
基于大规模语言模型的知识图谱可微规则抽取
2023-10-29 04:20潘雨黛张玲玲蔡忠闽赵天哲魏笔凡
计算机与生活 2023年10期
潘雨黛,张玲玲,蔡忠闽,赵天哲,魏笔凡,刘 均
1.西安交通大学 计算机科学与技术学院,西安 710049
2.陕西省大数据知识工程重点实验室,西安 710049
3.西安交通大学 系统工程研究所,西安 710049
知识图谱(knowledge graph,KG)通过由实体和关系组成的三元组(头实体,关系,尾实体)来存储大量事实,例如经典的通用知识图谱YAGO(yet another great ontology)[1]、DBpedia[2]和Wikidata[3]等。知识图谱上的推理是预测不完整三元组中缺失的实体或关系,并用于各种下游任务,如信息抽取[4]、语义检索[5]、问答任务[6]和对话系统[7]等。典型的知识图谱推理方法主要针对于关系和实体的表征与嵌入[8],如TransE[9]和RESCAL[10]等方法。然而,这些基于实体与关系表征的推理方法属于黑盒模型,在推理过程中缺乏一定的可解释性。因此在近几年的知识图谱推理中,规则学习已成为被广泛研究的一种可解释范式[11]。规则学习的方法旨在从结构化的知识图谱中抽取一阶逻辑规则,并将其运用于知识图谱的补全与推理等任务中。
从知识图谱中抽取的一阶逻辑(first-order logic,FOL)规则以霍恩子句(Horn clause)[12]的形式呈现如下:
其中,bornInCity(X,Z)为构成规则的原子公式,知识图谱中的关系bornInCity 在规则中为组成原子公式的谓词。X、Y、Z为从知识图谱中的实体泛化而来的变量。蕴含符号→从规则体指向规则头,指代从条件到结论的推理过程。但是在从知识图谱中抽取规则的过程中,依然有以下几个问题。
第一,一阶逻辑规则的结构信息表示为离散的符号,而知识图谱上的推理大多由连续的嵌入向量来实现。不管是基于翻译模型的方法,还是基于图网络的方法,知识图谱上的推理都需要将实体与关系表示成为连续的低维向量,而后通过最大化得分函数的值来进行推理。如何将离散的符号信息与连续的向量空间进行融合,实现可解释的知识图谱上的推理是一个挑战。
第二,在实现可微推理的过程中,使用的一阶逻辑规则不仅需要从三元组中泛化得到,同时需要考虑构成一阶逻辑规则的原子公式的顺序以及变量信息。改变原子公式的顺序会对可微推理的结果产生巨大影响。比如,对于一阶逻辑规则:
该规则表示X是Z的兄弟,且Z是Y的父亲,则X是Y的叔叔(伯伯)。如果将规则体中的原子公式进行顺序的调换:
该规则表示的是X是Z的父亲,且Z是Y的兄弟,则X是Y的叔叔(伯伯)。显然,该规则是不合理的。如何将正确的原子公式信息融入推理过程是一个难点。
因此,提出了一种融合大规模预训练语言模型的可微推理方法DRaM 来解决以上问题。为解决连续空间与离散空间的融合问题,使用一种可微的推理范式来将连续的嵌入推理过程与离散的规则符号进行融合;在编码过程中,为解决一阶逻辑规则中原子公式的顺序问题,设计了一种基于大规模语言模型(large language model,LLM)的编码方法。最终通过评估与最大化推理过程的得分来对连续的模型进行优化。
DRaM做出了以下三个贡献:
(1)提出了一种知识图谱上的可微推理方法DRaM,通过将嵌入向量与一阶逻辑规则进行融合,缓解连续空间与离散空间的语义鸿沟。
