
深度学习在手指静脉识别中的应用研究综述
2023-11-16 00:50李杰,瞿中
计算机与生活 2023年11期
李 杰,瞿 中
1.重庆文理学院 电子信息与电气工程学院,重庆 402160
2.重庆邮电大学 计算机科学与技术学院,重庆 400065
随着信息技术和移动互联网的发展,越来越多的场景需要进行人的身份认证。传统的基于钥匙或密码的认证方法已不能满足人们对安全性和便捷性的需求。生物识别技术通过获取人体独特的生物特征来进行身份认证,比密码或钥匙更安全,它还避免了用户忘记密码或钥匙的不便,使认证更加轻松。因此生物识别技术已广泛应用于社会的各个领域并成为了目前研究的热点之一。
常见的用于身份认证的生物特征有指纹、人脸、虹膜、指静脉等[1]。指纹识别和人脸识别是目前使用最广泛、技术最成熟的生物识别技术。但人的手指会因为磨损或沾染污渍而影响指纹识别的准确性。此外,指纹是皮肤表面的一种生物特征,比较容易伪造,因此安全性较低。与此同时,由于人的容颜变化、光线太强或太弱、摄像头拍摄角度太偏等原因会导致人脸识别失败。尽管虹膜识别的准确度很高,但该设备非常昂贵,而且它使用的是近红外光,长期暴露在近红外光下可能会导致眼睛不适[2]。与其他生物识别技术相比,手指静脉特征位于人体内部,其特征点极其丰富且分布极不规则,而且需要在血液流动的情况下通过血红蛋白对近红外光的吸收成像才能进行身份识别。而现代医学研究早已证明人的手指静脉图像具有唯一性,每个人每根手指静脉图像都不相同;而且人的手指静脉纹路终身不变,是人体最稳定的生物特征之一。因此,手指静脉识别技术具有高防伪性、活体识别和非接触式的特点[3],已应用到门禁系统、银行身份认证、安全监控等领域[4]。
2000年,日本医学研究者Kono等人首次提出使用手指中的静脉血管进行身份识别[5]。二十多年来,指静脉识别的研究呈现出迅速繁荣的趋势,取得了一批令人鼓舞的成果。手指静脉识别流程如图1 所示,主要包括图像采集、图像预处理、特征提取和匹配识别四个阶段[6]。在深度学习技术广泛应用之前,对手指静脉识别的研究主要以传统的图像处理算法为主,并在识别流程的各个阶段都涌现出许多经典的方法。在感兴趣提取(region of interest,ROI)方面,掩膜法[7-8]和Sobel算子法[9-10]是最常用的方法。在图像增强中,直方图均衡化(histogram equalization,HE)[11-12]、自适应直方图均衡化(adaptive histogram equalization,AHE)[13]、限制对比度自适应均衡化(contrast-limited adaptive histogram equalization,CLAHE)[14-15]、Gabor 滤波器[16-17]等方法均被广泛研究。在特征提取阶段,涌现出的经典算法有重复线性跟踪(repeated line tracking,RLT)算法[18]、局部最大曲率(local maximum curvature,LMC)算法[19]、增强型最大曲率(enhanced maximum curvature,EMC)算法[20]、主曲率(principal curvature,PC)算法[21]、宽线检测器(wide line detector,WLD)[22]、局部二值模式(local binary pattern,LBP)方法[23]和基于双重降维方向梯度直方图特征的方法[24]等,这些算法统称为基于手工提取特征的方法。此外,许多其他特征已应用于手指静脉识别的特征提取,包括主成分分析(principal component analysis,PCA)特征[25]、骨架方向编码特征[26]、超像素特征[27]和软生物特征[28]等。在匹配识别阶段,欧氏距离(Euclidean distance)[29-30]、余弦距离(cosine distance)[31-32]、曼哈顿距离(Manhattan distance)[33]常用于计算静脉纹路特征之间的相似度。对于用LBP 算法提取的二值特征,常用汉明距离(Hamming distance)计算相似度[34-35]。在模板匹配方法中,Miura等人[18]提出的“Miura-matching”是最经典的方法之一。
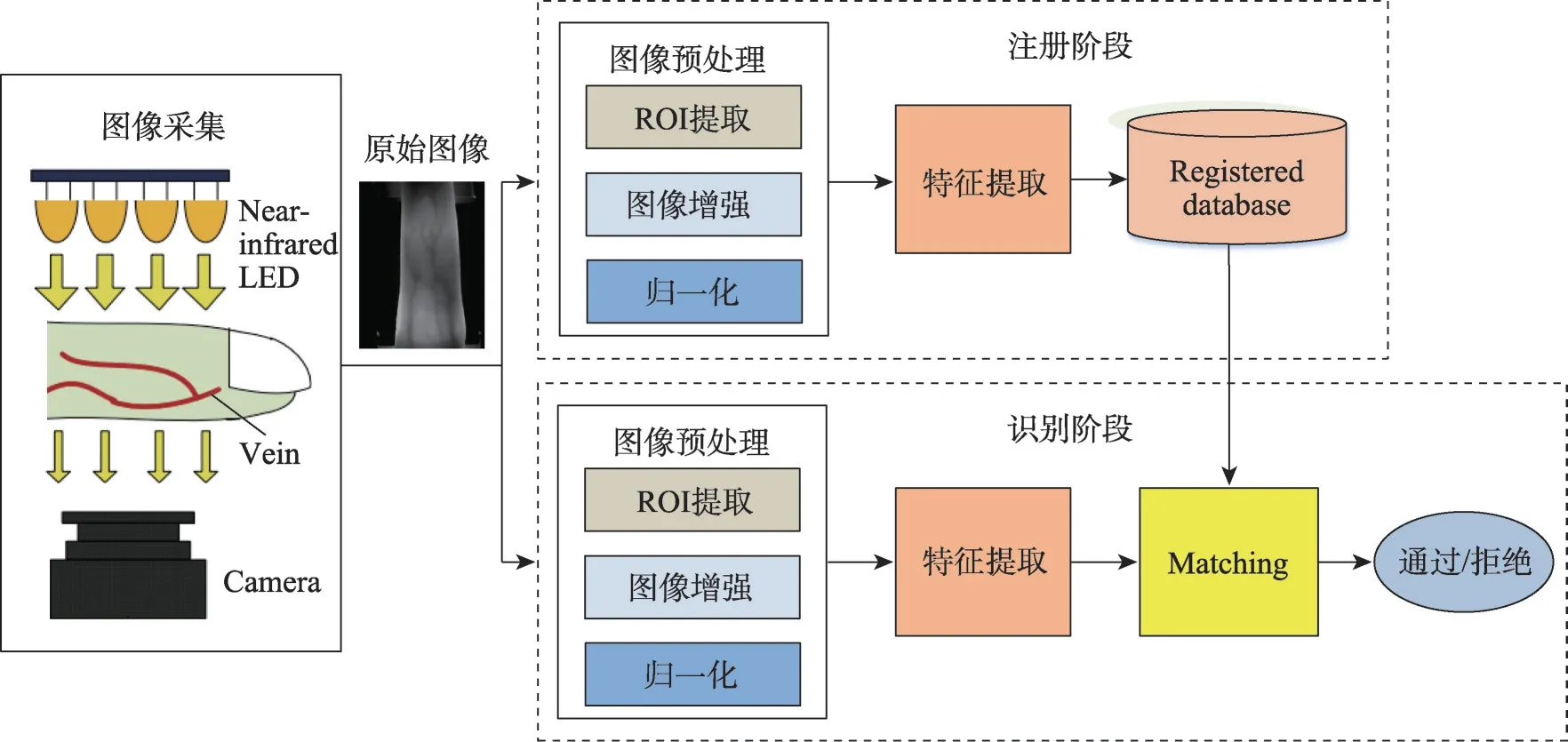
图1 手指静脉识别流程图Fig.1 Flow chart of finger vein recognition
基于传统图像处理的方法使手指静脉识别的性能到达较高水平,但是这些算法大都存在计算量大、效率低等问题。随着深度学习的发展,基于卷积神经网络(convolutional neural networks,CNN)的手指静脉识别成为主要的研究方向。深度学习的前身为人工神经网络(artificial neural network,ANN),ANN的历史可以追溯到20 世纪40 年代[36],之后经过了三次发展高潮和两次低谷,直到2012 年,由Hinton 和Alex Krizhevsky 设计的AlexNet 神经网络在ILSVRC ImageNet竞赛中取得冠军,引起世界瞩目[37]。从此以后,更多更深的优秀的神经网络被提出。2014年,牛津大学VGG(visual geometry group)视觉几何组提出了VGGNet[38]取得了ILSVRC ImageNet 竞赛的第二名,此后许多研究均把VGGNet 当作骨干网络。同年,Ian Goodfellow 团队提出生成对抗网络(generative adversarial network,GAN)[39],在图像生成、自然语言处理(natural language processing,NLP)等领域大放异彩。2015 年,残差网络(residual network,ResNet)被微软实验室提出[40],通过使用跳跃连接,缓解了在深度神经网络中增加深度带来的梯度消失问题。同样是2015 年,Ronneberger 等人[41]发表U-Net,其初衷是为了解决生物医学图像分割的问题,后来被广泛应用在图像语义分割的各个方向。2017年,MobileNet[42]、ShuffleNet[43]两个网络被提出,推动了轻量级网络的研究。同年,Huang 等人[44]提出DenseNet,通过密集连接和特征重用的方法,使网络的性能进一步提高。鉴于Transformer 在NLP 领域的出色性能,2020年,Google 团队提出了ViT(vision transformer)[45],成为了Transformer在计算机视觉(computer vision,CV)领域应用的里程碑著作。
以上经典网络及其变体已广泛应用到CV领域[46],如图像分类、图像识别、图像分割、图像修复等。研究者们都已应用到手指静脉识别领域,使识别性能进一步提高。基于深度学习的某些方法甚至改变了传统的需要先图像预处理,再特征提取,最后匹配识别这个流程,使其中的两个或者三个阶段通过神经网络融合在一起完成,实现端到端的识别。本文后面章节将对基于深度学习的手指静脉识别方法进行详细介绍。
1 数据集
