
知识与数据驱动相融合的朝鲜语自动标音方法研究
2023-11-08 05:47:16曹德智吴立成赵悦
数据与计算发展前沿 2023年5期
曹德智,吴立成,赵悦*
1.中央民族大学,中国少数民族语言文学院,北京 100081
2.中央民族大学,信息工程学院,北京 100081
引 言
自动标音技术即字音转换技术(graphemeto-phoneme conversion, G2P),是指利用计算机自动为单词系统标注音标,将用字符拼写的单词文本转换为可供人或机器阅读和处理的单词发音。G2P 算法可以应用到自然语言处理的很多领域,如语音识别技术、语音合成技术、语音关键词检测、机器翻译等应用中。
在语音识别与语音合成系统中,发音词典包含了从单词到音素之间的一一对应关系,在此基础上把声学模型和语言模型连接起来,共同组成一个用于进行解码工作的搜索状态空间,其规模和质量直接影响系统性能。随着朝鲜语自身的发展,内部不断涌现大量的新词和外来词,但字典数据库难以包括所有朝鲜语单词的发音。因此,除了数据库内的词汇,如何解决那些数据库以外的“集外词”即OOV(out of vocabulary)单词的读音就成了朝鲜语自然语言处理过程中不得不解决的问题。朝鲜语的字音转换技术不仅可以为朝鲜语发音字典的构建提供支持,并且能够有效解决OOV单词的自动注音问题。
字音转换方法可分成两类:
(1)基于知识驱动的方法。通过对朝鲜语的构词法和连续语流中的朝鲜语音节之间的音变现象进行总结,根据音变现象制定出朝鲜语的字音转换规则系统,然后实现字素到音素的转换。Wang 等[1]在朝鲜语语音合成系统研发过程中对基于知识驱动的朝鲜语字音转换算法进行了研究,通过对朝鲜语语音的分析总结出了元音和辅音结合以及字间所产生的语音变异现象,根据他们发现的音变现象构建了一个基于知识驱动的模型,将这些模型应用于朝鲜语文本字符串,以预测发音的音位表示。但该模型最终并没有建立可以应用于朝鲜语语音处理的发音词典,实验过程中也没有进行严格的交叉测试。由于朝鲜语语音变异规则多样,基于知识驱动的模型无法涵盖所有语言事实,这些都会影响字音转换的准确率。
