
可形变Transformer 辅助的胸部X 光影像疾病诊断模型
2023-10-24 10:08胡锦波聂为之宋丹高卓白云鹏赵丰
浙江大学学报(工学版) 2023年10期
胡锦波,聂为之,宋丹,高卓,白云鹏,赵丰
(1.天津大学 电气自动化与信息工程学院,天津 300072;2.长春职业技术学院 信息学院,吉林 长春 130033;3.天津市胸科医院 心血管外科,天津 300222)
近年来,新型冠状病毒感染对全球产生较大的影响,肺部病变诊疗受到越来越多人的重视.目前医院中一般使用X 光片对肺部疾病进行常规检查,这是因为X 光片获取方式比较简单,普通医院就可以基于常规设备标准获得[1].胸部X 光影像中有很多细小且相似的特点,人眼进行观察时,很容易区分不出.在这种情况下,医生可以利用计算机辅助检测(computer-aided detection,CAD)系统对X 光影像进行诊断[2].随着深度学习技术的发展,人们对使用人工智能改进CAD 系统产生了极大的关注.
医学图像的诊断一般属于多标签分类任务[3-6].由于医学影像成像的模糊性、部分病灶区域的不规则性和位置的不确定性,针对医学影像的多标签分类任务需要特别注意以下2 点:1)如何定位感兴趣区域并从区域中有效提取特征;2)如何处理标签不平衡问题.针对上述问题,提出可形变Transformer 辅助的胸部X 光影像疾病诊断算法.该算法对Transformer 模块和双注意力模块进行优化,可以高效地处理高分辨率的医学图像,在不影响诊断正确率的情况下,提升模型的计算效率,使其更有利于开展技术落地和应用场景的示范工作;在Transformer 部分引入预训练模型的分类表征作为先验知识,指导目标影像表征信息的更新和多类信息的融合;此外,还引入非对称损失函数[7],以此来更好地处理正负样本不均衡问题.本研究方法兼顾模型的分类精度和计算复杂度,通过公开数据集ChestX-14 和CheXpert 上的多组实验,证明了所提方法的正确性和有效性.工作代码已经公开,代码链接为:https://github.com/hjbzsy/Q2L-ChestX/tre e/master.
1 相关工作
随着计算机技术的快速崛起,医学人工智能(medical artificial intelligence, MAI)吸引了越来越多的学者进行研究[8-9],MAI 的相关技术也在很多医疗领域产生重要影响[10-12].在MAI 的研究工作中,学者们在胸部X 光图片分类问题上取得一系列新的研究进展.在CheXNet-8 数据集上Wang 等[13]测试了4 种网络算法,在对比4 种算法分类结果的同时,得出性能最好的网络为ResNet[14],而后又在ResNet 基础上将损失函数替换为加权损失函数,结果表明加权损失函数对于提升算法的性能有一定的作用.Li 等[15]采用长短期记忆网络(long-short term memory network, LSTM)来研究14 类疾病病理标签的相关性.在DenseNet[16]的基础上,添加LSTM 学习各个疾病病理标签之间的相关信息,并将DenseNet 网络中稠密块的卷积个数设为4 个来降低算法复杂度,同时使用Wang 等[13]设计的加权损失函数进行实验,最终模型取得较好的效果.Guendel 等[17]同时使用2 个数据集进行训练,将CheXray-14 数据集和PLCO数据集混合,在DenseNet 基础上提出DNetLoc,在实验过程中通过修改不同数据集的添加比例来对网络性能进行对比,最终得到更优的结果.Chen 等[18]根据人类的学习习惯提出一种新的网络训练方式,将数据集按照学习程度由易到难的顺序排列,并以这样的顺序对网络进行训练,这样训练得到的网络达到了很好的效果.Rajpurkar 等[19]提出CheXNet 算法,该算法使用迁移学习加微调的方式进行训练,并修改最后的全连接层来适应分类要求,在这种情况下,对14 类肺部疾病的诊断取得了更好的结果.
目前主流的分类方法大多是对不同的卷积神经网络做出改进,通过提高特征提取能力来提高分类精度.随着Transformer 在计算机视觉领域的发展,Liu 等[20]提出Query2label 模型,该模型先对图片通过一个骨干网络提取特征图,然后将图片特征和标签特征送入Transformer 解码器,把图片特征作为Key 和Value,标签特征作为Query,利用Transformer 解码器内部的交叉注意模块,预测相关标签的存在性,在自然图像分类任务上取得了较好的效果.本研究设计一种结合可形变Transformer 与压缩型双注意力模块的多标签胸部疾病分类模型,将Transformer 应用到医学图像领域,以期获得较好的分类效果.
2 可形变Transformer 辅助的胸部X 光影像疾病诊断模型
通过学者们的工作发现,适当增大特征图分辨率有利于提高模型的分类性能,但同时会带来高计算复杂度和高内存占用.本研究提出一种基于可形变Transformer 和压缩型双注意力模块的胸部X 光图像分类模型,模型框架分为特征提取阶段和类别预测阶段:特征提取阶段采用压缩型双注意力模块,有效去除影像的冗余信息,提升后期信息表征的有效性;类别预测阶段在可形变Transformer 部分,引入预训练模型的先验知识作为引导,指导多类别信息的表征.可形变Transformer解码器部分的交叉注意力模块可以有效定位不同病灶的区域,进一步对有效信息进行表征.本研究模型可以在得到较好分类精度的同时,有效地降低了模型的计算复杂度.所提模型框架如图1所示,其中H、W分别为特征图的高、宽,C为特征图通道数.