深度学习技术的发展离不开各种数据集的支撑,神经网络通过学习数据集里的大量数据可以提高模型的泛化能力。在手指静脉识别领域最常用的公开数据集有5个,分别是山东大学机器学习与数据挖掘实验指静脉数据集SDUMLA-HMT[47]、马来西亚理工大学手指静脉数据集FV-USM[48]、香港理工大学指静脉数据集HKPU[49]、清华大学指静脉与指背纹图像库THU-FVFDT[50]、韩国全北国立大学指静脉数据集MMCBNU-6000[51]。此外还有荷兰特文特大学指静脉数据库UTFVP[52]、瑞士达尔·摩尔感知人工智能感应研究所指静脉数据集VERA[53]、萨尔茨堡大学计算机科学系的指静脉图像库PLUSVein-FV3[54]、华南理工大学手指静脉数据库SCUT[55]等。表1为常用公开数据集的信息汇总,图2为部分数据集的图像展示。
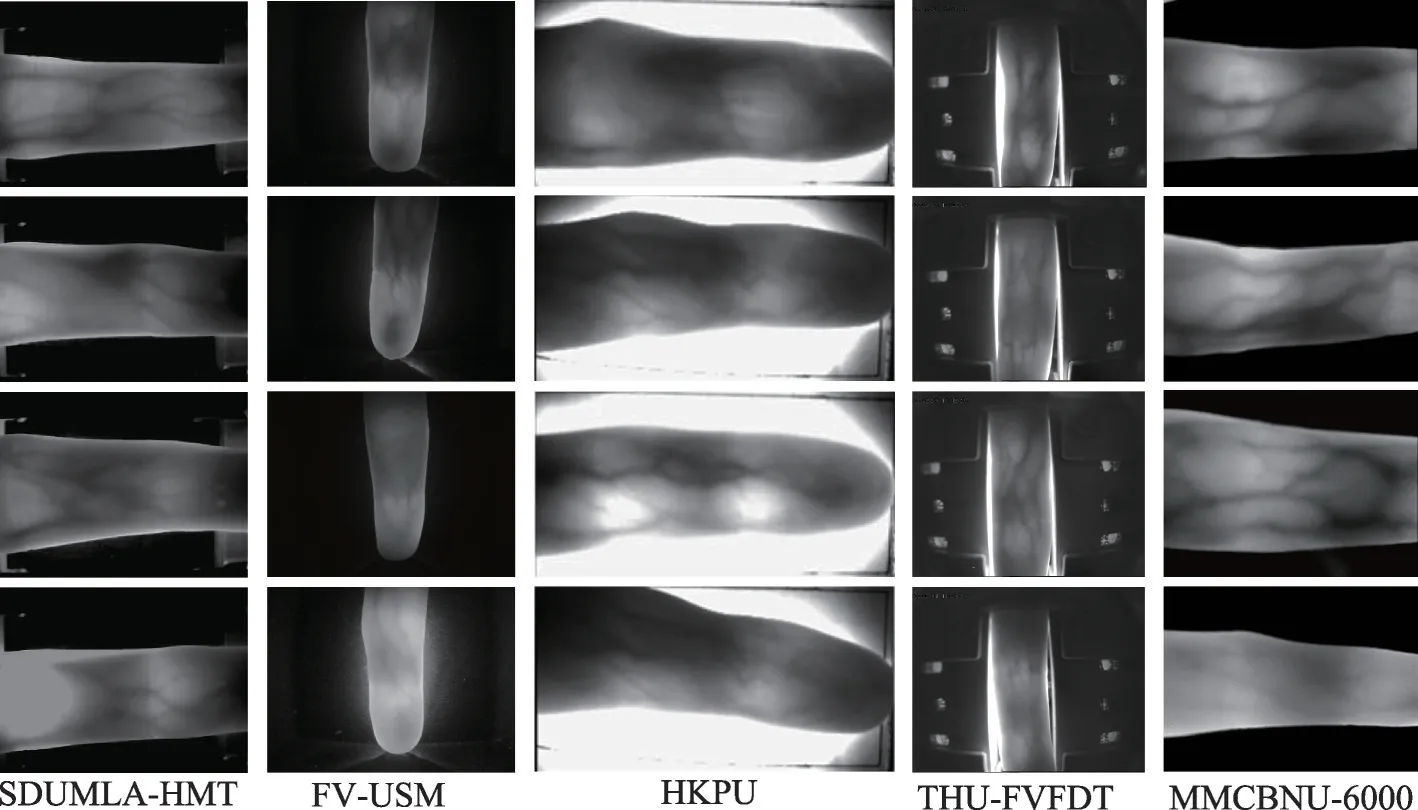
图2 常用公开指静脉数据集的图像展示Fig.2 Image display of some public finger vein datasets
(1)SDUMLA-HMT
该数据集中的手指静脉图像来自106个志愿者,每个人采集了6 个手指,分别是左手和右手的食指、中指和小拇指,每个手指采集了6 幅图像,因此一共包含了3 816幅图像。每幅图像为320×240像素的灰度图像。
(2)FV-USM
该数据集中的手指静脉图像来自123个志愿者,每个人采集了4个手指,分别是左手和右手的食指和中指。采集分为两个阶段,每个阶段每个手指采集6幅图像,因此一共采集了5 904幅图像。每幅图像为640×480 像素的灰度图像。该数据集同时还提供了每幅图像的ROI图像。
(3)HKPU
该数据集中的手指静脉图像来自156个志愿者,每个人采集了2 个手指,分别是左手的食指和中指。其中105 人的采集分为两个阶段,剩余的51 人只采集了一个阶段,每个阶段每个手指采集6 幅图像,因此一共采集了3 132幅图像。每幅图像为513×256像素的灰度图像。
(4)THU-FVFDT
该数据集包含3 个子数据集,分别是THUFVFDT1、THU-FVFDT2 和THU-FVFDT3。THUFVFDT1中的手指静脉图像来自220个志愿者,每个人只采集了一个手指,分两阶段采集,每阶段提供了一幅图像,因此一共有440幅720×576像素的灰度图像。THU-FVFDT2 一共有1 220 幅指静脉图像,前440 幅图像来自THU-FVFDT1,剩余的图像来自390个志愿者,分两阶段采集,每阶段提供了一幅图像。所有图像为200×100像素的ROI图像。THU-FVFDT3是THU-FVFDT2的扩充,将610个志愿者每个阶段每个手指的图像扩充为4幅,因此一共有4 880幅图像。
(5)MMCBNU-6000
该数据集中的手指静脉图像来自20 个国家的100个志愿者,每个人采集了6个手指,分别是左手和右手的食指、中指和小拇指,每个手指采集了10幅图像,因此一共包含了6 000幅图像。每幅图像为640×480像素的灰度图像。
(6)UTFVP
该数据集中的手指静脉图像来自60 个志愿者,每个人采集了6 个手指,分别是左手和右手的食指、中指和小拇指,采集分两阶段进行,每阶段每个手指采集了2 幅图像,因此一共包含了1 440 幅图像。每幅图像为672×380像素的灰度图像。
(7)SCUT
该数据集中一共包含100 个志愿者的10 800 幅图像。每个人采集了6 个手指,每个手指采集了18幅图像,其中6 幅图像是在正常光照和姿势下采集的,剩余的12 幅图像是在特殊光照和旋转姿势下采集的。
(8)VERA
该数据集中的手指静脉图像来自110 个志愿者的220 个手指,每个手指采集2 幅图像,共440 幅图像,每幅图像的像素为665×250。
(9)PLUSVein-FV3
该数据集中的手指静脉图像来自60 个志愿者,每个人采集了6 个手指,分别是左手和右手的食指、中指和小拇指,每个手指采集了5 幅图像,因此一共包含了1 800 幅图像。每幅原始图像为1 280×1 024像素的灰度图像,同时还存储每幅图像的ROI,其尺寸为736×192。
本文统计了近5 年基于深度学习方法的指静脉识别研究的70 篇论文中使用到的各个数据集的次数,如图3所示。
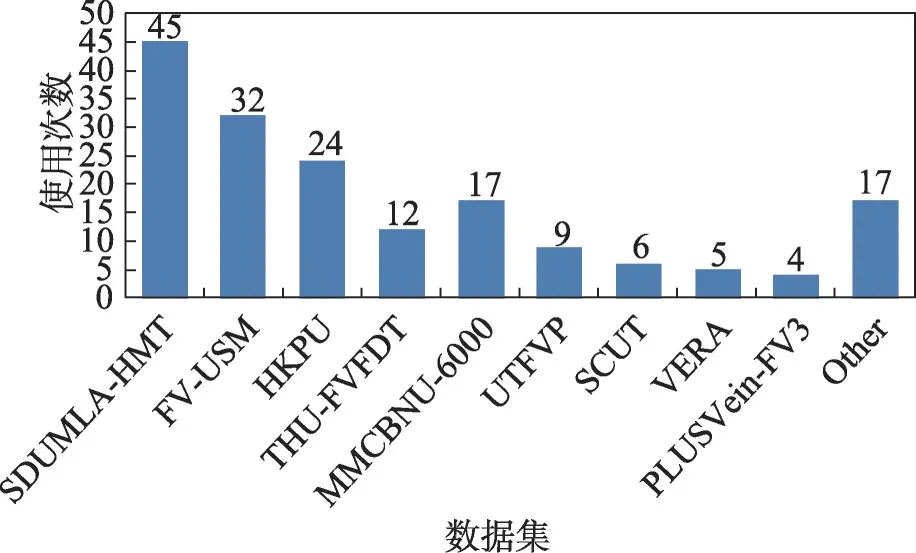
图3 常用数据集在手指静脉识别研究中的使用次数Fig.3 The number of times that common datasets are used in finger vein recognition studies
2 手指静脉识别中的深度学习方法
根据学习任务的不同,深度学习在手指静脉识别中的应用主要分为5 类[56],分别是基于分类的方法、基于双图像匹配的方法、基于特征提取的方法、基于图像生成的方法和基于图像分割的方法。5 类方法的对比如表2所示。此外,深度学习方法在手指静脉图像质量评估、ROI提取、模板保护、呈现攻击检测等方面也有应用。
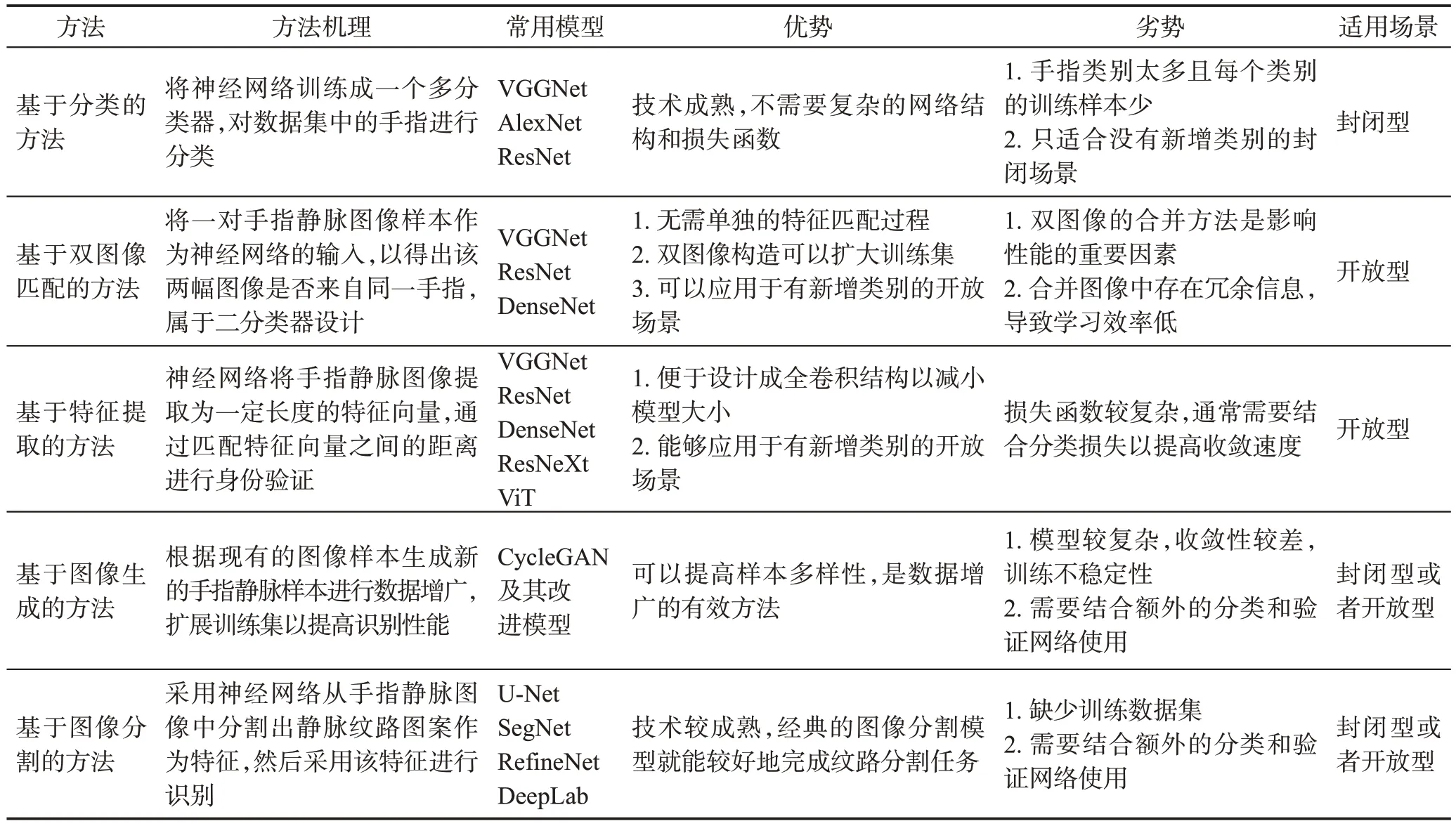
表2 手指静脉识别常用的深度学习方法Table 2 Common deep learning methods for finger vein recognition
2.1 基于分类的方法
基于分类的手指静脉识别方法又称为基于识别的方法(identification-based),通常将神经网络训练成一个多分类器,对数据集中的手指进行分类。如果数据集中一共包含N根不同手指的静脉图像,则训练时需要将图像分成N个类别,即训练成N分类器。测试时将输入图像送入网络,根据输出的概率值得出该图像属于哪一个类别。典型的卷积神经网络结构如图4 所示,输入图像大多是经过预处理之后的图像,许多研究者将输入图像转变为正方形图像之后再送入网络,如224×224尺寸的图像[57]。也有研究者直接将长方形的ROI 图像送入网络[58]。多个卷积层之后往往会连接一个或者多个全连接层,也可以为没有全连接层的全卷积结构[59]。全连接层的最后一层是经过Softmax 函数转换之后的N个类别的概率分布。并将此概率分布与真实标签采用损失函数进行Loss计算。
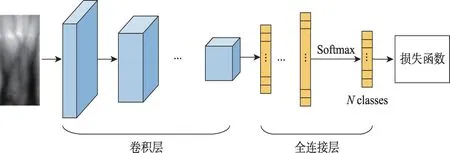
图4 用于分类的卷积神经网络示意图Fig.4 Schematic diagram of CNN for classification
Das等人[58]采用5个卷积层和1个Softmax全连接层进行识别。原始图像经过上下掩膜法[7]的ROI 提取、归一化以及对比度限制的自适应直方图均衡得到输入图像并送入神经网络,在4个公共数据集上测试都能达到95%以上的正确率。Radzi 等人[60]采用4层卷积神经网络结构进行手指静脉识别,在81 名受试者组成的自有数据集上识别正确率达到99.38%。Kuzu等人[61]提出了一种基于卷积和循环神经网络的识别框架,卷积神经网络包含6个卷积层、2个全连接层和1 个输出层。在自有数据集上测试的准确率达99.13%。Yeh 等人[62]采用ResNeXt-101 作为主干网络,Cutout 方法用于数据增广,在FV-USM 数据集上的识别准确率为98.1%。Huang等人[63]设计了一种基于ResNet-50的手指静脉分类CNN模型,其中引入了基于U-Net的空间注意机制。采用偏置场校正算法对手指静脉图像进行处理,以降低低对比度和光照不平衡对输入图像的影响。Li等人[64]将Vision Transformer与胶囊网络(capsule network)结合对手指静脉图像进行分类,首先将预处理图像分割成小块送入Vision Transformer 提取手指静脉特征,然后将特征向量输入到胶囊模块中进行进一步训练。该模型能够基于全局注意力和局部注意力对手指静脉图像信息进行挖掘,并选择性聚焦于重要的手指静脉特征信息。
