
适用于方面级情感分析的多级数据增强方法
2023-11-08 05:47:10张蓉刘渊
数据与计算发展前沿 2023年5期
张蓉, 刘渊
1.江苏信息职业技术学院,物联网工程学院,江苏 无锡 214153
2.江南大学,人工智能与计算机学院,江苏 无锡 214122
引 言
方面级情感分析(Aspect-based Sentiment Analysis,ABSA)[1]旨在确定产品评论等在线情感文本中出现的一个或多个方面的情感极性。例如,评论“I charge it at night and skip taking the cord with me because of the good battery life.”中的两个方面:“cord”为中性(neutral),“battery life”为积极(positive)。ABSA与句子级或篇章级的情感分析任务相比,能够更好地洞察用户评论,是一种细粒度的情感分析任务,在个性化推荐等应用中发挥着重要作用。
在文本情感分析领域,基于BERT[2]等大模型的预训练语言模型(Pre-trained language Models,PLM)+任务微调(Fine-tuning)训练范式已成为主流,并在GLUE 基准测试[3]上取得了最先进的性能。这种训练范式先在大规模无监督数据上进行预训练,然后在下游任务上进行有监督的微调。下游任务中用于微调的训练数据的质量和数量决定了实验效果的好坏[4]。实际应用中获取大量的标注数据往往因为代价高昂而变得不切实际[5]。小样本问题在ABSA 任务中尤为突出,以当下最受欢迎的ABSA 基准数据集SemEval 2014 Task 4 Sub Task 2[6]为例,该数据集包含2 个数据集:餐厅(简称Rest)和笔记本电脑(简称Laptop),其中Laptop 数据集共包含3,045 条评论,而可用于训练的含有方面词的句子仅为1,462 条,占比47.75%(见第4 节所示)。由此可见,ABSA 任务是典型的Few-shot 场景,而人为注释错误和噪声等问题加剧了这个问题,使得ABSA 任务依然是传统情绪分析中的一个具有挑战性的子任务[7]。
数据增强(Data Augmentation,DA)是一种缓解数据不足的有效技术,已经被图像处理、自然语言处理等领域用于增强现有的标记数据和提升深度网络性能[4]。然而,由于自然语言具有离散性、复杂性和抗干扰能力较差等特性,使得通用数据增强技术在NLP 中的应用更加困难[8-9]。Longpre等[10]通过实验证实,一些流行的DA技术(如EDA[11],反向翻译[12])并不能持续提高基于Transformers 预训练模型的文本分类任务的性能,有些情况下还会减弱其性能。另外,这些DA技术大都采取对整句中的任意单词进行替换、删除等操作,可控性较弱。例如,EDA 方法中对整个文本执行随机替换、交换或者删除操作,有可能改变文本标签、丢失方面词或者关键情感信息。
鉴于此,本文通过探索最常用的同义词替换数据增强方法,将其适应到细粒度的ABSA任务中,只运用于评论中的“方面词”替换,以解决小样本问题。主要贡献有:(1)利用ABSA 任务的特点,针对方面词设计多种级别的数据增强(Multi-Level Data Augmentation, MLDA)策略,既设置了合理范围的噪声,又确保了重要信息不丢失从而保持标签不变性,分别在基于注意力机制+预训练模型和基于依赖树+预训练模型上进行测试,结果表明,MLDA 策略能够有效解决ABSA 训练数据的稀缺性问题;(2)将MLDA 用于正样本对构建、设计对比学习训练框架,与原有训练模型进行多任务学习,提升ABSA任务性能;(3)首次提出类别领域级同类词替换方案并获得成功。
1 相关工作
1.1 方面级情感分析任务
