
基于LDA和语步标注的主题识别与分析方法研究
2023-11-08 05:47:02张辉串丽敏郑怀国赵静娟齐世杰
数据与计算发展前沿 2023年5期
张辉,串丽敏,郑怀国,赵静娟,齐世杰
北京市农林科学院数据科学与农业经济研究所,北京 100097
引 言
随着数据科学的不断创新与发展,论文、专利、基金项目等学术研究载体数量迅速增长,内容丰富且深入,在研究内容中蕴含了大量高学术价值的知识,涉及专家学者的研究观点、研究方法、研究成果等重要信息。面对海量学术信息,科技情报工作者、领域科研人员仅凭人工处理这些信息,并主观分析解读这些信息资源,不仅耗时耗力,而且难以全面、准确地识别出研究主题,获取有价值的信息。如何利用新兴信息技术对海量科技信息进行快速有效地主题内容识别,辅助科学知识发现,提高科研工作效率是目前迫切需要解决的关键问题。
主题识别的目的是对大规模的数据信息进行处理和分析,从而快速抽取其中的研究主题,并使用表征词对关键性的信息进行表示[1]。目前国内外学者在主题识别方法上开展了深入研究,主要集中在共词分析和主题模型两个方向。通过构建词语共现网络,利用复杂网络算法识别研究主题;通过机器学习算法挖掘隐藏在文档中的主题表征词信息。现有研究主要通过抽取词汇并计算词汇间关系强度来实现,然而单独使用缺乏上下文语境的词汇作为主题表征词,很难准确揭示主题含义。短语相比词汇更能表达丰富的语义信息,易于理解和分析。因此,从主题表示形式角度出发,构建生成短语结构表征词的主题识别新方法成为迫切需要。
另外,主题识别完成的同时,如何准确地揭示研究主题内容同等重要,而相关研究多侧重于主题识别算法的改进、基于主题词、时间跨度进行主题演化及热点分布等研究,较少针对主题所属的原始文本信息进行细粒度挖掘。文本句子语步结构识别可以从语义角度对内容进行划分类别,能够有效找出表达文本中研究目的、研究方法、研究结果以及研究结论的句子。通过对句子的深入挖掘,将有助于对主题进行语步结构的区块划分,对于揭示文本深层、细粒度的科学知识具有重大意义。
因此,本文基于潜在狄利克雷分布模型(Latent Dirichlet Allocation,LDA)进行主题识别,对LDA 主题识别结果的主题表征词进行扩展,构建表征词短语集合作为候选主题短语,利用Sentence Transformer 预训练模型,对候选短语和主题文本集合进行语义相似度计算,确定主题表征词扩展短语。同时,将主题文本切分成句子集合,通过训练的BERT 分类模型,标注主题句子功能标签(研究背景、研究目标、研究方法、结果、结论),对主题内容功能结构层面进行深度分析。在此基础上,选择农业资源环境领域论文数据进行实证研究,对主题内容进行细粒度、多维度的解读与分析。
1 相关研究
1.1 主题识别
目前,主题识别主要包含基于共词分析法和基于主题模型分析。基于共词分析方法由Callon等[2]提出,利用在同一篇文献中词汇对的共同出现频次,表示词对之间的亲疏关系,进而推断出该语料库中的学科和主题之间的结构关系[1]。众多学者在这方面进行了诸多研究,如郭崇慧、李锋等[3-4]通过统计领域文献中的高频关键词构建共现矩阵,同时结合互信息概念和AP 聚类算法,进行领域主题识别分析;闫涛[5]在基于VSM改进的共现潜在语义向量空间模型(CLSVSM)基础上,引入特征词词频信息,再将引入的词频作为权重赋予CLSVSM 的共现强度,最终构建特征加权的CLSVSM模型,提升文本聚类性能;田鹏伟等[6]通过构建专利文本共现网络,采用OVL 算法及加权运算对异构信息网络进行融合,基于融合后的网络开展专利技术主题识别。