
多标签分类综述
2023-11-16 00:50李冬梅孟湘皓张小平赵玉凤
计算机与生活 2023年11期
李冬梅,杨 宇,孟湘皓,张小平,宋 潮,赵玉凤+
1.北京林业大学信息学院,北京 100083
2.国家林业草原林业智能信息处理工程技术研究中心,北京 100083
3.中国中医科学院中医药数据中心,北京 100700
随着信息技术的不断发展,蕴含丰富信息的标签数据在呈指数级别地增长。为了从中获取更多有价值的信息,研究人员开展了一系列与标签分类相关的研究。传统的单标签分类包括二分类和多分类,其最终结果都是将标签集中的单个标签分配给一个实例。目前,这一研究方向已有许多成熟的算法,这些算法具有较好的性能,并成功地应用于许多领域[1]。然而,在现实情况中,一个实例往往同时与多个标签相关联[2]。例如,在文本分类中,一份电子病例可能与糖尿病、高血压、冠心病等多种疾病有关[3];在图像分类中,一张舌诊图像可以同时表达舌色、舌苔、形状等特征[4],进而能推断出患者的多种体征标签[5];在音乐分类中,一段音频可以传递各种信息,如钢琴、古典乐、莫扎特等[6]。这一研究方向被称为多标签分类,其本质是将一个实例与一个标签集合相关联。与单标签分类不同的是,在多标签分类中,每个实例对应的标签不止一种,标签的数量也是不确定的。此外,标签与标签之间存在语义相关性,一些领域的数据集还存在标签不均衡现象,这些问题都给多标签分类任务带来了一定的挑战。
多标签分类问题的研究出现在2000 年初,Tsoumakas等人[7]于2007 年首次对多标签分类进行了综述。随后,Zhang 等人[8]介绍了多标签学习的基本原理,同时还分析了挖掘标签之间相关性的3 种策略,并对8 种典型的多标签学习算法进行了讨论。Mayano 等人[9]根据标签间的依赖性和维数等特征,对来自不同领域具有不同特征的20 个数据集上的18种多标签分类集成算法进行了评估。武红鑫等人[10]从监督学习和半监督学习两方面对多标签分类算法进行了综述,同时还从不同的领域对其实际应用进行了介绍。近年来,深度学习技术发展迅猛,不少结合深度学习的多标签分类方法被提出。目前,多标签分类方法可以分为传统的多标签分类方法以及基于深度学习的多标签分类方法。传统机器学习方法从机器学习的理论出发,存在文本表示向量特征表达能力不足、人工实现特征表示的成本过高等问题;深度学习方法则通过卷积神经网络、循环神经网络等结构自动对特征进行提取,释放了人工成本,增强了特征表达能力。因此,本文将从传统和深度学习两个角度分别对多标签分类方法进行介绍,总体框架如图1 所示。
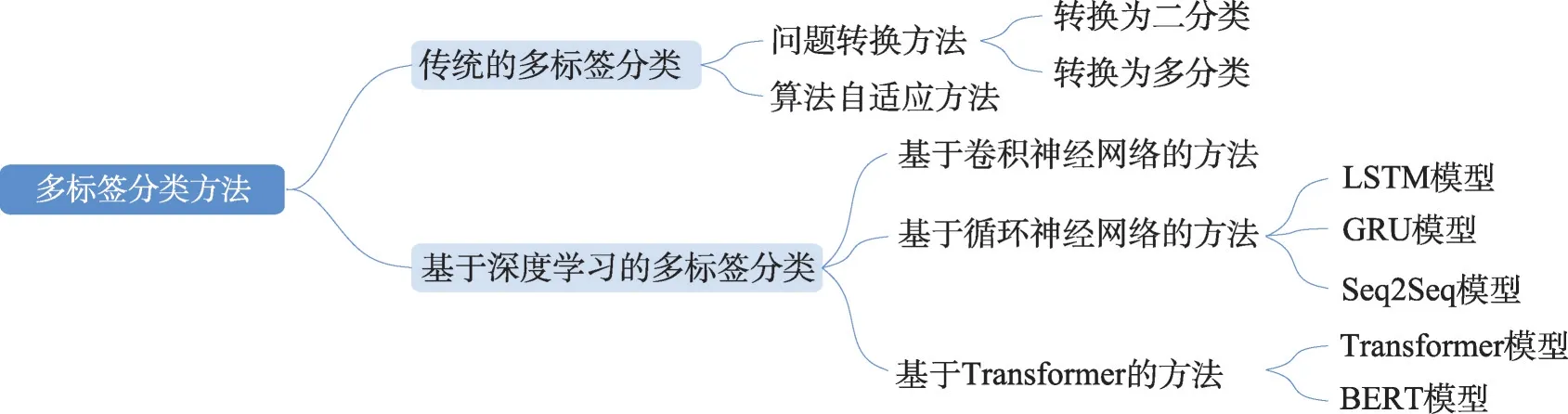
图1 多标签分类方法的总体框架Fig.1 Overall framework of multi-label classification methods
1 多标签分类的定义
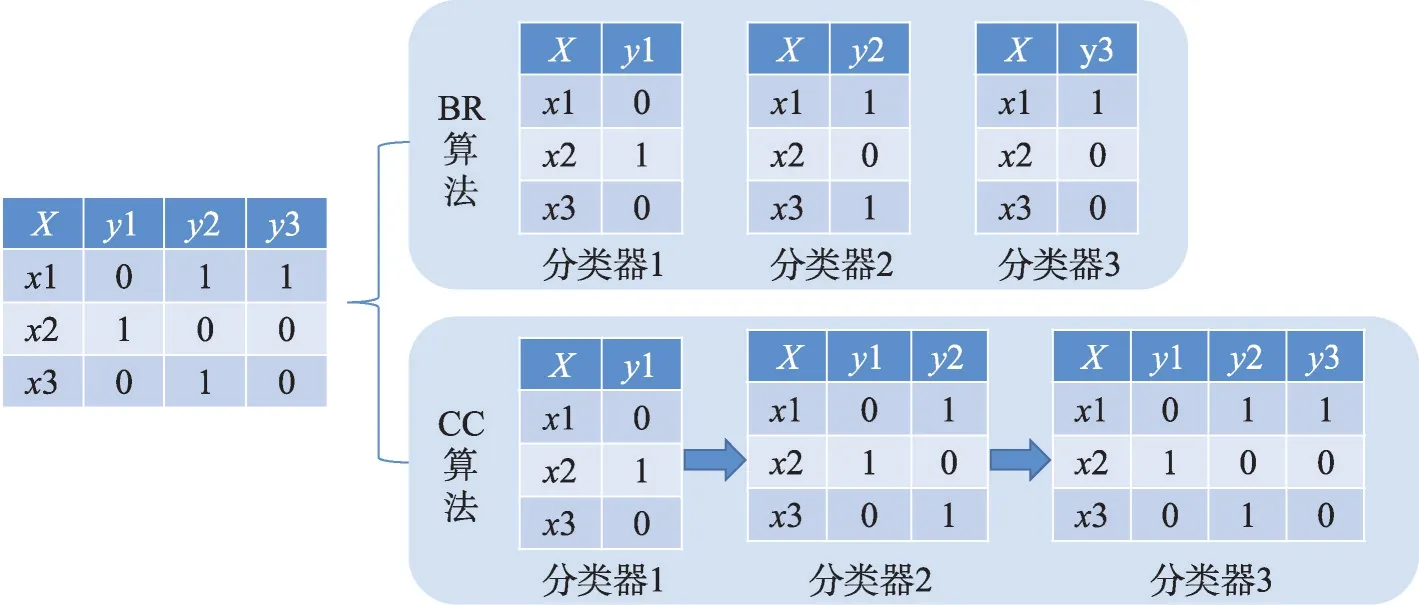
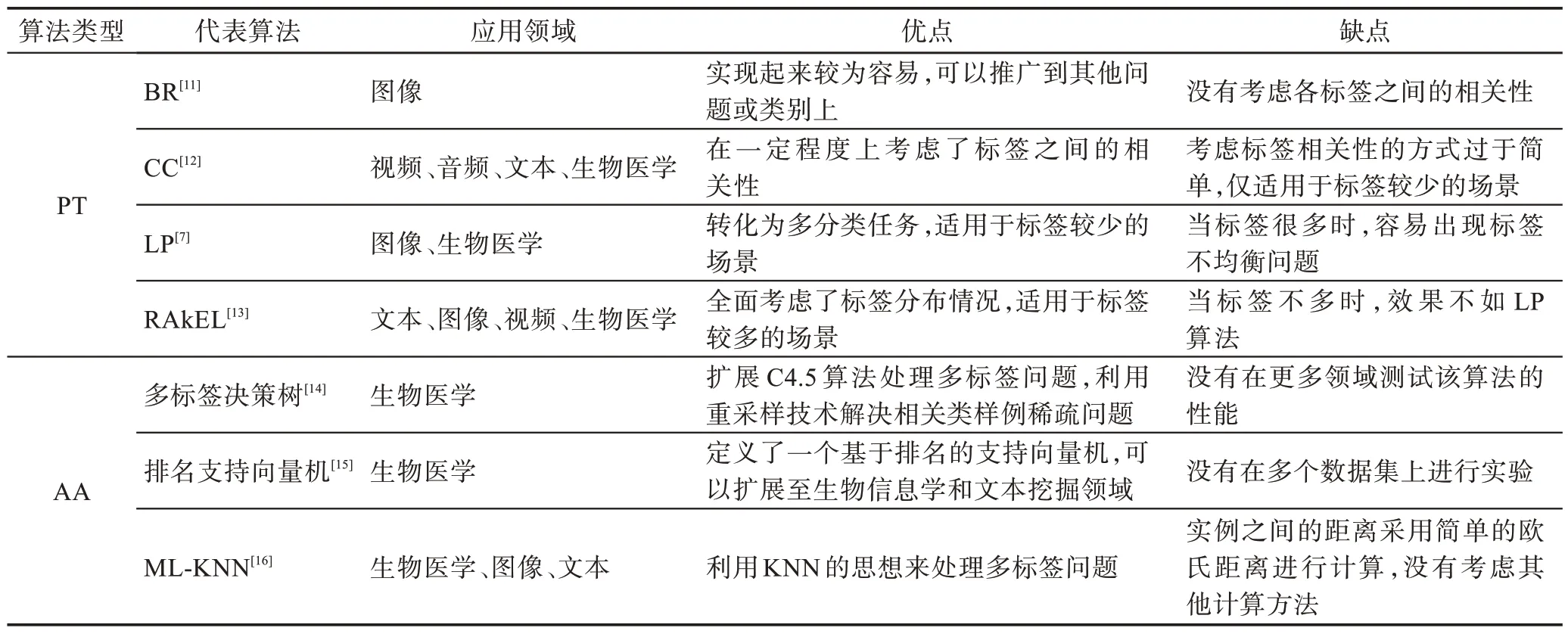
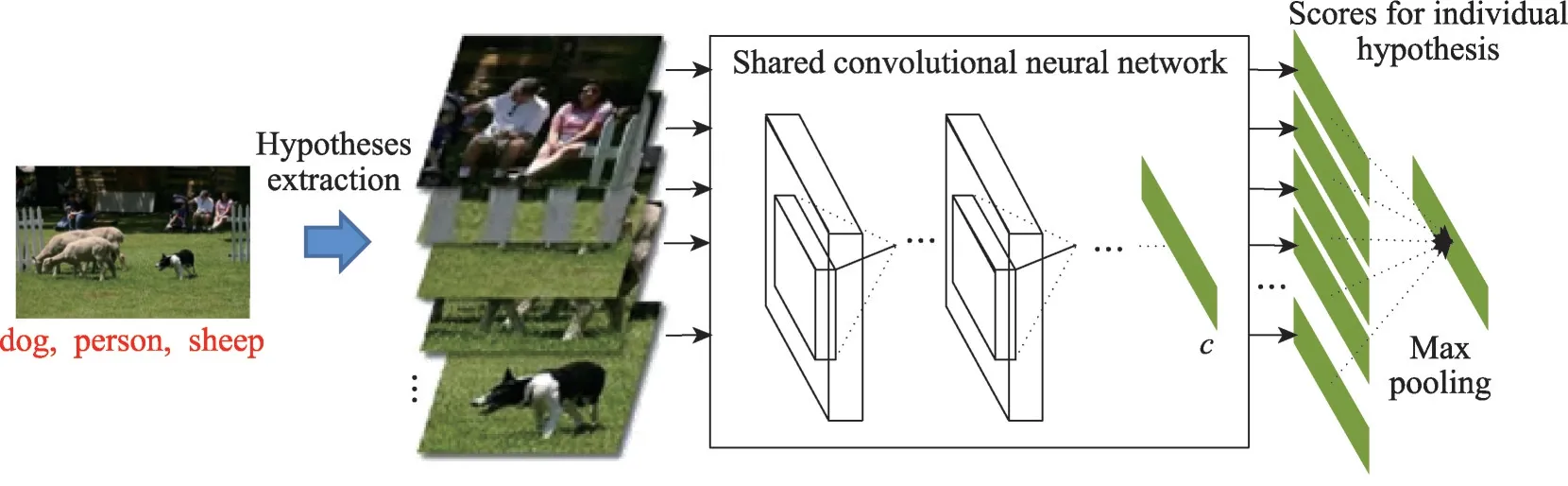
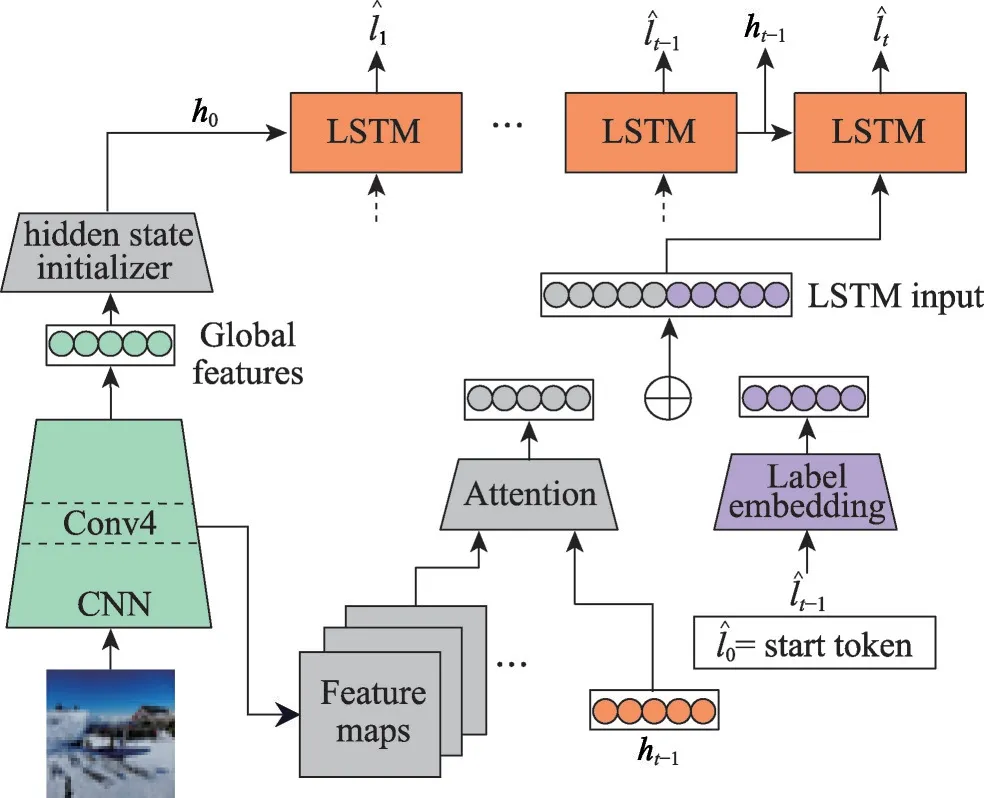
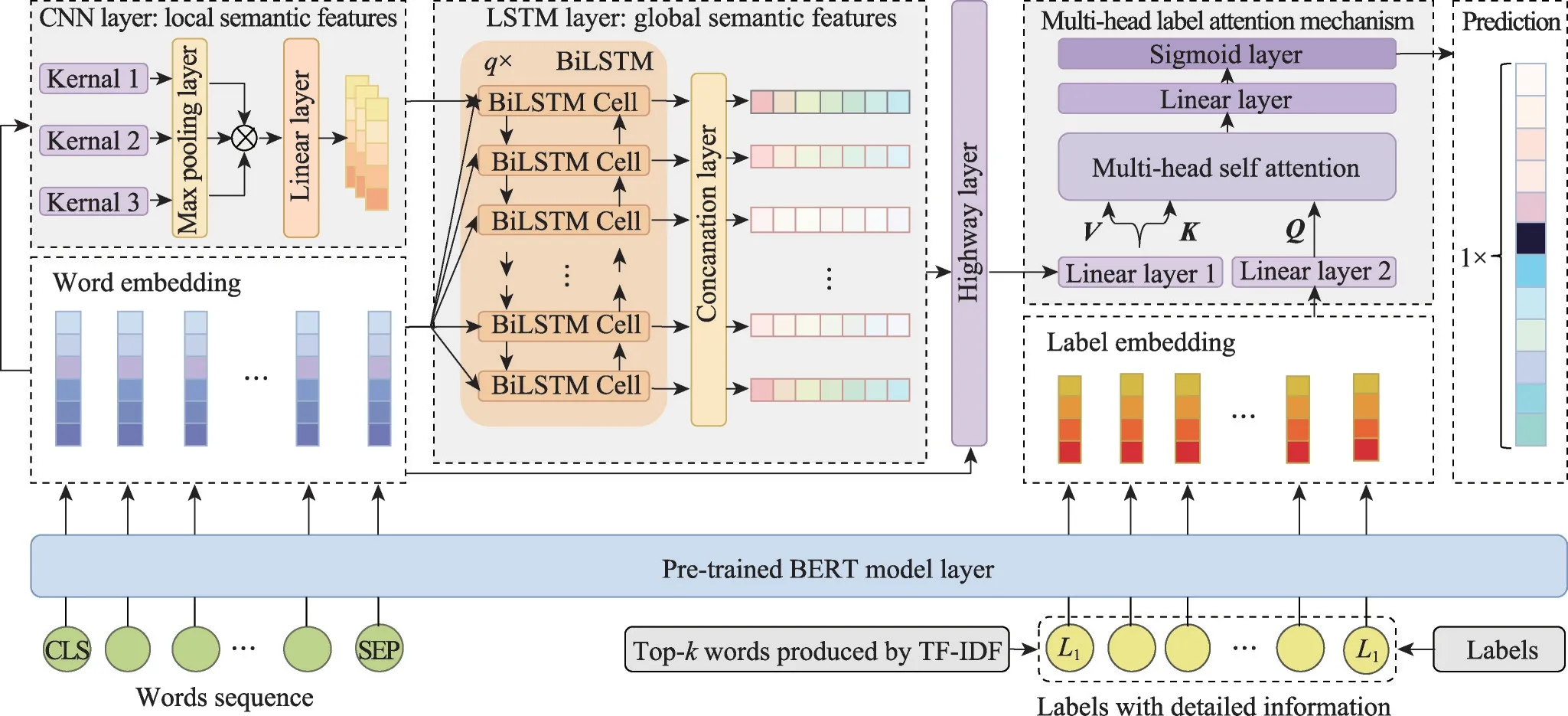
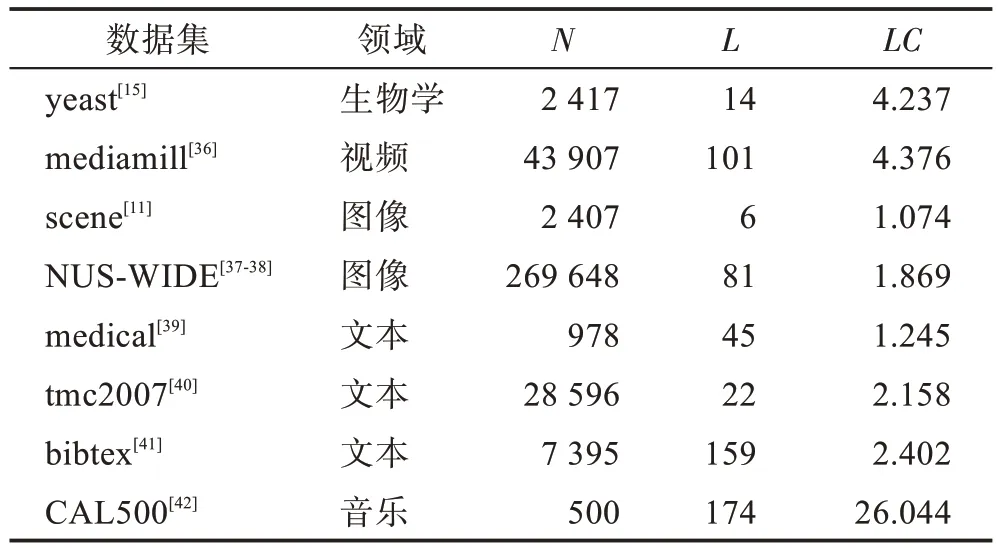
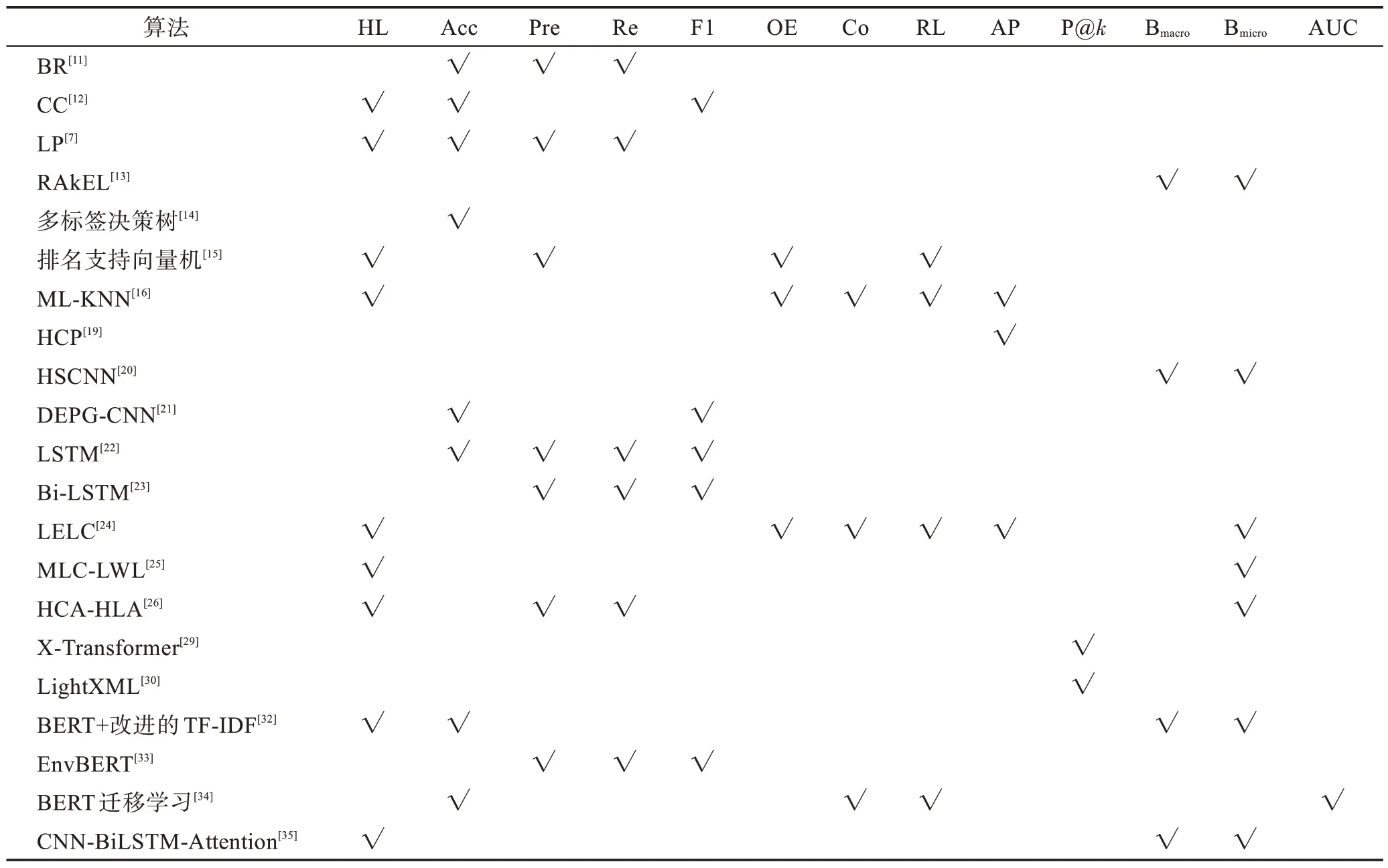