ABSA 任务需要关注每个具体方面的细微观点,它的核心任务是将各个方面与其相应的潜在意见词建立情绪依赖联系[13],意见词通常是一个具有明确情绪极性的表达。现有流行的ABSA 任务解决方案可分为基于经典注意力机制、基于依赖树、基于预训练模型或者是这3种方法的混合来达成目标。例如,Wang 等[14]提出一种基于注意力的LSTM网络用于方面级情绪分类,针对不同的方面,该模型通过注意力机制可以生成特定于方面的句子表征。但是RNN 模型难以并行化,并且通过时间截断反向传播给长期模式记忆带来了困难。为解决这个问题,Song等[15]提出了一种注意力编码器网络(AEN),将预训练过的BERT 应用于ABSA 任务,有效避免了重复,并使用基于注意力的编码器在上下文和目标之间进行建模。最近的研究更多关注采用图神经网络(GNN)结合依赖树的解决方案。这些研究使用图卷积网络(GCN)来建模目标词与其上下文词之间的语义情绪依赖关系,从而实现了很好的性能表现。例如,Huang 等[16]使用图注意力网络(GAT)明确地建立了单词之间的相关性,句子中的单词用Glove[17]或BERT初始化后,根据单词之间的依存关系构建图神经网络,之后使用GAT与LSTM显示地捕捉与方面相关的信息,然后利用这些信息完成ABSA 任务。不同于其他研究者直接编码现成的依赖树,Wang 等[13]通过重塑与修剪普通的依赖树将方面作为依赖树的根节点,并提出一个关系图注意力网络(R-GAT)对新的依赖树进行编码,用于ABSA任务。这些工作能够很好地建模方面与意见词之间的依赖关系,但还存在因训练数据不足而导致模型对关键性信息学习不足等问题。
1.2 数据增强技术
数据增强是指在数据不足的场景中,通过对现有数据进行轻微的修改而生成合成数据的方法[18]。如果使用得当,它能够提升训练样本的多样性,提高训练数据集的规模和质量,这样就可以使用这些数据建立更好的深度学习模型,因而DA是近年来广受关注与研究的一种解决数据稀缺问题的技术。Li 等[19]根据增强数据的多样性将NLP中DA方法分为:释义、噪声和抽样。如表1(见引言所示),这3 种类别依次提供了更多的多样性,进而带来不同的增强效应。

表1 常见数据增强技术及在评论中的示例Table 1 Common data augmentation techniques and examples in reviews
文本分类是NLP 中应用DA 最早和最广泛的任务。具体实现时,只要保留对文本分类很重要的单词语义,以确保新生成文本的标签与原始文本相同。替换法是最常见的数据增加方法之一,因为可以生成与原始句子相似的例子,相当于添加噪声数据以防止模型过拟合。接下来重点讨论的是基于不同策略的替换方法在文本分类任务中的应用。基于近义词替换和基于词向量替换是其中最简单和最流行的两种替换方法。例如,被广泛使用的EDA 方法[11]通过引入WordNet[20]近义词词典,采用随机机制对文本执行替换、插入、交换或删除等操作来扩展原始句子。但是,这种随机的方式可能会生成不可靠和不受控制的数据[21]。基于词向量的替换方法则使用预训练的词向量,如Glove[17]、Word2Vec[22]等,将原始单词替换为向量空间中最接近的单词。与近义词替换方法比,这种替换方法提供了更高的词汇覆盖率。例如,Liu 等[23]在邮件多主题情绪分类任务中结合了基于近义词表和词向量的单词替换方法。首先,基于Glove 词向量的相似度,为词表中的每个单词建立其最相关单词的字典。然后,根据WordNet对这个字典进行修正或补充。最后,对句子中每个单词按照一定概率替换为它的近义词,以此增加文档级电子邮件数据集。Wang等[24]同时对Twitter文本进行单词级和框架级的替换,对每个原始单词使用余弦相似度查找到KNN 单词替换,通过使用Word2Vec构建一个连续的框架袋模型来表示每个语义,然后使用相同的数据增强方法创建具有这些语义框架嵌入的其他实例。无论是基于近义词词典还是词向量的DA方法,当一个句子的替换次数过多时,都有可能损害句子的语义。
