activation function.The second one uses ordinary one-dimensional convolution and batch normalization.Batch normalization can avoid model overfitting and accelerate the convergence speed of the model.And the LeakyReLU activation function is used to ensure back-propagation during the training phase when negative response occur in neuron.Similar to the very deep convolutional neural networks,when dilated causal network based TCN’s layers are deep enough,the model will be insensitive to the response and the gradient vanishing problem will cause the convergence is extremely slow or stops.To tackle this issue,the residual structure is applied in the proposed TCN,from which a side path is added into the network where the input of each dilated causal network is connected to the output of the second residual sublock directly.Therefore,the TCN can focus on learning the difference factors of these `similar stimuli’ and extracting more informative representations.Furthermore,in order to increase the number of layers of TCN and reduce the model’s complexity,the number of filters for the first residual subblock is set to be the half of the second residual subblock,which constructs a bottleneck-like structure.It can be seen that the depth of the outputs representations from the two-layer residual subblocks are different.Thus,a 1×1 convolutional layer is applied on these two outputs to force them having the same depths,which can be added as the final output of the residual blocks.
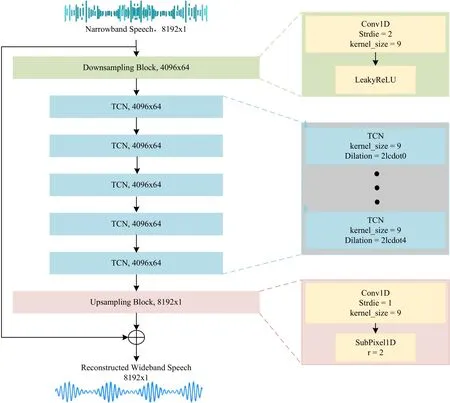
Figure 1. Block diagram of BWE based on a bottleneck residual temporal convolutional network.
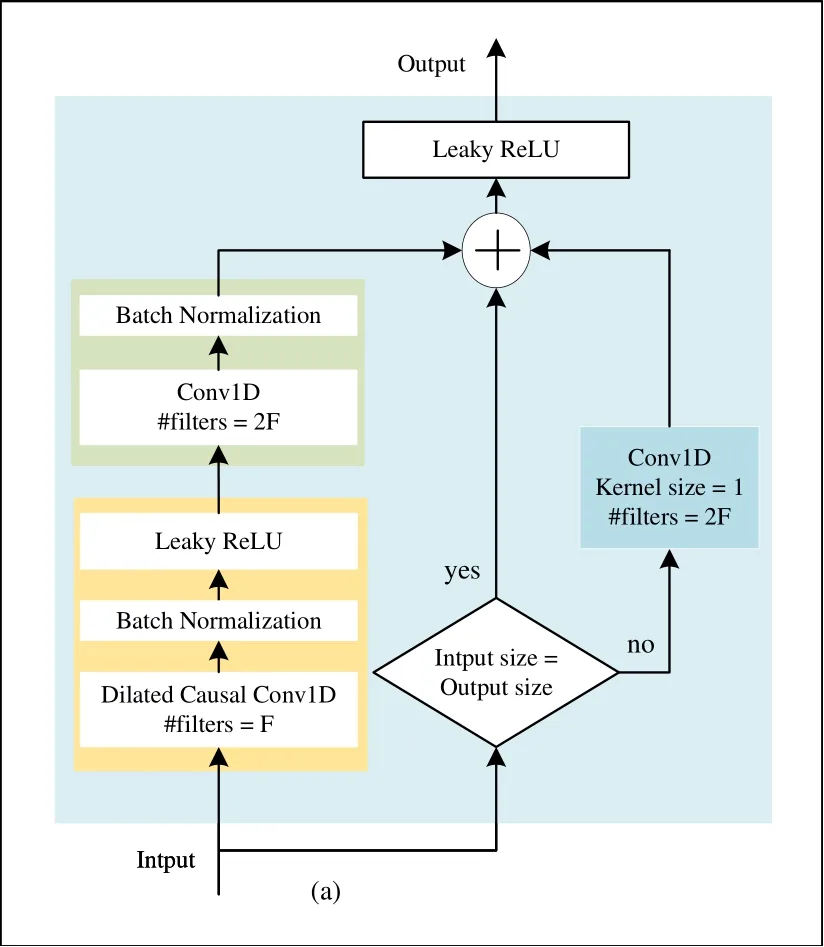
Figure 2. Detail from TCN with bottleneck residual structure.