丁敬达等[7]在运用共词分析进行主题聚类的基础上,通过Word2Vec 加权向量分别计算文献向量与聚类主题向量,并基于余弦相似度进行文献与主题的语义匹配,实现将相关文献匹配至对应主题。基于主题模型的分析方法用于对文本中潜在的语义关系和主题信息进行挖掘,当下主流方法是潜在狄利克雷分布(Latent DirichletAllocation,LDA)模型,作为非监督机器学习方法,受到学者们广泛关注与使用。如张琴等[8]通过建立频繁短语挖掘算法,设计候选短语重要度计算方法,结合“短语袋”主题模型PhraseLDA 进行主题挖掘。Tajbakhsh 等[9]结合了词语共现提出优化的LDA 模型用于对Twitter 短文本进行聚类;赵林静[10]通过HowNet常识知识库计算输入单词与当前主题聚类中单词间的语义相似度,以此调整LDA 模型中的超参数β,提高聚类准确率;王红斌等[11]基于传统LDA 模型,结合独立性检测、方差检测和信息熵检测3种不同的特征检测方法,识别文本主题内容,解决数据集中不同主题间文本数量不均衡导致文本主题识别不准确问题;张晨晨[12]提出TF-COLDA模型进行主题挖掘,首先通过TF-LDA 特征采样模型进行过滤与主题无关的词得到标准化文档,再利用CO-LDA词共现主题模型提取共现词汇表来构建词共现矩阵,解决语义特征稀疏、共现信息不足的问题。
1.2 语步标注
语步是语言学概念,指实现完整交流功能的一个修辞单位[13],语步的标注可以帮助阅读者有针对性地快速了解写作意图和内容。目前在学术论文语步结构识别方面相关学者开展了研究,如陈果等[14]采用主动学习策略,利用结构化的语步训练数据作为初始语料,训练SVM、CNN、Bi-LSTM 3 种分类器,同时结合少量人工标注训练集,多次迭代优化以识别科技文献句子语步功能结构。王末等[15]采用深度学习中的BERT预训练模型,结合文本句子位置改进模型输入,对学术论文句子进行语步分类。欧石燕等[16]提出的BERT预训练模型与深度森林分类算法相结合的混合模型,充分利用人工识别出的句子位置与结构特征,和深度学习自动识别的文本深层语义特征,取得较好的识别效果;赵旸等[17]对BERT 模型的输入层进行修改,通过融合每个语步句子在该篇摘要中的位置信息以实现摘要中各语步的精准识别;郭航程等[18]提出基于Paragraph-BERTCRF神经网络架构的摘要语步识别模型,能够充分利用摘要文本中的篇章上下文信息,同时考虑了注意力机制和语步标签序列内部的转移关系,实现提升语步功能信息的识别效果。
然而,目前已有研究存在主题识别内容语义信息不足、主题表征词专用短语较少等问题。因此,本文在LDA主题模型基础上,对主题表征词进行语义扩展,构建频繁共现短语作为候选主题表征词,并利用Sentence Transformer预训练模型对表征词主题文本进行语义相似度计算,获取主题表征词扩展短语。同时,引入语步分析法对主题内容进行细粒度挖掘,通过训练BERT语步分类模型,标注主题句子功能,对主题内容进行功能结构层面的理解和分析,以此为主题解读提供新的思路。
2 研究方法
2.1 方法框架
本文提出的基于LDA和语步标注的主题识别与分析方法框架(图1),主要包括两部分内容:
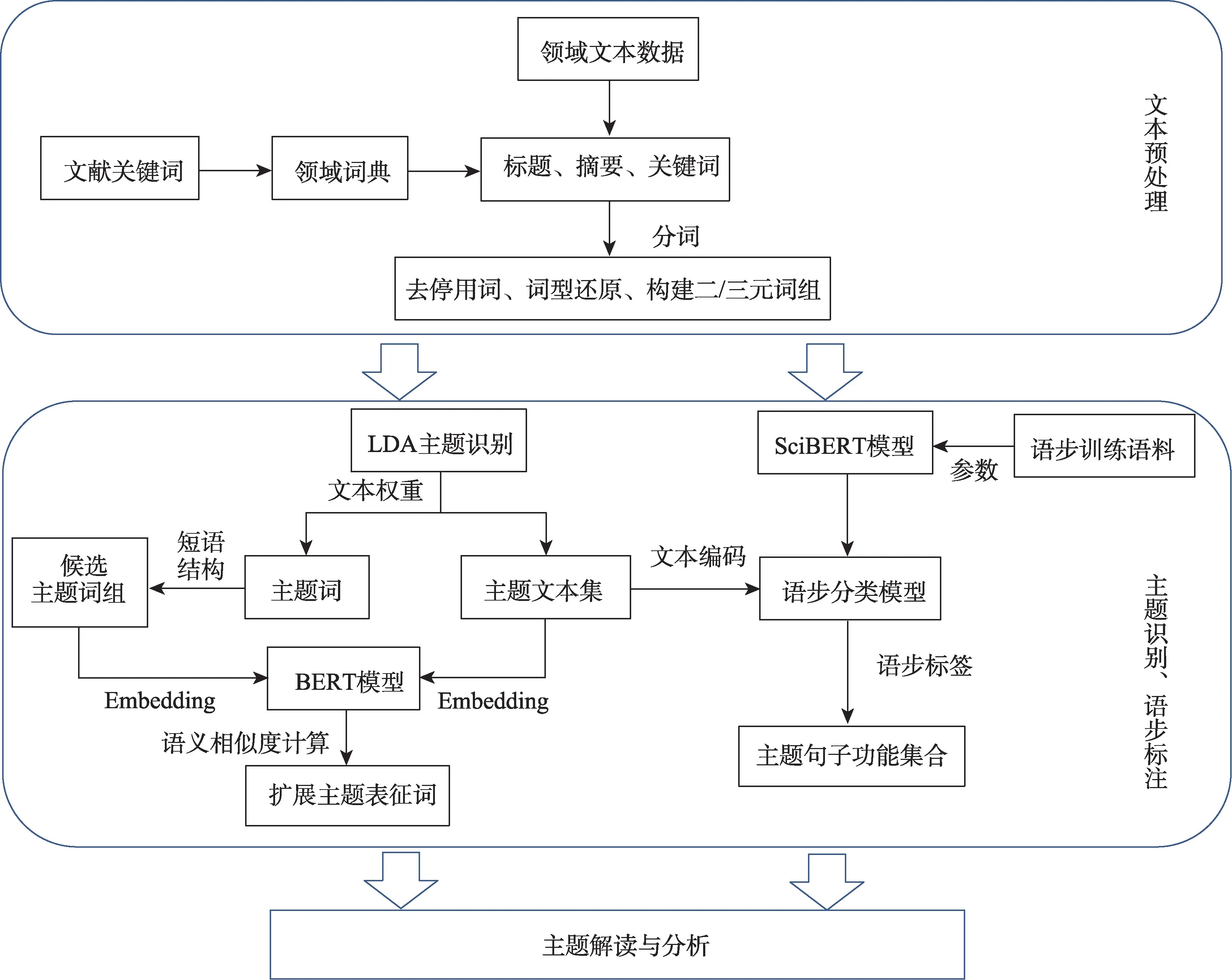
图1 研究框架Fig.1 Research framework
(1)基于LDA 主题识别与主题词短语提取。通过数据预处理,结合文档标题、关键词、摘要3 个维度对文档进行向量表示,生成语料库,并利用Python 中的Gensim 库进行LDA 主题建模,识别主题信息。在此基础上,对主题表征词进行扩展,通过短语结构分析,构建短语集合,并对主题表征词是否出现在短语集合内进行匹配,以提取候选主题短语集合,同时利用Sentence Transformer预训练模型,对候选短语和主题文本集合进行语义相似度计算,得到主题表征词短语,用户根据实际情况选择最佳短语进行解读。
(2)基于SciBERT模型的语步标注。通过构建农业领域的语步训练集,对SciBERT预训练模型进行微调,训练适用新任务的模型。在此基础上,将主题对应的文本以句子为单位进行切分,利用训练好的模型对句子进行功能识别。综合主题内句子功能识别结果,对主题内容进行多维度分析与解读。
2.2 基于LDA主题识别与主题词短语提取
2.2.1 LDA主题识别
主题模型(Topic Model)能够识别文档里的主题,并且挖掘语料里隐藏的信息,在主题聚合、从非结构化文本中提取信息、特征选择等场景有广泛的用途。本文通过LDA 主题模型,将文档-词汇矩阵变成文档-主题矩阵(分布)和主题-词汇矩阵(分布),其实现流程如图2所示:首先,按照概率P(di)选中一篇文档di,从Dirichlet分布α中抽样生成文档di的主题分布θm,从主题分布θm中抽取文档di第j个词的主题Zm,n,从Dirichlet分布β中抽样生成主题Zm,n对应的词分布ψk,最后从词分布ψk中抽样生成词wm,n。
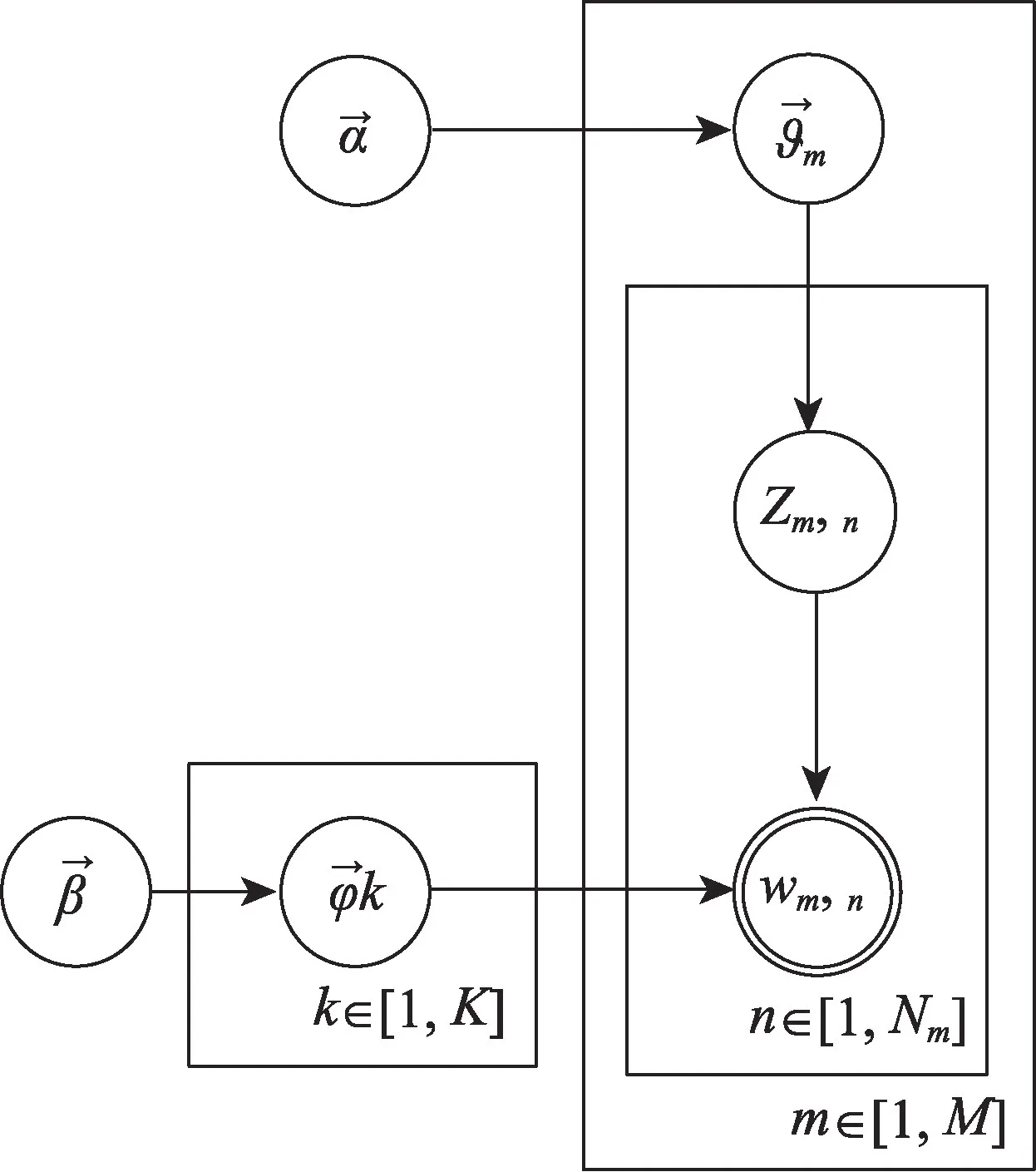
图2 LDA模型概率图Fig.2 LDA model probability diagram
因此,LDA 模型的语料库的生成概率如公式(1)所示,其中,α和β分别是主题分布θ和主题词分布φ的先验分布参数,w和z分别表示模型生成的主题及最终的主题词,K为主题个数,M为总的文档数量。
本文基于Python中主题模型工具库Gemsim进行主题抽取,将每一篇文档文本向量化,转化为词袋(Bag of words,BOW)向量,即构建词频向量输入LDA 模型中。在词袋构建过程中,本文对文档中摘要文本转化的同时,对文档标题和关键词也进行转化,通过实验计算给予三部分文本内容一定权重,以提高文本主题聚类效果。
2.2.2 主题词短语提取
在实际应用过程中,每个主题通过指定数量的主题表征词进行主题内容表达,但主题仅使用单词无法充分描述主题内容,对于非领域内人员无法准确看出特定词组搭配,更无法将它们组成正确短语。因此,本文在构建高质量的主题表征词方面,重点构建以短语为核心的主题词。研究采用Sentence-BERT 网络结构[19],它是对预训练BERT 网络的一种改进,Sentence-BERT 网络的左右两个神经网络在结构完全相同的基础上共享网络权重,以此通过简单、快捷的方法实现对句子、段落等密集向量的表达。