给定一个样本空间X=R,xi∈X是维度为d的特征向量,以及标签空间Y={y1,y2,…,yq},yi∈Y表示标签集合中的各个标签,q表示标签空间的大小。当标签j和样例xi相关时,yj等于1;当标签j和样例xi不相关时,yj等于0。多标签分类任务的最终目的是学习一个分类器h(X),该分类器使预测样本P的预测结果h(P)∈Y。因此,对于每个样例xi∈X,都能产生标签空间Y的二分集合(Yi,,其中Yi表示相关标签的集合,Yˉi表示不相关标签的集合。在大多数情况下,多标签分类模型对应于一个实值函数f:X×Y→R,其中f(x,y)表示y∈Y是x的正确标签的置信度。该实值函数也可以转换为一个排名函数rankf(x,y),它将输出映射至[1,q]的空间中,排名越靠前代表该标签评分越高,即如果f(xi,y1)>f(xi,y2),那么rankf(xi,y1) 多标签分类的流程如图2 所示,包括数据预处理、特征工程、多标签分类模型训练以及性能评估4个阶段。原始数据集中往往包含了许多噪声数据,如停用词、数据缺失以及拼写错误等。这些噪声和不必要的特征在一定程度上会影响模型的性能,因此需要对数据进行预处理操作。特征工程是分类任务中最重要的部分,包含特征表示以及特征选取两大步骤。典型的特征表示方法有one-hot、Word2Vec等,典型的特征选取方法有TF-IDF、期望交叉熵等。不同性能的多标签分类算法对分类的结果有着直接影响,可以分为传统的多标签分类算法和基于深度学习的多标签分类算法。在最终的性能评估环节中,将符合预期的模型保留下来即可得到最佳分类模型。 图2 多标签分类的流程图Fig.2 Flowchart of multi-label classification 根据处理问题的角度,可以将传统的多标签分类算法分为两大类,分别为问题转化方法和算法自适应方法。 2.1.1 问题转换方法 问题转换(problem transformation,PT)方法的本质是简单地将多标签分类问题转换为多个单标签分类问题。Boutell 等人[11]提出了一种二元相关(binary relevance,BR)算法。该算法为每一个标签训练一个单独的二分类器,然后用所有的分类器对样本进行预测。这样的做法实现起来较为容易,但是并没有考虑各标签间的相关性。在实际应用中,考虑标签间的相关性在一定程度上对多标签问题模型具有促进效果,如具有“武侠”标签的电影很可能同时具有“动作”标签。针对该问题,Read 等人[12]提出了分类器链(classifier chains,CC)算法。该算法在BR 的基础上对样本标签进行了排序,在预测样本某一个标签时,除了要考虑对应的特征之外,还要考虑当前标签的上一个标签。图3 对比了BR 算法和CC 算法,其中X表示输入样本空间,Y表示标签空间。这两类算法都将一个多标签分类问题转换为了3 个二元单标签分类问题,不同的是,CC 算法在各分类器上额外考虑了之前的标签。 图3 BR 算法和CC 算法对比Fig.3 Comparison of BR algorithm and CC algorithm 更为复杂地,可以将多标签分类问题转换为多分类问题。Tsoumakas 等人[7]提出了标签幂集(label power-set,LP)算法。该算法将每个样本对应的标签集合当作一个新的类别标签,当两个样本对应的标签集合相同时,则将这两个样本归为一类。然而,当标签数量n过多时,其产生的类别标签数量将在[0,2n-1]的空间中分配,导致数据变得非常稀疏。由此可见,LP 算法的本质就是将多标签分类任务转化为具有2n个类别标签的多分类任务,它仅适用于标签较少的场景。针对LP 的缺陷,Tsoumakas 等人[13]提出了随机子标签集成(randomk-labelsets,RAkEL)算法。