基于分类的方法的优势在于图像分类技术较为成熟,许多经典的网络的分类效果都很出色。但是该方法只适合没有新增类别的封闭场景,只能识别他们训练过的身份,当出现新的手指时,需要增加类别并重新训练才能识别新的身份,这在大多数实际应用场景中是不方便的。此外,手指静脉图像数据集的特点是类别很多,通常为几百甚至上千,且每个类别的训练样本很少,一根手指通常仅有几幅图像,这就加剧了训练难度,很容易造成过拟合。
2.2 基于双图像匹配的方法
基于双图像匹配的方法又称为基于验证的方法(verification-based),通常将一对手指静脉图像样本作为神经网络的输入,以得出该两幅图像是否来自同一手指,从而确定是否属于同一身份。该方法本质上是将网络训练为二分类器,两幅图像为同一身份为一类,不同身份为另一类。该方法在训练时需要构造图像对作为样本,在实际应用时需要将输入的图像与数据库中的图像依次组成图像对进行匹配识别。典型的卷积神经网络结构如图5所示,与基于分类的神经网络的主要区别是输入为两幅图像,输出层是两个类别的概率。输入的两幅图像经过函数f进行合并后再送入神经网络。函数f的合并方法可以为两幅单通道灰度图组合成一幅双通道图像[65-66],也可以是两幅图像的差分图像[57,67],还可以是采用其他方法组成的合成图像[68]。
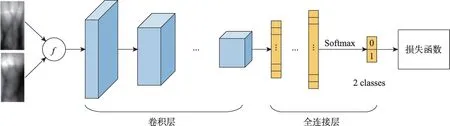
图5 用于双图像匹配的卷积神经网络示意图Fig.5 Schematic diagram of CNN for image pair matching
Hong等人[57]将两幅待匹配图像的ROI调整尺寸为224×224,然后进行差分运算,将差分图像输入预训练的VGG-16网络,在SDUMLA-HMT数据集上测试的等错误率为3.96%。Fang 等人[65]设计了一个双流网络,一个流的输入是两幅灰度图像组成的双通道图像,另一个流的输入是两幅图像的mini-ROI 组成的双通道图像,两个流的输出用Concat 层连接起来,并输入支持向量机(support vector machine,SVM)分类器进行最终决策。Song等人[68]采用两幅指静脉图像的合成图像作为DenseNet 卷积网络的输入,合成方法为将输入图像和注册图像的ROI拉伸为224×224,并将这两幅图像作为合成图像的第一通道和第二通道,然后将注册图像和输入图像调整为224×112,并将它们垂直拼接作为合成图像的第三通道。在HKPU 和SDUMLA-HMT 数据集上的等错误率分别为0.33%和2.35%。
基于双图像匹配的方法的优点是可以直接基于训练好的网络进行端到端验证,无需单独的特征匹配过程,并且能够处理身份不可见的开放集场景。虽然图像对的构造过程极大地扩大了训练集,但其中很大一部分可能是琐碎的、没有信息的对,它们对神经网络更新的反馈很少,导致学习效率低,性能下降。
2.3 基于特征提取的方法
基于特征提取的方法是目前研究得最多的方法,该方法旨在学习一个特征提取网络将手指静脉图像表示为一个一定长度的特征向量,通过匹配特征向量之间的距离来进行身份验证。典型的卷积神经网络结构示意图与基于分类的示意图类似,不同之处是全连接层的输出层不需要用Softmax 函数转换为N个类别的概率分布,而是直接为一定大小的特征向量。目前也有许多研究将特征提取与分类任务结合起来[56,69],典型的网络结构如图6所示,在损失计算时,需要将分类损失和特征度量损失进行融合。
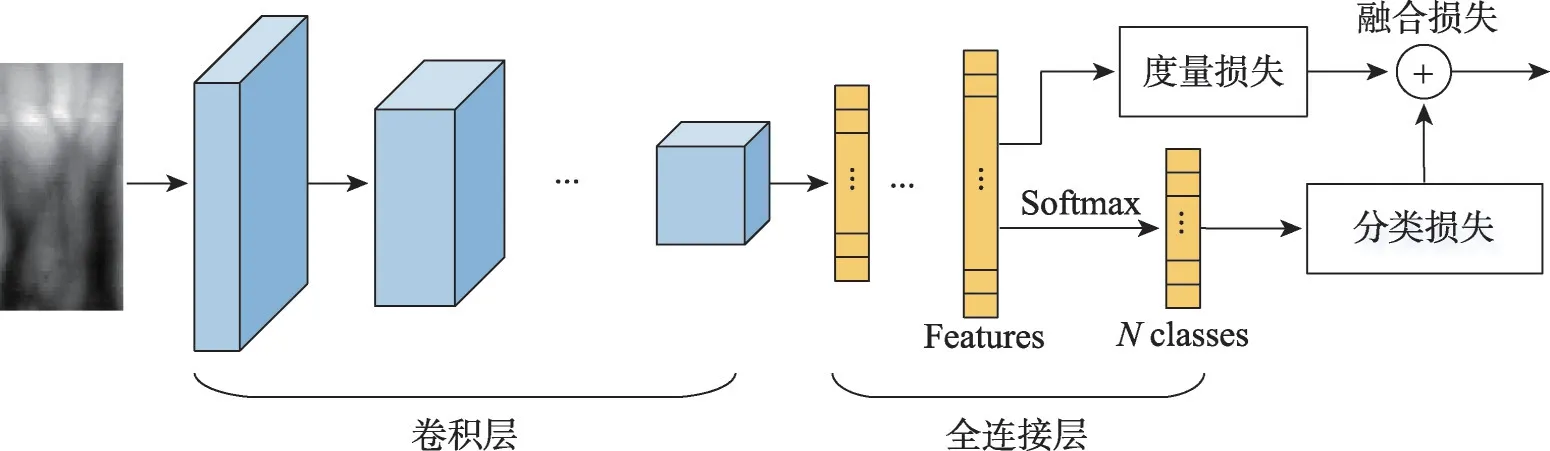
图6 特征提取与分类结合的网络示意图Fig.6 Schematic diagram combining feature extraction and classification
Huang 等人[69]针对指静脉信息受局部特征支配的特点,提出了一种基于Transformer的模型FVT,该网络采用级联的4个FVT模块提取手指静脉特征,在9个公开的数据集上都取得了不错的性能。Hou等人[70]将卷积自动编码器与SVM 相结合,用于手指静脉的验证,采用中心损失函数训练网络的有效性。Ou 等人[56]采用预训练的ResNet-18网络提取指静脉图像的特征,输出的特征向量的维数为512,并结合类内数据增广和融合的损失函数在3个公开数据集及自制系统上得到了不错的性能。Hu等人[71]基于VGGFace-Net提出了FV-Net,输出的特征向量为2×2×256,然后采用错位匹配策略进行特征匹配,在3 个数据集SDUMLAHMT、FV-USM 和MMCBNU-6000 上测试的等错误率分别为1.2%、0.76%和0.3%。Zhao 等人[72]提出了一个轻量级的CNN 网络,全连接层输出的特征向量长度为200,采集Softmax损失与中心损失相结合,在MMCBNU 和FV-USM 数据集上测试的EER 分别为0.503%和1.07%。Li等人[73]分别采用改进的ResNet-18和VGG-16 模型提取512 维度的静脉特征,并用三元组损失(triplet loss)进行训练,在3个公开数据集上进行交叉验证,最佳结果的准确率达到98%。
基于特征提取方法的优点是能够直接通过网络将静脉纹路图像表示为一定长度的特征向量,能够处理身份不可见的开放集场景,从相关研究可以看出,基于特征提取的方法的缺点主要是损失函数较为复杂,通常需要结合分类损失以提高收敛速度。要想提高基于特征提取方法的识别性能,损失函数的选择和设计是重要的环节。本文第4 章将对损失函数进行介绍。
2.4 基于图像生成的方法
基于图像生成方法的主要目的是根据现有的图像样本生成新的手指静脉样本进行数据增广,从而扩展训练集进行训练以提高识别性能。GAN网络是该方法采用的主要网络结构,许多学者都对其进行了研究并提出很多改进方法。典型的网络结构如图7 所示[74],GAN 网络主要由生成器和判别器组成,标签信号和噪声信号输入生成器,生成器网络生成“假”的手指静脉图像。“假”的手指静脉图像和真实图像输入判别器,判别器网络学习区分真假图像。“假”的手指静脉图像和真实图像一起组成训练数据,从而实现数据增广的目的。训练数据输入识别或者验证神经网络,从而实现图像分类或者特征匹配功能。
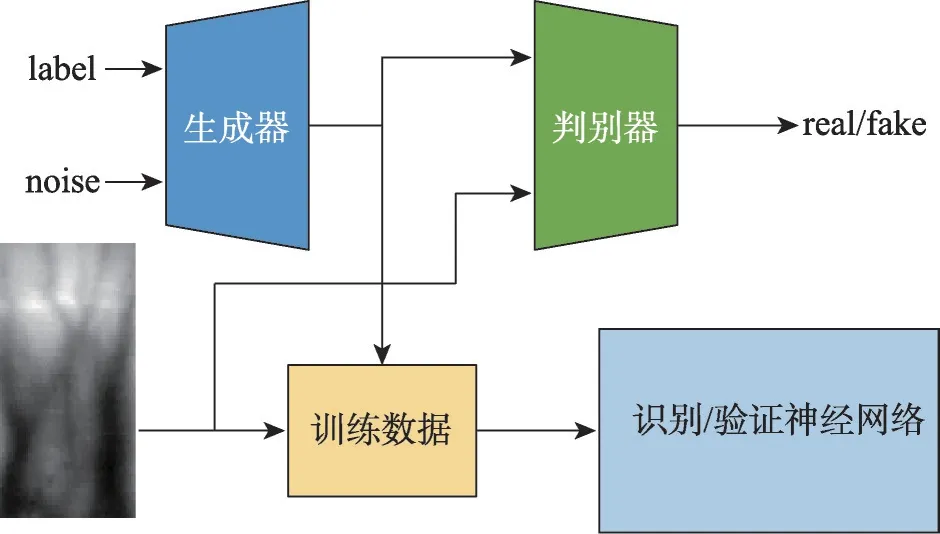
图7 基于生成对抗网络的结构图Fig.7 Architecture of GAN-based network
Zhang 等人[59]提出了一种轻量级的全卷积生成对抗网络架构,称为FCGAN(fully convolutional generative adversarial network),另外还提出了一种用于指静脉分类的网络FCGAN-CNN,实验表明通过FCGAN 进行数据增广能够改善CNN 用于指静脉图像分类的性能。Hou 等人[74]设计了一种新的生成对抗网络,称为三元组分类器GAN,用于指静脉验证。GAN与基于三元组损失的CNN分类器相结合,扩展了训练数据,提高了CNN的判别能力。Wang等人[75]提出了一种由约束CNN 和CycleGAN 组成的层次生成对抗网络用于数据增广,通过滤波器剪枝和低秩逼近的方法对模型进行压缩,从而使压缩后的模型更适合于在嵌入式系统上部署。Yang等人[76]基于CycleGAN提出了FV-GAN 网络,包含两个生成器,分别是图像生成器和纹路生成器,并设计合适的损失函数。该网络解决了真实标签不准确的问题。
