
增量式约简拉氏非对称ν型孪生支持向量回归机
2023-11-16 00:51张帅鑫顾斌杰
计算机与生活 2023年11期
张帅鑫,顾斌杰,潘 丰
江南大学 轻工过程先进控制教育部重点实验室,江苏 无锡 214122
构建贴合样本分布的模型是一项具有挑战性的工作。支持向量回归机(support vector regression,SVR)是贴合样本分布来构建回归模型的经典算法[1]。目前,SVR 已经在许多领域如预测电力负荷[2]、股市价格[3]、风速[4]和天气[5]等取得了成功的应用。
为了提高SVR 的泛化性能,Schölkopf 等人[6]提出了ν型支持向量回归机(ν-support vector regression,ν-SVR),在目标函数中引入比例参数ν(0≤ν≤1)来自动调整SVR 中的不敏感参数ε,实现对支持向量数量的控制。然而,ν-SVR 所考虑的上下ε区间内的样本数量是一样的,为了处理回归问题中的不对称噪声,Huang 等人[7]用弹球损失函数代替ε不敏感损失函数,提出了一种非对称ν型支持向量回归机(asymmetric-ν-support vector regression,Asy-ν-SVR),位于不同位置的样本会受到不同的惩罚,从而模型能够获得更好的泛化性能。
为了加快SVR的训练速度,Peng[8]提出了孪生支持向量回归机(twin support vector regression,TSVR),TSVR 将原来的求解单一大规模二次规划问题转化为求解两个较小规模的二次规划问题,构建两个非平行超平面,其训练速度大约是SVR 的4 倍,并且具有同样出色的泛化性能。随后涌现了大量关于TSVR的研究[9-12]。2017年,Xu等人[13]将TSVR和Asy-ν-SVR相结合,提出了一种非对称ν型孪生支持向量回归机(asymmetric-ν-twin support vector regression,Asy-ν-TSVR),兼顾训练速度和泛化性能。随后,Gupta 等人[14]对Asy-ν-TSVR 进行了改进,提出了一种基于弹球损失函数的改进正则项的拉氏非对称ν型孪生支持向量回归机(Lagrangian asymmetric-ν-twin support vector regression,LAsy-ν-TSVR)。首先用2-范数代替原来松弛变量的1-范数,使得最小化目标函数具有强凸性;然后在目标函数中加入正则化项,以遵循结构风险最小化原则;最后使用线性迭代收敛法改善计算性能,实验结果表明,LAsy-ν-TSVR 能获得比SVR、TSVR 以及Asy-ν-SVR 更出色的泛化性能。此后,为了解决核函数的半正定性问题,Gupta等人[15]提出了一种鲁棒的拉氏非对称ν型孪生支持向量回归机,引入光滑函数改进模型的训练速度,并提升了泛化性能。
然而,以上研究都是传统离线学习方法,不能满足在给定时间内处理大量数据的要求,从而导致越来越多的未处理数据累积,同时并未把新信息不断地集成到已经构建的模型中,可能会导致过时的模型。在大数据情况下,增量算法能够有效地解决以上问题。针对SVR 的增量形式,目前学者们取得了很多研究成果,主要分为精确求解形式和近似求解形式。
