
基于EEGNet 的脑电情绪分类应用研究
2023-10-25 02:52颜勇君龙柏睿张肖霞童炼
长沙大学学报 2023年5期
颜勇君,龙柏睿,张肖霞,童炼
1.湖南工业大学计算机学院,湖南 株洲 412007;2.广东工业大学计算机学院,广东 广州 510006;3.长沙学院计算机科学与工程学院,湖南 长沙 410022
情绪在我们日常生活中扮演着重要的角色,因此在建立人机情感互动方面,情绪识别变得越来越重要[1]。近年来,脑电波受到了广泛的研究,因为其可以提供一种简单、便携和易于使用的情绪识别解决方案[2]。在脑机接口(BCI)中,情绪识别是计算机了解人类状态的一项重要任务[3]。深度学习作为一种自动学习特征的方法,可以自动在数据中提取特征,并对网络学习到的特征进行进一步分类或回归[4]。在情绪识别任务中,深度学习方法包括卷积神经网络(CNN)、长短时记忆网络(LSTM)、门控循环单元(GRU)等,这些方法不需要人工进行特征提取,可以适应复杂的任务和大量的数据[5]。目前,深度学习在基于脑电信号的情绪识别领域中展现出了很好的效果[6]。
本研究的贡献在于验证了一种紧凑的卷积神经网络EEGNet 在用于处理脑电信号时具有更好的性能和更少的参数量。实验通过情绪识别相关脑电数据集的选取、脑电信号原始数据的预处理、超参数的优化训练、模型的训练等步骤实现了对常用的脑电情绪识别数据集SEED 和SEED-IV 的情绪分类,在三分类和四分类的任务上分别达到了85.3%和73.3%的准确率,表明了EEGNet 在处理情绪相关脑电信号方面的可行性及有效性。
1 数据集介绍及预处理方法
1.1 数据集介绍
实验数据集均由上海交通大学的BCMI 实验室提供。实验共计15 名受试者,其中有7 名男性和8 名女性,平均年龄为23 岁。对每个参与者在不同的时间里进行了3 次实验。数据集中包含对EEG原始信号降采样到200Hz,采用0—75Hz 带通滤波器的预处理原始脑电数据,以及通过人工特征提取所得到的如差分不对称(DASM)和有理不对称(RASM)等特征数据。上述特征适用于情绪分类的任务,其中DASM 是指不同脑电信号间的差异,而RASM 是指不同脑电信号间的比率[7]。SEED 数据集提供的情绪类别为3 种,分别为积极、中性和消极;SEED-IV 数据集提供的情绪类别为4 种,分别为恐惧、悲伤、中性和喜悦。数据集相关概要信息如下表1 所示。

表1 数据集概要
1.1.1 SEED 数据集
实验人员在6 部中文电影中选取了15 个电影片段的剪辑作为实验中的刺激,这些电影片段数量均等地对应上述3 种情绪,每段影片剪辑无特定说明且持续时间在4 min 左右,经过精心编辑,以保持每段剪辑能产生连贯的情感,并最大化情感含义[8]。
每次实验的过程中,受试者需要将15 个实验片段全部看完,因此每次实验均有15 个实验样本,受试者在观看每段影片剪辑前有5 s 的提示时间,观看完毕后有45 s 的自我评估时间和15 s 的休息时间。通过精心的实验顺序安排,确保了同一情感对应的影片不会连续显示。
1.1.2 SEED-IV 数据集
实验人员精心选取了72 个电影片段的剪辑作为刺激,将其划分为3 组,以每组24 个电影片段的方式进行了实验,这些电影片段数量均等地分别对应上述4 种情绪,每段影片无特殊说明且持续时间为2 min 左右[9]。
每次实验的过程中,受试者需要将24 个实验片段全部看完,因此每次实验均有24 个实验样本,受试者在观看每段影片剪辑前有5 s 的提示时间,观看完毕后有45 s 的自我评估时间和15 s 的休息时间。通过精心的实验顺序安排,确保了同一情感对应的影片不会在实验中连续显示。
1.2 数据预处理
1.2.1 在SEED 数据集上的预处理
在SEED 数据集中,经预处理的脑电信号数据的采样率为200Hz,即每秒的采样点数为200,受试者所观看的电影片段长度为3—4 min,故每段影片片段所对应采集的脑电信号数据样本的采样点数不尽相同。为确保尽可能地保留脑电信号原始数据中的时序特征,预处理时在15 个电影片段对应的实验样本中,以采样点数最少的样本为基准,使用数据裁剪的方法,对所有样本的采样点数进行归一化处理,最终所得的样本形状为(62,37 001)。其中,62 代表的是数据采集的刺激实验中的62 个脑电极,37 001代表的是归一化处理对象样本中采样点数的最小值。
