
利用指数损失因子提高长短期记忆网络轨迹预测精度的方法
2023-11-06 13:21王志文卢延荣孙洪涛
兰州理工大学学报 2023年5期
张 彤, 王志文*,2,3, 卢延荣, 孙洪涛
(1. 兰州理工大学 电气工程与信息工程学院, 甘肃 兰州 730050; 2. 兰州理工大学 甘肃省工业过程先进控制重点实验室, 甘肃 兰州 730050; 3. 兰州理工大学 电气与控制工程国家级实验教学示范中心, 甘肃 兰州 730050; 4. 曲阜师范大学 工学院, 山东 曲阜 273100)
自动驾驶车辆自主导航的关键在于其能否根据周围行驶车辆的未来轨迹做出合理的决策,即何时如何加减速、变道和超车[1].周围行驶车辆运动轨迹的预测对其导航、路径规划和决策规划都具有重要意义[2].
轨迹预测旨在根据目标车辆的历史轨迹和环境信息预测其未来轨迹[3].当前的轨迹规划算法要求自动驾驶车辆在现有感知数据的基础上准确预测出周围车辆的未来轨迹[1].但是,由于不同驾驶员驾驶目标和驾驶习惯的差异性,未来运动轨迹与历史轨迹之间的相关性存在不确定性[4].因此,车辆的轨迹预测通常难以建模.
长短期记忆(LSTM)网络是业界普遍采用的轨迹预测方法[5],但LSTM在前一时刻的预测误差会体现在当前时刻的轨迹预测结果上,使得累积误差随预测时间增加,轨迹预测的精度随预测时间逐渐降低.因此,如何减小LSTM方法在轨迹预测中的累积误差是一个关键性问题.
为减小LSTM方法在轨迹预测过程中产生的累积误差,本文提出了用指数项修正损失函数的方法.本文通过在平滑的L1损失函数的基础上乘以指数项,修正损失函数,使得损失函数在预测时呈指数增长,如图1所示.进而,模型损失对LSTM网络的惩罚增加,模型的累积误差降低,从而模型的预测精度得以提高.本方法的有效性将通过基于LSTM的编码器解码器网络进行验证[6].
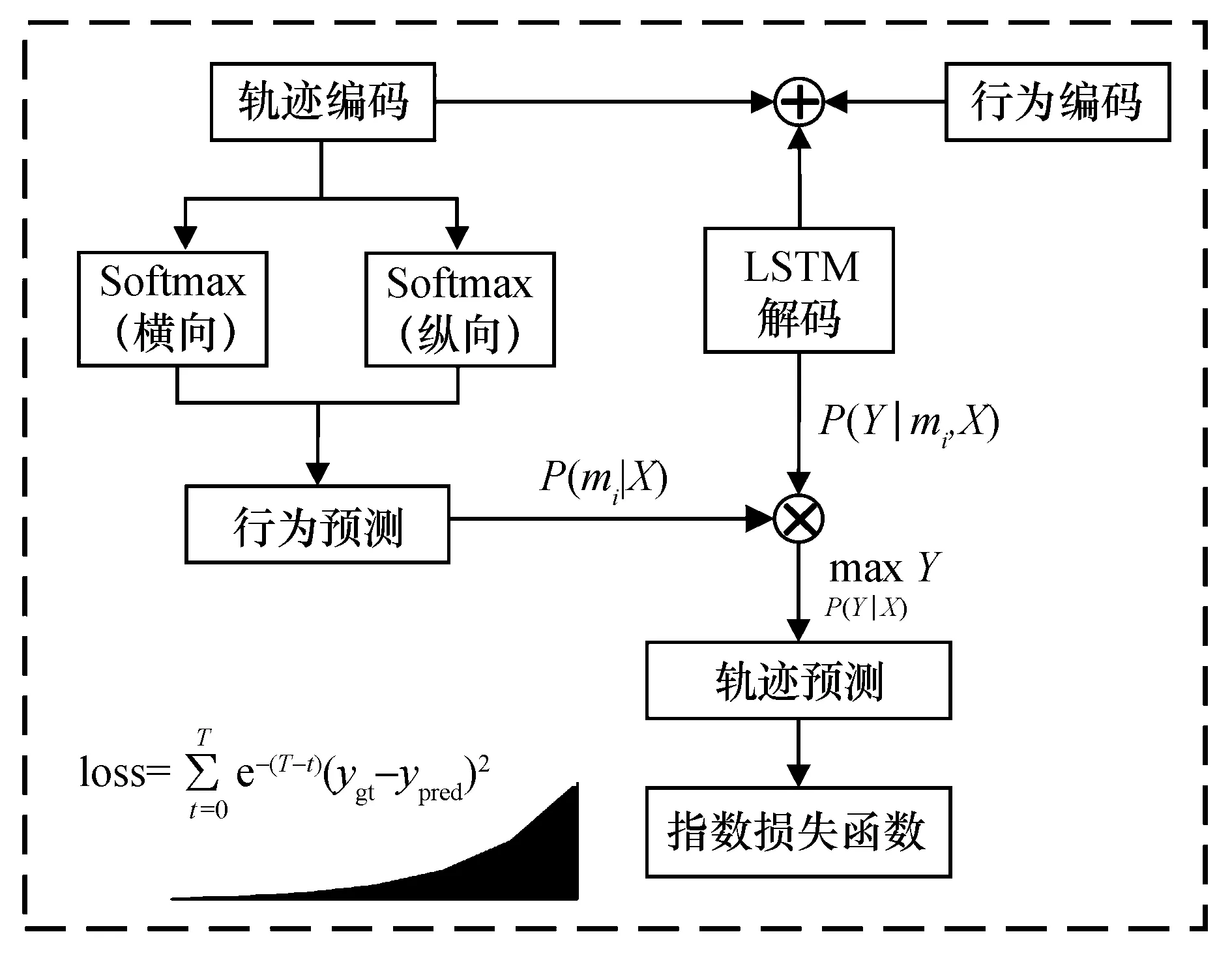
图1 利用指数项修正损失函数的方法
本文的主要贡献是将指数加权的损失函数应用于长短期记忆网络编-解码模型(LSTM encoder-decoder)框架上,使得损失函数随时间呈指数增长,缓解了LSTM编码器在递归更新过程中的误差传播问题.在社交卷积长短期记忆网络(CS-LSTM)的基础上验证了指数加权的损失函数的效果,并用均方根误差评估模型的预测值和真实值之间的偏差.评估结果表明,相比于传统的平方损失函数,指数加权的损失函数的应用可以降低预测值和真实值在全预测周期的累积误差,提高轨迹预测的精度.
1 相关研究