首先,选取适用语义-文本相似度(Semantic Textual Similarity,STS)任务的预训练模型,本文选择paraphrase-distilroberta-base-v2 模型对文本进行表示,其在针对STS 基准数据集上表现优秀,更符合本文需要;其次,构建候选短语,以LDA 主题识别单词作为种子词,结合短语结构搭配对文本进行划分,提取候选短语,实现流程如图3 所示;最后,利用预训练模型将候选短语和文本嵌入到向量空间,使用余弦相似度计算找到与文档最相似的短语,以此描述整个主题内容,实现过程如图4所示。

图3 提取候选词Fig.3 Extract candidate word
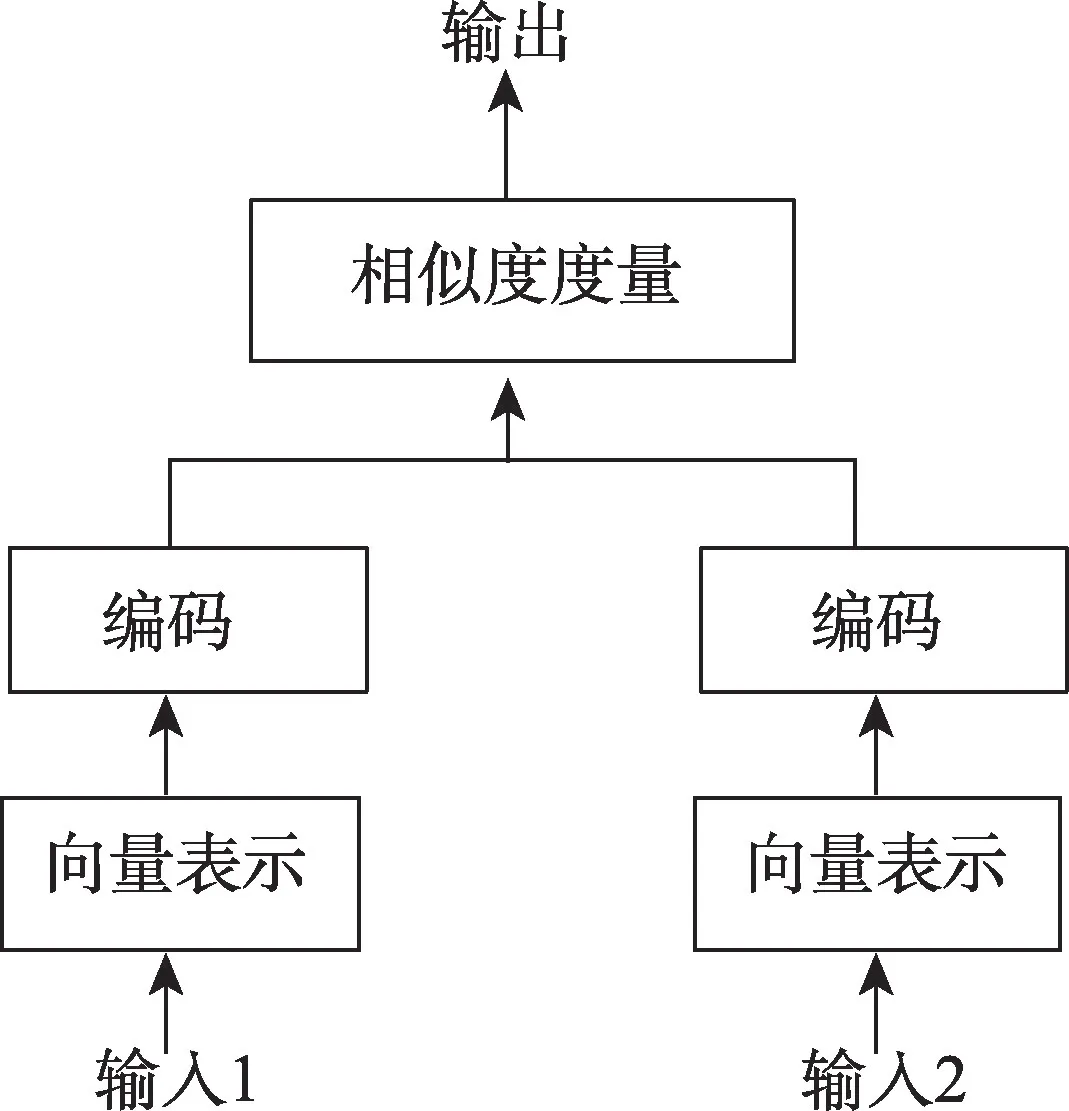
图4 计算主题短语流程Fig.4 Calculate topic phrase flow
提取候选短语。短语生成可利用检索惯例化表达的句法结构进行提取[20]。通过总结归纳,结合句法分析,构建文字搭配结构,生成候选短语。本文选用名词、形容词作为生成短语的单元,通过识别最长的形容词和名词序列,构建候选短语集合。利用NLTK 工具库的pos_tag 方法,对单词的词性进行标记,筛选名词和形容词词性('JJ','JJR','JJS','NN','NNS','NNP','NNPS'),识别短语序列,同时对短语序列进行词频统计、合并同义词、过滤低频词等处理操作,最终确定主题包含的候选短语集合。
计算主题短语。本文文本输入1 为某一主题候选主题短语集中一个短语,输入2为某一主题的全部文本分词、去除停用词后的预处理结果。通过文本表示层将两部分内容映射为词向量,并输入到特征编码层,特征编码层对词向量进行语义特征抽取,相似度计算层对候选主题短语与主题文本向量进行语义相似度计算,最终输出最相似的主题扩展短语TopN,用户根据实际情况确定主题表征短语。
2.2.3 基于SciBERT模型的语步标注
本文将语步标注任务转化为文本分类任务,通过选取预训练模型,构建语步标签的训练集,训练得到文本语步分类模型,以实现对文本内容的语步标注。科技文本摘要的内容高度凝练,具有结构化的撰写模式,通常包含:研究背景(BACKGROUND)、研究目标(OBJECTIVE)、研究方法(METHODS)、结果(RESULTS)、结论(CONCLUSIONS)五类句子,以此描述文本的核心思想。本文采用SciBERT 预训练模型[21]进行训练学习,标注上述五类语步结构。SciBERT是利用大型科学出版物语料库[包括生物医学(82%)以及计算机科学(18%)方向总共114万篇论文样本]进行无监督预训练的BERT 模型,因此,更加适用于科技文本数据的自然语言处理任务。
构建训练数据集。训练数据的特性和数量是决定一个模型性能好坏的最主要因素。本文重点针对农业领域科技文本进行主题分析,现有公开数据集未涉及农业领域,因此,首先构建农业领域语步标注训练数据集,再对预训练模型进行微调,该模型将更适应农业领域文本标注任务。为保证语步标注训练数据的准确性和权威性,本文以WOS(Web of Science)数据库中的结构化摘要论文作为语料来源,利用语步标签词语作为检索词,通过检索筛选研究方向为农业领域的文献进行数据导出,利用Python语言编写处理程序对论文摘要进行清洗,识别语步标签并提取标签后对应的句子,最终形成农业领域语步标注训练数据集。
训练语步分类模型。本文利用Pytorch深度学习框架,选取SciBERT 中推荐的scibert-scivocab-uncased 预训练模型进行语步识别任务训练。首先对输入的语步标签、句子文本进行编码,转为模型需要的编码格式,使用辅助标记符[CLS]和[SEP]来表示句子的开始和分隔。然后根据输入得到对应的embedding,在得到整体的embedding 后使用模型进行学习,最终根据本任务的分类层得到语步标注结果。对模型微调时训练参数如表1 所示,模型微调实现原理如图5所示。
