
基于改进生成对抗网络的图像数据增强方法
2023-10-24 10:08詹燕胡蝶汤洪涛鲁建厦谭健刘长睿
浙江大学学报(工学版) 2023年10期
詹燕,胡蝶,汤洪涛,鲁建厦,谭健,刘长睿
(浙江工业大学 机械工程学院,浙江 杭州 310023)
现代零件加工质量检测和设备故障诊断方法逐渐智能化,在各类机器学习和数据挖掘算法中,原始工业数据显得极为重要.性能良好的算法需要海量且优质的数据支撑,仅用少量数据驱动的模型很难具备较好的泛化能力.不过,多数情况下难以获取大量的工业数据集,例如变工况条件下标定完整的轴承振动数据集[1].
在图像处理领域,针对工业数据不足的问题,现有的数据增强方法包括对原始图像进行几何变换、随机调整亮度和对比度、添加各类噪声等操作,然而这些方法不能使训练样本的多样性产生质变[2].迁移学习[3]可以大幅减少人工标定成本,但是迁移学习模型难以改变其网络结构,且灵活性较差,当训练集和测试集数据分布差异过大时,模型易发生崩溃.随着生成模型的发展,逐渐出现基于深度玻尔兹曼机(deep Boltzmann machine, DBM)[4]、生成随机网络(generative stochastic network, GSN)[5]、变分自编码器(variational autoencoding, VAE)[6]、像素递归神经网络(pixel recurrent neural networks, PixelRNN)、像素卷积神经网络(pixel convolution neural networks, PixelCNN)[7-8]和生产式对抗网络(generative adversarial networks,GAN)等数据增强方法.与VAE 相比,GAN 不存在偏置,能够更好地拟合真实样本分布;与DBM、GSN 和PixelRNN/CNN 相比,GAN 可一次性生成样本,而不用反复计算马尔可夫链或通过逐个生成像素的方式生成样本.GAN 以其良好的图像质量和快速的运行速度,成为了当前数据增强方法的主流研究方向之一.
基于生成器与判别器零和博弈的思想,Goodfellow 等[9]提出生成式对抗神经网络,并将其应用于手写数字和人脸图像生成.Mirza 等[10]将标签信息输入到GAN 的生成器和判别器中,提出条件生成对抗网络(conditional generative adversarial nets, CGAN),通过引入条件信息实现GAN 的训练过程可控.Radford 等[11]将深度神经网络(deep neural networks,DNN)引入GAN,并用全局池化层替换全连接层,提出深度卷积生成对抗网络(deep convolutional generative adversarial networks,DCGAN).为了稳定GAN 的训练,Arjovsky 等[12]提出沃瑟斯坦生成对抗网络(Wasserstein GAN,WGAN).Gulrajani 等[13]提出带梯度惩罚项的沃瑟斯坦生成对抗网络(Wasserstein GAN with gradient penalty,WGAN-GP).传统GAN 方法生成的图像数据较为模糊,为了生成高分辨率的图像数据,Berthelot 等[14]基于自编码器提出边界均衡生成式对抗网络(boundary equilibrium generative adversarial networks, BEGAN).Karras 等[15]提出PG-GAN,通过渐进训练的方式增大生成图像的空间分辨率.Karras 等[16-18]借鉴风格迁移网络并通过修改渐进层输入,提出StyleGAN 系列对抗网络,实现对隐空间的解耦.图像超分辨率重建可以利用低分辨率图像经过训练得到高分辨率图像,Dong 等[19]将深层卷积网络应用于图像超分辨率重建提出超分辨率卷积神经网络(super-resolution convolutional neural network, SRCNN).相比通过GAN 方法得到高分辨率图像,图像超分辨率重建技术模型结构更简单,且训练过程更稳定.
综上所述,现有图像数据增强方法存在以下问题:1)基于传统GAN 方法直接建立向高分辨率图像的映射网络,网络难以工作.2)图像超分辨率重建技术是在已知低分辨率图像的基础上生成高分辨率图像,模型无法自主生成低分辨率图像.3)目前基于GAN 的模型对于噪声的输入都极为随意,在多数情况下都是直接输入一维随机噪声,导致输入的噪声和样本原始分布差异较大.网络可训练参数量过多,会影响模型收敛速度.4)现有的渐进式训练方法能够生成高分辨率图像,但是也带来了训练速度缓慢的问题.针对上述问题,本研究提出基于分布拟合对抗神经网络的图像数据增强方法.通过最大似然估计拟合原始样本数据空间分布;根据Box-Muller 和马尔科夫链蒙特卡洛(Markov chain Monte Carlo, MCMC)采样算法[20]生成符合原始样本空间分布的随机噪声;结合带条件信息的WGAN-GP 和SRCNN 提出新的图像数据增强方法,并利用轴承滚子表面缺陷检测数据验证所提方法的可行性和优越性.
1 基于传统对抗式神经网络的图像数据增强方法
1.1 GAN 和CGAN
GAN 由生成模型(G)和判别模型(D)2 个部分构成,生成模型输入随机噪声z,用于拟合真实样本数据分布,判别模型接收生成样本G(z) 以及真实样本x,用于判别生成样本G(z) 是否来自于真实样本x.生成模型的目的是最大化D(G(z)) ,即最大化判别模型将G(z) 判别为真实样本的可能性,而判别模型的目的是最小化D(G(z)) ,即最小化将G(z)判别为真实样本的可能性.在经过多次对抗训练后,生成器和判别器达到纳什平衡[21].GAN的目标函数为
式中:V(D,G) 为优化目标函数,由生成器和判别器2 个部分组成;E为分布函数的数学期望;x为真实数据;Pr(x) 为原始数据分布;z为随机噪声;Pz(z)为随机噪声数据分布;D(x) 为判别模型判别结果;G(z) 为生成模型输出样本.
CGAN 的结构以及原理和GAN 类似,CGAN在生成模型输入中增加了期望生成数据标签.判别模型输入中增加了真实数据标签,用标签信息控制CGAN 的训练过程,使得CGAN 能够生成和标签信息对应的数据.CGAN 的目标函数为
