
Intelligent Edge Network Routing Architecture with Blockchain for the IoT
2023-11-18 08:12YonganGuoYuaoWangQijieQian
China Communications 2023年11期
Yongan Guo ,Yuao Wang ,Qijie Qian
1 College of Telecommunications and Information Engineering,Nanjing University of Posts and Telecommunications,Nanjing 210003,China
2 Engineering Research Center of Health Service System Based on Ubiquitous Wireless Networks,Ministry of Education,Nanjing 210003,China
3 Edge Intelligence Research Institute,Nanjing University of Posts and Telecommunications,Nanjing 210003,China
*The corresponding author,email: guo@njupt.edu.cn
Abstract: The demand for the Internet of Everything has slowed down network routing efficiency.Traditional routing policies rely on manual configuration,which has limitations and adversely affects network performance.In this paper,we propose an Internet of Things(IoT)Intelligent Edge Network Routing(ENIR) architecture.ENIR uses deep reinforcement learning(DRL)to simulate human learning of empirical knowledge and an intelligent routing closed-loop control mechanism for real-time interaction with the network environment.According to the network demand and environmental conditions,the method can dynamically adjust network resources and perform intelligent routing optimization.It uses blockchain technology to share network knowledge and global optimization of network routing.The intelligent routing method uses the deep deterministic policy gradient(DDPG) algorithm.Our simulation results show that ENIR provides significantly better link utilization and transmission delay performance than various routing methods (e.g.,open shortest path first,routing based on Q-learning and DRL-based control framework for traffic engineering).
Keywords: blockchain;deep reinforcement learning;edge intelligence;intelligent routing;IoT
I.INTRODUCTION
In the Internet of Everything era,the use of various IoT terminal devices has grown exponentially[1].IoT services and applications rely on a network for operation,resulting in massive data.In addition,people’s expectations of network performance,reliability,and security are higher than ever[2].Networks must become more interconnected;thus,intelligent sensing and network routing are crucial in networks[3].
As shown in Figure 1,various types of IoT terminals access the edge network through heterogeneous protocols such as ZigBee,LoRa,UWB,and Wi-Fi.Edge network devices (ENDS) are devices at the edge of a network,providing an entry point to the core network[4].Numerous ENDS access the Internet through TCP/IP protocols,enabling smart application services for various types of terminals[5].However,in the early days,the edge network routing design and construction in the IoT was based on the“best-effort”concept of TCP/IP[6],which failed to meet the requirements of IoT service development.The following problems were encountered.(1)Poor self-adaptive capability;unable to adjust the routing strategy dynamically according to the current network environment.(2) Low dynamic responsiveness;unable to support the massive data collection required for the intelligent development of the IoT.(3) Insufficient collaboration capability,isolation of edge devices,difficulty in sharing various data types,and the risk of data leakage during sharing.Therefore,it is required to propose a new solution to improve the routing capability of the edge network while ensuring data security.
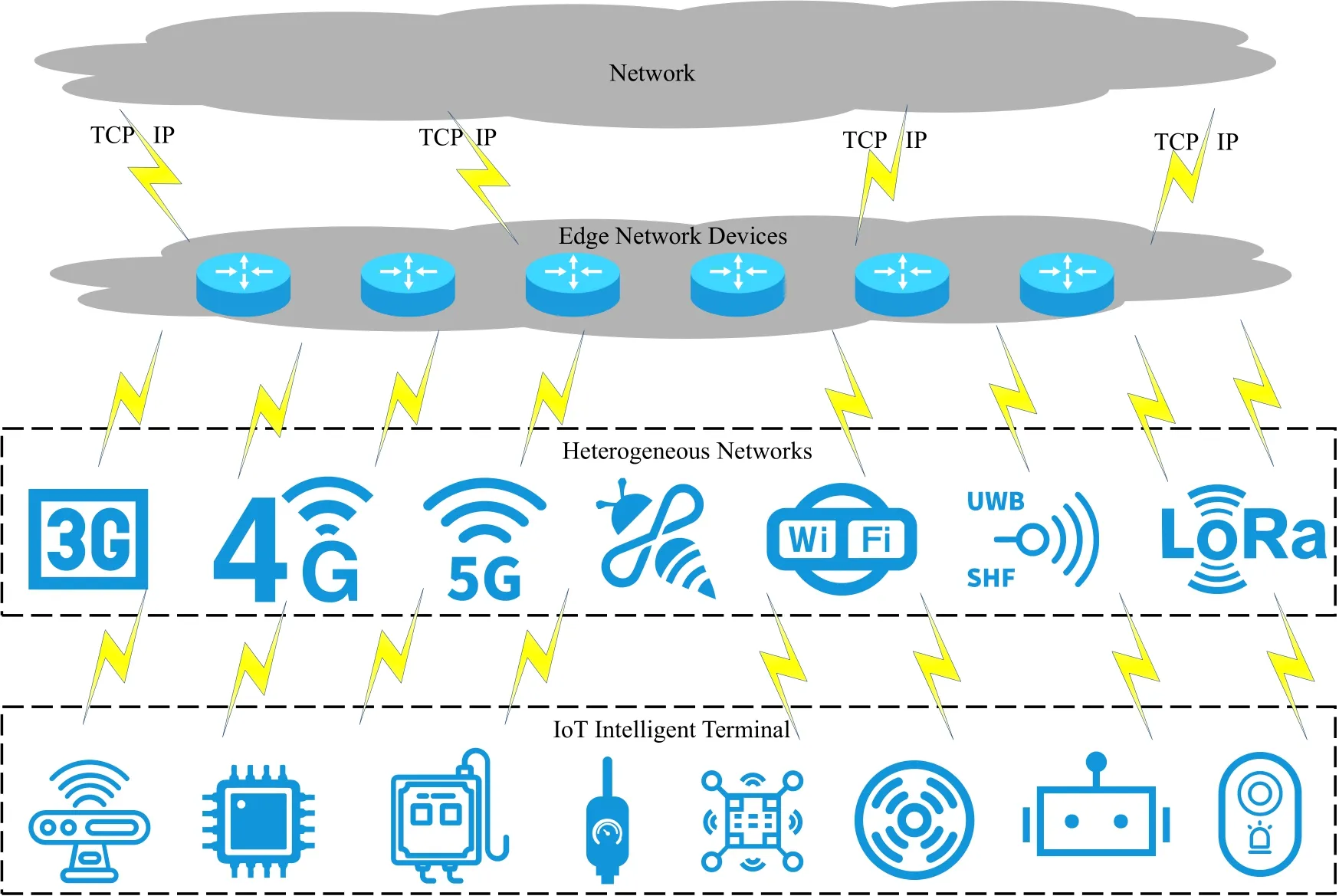
Figure 1. IoT edge network environments.