该算法结合了集成学习和LP 算法,将初始标签集根据相交策略或者重叠策略划分为若干个随机的小标签集,然后集成多个LP 分类器以保证预测的完整性。 2.1.2 算法自适应方法 不同于PT方法,算法自适应(algorithm adaptation,AA)方法的核心思想是通过修改现有合适的算法直接处理多标签分类问题。Clare 等人[14]提出了多标签决策树算法。该算法借鉴了决策树的思想,首先计算每个特征对所有标签的鉴别能力,即特征对应的信息增益,然后根据信息增益挑选特征并生成分类器。Elisseeff等人[15]提出了排名支持向量机算法。该算法遵循支持向量机的原理,核心思想是利用最大间距的方法。为了使排序损失评价指标最小化,该算法定义了一组线性分类器,同时还针对非线性分类任务引入了核技巧的思想。Zhang 等人[16]根据K近邻算法(Knearest neighbors,KNN)的思想提出了ML-KNN,其伪代码如下所示。 该算法基于多标签训练实例,首先计算未知标签的样本与所有已知标签的样本的距离,然后选出K个最近的已知标签样本,最后选择概率最大的标签作为当前样本最终的标签。具体而言,步骤1 和2 用于估计先验概率P(),步骤3 到13 用于估计后验概率,步骤14 到18 利用贝叶斯规则,根据估计的概率计算算法的输出。其中,rt是一个实数值向量,该向量用于计算标签排名,以便利用多标签分类的评价指标来分析算法的性能。 总体来说,问题转换方法的关键思想是数据与算法的拟合,通过转换问题数据的方式,将转换后的数据应用于现有的算法。而算法自适应方法的关键思想则是算法与数据的拟合,将特定的算法进行扩展或者改进,使之能应用于多标签数据。由于问题转换方法需要额外进行预处理操作,即将多标签问题转换为单标签问题,在标签类别过多的情况下,这一过程可能会导致算法性能下降。因此,当数据集中的标签类别过多时,建议采用算法自适应方法。为了方便地分析传统的多标签分类算法的性能和优缺点,表1 从代表算法、应用领域、优缺点等方面对所提出的算法进行了总结。 表1 传统的多标签分类算法Table 1 Traditional multi-label classification algorithms 在多标签分类领域,各种深层神经网络结构得到了广泛应用,并且取得了良好的分类效果。其中,用于多标签分类的神经网络结构可分为三种类型,分别为卷积神经网络、循环神经网络以及Transformer结构。 2.2.1 基于卷积神经网络的方法 卷积神经网络(convolutional neural network,CNN)最初应用于计算机视觉领域,随着研究的深入,该类神经网络在图像分类、文本分类等领域取得了较大的进展。Kim等人[17]首次在文本分类任务中使用了CNN结构并提出了Text-CNN。Johnson等人[18]在此基础上进一步研究了单词级别的CNN,并提出了一种深层金字塔CNN,用来捕获训练数据的全局表示。在多标签图像分类领域,Wei 等人[19]提出了一种灵活的深度CNN 架构(hypotheses CNN pooling,HCP)。如图4所示[19],首先通过假设选择方法,将数量较少的候选窗口作为假设;然后将选定的假设输入到共享的CNN中,并将输出的置信度向量通过融合层与最大池化操作组合在一起,生成最终的多标签预测。其中,共享的CNN 首先在大规模单标签图像数据集上进行预训练,然后在目标多标签图像数据集上进行微调。实验表明,HCP 相较于其他先进模型具有更加优越的性能,在VOC 2007和VOC 2012多标签图像数据集上的平均精确度分别达到了90.9%和90.5%。 