(2)基于数据驱动的方法。在丰富的训练数据支持下,利用概率统计和机器学习算法,建立发音模型,通过解码算法为任意单词进行标音。数据驱动的方法是目前主流的字音转换方法。在国外,Park 等[2]基于双向长短时常记忆算法(Bi- directional Long Short- Term Memory, Bi-LSTM)实现了汉语字素到音素的转换,并在包含99,000 多个句子的汉语数据集上进行了测试。Galescu 等[3]基于期望最大化(Expectation Maximization,EM)算法实现了英语字素音素一对一对齐,通过N-Gram 建立发音模型的字音转换方法。Jiampojamarn 等[4]将隐马尔科夫模型(Hidden Markov Model,HMM)应用于发音建模提出了字素音素多对多的对齐方式。Hannemann等[5]提出了联合序列模型的方法,并在英语、德语和法语测试集上进行了测试,该方法也是当时较为主流的字音转换方法。Lim 等[6]通过LSTM(Long Short-Term Memory)算法实现了韩国语的字音转换技术,并与基于规则和基于统计的方法进行了对比,最终识别率达到92.8%,实验结果表明,基于数据驱动方法的结果优于基于规则和基于统计的方法。在国内,王永生等[7]基于一种动态有限泛化法(Dynamic Finite Generalization,DFGA)的机器学习算法,用于英语字音转换规则的学习。冯伟等[8]针对俄语语音合成和语音识别系统中发音词典规模有限的问题,提出一种基于LSTM序列到序列模型的俄语词汇标音算法,实验结果表明,该算法音素正确率达到了94.5%。冯伟等[9]将加权有限状态转化器(WFST)用于实现俄语字音转换技术,首先利用期望最大化算法以“多对多”的方式对俄语字音进行对齐,然后将对齐结果通过联合N-gram 模型训练,并转化为WFST 发音模型,最后通过WFST 解码算法对任意单词的发音进行预测。交叉验证实验结果表明,平均音素正确率为92.2%。李鹏等[10]基于CART 树(Classification And Regression Tree)方法的构建了一个英语字素到音素的转换系统。赵坤等[11]提出了一种通过有条件维数扩展(Conditional Mixincrementing algorithm,CMI)决策树算法解决英语字音转换的方法。王永生等[12]提出过一种基于决策树的字素音素转换的监督学习算法,生成德语字素音素转换规则,进过10轮交叉测试,实现了德语字素到音素的转换。