Network optimization solutions using mathematical models[7],they are less effective when deployed.Because they are based on hypothetical idealized scenarios that are difficult to match exactly with real network application scenarios.With the development of machine learning,researchers have tried to combine it with network routing[8],which is known as intelligent routing algorithms.Existing deep learning(DL)models mainly learn shortest path routing algorithms,they are not sufficiently capable of learning complex dynamic routing algorithms.Robustness cannot be guaranteed in the complex and changing IoT edge network routing environment.Intelligent routing algorithms based on reinforcement learning(RL) are also being proposed,which typically use the Markov decision process(MDP)to model the routing.However,the input and output dimensions of edge network routing are higher and the optimization objectives are more complex,building MDP models is very difficult to meet the high-performance requirements of edge networks.
As a synthesis of deep learning and reinforcement learning,DRL[9] learns and optimizes policies directly from network data.Intelligent routing algorithms based on DRL do not need to make assumptions about the environment and are more suitable for the dynamic environment of edge networks.Also,due to advances in programmable network hardware[10],it is now possible to deploy DRL algorithms inside the network to enable network devices to perform flexible processing logic[11].However,current research on using DRL for routing is limited to data center networks and carrier network operations and maintenance,and intelligent routing of edge networks has not been investigated.
In recent years,research on applying edge intelligence (EI) in the IoT has gained increasing attention[12,13].However,the forwarding of network data is still based on traditional routing algorithms,which do not address the poor adaptive capability of networks.
Large amounts of information are generated by edge intelligent devices,and these pieces of knowledge are isolated and distributed,but the complex requirements of edge network routing require knowledge interchange and collaboration.Most studies focused on training optimized intelligent models using large amounts of data but did not consider the pooling and sharing of model output knowledge.During knowledge sharing,nodes may behave maliciously,which makes it difficult to guarantee the reliability of knowledge and,secondly,there are security issues.In addition,nodes may have security issues in the process of sharing knowledge on the network.Blockchain’s distributed and decentralized[14] features can effectively solve the problem of geographically dispersed ENDS[15],while blockchain-based smart contract technology can achieve secure and reliable network knowledge sharing.
Although many excellent studies have been conducted in academia related to EI,DRL,and the blockchain,the combination of these technologies has not been considered for network routing.Thus,this paper proposes an Intelligent Edge Network Routing(ENIR)architecture incorporating blockchain technology for adaptive processing of network routing and sharing of network knowledge while ensuring data transmission security.The main contributions of this paper are as follows.
(1)We design an IoT ENIR consisting of three layers: a massive heterogeneous device layer,edge network device layer,and knowledge sharing plane.
(2) The edge network device layer is composed of a data plane and a control plane.The data plane is responsible for network data sensing and intelligent routing policy execution.A DRL algorithm is deployed in the control plane for dynamic learning of network data and continuous optimization of routing policies.
(3) The knowledge sharing plane enables network knowledge sharing among ENDS and uses blockchain technology to ensure data transmission security.
(4) We propose an intelligent routing algorithm for IoT edge networks and perform a simulation to verify the method.The simulation results show that the proposed algorithm has a better delay and link utilization performance than comparable methods.
The rest of this paper is organized as follows.Section II presents the related research.Section III describes the architecture and operation of ENIR.A detailed analysis of the DRL algorithm deployed in the ENDS is presented in Section IV.The simulation verification of the algorithm and the discussion are given in Section V.Section VI summarizes the paper.
II.RELATED WORKS
Since ancient routing schemes such as OSPF and RIP rely on manual configuration policies when implementing network routing policies,there are many challenges in finding near-optimal decisions when facing IoT networks with complex requirements.There is already a number of studies focused on how to empower networks with intelligent control and management,enabling faster network response.
Knowledge-Defined Networking (KDN)[16] was proposed In 2017,which creates a knowledge plane on top of the control plane in SDN.However,as a new network architecture,it is only an idea and has no concrete implementation.In the same year,a routing scheme applied to the backbone network was proposed[17].This scheme deploys the Deep Belief Networks (DBN) model to the border routers.It is based on the idea of calculating the forwarding path of each packet within the backbone network by using the current traffic state of each node of the network.However,the deployment of this routing scheme requires extremely high computing power for the backbone routers and modifications to existing routing protocols.Therefore,it is extremely costly and can seriously affect the scalability of the network.Therefore,it is extremely costly and can seriously affect the scalability of the network.Reference[18] compared the effectiveness of various types of models in routing and found that combining topological information with deep learning models is more effective than using the models directly.Stampa’s research group[19]proposed a DRL-based network routing optimization scheme.They used a traffic matrix in the network to calculate the weights of network links to determine the routing paths.Valadarsky et al.[20]analyzes historical traffic data to predict future network traffic and developed appropriate routing configurations based on the traffic prediction results.Reference[21]proposed use the Q-Routing algorithm for a quality of service(QoS)routing problem in software-defined networks (SDNs).The authors regarded the routing problem as a discrete control problem and used a reward function with QoS parameters to improve the end-to-end network throughput.An in-line routing strategy using a multi-intelligence learning algorithm is proposed[22].This algorithm generates routes by calculating the next hop for various service requirements and has good scalability.Reference[23] developed a network intelligent routing algorithm for software-defined data centers.The routing problem was transformed into a scheduling problem of the network resources to obtain optimal network resource allocation.Liu[24] proposed a scheme that combines control theory and Gated Recurrent Unit (GRU).The author proposed Scale-DRL uses the idea of pinning control theory to select a subset of links in the network and name them as critical links,and use the GRU algorithm to dynamically adjust the link weights of critical links.The forwarding path of the flow is dynamically adjusted by a weighted shortest path algorithm.