精确求解形式的回归模型以Ma等人[16]提出的精确在线支持向量回归模型(accurate online support vector regression,AOSVR)为代表,保留逐个增加的每一个训练样本,能够求得模型的精确解,不会降低模型的泛化性能。随后,受AOSVR 思想的启发,Gu等人[17]提出了增量式支持向量有序回归学习算法,顾斌杰等人[18]提出了精确增量式在线ν型支持向量回归机。之后,为了降低噪声的影响,并加快训练速度,Huang 等人[19]提出了一种在线鲁棒支持向量回归机(online robust support vector regression,ORSVR)。最近,曹杰等人[20]提出了一种精确增量式ε型孪生支持向量回归机,实现了ε型孪生支持向量回归机高效地增量处理线性回归问题。
近似求解形式通过对输入样本的预处理或者筛选,只能求得目标函数的近似最优解。Hao等人[21]提出增量式最小二乘孪生支持向量回归机,通过矩阵求逆引理和基于已有核矩阵仅添加新增样本与旧样本构成的行向量,保持解的数量不增长,使增量更新模型的速度加快。为了解决最小二乘孪生支持向量回归机(least squares twin support vector regression,LSTSVR)存在构成的核矩阵无法很好地逼近原核矩阵的问题,曹杰等人[22]提出一种增量式约简LSTSVR。
目前还没有关于拉氏非对称ν型孪生支持向量回归机的增量学习算法。尽管Gupta 等人[15]对拉氏非对称ν型孪生支持向量回归机进行了光滑处理,提升了泛化性能,但其仍然是离线算法,并不适用于增量提供样本的场景(极端情况下,每次仅提供一个新样本),例如:时间序列预测、网络监测、入侵检测、数据挖掘、金融数据分析、谷氨酸发酵过程等。一方面,现有的拉氏非对称ν型孪生支持向量回归机无法随着样本的到来动态更新模型;另一方面,在历史样本积累到计算机内存无法承载处理的程度,应当考虑如何削减样本集的大小,保留有效的样本信息。为了将拉氏非对称ν型孪生支持向量回归机推广到在线学习模式,并缓解增量过程中内存消耗问题,本文提出一种增量式约简拉氏非对称ν型孪生支持向量回归机(incremental reduced Lagrangian asymmetric-ν-twin support vector regression,IRLAsy-ν-TSVR)。针对现有的LAsy-ν-TSVR 离线模型无法高效求解增量问题,选择特征相异的样本,构建能够保留原增广核矩阵中线性无关的列向量和行向量的增广核矩阵,然后以约简后的增广核矩阵为基础,推导增量递推公式,构建增量式约简拉氏非对称ν型孪生支持向量回归机。最后通过实验验证算法的可行性和有效性。
1 拉氏非对称ν型孪生支持向量回归机
拉氏非对称ν型孪生支持向量回归机的原始问题如下[15]:
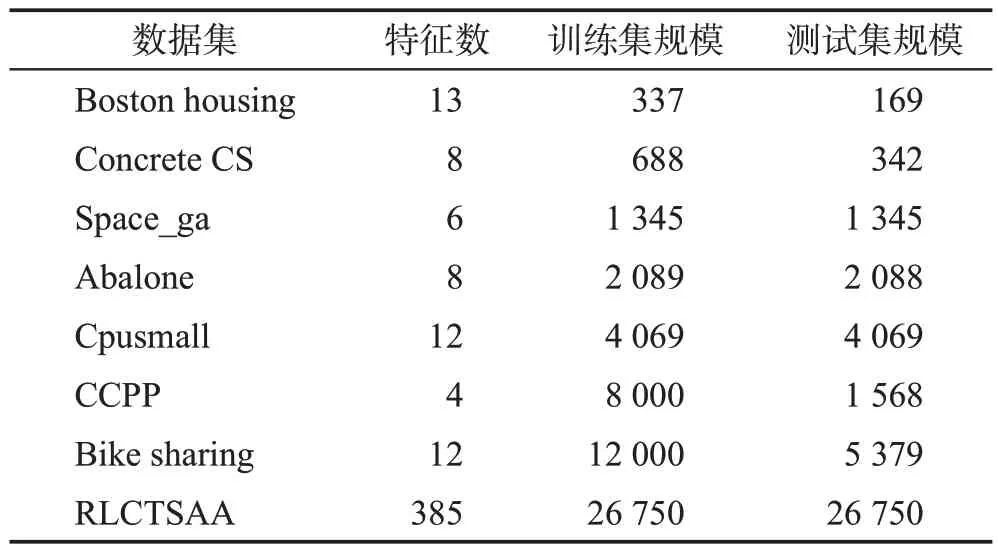