式中:y为条件信息.
1.2 基于GAN 和CGAN 的图像数据增强方法
基于传统对抗式生成网络的图像数据增强方法首先将一维随机噪声和真实图像样本输入到原始GAN 或CGAN 网络中,同时对生成模型和判别模型进行对抗训练,在模型训练完成后,单独取出生成模型,将一维随机噪声输入生成模型即可生成新的样本,基于传统GAN 方法的训练过程如图1 所示.
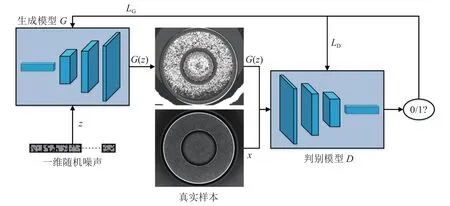
图1 基于传统GAN 的图像数据增强方法Fig.1 Image data enhancement method based on traditional GAN
上述2 个模型能够生成新的样本,但是都难以训练.原始GAN 和CGAN 在训练过程中容易产生模式崩溃和梯度消失问题,并且生成器和判别器的损失值无法反馈模型收敛信息[22].一维随机噪声长度较长,会导致全连接层参数过多,造成模型参数冗余,严重影响训练效率.
2 基于生成对抗神经网络超分辨率重建的图像数据增强方法
为了解决传统GAN 用于图像数据增强时存在的模型难以训练、参数大量冗余且噪声输入随意等问题,通过极大似然估计、Box-Muller 和MCMC 算法生成符合原始数据分布的随机噪声,在此基础上融合WGAN-GP 和SRCNN 网络,提出基于分布拟合对抗神经网络的图像数据增强方法.本研究的数据增强方法主要由数据预处理、原始数据分布拟合、随机噪声生成、模型训练及优化和生成样本质量评价等5 个步骤组成,框架如图2 所示.
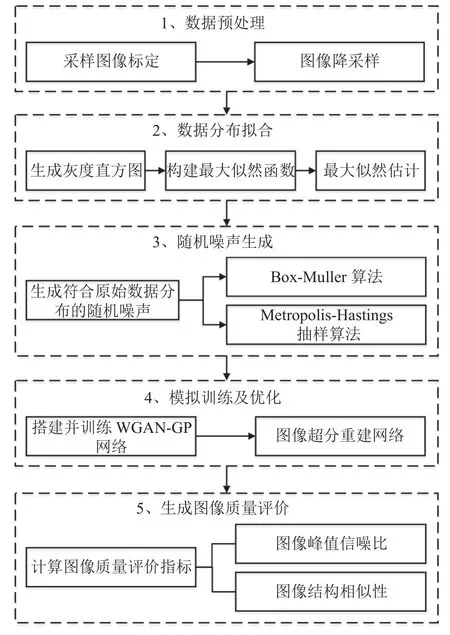
图2 基于生成对抗神经网络超分辨率重建的图像数据增强方法流程图Fig.2 Flowchart of image data enhancement method based on generative adversarial neural network super-resolution reconstruction
2.1 WGAN 和WGAN-GP
生成器随机初始化后的生成分布很难与真实分布有不可忽略的重叠,因此WGAN 用Wasserstein 距离作为等价优化的距离衡量,进而同时解决稳定训练和进程指标的问题[12].Wasserstein 距离计算公式为
式中:Pr为真实数据分布;Pg为生成数据分布;为Pr和Pg组合得到的所有可能的联合分布集合;对于每个可能的联合分布 γ 可以从中采样(x,y)∼γ得到样本x和y, //x-y// 为这对样本的距离.Wasserstein 距离计算公式的对偶形式为
式中: sup为 上确界,即最小上界;f为 一个连续函数;//f//L≤K表示f必须满足利普希茨连续条件(Lipschitz continuity),即存在一个常数K≥0 使得在定义域内 |f(x1)-f(x2)|≤K|x1-x2|.WGAN 的目标函数为
式中:D∈1-Lipschitz 为判别器D必须满足利普希茨连续条件,即满足 |D(x1)-D(x2)|≤|x1-x2|.为了满足这一条件,WGAN 在每步迭代完成后将判别器D的参数截断在 [-c,c] ,但是这种优化策略容易导致参数取值极端化、梯度消失和梯度爆炸.针对这个问题,WGAN-GP 通过对目标函数加入梯度惩罚项间接实现利普希茨连续条件,WGAN-GP的目标函数为
式中: λ 为梯度惩罚权重,xr、xg分别为真实分布Pr和生成分布Pg中的数据,为随机噪声在xr和xg的连线上随机插值采样得到数据,PPEN为采样得到数据的集合, ε 为服从0~1.0 均匀分布的随机数,为判别器D梯度的L2范数.
2.2 数据预处理
对工业相机采集的少量原始图像数据进行人工标定,获得图像对应标签;用单层卷积层对原始图像数据集进行降采样,将原始图像尺寸缩小到所需尺寸.目的是减少原始图像数据的空间冗余,提高模型的计算效率.降采样输出图像尺寸计算公式为
式中:Oout为输出图像尺寸,Iin为输入图像尺寸,kc为卷积核尺寸,V为边界填充参数,d为滑移步长.输出图像通道数等于卷积核数量.
2.3 原始数据分布拟合
通过最大似然估计法对降采样之后的数据进行分布拟合,目的是获得原始数据分布的概率密度函数.首先生成图像灰度直方图,根据灰度直方图初步判断数据近似服从的分布;然后分别将近似服从分布和常用分布的概率密度函数构建成最大似然函数;最后求解得到概率密度函数待估计参数值.最大似然估计法计算方法为
式中:L(θ) 为最大似然函数, θ 估计参数,f(xi|θ) 为概率密度函数,xi为样本值, θ ˆ 为极大似然函数估计值.
2.4 随机噪声生成
通过Box-Muller 和MCMC 采样算法,根据原始数据分布拟合得到的概率密度函数生成符合原始数据分布的随机噪声,具体方法步骤如图3 所示.
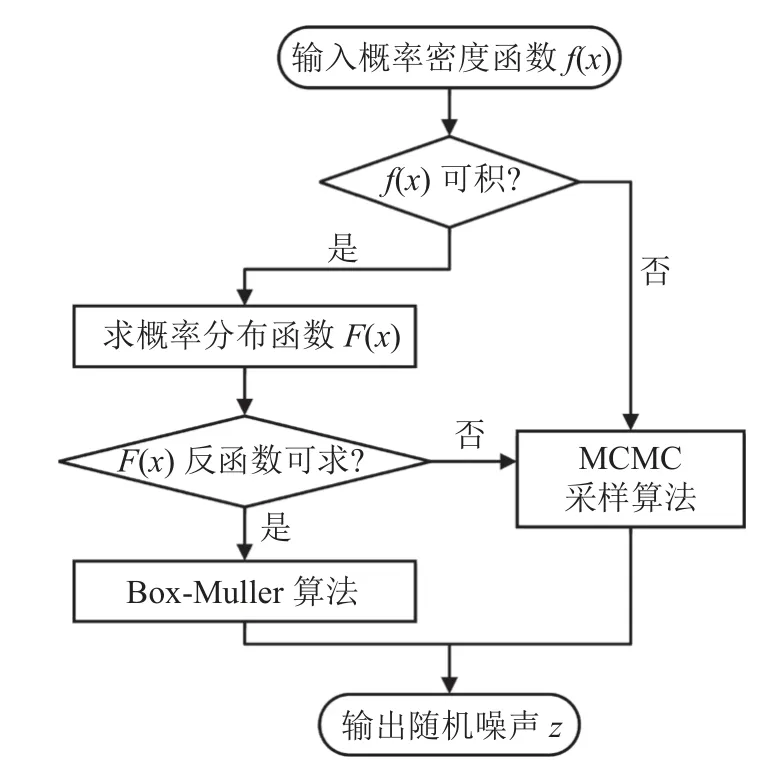
图3 生成随机噪声流程图Fig.3 Flowchart of generating random noise
2.4.1 Box-Muller 变换 在很多情况下累积分布函数的反函数无法直接获得.Box-Muller 变换通过对目标分布的联合概率密度函数进行三角换元,分别求出换元后联合概率密度函数关于R和 θ 的边缘分布函数,再对其求反函数,最后将服从均匀分布的随机变量映射到所求分布上,得到服从目标分布的随机噪声.Box-Muller 变换计算式如下:
式中:f(x,y)为x、y的联合概率密度函数,且x、y相互独立;FR和为关于R的边缘分布函数和其反函数;Fθ和为关于 θ 的边缘分布函数和其反函数;U1、U2为服从0~1.0 均匀分布的随机数;x、y服从均值为0,方差为1.0 的高斯分布.
2.4.2 Metropolis-Hastings 抽样算法 对于目标分布的累积分布函数或关于R、 θ 的边缘分布函数反函数不可求的情况,可以通过Metropolis-Hastings(MH)抽样算法得到符合目标分布的随机噪声[23].MH 算法是MCMC 采样算法中常用的一种,通过构建马尔可夫链,找到满足细致平稳条件的状态转移矩阵使马尔可夫链趋于平稳分布,算法流程如图4 所示.