For traffic matrices with obvious regular characteristics,RL and DL models are able to achieve good routing configurations by traffic prediction and approach optimal routing configuration results.However,in reality,traffic variations in real scenarios are irregular and contain many bursts of traffic.DRL models differ from other machine learning methods in that they can predict future traffic and make optimal routing decisions based on current network state data or historical information,and optimize the current policy based on feedback.However,most studies on network intelligence focused on scenarios in core networks and data center networks,and few studies considered the edge side in network routing optimization for the IoT.
Intelligent architectures and strategies about edge network routing are also being proposed,and their application scenarios include intelligent orchestration of network services and vehicular networking.These solutions combine cloud and artificial intelligence with edge networks,they are used to meet the optimization problems of edge network routing.A federated learning approach for routing in edge networks was investigated[25],which optimizes communication between SDN controllers.The authors proposed Blaster (a federated architecture for routing in distributed edge networks) to improve the scalability of data-intensive applications and predict optimal paths using Long Short-Term Memory(LSTM).A softwaredefined service-centric network (SDSCN) framework was proposed[26].They devised a three-plane architecture,including a data plane,a management plane,and a control plane.Specifically,in-network contextaware computing and caching capabilities are incorporated into the data plane.This framework enables the choreography of network activities through federated learning and flexible customization of network behavior.But the framework does not address the issue of how to ensure fairness when network devices occupy limited resources from each other.Reference[27] developed an efficient adaptive routing scheme based on online sequential learning.It dynamically selects a routing policy for a specific traffic scenario by learning network traffic patterns.However,this scheme is only applicable to a specific region.Faced with a large number of IoT endpoints and a constantly changing IoT network,Yicen Liu[28]presented a service function chain(SFC)dynamic orchestration framework for IoT DRL,and creatively proposed DDPG-based SFC dynamic orchestration algorithm,thus dealing with dynamic and complex IoT network scenarios.Most of these architectures are proposed for joint learning among edge network nodes and resource scheduling aspects,with insufficient research on the intelligence of edge network routing.
Few studies considered information sharing,EI,and blockchain technology.A knowledge trading market based on a federated chain is proposed[29],it can implement knowledge management and trading effectively.The authors designed a federated chain,cryptocurrency,smart contracts,and a consensus mechanism for proof of transaction (PoT).Reference[30]focuses on data sharing in smart cities;AI processes were used to crucial event information from edge nodes,and the results were saved in the blockchain after analysis.Blockchain-based offers provide a range of data services to upper layer applications,including data analysis using AI and sharing of the analysis results.
In summary,most research on network intelligence considered data centers and network business operations and maintenance.Few studies focused on using AI in edge networks.Thus,it is difficult to meet the real-time,micro-burst requirements of IoT edge networks.Some studies combined routing with edge intelligence.However,no deep routing optimization schemes have been proposed,and network knowledge sharing has not been considered.
III.ENIR ARCHITECTURE AND OPERATION MECHANISM
This section introduces the ENIR architecture and its operation mechanism.As shown in Figure 2,the massive heterogeneous devices are connected to the ENDS.This layer is divided into the data plane and the control to separate the data from the control.The data plane monitors the network status information and service traffic demand changes in real time.The DRL agent is located in the control plane to make routing decisions.The agent uses network data for training and continuously performs iterations to optimize the control policies,make optimal routing decisions,and improve network data transmission efficiency.We propose the blockchain for knowledge exchange and interoperability to ensure the security and traceability of knowledge sharing.The network architecture and its operation mechanism are described in detail below.