In order to produce the restored speech signals which have the same shape and size as the input speech,the upsampling layer is implemented as the last layer of TCN model,where the upsampling factor is 2.Because the spectral artifacts are not easily produced by subpixels[23],the one-dimensional subpixels is applied for the last upsampling layer to generate the reconstructed wideband speech signals.
Particularly,in our implementation,the number of filters in the TCN structure is set to 64,and the kernel size is set to 9.These parameters are optimized through a large number of experiments.The convolution used in this article is an all one-dimensional,so the convolution kernel is also one-dimensional,and convolves in the time dimension of the training data.The LeakyReLU activation function has a negative slope of 0.2.The model weight initialization is also critical to the model’s training to ensure the efficient convergence.In this paper,the comparisons between the random normal,Xavier[24],orthogonal[25] and variance scaling[26]weight initialization methods are carried out.It is can be seen that the optimal results are obtained by using orthogonal initializations.Therefore,orthogonal initialization is used in the subsampling module and TCN module of the model.To the one-dimensional convolution of the upper sampling module,the normal distribution initialization with the mean value of 0 and the variance of 0.001 is used.Finally,we add the narrowband speech to the output of the model.Because the low-frequency part of the input and the low-frequency part of the wideband speech are very similar,the model only needs to learn the missing high-frequency spectrum.And because the low frequency part of the input is expected to be maintained,the variance of the model is set to be small enough to force the model learn the representation of the high frequency part.
III.TIME FREQUENCY LOSS
Task of the BWE is to improve the resolution of speech.In the time domain,it aims to increase the sampling rate of speech.And in the frequency domain,the task is to expand the bandwidth of speech.The two bandwidth extension targets both are to restore the high-frequency component,but the results are different at some extent.The time domain method generates a more accurate waveform,while the frequency domain method generates a more realistic spectrum.In our work,we focus on the speech signal in the time domain,which is also differentiable to transform from time domain into frequency domain.We designed a new time-frequency loss objective function for TCN model to improve the accuracy of the speech spectrum,which can train the model with high accuracy of time domain waveform and realistic frequency domain spectrum.The proposed time-frequency loss function consists of time domain loss and frequency domain loss,whose calculation process is shown in Figure 3.
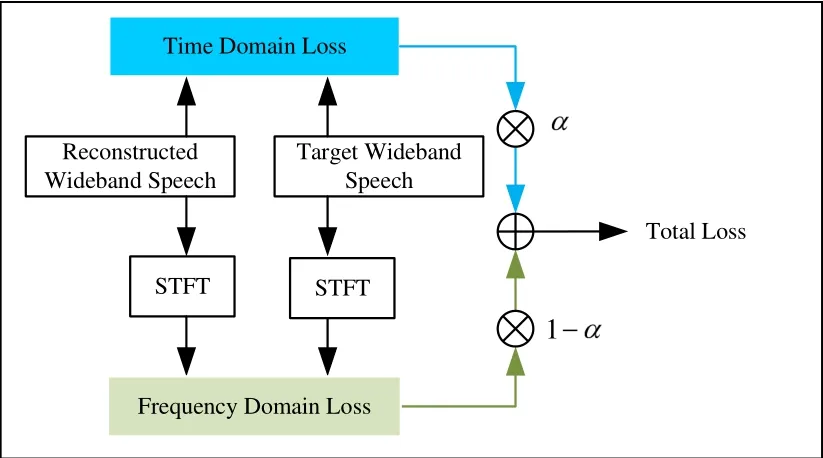
Figure 3. Time frequency loss diagram.
