
基于自注意力机制的双分支密集人群计数算法
2023-10-24 10:08杨天乐李玲霞张为
浙江大学学报(工学版) 2023年10期
杨天乐,李玲霞,张为
(天津大学 微电子学院,天津 300072)
随着人口的快速增长,高密集的人群聚集场景时有发生.人群计数通过估计图像中的人群总数和分布情况[1-3],可以有效规避人群密集带来的风险,目前已成为计算机视觉领域中热门的研究方向.在体育场、地铁站和旅游景区等场所中,人群计数能及时分析人群行为信息,避免人员踩踏、非法集会等公共安全事件.此外人群计数可以扩展到农业、生物医药和智能交通等其它领域中,如细胞计数[4]、果实计数[5]和车辆计数[6]等.
早期的人群计数算法通过手工特征分类[7]、目标检测[8]等方法实现,但是仅仅适用于稀疏场景,在高密集场景下由于严重遮挡的原因,检测效果不尽人意.随着计算机视觉技术的发展,基于深度学习的技术方案成为主流的研究方向[9].Lempitsky 等[10]提出将逐个体计数转换为像素值积分计数,更加适用于高密集、高遮挡场景,奠定了基于密度图的检测方式.Zhang 等[11]结合多个感受野不同的卷积,组成多列卷积神经网络,提取不同尺度的人头信息,优化人群计数中人群尺度跨度大的问题.万洪林等[12]引入注意力机制到网络中,将模型更加关注人群前景,并抑制噪声背景.Liu 等[13]采用双分支路径,同时实现检测和回归2 种计数方式,自适应地处理密集和稀疏场景.Xie 等[14]利用特征金字塔模块和涵盖通道、区域注意的特征重校准模块,实现同时解决人群尺度变化和复杂背景问题.此外,考虑到基于密度图的方式须花费较多精力来标注人头位置,近年来基于弱监督学习方式的研究越来越火热.Lei 等[15]提出多任务辅助的训练策略,构造正则化来限制生成密度图的自由度,实现从计数级标签和少量的位置级标签中学习模型.Liang 等[16]将Transformer 网络引入人群计数,利用Transformer 网络的自注意力机制,以增加人群数目序列的方式实现语义信息的提取.
由于卷积的感受野固定且有限,卷积神经网络 (convolutional neural network, CNN)方法仅能关注离散尺度的人群特征,无法适应密集场景,尤其是远近视角中跨度较大的连续尺度变化.上述方法仅仅利用通道或空间维度的注意力机制,对人群区域的聚焦有待进一步增强.由于CNN 网络特征的提取能力欠佳,计数级-弱监督方式多采用整体移植Transformer 通用网络的方式实现,但是Transformer 通用网络并非完全适配人群计数领域,存在检测精度低、模型参数量过大问题.
针对上述问题,本研究提出基于自注意力机制的双分支人群计数算法.结合CNN 和Transformer 这2 种网络框架,利用自注意力机制捕获的全局信息,关注并补充人群区域的局部细节信息,从而具备连续尺度的人群特征提取能力.为了进一步聚焦人群区域并抑制背景噪声,引入混合注意力模块,使人群区域的特征更加明显,从而提高模型的计数精度.采用基于位置级标签的全监督方式和基于计数级标签的弱监督方式分别进行实验,在几个常用的数据集上均取得了令人满意的结果.
1 算法设计
本研究提出的基于自注意力机制的双分支密集人群计数网络(dual-branch crowd counting net,DBCC-Net)整体结构如图1 所示.网络由3 部分组成:浅层特征提取网络、双分支融合网络和深层特征提取网络,最后通过一个简单的检测头输出人群密度图.浅层特征提取网络采用VGG-16 网络的前13 层,提取具有位置不变性的低层次特征.特征图分辨率依次降低,选取末端3 尺度特征作为输出,记为{f1,f2,f3}.