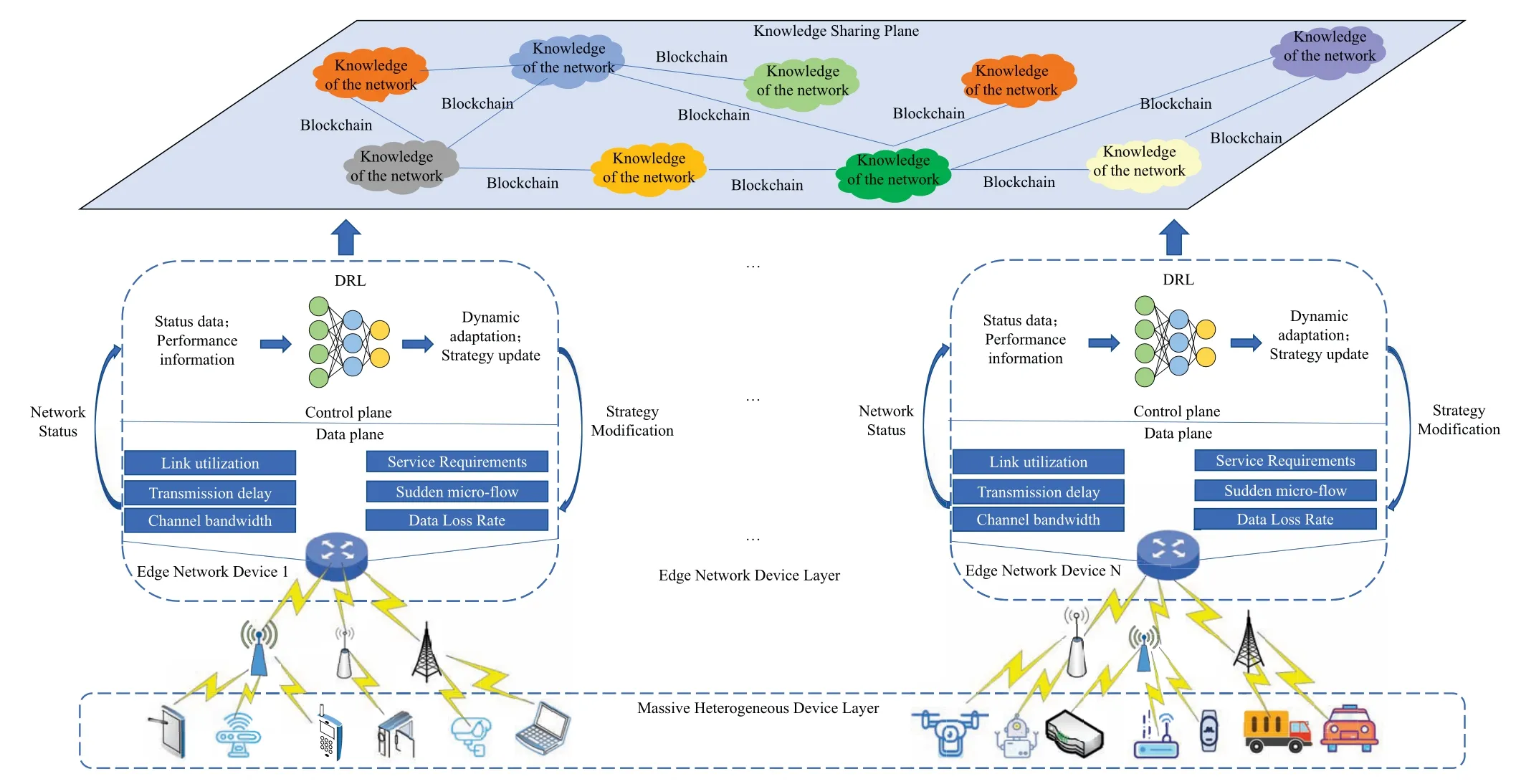
Figure 2. Intelligent routing architecture for IoT edge networks incorporating the blockchain.
3.1 Intelligent Routing Architecture for IoT Edge Networks
This architecture is divided into three parts: a massive heterogeneous device layer,an edge network device layer,and a knowledge-sharing plane.The current IoT environment has numerous heterogeneous devices,including various network cameras,vehicle terminals,smartphones,drones,and robots.These smart terminals must access the network through ENDS such as smart edge gateways,edge routers,and programmable edge switches.However,these devices communicate with each other using different applications and network requirements.Thus,we use the DRL agent in the ENDS to provide network services according to the needs of smart terminals to ensure efficient network data processing and flexible.dynamic routing.
ENDS perform routing,forwarding,and control.They access numerous heterogeneous devices downstream and perform massive network applications with different upstream demands;they are the core of the network.We divide the edge network device layer into a data plane and control plane to separate the functions logically.The data plane is responsible for measuring network events and dynamics and process packets.Specifically,the data plane monitors the network status information (link utilization,micro-burst traffic,transmission bandwidth,data loss rate,etc.) and reports the information to the control plane.Subsequently,the data plane executes the control policies and performs route processing according to the configuration instructions issued by the control plane.The control plane consists of high-performance CPUs and GPUs to provide computational power to train the DRL agent.We deploy the DRL agent in the control plane.After receiving data uploaded from the data plane,the agent analyzes the network characteristics(i.e.,the network state),continuously self-optimizes,and automatically generates control policies.It sends the updated control policies to the data plane to generate network knowledge.
We use a knowledge-sharing plane for network knowledge-sharing among ENDS.Each network device is located in different geographical locations and continuously collects network information.The generated network knowledge depends on the spatial and temporal network conditions.Each edge network device in the knowledge-sharing plane can share this knowledge with other devices to modify the learning process of the control policies,thus improving the global network performance.We utilize blockchain technology to ensure the data and device security of each device during knowledge sharing.
3.2 Intelligent Routing Closed-Loop Control Mechanism
We design an intelligent routing closed-loop control mechanism for adaptive edge network routing.It performs network data measurements and uses the DRL algorithm to determine the network state and optimize the routing policies (Figure 3).The data plane is responsible for collecting network state information and providing the control plane with a global view of the network domain.The control plane obtains the network state information,inputs it into the DRL agent,and converts the agent-generated decision into a flow table rule.The information is then sent to the data plane,which performs routing and forwarding and processes the packets using the rules.The processing results are then uploaded back to the control plane for correction by the DRL agent.
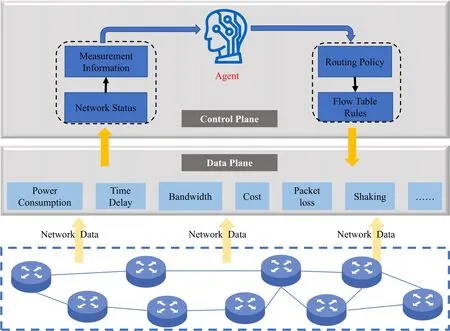
Figure 3. Intelligent routing closed-loop control mechanism.
The DRL agent performs iterations for selfoptimization.A closed-loop control system (network data-model training–decision-making-decision execution -feedback and correction) exists in the edge network device between the two planes to achieve comprehensive awareness,autonomous control,and on-demand routing of the local area network.We refer to these interactions as the intelligent routing closedloop control mechanism.The DRL agent has a powerful learning capability to generate internal control logic for intelligent routing while continuously interacting with the network environment through the data plane.This process enables automatic adaptation to edge-side network dynamics in the IoT environment to improve network performance and meet various business needs.