其中,ω1,ω2∈Rm为权重向量,b1,b2∈R 为偏置,C3,C4>0 为正则化常数,C1,C2>0 为线性项常数,ξ1,ξ2∈Rl是松弛向量,||∙||表示2范数,e表示元素全为1的列向量,0 式(1)和式(2)的对偶问题如下[15]: 因此,对于某个测试输入x可通过式(5)预测其输出: 本章首先引入正号函数,将拉氏非对称ν型孪生支持向量回归机的有约束最优化问题转换成无约束最优化问题,并说明为什么采用半光滑牛顿法直接在原始空间求解最优化问题;其次在增量环境下,为了节省矩阵求逆的时间开销,讨论如何利用矩阵求逆引理高效更新Hessian 逆矩阵;然后为了减少大规模数据集情况下样本累积导致的内存消耗,采用约简技术筛选出特征差异较大的样本,以确保解的稀疏性;最后给出了增量式拉氏非对称ν型孪生支持向量回归机算法的步骤,并分析了时间复杂度。 由于在原始问题转化为对偶问题后往往要求解一对二次规划问题,而二次规划的解不一定是凸优化最优解。Fung等人[23]将半光滑牛顿法运用到拉氏支持向量分类机上,直接在原始空间中求解凸优化问题,进一步加快了模型的收敛速度。受其启发,考虑到LAsy-ν-TSVR的目标函数具有局部连续二次梯度的特性,使用半光滑牛顿法可以保证局部二次收敛,为此采用半光滑牛顿法[24-25]在原始空间直接求解最优化问题,并将目标函数修改成方便后续增量推导的形式。 首先,参照文献[25]中的方法,引入正号函数(x+)=max{0,xi},i=1,2,…,l,将式(1)和式(2)改写成如下无约束最优化问题: 为了更加方便直观地处理正号函数,将式(6)和式(7)简化为: 其中,Λ1、Λ2表示对角矩阵,以式(8)为例,当第i个输入样本的二次梯度不存在时,则Λ1的第i个对角元素为0,表示为。式(9)中Λ2的第i个对角元素也同样构造。 ν型和ε型的区别在于ν型用一个比例参数ν去灵活控制管道宽度ε。因此,将ε当成一个变量,对含有双变量的目标函数求最优解。 接着,对目标函数L1分别求关于u1和ε1的偏导数,整理得到Jacobian矩阵为: 虽然在2.1 节中用半光滑牛顿法重新对LAsy-ν-TSVR进行了求解,加快了收敛速度[15,25],但是其仍是离线算法,无法处理在线问题。为此,结合逆矩阵的增量更新公式,将拉氏非对称ν型孪生支持向量回归机改写成增量形式。假设下标t表示t时刻,上标k表示第k次迭代,以此类推。假设在t+1 时刻,新增一个样本(xl+1,yl+1),则基于增量更新公式,u1(t+1)、u2(t+1)可以由u1(t)、u2(t)快速更新求解。接下来,将分别描述初始化和迭代更新的详细步骤。 2.2.1 初始化 初始化对角矩阵计算如下: 引理1[26]设A是l×l的可逆矩阵,b是l×1的向量,d是标量,且d-bTA-1b≠0,则有: 由引理1可得: 因此,Hessian矩阵的逆只需要通过求解W1的逆便可以求得。 在t+1时刻的初始矩阵如下: 引理2[27]设A∈Rl×l为非奇异矩阵,u,ν∈Rl是任意向量,若1+νTA-1u≠0,则A+uνT非奇异,且其逆矩阵可表示为: 2.2.2 迭代更新 离线算法和增量算法的共性问题是:增广核矩阵的行列数会随着输入样本的增加而增加,算法的复杂度会随着解的维数指数增长。因此,为了缩短大规模数据下的训练时间,同时减少由于大规模数据集情况下样本累积带来的内存消耗,提出了一种增量式约简拉氏非对称ν型孪生支持向量回归机(IRLAsy-ν-TSVR)。