The root mean square error (RMSE) between the wideband speechy(n)and the reconstructed wideband speech ˆy(n) is employed as our time domain loss,with wideband sampling index n,because RMSE is very sensitive to very large or very small errors,which means it is more efficient to learn a non-linear mapping relationships.The time domain loss is defined as:
whereNis the length of a frame.We use the mean absolute error (MAE) as the frequency domain loss,because the MAE can re ect spectrum errors of reconstructed wideband speech better than other measures.In our work,y(n) andsubject to a short-time Fourier transform(STFT)respectively to get spectrum amplitudeS(l,k) and,and the frequency domain loss is defined as the MAE betweenS(l,k)and:
wherelandkrepresent the indices of the speech frame and of frequency,respectively,LandKrepresent number of the speech frequency bins and total frames,respectively.For the STFT transformation,the Hamming window with a window length of 256 is used,the frame shift is 128,and the FFT length is 256.Finally,a linear combination of the time domain loss∂Tand the frequency domain loss∂Fis applied to form the final time-frequency loss:
whereα=0.85,which is obtained by a large number of experiments on validation data.
IV.EXPERIMENT AND ANALYSIS
4.1 Experimental Conditions
The experimental design and data selection in this article follows previous work of other scholars.The single-speaker and multi-speaker BWE experiments are designed[18].Single speaker experiments are designed on the P225 data set of CSTR VCTK corpus[27]and the S002 data set of AISHELL-1[28],and multi-speaker experiments are carried out on TIMIT data set[29].Each speech signal of the VCTK and the TIMIT data sets is recorded by an English native speaker,and the AISHELL-1 data set is recorded by a Chinese native speaker in Mandarin.The data set is divided into training set,validation set and test set with the ratio of 6:2:2,and there is no intersection between them.Among them,the training set is used to train the model,the validation set is used to tune the hyperparameters of the model,and the test set is used to conduct subjective and objective evaluation.
Because the five Generation Mobile Communication Technology (5G) uses the Enhanced Voice Service(EVS)[30]codec,we use the EVS codec and the STL[31] toolbox for speech preprocessing.The preprocessing stage of the speech data follows Abel et al[32].First,the speech signals in the dataset were filtered by the MSIN[33],then encoded and finally decoded with the EVS speech codec get the narrowband speech(NB)signals as input speech signals.The ITU-T P.341[33]stipulates the audio performance requirements of the wideband speech (WB) hands-free phone,so WB preprocessing performs P.341[33] filtering on the available WB speech signals data to obtain speech signals of 0.05 7kHz as the target speech signals.To train the proposed model,the batch size of training data in the temporal convolutional model is set to 64.If the GPU memory is large enough,this hyperparameter can be set to be larger.In this work,the Adam optimizer is used,and the learning rate is set to 0.0003.The model parameters are continuously updated with 300 epochs.Finally,the model with the minimum loss function is obtained.To verify the BWE performance of TCN,the spectrograph comparisons of wideband speech signals reconstructed by the TCN method,cubic spline interpolation method,Bachhav’s GMM[8],Li’s DNN[17],and Kuleshov’s AudioUNet[18] are carried out.The comparison of the wideband speech reconstructed by the TCN model and by Bachhav’s GMM[8],Li’s DNN[17],and Kuleshov’s AudioUNet[18] are evaluated both objectively and subjectively.Objective evaluation uses log-spectral distance (LSD),Perceptual Evaluation of Speech Quality(PESQ)[34,35]and short time objective intelligibility(STOI)[36].And we use mean opinion score(MOS)as our subjective evaluation criteria.
Figure 4 the sample speech of P225-355 from VCTK test set P225,and reconstructed wideband speech by TCN method.It can be observed,the spectrum of reconstructed wideband speech within 4kHz to 7kHz bandwidth recovers the main texture structure and energy distribution successfully.