尽管基于图像生成方法的结果令人鼓舞,但基于GAN 的方法需要结合额外的分类和验证网络使用,模型较单一网络复杂,且经常遇到收敛性较差和训练不稳定性的困难[77]。如何在有限的训练数据下,利用GAN生成高质量、多样化的手指静脉样本,仍然是有待研究的问题。
2.5 基于图像分割的方法
基于图像分割的方法采用U-Net 等神经网络从手指静脉图像中分割出静脉纹路图案作为特征,然后采用该特征进行匹配识别。该方法与传统的手指静脉识别流程类似,典型的流程图如图8 所示,ROI图像经过图像分割网络得到静脉纹路图像,然后将该纹路图像送入识别或者验证神经网络,从而实现图像分类或者特征匹配功能。图像分割网络通常为U-Net、SegNet、RefineNet 等经典的图像分割网络及其改进网络,识别或者验证神经网络与前几节提到的网络类似。

图8 基于图像分割方法的示意图Fig.8 Schematic diagram of image segmentation method
Jalilian等人[78]对比了三种网络(U-Net、RefineNet、SegNet)的静脉纹路分割性能,使用了自动生成标签的方法并与手动标签联合训练具有不同比例标签的网络,Miura match方法[18]用来匹配识别。Zeng等人[79]提出了一种改进的U-Net 的全卷积神经网络与条件随机场相结合的端到端静脉纹路提取模型。该模型能根据静脉的规模和形状自适应调整感受野,捕捉复杂的静脉结构特征。标签图像由传统的纹路特征提取算法生成并按权值融合得到。Zeng等人[80]在最新研究中提出的静脉纹路分割模型同样以U-Net 为骨干网络,并结合深度可分离卷积、Ghost模块、几何中值滤波剪枝等方法对模型进行压缩,最后得到的模型的参数量仅为U-Net 的9%,并且具有不错的性能。Song等人[81]提出了一种显式和隐式特征融合网络(explicit and implicit feature fusion network,EIFNet),用于手指静脉的识别。采用掩码生成模块进行纹路分割,然后采用掩膜特征提取模块对分割出的纹路图像进行特征提取得到显式特征,采用上下文特征提取模块直接提取原始图像的特征得到隐式特征。
深度神经网络具有较强的纹路分割能力,但是由于图像分割网络的训练需要大量标记数据,目前缺乏这样的数据集。因为手指静脉图像本来就不够清晰,人工标记的静脉纹路并不一定准确,这是缺乏数据集的主要原因。目前研究所使用的分割标签生成方法主要分为人工标注方法[82]、传统纹路提取方法自动生成方法[79,83]、人工标注与自动生成相结合的方法[78]。
以上提到的五种手指静脉识别中的深度学习方法,目前的研究主要以卷积神经网络为主,在每个领域都有一些经典的网络结构可以借鉴。在训练方面,常用的公开的手指静脉数据集由于每根手指图像样本偏少,在训练分类网络时存在容易过拟合的问题,因此需要在训练时结合图像增强技术以扩充样本。而基于图像分割的方法,训练时需要带标记的静脉纹路图像,目前还缺乏这样的数据集。因此,目前主流的方法是直接将输入的灰度图像提取为一定长度的特征向量。
在生物识别领域,其系统通常分为识别系统和验证系统,分别对应了封闭场景和开放场景的应用。在封闭场景中,系统中的身份个数已经确定,没有新增个体,识别系统的作用就是判断输入的生物特征属于系统中的哪个个体,因此识别系统被描述为一对多的匹配系统。基于分类的手指静脉识别方法就应用于这样的识别系统。验证系统通常被描述为一对一匹配系统,因为该系统试图将输入的生物特征与已经存入系统的特定生物特征进行匹配,以得出输入的特征是否存在于系统中,若是,进一步根据最佳匹配得出输入特征的身份。该系统适用于有新增个体的开放系统,当需要新增个体时,只需提取新增个体的特征存入系统中即可。基于双图像匹配的手指静脉识别方法就属于这样的验证系统。
基于特征提取的手指静脉识别方法将输入图像表示为一个一定长度的特征向量,通过匹配特征向量之间的距离来进行身份验证,该方法主要应用于开放场景。而基于图像生成的方法和基于图像分割的方法,生成的图像或者分割出的纹路图像可以送入识别网络或验证网络,因此分别适用于封闭场景和开放场景。
2.6 深度学习的其他应用
在手指静脉识别系统中,深度学习方法在图像质量评价、ROI 提取、模板保护(template protection)、呈现攻击检测(presentation attack detection,PAD)等方面也有应用。
(1)图像质量评价
由于图像采集装置在采集手指静脉图像时,受光照强度、环境温度、手指组织中的光散射、用户自身行为等因素的影响,导致采集的图像质量参差不齐。低质量的图像将会导致系统性能下降。如果能在图像采集阶段就自动辨别出低质量图像并提醒用户重新采集,将大大提高系统的准确率。许多学者对基于深度学习的指静脉图像质量评价方法进行了研究[84-86]。Qin等人[84]采用深度神经网络(deep neural network,DNN)对手指静脉的图像进行质量评价,将ROI 图像分成不同的块分别采用DNN 进行质量评价,然后将每个块的质量分数联合输入到概率支持向量机中以得出整幅图像的质量分数。通过该方法扩展了训练数据量,提高了质量评估性能。Wang等人[85]采用竞争Gabor响应自适应直方图进行识别,将识别正确的图像作为高质量样本图像,识别错误的图像作为低质量样本图像。针对高质量图像和低质量图像数量不平衡的问题,采用改进的SMOTE(synthetic minority over-sampling technique)方法扩充低质量图像的数量,最后使用卷积神经网络对这些图像进行区分。
(2)ROI提取
在传统的手指静脉识别方法中,感兴趣区域提取是重要的环节。对于采用深度学习方法的手指静脉识别系统,如果将原始图像进行ROI提取之后再输入网络模型进行分类或者特征提取,对系统性能的提升也会有帮助。因为ROI 提取算法可以对手指的位移进行校正,提高了CNN网络稳定性;ROI提取会过滤掉大部分不相关的区域,保留原始静脉模式,可以有效地改进训练过程[2,59,87]。Ma等人[88]针对传统卷积神经网络信息丢失的问题,提出了一种基于胶囊神经网络(capsule neural network)的手指静脉感兴趣区提取算法,在两个公共数据集上取得了不错的效果。Yang 等人[89]以VGG-16 网络作为骨干网络对ROI进行提取,用IOU(intersection over union)指标评价ROI提取的准确性,与传统方法相比取得了更好的性能。
(3)模板保护
手指静脉识别系统中存储的静脉特征模板属于个人隐私,一旦泄露,将会存在安全风险。许多学者对模板保护方法进行了研究[90-93]。Ren等人[90]提出了一种带模板保护的完全可撤销的手指静脉识别系统,采用RSA(Rivest-Shamir-Adleman)加密技术对手指静脉图像加密,使用CNN 对加密后的图像进行处理,在保证识别性能的同时保障用户静脉模板的安全性。Liu等人[91]提出了一种基于深度学习和随机投影的安全生物特征模板的手指静脉识别算法FVRDLRP(finger vein recognition based on deep learning and random projections)。即使用户的密码被破解,FVR-DLRP也会保留核心生物特征信息,而原始生物特征信息仍然是安全的。Shahreza 等人[92]使用深度卷积自动编码器从传统手指静脉识别方法生成的特征图中学习降维空间中的深度特征,然后对这些深度特征应用生物哈希算法来生成受保护的模板,采用自编码器损失和三元组损失结合的多项损失函数以提高在模板保护情况下的识别精度。