1.2.2 在SEED-IV 数据集上的预处理
在SEED-IV 数据集中,经预处理的脑电信号数据的采样率同样为200Hz,受试者所观看的电影片段长度为2—4 min,相比于SEED数据集,各影片片段所对应采集的脑电信号数据样本的采样点数差异更大。为尽可能地保留脑电信号原始数据中的时序特征的同时避免破坏数据本身的特征,本次实验没有使用插值法对脑电信号数据进行处理,而是在丢弃了部分采样点数过少的样本后对剩余的样本进行了裁剪处理,裁剪方法与处理SEED 数据集所使用的方法相一致。经归一化后所得的样本形状为(62,30 601)。其中,62 为实验所使用的脑电极数,30 601 为归一化处理对象样本中采样点数的最小值。
2 EEGNet 网络
2.1 网络结构
EEGNet 是一种紧凑的卷积神经网络架构,可用于基于EEG 的多种脑机接口范式[10]。EEGNet可在数据量非常有限的情况下进行训练,并且可以产生神经心理学可解释的特征。
所谓卷积操作,本质是对输入数据进行加权求和,其中的权重由卷积运算中的卷积核控制,并且在训练过程中,卷积核中的数值也会通过计算梯度进一步进行调整。整个卷积神经网络可以抽象为如下所示的公式,其中f所代表的是特征图,M和K分别代表卷积核的深度和大小,w和b代表权重和偏执,σ代表的是激活函数。其中,上下标中的l代表卷积神经网络的层数,i和j分别代表行数和列数,k和m为数量序号。
EEGNet 的总体网络结构如表2 所示,网络中的卷积层均为一维卷积,网络结构图中使用二维卷积仅为便于软件实现。EEGNet 接受形状为(C,T)的数据输入,其中C为脑电信号的通道数,T为脑电信号的采样点数,数据经过升维操作后以(1,C,T)的格式输入网络。

表2 EEGNet 网络结构
EEGNet 网络中先后使用了深度卷积和可分离卷积对输入数据进行卷积操作,如图1 所示[1],相比于常规的卷积操作,由于深度卷积仅在数据的各通道内进行卷积操作,而非对数据的每个位置都进行卷积,在脑电信号的处理中,这样的卷积有利于对各通道内脑电数据时序信息的提取,因此在EEGNet 中深度卷积核又被称为时序滤波器,其长度在EEGNet 中被定义为F1,是可针对数据集中数据的采样率进行自定义的超参数之一。而后续的可分离卷积则是深度卷积和逐点卷积的结合,以同样的方式进一步降低模型的参数量,使EEGNet 成为一个紧凑而轻量化的卷积神经网络。

图1 EEGNet 网络中的卷积操作
深度卷积(Depth-wise Convolution)是一种逐通道卷积的卷积方式,每个通道仅被一个卷积核进行卷积,其卷积核形状为(S,1,C),其中S为卷积核的长度,1 代表输入数据维度为一维,C表示输出数据被拆分的通道数,因此经过卷积操作后所得到的特征图(Feature Map)的数量即为变量C所定义的通道数,而传统卷积操作后往往会对特征图进行扩展,训练的参数量也更大。但由于深度卷积仅在每个通道内进行卷积操作,而忽略了不同通道在空间上的特征信息,因此需要在逐通道卷积操作后进行逐点卷积,将所得到的特征图重新组合生成新的特征图。
可分离卷积(Separable Convolution)本质上是一种逐通道卷积和逐点卷积(Point-wise Convolution)相结合的卷积方式。其中的逐点卷积的方式与传统卷积十分相似,其卷积核形状为(1,1),此时网络上一层输出的每一个特征图的格式为(1,T//4),其中T为最初输入数据的采样点数。因此,逐点卷积对每一个特征图都进行了单独的卷积操作,经过卷积操作后所得到的特征图的数量即为卷积核的数量,该数值在EEGNet 中被定义为F2,可作为网络中的超参数进行修改,本层卷积在深度方向上对其进行了加权组合,进而对不同通道间在空间维度上的特征进行提取。普通卷积和可分离卷积的区别如图2 所示。