图4 Metropolis-Hastings 抽样算法流程图Fig.4 Flowchart of Metropolis-Hastings sampling algorithm
假设P(x) 为目标概率分布,对于P(x) 构建一个关于样本x的马氏链,其状态转移矩阵记为Q.在MH 算法中Q即为给定的建议分布,x′为按建议分布随机抽取的候选状态,xt-1=x′、 α (x,x′) 为接收概率,MH 抽样算法根据 α(x,x′) 决定是否用x′更新xt,t为当前时刻,u为服从0~1.0 均匀分布的随机数,具体计算方法为
2.5 建立生成式对抗网络和SRCNN 网络
通过融合带条件信息的WGAN-GP 和SRCNN建立生成式对抗网络模型,可以使模型能够按照给定标签信息生成对应的样本图像,且减少模式崩溃、梯度消失问题的产生.本研究将WGAN-GP输出的低分辨率图像输入到预训练好的SRCNN网络中,经过超像素重建后得到高分辨率图像.为了探寻输入随机噪声分布对生成式对抗网络模型的影响,构建一个随机噪声生成模块,为模型生成符合样本分布的随机噪声,WGAN-GP 网络架构如图5 所示,模型整体结构如图6 所示.模型判别器损失函数为

图5 WGAN-GP 网络架构图Fig.5 Architecture diagram of WGAN-GP network
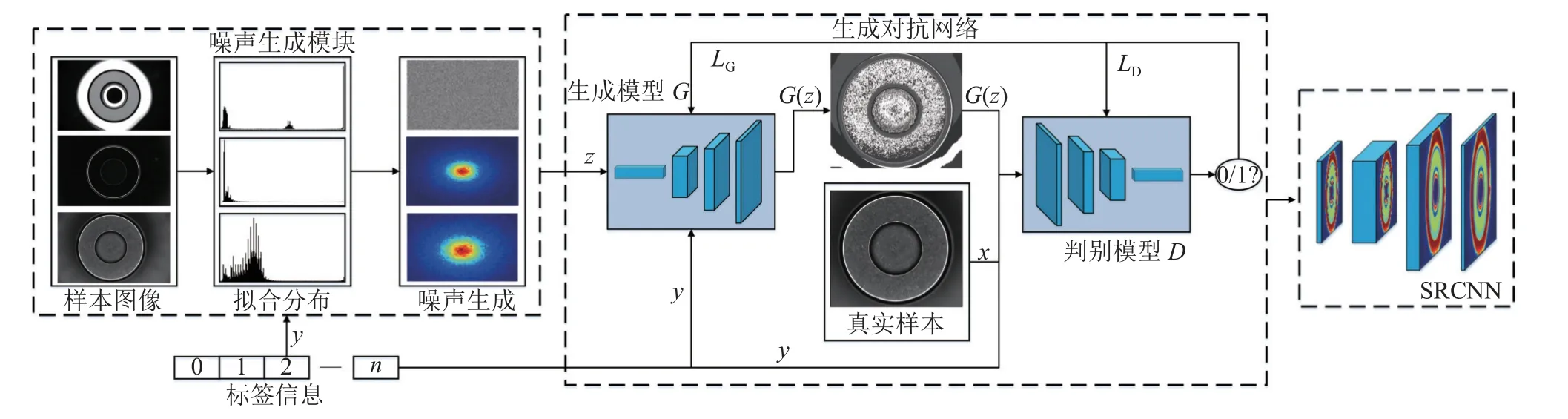
图6 WGAN-GP+SR 模型整体结构图Fig.6 Overall structure diagram of WGAN-GP+SR model
模型生成器损失函数为
SRCNN 损失函数选用均方误差(mean-square error,MSE)损失函数,计算式为
式中:n为图像像素的个数,yi为真实标签,f(xi) 为网络输出.
2.6 生成图像质量评价
图像峰值信噪比(peak signal-to-noise ratio,PSNR)和结构相似性(structural similarity, SSIM)能对生成图像质量进行量化.PSNR 是反映图像对应像素点间误差的客观评价方法,SSIM 则是从亮度、对比度和结构3 个方面衡量生成图像质量,更符合人眼视觉感受.具体计算方法为
式中: MSE(X,Y) 为生成图像X与真实图像Y之间的均方误差; µX、µY、σX、σY、σX,Y分别为X、Y的局部均值、方差和协方差;b为每像素比特数;C1=(K1L)2、C2=(K2L)2、C3=C3/2,一般情况下K1=0.01、K2=0.01、L=255.00.
弗雷歇初始距离(Fréchet inception distance,FID)作为衡量真实图像和生成图像之间特征距离的指标之一,既能够表示图像的多样性,也能被用来评价生成图像的质量.