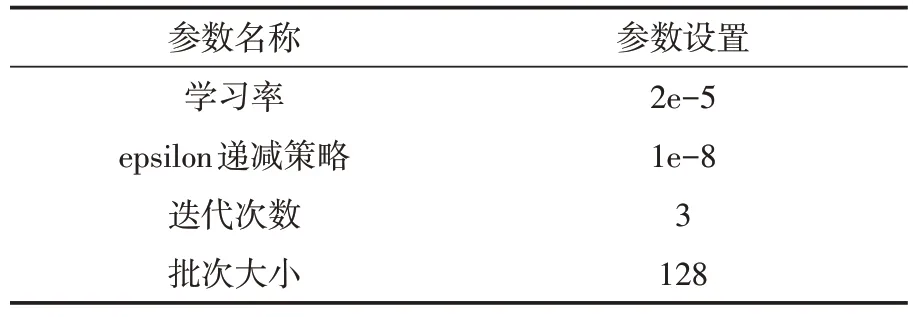
表1 SciBERT训练参数设置Table 1 SciBERT training parameter setting
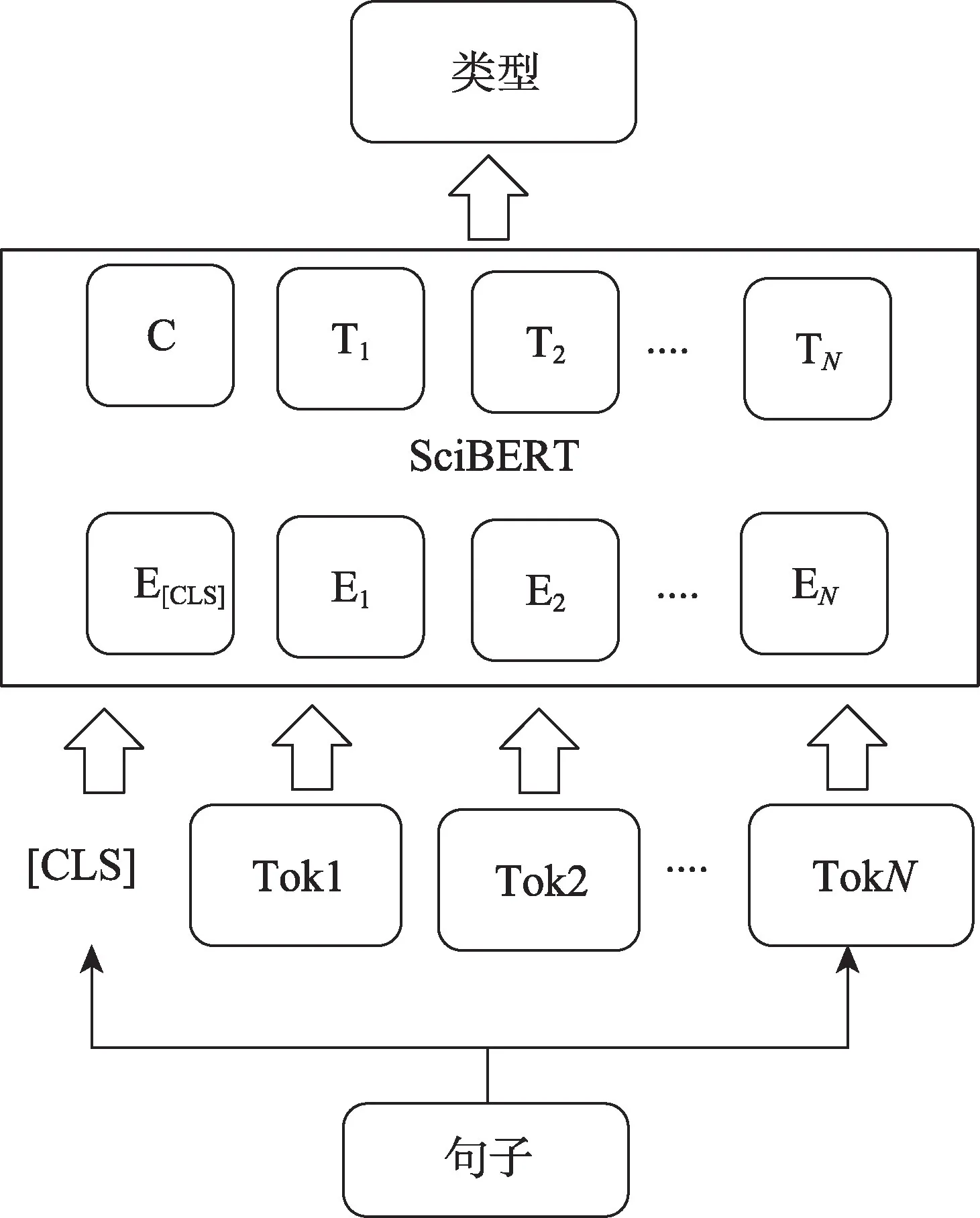
图5 模型微调实现原理Fig.5 Implementation principle of model fine tuning
3 实验步骤与结果分析
3.1 实验数据
本文的实证研究对象为农业资源环境领域论文数据,以Incites 数据库为基础,Incites 是基于30 年来WOS 核心合集七大引文数据库建立的科研评估与分析数据库,拥有更加全面的数据资源、多元化的指标和丰富的可视化效果。从Incites数据库研究方向中选择“中国国务院学位委员会学科分类(China SCADC Subject 97 Narrow)”,再选择“农业资源与环境(0903 Agricultural Resources and Environment Science)”一级学科,提取2020 年该领域的论文数据,检索时间为2021年9月24日。共检索到5,882篇文章。导出文献全部信息,经过核查、补充不完整信息等处理,选择标题、摘要、关键词三部分文本信息进行主题识别。
3.2 数据预处理
(1)构建领域词典。利用自定义分词字典进行文本分词,有助于提高切分词语的准确率。本文挑选WOS 数据库中农业领域期刊,提取近5年发表论文的作者关键词(Author Keywords),以及补充关键词(Keywords Plus),通过数据清洗,过滤无意义词语,最终确定91万条领域词语。
(2)文本处理。首先采用NLTK、Spacy 等自然语言处理工具库对文本内容进行分词、去停用词、词型还原、词性标注。同时,在文本向量表示过程中,通过压缩词向量,降低高频词和低频词对主题识别影响,最后提取分词结果用于LDA主题识别。
3.3 LDA主题识别
(1)主题数量确定。本研究采用困惑度(Perplexity)指标确定最优主题个数。困惑度表示文档所属主题的不确定性,当困惑度下降趋势不再明显或处于拐点处时,此时主题取值为最优主题数。计算公式如公式(2)所示:
其中,D代表测试数据集;M代表文档数量;wd代表构成文档集合D的单词集合;Nd表示第d个文档中出现的词语总数。
本文初始设定主题数10 个,通过实验结果可以看出当主题数量为4~6 时,困惑度值趋于平缓,如图6所示。因此,结合领域专家研判,最终确定本研究论文数据主题数量为4最佳。
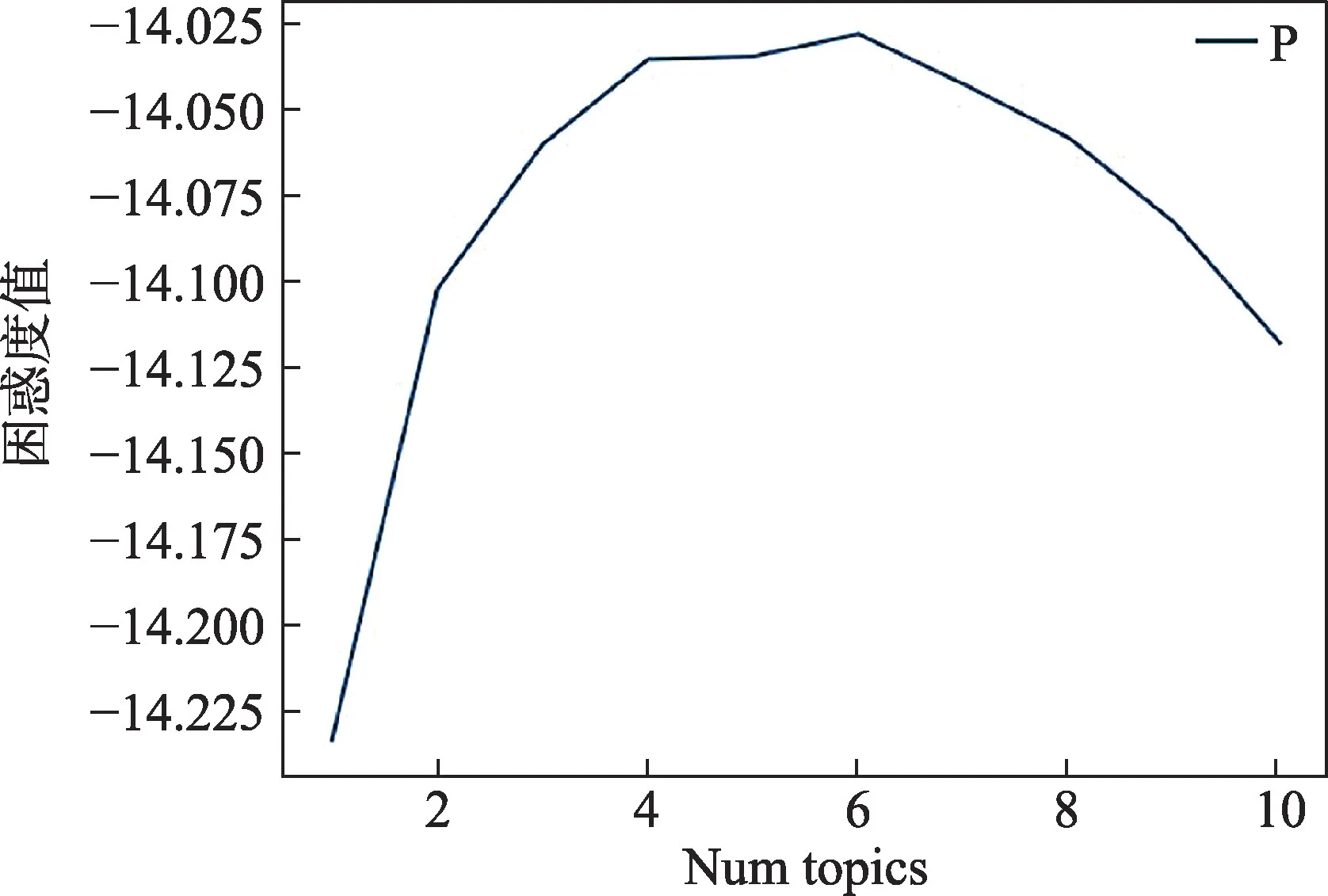
图6 困惑度计算Fig.6 Confusion calculation
(2)主题识别结果。基于语料分词结果构造字典和词袋,并对词袋向量进行压缩,减少高频词和低频次对主题识别的影响,包括去掉出现在全部语料中频次小于2的词,以及在50%的文档都出现的词语,经过筛选后的语料输入LDA 模型。本文LDA主题模型参数设置为:主题个数4个,迭代次数1,000 次,输出主题词个数10 个。LDA主题识别结果如表2所示。