图2 普通卷积和可分离卷积的区别
在每个卷积层后,EEGNet 使用了批量标准化(Batch Normalization)实现对输入数据的正则化操作,使输入的数据在深度学习优化过程中的分布相对稳定,即网络中每一层输入数据的均值和方差都保持在一定范围内,因此下一层网络不必不断去适应底层网络输入的变化,从而实现网络内的层间解耦,允许每一层进行独立学习,提高了整个网络的学习速度,减少权重较大的特征淹没权重较小的特征这一情况的出现,弱化了网络模型对内部参数的敏感性,有效提升网络模型在特征分布不规律的数据上的收敛效果。
输入数据在经过批量标准化过后,将通过ELU(Exponential Linear Unit)激活函数,为网络模型添加更多的非线性元素,使网络能在非线性的关系中也能有更好的拟合效果。相比于其他的线性非饱和函数,如ReLU 函数及其变体函数,ELU 函数对于所有负值输入经过激活后都能得到非零的输出,因此使用ELU 函数时不存在“神经元死亡”的问题,其在提升网络拟合能力的同时也有效地避免了梯度爆炸和梯度消失问题的出现。ELU 激活函数的公式如下:
激活层之后的是池化层(Pooling),池化的目的是对数据进行降维操作,去除了数据中的冗余信息,降低了网络中计算的参数量,能在一定程度上防止过拟合现象的发生。EEGNet 网络中使用了平均池化(Average Pooling)来对数据进行处理,即对池化核对应的数据进行加权平均,保留了卷积后数据的整体特征。随后数据将通过Dropout 操作训练期间对网络中的输入进行随机变换,依据一定的概率将部分神经元的输出值设置为0,这部分被抛弃的神经元将不会参与参数前向传播和反向传播的过程,防止神经元之间产生共适应,减轻网络在训练过程中的过拟合问题,增加了网络模型的多样性和健壮性。
输入数据分别经过两层特殊卷积以及上述处理后将通过全连接层进行特征空间变换,数据最终被压缩成模长为输出维度数的一维向量,而后该向量将经过Softmax 层进行激活,将神经网络的输出进行归一化处理。其中Softmax 激活函数的公式如下所示:
在该函数中,分子通过自然指数函数将输入数据中实数映射到0 到正无穷的范围上,分母则将输入数据中经过映射的实数求和,进而使得输入数据被转换为不同情绪类别中的概率分布。
2.2 与传统卷积神经网络的比较
EEGNet 作为一种紧凑的卷积神经网络,目前已成功地应用于涉及不同类型EEG 信号的多个任务中,例如P300 视觉诱发电位、错误相关负性反应(ERN)和运动节律(SMR)等,在多个脑电相关的数据集上展现出了良好的泛化能力。
得益于深度卷积层的应用,EEGNet 在处理数据的时序特征上有着更优秀的能力,因此,EEGNet对无特征工程的原始脑电数据有着出色的分类效果。传统的卷积神经网络在处理原始脑电特征时,往往忽略了脑电信号中的时序信息,而对不同通道在空间维度上的特征更加敏感,因此在包含时序特征的原始脑电数据上的分类效果相对较差。
2.3 与机器学习分类方法的比较
针对SEED 数据集中经人工提取的特征数据,如脑电数据的微分熵特征,同时尝试使用支持向量机(SVM)这一传统的分类方法对数据直接进行分类。
支持向量机(Support Vector Machine,SVM)是一类按监督学习方式对数据进行二元分类的广义线性分类器,该算法的决策边界是对学习样本进行求解所得的最大边距超平面,进而通过该决策边界进行分类。该算法的基本思想是在样本数据的特征空间上找到一个最优超平面,使该超平面能够将不同类别的样本分开,并且使不同类别之间的间隔最大。SVM 通常用于二元分类问题,也可以推广至多元分类的问题,在多元分类的情况下,通常将问题分解为多个二元分类的子问题,再利用SVM 进行分类。
但支持向量机作为传统的分类方法仍然存在着一些局限性,例如当数据噪声较大或实验数据分布为非线性的情况时,其分类效果往往不够理想。传统机器学习方法需要手动进行特征提取和选择,并对数据进行归一化、缩放等处理,这需要领域专业知识和经验。而EEGNet 使用卷积神经网络,可以自动提取特征,并且对于不同尺度、频率的信号具有较好的适应性。