式中:x为真实图像,g为生成图像, µx和 Covx分别为真实图像的特征向量的平均值和协方差矩阵,µg和 Covg分别为生成图像的特征向量的平均值和协方差矩阵,Tr为矩阵对角线上元素的总和.FID越低,则图像多样性越好,质量也越高.
3 实际案例分析
由于轴承滚子各个表面图像像素分布差异较大,且轴承表面样本采集存在一定难度,须先人工擦拭滚子各表面,再通过采集设备逐一采集,人力成本耗费较大,比较贴合实际工业生产中样本采集现状.以轴承滚子表面灰度图像数据增强为例,验证所提方法的有效性,原始样本灰度图像均通过CCD 工业相机采集获得,样本图像分为3 类,分别为轴承滚子侧面、倒角、端面灰度图像,数据集中3 类表面图像数量分别为351、468、471,总计1290.输入判别器的图像需要降采样,输入生成器的是二维噪声.首先将维度为(1 920,1 200, 1)的原始图像裁剪为(1 920, 1 184, 1),然后用卷积核数量为1 的单层卷积层对裁剪后图像数据进行降采样,分别降采样为(480, 296, 1)和(240, 148, 1),并将滚子侧面、倒角、端面图像标签记为0、1、2.维度为(240, 148, 1)的图像用于训练WGAN-GP 网络,维度为(480, 296, 1)的图像作为训练SRCNN 模型的高分辨率图像,训练好的生成对抗网络生成的800 张维度为(240, 148, 1)的图像作为训练SRCNN 模型的低分辨率图像,其中侧面、端面、倒角面图像分别为200、300、300 张.
标签相同的图像灰度值分布接近一致,随机从3 类图像中各抽取一张图像,生成3 类轴承滚子图像的灰度直方图,初步判断图像近似符合的分布类型,降采样后图像数据以及对应的灰度直方图如图7 所示.图中, GV 为灰度值,P为概率.滚子侧面图像灰度值集中分布在3 个区域,为多峰分布;滚子倒角面图像灰度值主要分布在0~50,为偏态分布;滚子端面图像灰度值分布较为均匀,考虑近似服从正态、柯西或拉普拉斯等分布.
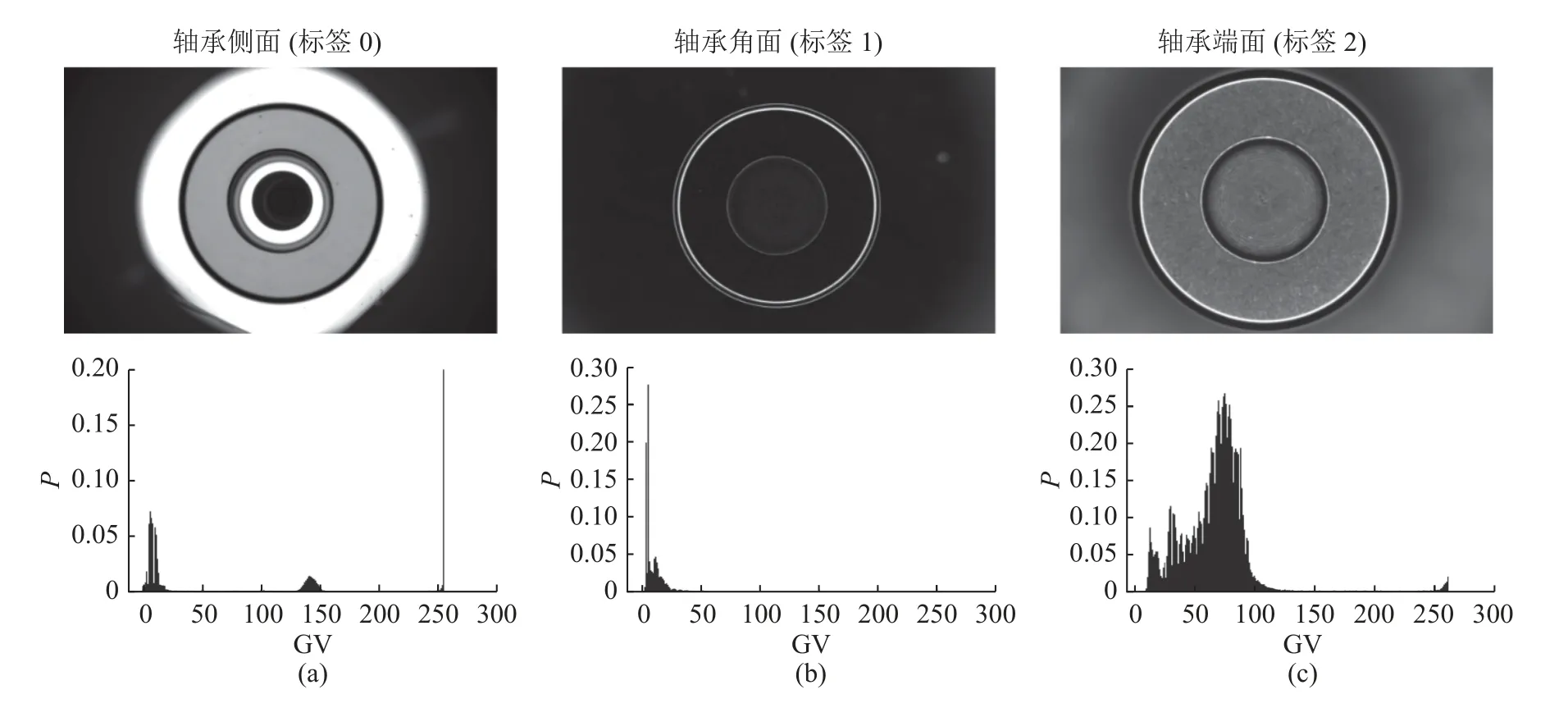
图7 降采样后图像数据及其灰度直方图Fig.7 Image data and gray histogram after down-sampling
以滚子端面为例,拟合图像原始数据分布,首先找出图像灰度值可能服从的分布,写出其待估计参数的概率密度函数,根据式(9)~(11)构建并求解最大似然函数,得到待估计参数值,通过计算真实值与拟合值之间的误差平方和(sum of squares for error, SSE)评价拟合程度.SSE 计算方法为
滚子端面图像可能服从的分布拟合结果及其SSE 如表1 所示,表中α 为位置参数,β 为尺度参数,ε 为形状参数.SSE 越小说明拟合误差越小,拟合效果越好.由表1 可知,用柯西分布拟合滚子端面灰度直方图拟合误差最小,即柯西分布为滚子端面图像的最优拟合分布,估计位置参数α = 69.070,尺度参数β = 11.861,即端面图像灰度值分布概率密度函数为