以上这些替换策略都能够很好适用于篇章级或句子级等粗粒度的文本分类任务,然而如果将这些策略直接应用于细粒度的ABSA 任务显然是不合适的。例如,如果在随机操作中删除、替换或者交换的是方面词本身,就会破坏ABSA任务的目标。基于此,本文提出的MLDA 方法只引入了简单的操作,在不改变情感极性的前提下针对各个方面执行句子、类别领域、词向量3个级别上的替换,由于生成的样本保持了原始样本中最重要的部分,因此可以保持标签不变。同时,MLDA 一个显著的特点是实现起来相当友好,通过不同单词空间的变化来丰富增强的数据,有效提高了模型的鲁棒性。
2 多级数据增强方法
受第1 节中相关工作的启发,本文为ABSA任务设计了只针对方面词进行替换的多级数据增强方法,其工作原理如图1所示。需要说明的是,考虑到过多的替换有可能影响模型性能,所以对替换的方面词做了限制,仅对由单个单词构成的方面进行替换,而对由多个单词构成的方面则不予以考虑。在这样的限制下,对于评论“Drivers updated ok but the BIOS update froze the system up and the computer shut down.”中的3 个方面词“Drivers”“BIOS update”“system”,仅对方面词“Drivers”和“system”执行3种级别的替换。
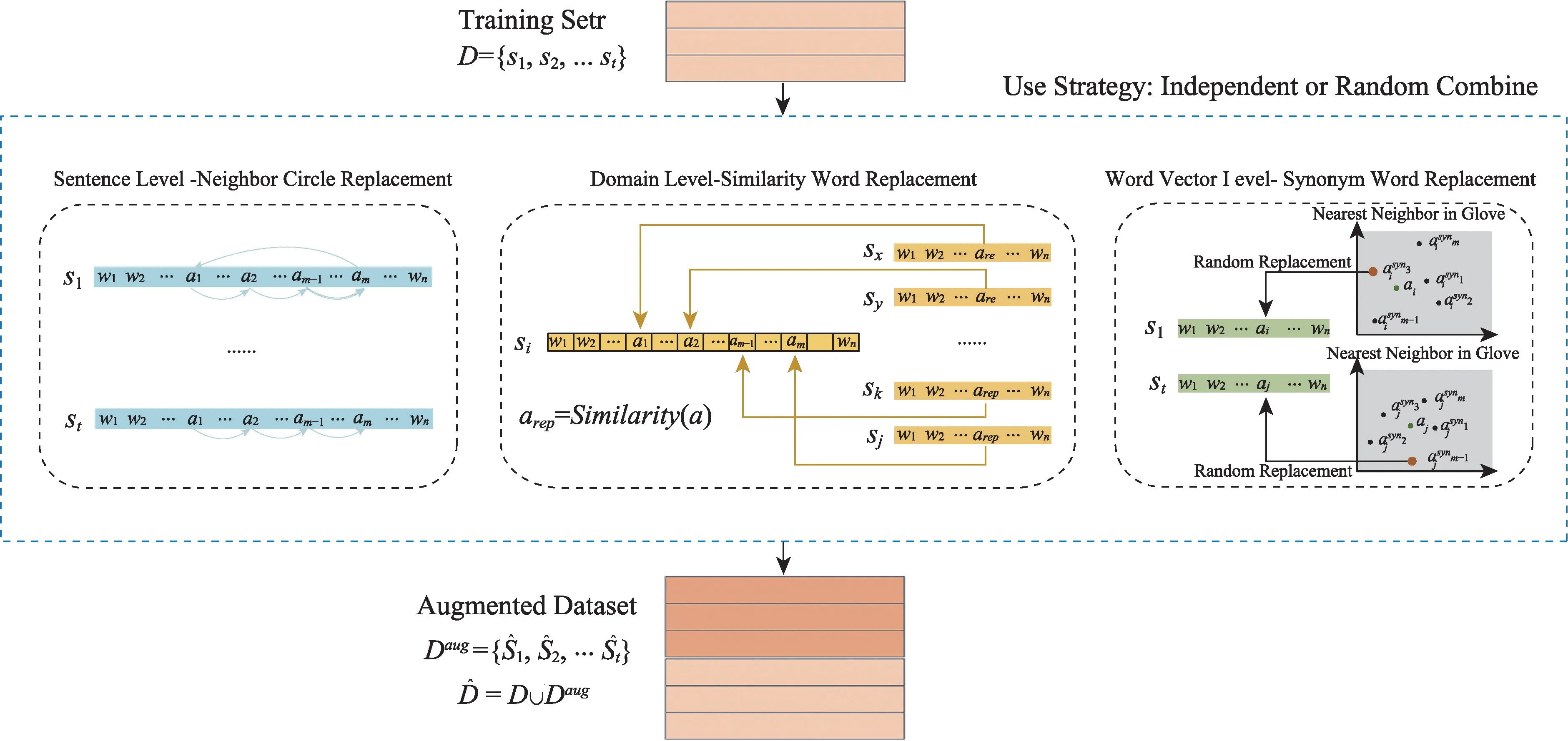
图1 多级数据增强方法工作原理图Fig.1 Work principle of Multi-Level Data Augmentation
MLDA 方法仅针对一个评论中特定几个目标方面进行句子级相邻词、领域级同类词和词向量级同义词替换,既保证了标签不变性,又达到了样本层次多样性。其中词向量级同义词替换是被广泛采用的替换策略,这里并没有对评论中所有单词执行随机抽取式的同义词替换,而是仅针对方面词执行。对于句子级相邻词替换策略,灵感来源于日常人类情绪表达的经验,在特定的场景下,用户围绕特定产品主题(餐厅或者笔记本电脑)开展评论,这些方面词尽管可能不是同义词、甚至也不是同类词(如“steak”和“decorate”),但是属于同一语境下、同一领域内、围绕同一产品主题的相关词,即使存在一些语义上的偏离,仍不失为合理范围,这种偏离反而会给模型带来适度的挑战。因此,该策略不仅可以增加训练数据的数量,也可以很好地提高模型的鲁棒性。而对于领域级同类词替换的灵感则来源于近年来在ABSA领域比较热门的关于方面情绪四元预测(Aspect Sentiment Quad Prediction,ASQP)研究课题的启发,这是旨在从评论句子中提取方面四联体的任务,四联体由4 个情感元素组成:方面类别、方面术语、意见术语和情绪极性。这里的方面类别即表示方面词的类别,如“sushi”“Ravioli”“pizza”等方面词都属于“food quality”方面类别[25]。
2.1 句子级相邻循环替换
句子级相邻循环替换(Sentence Level-Neighbor Circle Replacement, SL-NCR):对于训练集Dtr中给定的一个句子s={w1,w2,...,wn},n为句子的长度,设其由单个单词组成的方面集合为A={a1,a2,...am} ,m≥2 。那么SLNCR 操作如算法1 所示。
算法1 SL-NCR