2.4 EEGNet 的模型可解释性
使用EEGNet 进行分类任务时,理解网络所学到的特征对于保证模型的可靠性至关重要。模型所产生的分类结果需要确保不是由于数据中的噪声或异常值引起的,而是由相关特征所驱动的。
EEGNet 通过在深度卷积网络中使用专门的滤波器和一维卷积,可以提取到更有意义和区分性的特征,因此可以更好地进行情绪分类任务。另外,EEGNet采用的卷积方式较传统的CNN更加局部化,可以更好地保留信号的空间特征,这样在处理EEG信号时可以更好地保留空间信息,从而可以更好地识别不同的脑电波形式,有助于提高情绪分类的准确性。另外,由于EEGNet 采用的是一维卷积,在网络的输入输出上易于解释。在输入方面,EEGNet 中的每个特征通道都可以被视为对应于不同电极对应采集的脑电信号。在输出方面,EEGNet 的每个类别都可以被视为对应于脑电信号的不同情感状态。
2.5 EEGNet 应用于情绪识别的可行性
事件相关电位(ERP)是一种脑电生理学的测量方法,用于研究特定的感知、认知或运动事件对大脑电活动的影响。事件相关电位是通过将大量的脑电信号进行平均来获得的,以消除随机噪声和增强事件相关的电位。事件相关电位可以提供有关大脑对特定事件的反应时间和神经机制的信息。常见的事件相关电位包括P300、N400 和MMN 等。目前,EEGNet 已经在基于事件相关电位(ERP)的脑电信号数据集上得到了较为广泛的应用。
EEGNet 在使用P300 信号的数据集上进行了被试者间分类(Cross-Subject Classification)的实验,即利用数据集中的一组被试的数据来训练EEGNet模型,并在另一个不同的被试组的数据集上进行分类预测。该数据集是通过对受试者进行重复的“非目标性”视觉刺激所收集的基于事件相关电位的脑电数据集,反映了大脑对特定刺激的认知和注意的过程。在最终的测试中,EEGNet 的预训练模型在该数据集上的二分类准确率达到了90%左右。
上述实验充分体现了EEGNet 在基于事件相关电位的脑电信号上出色的泛化能力。事件相关电位的脑电数据是通过刺激和响应测量而产生的,而非通过受试者的自由思考和行为表现而获取,在数据收集的过程中,实验条件和刺激都能得到有效的控制,以获得可重复的结果。同时,事件相关电位是在刺激后几毫秒至几百毫秒内形成的,因此具有非常高的时间分辨率,有效地捕捉了脑电活动的快速变化及其时域特征。
在情绪识别领域,事件相关电位同样是一种常用的脑电信号测量方法,SEED 和SEED-IV 数据集即使用影片片段作为视觉刺激所收集的事件相关电位的脑电数据集,适合用于EEGNet 的训练与测试。
3 实验内容与数据分析
3.1 实验过程及结果
3.1.1 在SEED 数据集上的实验
针对SEED 数据集中经特征工程处理后的数据,进行了支持向量机(SVM)这一传统的机器学习分类方法的分类实验。这部分数据由15 位受试者经3 次实验得来,共计45 组实验数据,每组实验数据中包含15 个脑电数据的特征样本,其数据格式为(62,T),其中T为该数据对应影片刺激的时长,单位为s。
在支持向量聚类(SVC)中进行了基于RBF核函数的数据分类实验,其基本思想是将输入空间映射到一个高维的特征空间中,使得在该特征空间中可以更容易地进行线性分类。具体来说,RBF 核函数可以使低维空间中的数据映射到无穷维的空间中,从而可以捕捉到更多的数据信息。在RBF 核函数中,每个样本点都被看作一个基函数,而它们之间的距离则用高斯函数进行计算。因此样本点之间的相似性就可以通过它们在高斯函数下的距离来度量,距离越近的点相似度越高。
同时选取了基于线性动态系统(LDS)方法得到的微分熵(DE)数据。微分熵数据是对脑电信号进行微分处理后,通过计算微分信号的熵值来描述脑电信号复杂性和随机性的一类数据,其计算方式是将微分处理后的信号离散化为若干个状态,结合每个状态出现的概率,再通过熵的定义所计算得来。由于微分熵是基于时间序列的熵的概念,其计算充分考虑了信号的变化率和时间间隔,保留了原始数据中的时序信息,因此常用于研究脑电信号的时域特征,亦可直接用于脑电信号的分类。