(2)引入大规模预训练语言模型的可微推理,融合了一阶逻辑规则中的顺序信息,使得一阶逻辑规则更准确地提升可微推理的结果。
(3)通过在三个知识图谱数据集上进行链接预测,验证了DRaM的可行性与有效性。同时通过抽取出的规则及其置信度,增强可微推理过程的可解释性。
1 相关工作
1.1 知识图谱上的表示学习方法
知识图谱上的表示学习方法通过对知识图谱中的实体与关系进行嵌入表示,来用于下游推理任务。该方法主要可以分为三类,分别为基于翻译模型的方法、基于语义分解的方法以及基于图网络的方法。
基于翻译模型的表示学习将知识图谱中的实体与关系表示为低维向量。在知识图谱表示中广泛使用的算法包含TransE[9]、RotatE[13]和ConvE[14]。RESCAL[10]、HolE[15]和DisMult[16]是基于语义分解的表示学习方法,将每个实体的语义信息表示为低维向量,且将每个关系表示为一个矩阵。这些方法通过嵌入模型来处理每个三元组,从而获得知识图谱中关系和实体的低维嵌入。此外,考虑到知识图谱中的结构信息和邻居信息,一些模型通过图神经网络表示整个知识图谱。例如,R-GCN[17]和CompGCN[18]使用图卷积网络(graph convolutional network,GCN)来捕获邻居信息对关系进行建模。另外,一些融合文本嵌入信息的模型,例如pTransE[19]、DKRL[20]和StAR[21]同样可以通过得到嵌入向量来解决知识图谱上的推理问题。
1.2 知识图谱上的规则学习方法
知识图谱上的规则学习方法主要可以分为两类,分别为基于统计的方法和基于深度学习的方法。
1.2.1 基于统计方法的规则学习方法
最早的规则学习研究始于利用统计方法抽取一阶逻辑规则。此类方法通过不同度量方式,比如支持度(support)、置信度(confidence)、相对概率估计(relative probability estimate)和其他简单的度量方式筛选高质量的一阶逻辑规则。比如,一阶逻辑学习方法SHERLOCK[22]使用逐点互信息(pointwise mutual information,PMI)作为评估指标,并使用相对概率估计来评估Horn子句,以此抽取合理的一阶逻辑规则。此外,Galarraga 等人提出的AMIE[23]和AMIE+[24]算法,通过计算部分完整性假设(partial completeness assumption,PCA)置信度从知识库(knowledge base,KB)和知识图谱中挖掘相关规则。AnyBURL[25]提取有效时间跨度内的规则,并通过置信度在更短的时间内获取有效的一阶逻辑规则。与AMIE与AMIE+算法相比,AnyBURL 的推理结果在性能上有所提高,但抽取的结果并不稳定。
1.2.2 基于深度学习的规则学习方法
随着深度学习与知识图谱表示学习的发展,一些规则学习方法融合深度学习,进一步从知识图谱的事实中抽取一阶逻辑规则。基于深度学习的规则学习方法例如RLvLR[26],是通过知识图谱中关系与实体的嵌入表示来从大量一阶逻辑规则中进行筛选。RLvLR调用知识图谱表征的RESCAL模型来减少规则的搜索空间。Ho等人[27]不仅通过知识图谱中已知的事实,并且通过从知识图谱中抽取的规则推理出的事实来扩展规则。在此过程中,模型通过不同的知识图谱表征模型来评估所添加的事实。此外,最近的规则学习方法也提出了针对逻辑规则的可微学习。例如,Yang 等人[28]提出了NeuralLP 来学习知识图谱中的一阶逻辑规则,提出了一种神经控制器系统来构成一阶规则中的可微运算。Sadeghian等人[29]通过改进NeuralLP 提出DRUM 算法,利用双向循环神经网络(recurrent neural network,RNN)实现端到端的可微规则抽取。