Algorithm 1:SL-NCR Input: Dtr:training set with tsamples.alpha:random sampling factor.Output: Daug SL-NRR:augmented set.1D'tr←Random.sample(Dtr,t×alpha)//根据随机抽样因子抽取待增强样本2 for s∈D'tr//依次遍历抽取的评论3 do 4 if m=2:5saug←Swap(a1,am) //交换6 Append(DaugSL-NRR,saug) //生成新句7 else do:8 a1 ←am9 for i∈{1,…,m-1}10 do 11ai+1 ←ai//执行右循环替换12 Append(Daug SL-NRR,saug)13 end 14 end 15 end 16 end
最终形成一个向右循环替换的闭环,如图2(a)所示。图2(b)为基于SL-NCR 得到的新样本。

图2 应用SL-NCR 生成新样本示意图Fig.2 Schematic diagram of applying SL-NCR to generate new samples
这里选择相邻词循环替换法而不是随机替换法,主要考虑到用户通常会在发表评论时倾向于根据极性对各方面进行局部聚类,这就意味着相邻的方面词有可能会受到情绪一致性的影响[25]。选择相邻词循环替换策略既可以最大概率保持相邻词替换后的情绪极性不变。
2.2 领域级同类词替换
领域级同类词替换(Domain Level-Similarity Word Replacement, DL-SWR),是在不改变标签的情况下在各个方面的类别领域内实现同类词替换。无论是Rest 数据集还是Laptop数据集,数据集内部的评论都是围绕着各自主题领域的,各个方面词拥有共同的领域特性。观察图3和图4 可以发现,Rest 数据集中的各个方面围绕着餐厅主题领域可以划分为食品、人员、环境、服务等类别,Laptop 数据集中的各个方面围绕着笔记本电脑可以细分为部件、应用、性能、外观等类别。
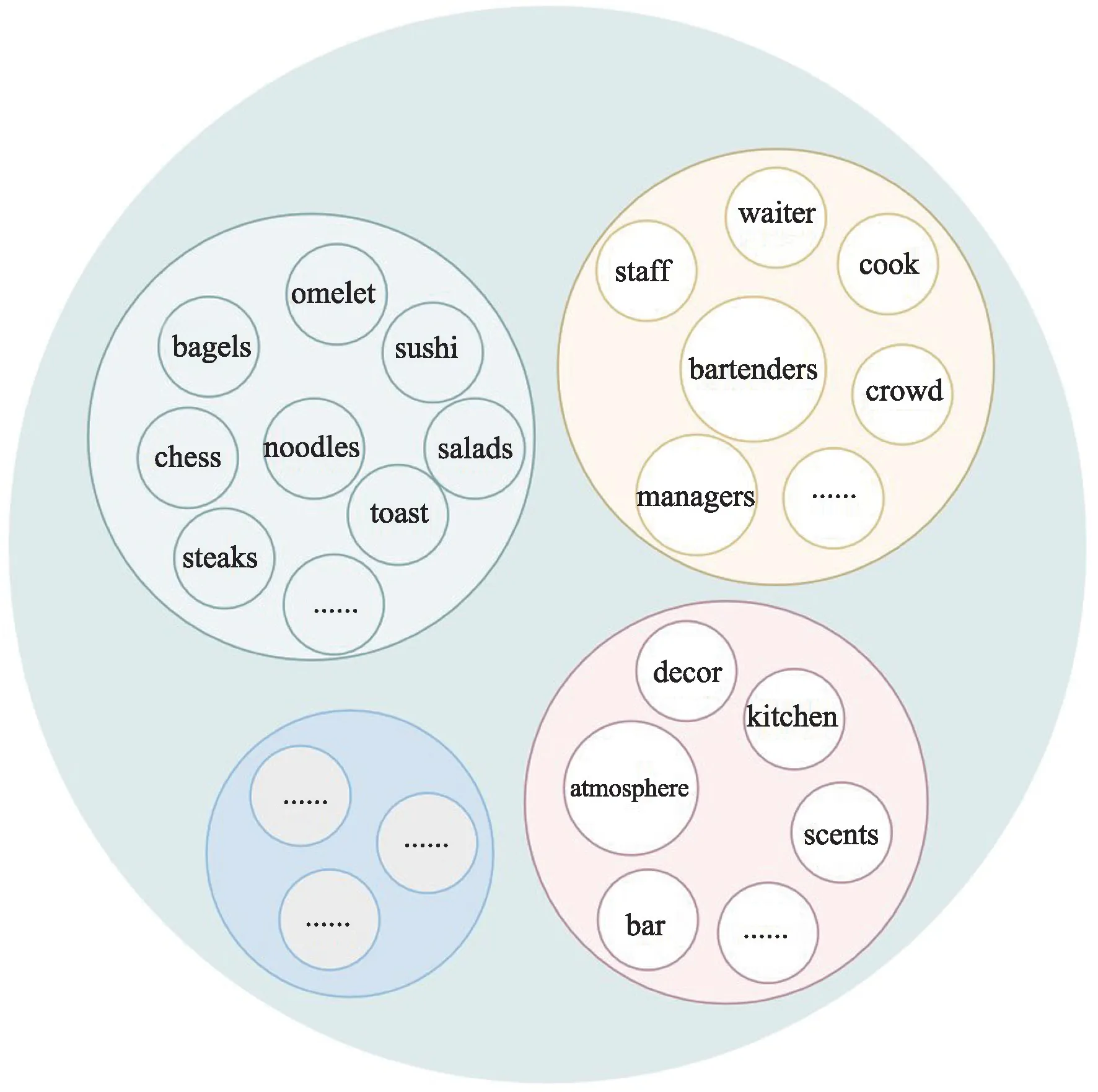
图3 Rest数据集主题领域Fig.3 Rest data-set subject area
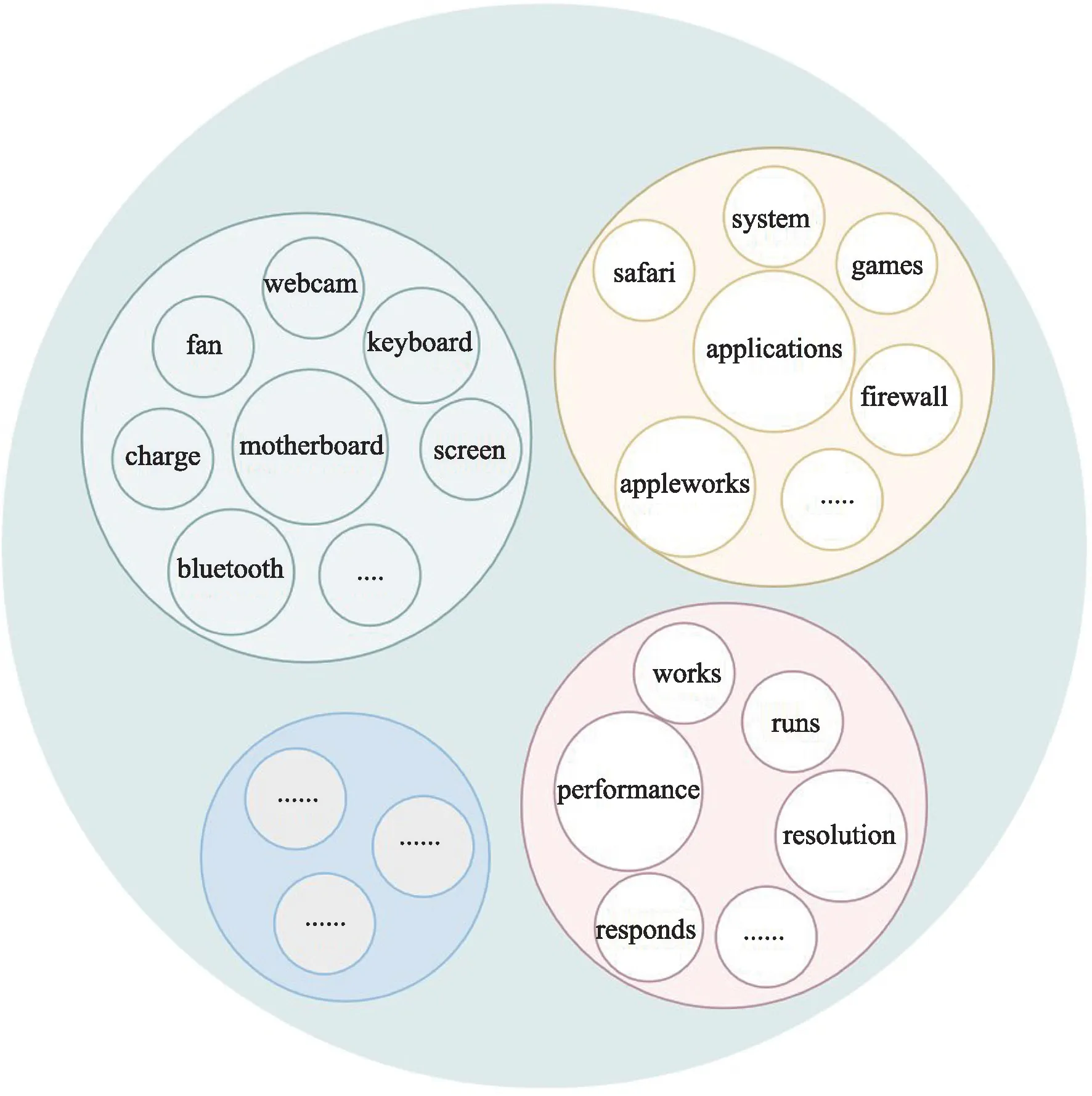
图4 Laptop数据集主题领域Fig.4 Laptop data-set subject area
属于同一类别的这些方面词具有领域相似性,可以作为同类词替换,用于扩充训练数据。具体做法是:(1)先提取出各个训练集中由单个单词构成的方面,去重后构建Rest和Laptop两个领域的aspects 集合;(2)加载词向量模型Glove,对同一领域内的aspects 集合依次计算各个方面与其他方面之间的余弦相似度,生成各个方面词aspect 和其相似度排在前10 的其他方面词的数据字典aspects_similars;(3)按照一定比列随机抽取训练集内的句子,将句子中符合条件的方面词用aspects_similars 中与其对应的领域内相似度词随机替换,从而生成新的训练样本。
2.3 词向量级同义词替换
词向量级同义词替换(Word Vector Level-Synonym Word Replacement, WVL-SWR),该方法类似于DL-SWR,不同之处在于生成的数据字典aspects_similars 的词向量范围不同,DL-SWR方法是在数据集主题领域内计算相似度词,而WVL-SWR则是在整个Glove词向量空间内计算相似度词。另外,实验中发现,在进行WVLSWR 同义词替换时,往往不是取最近似的词效果最好,也不是随机取[0-9]的任意一个近似词,而是随机取[4-5]的任意一个近似词效果最好。
表2 展示的是应用MLDA 得到的增强样本示例。从表2 中可以看出,应用SL-NCR 和DLSWR 生成的新样本都适当偏离了原语义,但是语法通畅,语义合理;而作为最常规的WVLSWR 方法,生成的新样本与原语义相对偏差最大,语法的流畅度也略有削弱。

表2 应用MLDA生成的增强样本示例Table 2 Examples of augmented samples generated by MLDA