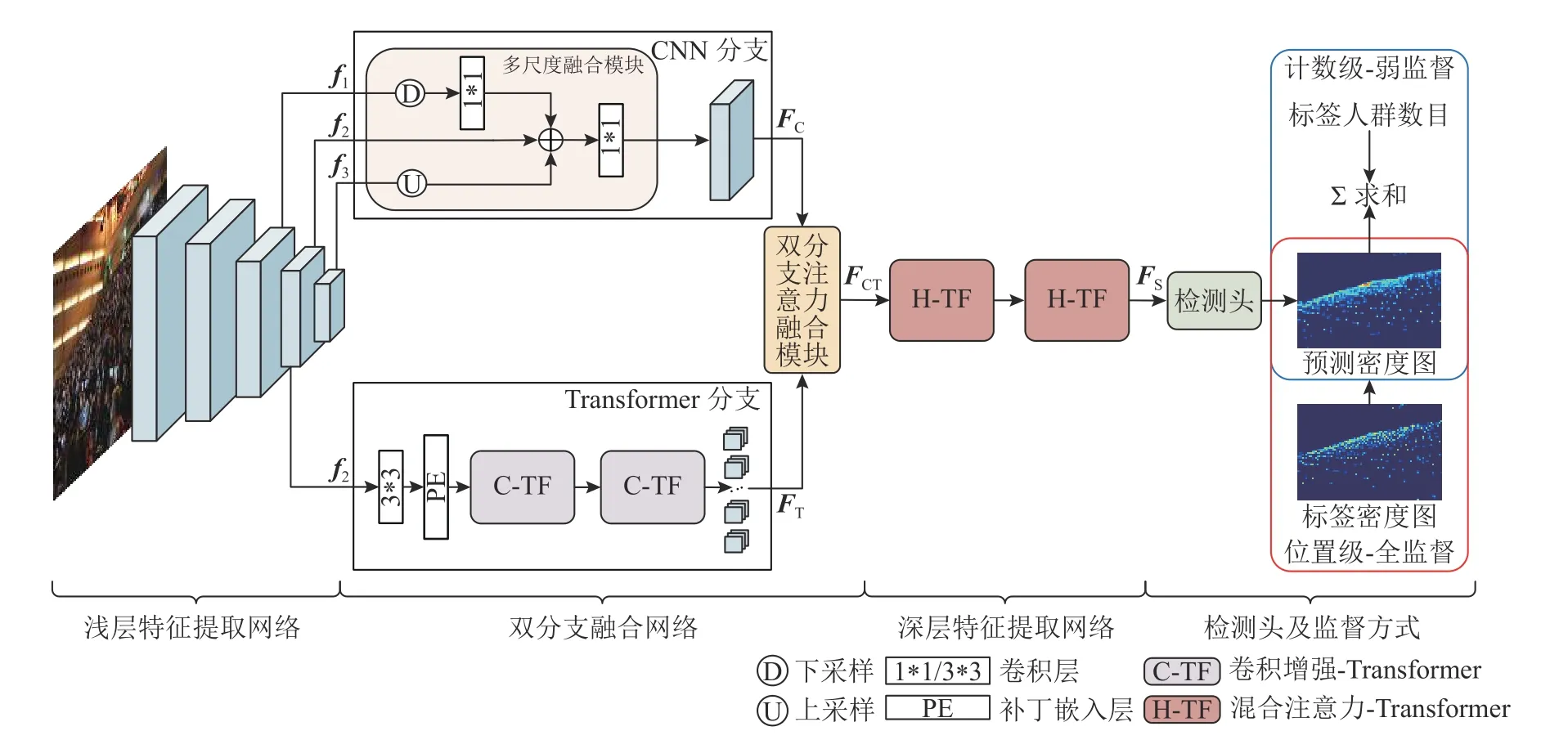
图1 基于自注意力机制的双分支密集人群计数算法整体结构图Fig.1 Overall structure of dual-branch crowd counting algorithm based on self-attention mechanism
双分支融合网络采用CNN 与Transformer 并行的双分支结构.CNN 分支通过多尺度融合模块提取{f1,f2,f3}的人群细节特征,经过合并下采样、插值上采样的操作,融合至1/8 尺度,输出该分支特征FC.Transformer 分支采用2 组基于卷积增强自注意力模块的Transformer 网络,将f2作为输入,经过降维卷积层、补丁嵌入层和Transformer网络后,输出该分支特征FT.由双分支注意力融合模块,将FC和FT融合,输出涵盖全局信息和局部信息的双分支特征FCT.深层特征提取网络采用2 组基于混合注意力模块的Transformer 网络,输出人群语义信息特征FS.最后,经空洞卷积检测头,将FS映射为通道数为1 的人群密度图P,求和即为人群总数.
本研究主要内容有:1)设计了CNN 和Transformer 双网络框架,结合卷积的局部关注和自注意力的全局建模,在保证精度的前提下,显著降低了Transformer 参数量.2)引入多尺度融合模块,提高局部信息提取能力;引入卷积增强自注意力模块,提高全局信息提取能力;引入双分支注意力融合模块,实现连续尺度的人群特征提取能力;引入混合注意力模块,进一步聚焦人群区域,提升模型整体计数性能.3)除位置级-全监督方式外,还关注了计数级-弱监督方式,缩小了两者之间的性能差距,为低成本人工标注提供解决方案.
1.1 双分支融合网络
1.1.1 CNN 分支 为了获取不同尺度下的人群细节信息,DBCC-Net 采用多尺度融合模块将{f1,f2,f3}进行融合.对于1/4 尺度特征f1,为了防止常规下采样过程中的人头细节损失,分别以(0,0)、(0,1)、(1,0)、(1,1)为起始位置,对特征图进行步长为2 的间隔取值采样,在通道维度拼接后即为1/8 尺度特征,由1 ∗ 1 卷积将通道数合并至256,过程如图2 所示.对于1/16 尺度特征f3,由双线性插值上采样至1/8 尺度.最终将3 种尺度特征相加,经卷积层和激活函数后输出CNN 分支特征FC.
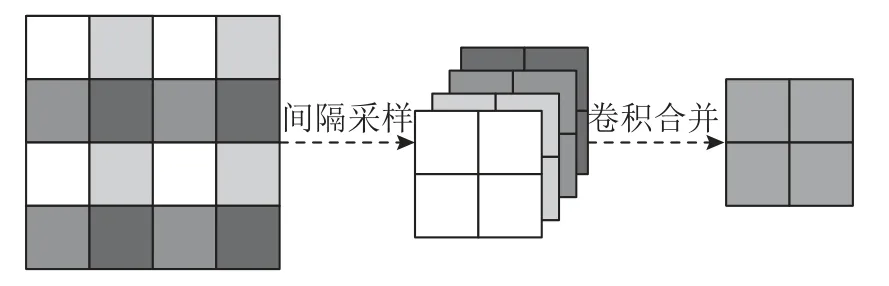
图2 1/4 尺度特征的下采样示意图Fig.2 Down sampled diagram of 1/4 scale feature
1.1.2 Transformer 分支 Transformer 分支采用浅层特征提取网络的f2作为输入,并将通道数目由512 降至256.相比于原图输入,较小的特征尺度和通道数目保证了较低的模型参数量,并且CNN低层次特征可有效防止Transformer 传播过程中的过拟合.DBCC-Net 采用的Transformer 网络由补丁嵌入层、卷积增强自注意力模块和前馈神经网络层组成.对于输入f2∈RB×H×W×C(其中B为批量大小,H和W为特征映射的长度和宽度,C为特征通道数),补丁嵌入层将其重塑为f2ʹ∈RB×C×H*W/P^2(其中P为补丁大小),实现三维特征到二维特征的转换.卷积增强自注意力模块是Transformer 网络的核心,负责全局范围内的特征提取.前馈神经网络内置激活函数和全连接层,负责增强非线性的表征能力.经过上述2 组深度为8 的网络传播后,输出Transformer 分支特征FT.