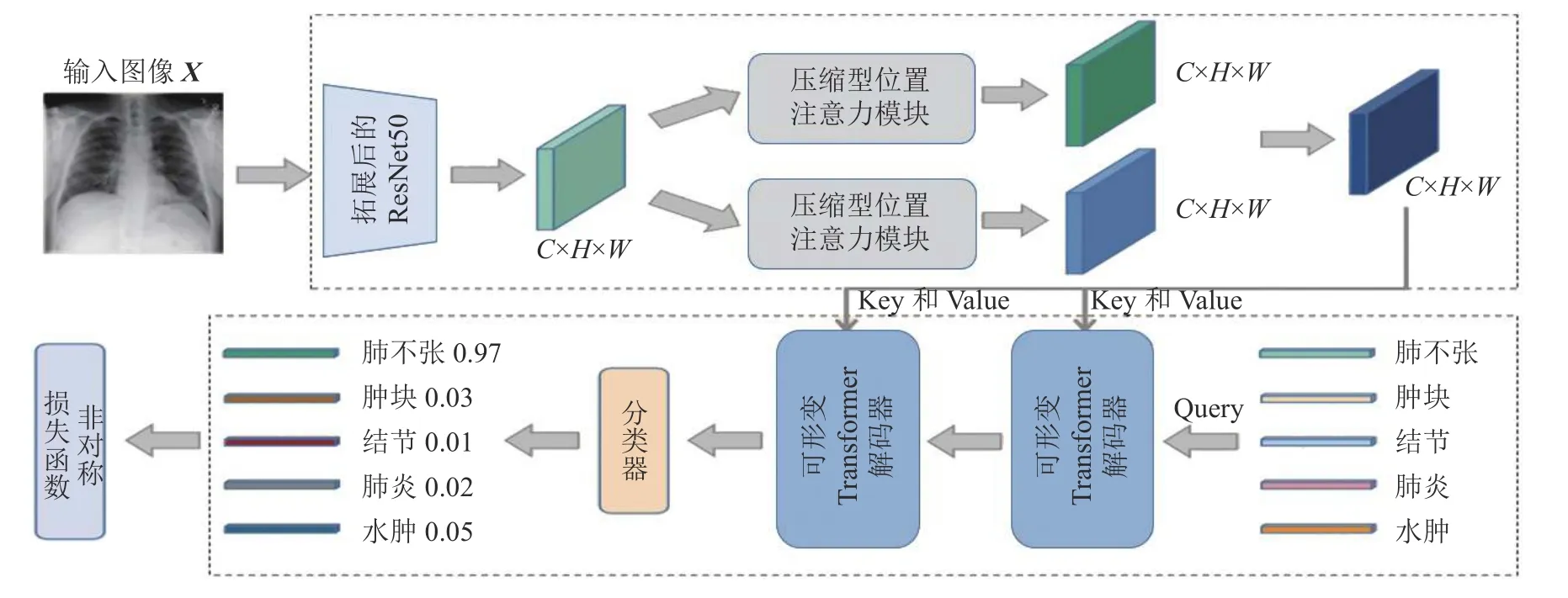
图1 胸部X 光图像分类模型框架Fig.1 Framework of chest X-ray image classification model
在特征提取阶段,首先使用扩展后的ResNet50获得较高分辨率的初始特征图[21],接着通过压缩型双注意力模块加强特征表示;在类别预测阶段,使用标签嵌入作为查询,通过可形变Transformer解码器内部的交叉注意力模块,自适应地从上游传来的特征图中提取与类别相关的特征,以预测相关标签的存在性.引入预训练模型的分类表征来指导影像数据在不同类别下的表征,最终传入分类器,获得预测结果.此外还引入非对称损失函数以改善数据集中正负样本不均衡的问题.
2.1 特征提取网络
特征提取层选取的是深度残差网络 (residual neural network, ResNet).ResNet 基于一种残差学习结构,有效地解决了卷积神经网络因为层次不断加深而引起的网络退化问题.目前,ResNet 主要使用2 种残差单元,结构如图2 所示.
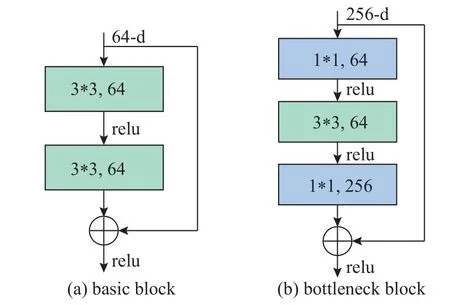
图2 ResNet 系列主要使用的2 种残差结构Fig.2 Two main residual structures used by ResNet family
在图2(a)为basic block,由2 个3 ∗ 3 卷积和一个快捷连接构成,并且卷积层与快捷连接的输出经过元素相加后的特征图作为下一层的输入.basic block 常被用于浅层网络,如ResNet18 和Res-Net34 中均使用basic block 作为基本残差单元;在图2(b)为bottleneck block,利用1 ∗ 1 卷积块进行降维,接着使用3 ∗ 3 卷积块进行特征提取,最后利用1 ∗1 卷积块进行升维.在不影响模型精度的同时,减少计算过程中的参数量,降低计算复杂度,进而缩短整个模型训练所需的时间.bottleneck block 常被用于深层网络,如ResNet50、ResNet101 和Res-Net152 均使用bottleneck block 作为基本残差单元.
出于对模型性能和参数量的考虑,选择扩展后的ResNet50(dilated ResNet50)进行特征提取.将原始ResNet50 中最后一个残差单元的下采样删除,并选取可变形卷积作为卷积核.在未引入额外参数的情况下,获取到含有更加丰富信息的特征图.输入图像X∈RH0×W0×3,经过扩展后的ResNet50获得特征图F0∈RH×W×d0, 其中H=H0/16,W=W0/16,d0=2 048,d0为特征图的通道数.特征图的分辨率与之前相比有所提高.