(4)呈现攻击检测
与其他生物识别方式不同,指静脉识别技术通过使用手指皮肤下的血管纹路来确定个人身份,具有高安全性的特点。但是,用“偷”来的指静脉图像欺骗指静脉识别系统仍然是可能的。为了保护指静脉识别系统免受欺骗攻击,对其欺骗检测方法,即PAD 方案的研究仍然是非常有必要的[94-96]。Shaheed等人[94]提出了一种基于残差连接和深度可分离的轻量级卷积神经网络与线性支持向量机的呈现攻击检测方法,能有效地从假指静脉图像和真实指静脉图像中提取特征并加以区分。Yang等人[95]提出了一种轻量级指静脉识别和反欺骗网络FVRAS-Net(fingervein recognition and antispoofing network),该网络利用多任务学习方法,将识别任务和反欺骗任务集成到一个统一的CNN 模型中,实现了高安全性和强实时性。
3 深度学习中的设计技巧
为了使模型更轻、性能更好、鲁棒性更强,许多深度学习中的设计技巧被用于手指静脉识别网络的研究与开发中。
3.1 轻量化网络设计
为了能使深度学习模型被部署到便携式设备中,轻量化网络的研究必不可少。目前常用的轻量化设计方法主要为轻量化网络结构设计和模型压缩两类[97]。轻量化网络结构设计的基本思想是采用较少的卷积层、全卷积结构替换参数量大的全连接层、深度可分离卷积(如图9所示)、分组卷积以及神经网络搜索(neural architecture search,NAS)等技术减少卷积运算量,降低模型训练和推理时间。模型压缩的方法通常在卷积层和全连接层采用张量分解、量化、剪枝等手段进行模型调整以减少参数的内存占用和计算成本。
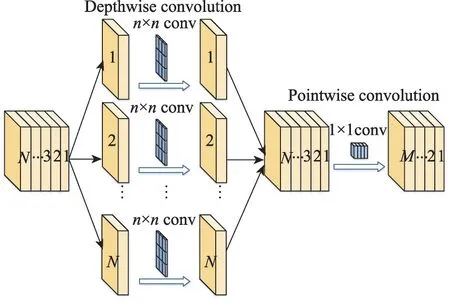
图9 深度可分离卷积流程图Fig.9 Flow chart of depthwise separable convolution
在手指静脉识别领域,多位学者采用了轻量化设计方法以提高识别速度,降低模型部署难度。Zeng 等人[80]将深度可分离卷积应用到基于U-Net 的轻量级网络设计中。Shaheed等人[94]提出了一种基于残差连接和深度可分离卷积神经网络与线性支持向量机相结合的呈现攻击检测方法,解决了手指静脉识别系统PAD领域缺乏轻量级高效特征描述符的问题。Shaheed等人[98]还提出了一种基于深度可分离的残差连接CNN 的预训练Xception 模型,该模型被认为是一种更有效、更简单的提取鲁棒特征的神经网络。Ren等人[99]受MobileNeV3[100]的启发,将深度可分离卷积、倒残差结构和NAS[101]相结合,设计了一个轻量级的多模态特征融合网络FPV-Net(fingerprint and finger vein recognition network)。文献[59]、文献[60]、文献[61]、文献[72]、文献[84]、文献[86]、文献[91]、文献[92]、文献[102]等采用自己搭建的小型网络实现模型的轻量化,这些模型通常只有3~6个卷积层,1~2个全连接层。文献[66]、文献[71]、文献[79]等对经典网络进行压缩来实现轻量化,通过删减卷积层或全连接层的数量、减少各层的通道数等方法减少模型的参数量及运算量。以上设计大多在实现模型轻量化的同时,能够保证识别准确率和稳定性在较高水平,因为手指静脉图像尺寸较小,样本数量少,直接采用大型的网络模型反而容易出现过拟合的问题。
3.2 数据增广
虽然公开的手指静脉数据集不少,但是与ImageNet、CoCo等用于图像分类、目标检测的大型数据集相比,手指静脉数据集中的图像较少,包含的手指数量通常只有几百个,而且每个手指的图像往往不超过10幅,这加大了神经网络的训练难度,使模型容易出现过拟合,在做分类任务时表现尤为突出。为了解决训练数据不充分的问题,数据增广是非常有必要的。许多学者在其研究中都用到了各种数据增广方法,这些方法主要分为传统图像处理方法和深度学习的方法。
传统图像处理方法主要是将图像的形状、亮度、清晰度等进行改变以获得新的图像从而扩充数据集。Ou等人[56]将类间增广和类内增广相结合对训练集进行扩充。类间增广采用图像垂直翻转来实现,类内增广通过图像的随机裁剪和调整大小、旋转、透视失真和颜色抖动来实现。Hou等人[103]采用翻转、旋转、移位、剪切和缩放等方法进行图像增广,并详细说明了各种方法的具体参数设置。Yang等人[89]采用仿射变换、亮度变换、添加高斯噪声和随机裁剪进行数据增广,每种操作的执行概率为0.5。图10为常见的数据增广示例。
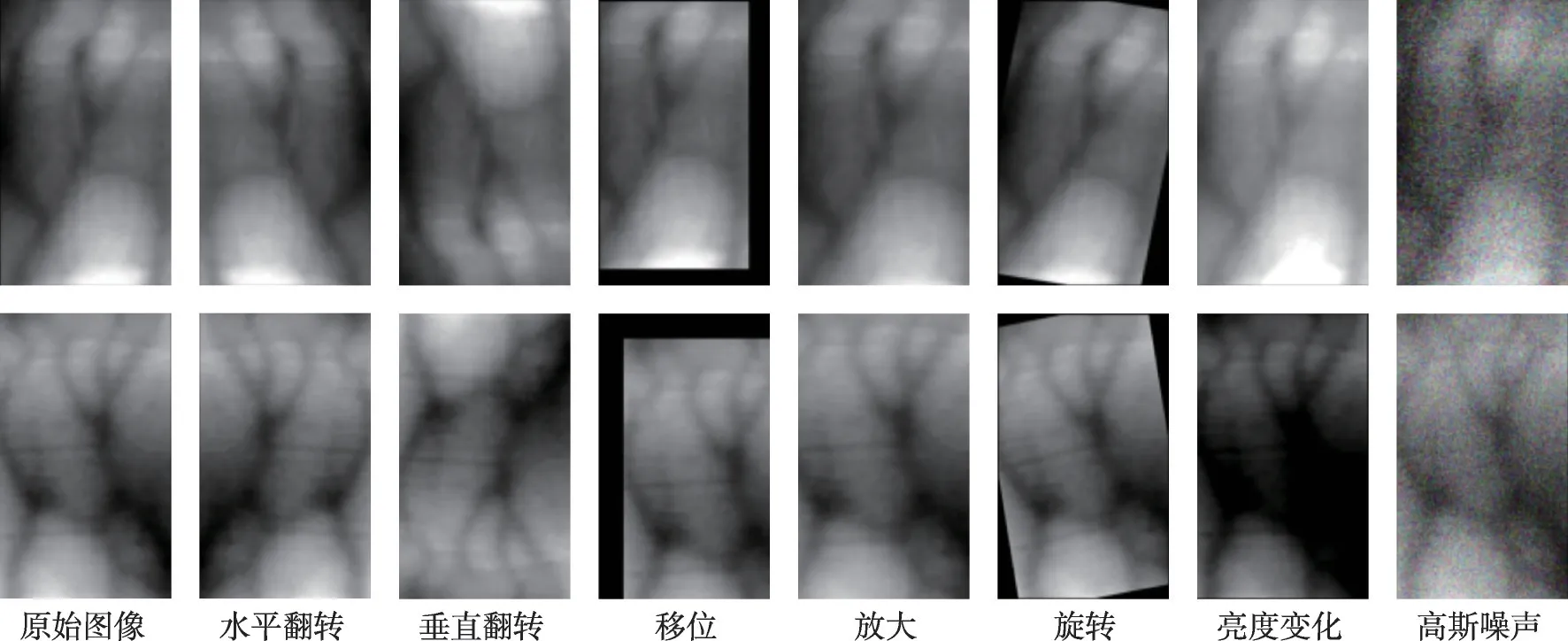
图10 指静脉图像数据增广示例Fig.10 Example of finger vein image data augmentation
前面提到的传统图像处理方法主要基于单幅图像进行变换,产生新图像时可以利用的先验知识很少,仅仅是图像本身的信息。基于深度学习的方法可以通过训练学习数据集中所有图像的特征,从而将整个数据集作为先验知识用于生成新的样本图像,这种数据增广方法在理论上是一种更加优秀的方法。该方法最常用的是采用GAN模型生成新的手指静脉图像来扩充数据集,在本文的第2章基于图像生成的方法介绍中已作详细描述,在此不再赘述。
另一种数据增广的方法是将图像分割成多个小块再送入神经网络进行训练,这样不仅能扩充数据集,还能通过使用更小网络模型实现系统的轻量化。Qin等人[84]和Zeng等人[86]将ROI图像拆分成5块再送入神经网络进行质量评价,为了保持纹路的连贯性,拆分时使部分区域重叠。Yang 等人[76]将原始的ROI图像拆分成90 个小块送入纹路生成模型中训练,极大地扩充了训练集。
3.3 迁移学习
迁移学习是指利用数据、任务或模型之间的相似性,将旧领域学习过的模型,应用于新领域的一种学习过程。迁移学习可以使模型在初始时就具备较优的性能,后续只需微调就可以使模型性能得到提升。使用预训练模型是迁移学习的主要方法,通过使用之前在大数据集上经过训练的预训练模型,可以直接获得相应的结构和权重。在机器视觉领域,预训练模型大都采用ImageNet 数据集作为训练集,因为它包含上百万幅图像,有助于训练普适模型。在手指静脉识别的研究中,许多学者采用预训练的经典网络模型来提升系统性能。Hong等人[57]采用预训练的VGG-16模型进行差分图像匹配。Song等人[68]将DenseNet-161 模型的卷积层采用预训练模型进行初始化,只对最后的全连接层进行微调。Hu 等人[71]采用预训练模型对VGGFace-Net 的前6 个卷积层进行权重初始化,并嵌入到FV-Net模型中。Kuzu等人[104]将ImageNet上的预训练模型应用于DenseNet-161和ResNext-101模型中进行性能比较。
3.4 注意力机制