表1 轴承滚子端面灰度直方图拟合结果Tab.1 Gray histogram fitting results of bearing roller end face
滚子端面图像灰度直方图各分布拟合效果以及最优拟合分布如图8 所示.同理可得轴承侧面及倒角面最优拟合分布,其拟合效果如图9 所示,估计参数和SSE 如表2 所示,侧面图像最优拟合分布为多峰柯西分布.由表2 可知,侧面图像最优

表2 轴承滚子倒角面及侧面灰度直方图的拟合结果Tab.2 Fitting results of gray histogram of bearing roller chamfering and side surface
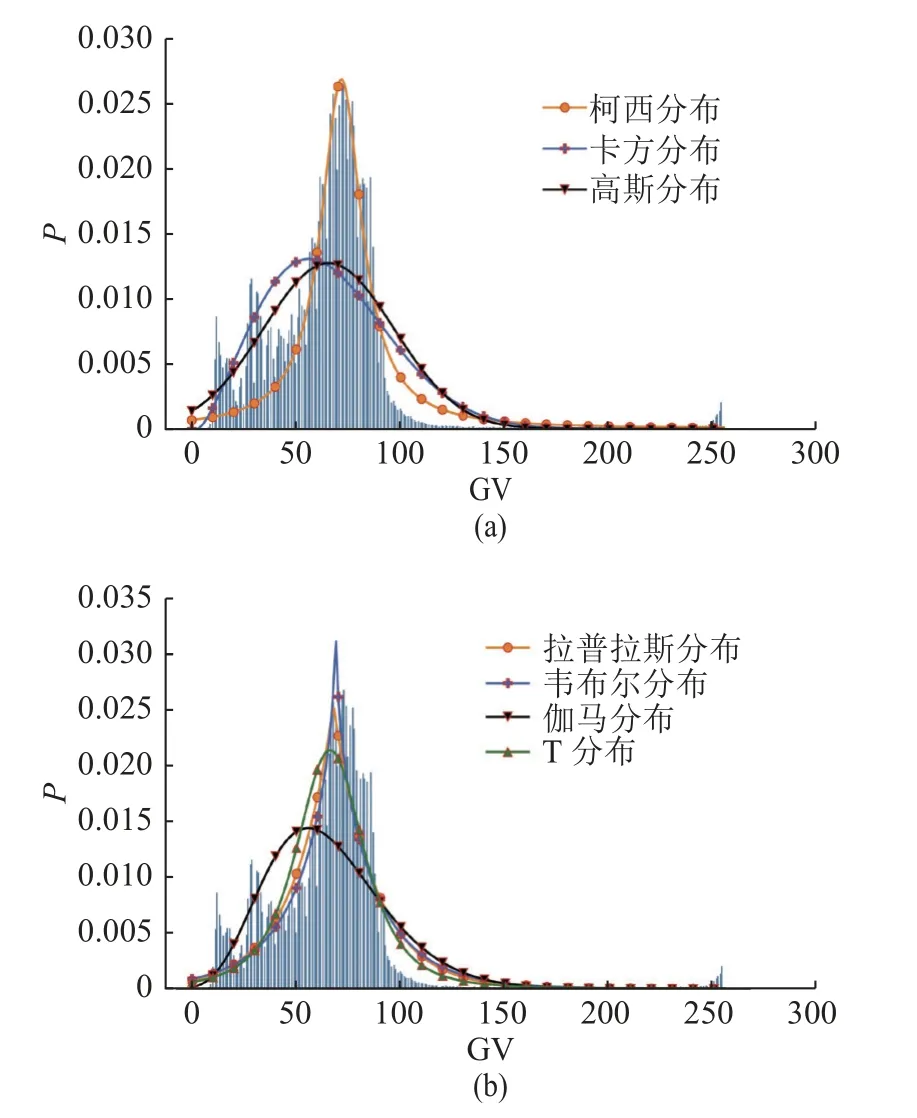
图8 轴承滚子端面灰度直方图拟合效果Fig.8 Gray histogram fitting effect of bearing roller end face
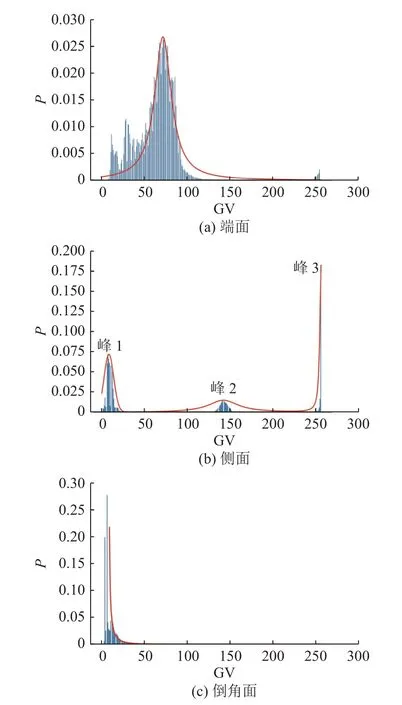
图9 轴承滚子各表面灰度直方图的最优分布拟合效果Fig.9 Optimal distribution fitting effect of gray histogram of bearing roller surface
拟合分布概率密度函数为
式中:α0、α1、α2为位置参数,β0、β1、β2为尺度参数.
倒角面图像最优拟合分布为三参数韦布尔分布,概率密度函数为