3.3 Network Knowledge Sharing
Network knowledge is the real value of data and includes learning outcomes and optimization strategies derived from the network state data.Knowledge differs from data because data contain redundant information.Continuous learning and correction by the agent are required to transform data into knowledge.The data plane and control plane constitute the closedloop control of the “network data -model training–decision-making -decision execution -feedback and correction” process,enabling dynamic adaptation to the network state.Although this closed-loop control scheme can quickly adapt to the network dynamics,the individual ENDS are decentralized,the input for model training is limited to the network routing data in the local area,and the output knowledge is also limited to the local area.When the DRL agent encounters unknown network routing data,it needs to relearn,train,and correct.To address this problem,we establish the knowledge sharing plane (Figure 4) for knowledge sharing among DRL models,simplify the training time of the DRL agents,and achieve global optimization of network routing.
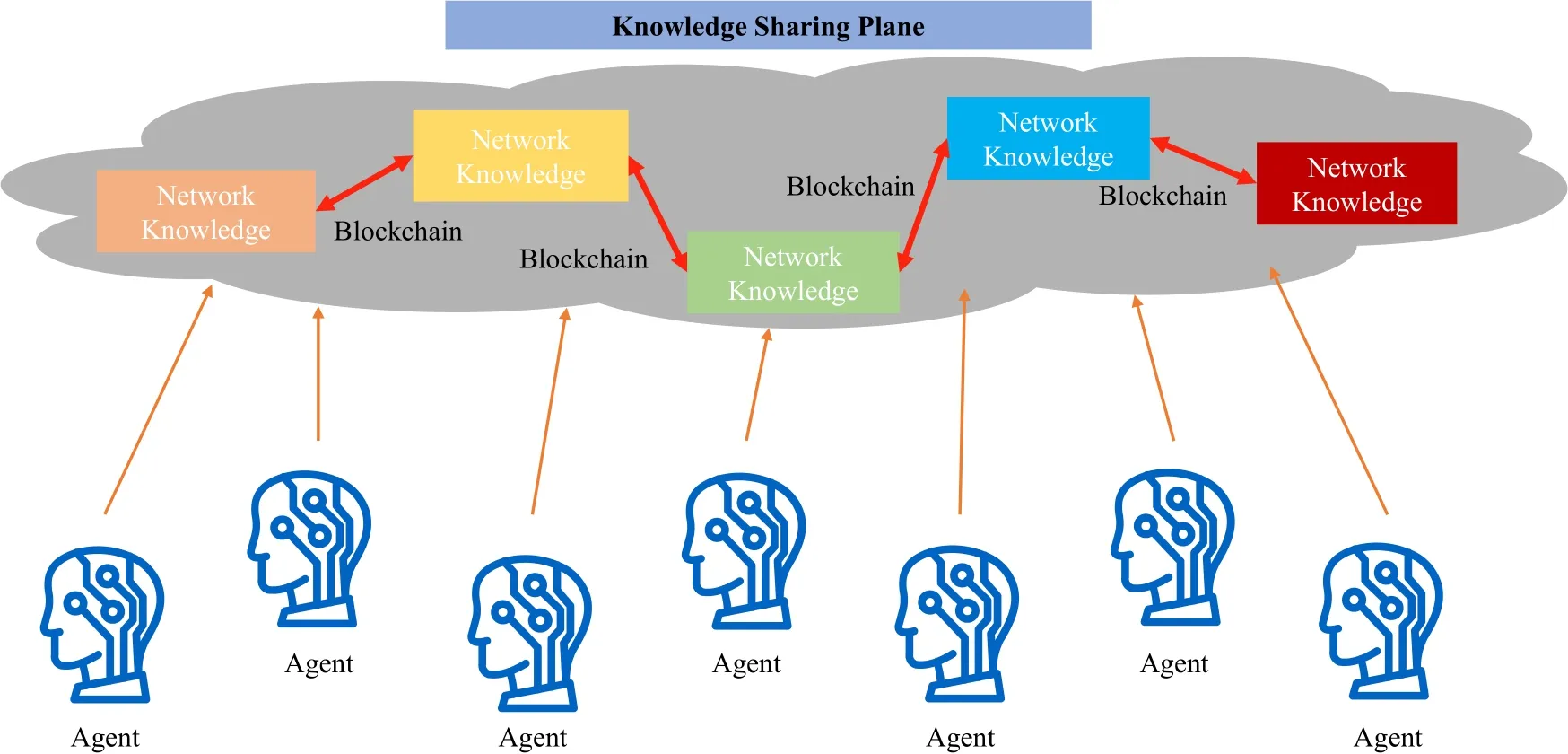
Figure 4. Network knowledge sharing.
The knowledge-sharing approach uses a distributed peer-to-peer (P2P) model because of the large number of geographically dispersed devices and the temporal,physical,and relational heterogeneity of network knowledge.We achieve knowledge management and sharing through the federated chain.If we use the public chain for sharing,some ENDS cannot meet the deployment requirements because of their arithmetic power and power consumption.When using federated chains,only high-powered devices are required for authentication,and other ENDS can share knowledge directly through neighboring high-powered devices.This approach is much less expensive and more efficient.We refer to ENDS that generate network knowledge as knowledge producers (KP) and ENDS that acquire network knowledge as knowledge acquirers (KC).The process of pooling and sharing knowledge is as follows.
Knowledge Pool: (1)All ENDS are assigned an ID after accessing the blockchain,which is generated by asymmetric encryption.(2) The knowledge needs to be given a corresponding index of information to facilitate KC to understand its parameters.(3) After generating the network knowledge,the ENDS should upload its index to a nearby high-powered device,which uploads the index.
Knowledge Sharing: (1) The knowledge sharing process uses a federated chain,which includes smart contracts.KC will continuously search the knowledge sharing chain for needed or interested knowledge.(2) After matching the corresponding parameters,they will initiate sharing requests to the KP.(3)Upon receipt of the request,KP encrypts the knowledge and uploads it to the chain via high-powered devices.Similarly,the shared incoming knowledge is sent to it by a high-powered device near the acquirer,and the knowledge is encrypted using a private key to secure the knowledge.If the acquirer and producer of knowledge belong to the same high-powered device,then it is sufficient to send the knowledge directly.The whole process of both sharing methods is automated by smart contract scripts to ensure efficiency and fairness of knowledge transactions.The sharing record will also be put into the block.