1.2.3 基于大规模语言模型的规则抽取
随着大规模语言模型在自然语言处理问题上获得的优秀结果,一些规则抽取方法利用大规模语言模型的表征学习能力来提升推理过程的可解释性。在逻辑文本的推理任务中,一些基于大规模语言模型的方法[30-31]通过挖掘上下文中的逻辑关系来抽取逻辑规则。例如,Logiformer[32]构建了两种不同的基于Transformer 的图网络,通过挖掘文本中的逻辑规则解决逻辑推理问题。在知识图谱的逻辑规则抽取中,大规模语言模型被用来提升实体与关系的表征,进而增强规则抽取的结果。例如,Lotus[33]利用已有的语言模型对实体的外部文本进行表征,通过融合知识图谱的结构信息与文本语义信息抽取高质量规则。相较于传统方法,此类方法不仅可以通过大语言模型构成可微的端到端规则抽取模型,并且更专注于利用大规模语言模型中的Transformer模块对一阶逻辑规则的原子公式以及序列进行编码,更有利于一阶逻辑规则的表征与抽取,进而增强逻辑推理的结果。
然而,目前的方法没有利用大规模语言模型构建出一个端到端的可微模型在知识图谱中抽取一阶逻辑规则。
2 方法
本文针对知识图谱上的推理任务,提出了一种端到端的具有可解释性的可微规则学习方法DRaM。此方法分为两部分:可微推理以及规则学习。
2.1 问题定义
知识图谱上的推理定义如下:给定知识图谱G={R,E,T},其中T⊂E×R×E为知识图谱中的三元组集合,E为实体集合,R为关系集合。通过规则学习的方法抽取形式为式(1)的一阶逻辑规则集合C。C中提取的规则可用于实现可微的知识图谱上的推理,即预测三元组中缺失的实体,例如r(h,?)或者r(?,t)。图1显示了解决此任务的模型的具体实现方法。
2.2 可微推理
不同于经典的基于黑盒的表示学习方法进行的知识图谱的推理,基于规则的可微推理需要解决推理过程中的实体无关性问题。比如,在利用规则(1)进行推理时,G中的三元组cityOf(Beijing,P.R.C.)和cityOf(LA,U.S.)会泛化为原子公式cityOf(X,Y),以此解决实体无关性问题。DRaM 不同于基于统计计算的规则学习方法,它将包含置信度的离散的逻辑规则与连续的嵌入空间融合,通过梯度来对模型进行优化。
在规则学习融合可微推理的过程中,若将作为推理结果的原子公式看作一个问题query,则利用一个一阶逻辑规则推理的过程如下:
其中,r1,r2,…,rn作为一阶逻辑规则中的谓词,其实质为知识图谱G中的关系。此时,根据TensorLog框架[34],基于逻辑规则的推理可以用矩阵与向量的乘法来实现。
在推理过程中,对于给定的问题query 和已知的实体x,不同结果y的得分为规则集合中能够得到结果y的所有规则的置信度之和。根据TensorLog 框架,在推理过程中,形如规则(4)的规则体可量化为:
其中,αm为第m个可能规则的置信度;βm为第m个规则的结构信息,主要由n个有顺序的关系序列(r1,r2,…rn) 构成;Mrk为rk的谓词矩阵,矩阵元素Mrk[i,j]的初始值为:
可微的推理过程旨在将融合规则的推理过程通过梯度下降来进行优化,因此在此过程中,将推理过程的得分函数f(y|x)定义为:
其中,ex向量初始值为将实体x映射成为one-hot 编码,其第x个元素值为1;ey同理。此过程可举例如下,对于规则(1)中规则体的推理过程bornIn-City(X,Z)∧cityOf(Z,Y),可以将实体转化为向量,关系转化为谓词矩阵,并通过矩阵的乘法来模拟实例化的逻辑规则推理过程,表示为MbornInCity×McityOf×ey。进行矩阵与向量的乘法后,向量中非零项位置与ex相同的话,说明通过该规则可以得到从实体y到实体x的推理结果。规则的长度可以根据推理过程中做乘法的矩阵个数来实现。可微推理进行梯度优化的目标是将所有满足query实体对的得分最大化:
其中,x、y分别为满足query(X,Y)中变量X、Y的头、尾实体。αm、βm分别代表学习到的规则的置信度与结构信息。通过这两个参数可以确定用于推理的一阶逻辑规则,该参数是在优化推理模型的过程中进行学习优化的。
然而,从式(5)来看,该得分函数依旧是离散的形式,不利于进行可微推理。因此,若将式(5)转化为注意力权重的形式,则该权重可以进行可微学习:
2.3 规则学习
根据上述得分函数的形式,考虑到规则的长度L可以进行变化,采用预训练模型来对query的序列进行编码,如图2 所示。在query 的最后加入可学习的token,[END]。对于长度为L+1(L>0)的输入q1,q2,…,qL,[END],将其送入预训练语言模型M,得到隐藏层的输出:
利用多层感知机(multilayer perceptron,MLP)模型进行维度的调整:
通过隐藏层的输出向量,得到推理过程中所用到的规则参数{al|1 ≤l≤L}和{bl|1 ≤l≤L+1}:
其中,W为可学习的转换矩阵,ϕ为偏置向量。由两个注意力al和bl,可以得到求解query时规则体的第l个谓词的向量:
当l′为0时,初始推理向量为ey。对于用于推理的规则,每一个在规则体序列中的原子公式代表推理的“一步”l。因此,最终可微的得分函数可表示为:
通过最大化可微推理过程中的得分函数,可以得到增强知识图谱上的推理过程的规则。参考NeuralLP 中的规则还原算法,从两个注意力参数al和bl抽取显式的规则。最终,通过该算法得到每个可能规则的αm、βm,并将连续的向量al和bl恢复为离散的一阶逻辑规则。
3 实验结果
本文比较了DRaM 与经典的知识图谱上的推理方法,包含基于表示学习以及基于规则学习的方法。另外,通过消融学习证明了DRaM的有效性。最后,通过其他实验,包括参数分析以及案例分析实验,验证了该方法的效果。
3.1 数据集与基线方法
知识图谱上的可微推理实验在三个不同的数据集上进行[35]。统一医学语言系统(unified medical language system,UMLS)由生物医学中的概念组成,如药物和疾病名称,以及它们之间的关系,比如如何诊断及治疗。亲属关系(Kinship)中的三元组为澳大利亚中部土著部落成员之间的亲属关系。家族数据集(Family)包含多个家族个体之间的血缘关系。每个数据集的信息如表1所示。

表1 数据集信息Table 1 Dataset statistics
在对比过程中,选择了经典且具有代表性的知识图谱上的推理方法作为基线方法。这些方法具体分为两类,分别是可微推理方法与表示学习方法。