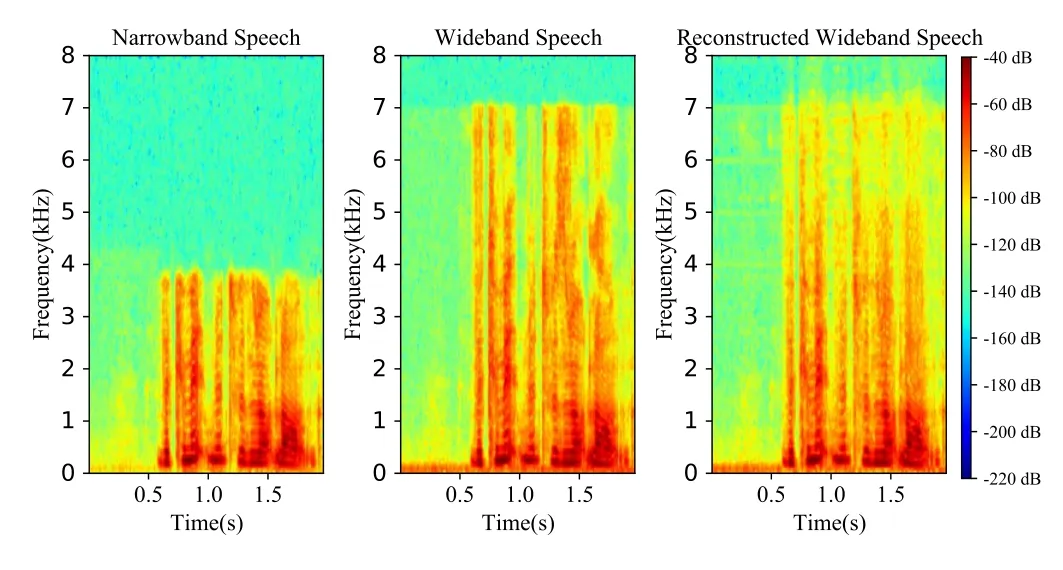
Figure 4. Comparison spectrograms.
4.2 Objective Evaluation
We use the log spectral distance(LSD)[13]to measure the Euclidian distance between two signals in the frequency domain.The smaller the LSD,the closer the estimated speech and target wideband speech are in the frequency domain.The LSD is defined as:
The Perceptual Evaluation of Speech Quality(PESQ) is a telephone voice quality evaluation index designated by the Telecommunication Standardization Department of the International Telecommunication Union,which is used to evaluate the voice perception quality,and its value is between-0.5 and 4.5,Higher PESQ indicates better listening quality.
The Short-Time Objective Intelligibility(STOI) objectively measure the speech intelligibility by the human auditory perception system,whose value is between 0 and 1,and the higher the value is,the more intelligible and clearer the speech is.
Table 1,Table 2,and Table 3,respectively show the objective evaluation experimental results of BWE on the three data sets.Experimental results illustrate that the proposed method is superior to other reference methods in PESQ evaluations.It obtains the minimum value in LSD objective evaluation,which is significantly lower than other methods.In the STOI objective evaluation,the score of the proposed method is higher than that of other methods.The LSD measurements in the TIMIT dataset experiment are significantly higher than those in the other two sets of experiments,which demonstrate that the performance of the proposed model is affected by different languages and data.
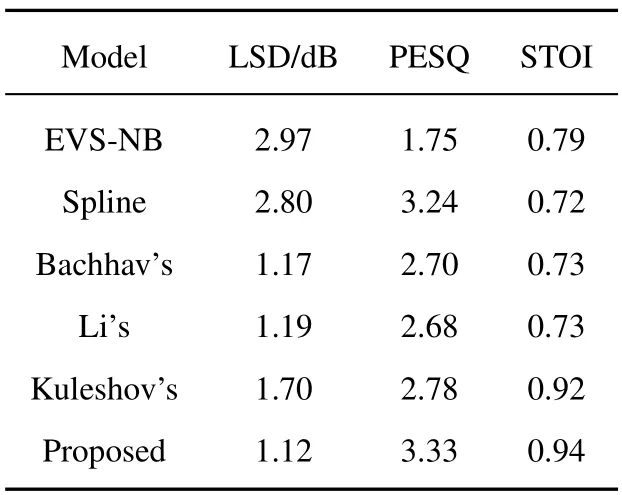
Table 1. Objective evaluation results of the VCTK-P225 data set experiment.