2.2 可形变Transformer 模块
标准Transformer 中使用多头注意力机制,具体计算式为
式中:zq为查询特征,x为输入特征,m为注意力头的索引,Wm为每个注意力头的权重矩阵,k为经过采样后Key 的索引,Am,q,k为第m个注意力头内的第k个采样点的注意力权重,为经过采样后每个注意力头的权重矩阵,xk为经过采样后的输入特征.该式的计算复杂度为O(NaC2+NbC2+NaNbC),其中Na、Nb分别为Query 和Key 的对象查询数.
原始的Transformer 解码器的输入包括2 个部分:一部分来自注意力模块的特征输出,另一部分为通过学习获得的标签嵌入表示的N个对象查询,N为类别的数量.Transformer 解码器内部包含交叉注意力模块和自注意力模块.对交叉注意力模块来说,Query 为对象查询,Key 为注意力模块的输出,因此,Na=N,Nb=H×W,则交叉注意力模块的复杂度为O(HWC2+NHWC),受到特征图分辨率与通道数的影响.对于自注意力模块来说,Query和Key 都是标签嵌入表示的N个对象查询,因此Na=Nb=N,则自注意模块的复杂度为O(2NC2+N2C),受到对象查询的数量以及标签嵌入维度的影响.Transformer 中的注意力模块会查询特征图上的所有位置.当特征图分辨率较高时,会带来较高的计算复杂度,因此提出采用可形变Transformer(deformable transformer)来解决这一问题.可形变Transformer 中使用可形变注意力模块,如图3 所示.
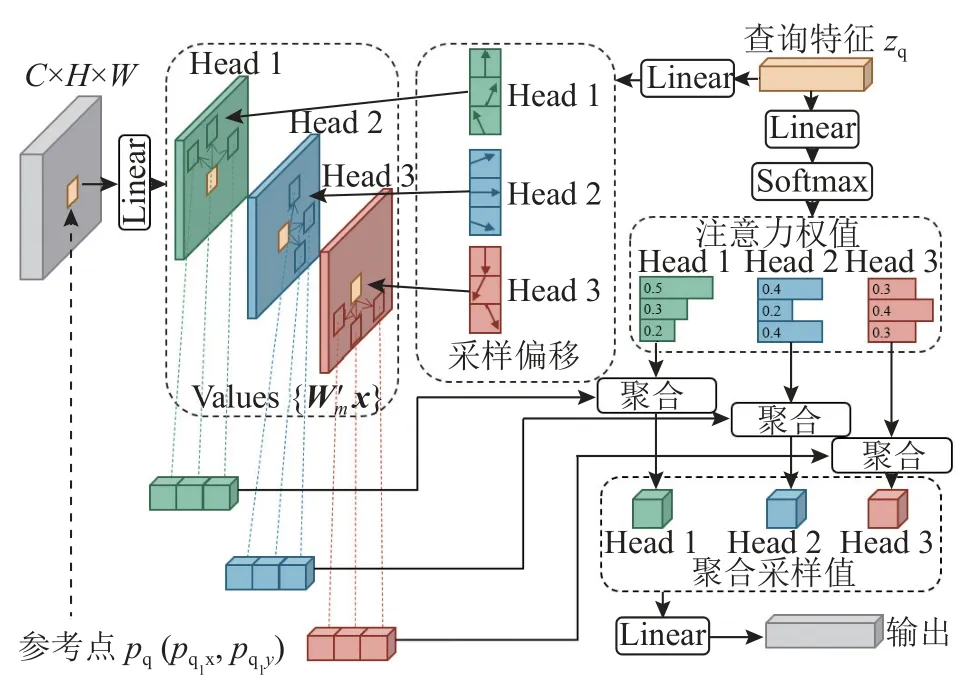
图3 可形变注意力模块Fig.3 Deformable attention module
该模块只关注查询点附近的一小部分采样点,通过每个Query 分配固定且较少的Key 来解决计算复杂度高的问题,具体计算式为
式中:K为经过Key 的总数,且K≪HW;pq为一个二维参考点; ∆pm,q,k为第m个注意力头内的第k个采样点的偏移量; ∆pm,q,k和Am,q,k都是由zq通过全连接层获得.复杂度计算式为
可形变注意力模块只关心参考点周围的一组采样点,而不用考虑特征图空间大小,复杂度不再受上游的输出特征图分辨率的影响.该模块的提出有效解决了特征图高分辨率带来的计算复杂度升高的问题,在保证准确率的情况下,提升了算法的效率.
2.3 先验知识Query 的构建
为了更好地提升分类信息的准确性,针对胸部X 光图像中可能存在的患病区域重叠问题,引入预训练的分类表征作为先验知识来引导多分类特征的学习.利用经典的ResNet+softmax 学习预训练得到的类别表征,最终可以得到初始的分类表征L={l1,l2,···,li};li=u,其中u为类别个数,li的维度为m维.此外,添加了具有可学习参数的多层感知器(multilayer perceptron, MLP)模块来优化标签嵌入.为了处理多类别信息融合,通过提出的模块将标签嵌入映射到融合的特征空间,在训练阶段,通过随机初始化操作获得初始标签嵌入L.高级标签嵌入表示为其中ω 和h为标签嵌入网络的参数,这些参数将在训练阶段被学习到,Fl作为最终的标签嵌入来指导多类别信息融合.在训练阶段结束之后,所学习到的Fl可以在下一次训练中作为初始化标签嵌入来引导特征的更新.
2.4 压缩型双注意力模块
压缩型双注意力模块(compact dual attention module, CDAM)由压缩型位置注意力模块和压缩型通道注意力模块并联组成.压缩型位置注意力模块首先获取所有位置特征的加权和,然后有选择地聚合各个位置的特征;压缩型通道注意力模块首先将所有通道特征之间的相关特征进行整合,之后有选择地强调相互依赖的通道特征.2 个注意力模块采取并联的方式,并将2 个支路的输出相加,以进一步改善特征表示.