可微推理方法:NeuralLP 和DRUM 为知识图谱上的可微推理方法。NeuralLP 提出一种神经控制系统,在知识图谱的推理过程中,可微地挖掘一阶逻辑规则。DRUM通过利用双向循环神经网络(BiRNN)对NeuralLP进行拓展。
表示学习方法:选择了最普遍的基于表示学习的方法进行推理性能的比较。此种方法包含基于翻译模型的方法、基于语义分解的方法、基于卷积层与全连接层的方法以及基于预训练语言模型的方法。
(1)基于翻译模型的方法利用分布式表示来描述知识库中的三元组,如TransE[9]、TransH[36]、TransR[37]、TransD[38];
(2)基于语义分解的方法将知识库中关系表示为矩阵,如DisMult[16]、ComplEx[39];
(3)基于卷积层的方法解决全连接层在训练时的过拟合问题,如ConvE[14];
(4)基于预训练语言模型的方法通过对三元组语义信息以及结构信息编码来对知识图谱进行表示,如KG-BERT[40]与StAR[21]。
3.2 实验指标与参数设置
正如之前的介绍,实验通过知识图谱上的推理结果来判断模型的有效性。知识图谱上的推理通常为链接预测,用以下几个指标来评估有效性:Hits@k,平均倒数排名(mean reciprocal ranking,MRR),平均排名(mean ranking,MR)。
Hits@k表示测试集S中目标三元组的得分在候选三元组中得分排名在前k个的比例:
MRR计算目标三元组在候选三元组中排名的平均倒数:
MR 计算目标三元组在候选三元组中排名的平均倒数:
本节使用Hits@1、Hits@10 和MRR 来全面展示DRaM的有效性。
该方法实现的硬件环境是Tesla V100 GPU。深度学习的平台为Python 3.6 与tensorflow1.14。其他参数设置如下:预训练模型含有12 个Transformer层、768维隐藏层以及12个多头注意力机制。最大序列长度为256,学习率为0.1,训练批次为64,Dropout为0.1,优化器选择Adam[41],迭代次数为10。
3.3 不同模型的性能对比
对于可微的知识图谱上的推理,将DRaM与其他方法进行性能比较,具体结果如表2和表3所示。

表2 可微推理比较结果Table 2 Comparison results of differentiable reasoning
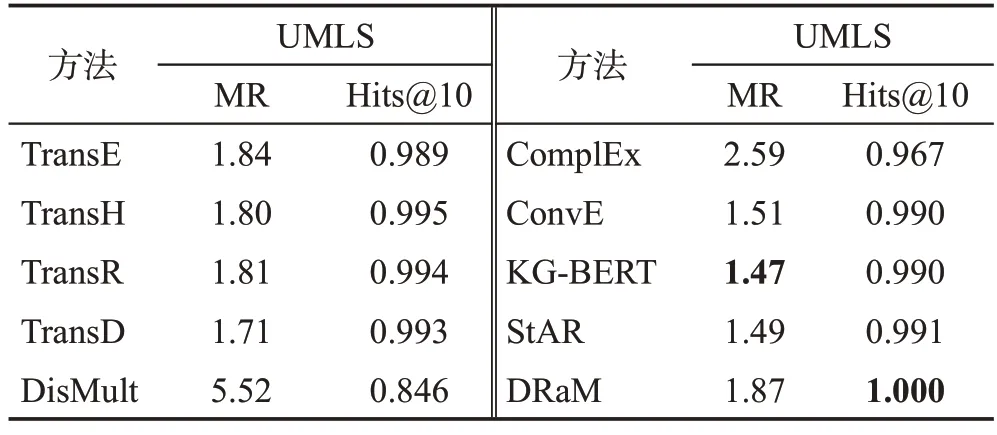
表3 可微推理与表示学习方法比较结果Table 3 Comparison results of differentiable reasoning and representation learning
(1)与可微推理方法结果比较
表2中的结果说明了DRaM在链接预测中能取得有竞争力的效果。例如,与经典的可微方法NeuralLP和DRUM比较,对于链接预测的指标Hits@1与MRR,虽然没有达到最优结果,但是对于Hits@3 与Hits@10,DRaM几乎已经达到最佳的推理结果。尤其在数据集Kinship上,Hits@3与Hits@10已经到达了1.00,充分说明了DRaM 的有效性。造成这种结果的原因可能是大语言模型对于计算三元组的得分函数上有很大的帮助,而链接预测的排名是由模型中的得分函数来进行排序,因此所有三元组的整体得分排名都在前10。但是对于每个三元组预测时的准确率,也就是Hits@1,还有待提高。