The knowledge sharing plane prevents knowledge silos of ENDS and enables knowledge sharing in the intelligent edge environment.We use blockchain technology to create a knowledge federation chain to ensure the security and efficiency of the plane.In addition,a consensus mechanism is added to the knowledge blockchain since it is applicable to the edge network and reduces resource consumption.
IV.INTELLIGENT ROUTING ALGORITHMS FOR EDGE NETWORKS
In this section,I describe in detail the DDPG algorithm in DRL,and the proposed intelligent routing algorithm based on DDPG.The description of the DDPG algorithm framework reveals the training mechanism of the intelligent body.In order to make the DDPG algorithm better adapted to the network environment,we optimize the DRL framework so that the intelligent routing algorithm can make better decisions.
4.1 Deep Deterministic Policy Gradient Algorithm
The deep deterministic policy gradient (DDPG)method enables efficient and stable continuous motion control and is suitable for performance optimization problems in continuous states.The algorithm framework of the DDPG is shown in Figure 5.In the figure,μ and Q denote the deterministic policy function and the Q function generated by the neural network,respectively.The DDPG algorithm framework is divided into two modules,Actor and Critic,both of which are composed of an online network and a target network.The initial parameters and structures of the two networks are identical,and the online network periodically updates the parameters of the target network with its own parameters.DDPG stores the information of each interaction with the environment in the experience pool during training and obtains the learning samples of the neural network by random sampling of the experience pool.
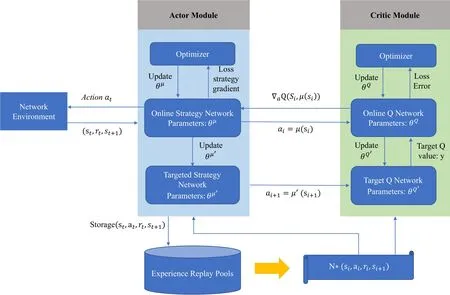
Figure 5. DDPG algorithm framework.
The DDPG contains four networks:
(1) Actor online network: it selects the actionat=μ(st|θμ)based on the current statest.The policy functionμinteracts with the environment to obtainst+1andrt,and update the policy parametersθμbased on the loss gradient∇θμJ.
(2)Actor target network:it selects the actionai+1=μ′(si+1|θμ′) based on the sample statesi+1of each sample obtained from the experience pool.
(3) Critic online network: it calculate the Q-valueQ(si,μ(si|θμ)|θQ) and update the value network parametersθQbased on the loss function L.
(4) Critic target network: it calculates the target Q value.
4.2 DDPG-Based Intelligent Routing
The routing problem in a network can be regarded as a continuous decision problem,and the DDPG algorithm is a policy learning method for continuous behavior.As shown in Figure 6,the proposed intelligent routing algorithm contains four types of elements: state,action,reward,and policy.The agent’s goal is to learn how to output better decisions(actions)in an environment to obtain the maximum sum of reward values,which requires setting appropriate states,actions,and rewards.
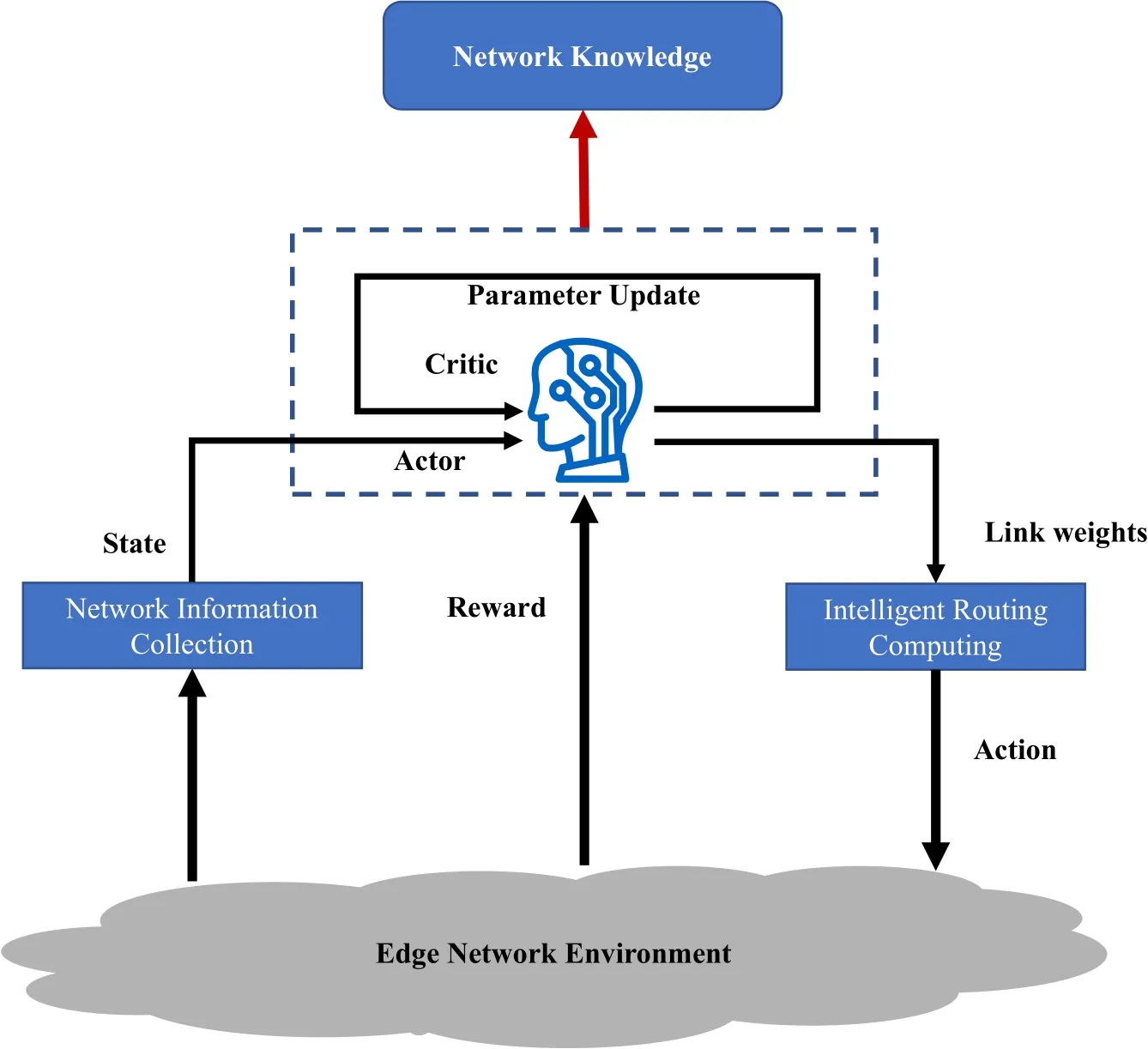
Figure 6. Intelligent routing algorithm based on DDPG.