通过增大特征图分辨率来获得更加丰富的视觉特征信息,进而提高识别精度,但增大特征图分辨率会带来较高的计算复杂度.因此,使用压缩型双注意力模块来应对这一问题,下面分别对这2 种注意力模块进行介绍.2.4.1 压缩型位置注意力模块 在原始的位置注意力模块中,为了获得任意2 个像素特征之间的关系,需要进行向量的内积运算.当像素特征较多时,会带来巨大计算量和内存消耗,为了缓解这一问题,采用压缩型位置注意力模块(compact position attention module, CPAM).CPAM 通过构建每个像素与一些聚集中心的关系来降低计算量,这些聚集中心由一个多尺度池化层获得,结构如图4 所示.
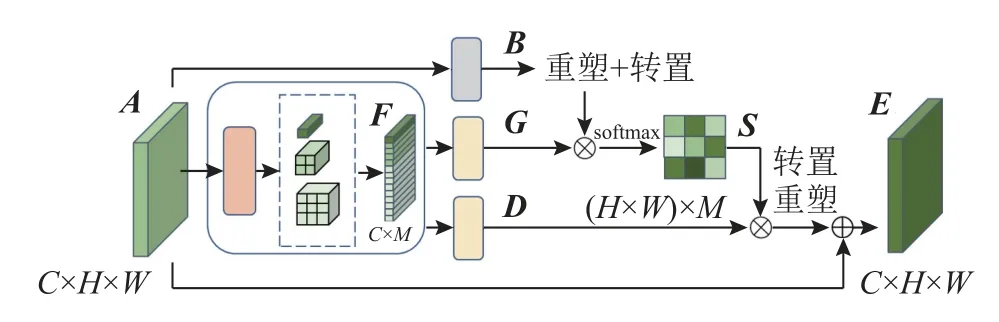
图4 压缩型位置注意力模块Fig.4 Compact position attention module
将维度为C×H×W的特征图A传入到一个由4 个自适应平均池化层和1 个1 ∗ 1 卷积层组成的多尺度池化层中.通过之后获得4 个不同尺寸的池化特征图,分别为1 ∗ 1、2∗ 2、3 ∗ 3 和6 ∗ 6(由于空间原因,图中未画出6 ∗ 6 的池化特征图),通道数仍旧为C.将池化后的特征图维度改为C×L2,为对应池化特征图的尺寸,将这些池化特征图拼接到一起,获得聚集中心特征图F∈ RC×M,其中M为所有池化特征图第二维度的和.将A传入一个1 ∗ 1卷积层和一个全连接层,获得特征图,接着改变其形状得到,其中N=H×W,为通过1 ∗ 1 卷积层改变后的维度,采用降维方式是为了降低计算量.对F进行同样的操作获得,之后对B的转置和G进行矩阵相乘操作,并通过softmax 层,得到位置注意力权重图的计算式为
式中:sj,i为第i个聚焦中心与第j个像素特征之间的关系.将聚集中心特征图F传入全连接层获得特征图D∈RC×M,得到最终输出特征图E的计算式为
2.4.2 压缩型通道注意力模块 在原始的通道注意力模块中,通过计算各个通道之间的相关性来获得通道注意力权重.当通道数较大时,会带来计算复杂度上的增加,因此引入压缩型通道注意力模块(compact channel attention module, CCAM)来解决这一问题.CCAM 与CPAM 类似,通过构建每个通道与通道聚集中心之间的关系来获得通道注意力权重,结构如图5 所示.
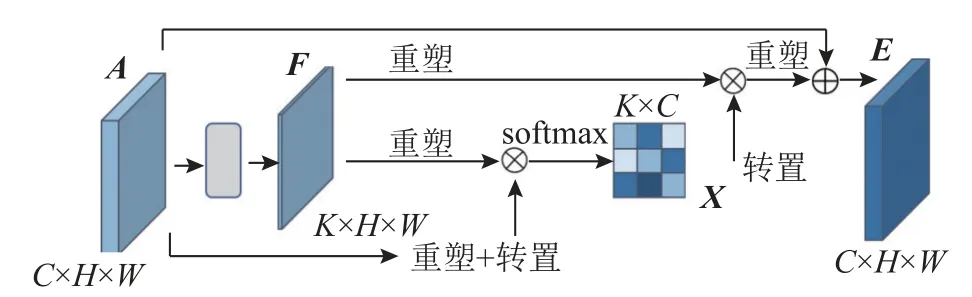
图5 压缩型通道注意力模块Fig.5 Compact channel attention module
对于输入特征图A∈RC×H×W,将其通过一个1 ∗ 1 的卷积层,获得特征图F∈RK×H×W.其中,K为通过1 ∗ 1 卷积层降低后的通道数.F的每一个通道映射都能看作一个通道聚集中心.之后的操作与CAM 一样,首先获得通道注意力映射X∈RC×K,计算式为
式中:xj,i为第i个通道聚集中心对第j个通道的影响.有选择性地将通道聚集中心整合到特征图A上,得到最后的输出特征图E,计算式为
2.5 非对称损失函数
为了解决数据集中正负样本不均衡的问题,采用非对称损失函数.在焦点损失函数[22]的基础上,解耦正样本和负样本的指数因子,可以更好地控制正样本和负样本对损失函数的贡献.本研究使用的是简化后的非对称损失函数,可以看作一种非对称聚焦损失函数,即
式中:K为类别数量,yk为图片的类别,pk为网络预测图片类别正确的概率, γ+为正聚焦参数,γ-为负聚焦参数,通常设置 γ->γ+.总损失通过对训练样本所有损失的和取平均得到,在本研究实验中, γ+设置为0, γ-设置为2.
2.6 本研究模型构建
在胸片中,灰雾现象与病变区域重叠等问题,使得病灶区域不清晰,导致诊断困难.因此,传统方法在基于胸片进行疾病的多分类任务时,表现有所欠缺.对于此类问题,本研究对模型进行针对性优化.