图4 HCP 的模型结构图Fig.4 Model structure diagram of HCP Yang 等人[20]在前人工作的基础上提出了一种孪生卷积神经网络(hybrid-Siamese convolutional neural network,HSCNN),该网络可以用于处理不平衡数据中的尾标签问题。在多标签分类任务中,他们对样本数量更多的标签采用相同的CNN结构,而对样本数量更少的标签则采用HSCNN 结构。Tan 等人[21]提出了一种动态嵌入投影门控(dynamic embedding projection gate,DEPG)卷积神经网络,该模型首次在词嵌入矩阵上应用DEPG。通过使用门控单元来转换和携带单词信息,可以有效地将单词嵌入矩阵中每个元素所携带的信息与对应位置的上下文信息进行合并。 上述基于CNN 的多标签分类模型大多都是在现有CNN 结构的基础上进行不同程度的改进或者与其他先进模型相结合,其本质都并未对CNN 自身的缺陷进行改进。在利用CNN 进行池化操作时,容易丢失关键信息。同时,在处理长文本时,CNN 也并不适用于捕捉长距离文本的语义消息。 2.2.2 基于循环神经网络的方法 与CNN 相比,循环神经网络(recurrent neural network,RNN)更适用于自然语言处理中序列化数据的输入。随着研究的深入,RNN在多标签分类领域也得到越来越广泛的应用。然而,由于RNN自身存在梯度消失、梯度爆炸以及长距离依赖等问题,现阶段研究大都集中于改进后的LSTM(long short-term memory)、GRU(gated recurrent unit)以及Seq2Seq模型。 Yazici等人[22]提出了一种用于训练多标签分类任务的无序LSTM 模型的方法,其模型结构如图5 所示[22],包括CNN 图像编码器、LSTM 文本解码器和注意力机制。其中,CNN 编码器用于从图像中提取紧凑的视觉表示,LSTM 解码器使用编码生成的标签序列对标签依赖进行建模。注意力模块关注的则是图像的不同部分,它将这些不同部分的注意力加权特征与前一个时间步中预测的类的词嵌入连接起来,作为当前时间步的输入提供给LSTM。实验表明,这种图像编码器和语言解码器的标准架构在MS-COCO、NUS-WIDE 多标签图像分类数据集上的F1 值分别为77.14%、72.37%。 图5 基于LSTM 的模型结构图Fig.5 Model structure diagram based on LSTM 然而,由于LSTM 模型基于单向传播,Yazici 等人的模型忽略了反向内容之间的语义相关性。Hu 等人[23]利用Word2Vec 和双向LSTM 对模型进行训练。该模型充分考虑了正反两个方向的语义相关性,提高了多标签文本的分类精度。Liu 等人[24]为了解决包含大量类标签的多标签分类问题,提出了一种基于多层注意力和标签相关性的多标签文本分类模型LELC(label embedding and label correlation)。该模型首先利用双向GRU 捕获文本的内容信息和序列信息,然后利用注意力机制选择与标签相关的有效特征,最后通过标签相关矩阵进行空间降维。在11 个真实数据集上的实验表明,LELC 能取得最先进的性能。Chen 等人[25]提出了一种具有潜在词标记的多标签分类模型(multi-label classification with latent word-wise label,MLC-LWL),并在学术文献和新闻数据集上取得了71.10%和88.10%的微观F1 值。该模型首先利用标签主题模型构造有效的词标签信息,然后利用门控网络将单词所携带的标签信息和上下文信息结合起来,最后通过标签到标签的结构获取标签之间的相关性。