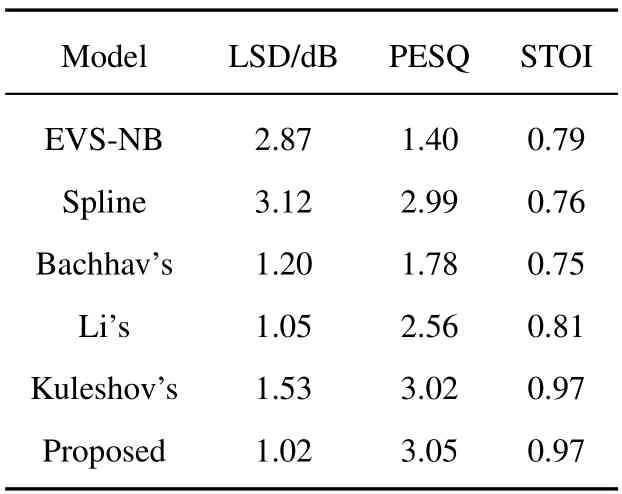
Table 2. Objective evaluation results of the AISHELL-1-S0002 data set experiment.
We should notice that the TCN bandwidth extension proposed in this paper is much smaller than the Li’s DNN and Kuleshov’s AudioUNet BWE algorithm in terms of the number of model parameters.We use NVIDIA GTX 1070 as the GPU benchmark and AMD Ryzen 5 3600X CPU @3.80GHz processor as the CPU benchmark,which can process 5.33×105 speech samples per second,In the case of CPU only,it also can process 1.52×105 speech samples per second,which is well enough in coping for real-time processing.The comparison of model parameters is shown in Figure 5.
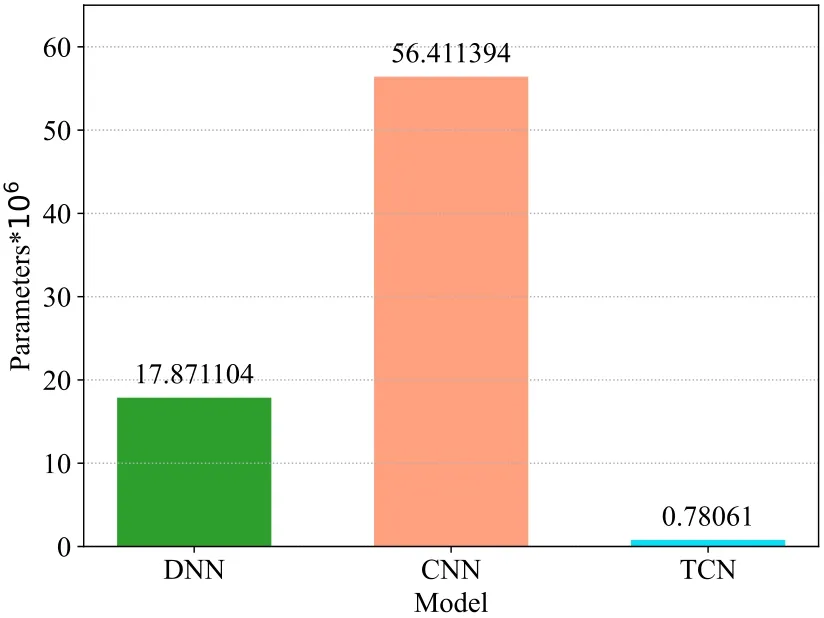
Figure 5. Comparison of model parameters.
4.3 Subjective Evaluation
The absolute category rating(ACR)[37]mean opinion score is used for subjective evaluation in this experiment.The reconstructed wideband speech signals (It was filtered by P.341),generated by cubic spline interpolation,Bachhav’s GMM,Li’s DNN,Kuleshov’s AudioUNet and our methods,are put together with narrowband speech signals and wideband speech signals randomly.Then,we invite twenty listeners,whose ages range between 20-25 years old,as the evaluator.Among them,ten are males and ten are females.The tests are conducted in a quiet room,using the Sony MDR 7506 headphones,the test speech files are single-channel files.According to the MOS method,listeners rate each speech signal on their own subjective opinions based on its clarity and naturalness.The score is divided into 1 to 5 levels,with 5 being the highest score and 1 being the lowest score.Finally,the score of each speech is averaged.Table 4,Table 5,and Table 6 show the average scores of speech signals for all bandwidth extension systems.Through MOS scores of wideband speech and narrowband speech,we conclude that the subjective evaluation is fair and correct.Compared with narrowband speech and several reference methods,the reconstructed wideband speech by the proposed method has better natural speech expressiveness,the timbre is closer to wideband speech,and the speech recognizability increases significantly.Therefore,the method proposed in this paper achieves the highest MOS score in three groups of experiments respectively,however,the perceived quality of the reconstructed wideband speech is slightly different due to the in uence of language and data diversity.