在脑电信号的delta 波段、theta 波段、alpha波段、beta 波段和gamma 波段中,theta 波段(4—8Hz)多出现在轻度睡眠、沉思和冥想状态,alpha波段(8—13Hz)多出现在放松、专注和集中状态,因此,上述波段对应的脑电数据与人的情绪相关度更高。实验中也将theta 波段和alpha 波段对应的特征数据作为研究对象开展分类实验,虽然相较于传统的机器学习方法,深度学习在处理复杂数据的分类问题上有着更强的表达能力,但这一分类结果能为基于深度学习方法的情绪分类实验提供一个可供参考的标准。实验依据3∶2 的比例将每组实验中的15 个数据样本划分为训练集与测试集,在三分类情况下,theta 脑电波段最终所得的平均分类准确率为61.7%,如图3 所示;alpha 脑电波段最终所得的平均分类准确率为63.4%,如图4 所示。

图3 theta 波段特征数据在SVM 分类器上的分类准确率及其平均分类准确率
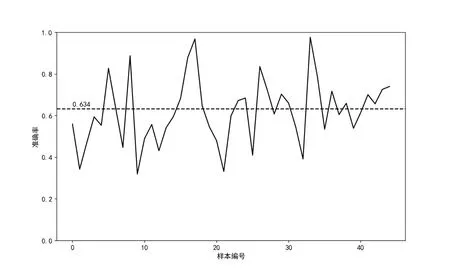
图4 alpha 波段特征数据在SVM 分类器上的分类准确率及其平均分类准确率
SEED 数据集中的原始脑电数据同样对应45组实验数据,每组实验数据中包含15 个二维脑电原始数据样本,分别对应唯一的标签序列,在时间维度对数据进行归一化处理后输入EEGNet 网络进行训练。
训练中使用的损失函数为交叉熵函数,作为凸函数,在训练过程中不存在局部最优解的问题,故在梯度下降等优化算法中可以有效地找到全局最优解,交叉熵可用于判断两个概率分布之间的差异性大小,在衡量模型分类能力的任务中有很高的适用性。训练中使用的优化器函数为Adam 优化器,相比于传统的梯度下降法,Adam 优化器不需要手动地调节学习率,而是根据梯度的一阶矩估计(梯度的均值)和二阶矩估计(梯度的无中心矩)自适应地调节每个参数的学习率。训练过程中的学习率使用了StepLR 学习率调整机制进行自衰减,每经过5 轮学习,学习率将降低为原来的90%。其中Adam 优化器的公式如下所示,θ为EEGNet 中全体参数构成的向量;m为冲量,当对模型优化参数时可辅助进行方向修正,使参数优化不仅仅依靠梯度,避免了优化时陷入鞍点;v-hat为指数移动均值,根据梯度计算得来;下标t表示当前时刻,t-1为上一时刻。
关于EEGNet 网络,其深度卷积层(Depthwise Convolution)中的卷积核,即时序滤波器的长度被设置为了100。这是因为当时序卷积核的长度被设置为采样率的一半时,网络能有效地提取2Hz及以上的频率信息[11],即对低频信息能更加敏感。在深度可分离卷积层,在参考了EEGNet 原始论文中的建议后,将该层卷积核长度设置为了16,以达到更好的分类效果。
实验根据7∶2∶1 的比例,以受试者编号为依据将数据集划分为训练集、验证集和测试集,其中训练集和验证集用于EEGNet 模型的训练,测试集则用于测试预训练EEGNet 模型的泛化能力及分类表现。经训练,最终模型在训练集上的损失降到了0.554,验证集上的分类准确率达到了66.2%。
对此预训练模型以8 为批量大小在测试集上进行了三分类测试,以0、1、2 作为情绪标签分别对应了消极、中性和积极的情绪,测试同时也计算了预训练模型在各批数据中的均方误差、平均绝对误差、召回率和Macro-F1分数。其中,召回率是指对于某个类别,模型正确识别出该类别的样本数量与该类别实际样本数量之间的比例,用于衡量模型对各个类别的识别能力。多分类时的Macro-F1分数则是各类别F1分数的平均值,每一类的F1分数是综合考虑模型在该类别上进行预测的精确率和召回率的调和平均数,这一指标避免了只关注精确率和召回率的其中一个而造成的误差。最终,该预训练模型在测试集上的平均准确率达到了90.0%。
3.1.2 在SEED-IV 数据集上的实验