综上所述,字音转换技术在国内外已有不少研究,但应用对象主要为英语、俄语、德语,目前国内还没有任何朝鲜语字音转换方面的研究和实验,并且相关研究中均采用的是单一方法,或是仅基于知识驱动或是仅基于数据驱动。基于知识驱动的方法有比较完备的理论支撑,可解释性强、执行效率较高,但大规模复杂问题导致模型复杂计算困难,且难以使模型持续学习进化。基于数据驱动的方法通用性强,可支持模型持续学习进化,但理论知识分析困难,依赖高质量数据又难以合理确定输入变量,且需要模型特征充足且选取精准。因此,有必要以朝鲜语语音学知识为基础,融合数据驱动的方法,对朝鲜语字音转换方法的实现与应用做进一步研究。考虑到朝鲜语的发音特点及音变规则,其字音转换模型训练的过程与其他语言存在差异性,本文根据朝鲜语的发音规则以及字间的语音变异规律提取特征属性送入预测模型中进行训练。本研究建立了10,000 条朝鲜语字素和音素对照的平行语料库,目的是在这个平行语料库的基础上,通过朝鲜语音变知识与数据驱动相融合的方法来解决朝鲜语自动注音问题。
1 基于知识驱动的朝鲜语数据属性特征提取
1.1 朝鲜语语音结构特点
朝鲜语是国内外朝鲜民族的共同语,使用区域主要有中国东北三省的部分地区和朝鲜半岛,既是中国的少数民族语言之一,同时也是朝鲜、韩国使用的通用语。朝鲜语文字属于音型文字,其在组字的时候以音节为单位,即每一个朝鲜文字表示一个音节。每个朝鲜语音节至多由3 个音素构成,按照发音顺序,分别称为首辅音、元音和尾辅音。朝鲜语文字按照“从左到右,自上而下”的基本规则进行读写,如果以C代表辅音,V代表元音,则朝鲜语的音节结构类型有CVC、VC、CV或V。图1给出了一个朝鲜语文字的示例[13]。

图1 朝鲜语文字示例Fig.1 Example of Korean characters
按书写方式来分,在朝鲜语中共有首辅音19种、元音21 种、尾辅音27 种,本研究为每个位置可能出现的字母定义了对应的拉丁转写映射,如表1所示。
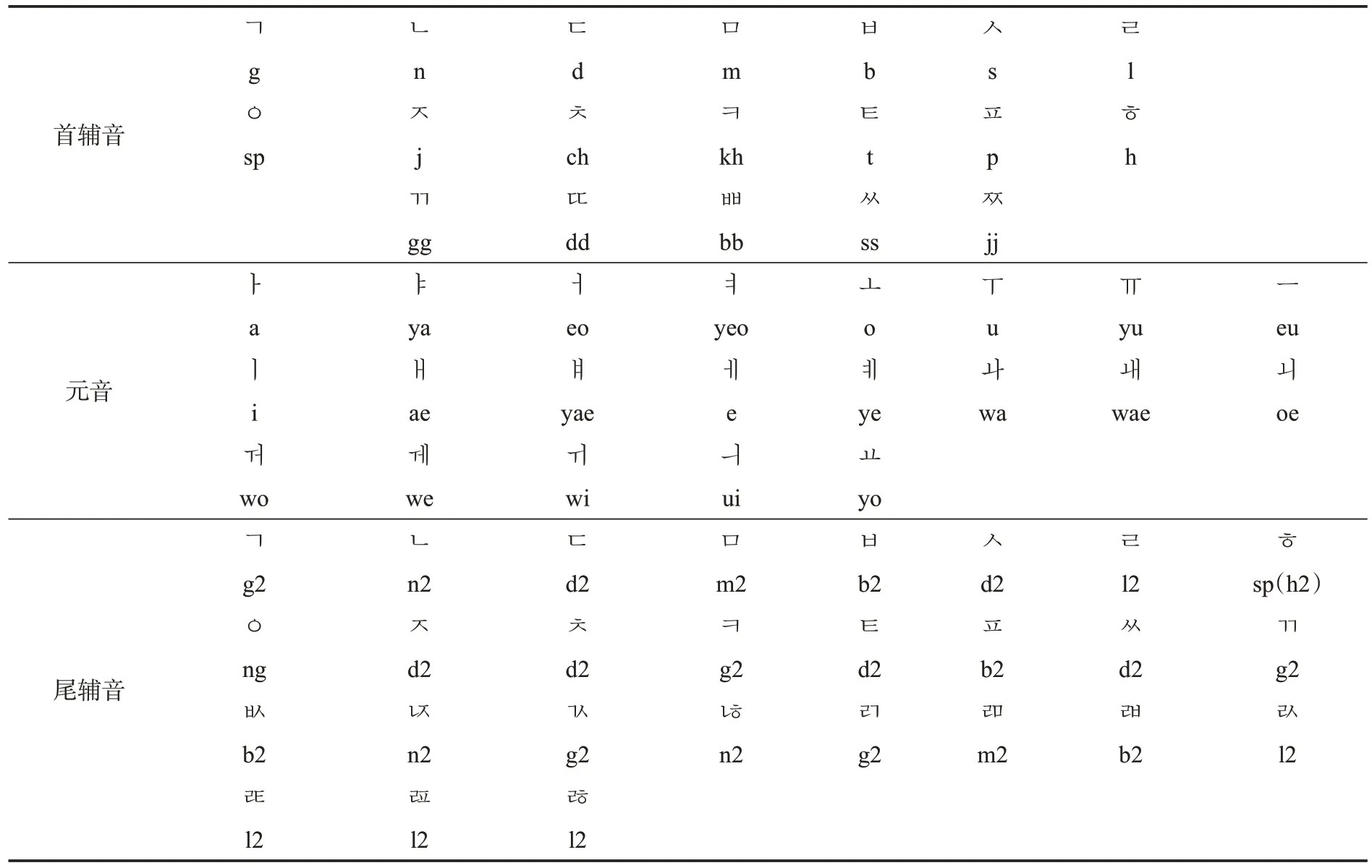