Xiao等人[26]提出了一种基于历史注意力机制的Seq2Seq模型,通过考虑历史信息,有效地探索多标签文本分类中标签预测的信息表示。其中,基于历史的上下文注意力(history-based context attention,HCA)着重考虑上下文历史权重趋势,有助于琐碎标签的预测;基于历史的标签注意力(history-based label attention,HLA)通过探索历史标签来缓解错误传播的问题。相较于MLC-LWL,HCA-HLA 的微观F1 值分别提高了0.10%和0.7%。 2.2.3 基于Transformer的方法 Google 于2017 年提出了Transformer[27]网络结构。该网络打破了原有的编码器、解码器模式,仅仅采用注意力机制来执行自然语言处理任务。面对更具挑战的极端多标签分类(extreme multi-label classification,XMC)[28]任务,Chang等人[29]提出了X-Transformer模型。其中,XMC 是指在一个非常大的标签空间中,为每一个样本分配最相关的若干标签。X-Transformer模型由语义标签索引组件、深度神经匹配组件和集成排名组件构成,是第一个用于微调Transformer 的可扩展框架,并在4 个基准数据集上取得了最佳分类效果。Jiang 等人[30]发现X-Transformer 模型在训练标签排序模型时,静态采样负值标签的方法降低了模型的效率和准确性。因此,他们提出了LightXML 模型。该模型采用端到端训练和动态负值标签采样的方法,使用生成式合作网络对标签进行回收和排序,并在5 个XMC 数据集上表现优于最先进的方法。 随后,基于Transformer 提出的BERT(bidirectional encoder representations from transformers)预训练模型[31]在自然语言处理领域取得了突破性的进展。这类模型本质上是利用海量语料训练大量参数,免去了从零开始训练的过程。在多标签分类领域,大量研究人员也逐渐引入该类模型。Jin 等人[32]提出了一种基于BERT 和改进TF-IDF 的多标签文本分类模型,通过计算单个类别标签的不同权重,更好地反映其重要性。在餐厅顾客评论数据集上进行的多标签分类实验表明,该模型与基准BERT 相比,性能略有提高,微观F1 值达到了73.59%。Kim 等人[33]提出了一种基于KoBERT 的多标签文本分类模型EnvBERT,通过数据过采样技术解决了多标签数据的不平衡问题。实验表明,该方法对不平衡的、有噪声的多标签新闻数据具有更加优越的预测性能,准确度达到了80%。林森等人[34]针对地震灾害社交媒体数据的特点,提出了一种BERT 迁移学习模型。他们利用BERT 预训练模型建立地震灾害社交媒体信息多标签分类模型,并达到了91.6%的准确度,为灾后快速辅助响应决策提供科学依据。 目前已有的多标签文本分类器存在以下问题:一方面,忽略了文本中不同层次的语义特征;另一方面,忽略了语义标签的意义以及标签与底层文本之间的关系。为了克服这些问题,Lu 等人[35]设计了一种CNN-BiLSTM-Attention 分类器,如图6 所示[35]。该分类器结合了BERT 模型,可以更好地利用标签和基础文本之间的多级语义特征。首先,使用预先训练好的BERT 模型生成词嵌入和标签嵌入。然后,利用CNN 层提取文本的局部语义特征。BiLSTM 层将该局部语义特征作为初始状态,通过融合文本的上下文特征,生成表示全局语义信息的混合特征。最后,利用注意力层为每个标签选择最相关的特征。