该算法利用约简技术,首先通过筛选特征差异较大的输入样本,对应保留原增广核矩阵中线性无关程度较大的列向量;然后筛选增量过程中位于ε管道以外的样本,对应保留原增广核矩阵中对模型信息贡献较大的行向量,以此构成约简增广核矩阵。接下来对该IRLAsy-ν-TSVR算法的约简部分进行描述。 2.3.1 增广核逆矩阵列约简 在t+1 时刻,新增一个样本(xl+1,yl+1),假设之前l个样本中按照列约简技术已经筛选出线性无关程度较大的样本,命名为基准样本,并将基准样本存储在集合B中,用式(13)来判定该样本是否为基准样本: 然后,把式(14)代入式(13),可由式(12)求得Δ的值: 如果Δ大于或者等于预先设定的常数ρ∈(0,1),那么新增样本被添加到集合B中;否则,不被添加到集合B中。 在处理完当前新增样本的列归属之后,还要更新Φt+1,为处理下一轮新增样本做准备。需要考虑如下两种情况: 2.3.2 增广核逆矩阵行约简 在t+1 时刻,新增一个样本(xl+1,yl+1),假设之前l个样本中按照行约简技术已经筛选出特征差异明显的样本,并将其按照输入顺序存储在集合P中,以下用式(18)来判断是否当前的输入样本应该为增广核矩阵增加一行有效的数据行: 如果γ1大于或者等于本轮迭代更新得到的ε1(t+1),也就是间隔函数的预测值位于ε1(t+1)带以外,则新增样本被添加到集合P中;否则,新增样本被丢弃。 同样,在处理完当前新增样本的行归属之后,还要更新Φt+1,根据列约简的分属情况,将行约简总结为以下四种情况: 情况1如果样本不被添加到集合B中,但被添加到集合P中,则Φt+1的更新与式(16)相同。 情况2如果样本不被添加到集合B中,同时也不被添加到集合P中,相当于丢弃新增样本对增广核矩阵的更新信息,增广核矩阵既不增加行,也不增加列,则Φt+1无需更新。 情况3如果样本被添加到集合B中,同时被添加到集合P中,则Φt+1的更新与式(17)相同。 情况4如果样本被添加到集合B中,但不被添加到集合P中,相当于执行增广核矩阵的列更新而不执行行更新。则: 算法1 给出了IRLAsy-ν-TSVR 中迭代求解u1(t+1)和ε1(t+1)的过程。 u2(t+1)和ε2(t+1)可以用同样的算法步骤求解,此处不再赘述。 针对2.3 节和2.4 节给出的增量算法,以下分析新增一个输入样本所需的时间复杂度,并且将其分为半光滑牛顿法寻优时间复杂度和约简样本时间复杂度。由于加法时间复杂度所消耗的时间远小于乘法时间复杂度,分析时只考虑后者。 综上,如果使用直接求解逆矩阵的方法来计算半光滑牛顿法的二阶梯度,其时间复杂度将为,而结合矩阵求逆引理,可将复杂度由原先的立方阶降至平方阶,大大加快了算法的运算速度。虽然在更新时的时间复杂度为立方阶,但考虑到与l1、l2有关,而l1、l2大小是由约简过程中的参数ρ和中间计算的ε1、ε2进行控制。实际上,只要参数相对合理,在增量过程中会筛选掉大量线性无关的样本,时间复杂度远远小于立方阶,同时能够保证精度损失不严重。 