表1 朝鲜语字母及其拉丁字母映射表Table 1 Korean letters and its Latin transcription mappings
1.2 朝鲜语音变规则
朝鲜语有很多音变现象,其规则也相对较复杂,可分为连音现象、同化现象、送气化现象、紧音化现象、腭化现象、添加现象以及脱落现象。具体规则解释及相关实例如表2所示。
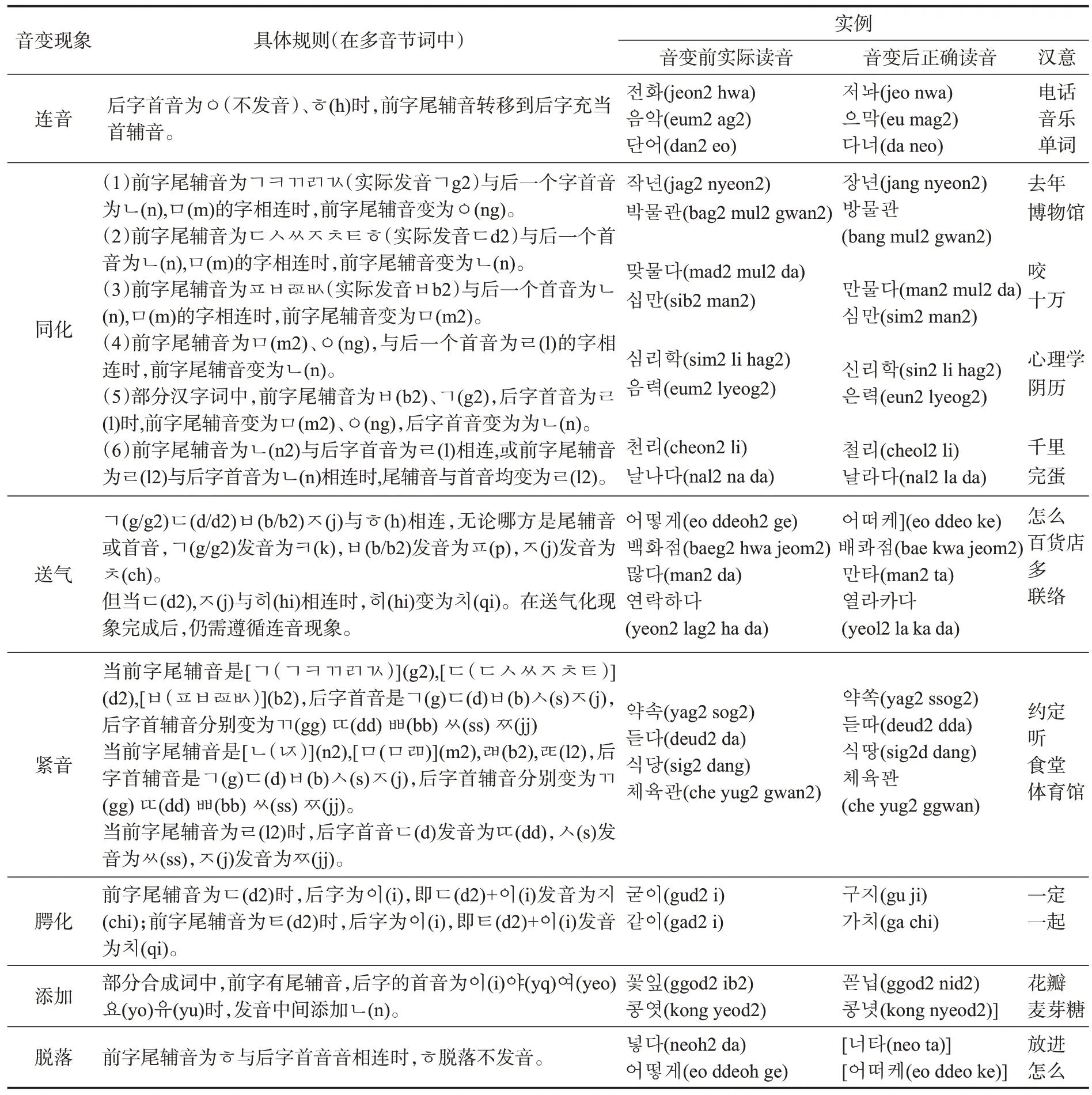
表2 连续音节中朝鲜语音变现象规则表Table 2 Rules of Korean phonetic varition
朝鲜语中的字母与音素之间并不是一一对应的,同一个字素可以对应多个音素。同样地,同一个音素可能和不同的字母相对应,尤其是其中的一些辅音的变音规则就更为复杂,即有一对一、一对多、多对一等情况。比如字素“ㄷ”,在不同的音变条件下可以与音素/d/、/t/、/j/、/dd/对应;再如音素/kh/,在不同情况下可以与字素“ㅋ”“ㄱ”“ㄲ”对应。这显然给单词与其读音之间的转换带来了困难。表3 为朝鲜语单词“쉬땅나무”的字素音素对应情况。

表3 “쉬땅나무”字素与音素的对应情况Table 3 Correspondence between “쉬땅나무” grapheme and phoneme
1.3 属性特征的提取及定义
针对单词中某个需要进行转换的字素,本文提取了5 个特征来组成一个示例,如表4 所示。实例用“特征-值”表示,以单词“쉬는날”为例,针对单词中每个字素所提取的特征如表5所示。

表4 特征定义Table 4 Feature Definition
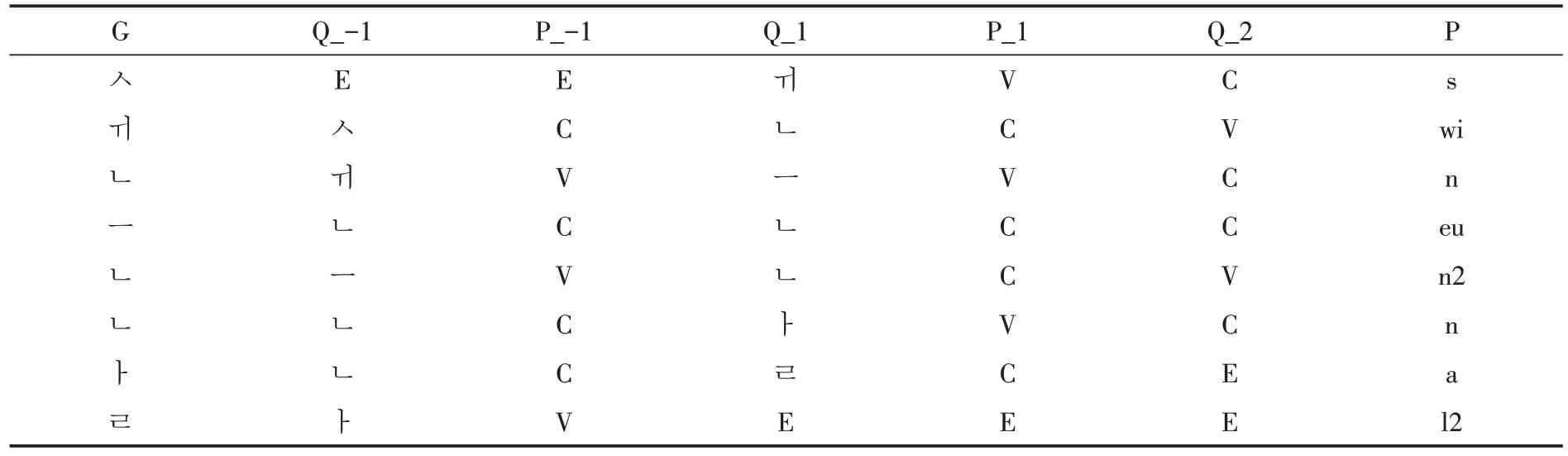
表5 单词“쉬는날”各字素特征表示Table 5 Characterization of the word"쉬는날"by grapheme
表5 字母“G”代表字素,“P”代表音素,“V”表示元音,“C”表示辅音。当目标字素为首字素或尾字素,前后没有其他字素时则为空,用“E”表示。表6中的字素“ㄴ”与音素是一对多关系,其4 个音素分别是/n/、/n2/、/l/、/l2/,表5 选取了字素“ㄴ”10个比较典型的实例。

表6 字素“ㄴ”的实例Table 6 Example of the character"ㄴ"
2 基于数据驱动的发音预测模型