已知3 类样本图像分布的概率密度函数,根据Box-Muller 变换和MH 采样算法生成符合样本分布的随机噪声,端面数据为柯西分布,直接通过Box-Muller 变换求得概率密度函数关于R和θ边缘分布函数的反函数.由式(12)~(17)得到端面图像Box-Muller 变换后结果如下:
式中:U1、U2为服从0~1.0 均匀分布的随机数.
Receiving LRPT Weather Satellite Signal at VHF Band
根据Box-Muller 变换结果得到的一维随机噪声分布如图10 所示,图中Q为采样频数.侧面和倒角面图像概率密度函数形式较为复杂,直接通过MH 采样算法生成符合原始数据分布的噪声,设置MH 抽样算法f(x) 为侧面和倒角面的概率密度函数,q(x) 均为0~1.0 均匀分布,燃烧期M=10 000,迭代步数N=19 000.MH 采样算法一维采样结果如图11 所示.3 类样本图像二维采样结果与原始分布对比如图12 所示.图中,左侧为采样数据分布,右侧为原始数据分布.
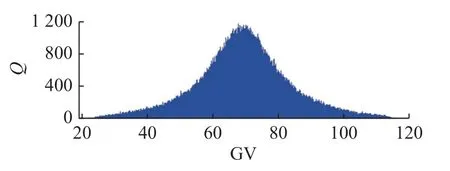
图10 Box-Muller 变换生成的端面一维随机噪声分布Fig.10 One-dimensional random noise distribution of end face generated by Box-Muller transform
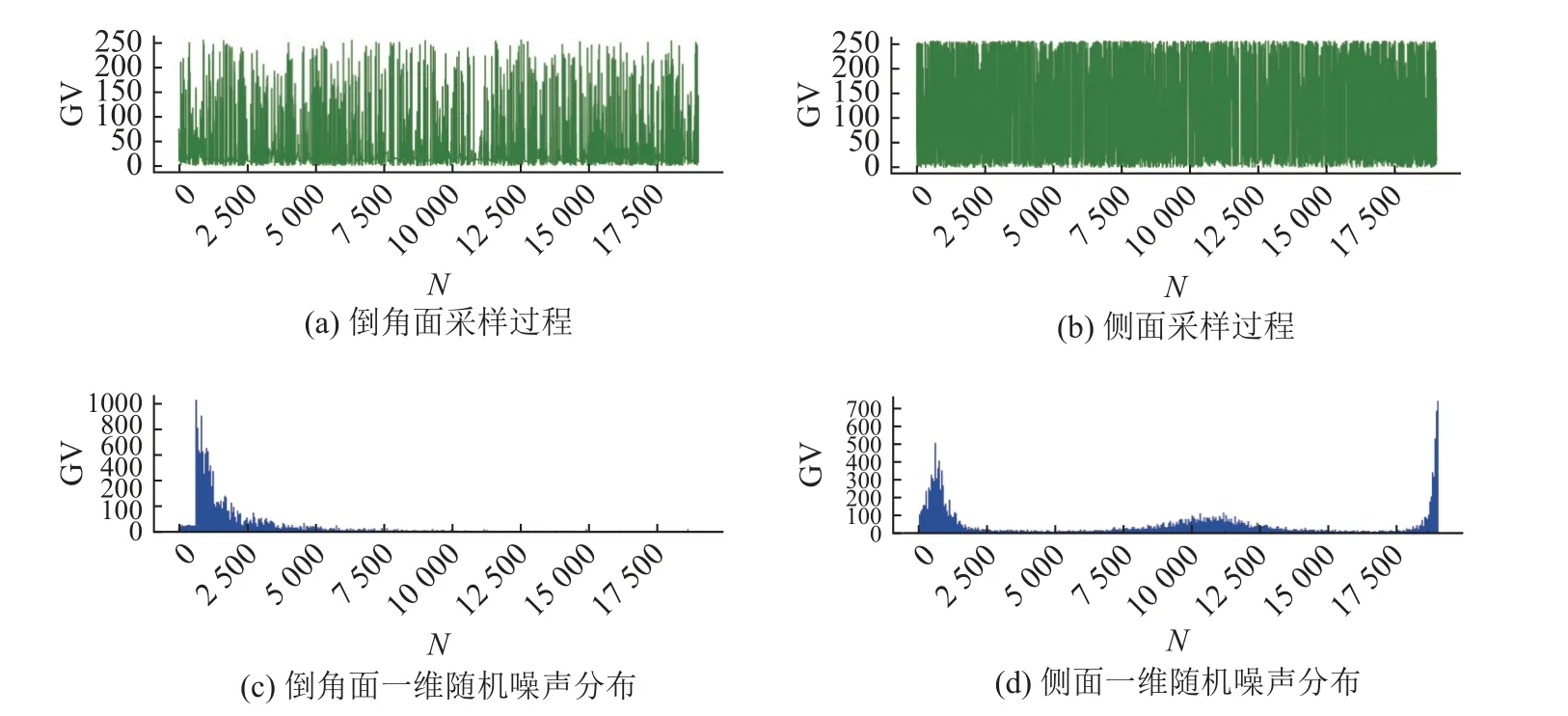
图11 MH 采样算法采样结果Fig.11 Sampling results of MH sampling algorithm