2018年,基于压缩和激励(squeeze-and-excitation,SE)模块的通道注意力机制被提出[105],通过给每个通道计算一个权重,让不同通道对结果有不同的作用力,可以增强网络提取图像的能力。针对SE 模块中采用全连接层参数量大的问题,高效通道注意力(efficient channel attention,ECA)模块将全连接层改为一维卷积[106],每一次卷积过程只和部分通道进行运算,实现了适当的跨通道交互,可以在显著降低模型复杂度的同时保持性能。在SE模块的基础上,卷积块注意力模块(convolutional block attention module,CBAM)实现了通道注意力和空间注意力的双机制[107],进一步扩展了注意力机制的作用。注意力机制目前在图像生成、图像恢复、图像分割、图像分类等多种计算机视觉任务中都表现出了优异的性能。
在手指静脉认证任务中,深度网络生成的特征包含了跨通道和跨空间域的不同类型的信息,这些信息对于学习静脉纹路的详细信息有不同的贡献。如果能够增强网络对高贡献特征的敏感性,使其专注于学习更具鉴别性的特征,那么网络提取的指静脉特征就能更容易分辨。Huang等人[63]基于U-Net设计了一个像素级空间注意力模型。将U-Net 输出图像的每个像素当作权重与原图像的对应像素值进行相乘,达到图像增强的目的,使网络更关注图像的纹路区域,从而提取出鲁棒的静脉特征。Hou等人[103]为了提高CNN模型的性能,将ECA模型嵌入到ResNet模型中,提出了高效的ECA-ResNet 模型,进行指静脉特征提取。Ren等人[90]将通道注意力SE 模块作为子结构嵌入到基本网络中,形成手指静脉加密图像的特征提取网络。
为了能更加充分并精确地提取出静脉图案特征,多位学者对注意力机制进行了改进。Huang等人[108]提出了一种联合注意力(joint attention,JA)模块,该模块在特征图的空间和通道维度上进行动态调整和信息聚合,聚焦于细粒度细节,从而增强了静脉图案对提取识别特征的贡献。Wang等人[109]针对手指静脉的特点,设计了维度交互注意力机制(dimensional interactive attention mechanism,DIAM),它不仅可以加强图像空间和通道上细节特征的提取,还可以加强空间与通道之间的关系。
DIAM的结构如图11所示[109],它由3个平行分支组成,其中两个分支负责捕获通道C 与H、C 与W 的跨维交互,剩余分支用于构建空间注意力。最后,聚合所有3 个分支的输出。一般的注意力机制是分别计算空间注意力机制和通道注意力机制,因此不考虑两者之间的关系。而DIAM 的空间注意机制的维度相互作用,既增强了空间和通道的特征提取能力,又能捕捉不同维度之间的依赖关系。该注意力机制的缺点是增加了运算复杂度。
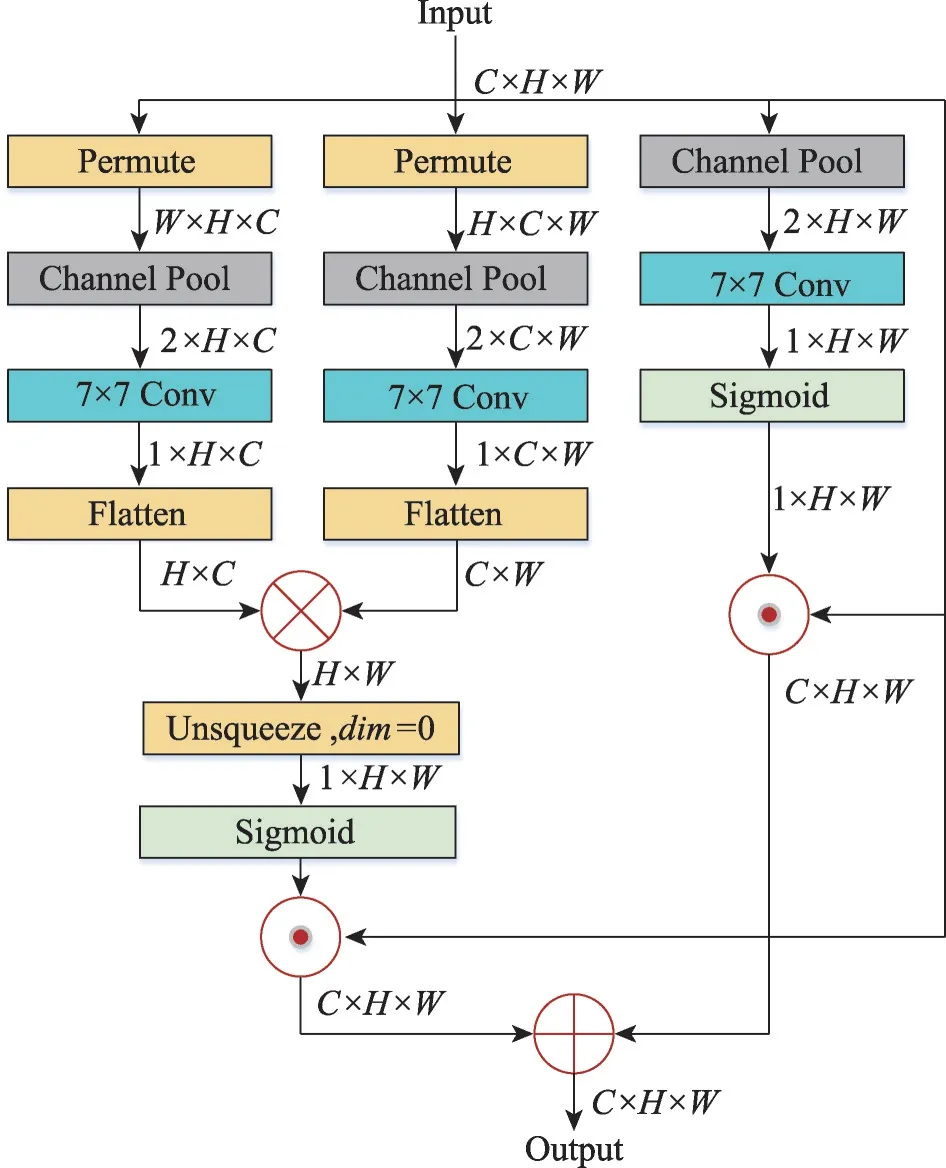
图11 DIAM模块结构图Fig.11 Structure diagram of DIAM module
4 损失函数
损失函数(loss function)是用来估量深度学习网络模型的预测值与真实值不一致程度,是训练阶段非常重要的环节。根据任务的不同,基于深度学习的手指静脉识别系统中,损失函数分为分类损失函数和度量学习损失函数[56]。分类损失利用额外的分类器将特征学习过程表述为分类问题,主要通过优化预测类别的概率达到学习的目的。度量学习损失的目的是学习一对特征向量的相似度,直接优化特征之间的距离。
在分类任务中,常用的损失函数有Softmax 损失、大裕度余弦损失(large margin cosine loss,LMCL)、附加角裕度损失(additive angular margin loss,AAML)、负对数似然损失函数(negative log likelihood loss,NLLLoss)等。常用的度量学习损失有对比损失(contrastive loss)、三元组损失(triplet loss)、中心损失(center loss)、反余弦中心损失(arccosine center loss)等。
4.1 分类损失函数
(1)Softmax损失
Softmax损失是Softmax函数与交叉熵损失(crossentropy loss)组合而成的损失函数,是分类任务中最常用的损失函数。Softmax 函数的作用是把一个序列(通常是全连接层的输出)转换成概率分布,交叉熵函数根据概率分别计算得到loss,整个Softmax Loss的公式如式(1)所示:
式中,N表示样本总数量,K表示类别数量,yi表示样本xi的真实类别,表示最后一个全连接层中第j个类别的权重向量,即为最后一个全连接层的第j个类别的输出(偏置为0)。
Softmax Loss深度网络只鼓励特征的可分性,通常只关注类间信息而忽略类内信息,这可能会导致误分类。
(2)大裕度余弦损失
许多学者都基于Softmax Loss进行改进,改进的主要目的都是最大化类间差异和最小化类内差异,大裕度余弦损失就是其中的改进之一[110]。根据Softmax Loss的公式可以得到:
式中,θj是Wj和xj的角度,将||Wj||||xj||规范化为一个尺度s,并引入一个余弦裕度(cosine margin)m来进行度量的约束,让当前样本所属的类别在减去一个m之后仍然属于这个类别,得到最后的损失函数如式(3)所示:
(3)附加角裕度损失
附加角裕度损失[111]的计算如式(4)所示:
与大裕度余弦损失将裕度m添加到余弦值之后不同,附加角裕度损失在W和x之间添加了一个附加的角裕度惩罚m,再进行余弦计算,以同时增强类内紧致性和类间差异性,因为当θ的范围为[0,π-m]时,cos(θ+m) (1)三元组损失 三元组损失主要是为了非同类极相似样本的区分,最早用于人脸识别任务[112]。Triplet Loss 需要输入一个三元组,分别是锚样本(Anchor)、正样本(Positive)和负样本(Negative),锚样本与正样本属于同一类,锚样本与负样本不是同一类。根据式(5)优化锚样本与正样本的距离小于锚样本与负样本的距离,实现样本之间的相似性计算: 式中,a表示锚样本,p表示正样本,n表示负样本,D表示两样本特征之间的距离,margin为设定的阈值。 (2)中心损失 中心损失最早也用于人脸识别任务[113],主要为了提高类内特征的紧凑性。其函数如式(6)所示: 式中,cyi表示第yi个类别的特征中心,xi表示全连接层之前的特征。实际使用的时候,m表示minibatch的大小。Loss越小,表示一个batch中的每个样本特征离该样本所有特征中心的距离的平方和越小,也就是类内距离越小。 (3)反余弦中心损失 中心损失主要是为了减小特征与相应中心之间的距离,因此在最小化类内距离方面是有效的改进。但是中心损失仍然使用欧氏距离,它只关注特定特征之间的绝对差异。这种差异体现在单个矢量的不同维度的数值上,这意味着欧氏距离对特定特征的绝对值很敏感。与欧氏距离一样,余弦距离也常用于验证领域的相似性度量。余弦距离侧重于区分特征向量方向的差异,对特定特征的绝对值不敏感。余弦距离将特征向量作为一个整体来考虑,从而避免了个别特征的影响。Hou 等人[103]提出引入余弦距离代替欧氏距离来测量特征与中心之间的距离,从而得出反余弦中心损失函数,如式(7)所示: 式中,fi表示全连接层之前的特征向量,cyi表示第yi个类别的特征中心。 以上各种损失函数在生物识别领域都有广泛的使用。在手指静脉识别的研究中,文献[58]、文献[61]、文献[63]、文献[65]、文献[66]等将Softmax 损失函数用于手指静脉特征分类。Li 等人[73]将三元组损失函数用于优化其特征提取网络。