数据驱动方法中决策树算法容易理解,机理可解释性强,得到的模型很容易可视化,非专家也很容易理解。相比于其他算法,决策树算法计算量相对较小,且容易融入知识规则,可以处理连续字段。其他的技术往往要求先把数据一般化,比如去掉多余的或者空白的属性,而决策树算法不需要对数据进行复杂的预处理,比如归一化或标准化,并能够在相对短的时间内对大量数据做出可行且效果良好的处理。
2.1 基尼系数
CART决策树算法采用基尼指数来代替信息增益比选择最优特征。基尼系数代表了模型的不纯度,基尼指数越小,纯度越高,该特征越好[14]。
假设有k个类别,第k个类别的概率为pk,概率分布的基尼系数表达式如公式(1)。
如果是二分类问题,一个样本属于其中一类的概率为p,概率分布的基尼系数表达式如公式(2)。
如果是多分类问题,对于样本集D,样本个数为|D|,假设有K个类别,第K个类别的数量为|Ck|,则样本集D的基尼系数表达式如公式(3)。
根据特征A的某个值a,把D分成|D1|和|D2|,则在特征A条件下,样本D的基尼指数表达式如公式(4)。
基尼系数Gini(D)表示集合D的不确定性,基尼指数Gini(D,A)表示经A=a分割后集合D的不确定性。因此基尼指数值越大,样本集合的不确定性也就越大,即基尼指数小的特征具有更强的分类能力。
以表5为例,计算各特征的基尼指数,选择最优特征及其最优切分点,假设从表5内特征Q_-1中取特征值E,将样本集D分成“是E”=|D1|和“非E”=|D2|,求特征Q_-1在类别P_-1下(“是E”和“非E”)的Gini值:

此时Gini(D,Q-1,‘E’)=0 值为0,即没有杂质,该特征具有更强的分类能力。
2.2 构建决策树
在构建决策树的初始阶段,计算所有特征的基尼指数,选取基尼指数最小的特征作为根结点。根据根结点的最优切分点分成两个叉和与之相对应的数据集,然后再沿着最左侧的分枝继续计算其他特征的基尼指数,再选取一个最佳的特征作为该分叉的结点,以此类推,当这一条分枝结点全部计算完成或者无法继续生长,则回到上一个未完成的分叉继续树的生长,直到所有分叉均完成结点计算或者树无法继续向下生长为止。具体步骤如下:
输入:训练数据集D,停止计算的参数条件。
输出:CART决策树