卷积增强自注意力模块由多头注意力模块和大感受野卷积增强模块组成,采用双分支结构连接,其结构如图3 所示.对于多头自注意力模块,首先经过线性层的转换,分别生成Q(query)、K(key)、V(value)参量.其中,Q参量与K参量的转置相乘生成空间维度的注意力特征,增加相对位置编码后,经SoftMax 归一化函数生成注意力权重.最后,该权重与V参量做矩阵乘法,经过线性层和残差连接后输出,自注意力机制计算式为
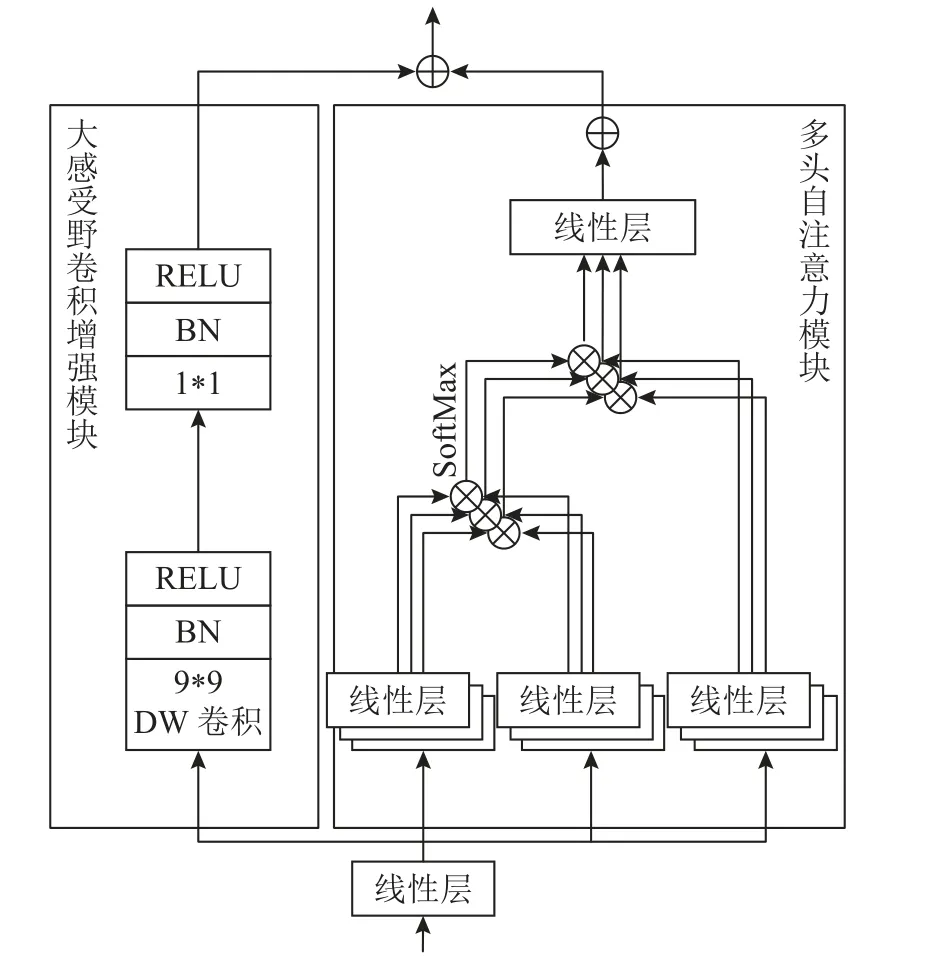
图3 卷积增强自注意力模块Fig.3 Convolution enhanced self-attention module
式中:d为多头自注意力的维度,可防止模型计算量过大;E为相对位置编码,可以显式地为一维特征添加二维位置信息.
DBCC-Net 为有效利用CNN 低层次特征并降低模型参数量,在Transformer 传播时固定了特征尺度和通道数目.然而在Transformer 通用模型[17]中,常采用逐层下采样升通道的方式来增加感受野.为了弥补感受野的部分缺失,引入了大感受野卷积增强模块.该模块由卷积核尺寸为9 ∗ 9 的深度可分离卷积组成,9 ∗ 9 的卷积尺寸保证了全局层面的信息交互,深度可分离卷积可有效避免引入较高的参数量和计算量.将以上2 个分支的特征相加,即为卷积增强自注意力模块的输出.
1.1.3 双分支注意力融合模块 CNN 分支具有细节丰富、局部注意的特征,Transformer 分支具有细节粗糙、全局注意的特征.由于2 种网络机制的不同,若不加区分的将两者相加或拼接,会产生次优的效果.因此,DBCC-Net 采用了双分支注意力融合模块,利用自注意力机制的基本思想,将Transformer 输出特征作为一种监督信号,来选择性的增强CNN 分支的细节信息,从而实现两种特征的融合,其结构如图4 所示.将FT经线性层生成Q参量,将FC经补丁嵌入层映射为一维特征并生成K、V参量.Q参量与K参量的转置相乘生成空间维度的注意力特征,经SoftMax 归一化函数生成注意力权重.最后,该权重与V参量做矩阵乘法,输出CNN 分支注意力特征FCʹ,与原始FC和FT做加后,即为双分支注意力融合模块输出FCT.
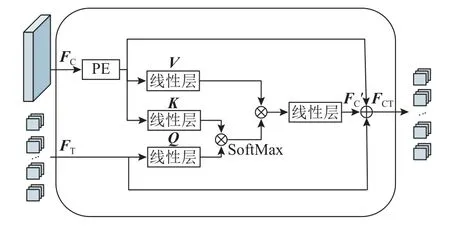
图4 双分支注意力融合模块Fig.4 Dual-branch attention fusion module
1.2 深层特征提取网络
深层特征提取网络由基于混合注意力模块的Transformer 组成,结构同上文提到的Transformer 网络结构.Transformer 只能利用有限的信息范围,可以通过增加特定层面的注意力机制学习更多的特征[18].因此,在自注意力模块的基础上,引入空间通道注意力模块,增强Transformer的表达能力,以进一步聚焦人群区域.混合注意力模块由多头注意力模块和空间通道注意力模块组成,采用双分支结构连接,其结构如图5 所示.