早期的轨迹预测方法,如基于马尔可夫模型的轨迹预测方法[7-8],通过运动轨迹匹配预测移动对象的位置,但该方法存在数据稀疏问题[9-10].传统的机器学习算法,如K-最近邻和决策树[11],通过输出离散的坐标识别和预测目标的位置,但不适用于小采样时间间隔的坐标组成的轨迹的生成.
LSTM深度学习方法,如Hochreiter等[12]提出的LSTM网络,可以更加有效地处理时间序列问题.现有的大多数轨迹预测算法都是基于对LSTM网络的改进.Altche等[13]通过引入LSTM神经网络体系结构,预测车辆在高速公路上的未来纵向和横向轨迹.Scheel等[14]提出了一种带有车道变换预测注意机制的LSTM网络,降低了预测误差.Bi等[15]通过对不同种类的车辆和行人使用单独的 LSTM,解决了车辆-行人混合场景中的轨迹预测问题,Alahi等[6]结合了卷积网络和LSTM对目标车辆轨迹进行时空预测,因此,基于LSTM的轨迹预测方法在车辆轨迹预测中应用广泛.
然而,基于LSTM的轨迹预测模型在轨迹生成过程中存在误差的累积问题,目前解决累积误差的方法主要有三类.
第一类是基于算法的.徐洪敏[16]在LSTM轨迹预测模型的基础上,采用高斯回归算法使轨迹预测精度具有自适应性,有效降低了预测结果和实际轨迹之间的误差.Park等[17]在LSTM encoder-decoder神经网络结构的基础上,应用波束搜索算法,这种方法通过为每次解码迭代保留K个最佳候选轨迹的方法,缓解了LSTM迭代解码过程中的误差传播问题,显著提高了车辆轨迹预测的精度.
第二类是基于模型的.Wang等[18]提出了基于LSTM的编-解码器网络(Seq2Seq)框架,将特征提取过程和预测过程耦合,从而避免了局部误差,降低了多步预测的误差累积效应.刘创等[19]在经典的CS-LSTM轨迹预测模型的基础上,提出了一种采用注意力机制的车辆轨迹预测算法,在减小自动驾驶车辆的预测轨迹相对真实轨迹偏离程度的同时,降低了单点和整体误差.但二者在轨迹预测过程中,初始时间段的误差都较大.
第三类是基于损失函数的.王皓昕等[20]提出了加权指数损失下LSTM网络换道意图识别模型,证明了LSTM网络应用于长序列换道意图识别过程的优越性和加权指数损失函数对模型权重优化的效果.然而,这种方法只解决了对驾驶员换道意图的分类问题,没有解决预测车辆轨迹的回归问题.
2 问题描述
2.1 LSTM单元介绍
LSTM模型已被广泛用于长输入问题,主要解决循环神经网络(RNN)的梯度消失问题.LSTM接受上一时刻的输出结果、当前时刻的系统状态和输入,通过输人门、遗忘门以及输出门更新系统状态,最终输出当前时刻的语义向量ct和隐藏向量ht.图2为LSTM的单元结构图.