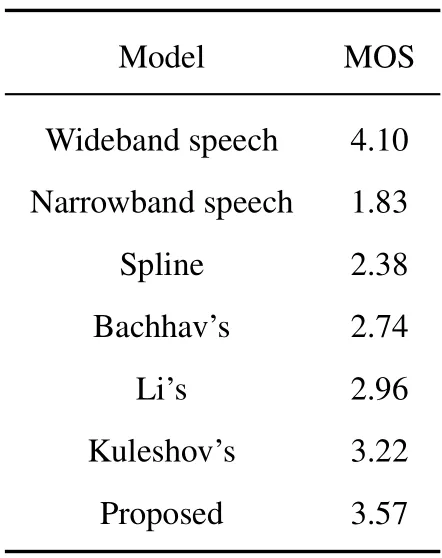
Table 4. ACR results on the VCTK-P225 data set.
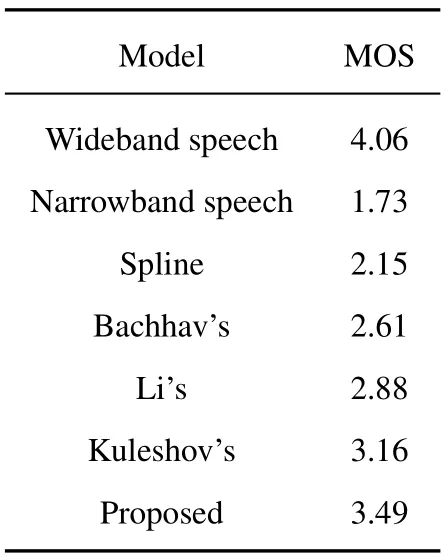
Table 5. ACR results on the Aishell-1-S0002 data set.
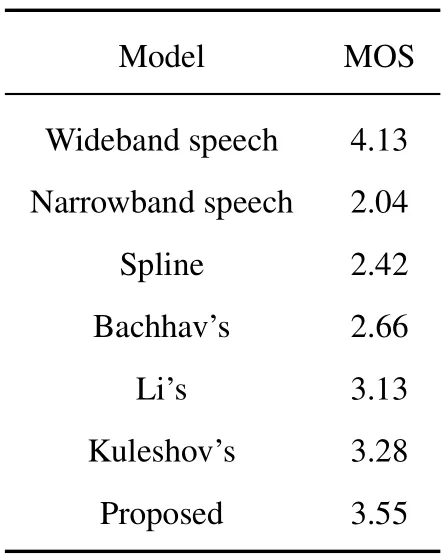
Table 6. ACR results on the TIMIT dataset experiment.
V.CONCLUSION
In this paper,a BWE method based on TCN is proposed,which provides a good fit for the nonlinear mapping relationship between narrowband speech and wideband speech.And the proposed method can also generate and reconstruct wideband speech in realtime.We also propose a time-frequency loss function.By optimizing the model in both time domain and frequency domain at the same time,the generated speech can obtain a more accurate time domain waveform and more real frequency domain spectrum.Even though the proposed network has a smaller number of parameters,it still performs better than the investigated reference methods.

- China Communications的其它文章
- PowerDetector: Malicious PowerShell Script Family Classification Based on Multi-Modal Semantic Fusion and Deep Learning
- A Rigorous Analysis of Vehicle-to-Vehicle Range Performance in a Rural Channel Propagation Scenario as a Function of Antenna Type and Location via Simulation and Field Trails
- Intelligent Edge Network Routing Architecture with Blockchain for the IoT
- Privacy-Preserving Deep Learning on Big Data in Cloud
- Dynamic Task Offloading for Digital Twin-Empowered Mobile Edge Computing via Deep Reinforcement Learning
- Resource Trading and Miner Competition in Wireless Blockchain Networks with Edge Computing