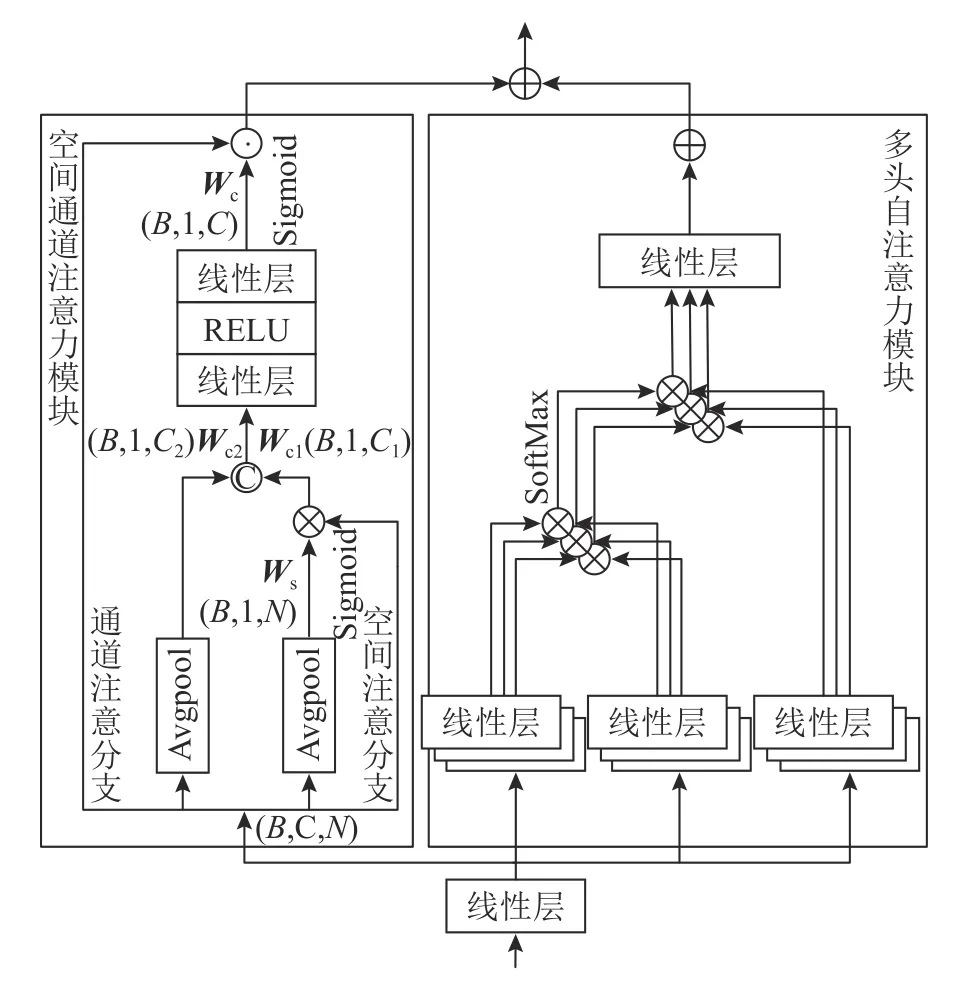
图5 混合注意力模块Fig.5 Hybrid attention module
空间通道注意力模块由空间注意分支和通道注意分支组成,全程在一维特征层面进行,不需要多余的重塑操作.对于输入fx∈RB×C×N,空间注意分支在通道维度进行平均池化,经Sigmoid 函数,生成空间维度的注意力权重Ws∈RB×1×N.空间注意力权重Ws与输入特征fx做矩阵乘法,经加权平均处理,生成融合空间信息的通道注意力权重Wc1∈RB×1×C;通道注意分支在空间维度进行平均池化,直接输出通道注意力权重Wc2∈RB×1×C.将两分支的输出权重拼接,经全连接层和Sigmoid 函数,生成最终的注意力权重Wc∈RB×1×C.fx与Wc进行Hadamard 乘积,即为空间通道注意力模块的输出特征fout∈RB×C×N.最后与多头注意力模块做权重为α 的加权融合,即为混合注意力模块的输出.
1.3 检测头与损失函数
检测头负责回归人群密度图,通过3 个膨胀系数分别为1、2、3 的3×3 空洞卷积实现,并由两层1×1 卷积将通道数目映射为1,输出1/8 尺度的人群密度图.
位置级-全监督使用人群计数中流行的DMLoss[19]作为损失函数,由人工标注的离散图直接作为标签,避免生成伪密度图过程中的误差影响.全监督损失函数Lfull由3 部分组成,其中,最优运输损失LOT负责度量预测图和标签之间的相似性,总变量损失LTV负责稀疏区域的回归,计数损失LC负责增加训练稳定 性,计算式为
式中:G为标签离散图,P为预测密度图,λ1和λ2分别设置为0.10 和0.01.
计数级-弱监督仅使用CG(对G求和得到的真实人群数目)作为标签,无须提供涵盖人头坐标和区域的位置级信息,从而能更好地节约标注成本.该方式将模型输出的预测人群密度图P求和,得到CP(对P求和得到的预测人群数目).利用损失函数Lweak衡量CG和CP之间的差异,完成对预测人群数目的监督.除了能够实现人群数目的预测外,通过计数级-弱监督方式获得P,仍涵盖较为精确的位置级信息.
弱监督采用Smooth L1[20]作为损失函数,相比于L1 损失或者L2 损失,Smooth L1 损失更易收敛,可以避免L1 损失的原点不可导问题.
2 人群计数实验及分析
2.1 实验细节与评价指标
实验的硬件配置为Intel Xeon 4310 处理器和NVIDIA A40 显卡;软件环境使用Ubuntu 18.04 操作系统、Python 3.8 编程语言、PyTorch 1.12.1 深度学习框架和CUDA 11.7 并行计算架构.