(1) State: In the DRL model,the state reflects the real-time characteristics of the network environment where it resides.To obtain the state in the network routing scenario,we usually use the data plane to monitor and upload the data to the control plane.IoT edge networks are delay-sensitive and also need to be loadbalanced due to the small bandwidth.We hope to improve edge network routing performance,with the main optimization goals of reducing transmission delay and improving link utilization.We use the time delaytkand link utilizationxk,then the state vector iss=[(t1,x1),(t2,x2),···,(tk,xk),···,(tK,xK)].
(2) Actions: Actions need to be performed by the DRL model according to the current state and policy,i.e.,the specific routing rules issued by the current control plane to the data plane.The data plane receives the instructions to process the packets,and we use the respective link weights[l1,l2,···,ln,···,lN].
(3)Reward: In Figure 6,the rewards in DRL training refer to the network performance metrics fed by the edge network environment.Based on the current moment of the network state and the specific behavior made by the DRL model,the agent will receive feedback in the next moment and calculate the reward based on the feedback.In the edge network environment,we need to consider the delay,throughput,bandwidth,link utilization and other metrics,and the selected metrics are related to the current edge network strategy adopted,and the selected metrics are different for different application requirements.So rewards can be selected for individual performance metrics like latency and throughput,or you can set weights to consider different metrics together:r=α1delay+α2throughput+α3capacity+α4linkutilization,αis the weighting factor.Since this optimization objective is delay and link utilization,we set the reward function to the overall network performance:(α1ti,α2xi),α1=-1,α2=1.
(4)Strategy: The strategy is also known as network knowledge,which is the core of learning.A policy is the mapping from the current state to the current action to guide the agent’s behavior in a given situation.The design of the state,action,reward,and strategy encapsulates the key components of the routing scenario.The control action is generated by the current policy by observing the global state of the network.The new routing rules are passed on to the data plane,the reward is obtained,and the training experience is recorded at the next moment.After uninterrupted data input,the agent can self-optimize and continuously iterate the policy,eventually generating high-value network knowledge.
The specific intelligent routing algorithm runs as follows.First,the online network weightsθQandθμof the Critic and Actor modules are initialized,and copies are createdQ′(θQ′)andQ′(θμ′),respectively)to improve the stability of the target network.The DRL agent continuously interacts with the environment to improve the routing decisions by iteratively learning routing policies and performing the following actions in each iteration.The DRL agent acquires an initial statestand chooses an actionatto execute according to the current policy.Subsequently,the network is in a new statest+1,while the DRL agent receives a rewardrtto evaluate the effect of the action.Then the transition samples(st,at,rt,st+1)are stored in the experience replay pool.The DRL agents are trained on the online network of the Actor and Critic modules using a small sample of transitions randomly selected from the experience pool.The DRL agent updates the online network Q value of the Critic module andθμ,approximating the neural network to the Q table by minimizing the loss.Finally,the DDPG agent updates the target network to improve learning stability.
The core of the DRL agent training is determining the optimal action to maximize the reward based on the network state.The smart body can execute different routing policies for different network scenarios using continuous iterative optimization,achieving dynamic control of traffic scheduling and self-adaptation to the network environment.
V.SIMULATION VERIFICATION
This section introduces the experimental environment of the ENIR architecture and analyzes the performance metrics of the intelligent routing algorithm,including the delay and link utilization.
5.1 Simulation Environment
We test and verify the performance of the intelligent routing algorithm for edge networks by creating a semi-physical network environment.The control plane of the ENIR architecture is implemented using ONOS controllers,and the language to implement the intelligent routing policy is Python;the data plane is used with P4 switches for network data collection.To test the performance of ENIR at different network topology sizes,10 network topologies of different sizes were selected,and the number of network nodes was gradually increased from 5 to 50.The largest topology is shown in Figure 7,50 routing nodes,where each routing node is connected to a device to generate traffic and receive information.In addition,the bandwidth of the links between the nodes in the simulation is 10Mbps,the mounted devices are all active,and the data rate of the devices is 5Mb/s.
Figure 7. Network topologies of biggest sizes.
We also built the knowledge sharing model,which is deployed on Ether.We use Python to implement the interaction between each routing node,the solidity language to write smart contracts,and the compiled smart contracts are deployed to the blockchain.
5.2 Performance Verification
This section compares the ENIR algorithm with 3 routing schemes using different performance metrics.
(1) Open shortest path first (OSPF): this method finds the shortest path by assigning weights to individual network links according to their pre-assigned weight values.This protocol is suitable for large-scale networks.
(2) Distributed routing protocols based on Graph Neural Networks(GNN),which is a method of applying graph-based deep learning to distributed routing protocols via GNN.This approach is applicable to the tasks of shortest path and max-min routing.
(3)Q-routing,is a reinforcement learning routing algorithm based on Q-learning.It treats each routing node as a state in the reinforcement learning model,routes the neighbor node selected for the next hop as the action,and the delay spent for routing each hop as the feedback value obtained from reinforcement learning one action.