3 基于多级数据增强方法的ABSA
本小节主要介绍将MLDA 方法应用于基于依赖树+预训练模型进行ABSA 任务处理的过程,选用模型为Wang 等[13]提出的RGAT+BERT。图5 展示了整体框架,它主要由数据预处理、多级数据增强模块、BERT 嵌入层、特征提取层和输出层构成。

图5 MLDA方法的运用示意图Fig.5 Schematic diagram of the application of the MLDA method
3.1 数据预处理
数据预处理模块是利用依赖树进行修剪的过程,首先对输入的每个句子应用一个依赖解析器来获得它的依赖树,选择的解析器是双仿射解析器(Biaffine Parser)[18],然后通过重构和修剪来构建基于方面的依赖树,如果存在多个方面,则为每个方面构造一个独立的语法依赖树。图6为基于语法依赖树解析出的真实笔记本电脑评论的上下文表示,单词之间的关系可以用有向边和标签来表示,其中方面“Drivers”是积极情绪,方面“BIOS update”和“system”是消极的情绪。图7为经过重构和修剪得到的面向方面“system”的依赖树,为了突出重要依赖关系,图中只保留到二级虚拟关系(实验结果表明三级以后的虚拟关系对方面情绪极性影响微乎其微)。

图6 基于语法依赖树解析出的真实笔记本电脑评论的上下文表示Fig.6 Dependency-based context example parsed from a real laptop review
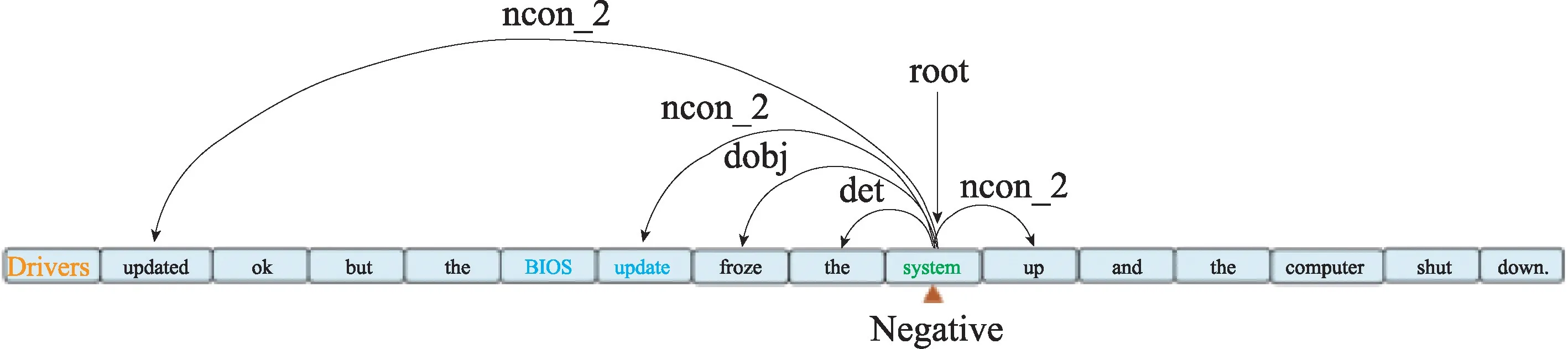
图7 经过重构和修剪得到的面向方面“system”的依赖树Fig.7 Aspect-oriented "system" dependency tree from reshape and prune
3.2 基于RGAT的特征提取
本文采用关系图注意力网络(Relational Graph Attention Network, RGAT)[13]对带有标记边的图进行编码。RGAT 包括两种类型的多头注意机制,即注意头(Attentional Head)和关系头(Relational Head)。
经过预处理后的依赖树用一个有n个节点的图ℊ 表示,每个节点代表句子中的一个单词,连接各个节点的边代表单词之间的依赖关系。Ni代表节点i的邻接节点。RGAT通过使用多头注意力聚合邻接节点的表示迭代地更新每个节点的表示。其中Attentional Head计算公式为:
考虑到具有不同依赖关系的邻接节点有不同的影响,考虑使用这些Relational Head 作为关系级门控机制来控制领域节点的信息流入程度。具体来说,首先将依赖关系映射到向量表示中,然后计算Relational Head,计算公式如下:
其中,rij表示节点i和节点j之间的依赖关系嵌入表示。
RGAT 包含K个注意头和M个关系头。每个节点的最终表示法的计算方法为:
3.3 模型训练
使用预先训练过的BERT 的最后一个隐藏状态来对依赖树节点的单词嵌入进行编码,并在任务中进行微调。在一个面向方面的修剪依赖树上应用RGAT后,其根节点表示通过一个全连接softmax层,映射到不同情绪极性上的概率。
最终标准的交叉熵损失作为模型需要优化的目标函数(损失函数),其定义为:
其中,D包含所有的句子-方面词对;A表示句子S中出现的方面词;θ包含所有的可训练的参数。
4 实验及分析
为了验证提出的MLDA 方法的有效性,所有的实验和基准测试都使用一个单一的GPU(RTX 2080 Ti)运 行,CPU 为Intel Core i7-8700K@4.7 GHz,内存为32G。
4.1 数据集分析