胸片的特征图分辨率越高,分类效果相对来说会更好.在提取特征时,删除ResNet50 最后一个残差单元的下采样,将可形变卷积作为卷积核,得到分辨率更高的特征图.考虑到病灶区域较小的疾病,采用双注意力机制对特征图进行处理,增强病变区域和非病变区域的特征差异.提高特征图分辨率必然会导致模型计算复杂度提升,因此对双注意力模块进行压缩操作,有选择地聚合位置特征和通道特征,去除特征中的冗余信息,降低模型的计算复杂度.普通Transformer需要关注整张特征图的内容,在前期提高特征图分辨率的基础上,会带来更高的计算复杂度.本研究提出可形变Transformer 提取类别相关信息,只须关注病灶周围的内容,提升模型的效率.在可形变Transformer 模块中引入预训练模型的先验知识,指导多类别信息的表征,有利于提高不同疾病在影像区域重叠情况下的特征区分度.在训练过程中,由于数据集中的部分疾病样本之间数量相差过大,容易导致正负样本不均衡问题.通过解耦正负样本的指数因子,使用非对称损失函数,控制正负样本对损失函数的贡献,弱化正负样本不均衡问题带来的影响.
3 实验结果与分析
3.1 实验数据集
采用数据集ChestX-ray14 和CheXpert 对模型性能进行评测.ChestX-ray14 是美国国立卫生研究院在2017 年发布的胸部X 射线数据集,该数据集中共有14 种常见的肺部疾病,共计112 120 张胸部X 光片.这些X 光片来自30 805 名肺部病变患者,标记了14 种疾病中的一种或多种.在数据集中,由专业的放射科医生在984 张胸部X 光图像中手工标注了患病区域,其中包含8 种疾病,如图6 所示.
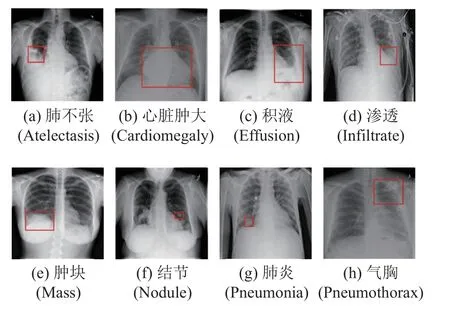
图6 8 种胸部常见疾病病变区域图Fig.6 Lesion area maps of 8 common chest diseases
CheXpert 数据集是吴恩达团队于2019 年公开的一个大型胸部X 光片数据集[23],其中包含65 240位病人的224 316 张胸片.该数据集中每张胸片共标注了14 个标签,其中12 个是心脏肥大、肺不张、肺实变等12 种疾病特征,另外2 个标签分别为未发现病灶和辅助设备.此外,每种类别有3 种标记,包括阳性、阴性以及不确定,不确定为医生仅通过X 光片还判断不出是否患有某种疾病.
3.2 评价指标
为了准确且客观地评估模型性能,选用受试者操作特征曲线(receiver operating characteristics,ROC)来反映模型对肺部疾病的分类性能.利用该曲线下的面积值(area under curve, AUC)对模型进行分析,并以此作为比较的指标,AUC 值越大,表示模型的分类性能就越好.后文为平均AUC.ROC 曲线的横、纵坐标分别为假正例率(false positive rate, FPR)、真正例率(true positive rate, TPR).FPR 为将负样本错判为正例的概率,TPR 为对正样本判别正确的概率.
3.3 与现有SOTA 算法比较
为了验证所提方法的有效性,分别在Chest X-ray14 数据集和CheXpert 数据集上与其它现存的先进方法进行性能对比实验.实验结果如表1、2所示,其中为每种方法在所有疾病上的平均AUC 值.Deformable-CDAM 为本研究的模型,表中数据加粗为该方法得到的指标经过对比为最佳指标.
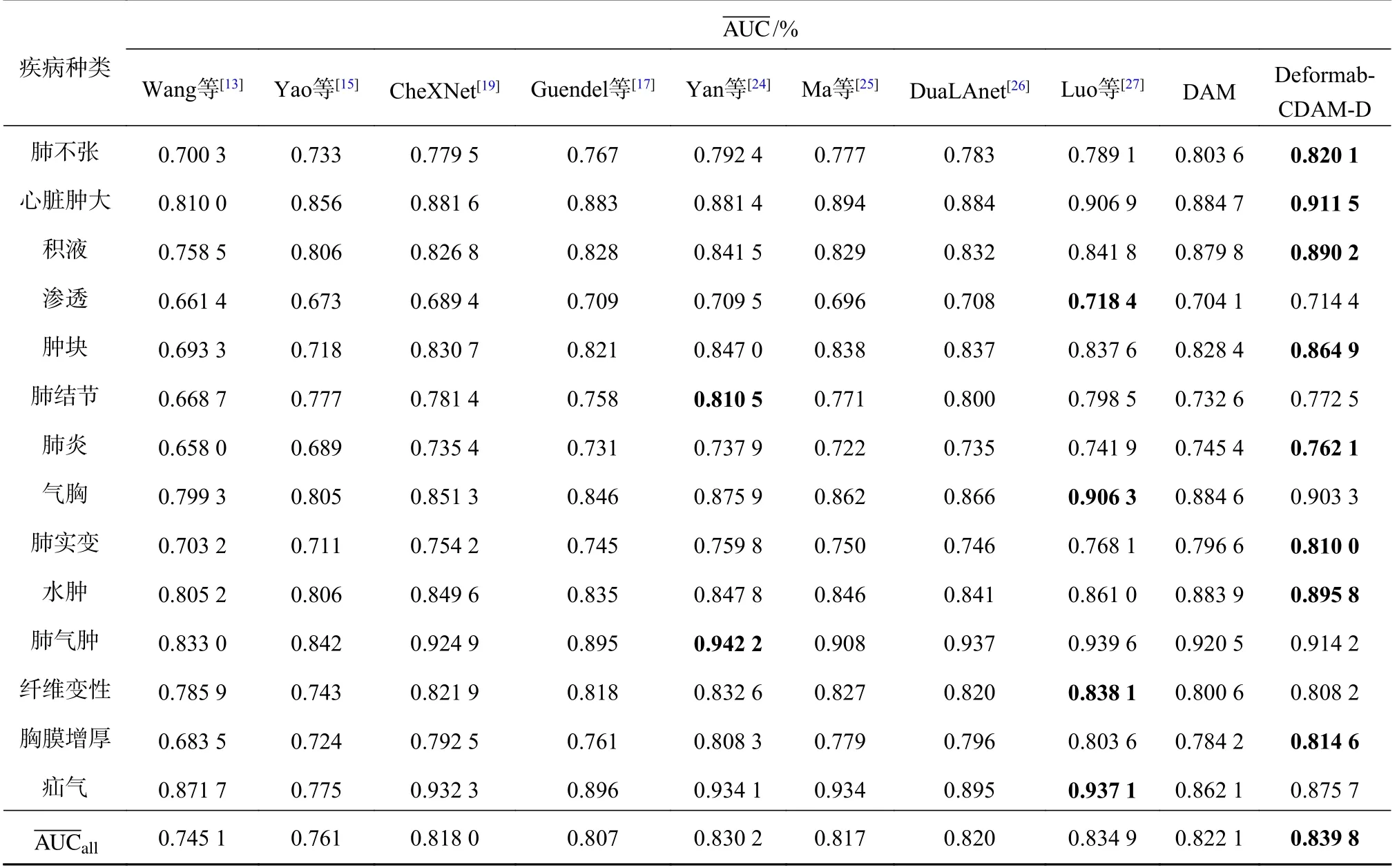
