
基于Lasso降维的不平衡数据处理方法在股票中的应用
2023-10-28 21:36:01严涛王舒梵姜新盈
经济研究导刊 2023年17期
严涛 王舒梵 姜新盈
摘 要:为了在高维财务股票数据中选出重要的特征以及如何选出优质股票是每个投资者所面临的问题。为了减少特征选择过程中人为因素的干扰,提出一种基于Lasso降维的股票分类方法(LR-SC)。首先将高维的财务股票数据放入Lasso进行特征选择,对于降维后的数据,选择每股收益前10%的为少数样本,之后计算每个少数类样本到svm生成的超平面的距离,通过Random-SMOTE算法来生成新的少数类样本,并选择距离超平面最远的后50%的多数类样本来剔除,以此来达到样本之间的平衡。实验结果表明,其选出优质股的精度有所提高,证明了该算法在股票选股上的可行性和有效性。
关键词:股票选股;不平衡数据;lasso降维;Random-SMOTE
中图分类号:F830.2 文献标志码:A 文章编号:1673-291X(2023)17-0070-04
一、研究背景
当今,我国金融市场欣欣向荣,股票市场得到了越来越多的关注,如何从众多的股票中选择优质股对于投机人来说就显得尤为重要。从股票的选择来看,就是对那些上市大公司的价值进行估计,而一个公司的财务数据可以很明显地反映一个公司的经营情况,而且已经有许多的研究者对股票的涨幅情况和财务数据做了相关研究,成果都表明它们之间有重要的联系。
对于股票数据来说,优质股票毕竟是占一小部分,所以数据是极度不平衡的。现如今在不平衡问题上分类方法主要有两个方面,一是算法方面的处理,有代价敏感学习[1]、集成学习[2]和单类学习,集成学习算法是通过将一些弱分类器进行组合来提高分类器的性能,如Adaboost[3]算法等。二是数据处理方面,有两大类,分别是过采样和欠采样。欠采样就是对少数类样本进行增加已达到数量上和多数类样本持平。过采样的基本算法就是SMOTE[4]算法,它是通过对少数样本进行随机的线性插值,依此来创造新样本。但由于参与合成的样本是随机选择,这就导致新合成的新样本质量不高。Borderline-SMOTE[5]算法首先确定出边界集,对其边界集上的样本进行插值,董燕杰等人用Random-SMOTE算法把插值放入三角形内,缓解了少数类样本分布稀疏的问题[6]。文献[7]所提出的SVMOM算法通过少数类样本的密度和距离权重来选择样本,进而缓解噪声样本带来的影响。Douzas Georgios等人提出了G-SOMO:一种基于自组织映射和几何SMOTE的过采样方法,该算法以知情的方式确定创建人工数据实例的最佳区域,并在数据生成过程中利用几何区域来增加其可变性[8]。通过实验结果,表明G-SOMO始终优于初始的过采样方法。欠采样算法是对多数类冗余的样本进行剔除。
根据上述的研究,针对股票分类问题,本文提出一种基于LASSO-R.SMOTE股票分类方法(Based on Lasso-R. SMOTE stock classification method,LR-SC)。首先通过Lasso算法对高维的股票财务数据进行压缩。将降维后的股票财务数据放入SVM支持向量机内产生超平面。对于少数类的股票财务数据,通过Random-SMOTE算法来产生新的少数类样本,再选择距离超平面距离最远的后50%的多数类样本数据来剔除,以达到少数类和多数类样本的平衡。实验结果表明,本文所提出的LR-SC算法相较于其他算法,分类效果更好。
二、相关理论
(一)Random-SMOTE算法
Random-SMOTE算法是在三个样本内产生新样本,算法流程如下:一是随机选择一个初始样本以及和周围的两个样本a、b组成一个三角形;二是在样本a、b上进行随机线性插值产生临时样本y;三是在初始样本和临时样本之间通过如下公式产生新的少数类样本Xnew:
(二)LASSO算法
现在大多数关于股票的研究,其特征的选取往往是基于研究人员的检验来选取,这样掺杂主观性的选择或多或少会带来一定的误差或是特征的遗漏。为了尽可能地去减少这方面所引起的误差,本文选择Lasso方法来进行降维处理。Lasso方法就是在普通的线性模型中增加了一个L1的惩罚项,这是由于当数据的维数过高而导致不是列满秩,进而无法采用最小二乘法来求解。惩罚项就是对部分参数进行压缩为0,而达到降维的目的。
等价于:
其中λ为调和参数。
(三)评价指标
不平衡数据的特殊性,使得传统的平衡数据的评价指标已不再适合,这是因为错分的代价是不一样的,所以需要选择更加合理的评价指标。本文所选择的是混淆矩阵结合G-mean和F1-value[9]的评价方法,其中F1-value和G-mean值是处于同等重要地位。