在某市电子政务多标签数据集以及新闻、法律两个领域公共数据集上的微观F1 值分别达到了87.52%、77.22%、84.42%。基于Transformer 的方法利用了预训练模型的优点,未来可以对各类预训练模型进行改进,使其更适用于下游任务。 图6 CNN-BiLSTM-Attention 的模型结构图Fig.6 Model structure diagram of CNN-BiLSTM-Attention 总体来说,深度学习模型无需人工构造特征,就能从原始数据中学习有利的特征,从而获得更加有效的特征表示。这类模型能很好地解决多标签分类任务中的数据表达能力不足、标签相关性考虑不充分以及模型复杂程度高等问题。为了方便地分析基于深度学习的多标签分类算法的性能和优缺点,表2从代表算法、应用领域、优缺点等方面对所提出的算法进行了总结。 表3 展示了来自不同领域的多标签分类数据集。其中,N表示数据集中实例的数量,L表示数据集中预定义的标签的数量,LC表示标签基数,其定义如式(1)所示,表示与每个实例相关联的标签的平均数量。所有数据集和它们的更多相关信息可以从https://mulan.sourceforge.net/datasets-mlc.html 或其原始文献中获得。 表3 多标签分类数据集Table 3 Multi-label classification datasets yeast 数据集包含2 417 个酵母基因的微阵列表达和系统发育谱,每个基因都与一组功能类相关,共注释了14 个功能类别子集,如代谢、能量等。 mediamill 数据集是一个类别不平衡的大规模数据集,共包含43 907 个视频帧,通过手动注释的方式产生了101个语言概念的词典,如军事、沙漠、篮球等。 scene 数据集用于多标签场景分类,包含2 407 张图像,每张场景图像可能包括海滩、落日、落叶、山脉、田野、城市这6 类概念中的一种或多种。 NUS-WIDE 数据集由新加坡国立大学媒体检索实验室创建,共包含269 648 张图片,邀请具有不同背景的学生手动标注了81个属于不同类别的概念,如游泳、跑步等活动类概念和沙滩、马路等场景类概念。 medical 数据集来源于美国辛辛那提儿童医院医学中心放射科,经过消除歧义、匿名化等预处理步骤,最终得到978 份临床文本报告,每份病历标记有45 种疾病代码中的一种或多种。 tmc2007 数据集包含28 596 份自由文本形式的航空安全报告,注释了飞行期间出现的22 种问题类型中的一种或多种。 bibtex 数据集包含7 395 个由论文标题、作者等信息组成的bibtex 条目,注释了159 个由用户分配的标签集,如统计、数据挖掘等。 CAL500 数据集包含500 首西方流行音乐,每首歌曲都有至少3 位听众的注释,考虑了135 个属于不同类别的音乐相关概念,如钢琴、吉他等乐器类概念和古典、流行等流派类概念,最终经过语义特征处理得到174 个概念标签。 在多标签分类任务中,评价指标可以概括为两种。如图7 所示,一种是基于实例的评价指标,另一种则是基于标签的评价指标。基于实例的评价指标是针对每个实例去预测标签,而基于标签的评价指标则是对每个标签预测实例。 图7 多标签分类评价指标的总体框架Fig.7 Overall framework of multi-label classification evaluation metrics 基于实例的评价指标用于评估模型在各测试实例上的性能,最终返回其在整个测试集上的平均值。 根据多标签分类器h(⋅),可以定义以下6 个基于实例的分类指标。 (1)子集准确度 子集准确度用于评估正确分类实例的比例。其中对于〚〛⋅,如果“⋅”成立则返回1,否则返回0。