实验针对SEED-IV 数据集中的原始脑电数据对EEGNet 进行了训练,该数据集同样是由15 名受试者通过3 次实验得来,但由于3 次实验中所使用的刺激不同,因此,其数据样本对应的标签序列也有所不同。数据在时间维度上进行了归一化处理,以确保数据样本格式的唯一性,而后输入到EEGNet 中进行训练。
实验中所使用的损失函数和优化器函数仍然为交叉熵函数和Adam 优化器,学习率仍使用StepLR学习率调整机制进行衰减,每经过5 轮学习,学习率将降为原来的90%。同时由于数据采样率为200Hz,EEGNet 中深度卷积层的时序卷积核长度被设置为100。
由于SEED-IV 数据集中的原始脑电数据在时间维度上的差异较大,即采样点数在数量分布上的均方差较大,部分数据样本的采样点数过少,导致在实验之初对数据格式进行归一化处理时,选取的采样点数的基准值较小,使最终输入网络进行训练的数据量及其在时间维度上的特征相对有所减少。经多轮训练,EEGNet 模型始终难以收敛到理想的范围,得到的预训练模型的泛化能力较差,其在测试集上的准确率为48.5%,测试集中包含受试者编号为2 和15 的数据样本。
因此,考虑到时间维度上的数据特征对EEGNet 模型拟合能力的影响,在实验过程中通过不断提高采样点数的基准值进行数据归一化处理,并手动过滤了部分采样点数过少的数据样本,在5轮训练和测试后,所得预训练模型的准确率在相同测试集上的变化趋势如图5 所示。

图5 不同采样点数对应的EEGNet 预训练模型在测试集上的准确率
为兼顾较好的模型拟合效果和充足的训练数据量,最终选定了以30 601 作为SEED-IV 数据集上采样点数归一化的基准值。对整体数据进行归一化处理后,将数据集以7∶2∶1 的比例划分为训练集、验证集和测试集。同样对数据集进行了多次重新划分,确保每次划分所得的测试集中数据归编号不同的受试者所有。经训练,模型最终在训练集上的损失降到了0.746,在验证集上的分类准确率达到了58.6%。
与在SEED 数据集上的测试实验类似,以0、1、2、3 作为标签分别对应了中性、悲伤、恐惧和喜悦4 种情绪,对此预训练模型在测试集上以8 为批量大小进行四分类测试,同样地,在测试过程中计算了每一批量数据的均方误差、平均绝对误差、召回率和Macro-F1分数,用于对模型的泛化能力进行更加直观的考察,通常情况下Macro-F1的值能与模型的泛化能力成正相关关系。最终,该预训练模型在测试集上的准确率达到了86.4%。
3.2 实验总结与数据分析
经过在SEED 数据集和SEED-IV 数据集上的多轮实验,且每轮实验都重新打乱并划分数据集,得到了如图6 所示的EEGNet 预训练模型在不同的测试集上的准确率。其中,在5 轮实验中,EEGNet 在SEED 测试集上的三分类平均准确率达到了85.3%,在SEED-IV 测试集上的四分类平均准确率达到了73.3%。图中横轴方向的标记即为当次训练时所划分测试集数据对应的受试者编号。

图6 EEGNet 预训练模型在SEED 和SEED-IV 测试集上的准确率
由以上的实验结果可得知,与传统的机器学习分类方法相比,经深度学习训练的EEGNet 模型在SEED 数据集上有着更好的分类能力。在三分类的SEED 数据集上,EEGNet 模型在测试数据上也表现出了良好的泛化能力。在四分类的SEED-IV 数据集上,限定数据样本的采样点数在30 000 以上时,仍有较为可观的数据量参与模型的训练,在此情况下,EEGNet 也能保持较高的分类准确率,笔者认为主要原因还是EEGNet 对输入数据中的时序特征有着较高的敏感度,因此脑电数据采样点的数量将直接对EEGNet 模型的分类准确率产生较大的影响。
在保持模型训练的超参数不变的情况下,随着数据集划分的不同,实验所得预训练模型的在对应测试集上的准确率有所不同,甚至产生了较大的差异,这一现象在四分类的SEED-IV 数据集上尤为明显。针对这一现象,初步认为其原因可能为如下三点。
第一,数据集中数据分布不均,使EEGNet 网络在学习的过程中难以收敛,模型欠拟合。
第二,部分受试者之间存在着较大的个体差异性,使得模型在其对应测试集上的泛化能力较差,预测准确率低。