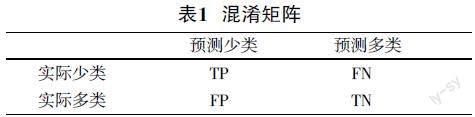
表1 混淆矩阵
其中,TP表示实际为少数类且预测为正确样本数量,FN是实际为少数类且预测错误的样本数量,FP是实际为多数类且预测错误的样本数量,TN是实际为多数类且预测正确的样本数量。
(1)Re:少数类样本被成功分类的精度:
(2)Re:多数类样本被成功分类的精度:
(3)Pr:分类器的分类精度:
(4)G-mean值:
(5)F1-value值:
由于G-means值仅考虑了少数和多数类被正确分类的情况,其值只会随着少数类样本和多数类样本正确分类精度的提高而提高。F1-value值是综合考虑了召回率和查准率这两种情况,可以较为全面地反映少数类被正确分类的精度。本文选取Re、Rp、G-mean、F1-value值这四个指标来研究算法的分类效果。
三、LR-SC算法描述
假设在一个二分类问题中,数据集C=C(0)∪C(1),C(0)∩C(1)=Φ,|C(0)|>|C(1)|,其中少數类样本新增加的样本为CNew(1)。LR-SC算法首先是对高维的财务股票数据进行降维,使用Lasso算法对训练集的数据进行特征选择,降低维数。将处理好的训练集放入支持向量机SVM里来生成超平面,通过Random-SMOTE算法来生成新的少数类样本,并选择距离超平面距离最远的多数类样本数据来剔除,最终合成新的训练样本。
LR-SC算法流程:
输入:高维不平衡的股票财务数据集C。
输出:低维平衡的股票财务数据集。
Step1:将高维数据集用Lasso进行降维得到新的训练集。
Step2:将新的训练集放入SVM进行训练,生成超平面Σ。
Step3:确定少数类样本生成数量|C(1)New|= -|C(1)|。
Step4:对于少数类样本,通过Random-SMOTE产生其新样本C(1)New。
Step5:CNew(1)和C(1)合并形成新的训练集Train_data_
min。
Step6:对于多数类样本,选取距离超平面Σ最远的后50%样本进行剔除,形成新的多数类样本Train_
data_most。
Step7:将Train_data_min和Train_data_min合并为Train_data,放入分类器里进行训练。
四、数据集描述和处理
本文从wind金融数据库选取了2019年300家A股制造业行业上市公司财务报表年报的相关数据作为训练时的数据特征,其中包括每股指标、现金流量、资本结构、偿债能力、盈利能力、收益率、运营能力共35组特征,其训练标签选择的是2020年的每股收益,用此数据集来验证本文所提出算法的有效性。对于股票财务数据,把股票每股收益在前10%的记做阳性样本,即优质股,其余的样本记做阴性样本。为了去除不同量纲对实验结果的影响,对数据进行归一化处理。处理方法如下:
上式中Max,min为一组特征值的最大和最小值。
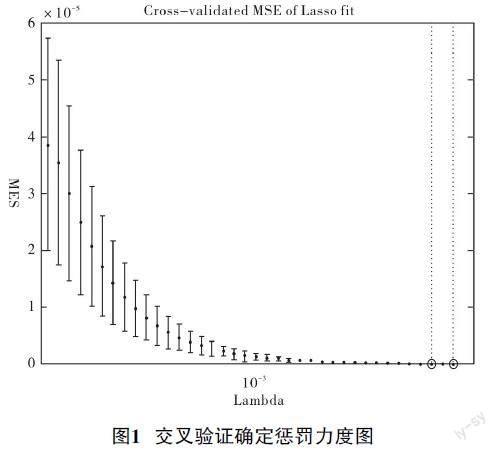
本文使用十折交叉验证来估计Lasso算法中的λ值,从图中可以看出,λ的值不断增大MSE(误差平方和)呈现先降后升的趋势,其曲线的最低点对应的就是MSE的最小值,此时的λ=0.0027,Lasso最终筛选出13个特征。将最后降维后的数据放入SVM中进行训练。
为了测试本文中LR-SC算法的可行性,也为了验证Lasso算法可以得到更好降维结果,于是设计了和把该算法和Borderline-SMOTE算法、SMOTE算法、ISMOTE算法、SMOTE+TOMEK算法和RU-SMOTE分别在另外三种降维算法:主成分分析方法、因子分析方法和线性判别分析方法进行精准度的打分比较,为了确保实验结果的准确性,每次使用的训练集和测试集统一按照7∶3进行划分,本文采取MATLAB2016b为仿真环境,其他算法均由imbalance-learn提供支持。本文SMOTE算法的K近邻选取为5。
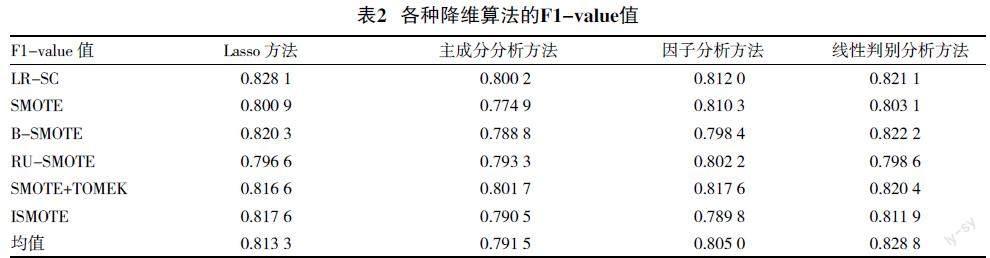
通过图1的结果,将Lasso降维过后的财务数据用来实验,将本文算法和其他五种算法在不同的降维方法下进行打分比较。表2是各种降维算法在F1-value指标上的打分情况,表3是各种降维算法在G-mean指标的打分情况,图2是六种算法在各种降维方法下的打分情况。
从表2的结果可以看出,在四种降维算法中,Lasso方法的最终均值最高,在Lasso方法的内部也可以看出,本文提出的LR-SC算法相较于其他五种不平衡数据的处理方法,F1-value值得分最高,这是有Lasso方法在特征选择的时候降低了人为的因素,减少误差,对少数类样本的采样是在三角形内完成的,提高生成样本的质量。