(4) DRL-TE is a DRL-based control framework for traffic engineering.The framework maximizes a widely used utility function by learning the network environment and its dynamics,and making decisions guided by Deep Neural Networks(DNNs).
We selected two performance metrics for comparison: transmission delay and link utilization.We performed a comparison verification for each metric.
(1) As shown in Figure 8,we tested and compared the delay of OSPF,Q-Routing,DRL-TE and ENIR at different network sizes.OSPF has the worst performance,and the remaining three routing schemes have little difference in performance at smaller scales.As the network topology size increases,the performance of Q-routing gradually deteriorates,because it uses packet-level routing control,which is difficult to meet the needs of edge networks.The latency of DRL-TE increases dramatically as the routing size continues to get larger.ENIR enables fast response without large performance degradation due to the increased network size because of knowledge sharing.
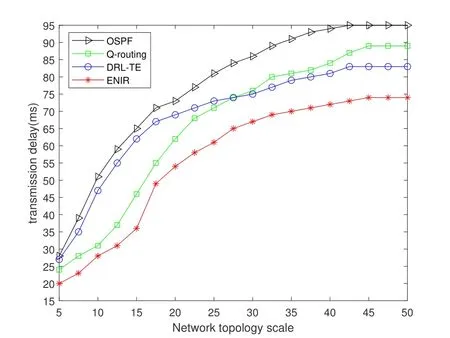
Figure 8.Transmission delay for different network topology sizes.
(2)As shown in Figure 9,we compare the link utilization of OSPF,Q-Routing,DRL-TE,and ENIR,all other things being equal.The link utilization of each scheme decays to different degrees after the routing scale is increased.Among them,Q-Routing performs the worst because it is difficult to sense the congestion removal quickly.The link utilization of ENIR is significantly better than the other three schemes.
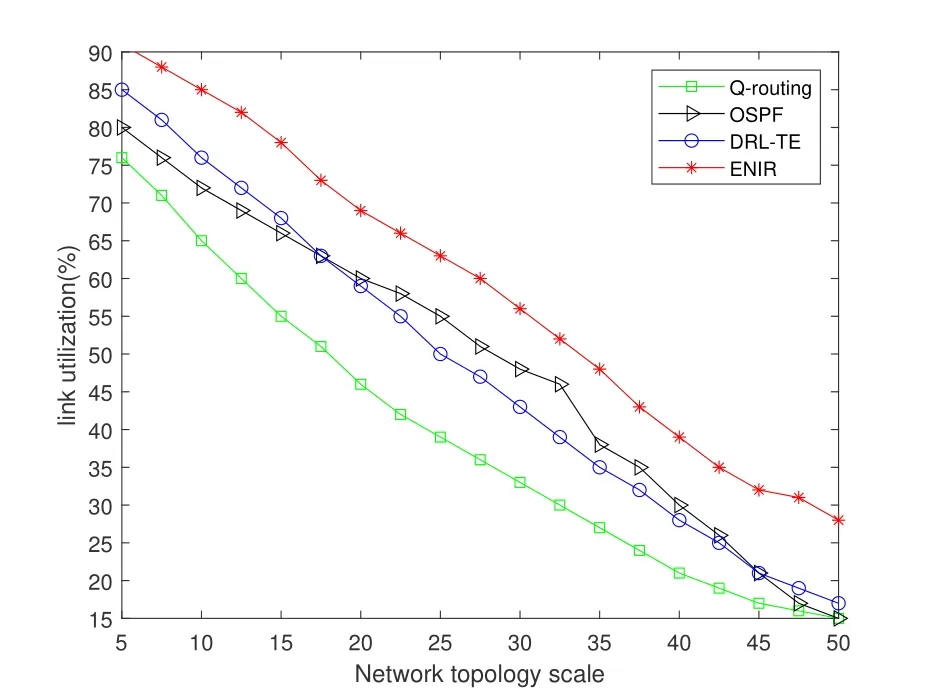
Figure 9. Link utilization for different network topology sizes.
The ENIR outperforms the OSPF,Q-Routing and DRL-TE schemes regarding transmission delay and link utilization.The reason is that ENIR can train the agent with the overall network state and share knowledge.This solution allows faster adaptation to the edge network environment and fast response.
VI.CONCLUSION
In this paper,we propose an intelligent routing architecture for IoT-oriented edge networks,named ENIR,to solve the problems of poor routing adaptability and weak corresponding capability of edge networks,while incorporating blockchain technology to realize knowledge sharing among devices to achieve the goal of global network routing optimization.
Specifically,ENIR uses deep reinforcement learning technology to adjust routing policies and achieve network optimization based on current network demand and state.ENDS can continuously learn and make better routing control decisions by interacting with the network environment.Based on this,an intelligent routing algorithm based on DDPG is designed to maximize the network efficiency.Simulation results show that the algorithm has good convergence and effectiveness.ENIR achieves better network performance by reducing latency and improving link utilization,both compared to traditional OSPF and to more advanced routing policies such as Q-Routing and DRL-TE.We will test the architecture and algorithm in more complex edge network scenarios in the future.
ACKNOWLEDGEMENT
This work has been supported by the Leadingedge Technology Program of Jiangsu Natural Science Foundation(No.BK20202001).

- China Communications的其它文章
- Secure and Trusted Interoperability Scheme of Heterogeneous Blockchains Platform in IoT Networks
- A Rigorous Analysis of Vehicle-to-Vehicle Range Performance in a Rural Channel Propagation Scenario as a Function of Antenna Type and Location via Simulation and Field Trails
- Privacy-Preserving Deep Learning on Big Data in Cloud
- PowerDetector: Malicious PowerShell Script Family Classification Based on Multi-Modal Semantic Fusion and Deep Learning
- Dynamic Task Offloading for Digital Twin-Empowered Mobile Edge Computing via Deep Reinforcement Learning
- Resource Trading and Miner Competition in Wireless Blockchain Networks with Edge Computing