第三,对SEED-IV 数据集进行预处理时,由于对大量数据进行过滤和裁剪,对数据集中部分数据的特征在一定程度上造成了破坏,导致对模型的训练造成影响。
综上所述,EEGNet 作为适合处理时序信号的紧凑型卷积神经网络在SEED 和SEED-IV 数据集上表现出了良好的分类能力,在数据量有限的情况下也表现出了良好的识别能力和健壮性。
本次实验设计的方法仍存在一定的局限性,在实验中所遇到的部分现象仍有待进一步设计实验进行验证。例如,考虑到受试者之间的差异,仅对实验数据集进行受试者间分类(Cross-Subject Classification),而忽略同一受试者自身在不同情绪上的差异性。这需要更改数据集的划分方式,进行受试者内分类(Within-Subject Classification),开展进一步的研究。另外,由于参与本次实验的SEED 数据集和SEED-IV 数据集间在数据格式上存在一定程度上的差异,因此在训练前对数据进行预处理时对实验变量的控制存在一定的不合理之处。
4 结论
针对脑电情绪识别任务,对一种紧凑型的、适用于基于脑电信号的脑机接口范式的卷积神经网络EEGNet 模型进行了研究。该模型在传统卷积神经网络的基础上引入了深度卷积和可分离卷积机制,因此得以更加有效地处理时序信息中的相关特征。实验围绕SEED 数据集和SEED-IV 数据集中的单模态脑电数据对EEGNet 进行了训练和测试,对EEGNet 网络模型在基于脑电信号的情绪识别效果方面进行了评估。EEGNet 模型在测试过程中体现出了良好的泛化能力,在情绪分类上取得了较高的准确率。
预处理后的数据均为脑电信号经下采样和去噪后的原始数据,未经特征工程处理和数据增强处理,表明EEGNet 模型在网络设计层面的合理性,通过逐通道卷积和逐点卷积的结合,能十分有效地从原始数据中提取到分类相关的特征,尤其是EEGNet 对输入数据中的时序特征有着较高的依赖性,实验结果充分地体现了这一点,这说明了EEGNet 在实践过程中有着良好的实用性。另外,对于数据量相对较小的数据集,EEGNet 网络模型同样能保持较高的分类准确率,说明其在数据量不够充足时,依然能对实验数据进行较好的拟合,在小样本的脑电信号的分类问题上仍保持较高的健壮性。
作为卷积神经网络,EEGNet 只能接受定长格式的数据输入,而SEED 数据集和SEED-IV 数据集中所提供的脑电数据在时间维度上的格式并不是固定的,这与数据集的采集方式以及所使用的刺激密切相关。因此,在预处理数据的归一化过程中,难免对原始数据进行裁剪,对数据的完整性以及数据集中不同数据间的整体性造成破坏,对模型的训练也将产生一定程度的影响,甚至使得模型在特定的数据集上难以收敛。因此,EEGNet 在处理变长序列信息方面仍然有较大的优化空间,可适当地引入类似于RNN、LSTM 网络等结构的适合处理变长序列的网络层对输入数据预处理后,再进一步进行卷积操作提取特征,但其实用性还有待设计实验进行进一步的验证。另外,实验中所使用的数据集均基于事件相关电位,仅记录了受试者经刺激后的脑电反应,但情绪是一个动态的过程,因此仍存在着一定的局限性。
最后,由于EEGNet 网络有着较为出色的稳健性,其深度可分离卷积层的设计减少了它在训练过程中所需的参数量,使其在计算能力较弱的嵌入式设备中的应用成为可能,而边缘学习是当前人工智能领域的热点之一,EEGNet 网络与边缘设备的结合将为基于脑电信号的情绪识别任务提供更加高效、准确和便捷的解决方案。
猜你喜欢
成都信息工程大学学报(2021年4期)2021-11-22
数学年刊A辑(中文版)(2020年2期)2020-07-25
数学物理学报(2019年6期)2020-01-13
科技传播(2019年24期)2019-06-15
北京航空航天大学学报(2017年9期)2017-12-18
数学物理学报(2017年5期)2017-11-23
现代电生理学杂志(2016年3期)2016-07-10
现代电生理学杂志(2016年4期)2016-07-10
现代电生理学杂志(2016年1期)2016-07-10
现代电生理学杂志(2015年1期)2015-07-18