为了验证所提出的IRLAsy-ν-TSVR 算法的优势,选取AOSVR、拉氏ε型孪生支持向量回归机(Lagrangianε-twin support vector regression,L-ε-TSVR)[28]、LAsy-ν-TSVR、光滑鲁棒非对称拉氏孪生支持向量回归机(smooth robust asymmetric Lagrangianν-twin support vector regression,SRALTSVR1)[15]在基准测试数据集上进行对比,其中,AOSVR是增量学习算法,其余都是离线学习算法,而SRALTSVR1是指用平滑近似函数ζ1(x,τ)=x+ln(1+exp(-τx))/τ将LAsy-ν-TSVR 光滑处理的算法,其中ζ1(x,τ)是τ+的近似函数,τ为非负实数。所有实验均在Intel i5-8400T(@1.70 GHz)处理器,8 GB 内存的PC,Matlab 2016a软件平台上完成。 表1 中给出了实验所使用的8 个基准测试数据集,它们分别是Boston housing、Concrete CS(compressive strength)、Space_ga、Abalone、Cpusmall、CCPP(combined cycle power plant)、Bike sharing和RLCTSAA(relative location of CT slices on axial axis),数据集规模从506到53 500不等,且所有数据集的特征被归一化到[0,1],然后划分为训练集和测试集。 表1 实验中使用的基准测试数据集Table 1 Benchmark datasets used in experiment 在训练集上采用5 次五折交叉验证,共25 次实验的平均值进行参数寻优,最终以训练集上的最优模型在测试集上的表现来评价模型的性能。采用均方根误差(root mean square error,RMSE)和绝对平均误差(mean absolute error,MAE)来综合评价回归算法的泛化性能,并且在实验中统计了列解稀疏率φ和行解稀疏率ψ,具体定义见式(20)~式(23)。同时记录了训练平均单个样本所需的CPU时间,单位为s。 其中,表示第i个输入样本的预测值,yi表示第i个样本的实际输出值,l为当前训练样本的总数,lB是集合B中样本的个数,lP是集合P中样本的个数。 采用网格化搜索进行参数寻优,为了保证实验条件一致性和对比公平起见,AOSVR 的参数设置为ε=0.01,C=2i在i∈[-8,8]范围内寻优。L-ε-TSVR的参数设置为C1=C2=2i,C3=C4=2i在i∈[-8,8]范围内寻优,ε1=ε2=0.01。LAsy-ν-TSVR和SRALTSVR1的参数设置为v1=v2=j×0.1,r=k×0.1,在j,k∈[1,9]范围内寻优,C1~C4的设置与L-ε-TSVR 相同。IRLAsy-ν-TSVR 使用与对应离线算法相同最优参数,最大迭代次数设置为k=100,半光滑牛顿法迭代停止精度设置为σ=10-5,列线性无关常数ρ=10-3。 为了便于比较,统一选取高斯径向基核函数作为核函数K(xi,xj)=exp(-||xi-xj||2/2σ2),其中核参数σ=2i在i∈[-5,5]范围内寻优。 表2 所示为选取的五种算法在基准测试数据集上的实验结果,“—”表示该处指标无意义,“@”表示内存不足无法运算。为了清楚起见,最优指标加粗表示。 