表1 ChestX-ray14 数据集上模型对各类疾病分类的性能对比Tab.1 Comparison of model performance on ChestX-ray14 dataset for classification of various diseases
由表1 可知,与对比算法相比,本研究算法有明显的性能提升,这主要是由于采用分辨率更高的医学影像信息,得益于压缩型双注意力模块和可形变Transformer 网络对算法复杂度的降低.Wang 等[13]将ImageNet 预训练后的卷积神经网络作为特征提取器,只对过渡层和分类层进行训练,最终取得较好的结果,但其并未对数据的冗余信息进行处理.Ma 等[25]提出一种多注意力网络,主干网络为ResNet101,并在主干网络中加入挤压激励模块来构建通道之间的依赖关系,还添加了空间注意力模块来融合整体与局部的信息.此外为了处理类失衡的问题采用错分样例模块,这些方式使得算法取得较好的分类结果,但是缺乏对先验知识的应用,相对于本研究的算法性能仍有一定的差距.Luo 等[27]使用多个数据集进行训练,并对不同数据集之间存在的差异进行处理,解决了域和标签差异的问题.与所提算法相比,文献[5]所提方法在部分疾病上的诊断效果较好.由于本研究采用引入先验知识等操作,从整体诊断效果上看,所提算法效果仍然占优.
在CheXpert 数据集上,采用数据集作者提出的3 种方法,即使用U-Ignore、U-Zeros 和UOnes 以及一些其他SOTA 算法来进行比较.CheXpert 作者提出的3 种方法对不确定性标签数据分别采用3 种处理方式,即忽略、当作未患病和当作患病,其中U-Ones 方法获得最高的性能表现.在处理含有不确定性标签的数据时,按照与UOnes 方法一样的处理方式.由表2 可知,在该数据集上,对于肺实变、心脏肿大2 种疾病的诊断,其他算法也取得较好的效果.这是因为主要改善的是小病灶疾病的分类,而肺实变、心脏肿大的病灶区域较大,相对容易识别,其他算法也可以获得较好的分类结果.从整体上看,本研究模型的达到90.61%,相比其他方法均有所提高,进一步证明了本研究模型的有效性和鲁棒性.

表2 CheXpert 数据集上模型对各类疾病分类的性能对比Tab.2 Comparison of model performance on CheXpert dataset for classification of various diseases
3.4 特征图分辨率对模型性能的影响
通过设置对比实验,分别在数据集ChestX-ray14和CheXperts 上对比特征图分辨率对模型性能的影响,实验结果如表3 所示.“Deformab-CDAM-D”为使用高分辨率的特征图.由表3 可知,在2 个数据集上,与使用低分辨率特征图的模型相比,使用较高分辨率特征图的模型,在指标上分别提高1.65%和1.42%,提升比较明显.这得益于提高特征图分辨率后,特征图中包含更多的特征信息,使得模型的分类性能有所提高.
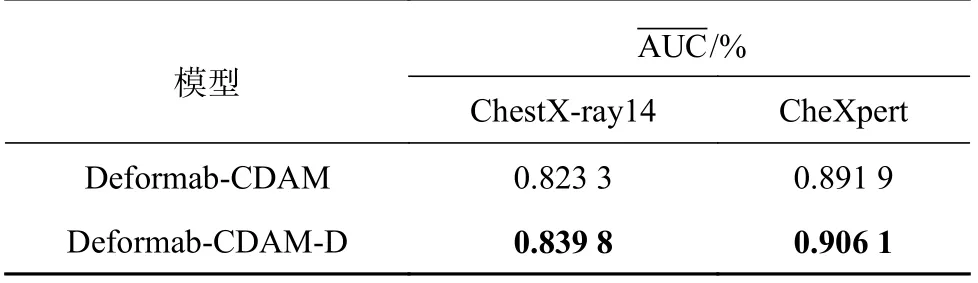
表3 特征图分辨率对模型性能的影响Tab.3 Effect of feature map resolution on model performance
3.5 先验知识Query 的构建对模型性能的影响
针对病灶区域重叠的问题,利用预训练的分类表征作为先验知识.在数据集ChestX-ray14 和CheXpert 数据集上,基于本研究模型分别设置了是否构建先验知识Query 的对比实验,实验结果如表4 所示.“null”为未进行先验知识的构建,“Query”为进行了先验知识的构建,“Query+MLP”为在进行先验知识构建的同时,添加了MLP 模块.