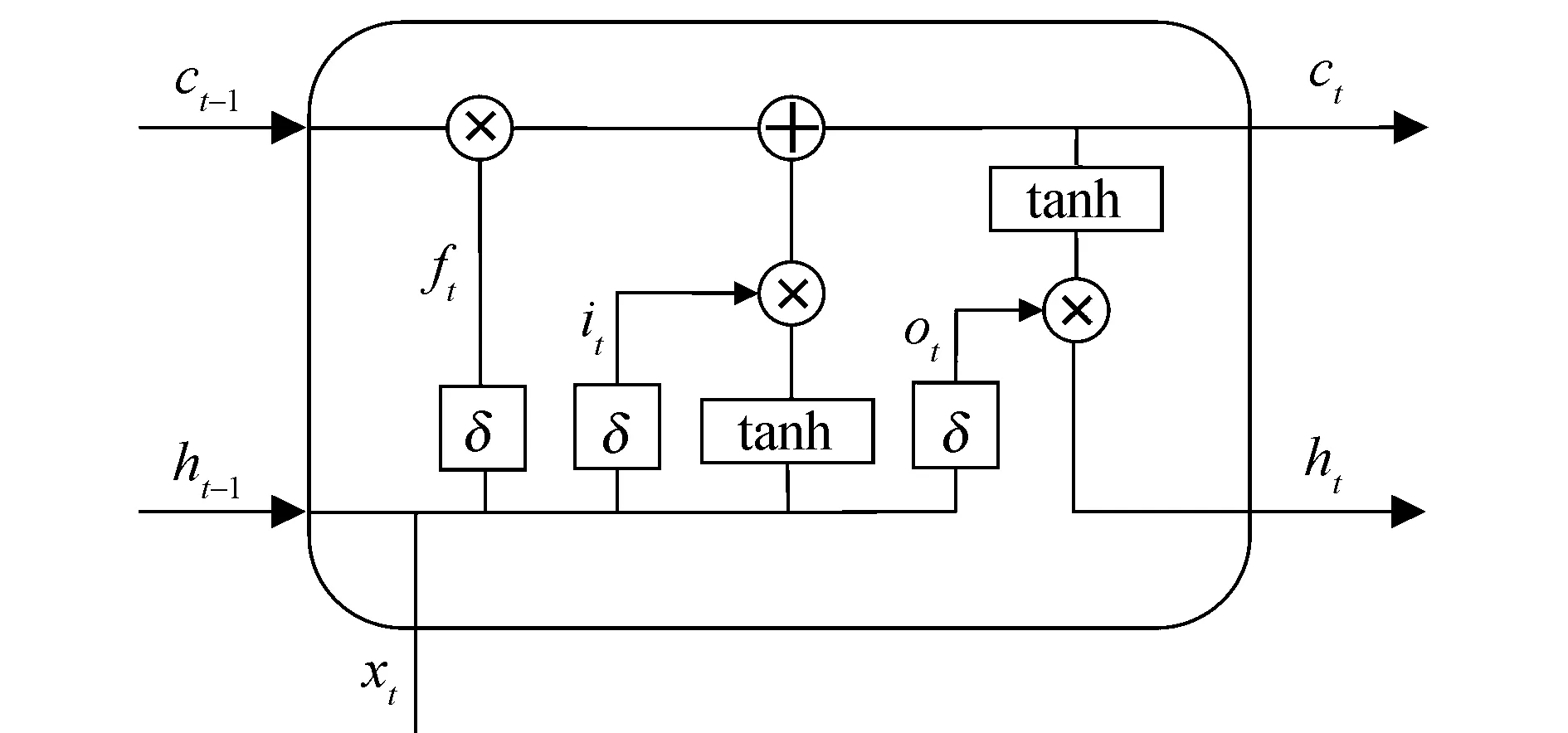
图2 LSTM单元的典型结构
LSTM单元由输入门it、遗忘门ft和输出门ot三部分组成.输入门决定当前输入中需要保留在当前状态中的数据.遗忘门决定上一时刻的状态信息中需要被遗忘的数据.输出门决定由当前时刻的输入、前一时刻的输入和状态组合的信息中可以作为最终输出的部分.下面的公式描述了LSTM的工作原理[21]:
其中:it、ft和ot分别代表输入门、遗忘门和输出门的输出;σ(·)为sigmoid激活函数,用于将LSTM门控单元的输出映射到[0,1];W和b是三个控制门和存储单元相应的权重矩阵及偏置向量;下标f、i和o分别对应遗忘门、输入门和输出门;xt为t时刻LSTM单元的输入;ct、ct-1分别是t、t-1时刻存储在神经元中的值;ht、ht-1分别是隐藏层在t、t-1时刻的输出.
2.2 LSTM 编码器-解码器模型
LSTM编码器-解码器(encoder-decoder)模型框架是轨迹预测的常用结构.本文使用LSTM神经元搭建的编码器-解码器模型,将构建的输入序列编码和解码,实现对目标车辆的轨迹预测.如图3所示,该框架主要包括编码器和解码器两个部分.首先,目标车辆及其周围车辆的轨迹历史被输入到编码器中,得到表征目标车辆及其周围车辆的轨迹历史语义向量和隐藏向量.继而,由解码器分析语义向量和隐藏向量并最终生成目标车辆的未来轨迹.