浅层特征提取网络VGG-16 采用ImageNet-1k 预训练权重,剩余卷积层和全连接层采用均值为0、方差为0.02 的随机权重.对于模型的超参数,混合注意力模块相加权重α 设为0.01,Transformer 模块深度设为8,多头注意力模块head 数设为8.在训练过程中,采用AdamW 优化器进行优化,其中学习率设为0.000 01、权值衰减设为0.000 1、批量大小根据图片裁剪尺寸设为4 或16.根据不同数据集的特点,采用固定尺寸Patch 进行训练.为避免数据冗余,从训练图片中随机裁剪出所需尺寸的Patch,并使用随机率为0.5 的水平翻转进行数据增强.
DBCC-Net 在Part A 数据集上的训练曲线如图6 所示,其中圆圈为损失值,三角为平均绝对误差,方块为均方误差,横坐标E为迭代次数,纵坐标LOSS、MAE、MSE 为结果数值.从图中可以看出,随着训练的进行,损失值能够快速下降并完成收敛,在440 轮次获得最佳计数性能,即MAE为55.3、MSE 为93.1.由此可以说明损失函数的选择和训练参数的设置较为合理,达到预期结果.

图6 DBCC-Net 模型的训练曲线Fig.6 Training curve of DBCC-Net
实验使用人群计数领域中常用的平均绝对误差(mean absolute error,MAE)和均方误差(mean squared error,MSE)用于性能评估,2 个指标的定义为
式中:N为测试数据集的图片总数,为测试集中第i张图片的真实人群数目,为测试集中第i张图片的预测人群数目.评价指标MAE 和MSE越小,表示模型的误差越低,计数性能越好.
2.2 数据集
ShanghaiTech: ShanghaiTech 数据集[11]包含了1 195 张标注图片和330 165 个标注人数,数据集由Part A 和Part B 这2 个部分组成.Part A 由482 张从互联网收集的高密集场景下的图片组成,训练集与测试集的数量比例为300∶182.Part A 中单张图片人数在33~3 139,是一个高度密集的数据集.Part B 由716 张上海街道图片组成,训练集与测试集的数量比例为400∶316.Part B 中单张图片人数为9~578,是相对稀疏的数据集.在训练过程中,对于Part A 数据集,Patch 大小设置为256×256;对于Part B 数据集,由于人群较稀疏且分辨率较差,裁剪大小设置为512×512.
UCF-QNRF: UCF-QNRF 数据集[21]包含1 535 张标记图片和1 251 642 个标注人数,是一个大型且具有挑战性的人群数据集.该数据集中单张图片人数为49~12 865,训练集与测试集的数量比例为1 201∶334.相比于其他数据集,该数据集中场景更加拥挤,更接近真实情况.由于分辨率较大,考虑到训练速度和内存占用,对于全监督部分,将最小边重塑为不超过2 048,裁剪大小为512×512.对于弱监督学习部分,将最小边重塑为不超过1 024,裁剪大小为256×256.
UCF_CC_50: UCF_CC_50 数据集[22]包含50 张标记图片和63 075 个标记人数,是极密集的小型人群数据集,单张图片人数为94~4 543.由于数据集的数量仅为50 张,采用5 折交叉验证的方式进行训练,裁剪大小为512×512.
JHU-Crowd++: JHU-Crowd++数据集[23]包含4 372 张标记图片和151 万余个标注人数,是在各种不同场景下收集的超大型人群数据集.该数据集中单张图片人数为0~25 000,训练集与测试集的数量比例为2 772∶1 600.由于分辨率较大,同样考虑到训练速度和内存占用,对于全监督部分,将最小边重塑为2 048 以下,裁剪大小为512×512.对于弱监督学习部分,将最小边重塑为不超过1 024,裁剪大小为256×256.
2.3 实验结果
采用全监督和弱监督2 种方式,评估模型在4 个常用数据集上的检测效果,并与其他人群计数模型进行对比.从结果可以看出,所提模型在ShanghaiTech、UCF-QNRF、UCF_CC_50 和JHUCrowd++数据集上均获得令人满意的成绩.
2.3.1 定量结果 采用基于位置级标签的全监督方式,结果表1 所示,对于Part A 数据集,所提模型在所有比较的方法中取得了最好的成绩.与采用CNN 与Transformer 结合的CLTR 算法相比,DBCC-Net 将Part A 的MAE 和MSE 分别降低了2.8% 和2.2%;在Part B 数据集中,DBCC-Net 以9.8 的MSE 取得最优效果,MAE 也十分接近最优成绩.与其他数据集相比,Part B 数据集更加稀疏和简单,复杂背景噪声和连续尺度人头变化问题不突出,因此本模型在MAE 上取得与其他模型相似的性能.对于QNRF 数据集,DBCC-Net 以82.9 的MAE 达到优秀的计数水平,验证了算法在拥挤场景、复杂背景干扰下的计数性能.对于UCF_CC_50 数据集,取得最低的误差结果,证明算法可以很好地适用于小型数据集.对于JHUCrowd++大型数据集,该算法展现了良好的计数性能.与采用相同损失函数的DM-Count 模型相比,在4 个数据集上,DBCC-Net 的MAE 分别降低了4.4、0.7、2.1、63.5,MSE 分别降低了2.6、2.0、2.3、86.4.

表1 位置级-全监督对比实验的结果Tab.1 Results of position-level full supervision comparison experiment
采用基于计数级标签的弱监督方式,结果如表2所示.可以看出,DBCC-Net 在4 个数据集上均取得了最好的成绩,进一步表明算法的有效性.相比于采用Transformer 网络的TransCrowd 算法,DBCC-Net 在4 个数据集上的MAE 分别降低了9.1%、19.4%、6.5%和18.2%.DBCC-Net 极大地缩小了全监督和弱监督算法之间的性能差距,达到全监督算法87.9%的计数性能,为降低人工标注成本提供了解决方案.