从表2的结果可以看出,在四种降维算法中,Lasso方法的最终均值比线性判别分析方法稍低,只低了不到0.005。从Lasso方法的内部来看,只有ISMOTE算法高于本文的算法,这是由于LR-SC算法提高了少数类样本的分类精度,降低了对多数类的分类精度,以至于提高了F1-value的值而牺牲了G-mean的得分。但是,从整体而言,本文所提出的算法相较于其他算法都是有优势的,这也验证了LR-SC算法思想的有效性。
为了可以更加直觀明了地展示LR-SC算法在不同的降维算法下与其他算法的打分情况,绘制了六种算法在各种降维方法下的打分情况(见图2),纵坐标反映的是各种算法的得分范围是从0-1,横坐标是Lasso方法、主成分分析方法、因子分析方法和线性判别分析方法这几种降维算法。从结果上来看,Lasso方法对于高维股票财务数据降维效果更优秀,本文所提出的LR-SC算法在整体上更优。
五、结束语
本文针对股票财务数据分类问题,提出了一种基于Lasso降维的股票分类方法(LR-SC),LR-SC算法是通过Lasso算法对高维股票财务数据进行特征选择,对处理后的数据通过Random-SMOTE算法来产生新的少数类样本,并通过距离来确定多数类样本剔除的数量。最后将样本数量相等的平衡数据放入SVM进行训练。这样一方面保证避免了特征选择时的人为因素干扰,也保证了少数类及多数类样本在生成和剔除时的合理性,LR-SC算法在一定程度是提高了股票分类的精度。本文提出的算法也存在些许不足之处,例如,在使用SVM时,所使用的参数是默认值,参数调优以及对于噪声点等问题并没有考虑在内,这些都是今后的研究重点。
参考文献:
[1] 蔡艳艳,宋晓东.针对非平衡数据分类的新型模糊SVM模型[J].西安电子科技大学学报,2015,42(5):120-124,160.
[2] 张银峰,郭华平,职为梅,等.一种面向不平衡数据分类的组合剪枝方法[J].计算机工程,2014,40(6):157-161,165.
[3] Ma S.,Bai L.A face detection algorithm based on Adaboost and new Hear-like feature[C].IEEE International Conference on Software En-gineerning & Service Science,2017.
[4] Chawla N.V.,Bwoyer K.W.,Hall L.O.,et al. SMOTE:synthetic minority over-sampling technique[J].Journal of Artificial Intelli-gence Research,2011,16(1):321-357.
[5] Han H.,Wang W.Y.,Mao B.H. Borderline-SMOTE:a new over-sampling method in imbalanced data sets learning[C].Proceed-ings of the 2005 International Conference on Advances in Intelligent Computing - Volume Part I,2005.
[6] 陶新民,张冬雪,郝思媛,等.基于谱聚类欠取样的不均衡数据SVM分类算法[J].控制与决策,2012,27(12).
[7] Han H.,Wang W.Y.,Mao B.H.Borderline-SMOTE:a new over-sampling method in imbalanced data sets learning[C]//International conference on intelligent computing. Springer, Berlin, Heidelberg, 2005: 878-887.
[8] 董燕杰.不平衡数据集分类的Random-SMOTE方法研究[D].大连:大连理工大学,2009.
[9] Z. Gu,Z.Zhang,J.Sun.Robust Image Recognition by L1-norm Twin-Projection Support Vector Machine[J].Neurocomputing,2017(223):1-11.
[责任编辑 白 雪]