实验使用来自SemEval 2014 Task 4 Sub Task 2[6]两个公共数据集:Rest 和Laptop,每个评论包含0 个、1 个或多个目标方面,拥有3 种情绪标签:{positive,negative,neutral}。这些评论包含不规则的词汇单位和句法模式,因此,这些数据是有噪声的、稀疏的,甚至是有冲突的。与前人的实验结果进行比较,确保实验数据的一致性。详细统计数据如表3所示。
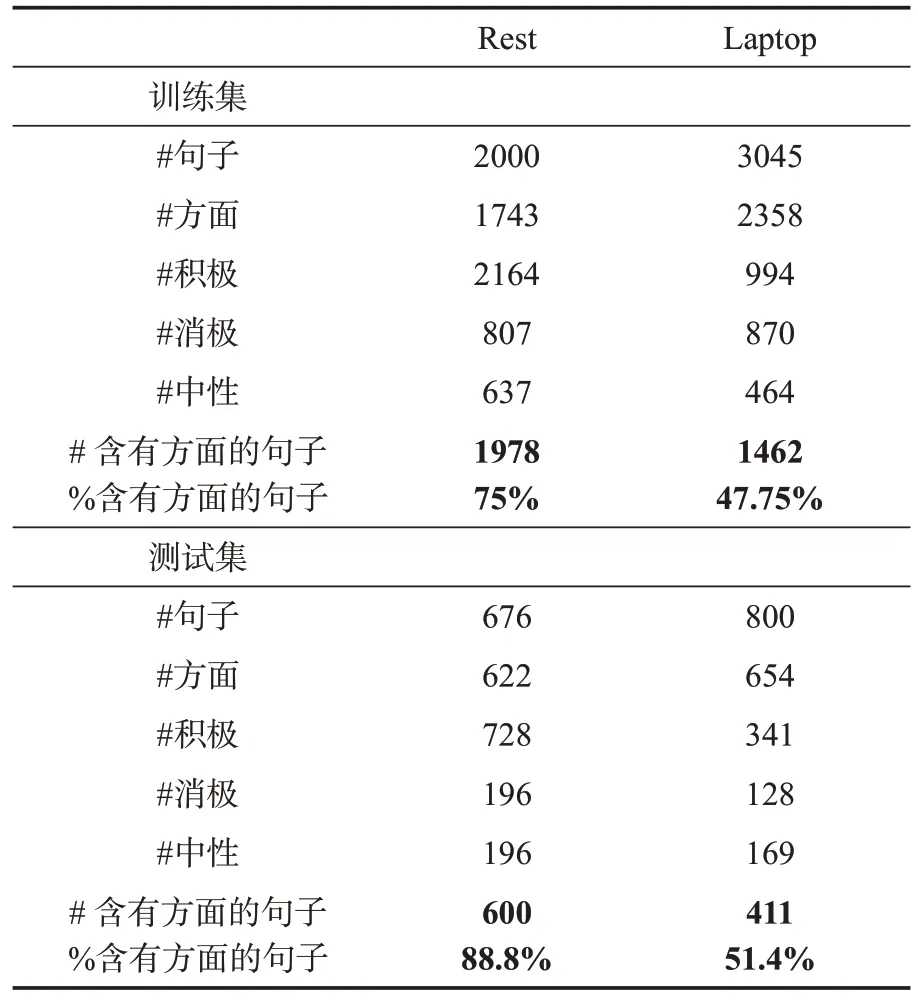
表3 SemEval 2014 Task 4 Sub Task(2)方面情绪分类统计表Table 3 Summary of SemEval 2014 Task 4 Sub Task 2 on aspect sentiment classification
4.2 实验设置
为了进行公平比较,在进行性能测试时,分类模型的参数设置与文献[13]中的实验设置保持一致。双仿射解析器(Biaffine Parser)用于依赖关系解析,依赖关系嵌入维数设置为300。BERT模型dropout选择0.3。初始学习率设置为5e-5。
MLDA 模块使用Glove 的300 维单词嵌入。引入变量α作为训练集中用于数据增强的样本随机抽取比率,实验中尝试α∈{0.05、0.1、0.2、0.3、0.4、0.5、0.6、0.7、0.8、0.9、1},对新提出的3种DA方法单独应用后,再将其组合应用,具体组合方式尝试如下几种策略:(1)通过生成随机因子ε∈{0,1,2},针对某一训练样本随机挑选其中一种DA 方法随机组合运用;(2)将各种方法单独运用时的最佳增强数据生成合集组合运用;(3)针对每一种DA方法选取一些代表性的α值如{0.05、0.3、0.7、0.9}运行,然后再组合运用。训练集的批量大小设置为16,测试集的批量大小设置为32。在训练过程中,设置epoch 数为30,并保存在此期间训练得到的最大准确率模型。采用Adam 优化器对所有参数进行更新。每个模型训练了5轮,并给出了平均性能。
4.3 对比模型
本文选取以下几个最先进的模型进行比较,其中大多数是基于依赖学习的,同时对本文提出的改进方法进行了消融实验。
BERT-BASE[2]:基于BERT模型的基线。
TD-GAT-BERT[16]:基于GAN 的模型,采用多层图注意网络,可以捕获跨层的方面相关情感依赖关系。
DGEDT-BERT[26]:提出一种双向的transformer 结构的网络,支持“水平表示学习”与“基于图神经网络的表示学习”之间交互地学习。
LSA-BERT[27]:是一个基于GCN 的模型,目前在SemEval 2014 Task 4 Sub Task 2数据集上获得了最高性能,它们针对相邻方面的情绪集群,引入情绪模式帮助模型学习情感依赖。
AEN-BERT[15]:使用基于注意力的编码器在上下文和目标之间进行建模。
RGAT-BERT[13]:是一种基于细化依赖解析树的关系图注意网络。
4.4 实验结果与讨论
模型的性能采用Accuracy 和Macro-f1 度量来评估,表4包含了对比模型和MLDA单独应用和随机组合应用在RGAT-BERT模型上的最优实验结果的总结。
4.4.1 MLDA影响
从实验结果可以看到无论是单独应用SLNCR、DL-SWR 或WVL-SWR,还是3 种方法组合应用,与原有模型相比,在Rest 和Laptop 两个数据集上的分类性能都获得了一定的提升。
具体来看,针对RGAT-BERT模型,在Rest和Laptop 两个数据集上的分类性能都获得了约1.2%~3%的提高。3 种DA 方法中SL-NCR 对Rest数据集最有效,DL-SWR对Laptop数据集最有效,混合应用策略要优于单独应用策略。与目前已公布的最佳模型LSA-BERT相比,本文提出的改进方案获得了不相上下的性能,特别是在Rest 数据集上有所改善,Macro-f1 值均提升了1.4%。