它对应于传统分类任务中的准确度,只有当实例预测的标签完全正确时才被认定为正确分类,因此过于严格,将导致较低的度量值。 (2)汉明损失 汉明损失用于评估错误分类标签的实例的比例。其中Δ 表示两个集合之间的异或关系。当数据集中的每个实例仅与标签集中的单个标签相关联时,即在单标签情况下,汉明损失将退化为传统误分类率的2/q。 (3)准确度 准确度用于评估正确分类标签的实例的比例。 (4)精确度 精确度用于评估样本中被正确分类标签的实例的比例。 (5)召回率 召回率用于评估所有实例成功预测相关标签的平均比例。 (6)F值 F值通常被认为是比精确度和召回率更好的性能评价指标,它通过精确度和召回率加权得到。其中β表示平衡因子,通常取值为1。 根据实值函数f(⋅,⋅),还可以定义以下5 个基于实例的排序指标。 (1)1-错误率 1-错误率用于评估排名最高的标签不在相关标签集合中的实例的比例。 (2)覆盖率 覆盖率根据排序后的标签列表,计算覆盖实例所有相关标签的步数。 (3)排序损失 排序损失用于评估错误排序标签对的比例,即不相关标签的排名高于相关标签。 (4)平均精确度 平均精确度用于评估排名高于某一特定标签的相关标签的平均得分。 (5)前k个的精确度 前k个的精确度用于评估前k个评分标签中正确分类标签的百分比。 在上述基于实例的评价指标中,对于1-错误率、覆盖率和排序损失,值越低,模型的性能越好;对于其他评价指标,值越高,模型的性能越好。 基于标签的评价指标用于评估模型在每个类别标签上的性能。对于第j类标签,根据多标签分类器h(⋅),可以定义以下两个基于标签的分类指标。 (1)宏观平均值 (2)微观平均值 宏观平均值是在单个类别标签上计算得到的,而微观平均值是在所有类别标签上计算得到的。其中B∈{Arruracy,Precision,Recall,Fβ},TP、FP、TN、FN分别表示真阳性、假阳性、真阴性、假阴性的数量。 根据实值函数f(⋅,⋅),还可以定义以下两个基于标签的排序指标。 (1)宏观AUC (2)微观AUC 曲线下面积(area under curve,AUC)代表特征曲线下的面积,它是一种统计度量,表示真阳性占实际阳性的比例以及假阳性占实际阴性的比例。 对于上述所有基于标签的评价指标而言,值越高,模型的性能越好。 在评价算法性能时,通常不仅仅考虑某一特定的评价指标,而是结合多个评价指标一起使用。为了方便地了解评价指标在多标签分类中的作用,表4对上述多标签分类算法的评价指标进行了总结。其中HL 代表汉明损失,Acc 代表准确度,Pre 代表精确度,Re 代表召回率,OE 代表1-错误率,Co 代表覆盖率,RL 代表排序损失,AP 代表平均精确度,P@k代表前k个的精确度。 表4 多标签分类算法的评价指标Table 4 Evaluation metrics of multi-label classification algorithms 由于子集精确度在评估时过于严格,大多数算法并没有考虑该评价指标。若要研究分类器的性能,则可以采用一些分类指标对算法进行评估;若要考虑返回的实值函数,则可以采用一些排序指标对算法进行评估。在XMC 任务中,标签数量非常多,通常意义上的精确度等指标不太适用,因此选择P@k作为评价指标。AUC 在单标签领域较为常用,在多标签分类领域,也可以对结果计算宏观AUC 或微观AUC,其更适用于一些标签不平衡数据集。 现有的一些多标签分类方法已经能较好地运用在实际使用中,但目前仍有一些问题需要解决,例如多模态数据多标签分类、基于提示学习的多标签分类和不平衡数据多标签分类。下面将对这三类问题进行分析,并将其作为未来的研究方向。 (1)多模态数据多标签分类 随着时代的发展,数据类型不仅仅局限于文本一种,人们可以借助各种设备采集音频、视频、图片等多模态数据。