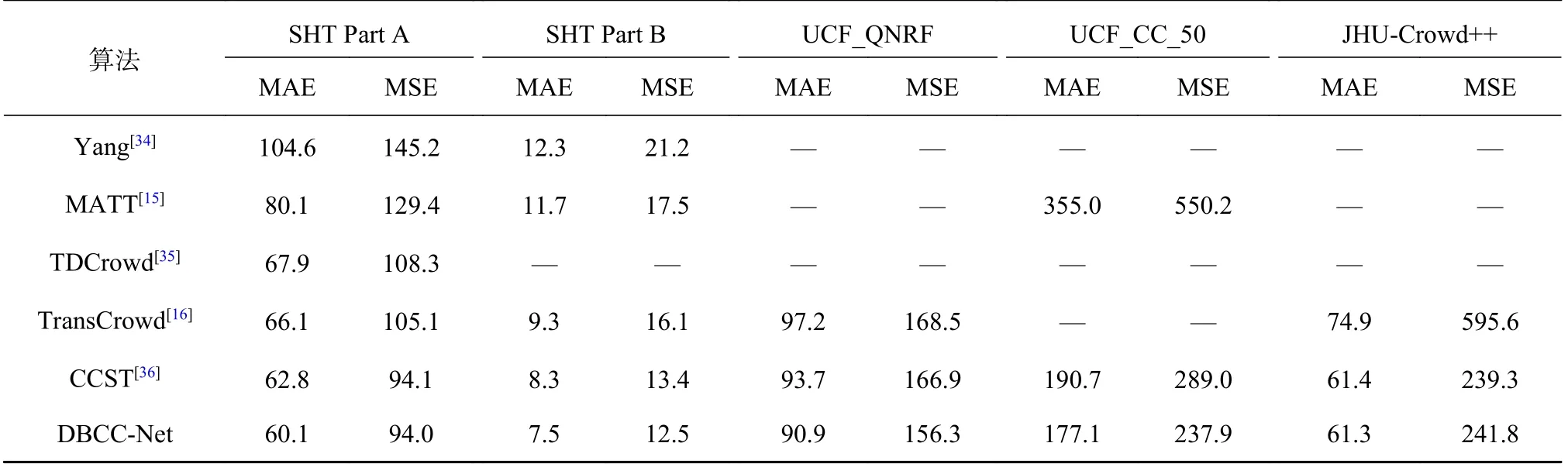
表2 计数级-弱监督对比实验的结果Tab.2 Results of count-level weakly supervision comparison experiment
2.3.2 可视化结果 将模型输出进行可视化展示,图7 展示全监督下的模型在4 个数据集上的预测密度图.其中,SHT Part B 和UCF_CC_50 图片分别为稀疏场景和全密集场景下的检测效果,SHT Part A 和QNRF 图片为复杂场景、多尺度人头大小和遮挡下的检测效果.由图7 可以看出,预测密度图接近真实值,计数结果较为准确.

图7 位置级-全监督人群密度图Fig.7 Position-level full supervision crowd density map
为了进一步分析本研究模型优于其他方法的原因,图8 展示DBCC-Net 与DM-Count[19]、CFANet[37]的可视化对比图.从第1 行标记可以看出,本研究模型在准确计数稀疏场景的基础上,在高密集、高遮挡场景下更具优势,能够清晰地定位出人头位置,证明了采用双分支融合模块能够较好地融合细节特征和全局特征;从第2 行标记可以看出,本研究模型能够有效识别大、中、小尺寸的人头目标,说明DBCC-Net 具备连续的尺度特征提取能力.从第3 行标记可以看出,与其他方法相比,本研究模型能准确区分前景和背景,有效排除复杂环境下的干扰.
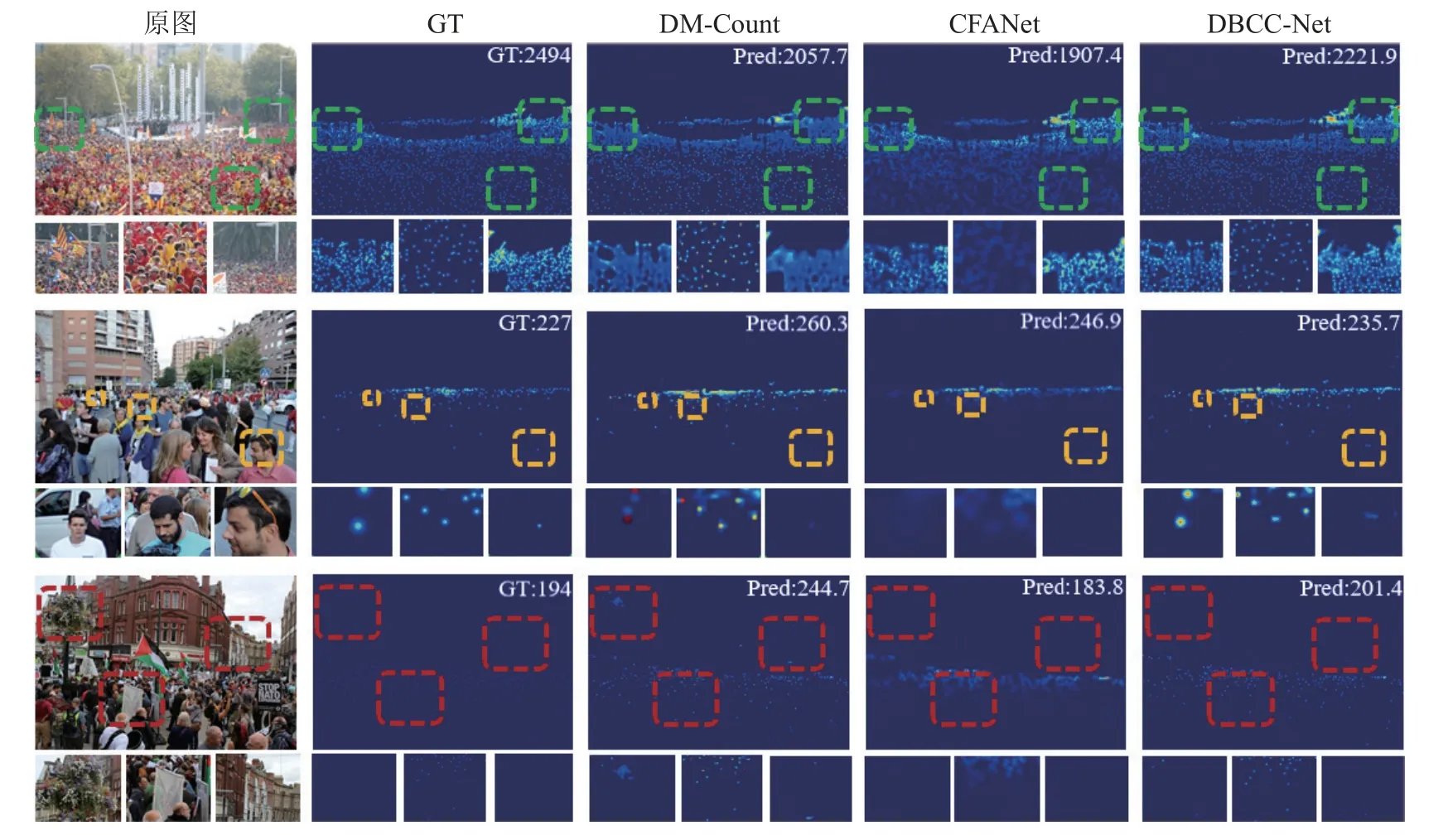
图8 不同方法的可视化对比图Fig.8 Visual comparison of different methods
图9 展示弱监督下的模型在QNRF 数据集上的人群关注图,图中138、198、398、652 的人群数量对应从稀疏到密集的不同场景.从预测结果可以看出,DBCC-Net 仅以人群数目作为学习对象,即可准确地定位到人头位置,实现人群数目估计和人群分布估计2 种任务需求.