总体来看,3 种数据增强方法中DL-SWR 方法最有效,而将3种方法组合应用即MLDA方法性能提升效果最佳,从组合策略上来看,尝试的第二种策略即将各种方法单独运用时的最佳增强数据生成合集组合运用最佳。由此可见,MLDA 方法对基于依赖树+预训练模型的ABSA任务性能提升是有效的。
4.4.2α值的影响
图8 与图9 分别显示了针对RGAT-BERT 模型的数据增强实验中,在不同随机抽样因子α值条件下3 种数据增强方法在Rest 和Laptop 数据集上的性能。可以观察到随着α的增加,性能变化并不是呈规律性的增加,而是跳跃性的,最终趋于平缓。总体来看,对于Rest 数据集α取0.3是一个比较合适的值,而对于Laptop数据集α取0.4是一个比较合适的值。从新增的训练样本数量来看,两个数据集都是增强后的训练集是原训练集的1.5倍左右较为合适。例如Rest数据集经过依赖树重构后生成的训练样本数为3,602,而增强后比较合适的训练样本数大约在5,400 左右。Laptop 数据集是从2,313 扩充到3,500 左右比较合适。

图8 Rest数据集在不同α值下MLDA的性能可视化Fig.8 Visualization of performance under differential αon the Rest dataset
同样类似的结论也出现在针对AEN-BERT模型的数据增强实验中,随着α的增加,性能呈不规律性变化。只是因为模型设计不同的原因,针对所提出的3种数据增强方法,获得最优性能的α取值并不相同:对于两个数据集,采用SL-NCR 方法时α取值是0.3,采用DL-SWR 方法时α取值是0.7,采用WVL-SWR 方法时α取值是0.9,这表明针对基于注意力+预训练模型的数据增强方法,采用越偏离原始样本的增强数据所需要的数据量越少。总体来看,应用数据增强时并不是合成的训练样本越多越好,而是和原训练集的规模有一定的比列,并与分类器选择也是紧密相关的。
4.4.3 MLDA泛化能力分析
为了考察MLDA 方法的泛化能力,本文将其应用于基于注意力机制+预训练模型的ABSA任务中,选用模型是Song等[15]提出的AEN-BERT模型。整个实验流程和RGAT-BERT+MLDA 模型类似,如图4 所示,数据预处理部分和特征提取模不同之处在于数据预处理部分和特征提取模块。在进行性能测试时,分类模型的参数设置与文献[15]中的实验设置保持一致。预训练的BERT 嵌入维数设置为768,隐藏状态的维数设置为300,dropout 选择0.1,初始学习率设置为3e-5。MLDA 模块参数设置和4.2小节中设置相同。训练集的批量大小设置为32,测试集的批量大小设置为8。采用Adam 优化器对所有参数进行更新。每个模型训练了5 轮,并给出了平均性能。
实验结果如表5 所示。从实验结果可以看到无论是单独应用SL-NCR、DL-SWR 或WVL-SWR,还是3 种方法组合应用,与原有模型相比,在Rest 和Laptop 两个数据集上的分类性能都获得了一定的提升。
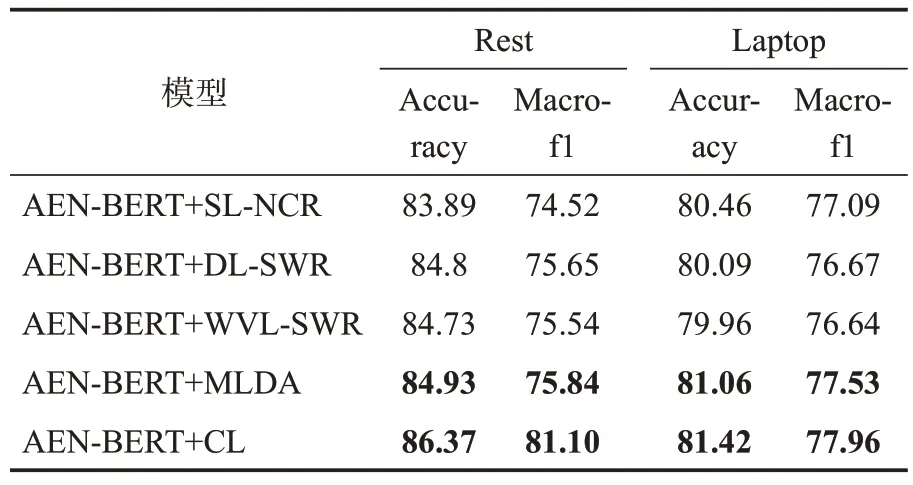
表5 MLDA泛化能力及应用性能分析Table 5 Generalization ability and application performance analysis of MLDA
具体来看,单独应用3 种数据增强方法,可以提升Rest数据集的分类性能0.8%~1.8%,其中DL-SWR 方法最有效。但是在Laptop 数据集上的分类性能提升微乎其微,最佳效果是SL-SWR方法,Accuracy 提高了0.53%,Macro-f1 提高了0.76%,原因可能是所提出的数据增强方法以方面词为替换核心,而Laptop数据集中的方面词相对偏少,导致模型学习到的样本多样化不足使得整体性能提升不明显。不过,当将这3 种数据增强方法组合使用时,在Rest 和Laptop 两个数据集上都获得了相当可观的提升,其中在Rest 数据集上的Accuracy 和Macro-f1 分别提升1.81%和2.08%,而在Laptop 数据集上的Accuracy 和Macro-f1 分别提升了1.13%和1.22%,并取得了所有实验的最佳性能。由此可见,MLDA方法也能很好地适用基于注意力机制+预训练模型的ABSA任务,该方法具有一定的泛化能力。