根据训练数据集,从根结点开始,递归地对每个结点进行以下操作,构建二叉决策树:
(1)设结点的训练数据集D,计算现有特征对该数据集的基尼指数。此时,对每一个特征A,对其可能取得的每个值a,根据样本集对A=a的测试为“是”或“否”将D分割成|D1|和|D2|两部分,利用公式(5)计算A=a时的基尼指数。
(2)在所有可能的特征A以及它们所有可能的切分点a中,选择基尼指数最小的特征以及其对应的切分点作为最优特征与最优切分点。依最优特征与最优切分点,从该结点生成两个子结点,将训练数据集依特征分配到两个子结点中去。
(3)对两个子结点递归地调用(1)、(2),直至满足停止条件。
(4)生成CART决策树。
算法停止计算的条件是结点中的样本个数小于预定阈值,或样本集的基尼指数小于预定阈值(样本基本属于同一类),或者没有更多特征[15]。
当然在实际的决策树构建的过程中,不可能像表5 那么简单,这里只是为了方便算法说明,特意选取了几个实例。
2.3 规则测试
2.3.1 数据集
本文选用了韩国开源的Zeroth[16]数据集,该网站内语料库包含基于语素的分词以及预先标注好的词条。进一步对词条进行筛选,删除韩国本土词、外语音译词,根据《中国朝鲜语规范原则与规范细则研究》(金永寿著,2012 年,人民出版社)选取中国朝鲜语使用的基础词汇。
2.3.2 规则测试
本文采用K折交叉验证法,即将数据集分为K份,K-1份的训练数据集用于构建模型,确定模型最优超参值,然后基于这个确定的超参值再基于1 份测试数据集验证模型性能。经验表明,K的最佳取值为10,因为在这种情况下,10折交叉验证可以让偏差与方差取得最好的平衡。所以本文将预先创建的字素音素平行语料库中的10,000 个样本数据平均分成10 份,每份1,000 个样本,经过10 折交叉测试,将9 份样本数据用于训练规则,1 份样本数据用于规则测试。过程如图2所示。
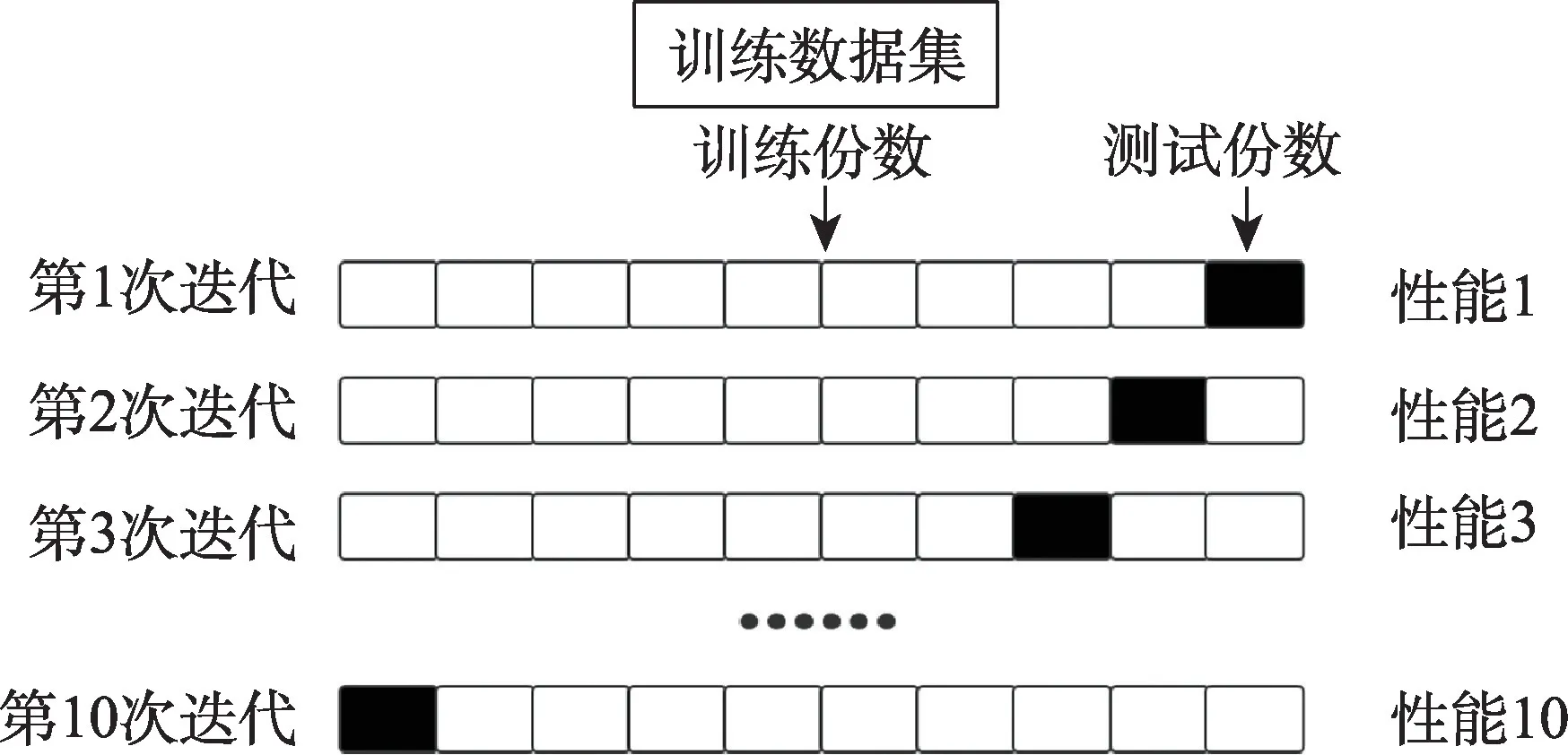
图2 10折交叉验证流程图Fig.2 10-fold cross-validation flow char
结果显示平均字素音素转换正确率只有82.52%,并不理想(表7)。为了进一步提高正确率本研究对单词数据进行了预处理。