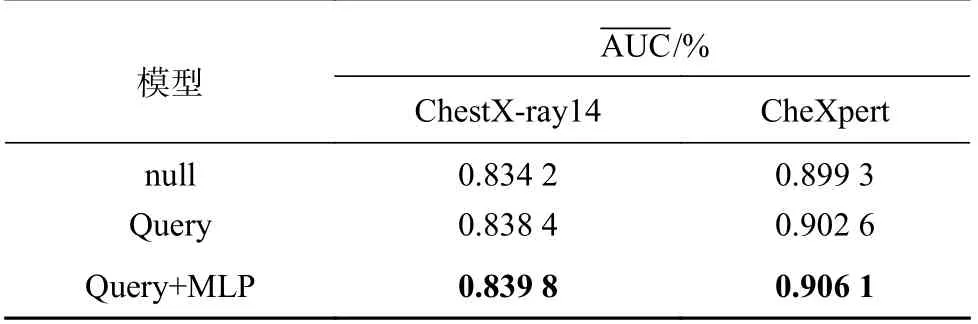
表4 先验知识对模型性能的影响Tab.4 Effect of prior knowledge on model performance
由2 个数据集上的实验结果可知,相较于未构建先验知识的模型,构建先验知识的模型的分别提高了0.56%和0.68%,具有可学习参数的MLP 模块也对模型性能提升有所帮助.结果表明,引入先验知识对多类别的表征起到指导作用,使模型分类的准确性得到相应的提高.
3.6 消融实验
为了验证可形变Transformer 和压缩型双注意力模块对于模型性能的影响,分别在ChestXray14 数据集和CheXpert 数据集上进行消融实验,共进行4 组实验:第1 组的模型结合原始Transformer 和压缩型双注意力模块;第2 组的模型结合可形变Transformer 和原始双注意力模块;第3 组的模型结合可形变Transformer 和压缩型双注意力模块,前3 组实验均采用预训练的label embedding 信息来引导学习影像特征;第4 组实验与第3 组实验不同之处在于,采用的是随机生成的label embedding 信息来学习影像特征.实验结果如表5 所示.
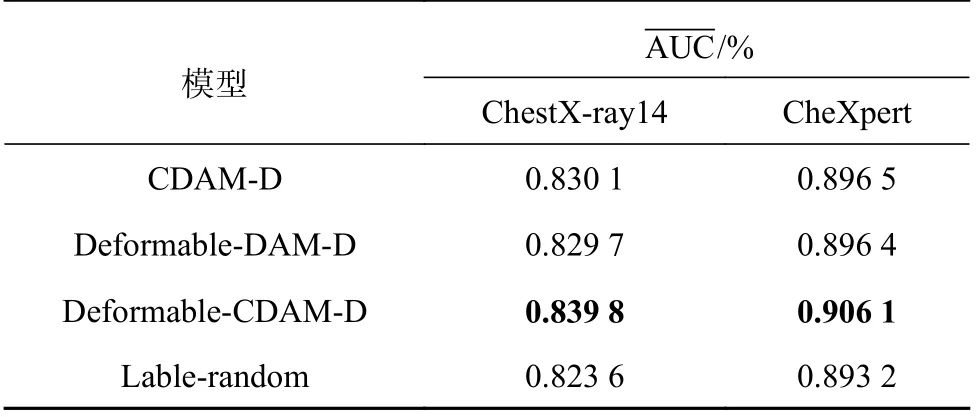
表5 不同模块对模型分类效果的影响Tab.5 Effect of different modules on model classification performance
对比1、3 这2 组结果可知,与原始Transformer相比,使用可形变Transformer 的模型的指标在2 个数据集上分别提升了0.97%和1.04%,因此使用可形变Transformer 对分类性能有一定的提升.对比2、3 这2 组结果可知,在模型架构与其他模块相同的情况下,使用压缩型双注意力模块可以一定程度上提升算法的分类准确率.由3、4 这2 组实验的比较可以看出,预训练模型信息的引入有效地提升了算法的性能,证明了引入预训练模型的必要性.
本研究还验证了可形变Transformer 和压缩型双注意力模块对模型计算复杂度的影响.实验采用与上述消融实验相同的实验分组,用模型处理单张胸部X 光片的处理时长反映其计算复杂度.实验结果如表6 所示,其中T为处理时长.
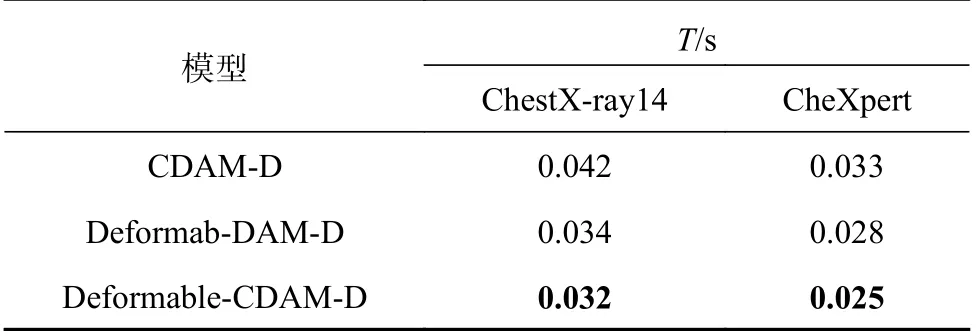
表6 消融实验不同模型处理时长对比Tab.6 Comparison of different models processing time in ablation experiments
对比1、3 这2 组实验结果可知,使用可形变Transformer 的处理速度是原始Transformer 的1.3 倍,在与原始Transformer 取得近似分类精度的同时,又在处理速度上有所提升,这体现了可形变Transformer 的高效性.对比2、3 这2 组实验结果可知,使用压缩型双注意力模块的模型计算复杂度相对较低,可以证明该模块的有效性.