Kuzu 等人[114]对比了Softmax、LMCL、AAML三个损失函数对网络的优化能力,得出AAML 具有最佳效果。Tran 等人[115]将附加角裕度损失函数用于网络优化。Kang等人[116]采用中心损失函数进行特征匹配。 由于大多数度量学习损失函数单独使用会使模型训练过程表现很不稳定,收敛速度慢,需要根据结果不断调节参数,经常将度量学习损失函数与分类损失函数结合在一起使用。Huang等人[69]将NLLLoss与中心损失相结合进行网络训练。Ou等人[56]将大裕度余弦损失函数与三元组损失函数进行融合取得了不错的性能。Zhao 等人[72]将中心损失与Softmax 损失函数进行结合用于优化其轻量级特征提取网络。Hou 等人[103]将Softmax 损失函数与反余弦中心损失函数结合训练其高效通道注意力残差网络,并与10余种损失函数的训练效果进行对比,证明了其损失函数的高效性。 手指静脉识别系统常用的评价指标有准确率、等错误率、真正率、假正率、正确接受率等,还有ROC(receiver operator characteristic curve)曲线直观显示算法性能。 (1)识别准确率Accuracy 基于分类的指静脉识别系统,常用的评价指标是识别准确率Accuracy(简写为Acc),即所有测试样本中,能正确分类的百分比,如式(9)所示: 式中,Ntotal表示所有测试样本的数量,Ncorrect表示能正确分类/识别的样本数量。表3为2019年至今部分文献的方法在公开数据集上的准确率。 (2)等错误率EER 等错误率(equal error rate,EER)是指静脉验证系统常用的评价指标,与EER相关的参数有错误接受率(false acceptance rate,FAR)和错误拒绝率(false rejection rate,FRR)。 FAR又称误识率,表示两个不同类别的样本(类间)匹配时,被错误地认为是相同样本的百分比,如式(10)所示: 式中,Ninter表示所有类间匹配的次数,Nacceptance表示错误接受的次数。 FRR又称拒真率,表示两个相同类别的样本(类内)匹配时,被错误地认为是不同样本的百分比,如式(11)所示: 式中,Nintra表示所有类内匹配的次数,Nrejection表示错误拒绝的次数。 当两幅手指静脉图像进行匹配识别时,会得到匹配分数Score,Score值越高,表示两幅图像越相似。通常会设定一个阈值TScore,当Score≥TScore时,认为两幅图像来自同一手指,否则认为来自不同手指。TScore设置得越大,FRR就越大,FAR就越小;同样,TScore设置得越小,FAR就越大,FRR就越小。通过选择TScore的值,使FRR与FAR相等或相差最小,这时的错误率称为EER。表4列举了2019年至今部分文献的方法在公开数据集上实验的等错误率。 FRR@FAR=0.1%[56]也是常用的评价指标,指当错误接受率FAR为0.1%时,FRR的值,该指标更加关注生物识别身份验证系统的安全性。在实际测试时,FAR也可以取其他值,如1%或0.01%等。 (3)ROC曲线 ROC曲线是一种已经被广泛接受的系统匹配算法测试指标。在手指静脉识别领域常用的ROC曲线为FAR-FRR曲线,它是误识率、拒真率和匹配分数阈值之间的一种关系,反映了识别算法在不同阈值上,FRR和FAR的平衡关系。图12为ROC(FAR-FRR)曲线的示意图,其中横坐标是FAR,纵坐标是FRR,EER是FAR-FRR曲线中FAR=FRR的平衡点,EER的值越小,即曲线越靠近左下角,表示算法的性能越好。FRR越大,表示安全性高,但是通过性不好;FAR越大,表示通过性好,但是安全性就低。在多种方法性能对比时,通常将每种方法的ROC 曲线绘制在同一个坐标图上,以便于直观对比。 传统的依靠手工提取特征的手指静脉识别方法在面对图像质量差、类间差异小和类内差异大的情况下,难以表现出优异的性能,使其发展遇到一定的瓶颈。深度学习技术的兴起并应用到手指静脉识别领域,极大地克服了这一瓶颈,将手指静脉识别的性能提升到了新的高度,但是该领域面对的困难和挑战依然存在。 (1)低质量的图像仍然是制约识别性能的首要因素 受光照强度、手指厚度、环境温度、采集姿势的影响,手指静脉采集装置采集到的图像有可能存在低质量的图像。这些图像有可能亮度过高或过低,导致部分静脉图案信息丢失,纵使复杂的图像增强算法也难以达到理想效果。也有可能出现图像错位、水平旋转或轴向旋转,严重的错位或者旋转极大地增加了类内差异性,纵使优秀的网络模型也无法学习出理想的辨别能力。因此,低质量的图像仍然是制约识别性能的首要因数。要想提高系统性能,须从源头上解决低质量图像的问题。这就需要从图像采集设备、图像质量评价方法、生物特征建模等方面来解决图像质量过低导致的性能下降的问题。 (2)有限的数据集阻碍了深度学习方法的全面应用 虽然目前公开的手指静脉图像数据集较多,但这些数据集中每根手指采集的图像样本太少,通常只有几幅图像,不利于基于分类方法的模型训练。此外还缺乏用于手指静脉图像分割的数据集,而人工标记的纹路和自动生成的纹路都存在标注不准确的问题,这阻碍了基于图像分割的手指静脉识别方法的研究。为了增强身份认证的安全性和提高识别的准确率,将手指静脉与指纹、掌纹、人脸、虹膜等其他生物特征进行融合以实现多模态识别是研究的方向,但是目前也存在缺乏公开的多模态数据集的问题。综上所述,要想各种深度学习方法都能得到全面研究和应用,相应的公开数据集必不可少。 (3)高辨识度的特征依然需要更优秀的模型提取 随着深度学习技术的发展,许多优秀的网络模型已经被用于手指静脉识别认证系统中。这些模型大都基于现有的公开数据集学习特征提取能力,在这些数据集上取得了较强的辨识能力,但是这些模型应用到真实场景中不一定会取得与仿真实验相同的效果,这严重地限制了指静脉识别的应用。因此,还需要设计出更优秀的模型能在各种场景下提取出高辨识度的特征。随着手指静脉识别技术的发展,三维指静脉识别和融合指静脉的多模态识别技术将会成为发展的趋势。三维图像和多模态信息比传统的单幅指静脉图像拥有更多的特征,提取特征需要更多的参数和运算量,这也需要设计出高效的网络模型,实现特征提取能力和运算速度的双优。 (4)广泛的应用还受到各种因素的制约 虽然手指静脉识别算法的研究已经取得了丰硕的成果,但是与指纹识别和人脸识别相比,还谈不上广泛的应用。制约其应用的因素是多样的,包括设备价格、采集舒适度、算法复杂度、识别精度等。如果想从采集设备的角度解决低质量图像的问题,需要采用更优秀的近红外摄像头和光源,采用自动调光电路对光照强度进行调节,采用更好的处理器运行神经网络模型等,这都会增加设备的成本。与人脸识别相比,手指静脉识别并不算动态识别,需要将手指放入采集设备的卡槽中静置一段时间才能完成注册或识别,并且对手指的姿势和放置位置有较高的要求,因此在采集舒适度方面有所欠缺。此外,许多性能优异的指静脉识别算法和模型往往较复杂,不利于在便携式的手指静脉识别装置中部署。在实际应用场景中的识别精度也备受质疑。 手指静脉识别面临的四大挑战相互关联、相互制约,这也映射出今后的发展和改进方向。 (1)三维手指静脉图像识别 将多个摄像头拍摄的同一手指的多个二维静脉图像构造成三维图像,然后利用所构造的三维手指静脉图像代替传统的二维图像进行识别,可以获得更多的特征信息,包括所有的静脉纹路信息和手指的几何特征,而且在3D手指静脉图像中,无论手指姿势如何变化,静脉结构都是一致的,可以解决低质量图像中的图像错位和旋转问题。