图12 采样数据分布与原始数据分布的对比图Fig.12 Comparison between distribution of sampled data and distribution of raw data
由图11、12 可知,MH 算法采样过程曲线呈现出较好的混合度,一维和二维采样数据分布近似还原了原始数据分布,验证了所提采样方法对于一维和二维采样都能取得较好的采样效果且采样过程稳定.
将使用的采样方法构建成噪声生成模块,外接在生成式对抗网络前端,为网络生成符合原始样本分布的噪声.当搭建WGAN-GP 网络时,判别器最后一层为未激活的全连接层,设置梯度惩罚权重参数 λ=1 ,学习率 l r=10-4,优化算法选用RMSProp.
设置SRCNN 前置层学习率 lr=10-3,最后层网络学习率为 1 0-4,优化算法选用Adam.批量大小均设置为3,GPU 为英伟达GTX-3080.通过与传统GAN 方法对比验证本研究所提出方法的优越性.WGAN-GP 模型经过22 000 个批次训练,生成的低分辨率图像作为SRCNN 的输入,再对SRCNN 模型训练300 个批次.本研究所提模型和对比模型生成的图像如图13 所示,各模型生成器和判别器的损失函数值变化如图14 所示.图中,E为迭代次数,b为批次大小,L为损失函数值.

图13 各模型输出结果对比图Fig.13 Comparison diagram of output results of each model
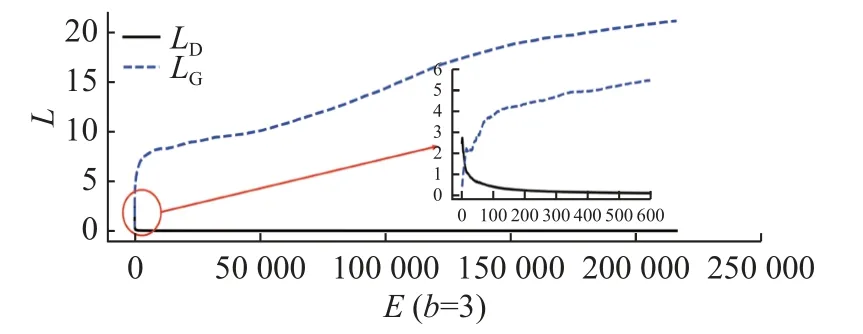
图14 CGAN 损失函数值变化曲线图Fig.14 Change curve of CGAN loss function value
由图13 可知,传统CGAN 网络难以训练,在训练过程中会出现严重的梯度消失问题,导致模型经过22 000 个批次训练后依旧无法有效收敛.WGAN-GP 相比CGAN 收敛效果较好,经过7 000个批次训练后,模型已经具备拟合原始图像基本轮廓的能力,但是直接向高分辨率图像建立映射关系,生成图像质量较差.所提方法采用逐层训练的方式,避免了生成对抗网络直接向高分辨率图像映射的弊端,而是通过SRCNN 提升图像分辨率,相比单独使用CGAN 和WGAN-GP 模型,本研究所提模型能够获得最优的生成图像质量.
由图14 可知,CGAN 网络由于判别器过于强大,经过600 次迭代后,判别器接近收敛,导致模型优化饱和,生成器无法学到有用的信息,输出图片质量较差.