表7 字素音素转换规则10轮交叉验证结果Table 7 Results of 10 rounds of cross-validation of grapheme-phoneme conversion rules
在朝鲜语中不是所有字素都是发音字素,也存在字素不发音的情况,例如字素“ㅇ”,当字素“ㅇ”位于首辅音位置的时候不发音,所以单词“오이”按照读音标注音素应是“o i”,这就出现了4个字素对应2个音素的情况。
字素“ㅎ”也是如此,当字素“ㅎ”位于尾辅音的位置时同样不发音,这就导致了数据内大量音素字素不对齐的情况,进而影响了模型的训练。于是本文对单词进行词法预处理,将所有不发音的情况用一个音素“sp”代替,这样每个字素都能对应实际发音的音素,保证了数据间的对齐。
由此经过新生成的规则库再次进行10轮交叉测试结果,如表8 所示,平均转换正确率提高到94.63%。
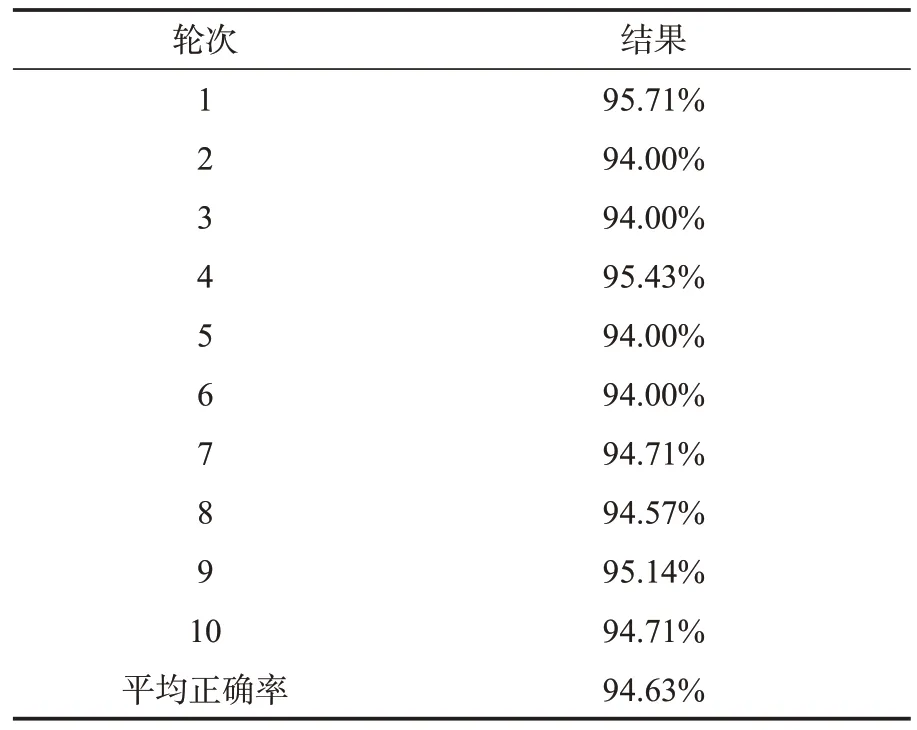
表8 处理后10轮交叉测试结果Table 8 Results of 10 rounds of cross-testing after processing
3 实验对比模型
此前,韩国学者Lim 等[6]通过LSTM 算法实现了基于数据驱动的韩国语的字音转换技术,最终识别率达到92.8%。为了进一步验证决策树模型的性能,本研究也采用了基于长短时记忆网络的编码器-解码器(Encoder-Decoder+LSTM)模型结构来进行对比实验。实验结果如图3所示。
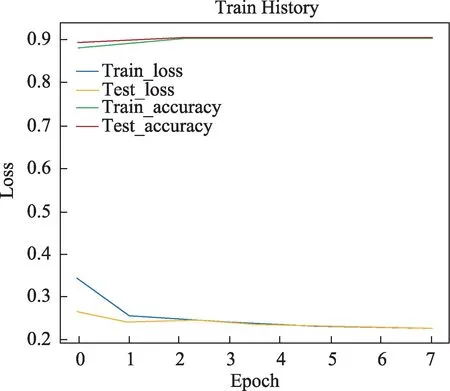
图3 Encoder-Decoder+LSTM实验结果图Fig.3 Encoder-Decoder+LSTM experimental result graph
从图3 的实验结果显示,当模型batch_size值为5,单元数为256,Epoch 值为7 时Encoder-Decoder+LSTM 模型学习效果最好,朝鲜语音素识别准确率到达90.46%。
Lim 等[6]用的单纯数据驱动的方法,而本文方法除了采用数据驱动的方法以外,还结合了朝鲜语音学音变规则创造性地为每个数据定义属性特征用于训练CART 决策树模型。本文方法的实验结果优于对比模型的实验结果,从表9实验对比结果显示,在数据量相仿的情况下,本文方法可以提高朝鲜语字音转换技术的准确率。