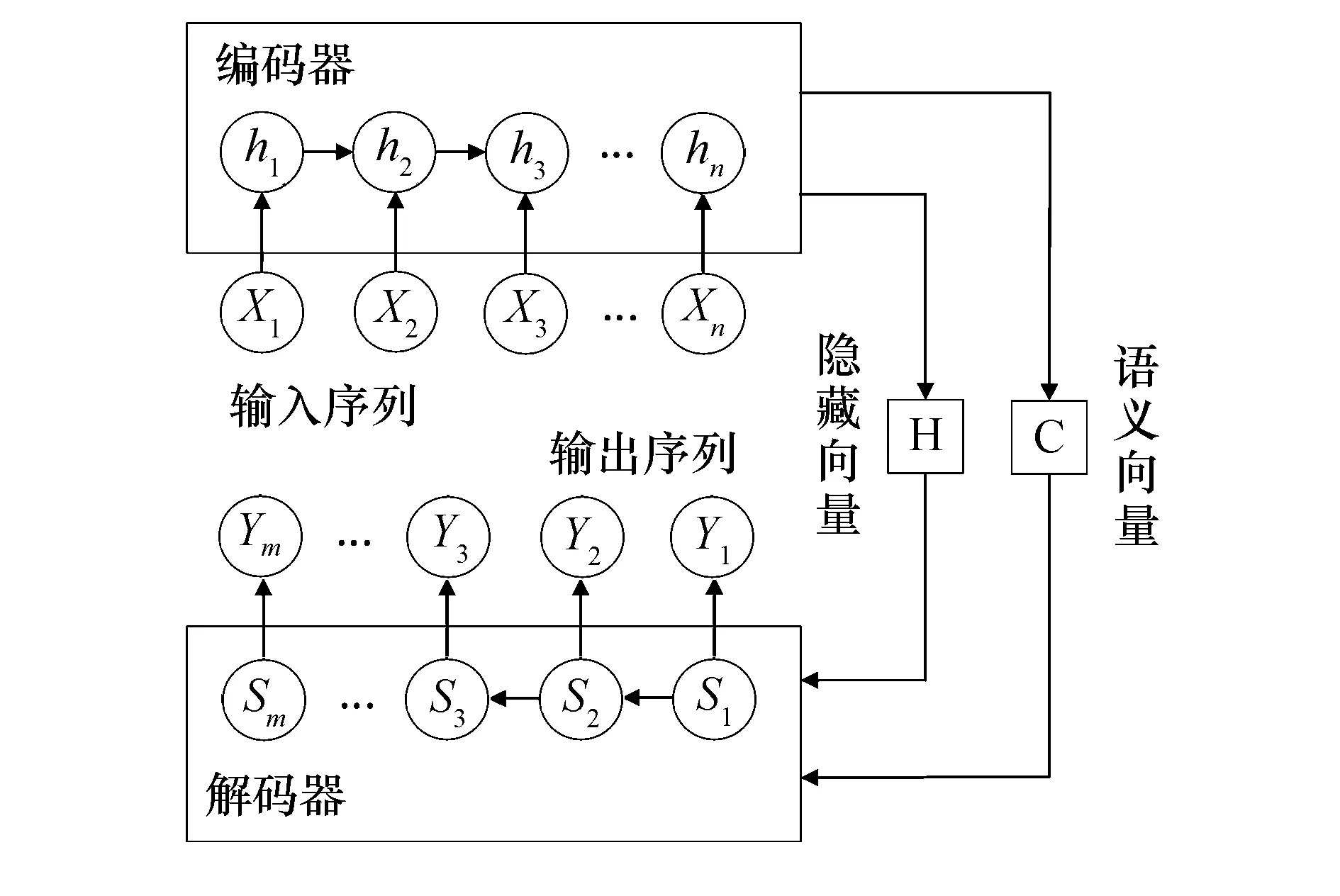
图3 编码器-解码器模型
本文的研究对象为目标车辆及其感知到的周围车辆个体,其历史轨迹用时间序列表示为
Xt=[xt-th,…,xt-1,xt]
(6)
式中:th为历史轨迹的时间长度;xt为研究对象在t时刻的坐标位置,且
(7)
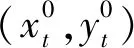
(8)
其中:Φ(·)为嵌入函数;Wrel为嵌入权重.其次,将该嵌入层向量处理为LSTM单元进行时间信息的传递:
(9)

(10)
其中:Wdec为LSTM的解码权重.目标车辆的预测轨迹为
(11)
是目标车辆从t+1时刻到t+m时刻由神经网络预测出的坐标位置.其中:(xt+1,yt+1)为目标车辆在t+1时刻的横向和纵向坐标.