于玉海等人[43]提出了生物医学图像多标签分类方法,融合了图像内容和相关说明文本这两种模态的数据,可以更加有效地识别生物医学模式标签。井佩光等人[44]提出了一种基于多模态子空间编码的短视频多标签分类模型,充分将短视频的多模态特性与多标签相关联。Tang 等人[45]提出了一种用于多标签皮肤病分类的两阶段多模态学习算法FusionM4Net-FS,在标签不平衡的医学数据集上取得了强大的分类性能。Zhang 等人[46]提出了一种用于多标签情感识别的通用多模态学习方法,通过对抗性多模态细化模块,充分挖掘不同模态之间的共性。由于各模态数据之间存在差异性,如何更好地融合多个模态的特征是一大难点。针对这一问题,可以根据模态特征的粗细粒度采用分层交叉模态融合的方法。此外,在多标签分类中合理地融入多模态数据,将多模态表示与标签语义对齐,也具有重要的研究价值。 (2)基于提示学习的多标签分类 近年来,人们对于提示学习的研究越来越深入,它作为自然语言处理领域的第四范式,在实体关系抽取、问答、推荐等任务中取得了不错的效果[47]。在多标签分类任务中,Chai等人[48]提出了一种基于提示的多标签情感预测模型,该模型利用标签提示和对比学习来捕获标签信息,能够更好地预测情感标签。Song 等人[49]提出了一种标签提示多标签文本分类模型,设计了一套多标签文本分类模板,将标签集成到预训练模型的输入中,有效地提高了模型的性能。Wang等人[50]提出了一种自动多标签提示AMuLaP,为少样本文本分类设计了一种自动选择标签映射的方法。上述方法通过引入标签提示,将标签整合到预训练语言模型的输入中,可以有效地捕获标签和文本间的语义信息。此外,鉴于提示学习可以有效地应用在小样本甚至零样本场景下,基于提示学习的低资源多标签分类也是未来的一个研究方向。 (3)不平衡数据多标签分类 不平衡是大多数多标签数据集的固有特征,其特点是样本及其对应的标签在数据空间上的分布是不均匀的。现有的分类算法更适用于对平衡数据进行分类,在处理不平衡数据时,分类性能会急剧下降。Tarekegn 等人[51]对处理多标签数据中的不平衡问题的方法进行了综述。在多标签分类任务中,集成方法通常被用来解决不平衡和标签相关性问题。Zhu 等人[52]提出了一种新的多标签分类与动态集成学习方法,通过选择并组合最有效的基分类器集合来预测每个未知的实例。鉴于不同的基分类器组合对于特定的问题具有不同的性能,如何在多标签分类中选择基分类器也有待进一步研究。此外,还可以采用重新采样的方法对不平衡数据进行扩充,以减轻类不平衡造成的影响。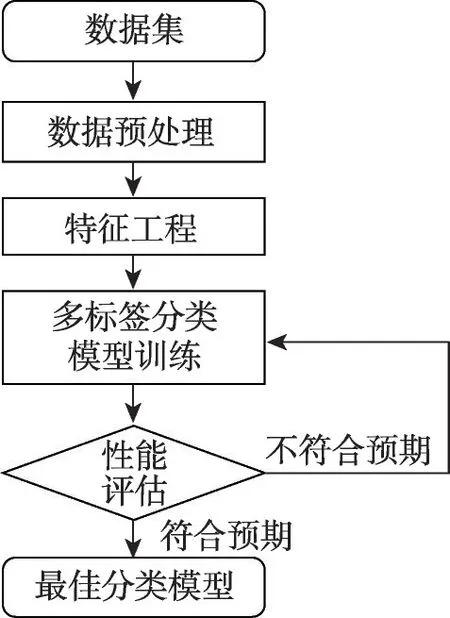
2 多标签分类方法
2.1 传统的多标签分类
2.2 基于深度学习的多标签分类
3 数据集
4 评价指标
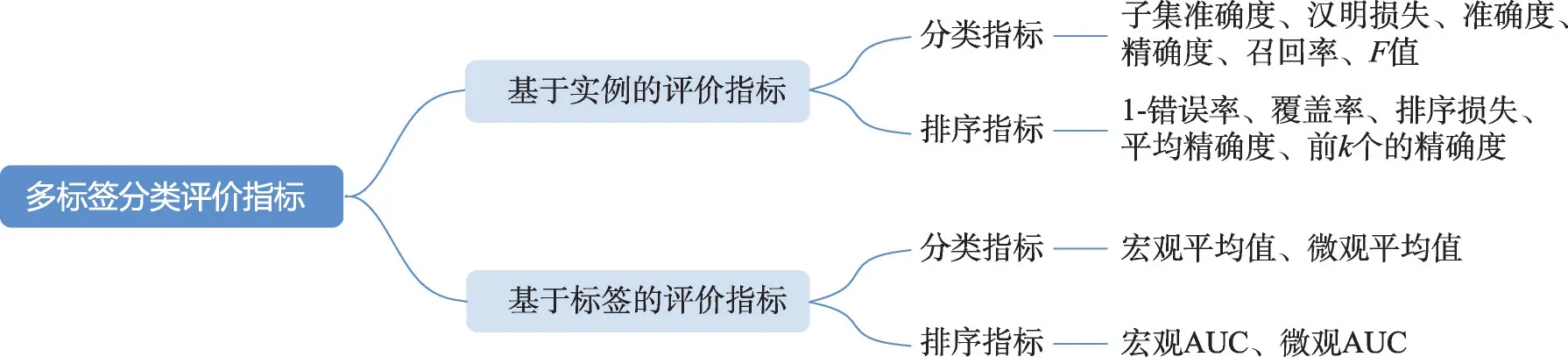
4.1 基于实例的评价指标
4.2 基于标签的评价指标
4.3 小结
5 未来工作展望
猜你喜欢
车迷(2018年11期)2018-08-30
海峡姐妹(2018年3期)2018-05-09
电子测试(2018年1期)2018-04-18
光学精密工程(2016年4期)2016-11-07
光学精密工程(2016年3期)2016-11-07
公民与法治(2016年10期)2016-05-17
计算机工程(2015年8期)2015-07-03
高中生学习·高三版(2014年3期)2014-04-29
高中生学习·高三版(2014年3期)2014-04-29
电测与仪表(2014年15期)2014-04-04