DRaM 在三个数据集上MRR 与Hits@1 的推理结果相较其他基线方法结果较低。两个指标相较于Hits@3 和Hits@10 主要反映了三元组得分的准确程度。出现该现象主要原因是大规模语言模型的编码部分会被数据集中谓词的频率影响[42]。在DRaM中,可微的规则抽取过程会将推理过程用一阶逻辑公式(4)来表示,从而通过谓词向量得到推理向量,并得到推理过程中抽取到的规则与其置信度。而对于Family 数据集,有限的关系个数会导致有限的谓词,每个谓词出现频率不同,会对query 的表征产生偏差。在Family 数据集中,12 个谓词不足以涵盖所有的家庭成员关系。例如,以下一阶逻辑对应的推理过程:
在12 个谓词中没有可以正确匹配father_in_law 语义的答案。因此,在对query表征时不同谓词出现频率会使大规模语言模型影响表征结果,进而影响抽取的一阶逻辑规则与三元组的得分,尤其是影响得分的准确程度,如MRR 与Hits@1 的结果。而对于Hits@3和Hits@10,尽管不能准确得到其得分,但query的语义信息也与谓词father_in_law语义有一定的相似性。
(2)与表示学习方法结果比较
表3 中的结果说明了DRaM 与基于表示学习的方法相比也能取得较好的结果。例如,对于平均排名指标MR,相比于基于翻译模型和基于语义分解的方法,DRaM可以得到具有竞争力的结果。对比同样引入大语言模型的方法KG-BERT和StAR,虽然指标MR略低于这两种方法,但是对于Hits@10,不管是基于翻译模型、基于语义分解模型的方法,还是基于大语言模型的方法,DRaM都可以得到最优的结果。同时,将DRaM 与黑盒的表示学习方法比较,可以获得一阶逻辑规则,为知识图谱上的推理过程提供可解释性。
3.4 消融实验
表4 的结果说明了在DRaM 中运用大规模预训练语言模型LLM与MLP的作用,同时在UMLS数据集上进行了消融实验。分别去掉LLM以及MLP后的两种方法表示为“DRaM-w/o-LLM”和“DRaM-w/o-MLP”。通过知识图谱上的推理结果可以看到,当去掉LLM后,链接预测指标Hits@10下降了16.0个百分点,MR 上升了375.9%。去掉MLP后,链接预测指标Hits@10下降了35.7个百分点,MR上升了628.9%。由此结果可以验证DRaM中主要模块的有效性。
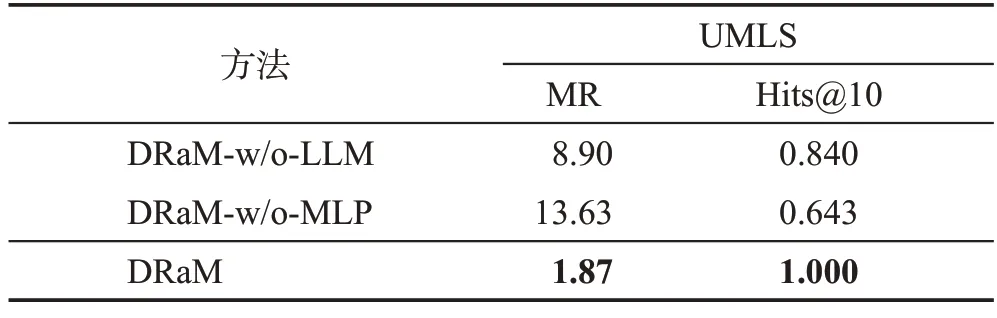
表4 消融实验结果Table 4 Ablation experiment results
3.5 参数分析
本节通过对重要参数的分析来说明参数选值对可微推理的重要性。
(1)对规则最大长度的分析
在DRaM中,通过抽取一阶逻辑规则来进行可微推理。这一过程中,规则的长度以及数量会影响可微推理的效果。图3(a)记录了当抽取的规则最大长度L=2,3,4 时对链接预测结果的影响。从推理结果可以看出,当L=3 时,DRaM可以获得最佳的推理效果。这说明完整且较长的一阶逻辑规则可以得到更好的推理结果,但是过多的规则也会存在噪声,影响模型效果。
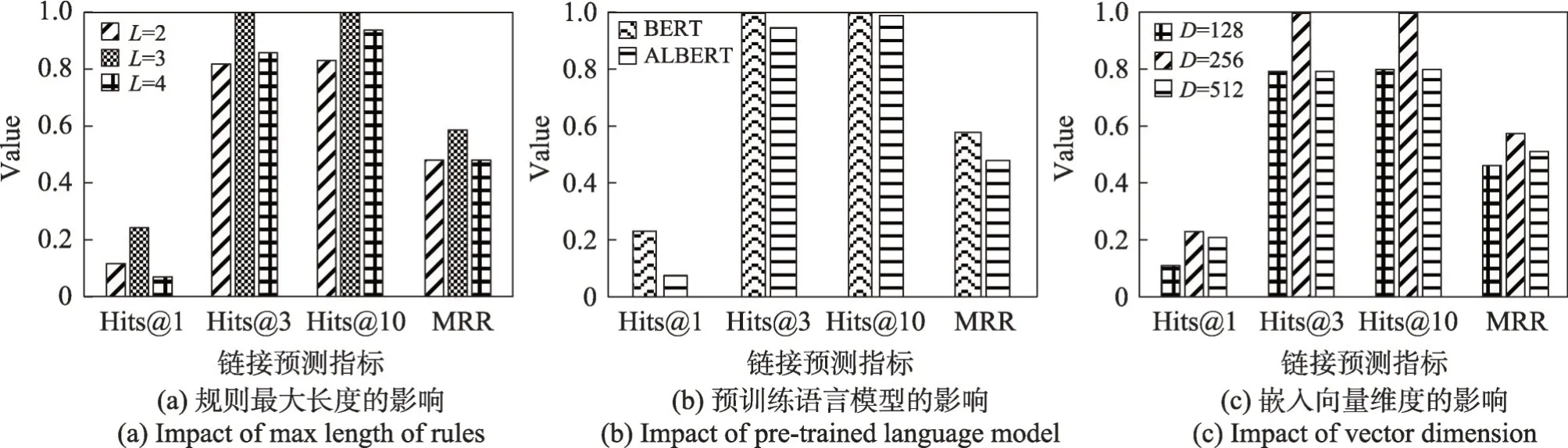
图3 不同参数对DRaM可微推理结果的影响Fig.3 Impact of different parameters on differentiable reasoning by DRaM
(2)对预训练语言模型类别的分析