2.3 预测误差分析
解码器在每一时刻的LSTM输出代表了当前预测的横向和纵向坐标.LSTM的迭代性质使用上一时刻的输出作为下一时刻的输入,如图4所示.这样,预测误差随时间传递和积累,导致输出误差随预测时间逐渐增加,直至序列的发散[22].误差的绝对值可以表示为
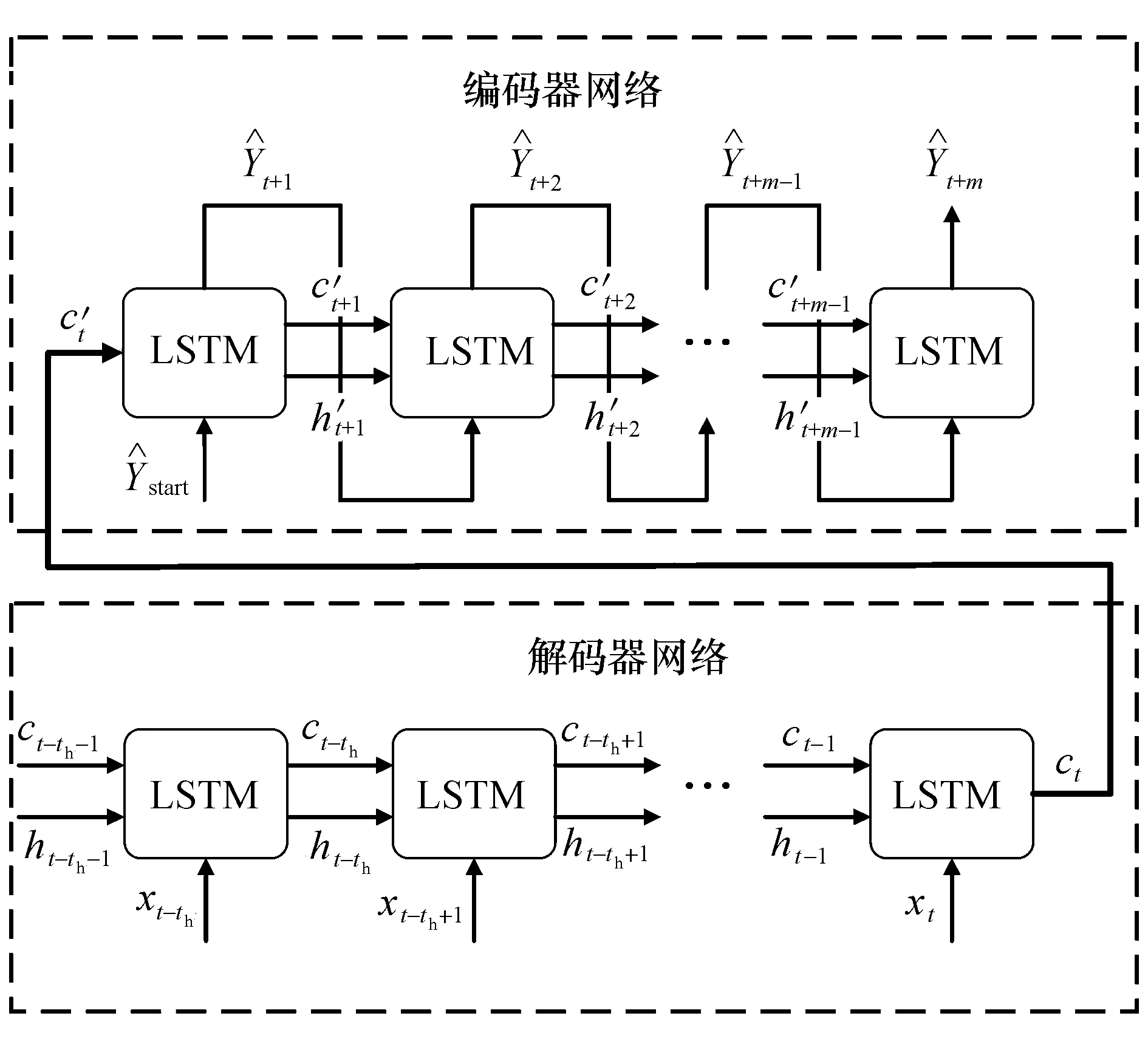
图4 LSTM网络迭代误差分析
(12)

Δt+m>…>Δt+2>Δt+1
(13)
其中:m为轨迹预测的时间长度,误差随时间不断增大,轨迹预测的精度逐渐降低.因此,如何减小LSTM深度学习方法在轨迹预测过程中的累积误差是一个关键性问题.
3 问题定义及其提出的方法
3.1 目标函数
本文基于LSTM网络预测目标车辆的运动轨迹,车辆的预测轨迹最终由行为编码器编码得到.而现有的行为预测编码器利用LSTM等迭代求解,迭代过程导致累积误差增加,预测误差随预测时长增加.在图5所示的曲线图中,目标车辆预测轨迹和真实轨迹之间的误差随时间增长幅度大,难以准确预测目标车辆的未来轨迹.