表2 五种算法在基准数据集上的实验结果Table 2 Experimental results of five algorithms on benchmark datasets 从表2 可以看出,相对其他四种算法,本文算法的RMSE更小,也就是泛化性能要优于AOSVR、L-ε-TSVR、SRALTSVR1 和其对应的离线算法LAsy-ν-TSVR,即继承了LAsy-ν-TSVR 的泛化性能,这与文献[14]中的结论一致,一方面参数ν和非对称参数q的引入让模型灵活地去贴合样本,另一方面在约简过程中,剔除相似特征的列向量和约简对预测性能贡献较小的行向量,使得处理过后的核矩阵比只筛选列向量更加逼近原核矩阵,获得和离线算法相当甚至更优的泛化性能,而其他算法的增广核矩阵由于没有行列信息筛选的步骤,并不能反映原核矩阵的有效信息。同时,在单步增量的半光滑牛顿迭代中,设置合适的迭代停止精度也会让模型的RMSE更小。 从行列稀疏率指标上看,只有本文算法对核矩阵的行具有约简过程,其稀疏率随着样本的增加而减小,说明其有效地剔除了核矩阵中的无效行,使增广核矩阵逼近原核矩阵。 对于单个样本的增量时间,本文提出的IRLAsyν-TSVR与L-ε-TSVR和LAsy-ν-TSVR相比有着相当大的优势,通过2.5 节的时间复杂度分析,IRLAsy-ν-TSVR 的平方阶复杂度优于离线算法的立方阶的时间复杂度,但对比SRALTSVR1 算法,其训练速度较差,主要原因在于本文算法添加了对增广核矩阵的列向量和行向量的约简,如2.5节中四种行约简情况所分析部分,具体的时间复杂度取决于样本的归属情况,同时在增量过程中,更新初始解和更新Hessian矩阵的过程中,也会增加平方阶的时间复杂度,从而导致增量过程中平均一次更新时间稍大。但是从数量级上来看,两者在大规模数据集CCPP上平均单个样本的增量时间数量级相当,时间相差不大,详见2.5节中的时间复杂度分析。 对于更大规模的数据集Bike sharing和RLCTSAA,由于三种离线算法均因为超过内存无法运算,表2中仅列出在线算法的实验结果。在数据集Bike sharing上,虽然本文提出的IRLAsy-ν-TSVR 训练速度不及AOSVR,但RMSE 和MAE 更小。而在数据集RLCTSAA上,只有本文提出的IRLAsy-ν-TSVR能够训练,这也体现其解决大规模数据集的在线学习问题的优势。 为了使算法对比更加直观,图1 给出了在CCPP数据集上,RMSE、MAE、总训练时间随着训练样本个数的增加的变化过程。从图1(a)和图1(b)中可以看出,在大规模数据集上,本文算法在RMSE和MAE的下降趋势方面都要优于SRALTSVR1。 图1 CCPP数据集上不同算法的性能对比Fig.1 Performance comparison of different algorithms on CCPP dataset 从图1(c)中可以看出,IRLAsy-ν-TSVR 算法的总训练时间要小于LAsy-ν-TSVR算法,与AOSVR算法类似,训练总时间大致呈线性增长。IRLAsy-ν-TSVR 的时间增长趋势要优于AOSVR,这是由于AOSVR 算法属于精确增量算法,在其每次增加样本时,所有历史样本的信息都要整合到核矩阵中,稀疏率会远大于本文算法,增加后续增量过程中的计算量。