图9 计数级-弱监督人群关注图Fig.9 Count-level weakly supervision crowd density map
2.4 实验分析
2.4.1 框架与模型复杂度分析 为了评估模型的空间和时间复杂度,本研究根据参数量Np和每秒浮点运算次数GFLOPs 对模型进行对比分析,如表3 所示.在空间复杂度方面,DBCC-Net 以38.0×106的参数量处于Transformer 框架模型中的较低水平,接近CNN 框架模型的参数量.在时间复杂度方面,由于结合了2 种网络的运行机制,本研究算法在运算次数方面没有明显优势,但仍优于RAN[32]、CCST[36]近期研究,并且在计数性能方面取得更好的表现.经本实验硬件平台验证,DBCCNet 能将1 024×768 大小的图片以单张0.368 6 s 的推理速度实现人群计数,满足实时性要求.

表3 时间及空间复杂度对比的实验结果Tab.3 Experimental results of time and space complexity comparison
为了验证算法框架的有效性,使用相同的损失函数和训练方法,对不同框架的算法进行对比实验,结果如表4 所示.基于CNN 的算法拥有较小的模型尺寸,但其精度有待进一步提高.基于Transformer 的算法精度较高,但其模型参数量较大.采用CNN 与Transformer 直接串联的方式,效果提升有限.采用DBCC-Net 的双分支融合框架,较好地结合了2 种网络的优势,相比CNN 框架绝对误差降低了6.9%,相比Transformer 框架模型参数量降低了64%.
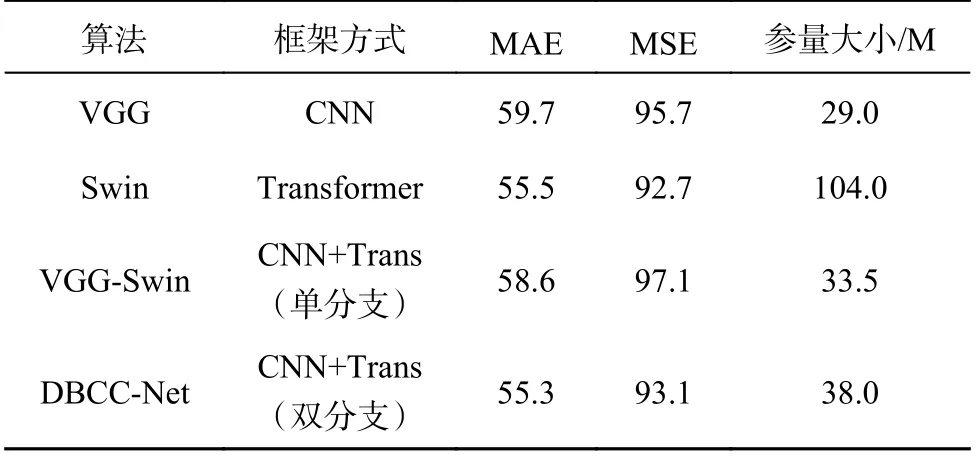
表4 网络模型框架的对比实验结果Tab.4 Comparison of experimental results with network model framework
2.4.2 消融实验 为了验证DBCC-Net 各个组成的有效性,将串行连接的VGG 和Swin Transformer作为基本模型进行消融实验,结果如表5 所示.结合CNN 与Transformer 这2 种网络的基本模型即具备较高的计数精度,展示良好的人群特征提取能力.在串行连接的基础上引入CNN 分支并进行双分支融合后,MAE 和MSE 分别降低了0.9 和0.7,表明融合局部信息和全局信息可以有效提升模型性能.在引入卷积增强自注意力模块后,误差进一步降低.最后在此基础上,引入混合注意力模块,MAE 和MSE 相较于基本模型分别降低了3.3 和4.0.以上实验证明,各组成有效提升了模型计数性能.

表5 DBCC-Net 模型消融实验结果Tab.5 Results of ablation experiments for DBCC-Net
为了验证全监督损失函数DM-Loss 的有效性,与基于传统高斯密度图的MSE-Loss 和基于离散点标注图的Bayesian-Loss 进行定量对比实验,如表6 所示.相比于前两者,DM-Loss 能将MAE降低1.9 和5.3,MSE 降低2.5 和8.1,表明DMLoss 能更好地适用于DBCC-Net 网络模型.为了确定全监督损失函数中最优运输损失LOT的权重λ1和总变量损失LTV的权重λ2,类比于DMCount[19],本研究将λ1固定0.1,设置λ2分别为0.01、0.05 和0.10,输出误差结果55.3、56.8 和57.3,从而确定λ2为0.01.设置λ1分别为0.01、0.05 和0.10,输出误差结果57.9、56.4 和55.3,从而确定了λ1和λ2的最优权重为0.10 和0.01.