表2 主题识别结果Table 2 Subject identification results
3.4 主题表征词扩展
基于LDA 输出的主题表征词进行扩展,通过查找包含主题词短语作为候选短语,统计词频排序并设置阈值,频率低于5次的短语将会被剔除,以降低对核心短语提取影响。在计算候选短语与主题相似度过程中,选取计算结果排名前3的短语作为扩展短语,并根据实际主题内容经过专家筛选,最终确定主题表征短语。选取其中一个主题扩展短语进行展示与对比,如表3 所示。通过对扩展结果的阅读理解,可以更为准确地确定主题、了解主题涵盖内容等。
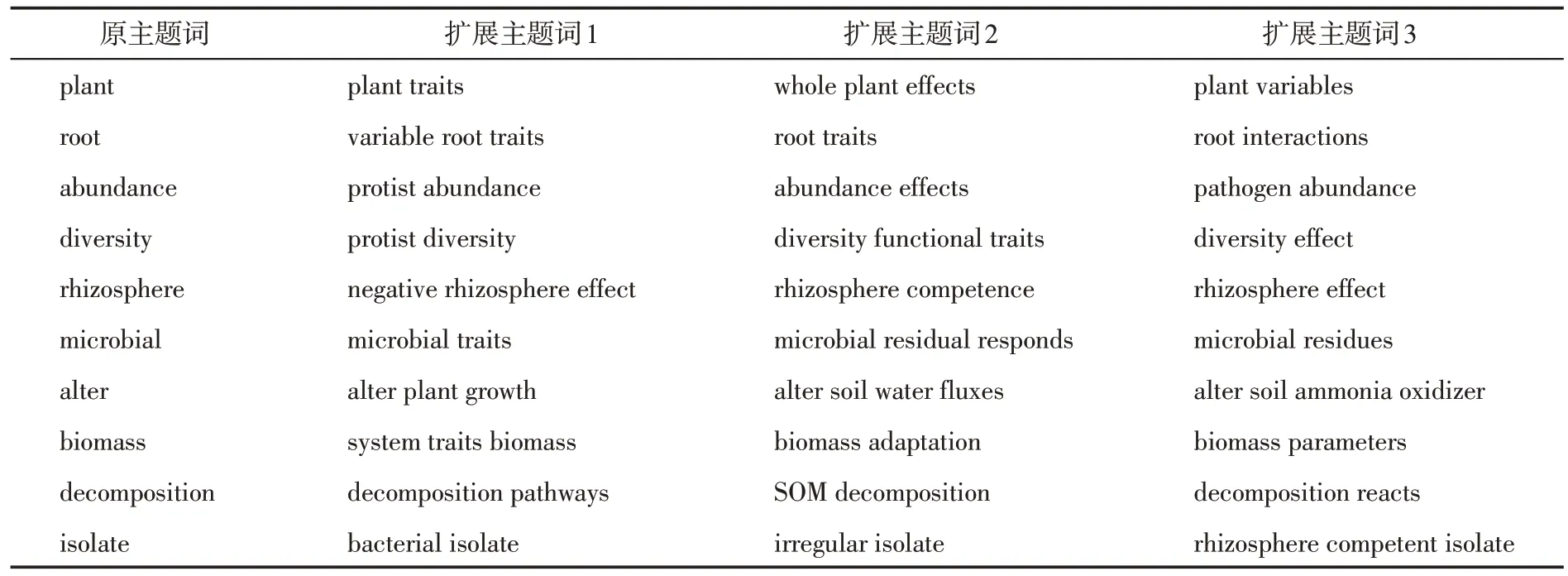
表3 主题短语扩展结果Table 3 Subject phrase extension results
3.5 主题句子语步标注
通过对训练数据集的清洗与筛选,共获得句子标注语料为160,361 条,其中研究背景32,130条、研究目标10,018条、研究方法38,602条、结果53,739条、结论25,872条。利用训练数据进行语步模型训练,最终得到训练结果如表4所示。从训练结果看,研究方法、结果、结论3个功能标签识别效果较好,准确率在80%以上,研究目标识别效果不理想,只有66%,还有待提升。从整体识别效果看,加权平均各个标签的F1值,最终模型识别效果F1值为81.9%。
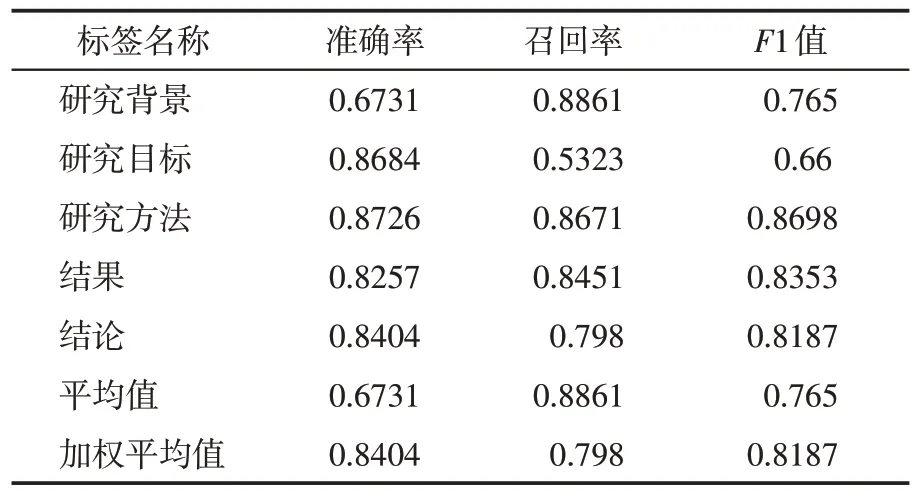
表4 SciBERT语步分类训练结果Table 4 SciBERT move classification training results
利用模型训练结果,对各主题文本进行语步标注,实验标注结果示例如表5所示。通过标注结果可以看出,模型实际应用效果较好,但也存在研究背景、研究目标等句子被标注错误的现象。

表5 SciBERT语步分类标注结果Table 5 SciBERT move classification annotation results
3.6 语步标注方法对比
在相同数据集上,使用原始SciBERT模型与改进预训练模型进行对比实验,实验结果如表6所示。与原始SciBERT模型相比,本语步标注方法由于构建了农业领域的训练集,整体表现具有更佳效果,平均准确率、召回率、F1 值分别提高5.7%、2.7%、4.7%。
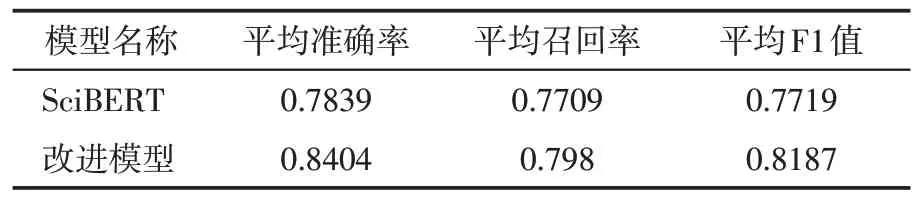
表6 语步标注结果对比Table 6 Comparison of move tagging results
3.7 主题内容分析
基于主题识别与主题句子语步结果进行主题内容分析,将从以下两方面进行解读:
3.7.1 主题挖掘
通过LDA主题识别结果(表2),结合主题表征词扩展结果(表3),经过人工筛选,最终确定农业资源环境研究主题内容(表7)。通过阅读分析,发现2020 年农业资源环境相关论文研究方向主要集中在4 个主题:主题0 主要研究作物根际与微生物多样性,如有机微生物分解、微生物多样性、根际微生物对作物生长的影响;主题1主要研究土壤退化模拟与评估,如土壤退化模型应用与评估、土壤退化相关理化性状、数字土壤制图等;主题2 主要研究生物炭施用及效应,如生物炭投入对作物产量、氮素利用效率、土壤肥力、重金属元素有效性的影响等研究;主题3 主要涉及土壤质量提升研究,如采取不同耕作措施、不同填闲作物覆盖等对土壤理化性质的影响,以提升土壤质量。