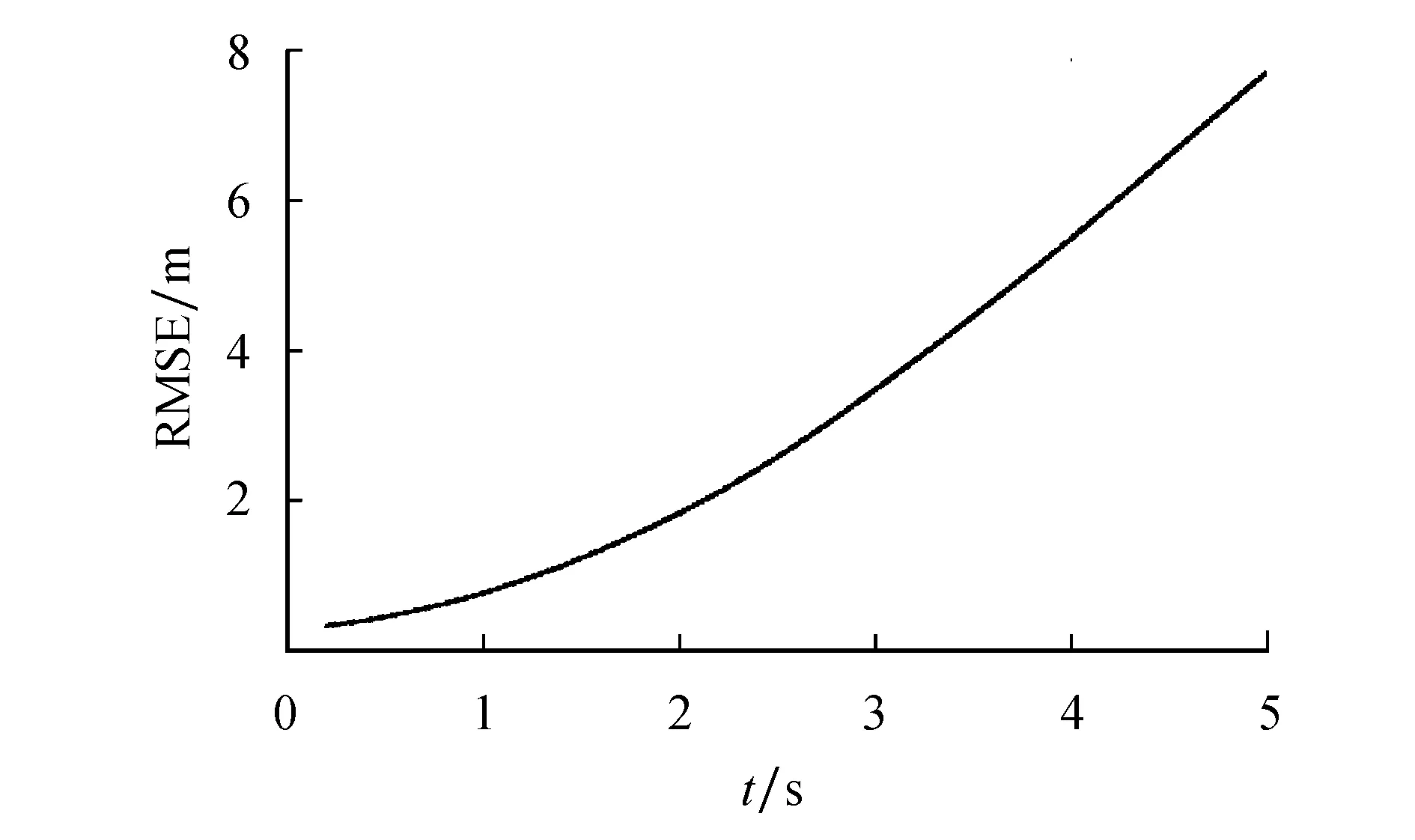
图5 LSTM网络迭代求解过程中轨迹预测的误差
本文的目标是优化由于LSTM导致的累积误差及初始预测误差,该目标可用以下目标函数描述:
C=min[|Δt+m-Δt|+|Δt|]
(14)
约束条件为
式(14)中目标函数有两部分组成,第一部分|Δt+m-Δt|为LSTM的累积误差,第二部分|Δt|为第一步预测误差.选用该目标函数的目的是降低LSTM累积误差及模型预测误差.式(14,15)为约束条件,保证所有误差都大于零.
3.2 提出的方法
针对回归问题,平方损失函数常被选作损失函数训练模型,利用梯度优化求解模型参数.然而,传统的平方损失函数没有考虑误差重要性的差别,假设所有的误差具有相同的权重,因此无法对累积误差进行修正.绝对值损失函数和指数损失函数也具有同样的问题,无法解决累积误差问题.
为了降低累积误差以提高模型在所有时间点的预测精度,本文通过拟定合适的损失策略,使损失函数更好地反映误差的分布规律,并最终指向对结果更有益的模型训练方向.本文采用与误差具有相同趋势的权重函数对误差进行加权,通过加大对较高误差点的权重来降低模型预测的累积误差,从而提高模型的预测精度.
具体地说,本文通过采用随预测时间增长的指数函数对平滑的L1(smooth L1)损失函数加权来定义损失函数,即在样本的每个时间步的损失值前分配反映时间信息的指数权重项.即,本文通过在smooth L1损失函数的基础上乘以指数项,修正损失函数,使得损失函数随时间呈指数增长:
(17)
(18)
由于加权损失项的值随着时间不断增大,而LSTM编码器-解码器模型的输出误差随时间累积,因此,本文定义的损失函数对累积误差的惩罚也随时间不断增大,提高了损失函数对累积误差的敏感度,进而反馈到神经网络调整相关的参数,使模型的预测误差减小.同时,通过指数权重使损失函数对整体误差的惩罚力度变小,降低了误差方向突变对梯度优化的影响,从一定程度上起到了正则化的效果,降低了过拟合的风险.