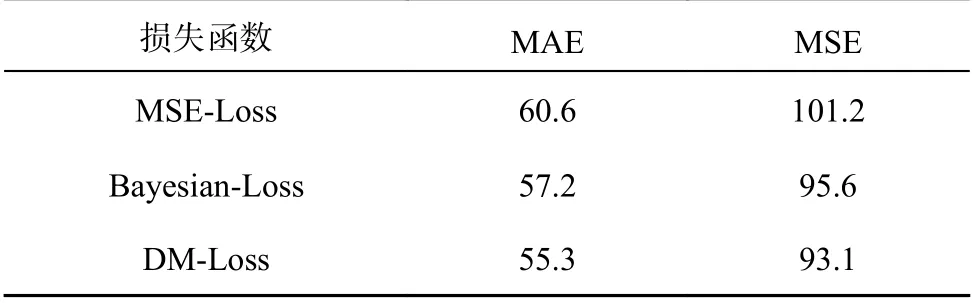
表6 损失函数的对比实验结果Tab.6 Comparison experiment results of loss function
为了进一步分析各模块对计数性能的影响,本研究采用弱监督学习的方式进行对比实验.分别在多尺度选择和注意力增强方面进行探究.对于多尺度融合模块,结果如表7 所示.采用1/4、1/8 或1/16 单个尺寸的卷积特征,仅能补充单一尺度的细节信息,模型效果相似.利用多尺度融合模块,可以充分提取不同尺度下的细节信息,从而有效降低模型误差.对于混合注意力模块,结果如表8 所示.相比于仅使用单一维度的注意力增强,同时关注通道和空间维度的注意力增强,有助于进一步提升模型效果.相较于传统CBAM模块,本研究提出的空间通道注意力模块获得最优的结果,且仅在一维特征层面实现,有利于Transformer 网络中一维序列的传播,无需空间注意力分支中一维特征到二维特征之间的转换.
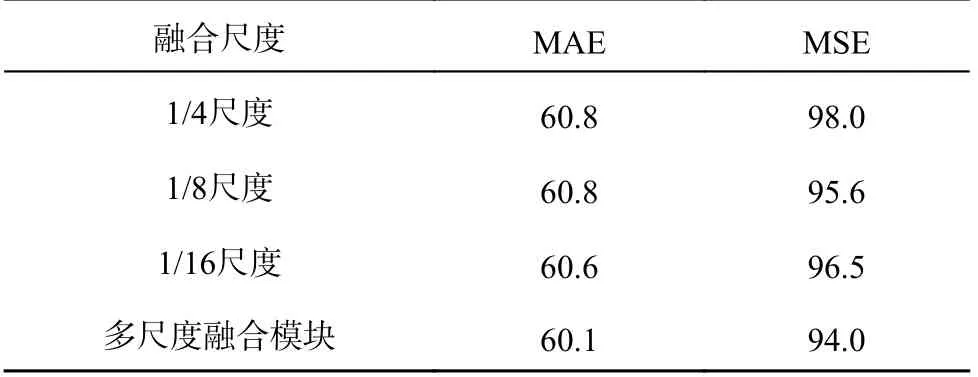
表7 多尺度融合模块的对比实验结果Tab.7 Comparative experiment results of multiple fusion modules
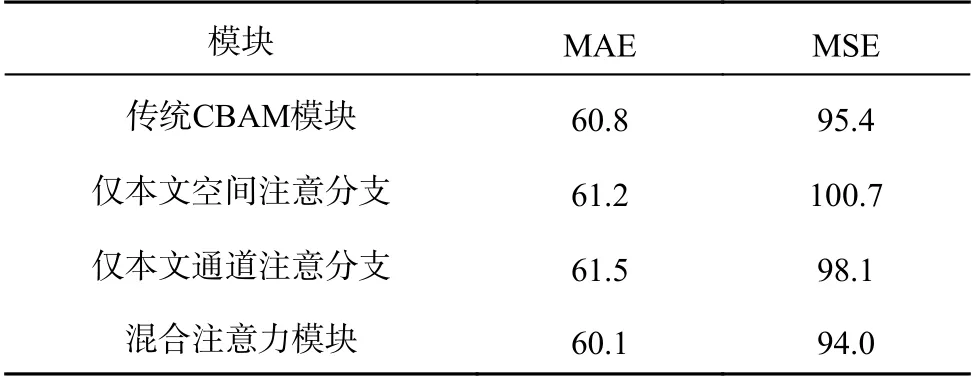
表8 混合注意力模块的对比实验结果Tab.8 Comparative experimental results of hybrid attention modules
3 结 语
本研究提出基于自注意力机制的双分支密集人群计数算法,有效解决了当前人群计数算法面临的主要问题.通过引入多尺度融合模块提高局部信息提取能力,通过引入基于卷积增强的自注意力模块提高全局信息提取能力.通过采用双分支融合模块,实现连续尺度的人群检测能力.通过增加混合注意力模块,进一步聚焦人群区域,提升模型的整体计数性能.本研究分别采用全监督学习和弱监督学习进行实验,两者在多个数据集上取得满意的性能表现.在弱监督学习中,以较低的参数量实现更佳的计数效果,并缩小与全监督算法之间的性能差距.实验结果表明,该算法具备良好的人群计数性能,可以实现高密集、高遮挡场景下的准确计数,具有较高的应用价值.
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09
内蒙古民族大学学报(社会科学版)(2020年2期)2020-11-06
学生天地(2019年28期)2019-08-25
数学物理学报(2018年1期)2018-03-26
传媒评论(2017年3期)2017-06-13
第二课堂(课外活动版)(2016年2期)2016-10-21
太空探索(2016年5期)2016-07-12
时代英语·高三(2014年5期)2014-08-26
山西大同大学学报(自然科学版)(2014年3期)2014-01-23
疯狂英语·口语版(2013年1期)2013-01-31