表7 主题表征词结果Table 7 Topic representation results
3.7.2 主题内语步分析
对主题内文本语步结构进行标注和梳理,综合各类语步结构进行解读分析。
主题0:主要研究作物根际与微生物多样性,如有机微生物分解、微生物多样性、作物生长影响。
微生物群落功能多样性是土壤质量变化重要的指标,可综合反映土壤肥力和环境质量状况。有学者为充分了解植物-微生物-土壤三者之间相互作用,研究了不同植物种类在生长、产量、抗病等方面的影响因素,采用(CO2)-C-13 连续标记番茄菌根野生型祖细胞(MYC)及其菌根缺陷突变体(减少菌根定殖:RMC),以追踪土壤中的根C 输入,并量化受AMF 共生和氮肥影响的根际启动效应(RPE);还有研究人员分别利用16S rRNA 为基础的高通量测序技术(HTS)和微孔箱(MWCs)原位培养技术,探索与小麦根际相关的可培养的根际细菌群落多样性;或利用从森林、大豆和番茄土壤中分离的不同微生物菌剂进行微生物移植试验,测定它们对灭菌番茄土壤中番茄植株生物量和养分同化的影响。学者们通过众多方法试验发现了影响根际微生物群落的组成、数量和多样性等的诸多因素;也提出根际微生物具有培肥地力、病原生物防治等作用,同时可改善植物对营养元素的吸收,促进植物生长发育。
主题1:主要研究土壤退化模拟与评估,如土壤退化模型评估、土壤理化性状、数字土壤制图等。
土壤是自然环境的重要组成部分,也是最重要的自然资源之一,土壤退化在全球是一个普遍存在的问题,导致可利用的耕地、草地、林地等不断减少,因此,如何解决土壤退化问题引起了广泛关注。研究者们采用CNN 深度学习模型、LANDPLANER模型、WetSpass模型、SWAT模型等众多模型进行土壤理化性状分析与预测、土壤退化模型构建研究,并评估各类因素对土壤侵蚀的影响;另有研究者基于已有土壤数据,利用沙普利加和解释(SHAP)值、重采样分类树(DSMART)、随机森林模型与综合采样策略相结合等方法,识别和绘制数字土壤制图(DSM),作为高质量的土壤基准信息。并且,研究人员通过实验与评估,发现未来气候变化可能是增加土壤侵蚀风险的主要驱动因素。因此,研究人员提出今后几年迫切需要加强水土保持研究和管理;将退化的土地和裸地进行重新造林、等高线耕作和农田平行梯田相结合,可实现最大程度的减少土壤退化;开展的模型构建可准确预测土壤性状,评估对土壤侵蚀的影响,以提高农产品质量和减少土壤退化等负面环境影响及相关风险;可以在没有收集土壤信息的地区,构建准确度较高的土壤特性单元图,记录土壤性状和空间分布,对区域内外的农业和环境资源进行有效管理与研究。
主题2:主要研究生物炭施用及效应,如生物炭投入对作物产量效应、氮素利用效应、土壤肥力、重金属元素有效性等研究。
生物炭作为一种土壤改良剂,可以影响土壤的物理、化学和生物性质。近年来,研究人员在改善土壤肥力、土壤有机碳和作物产量,提高氮素利用效率,修复受重金属污染的土壤等方面开展了深入研究。将生物炭与其他有机改良剂联合应用、与控释尿素与普通尿素相结合以及与不同有机肥料及其组合相结合,研究其对土壤性质改良、土壤肥力提高、作物产量增加的效果。也有学者研究了连续施用石灰、铝改性生物炭、稻壳生物炭、70%无机肥和30%有机肥的比例联合施用等方法,对土壤中镉、铜、铝、锌、镍、砷等金属元素污染修复作用。有研究结果显示,污泥衍生生物炭可以提高氮的利用效率;尿素与控释尿素的混合比为3:7搭配时,可有效减少氮肥施用;家禽粪便和生物炭的联合施用、生物炭和其他有机改良剂的联合应用是改良酸性土壤和提高土壤肥力的有效策略;酸性镉污染稻田可以通过连续施用适量的石灰来实现水稻的安全生产;铝改性生物炭可以有效将金属砷(尤其是铝)固定在酸性土壤中;稻壳生物炭在降低镍生物有效性方面最为有效;以70%无机肥和30%有机肥的比例联合施用,可能是重金属污染风险最小的前提下作物高产的较好策略。