为进一步提高梯度优化的鲁棒性,本文引入了平滑的L1损失函数.如图6所示,平滑的L1损失函数实质是一个分段函数,在[-1,1]区间内表现为均方误差(L2)损失函数的特征,解决了均绝对误差(L1)损失函数的不光滑问题;在[-1,1]区间外表现为均绝对误差损失函数的特征,解决了离群点梯度爆炸的问题.因此,平滑的L1损失函数结合了均绝对误差和均方误差损失函数的优势.当预测值与真实值之间的差异较大时,平滑的L1损失函数的梯度变化小,避免了均方误差损失函数在模型训练初期由于梯度变化过大导致的训练不稳定现象.此外,当预测值与真实值之间的差异较小时,平滑的L1损失函数的梯度变化平滑,避免了均绝对误差损失函数在训练后期由于梯度变化过大导致的模型无法正常收敛的问题.在此基础上,平滑的L1损失函数的稳定性和快速性均得到了保障,同时避免了梯度过大造成的误差突变,模型的训练速度和精度得以提高.
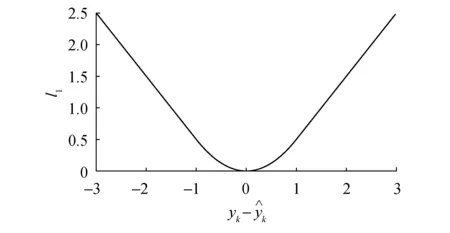
图6 平滑的L1损失函数
3.3 实验设置
3.3.1数据集选取及预处理
本文采用美国交通部下一代仿真(NGSIM)计划数据集.NGSIM数据集包含了结构化道路路口、高速上下闸道等区域.该数据集由摄像头在美国的US-101号公路、I-80号公路、Lankershim Boulevard以及Peachtree Street四个不同地区采集获得.摄像头采集的数据被加工为每个车辆的轨迹点并予以记录,最终包含了交通流中每辆车的行驶轨迹.
为提高模型泛化能力,本文选择NGSIM的US-101[23]和I-80[24]两个数据集作为模型建立的原始数据,并将这两个数据集合并为一个整体对样本进行训练和测试.此外,NGSIM数据中车辆种类包括摩托车、小型汽车和卡车.对于不同类型的车辆,外廓尺寸与车辆动力性的对应关系差别较大.为排除摩托车和卡车对模型造成的干扰,研究中仅使用Class项为2(小型汽车)的数据记录.
US-101和I-80数据集共有830万个样本,70%用于训练,10%用于验证,20%用于测试[25].使用被预测车辆在过去3 s的坐标信息及网格占用信息作为神经网络的输入,测试其在未来5 s的运动轨迹.其中每个网格单元都是标准车辆的大小.为了降低模型复杂度,本文对样本的历史轨迹和未来轨迹进行降采样.原始数据集中采样频率为10 Hz,即每秒包括10个点.本文每隔0.2 s选取一个点保留,最终样本包括3 s共16个点的历史轨迹和5 s共25个点的未来轨迹.
3.3.2模型训练设置
本文将模型在NVIDIA GTX1050Ti显卡上训练.训练时使用ADAM算法对神经网络进行优化,模型迭代次数(number of epochs)为4 000;学习率设定为0.001;一次批训练所选取的样本数(batch size)设定为128;并且参数在所有实验中保持不变.实验时采用本文提出的指数函数加权的损失函数进行训练.
3.4 模型评估方法
为了评估模型预测的准确性,本文将最终得到的预测轨迹与真实轨迹的均方误差的平方根作为模型的评价指标.此外,为了更好地评估模型的测试充分性,本文从US-101和I-80数据集中选取与训练集不同的20%用于测试.
均方根误差(RMSE)是在模型预测的准确性中一个切实可行的衡量标准[26].均方根误差的表达式为
(19)
3.5 实验结果分析
3.5.1基准模型
本文采用经典的CS-LSTM轨迹预测算法作为对比的基准模型[26].CS-LSTM在LSTM编码器-解码器模型的基础上,引入卷积社交池化层,并将目标车辆及其周围车辆的历史位置信息通过卷积网格表征.这样,模型可以在保证车辆空间相对位置不变性的同时模拟车辆交互.在此基础上,CS-LSTM应用LSTM解码器预测未来轨迹.