3.7 损失函数对模型性能的影响
设置对比实验,将本研究模型分别在ChestXray14 数据集和CheXpert 数据集上进行实验,比较不同损失函数对模型性能的影响,结果如表7 所示.由表中数据可以看出,在2 个数据集上,使用非对称损失函数的均为最优.由此表明,使用非对称损失函数可以在一定范围内解决正负样本不均衡所带来的问题,提升模型的分类性能.

表7 不同损失函数对模型分类效果的影响Tab.7 Effect of different loss functions on model classification performance
3.8 病灶区域可视化
通过加权梯度类激活映射(Grad-CAM)方法来证实模型的有效性[31],生成病灶定位热图,使网络在识别肺部疾病时有位置依据.Grad-CAM 方法对模型参数进行加载,然后采用梯度加权平均的方式处理特征图权重,进而可以生成热图.图7展示了8 种疾病的医生标注图与其对应热图,热图中颜色越红的地方表示越接近病灶区域,医生标注的病变位置为长方形边框.经过图7 的对比可以发现,热图所确定的位置基本与专业放射科医生标出的位置相同,这表明模型根据X 光片诊断肺部疾病时依据的特征信息是可靠的.
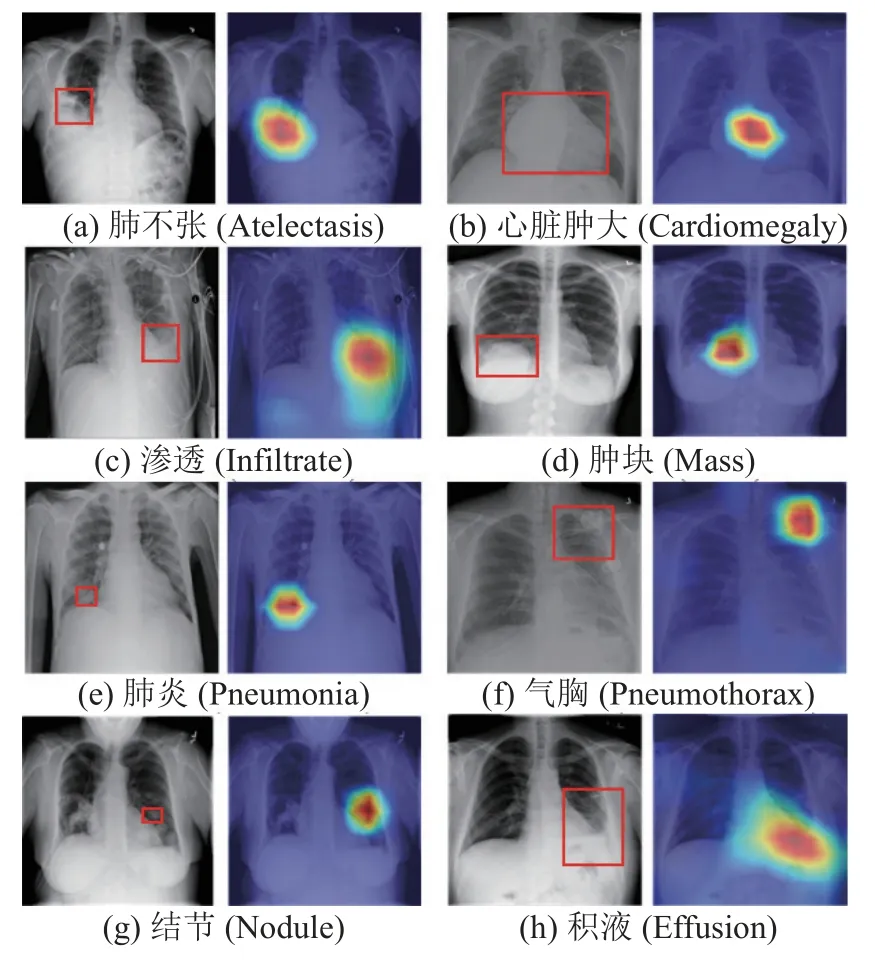
图7 医生标注病变区域(左)与Grad-CAM 热力图(右)对比图Fig.7 Comparison between doctor’s marked lesion area (left) and Grad-CAM heat map (right)
4 结 语
基于预训练模型提出一种可形变Transformer和压缩型双注意力模块的胸部X 光图像分类模型.该模型通过提高特征图的分辨率以获取更加丰富的特征信息;针对框架本身对小目标对象识别差的问题,引入压缩双注意力模块,增强病变区域和非病变区域特征差异,减少冗余信息,有效提高肺结节、肿块以及肺炎等较难识别疾病的分类精度,降低了模型的计算复杂度;利用可形变Transformer 解码器内部的交叉注意模块,使用预训练模型的类别表征信息作为先验知识,有效地提取与类别相关的特征,也极大地降低了计算复杂度和内存占用;模型引入非对称损失函数,用以解决正负样本不均衡所带来的问题,进一步提高了分类精度.通过实验与SOTA 算法的对比,证明了所提方法具有有效性和实用性.
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09
中国惯性技术学报(2019年6期)2019-03-04
车迷(2018年11期)2018-08-30
海峡姐妹(2018年3期)2018-05-09
传媒评论(2017年3期)2017-06-13
中央民族大学学报(自然科学版)(2017年2期)2017-06-11
第二课堂(课外活动版)(2016年2期)2016-10-21
公民与法治(2016年10期)2016-05-17
火控雷达技术(2016年3期)2016-02-06
计算机工程(2015年8期)2015-07-03