主题3:主要研究土壤质量提升,如耕作措施、理化性质、覆盖作物等对土壤质量提升效果。
土壤质量是土壤提供生态系统功能和服务的能力,其在农业生态系统健康可持续发展方面起着至关重要的作用。随着土壤退化问题日趋严重,了解土壤质量下降影响因素、掌握土壤管理策略,对土壤质量提升具有重要意义。通过长期试验,研究人员评估了免耕、常规耕作、作物轮作、秸秆还田等耕作措施对土壤有机碳的矿化和积累特征的影响;研究多种覆盖作物对提高土壤有机碳储量影响;研究疏水物质和孔结构土壤憎水性、土壤水力特性和土壤孔隙系统结构等因素对土壤参数的影响。结果表明,常规耕作和免耕耕作制度下多样化作物轮作提高了土壤物理和水文特性;作物轮作和冬季覆盖作物的种植制度有可能提高土壤有机碳、孔隙特征以及相关的物理和水文特性;长期保护性耕作提高了土壤有机碳储量,减少了碳损失,从而对土壤健康和可持续性产生了积极影响;与耕作处理相比,免耕增强了土壤有机碳和土壤易氧化有机碳的积累和宏观聚集,覆盖种植和复合种植进一步提高了土壤有机碳的积累;适当的深层土壤扰动在激活大团聚体和封闭微团聚体中更多的碳固存方面具有巨大潜力,对制定土壤管理策略具有重要意义。
4 结论与展望
本文提出基于LDA和语步标注的主题识别与分析方法,在LDA主题模型基础上,通过短语结构分析和深度学习Sentence Transformer 预训练模型对主题表征词进行语义扩展,获取主题表征词扩展短语,提高了主题解读性。同时,引入语步分析法,通过构建领域语步训练数据集,基于SciBERT 预训练模型,训练语步标注模型,并对主题结果进行句子功能标注,提高了主题内容在功能结构层面的理解与分析。在实证分析中,本研究相比传统主题识别与分析方法,更易于主题内容的解读和细粒度分析,证明了研究方法的合理性。
本文为主题内容解读提供了新思路,但还需要进一步研究。首先,目前实验数据为文献数据,文本内容描述相对统一规范,因此实验结果较好,后续还需在其他文本类型(比如基金项目、专利等)进行实证分析。其次,扩展的主题短语存在含义相同问题,有待针对表征词的多样性方面进一步改进。最后,语步功能识别特别是针对研究背景、研究目标等标签的识别,准确率方面有待进一步提升。
利益冲突声明
所有作者声明不存在利益冲突关系。
猜你喜欢
开封文化艺术职业学院学报(2021年1期)2021-01-02 22:02:23
制造技术与机床(2019年10期)2019-10-26 02:48:08
电子制作(2018年18期)2018-11-14 01:48:06
厦门理工学院学报(2016年6期)2016-02-06 08:57:34
小学教学参考(2015年20期)2016-01-15 08:44:38
黑龙江工业学院学报(综合版)(2015年10期)2015-12-13 13:08:38
语文知识(2014年1期)2014-02-28 21:59:13
外语学刊(2011年3期)2011-01-22 03:42:17