3.5.2对比基准
为了验证本文所提出方法的改进效果,本文将原始模型的损失函数作为基准.损失函数如下:
(20)

3.5.3模型整体偏差对比
基准模型CS-LSTM的行为预测编码器利用LSTM迭代求解,迭代过程导致累积误差增加.因此,基准模型的预测误差随预测时长增加,从而轨迹预测的精度随预测时长降低.本文采用均方根误差(RMSE)对模型进行评估,从而对基准模型和本文提出的模型在5 s范围内的预测轨迹作对比,得出轨迹预测均方根误差对比效果.如表1所列,每隔0.2s统计一次结果,最后得出25个点的均方根误差值并作统计.由表1可知,对于基准模型,随着预测时间的推移,模型的均方根误差不断增加,由0.2 s的0.332 0 m增长为5 s的7.716 8 m,增加了22.3倍.

表1 基准模型各点的均方误差值
表2为本文提出的模型在各个时间点处预测值相对真实值的均方根误差.可以看到,本文提出模型的均方根误差值明显低于基准模型的.本文提出的模型的均方误差在0.2 s的误差由0.332 0 m降低到了0.103 2 m,并且在5 s的误差由7.716 8 m降低到了6.624 3 m,表明了所提出方法的有效性.因此,随着对损失函数的改进,预测轨迹相对真实轨迹的偏离程度减小,单个时间点和整体的误差都有所减小.这是由于加入指数加权的损失函数后,随着预测值和真实值差距的增加,指数加权的损失函数的值增加,损失对LSTM的惩罚也相应呈指数增长.损失对LSTM的惩罚通过神经元之间的反馈,使得均方误差较基准模型有所降低.
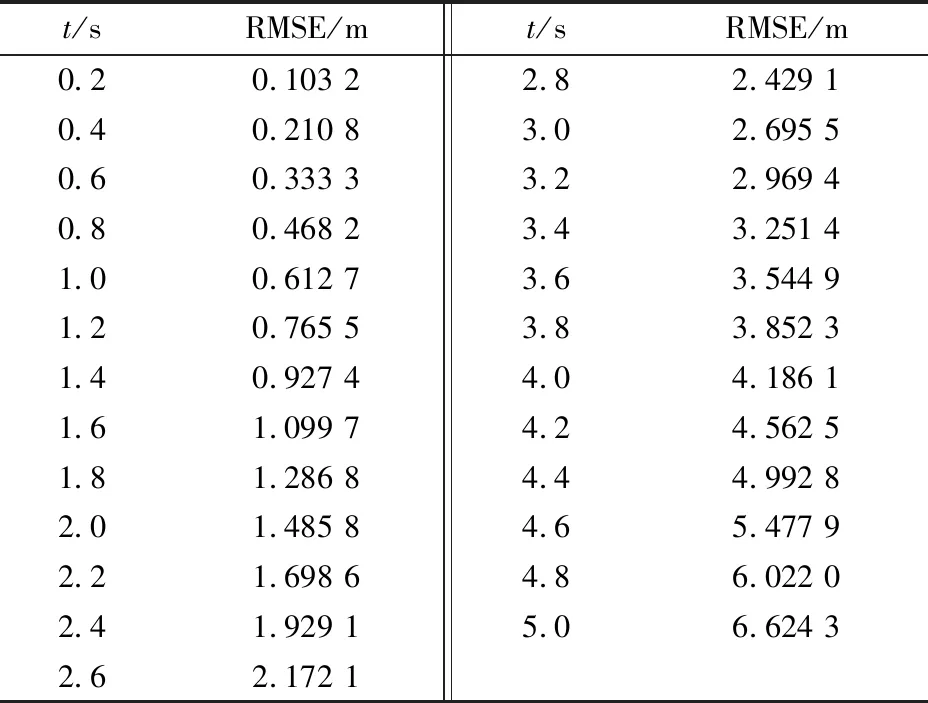
表2 本文提出的模型各点的均方误差值
图7所示为基准模型和本文提出的模型预测轨迹相对真实轨迹的均方误差对比.可以看到,在引入指数加权的损失函数后,模型的累计均方误差由原来的7.716 8 m降为6.624 3 m,总体上比原来降低了14.16%.因此,本文提出的模型算法的误差更小,其对车辆的轨迹预测更准确.

图7 基准模型和本文提出的模型预测值相对真实值的均方根误差对比
4 结语
本文分析了将LSTM用于车辆轨迹预测过程中累积误差的产生原因,并提出了应用指数加权的损失函数来解决问题的方法.在NGSIM US-101和I-80驾驶数据集上的实验表明,与常用的未加权对应的平方损失函数相比,累积误差在全局范围内得以下降,轨迹预测精度有了显著提高.虽然在这项研究中仅限于特定的数据集的选择,但指数函数加权方法与数据集无关,本文提出的方法有广泛的适用性.
猜你喜欢
小学生必读(低年级版)(2021年10期)2022-01-18
小学生必读(低年级版)(2021年11期)2021-03-09
小学生必读(低年级版)(2021年12期)2021-03-04
读友·少年文学(清雅版)(2020年4期)2020-08-24
读友·少年文学(清雅版)(2020年3期)2020-07-24
家庭影院技术(2019年8期)2019-12-04
成都信息工程大学学报(2018年3期)2018-08-29
现代装饰(2018年5期)2018-05-26
中国三峡(2017年2期)2017-06-09
电子设计工程(2017年20期)2017-02-10