表9 实验对比结果Table 9 Experimental comparison results
4 结语
由于朝鲜语构词功能十分强大,新词不断涌现,因此不可能建立一个包含所有词汇的数据库。本研究将知识驱动与数据驱动两大类方法相结合,利用其各自优势,形成了知识与数据协同驱动的新方法路径,使自动标音结果能够反映朝鲜语连续语流中音节弱化、脱落、增音、异化等音变现象,并能够准确地获得字素相对应的音素,实现了朝鲜语字音在音变条件下的一一对齐,在交叉验证中平均字音转换的正确率达到了94.63%。利用本文提出的朝鲜语自动标音方法能够有效建立准确的朝鲜语发音字典,有望为朝鲜语语音识别与语音合成等系统提供技术支持。基于本文方法可以扩展到不同的语言场景下,例如:维吾尔语、蒙古语、日语等其他与朝鲜语同属黏语系的语言之中。通过总结音变规则,提取属性特征,再结合数据驱动方法实现该语言的自动标音技术,提高该语言字音转换技术的鲁棒性。
在下一步工作中将探索用于解决自动标音的其他方法,例如:将考虑如何基于无监督或者半监督的机器学习方法充分利用网络空间的朝鲜语资料提高朝鲜语字音转换技术的准确率,将作为本文的后续工作继续开展研究,并与本文的实验进行比对,为进一步提升朝鲜语字音转换的正确率寻找新途径。
利益冲突声明
所有作者声明不存在利益冲突关系。
猜你喜欢
中学生英语·阅读与写作(2023年9期)2023-10-19 14:24:34
戏曲研究(2023年1期)2023-06-27 06:54:32
韩国语教学与研究(2021年1期)2021-07-29 08:43:46
北京教育·普教版(2020年9期)2020-10-09 11:15:09
校园英语·中旬(2019年11期)2019-11-26 10:01:06
家教世界·创新阅读(2018年7期)2018-11-20 12:19:30
疯狂英语·新策略(2018年7期)2018-08-29 08:54:26
韩国语教学与研究(2016年2期)2016-10-19 00:54:36
新闻传播(2016年4期)2016-07-18 10:59:20
长江学术(2015年1期)2015-02-27 07:11:12