图15 WGAN-GP 损失函数值变化曲线图Fig.15 Change curve of WGAN-GP loss function value

图16 SRCNN 损失函数值变化曲线图Fig.16 Change curve of SRCNN loss function value
各模型生成图像质量评价指标如表3 所示.CGAN 模型由于生成器无法学习到有效信息,生成图像质量较差,本研究所提模型相比WGANGP 模型,生成图像的信噪比提高13.07%,平均结构相似性提高32.40%,平均FID 降低37.58%.

表3 各模型生成图像质量评价表Tab.3 Quality evaluation table of image generated by each model
为了研究不同噪声对模型训练结果的影响,分别用不同离散程度的噪声输入WGAN-GP 模型进行训练,经过2 000 个批次训练输出结果如图17所示,输出图片质量评价如表4 所示.由表4 可知,随着输入噪声离散程度增大,生成图像的PSNR和SSIM 指标均降低,FID 升高,生成图像质量下降,因此,在训练时尽量采用离散程度较小的噪声.

表4 各模型生成图像质量评价表Tab.4 Quality evaluation table of image generated by each model

图17 不同标准差噪声及对应生成图像Fig.17 Different standard deviation noise and corresponding image generation
图18 为不同采样方式在WGAN-GP 网络训练过程中的FID 变化曲线,图中,MAP 为平均精确度.所提的预先对样本图像分布进行拟合的随机采样方法,相比直接采用均匀分布和正态分布生成噪声的方法更利于模型训练.

图18 轴承滚子数据集不同采样方式训练过程FID 曲线图Fig.18 Training process FID curve of bearing roller data set with different sampling methods
如图19 所示为WGAN-GP+SR 和WGAN-GP图像的对比.可以看出,相比直接用对抗网络生成的图像,超分辨率重建后的图像质量明显提升.

图19 WGAN-GP+SR 与WGAN-GP 图像对比Fig.19 Comparison of WGAN-GP+SR and WGAN-GP images
如图20 所示为对抗网络数据增强前后Yolov5目标检测模型训练过程平均精确度(MAP)曲线对比图,MAP 越高,检测效果越好.从图中可知,数据增强前和数据增强后MAP 峰值分别为0.532 和0.574,对抗网络数据增强后模型MAP 提高7.89%.

图20 Yolov5 目标检测模型训练过程MAP 曲线图Fig.20 Map diagram of Yolov5 target detection model training process
如图21 所示,对比3 组数据增强前后对轴承滚子缺陷检测的结果.可以看出,第1 组中Hump类缺陷在数据增强前被误检为ResidualPit 类,而第2 组和第3 组中的Hump 类缺陷在数据增强前则皆被漏检,证明通过对抗网络数据增强能够降低检测模型的误检率和漏检率.

图21 轴承滚子缺陷检测对比Fig.21 Comparison of bearing roller defect detection
4 结 语
对图像数据增强方法做了深入研究,提出基于生成对抗神经网络超分辨率重建的图像数据增强方法,通过案例分析和模型对比验证了所提方法具有最优的生成图像质量.通过拟合原始数据分布构建噪声生成模块,为模型输入符合数据分布的二维噪声,有效降低了模型的参数冗余度,提高了模型生成图像质量的计算经济性.融合WGAN-GP 和SRCNN 模型提出一种复合模型,避免生成对抗网络直接向高分辨率图像建立映射关系的弊端.本研究所提出的生成对抗网络结合图像超分重建思想所用模型并不固定,下一步可以尝试不同的模型组合,例如BEGAN+SRCNN.
猜你喜欢
北京航空航天大学学报(2022年6期)2022-07-02
广西民族大学学报(自然科学版)(2022年1期)2022-05-18
哈尔滨轴承(2021年1期)2021-07-21
高技术通讯(2021年3期)2021-06-09
哈尔滨轴承(2021年4期)2021-03-08
轴承(2018年10期)2018-07-25
当代旅游(2018年8期)2018-02-19
自动化学报(2017年5期)2017-05-14
光学精密工程(2016年1期)2016-11-07
华东理工大学学报(自然科学版)(2015年1期)2015-11-07