但相较于SRALTSVR1,本文算法的训练时间较长,是因为本文算法一方面增加了对列向量和行向量的约简处理,另一方面,本文算法增加了增量过程和半光滑牛顿法中Hessian 矩阵初始化和迭代更新,因此本文算法的时间复杂度要稍大于SRALTSVR1算法。本文算法的时间复杂度由l1、l2决定,参与模型更新的样本减少,即l1、l2减小,总的训练时间也相应减少。 此外,为了体现本文算法在迭代更新时模型的收敛情况,图2统计了在CCPP数据集上,每次新增一个样本时,IRLAsy-ν-TSVR 算法中半光滑牛顿法的迭代次数。从图2中可以看出,大多数情况下仅需要两次迭代就可以收敛到设定的迭代停止精度,少数情况下只需要一次。一方面,增广权重向量在梯度方向上的维度是累加的,增量过程使得在每次添加解的维度时只需要对新增维度进行梯度下降纠正,加快了收敛速度;另一方面,在列举的四种约简情况中,有的情况对模型有较小更新,甚至无需更新,这也会缩短算法的训练时间。 图2 CCPP数据集上每次新增一个样本时IRLAsy-ν-TSVR的迭代次数Fig.2 Iterations of adding a new sample for IRLAsy-ν-TSVR on CCPP dataset 本文将约简技术运用到拉氏非对称ν型孪生支持向量回归机上,提出了一种增量式约简拉氏非对称ν型孪生支持向量回归算法。在增量过程中,该算法结合矩阵求逆引理,通过对增广核矩阵的行列约简以逼近原增广核矩阵,避免了半光滑牛顿法中Hessian 矩阵的直接求逆,获得约简拉氏非对称ν型孪生支持向量回归机模型,在保证最优解的高效更新的同时,实现了解的稀疏化与解的增量连续性,而且继承了原离线算法的泛化性能。实验结果表明,本文算法获得的模型和离线模型具有相近的回归精度,并且能够获得稀疏解,与利用光滑函数优化的离线算法SRALTSVR1 相比,泛化性能更加出色,因此更加适合解决大规模数据集的在线学习问题。2 增量式约简拉氏非对称ν型孪生支持向量回归机
2.1 半光滑牛顿法
2.2 高效更新逆矩阵和对角矩阵
2.3 约简技术
2.4 算法步骤
2.5 时间复杂度分析
3 数值实验与分析
3.1 实验设计和参数设置
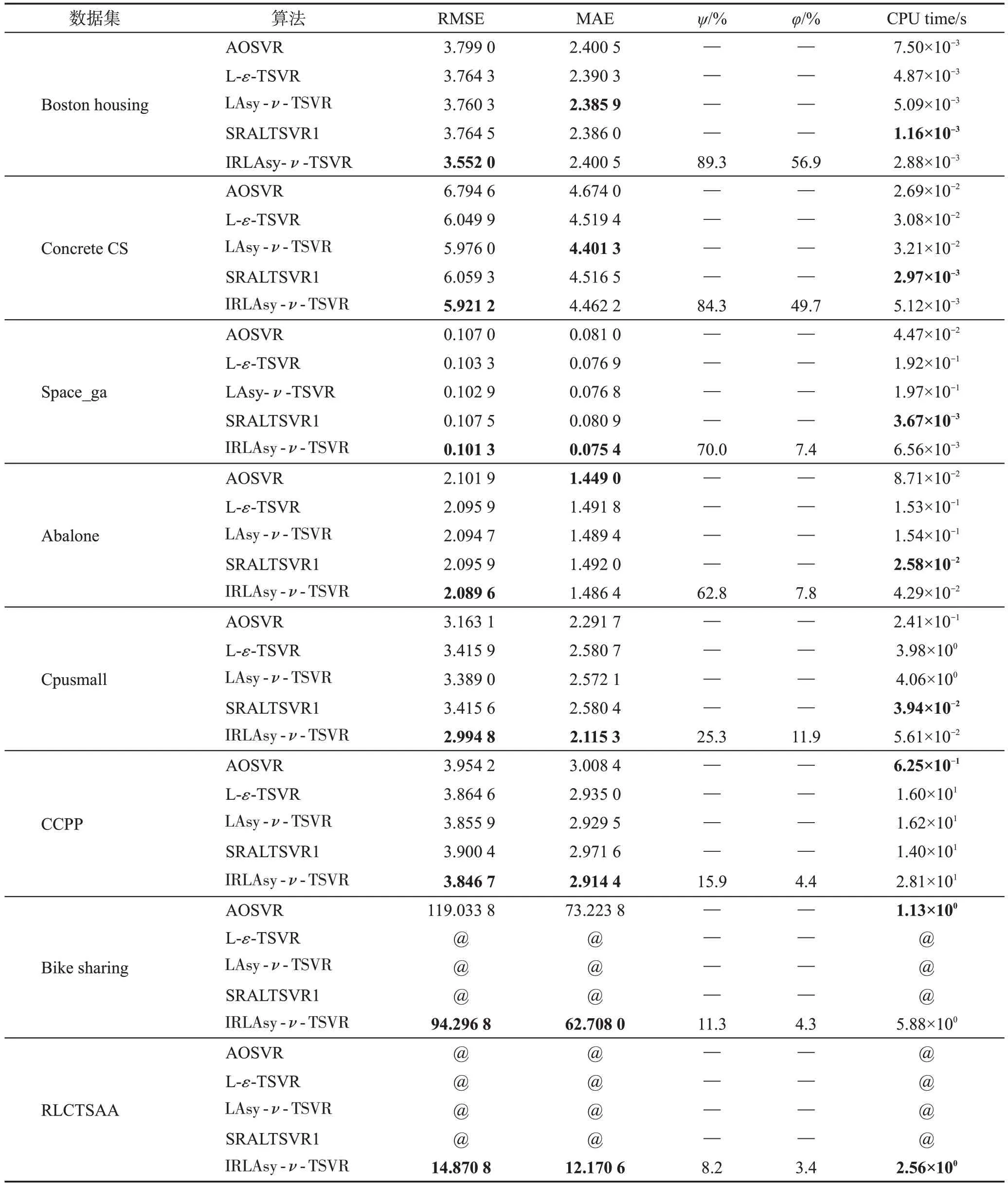
3.2 实验结果分析
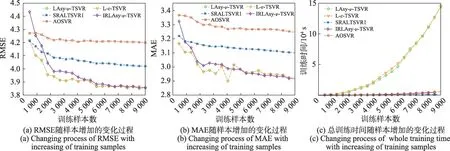
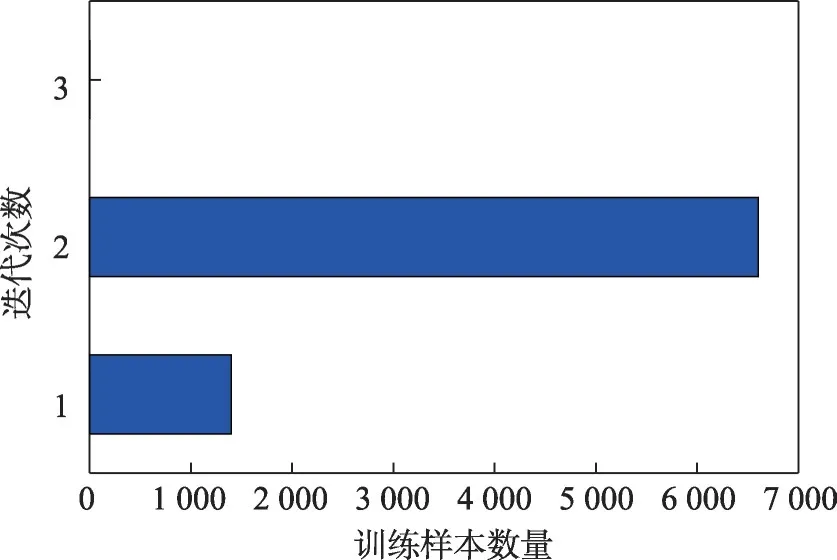
4 结论
猜你喜欢
科教导刊·电子版(2022年14期)2022-07-25
水产科学(2022年2期)2022-03-20
成都信息工程大学学报(2019年2期)2019-08-28
数学年刊A辑(中文版)(2018年2期)2019-01-08
自动化学报(2018年2期)2018-04-12
成都信息工程大学学报(2017年1期)2017-07-21
数学理论与应用(2016年4期)2016-05-17
电测与仪表(2015年4期)2015-04-12
河南科技(2014年7期)2014-02-27
电气电子教学学报(2010年3期)2010-08-23