考虑到方法实现的效率与复杂度,比较了不同的大规模语言模型对可微推理结果的影响。这里,选择BERT(bidirectional encoder representation from transformers)[43]和轻量级的ALBERT(a lite bidirectional encoder representation from transformers)[44]作为预训练语言模型对DRaM 进行编码。如图3(b)所示,可以看出,不同的LLM 会影响可微推理的结果。对于4个链接预测指标,Hits@1 在使用ALBERT 时相比较BERT 结果较低,其他指标如Hits@3、Hits@10 和MRR只是略低于BERT。
(3)对嵌入向量维度的分析
除此之外,比较了不同的嵌入向量维度对可微推理结果的影响。如图3(c)所示,记录了当嵌入向量维度分别为128、256 以及512 时链接预测的结果。从记录的结果可以得到,当维度为128 时,链接预测中的Hits@1 指标较低。而当维度为512 时,Hits@1同样会有较为明显的下降。当嵌入向量维度为256时,DRaM可以得到最好的可微推理结果。这说明嵌入向量的维度会对三元组的得分以及链接预测的准确率有较大影响。
3.6 可解释性与规则抽取
DRaM 在进行可微推理的时候可以抽取出一阶逻辑规则。每个一阶逻辑规则都有置信度来表示其合理性。表5 为在数据集UMLS 和Family 进行可微推理的过程中,DRaM抽取出的一阶逻辑规则。如表中所示,当query 为Isa 时,抽取出的置信度更高的规则更加合理。比如,对于规则Isa(B,A)←equal(B,A),置信度值为1,这条规则是一条正确的规则。而对于置信度为0.5 的规则Isa(C,A)←Indicates(C,B) ∧Indicates(B,A),Indicates(C,B)意为“表示”,但不代表完全相同,因此,置信度并不为1。这说明通过DRaM抽取出的置信度和规则结构合理。

表5 规则抽取结果Table 5 Extracted rules with confidences
4 结论与未来工作
本文在知识图谱的推理任务上,提出了一种可微的推理范式,通过融合一阶逻辑规则对知识图谱上的推理提供了可解释性。在实现过程中,针对连续空间与离散空间的鸿沟,设计得分函数对推理结果进行评估,同时融合离散的逻辑符号公式以及连续的嵌入向量空间;对于一阶逻辑规则中原子公式的顺序问题,通过引入大规模语言模型对逻辑规则进行编码,提升规则融合效果。此过程不仅能够在三个知识图谱数据集上得到较好的推理结果,同时可以为模型提供可解释性。
未来,将会在更多的知识图谱上验证方法的有效性,比如通用知识图谱、教育领域的知识图谱。同时也会在更多场景验证可微推理的作用,比如归纳学习领域等。
猜你喜欢
计算机与数字工程(2023年5期)2023-08-31
核科学与工程(2021年4期)2022-01-12
山西大学学报(自然科学版)(2021年1期)2021-04-21
少先队活动(2020年12期)2021-01-14
五邑大学学报(自然科学版)(2019年3期)2019-09-06
计算机应用(2018年5期)2018-07-25
中成药(2017年3期)2017-05-17
领导科学论坛(2016年9期)2016-06-05
轴承(2015年2期)2015-07-25
现代防御技术(2014年6期)2014-02-28