基于以上优势,三维手指静脉识别可能会成为未来的研究热点。目前已有部分学者对其进行了研究并取得了部分成果。Zhao 等人[3]设计了一种低成本的基于多视角的指背静脉成像设备用于数据采集,建立了一个新的多视角指背静脉数据库THU-MFV,然后提出了一种名为分层内容感知网络的深度神经网络来提取手指静脉的分级特征。Kang等人[116]设计了一种能同时获取一根手指所有静脉图案的三摄像头采集方法,提出了基于深度可分离卷积的轻量级卷积神经网络构建全视图三维手指静脉图像的三维重建方法以及相应的三维手指静脉特征提取与匹配策略。 虽然三维手指静脉识别方法具有二维识别方法无法比拟的优势,但是三维建模过程计算复杂,特征提取需要更大的网络模型。同时,由于需要使用多个近红外摄像机从不同角度进行图像采集,采集设备成本较高。此外,目前还缺乏可供其他网络模型训练的三维手指静脉的大型公共数据集。综上所述,虽然三维手指静脉识别可能会成为未来的研究热点,但是在实际应用时仍然会面临挑战。 (2)多模态生物特征提取 随着人们对安全性的要求越来越高,在采集手指静脉图像的同时采集其他生物特征,如指纹、人脸、掌纹、手指形状等,将多种生物特征进行组合以达到多模态生物识别的目的,是未来的发展方向。Kim 等人[67]研究了能够同时识别手指静脉和手指形状的多模态生物识别系统,提出了基于深度卷积神经网络的多模态生物识别方法,在山东大学同源多模态特征数据库和香港理工大学手指图像数据库上的实验结果表明该方法在性能上优于传统方法。Goh等人[93]提出了一种基于最大索引哈希、无对齐哈希和特征级融合的多模态生物特征认证框架,可以快速采用具有不同特征分布的所有流行生物识别模式用于特征级融合,实验证明了在指静脉、指纹、人脸和虹膜数据集上的有效性。Wang 等人[120]提出了一种基于手指静脉和人脸特征层融合的生物特征识别方法。该方法利用自注意机制获得两种生物特征的权重,并结合ResNet残差结构,将自注意权重特征与双模态融合特征在通道上级联。Ren 等人[99]设计了一种能同时采集手指静脉和指纹的设备,制作了数据集NUPT-FPV,提出了一种基于卷积神经网络作为基准的多模态融合方法。Cherrat等人[128]将卷积神经网络与随机森林(random forest,RF)分类器结合用于指静脉、指纹和人脸识别三模态生物识别系统。 多模态生物识别系统的优势在于,它融合了人体的多种特征,比大多数现有的单模态生物识别系统具有更高的安全性,并可以解决单一模态采集质量较低带来的特征辨识度不高的问题。然而,由于获取不同类型的生物特征需要不同的采集设备,而且不同生物特征的融合机制和方法尚未明确,多模态生物识别系统还需进一步研究。 (3)基于Transformer的网络模型研究 Transformer是谷歌在2017年提出的一个里程碑式的模型[129],最先应用于自然语言处理领域。Transformer 基于自注意的Encoder-Decoder 结构,能并行方式处理数据,因为注意力机制允许模型考虑任意两个单词之间的相互关系,而不管它们在文本序列中的位置。鉴于Transformer在NLP任务中取得的巨大成功,许多学者将其引入到计算机视觉领域并加以改进,提出了许多优秀的模型,如ViT[45]、Swin Transformers[130]、Deformable DETR(detection transformer)[131]、DN-DETR(denoising DETR)[132]等,它们在图像分类、目标检测、图像分割等任务中大放异彩。 虽然Transformer由于其良好的全局特性和特征融合能力,在计算机视觉上取得了多项最先进的性能,但是由于Transformer 模型较复杂、训练时间长、效率较低等原因,目前在手指静脉识别领域采用Transformer 的方法还很少。同时,要想训练Transformer使其性能超过CNN,需要大型的数据集,而现有的手指静脉数据集中的图像样本普遍偏少。与CNN相比,Transformer提取局部特征的能力偏弱,因此目前主流的解决方案为Transformer 与CNN 结合以提取静脉特征[133]。例如,Li等人[64]将视觉转换器架构与胶囊网络相结合,提出了ViT-Cap模型。该模型能够基于全局注意力和局部注意力对手指静脉图像信息进行挖掘,并选择性聚焦于重要的手指静脉特征信息。实验证明了该模型在手指静脉识别中的有效性和可靠性。此外,为了降低模型的复杂度,有学者只采用Transformer 的编码器进行特征提取。Huang 等人[69]深入研究了ViT,针对手指静脉信息受局部特征支配的特点,对Transformer 的编码器进行改进,提出多层特征提取功能的新模型FVT(finger vein transformer),与纯CNN 相比,该模型获得了具有竞争力的结果。 随着视觉Transformer 的深入研究,其缺点将会得到改进,基于Transformer 的手指静脉识别方法也将成为研究的热点。 (4)轻量级网络设计 只要是涉及到人的身份认证的场景,都可以利用手指静脉识别系统。在这些场景中,许多时候都需要采用移动设备或者轻小型设备以提高安装和使用的便捷性。采用深度学习的方法虽然可以通过神经网络使系统性能得到提升,但也使得网络模型结构越来越复杂,对硬件设备的运算能力和存储空间的依赖愈发严重,这极大地限制了手指静脉识别方法的应用。因此,如何在保持模型较高精度的前提下对网络进行优化,降低其内存需求和计算成本,已成为将指静脉识别算法向移动端或者轻小型设备迁移时首当其冲的一大课题。 虽然目前许多关于手指静脉识别的深度学习研究都提出了轻量级的网络设计方法[72,80,86,119],这些方法在某种程度上确实达到了模型参数少、推理时间短的指标,但是难以保障在真实场景中的识别精度。目前提出的手指静脉识别网络的轻量级设计方法大多是通过减少卷积层或全连接层的层数,或者采用全卷积网络、深度可分离卷积结构减小模型参数量等,设计方法较单一,更多更有效的轻量级设计方法,如知识蒸馏、神经网络结构搜索技术、参数量化等方法有待应用到手指静脉识别的研究中。随着深度学习的发展,性能更优的复杂网络模型是必然的趋势,而基于这些模型的轻量级设计也会是一个永恒的话题。 近年来,尽管针对手指静脉识别问题已经涌现出了大量优秀的基于深度学习的解决思路,这些方法在公开数据集上测试的精度普遍已达到98%以上,等错误率大都在1%以内。但是大部分研究仍局限于实验室理论研究阶段,距离正式的产业化落地应用仍有很长的路要探索。技术终究要为解决实际应用问题服务,手指静脉识别和认证技术将通过不断优化与发展,更广泛地应用到人们的日常生活中。4.2 度量学习损失函数
5 评价指标与方法
6 面临的挑战及未来发展方向
6.1 面临的挑战
6.2 未来发展方向
7 结束语
猜你喜欢
实用手外科杂志(2022年2期)2022-08-31
北京航空航天大学学报(2021年9期)2021-11-02
数学小灵通·3-4年级(2021年5期)2021-07-16
小聪仔(婴儿版)(2020年12期)2021-01-26
电子制作(2019年11期)2019-07-04
今日农业(2019年15期)2019-01-03
北京航空航天大学学报(2018年1期)2018-04-20
广西民族大学学报(自然科学版)(2015年3期)2015-12-07
少年科学(2015年8期)2015-08-13
读者·校园版(2015年19期)2015-05-14