4.4.4 MLDA应用于对比学习
尽管PLMs 在NLP 任务上获得了最先进的性能,然而近来一些研究表明,由PLMs 生成的句子表示在整个向量空间中只占据了一个狭窄的锥体,并非呈现均匀分布,这使得模型的空间表达能力受限,不利于下游任务[28]。而对比学习[29]已被证实可以有效地解决这个问题,其训练目标是拉近正样本对来增强对齐,同时推远不相关的负样本以实现整个表示空间的均匀性。为了更广泛地测试MLDA应用性能,同时受文献[30]启发,本文在AEN-BERT模型基础上,将MLDA中的SL-NCR 和DL-SWR 作为两种不同的数据增强策略应用于原始句子上来产生高度相似的变化,形成正样本对,构建对比学习任务,与原ABSA 任务做多任务联合训练。AEN-BERT 模块的参数设置同4.4.3小节。对比学习任务模块与文献[30]相同,采用正则化的温度缩放的交叉熵损失(NT-Xent)作为对比目标。在每个训练步骤中,从可数据增强的训练集中随机地采样N条评论以构建mini-batch,经增强模块后得到2N个表示。训练每个数据点,以在2(N-1)个样本中找到其对应的正例:
其中,sim(·)表示余弦相似函数;τ控制温度,〛是指示函数;平均所有2N个样本的分类损失得到对比学习损失Lcl。
最终多任务训练模型的损失函数如下:
其中,Laen为AEN-BERT 模块的损失函数;λ为L2正则化项的系数;Θ 为参数集。训练中,批量大小设置为32,τ设置为0.1。实验结果如表5所示。在Rest 和Laptop 两个数据集上取得比AEN-BERT+MLDA 更优的性能,其中在Rest 数据集上的Accuracy 和Macro-f1 分别提升2.61%和1.17%,而在Laptop 数据集上的Accuracy 和Macro-f1分别提升了1.49%和1.65%。从中可以发现将MLDA 方法应用于对比学习作为多任务参与到ABSA下游任务中,可以增强模型的表达能力,效果上比单纯将MLDA 用于补充训练集更好。未来还将继续尝试将对比学习应用于NLP其他下游任务中。
5 结语
本研究调查了NLP 文本分类任务常用的替换法数据增强方法,并将其适应到细粒度的ABSA 任务中,设计一个MLDA 方法,可以在句子、类别领域、词向量3 个级别上生成具备弱噪声并不会改变句子情绪标签的训练样本。还将MLDA 方法分别应用在基于注意力机制+BERT模型和基于依赖树+BERT 模型上进行方面级情感分析任务,并测试其应用于对比学习框架的效果,通过在两个公共数据集上的实验,表明MLDA方法能有效提升模型性能。
利益冲突声明
所有作者声明不存在利益冲突关系。
猜你喜欢
中学生数理化·高一版(2021年2期)2021-03-19 08:32:00
阅读(快乐英语高年级)(2020年8期)2020-01-08 02:21:16
家庭影院技术(2019年8期)2019-08-27 02:44:56
知识经济·中国直销(2018年8期)2018-08-23 09:16:16
智慧少年·故事叮当(2018年11期)2018-05-14 11:48:18
意林(绘英语)(2017年5期)2017-05-15 02:17:23
数学学习与研究(2017年3期)2017-03-09 18:12:42
中国老区建设(2016年1期)2016-02-28 09:32:00
燕山大学学报(2015年4期)2015-12-25 02:19:45
中国塑料(2015年4期)2015-10-14 01:09:28
