
基于混合特征提取的细粒度图像识别方法
2023-10-21 06:49:14李明峰邵琳钰蔡昌利
南昌大学学报(工科版) 2023年3期
李明峰,邵琳钰,蔡昌利
(1.上海理想信息产业(集团)有限公司,上海 201200; 2.北京邮电大学信息与通信工程学院,北京 100876)
图像识别是计算机视觉领域的基础任务和重要研究方向。随着相关研究的不断深入,更具挑战性的细粒度图像识别任务受到了越来越多的关注。细粒度图像识别的目标是准确地区分一个大类下的多个子类别,例如区分图1中3种形态十分相似的鸟类。相较于一般的图像识别任务,细粒度图像识别具有类间差异小、类内差异大的特点。具体来说,类间差异小是指,不同子类的对象具有相似性,需要通过一些关键的区域(以鸟类为例,如鸟嘴、翅膀、爪子等部分区域)来加以区分,然而标注关键区域会增加额外的标注成本;类内差异大是指,同一个子类中,由于姿势、背景、光线以及拍摄角度等因素的不同,对象之间差别相对较大。细粒度图像识别的实际应用非常广泛,如图1中提到的鸟类分类[1],以及针对零售商品[2]、车辆[3]、真菌[4]等对象的分类任务,并且很多工业缺陷分类与医学计算机体层摄影(computed tomography,CT)图像分类任务也可以归为细粒度图像识别问题。

(a) 钩嘴鸟 (b) 黑脚信天翁 (c) 凤头海雀
针对上述提到的细粒度图像识别问题的特点和难点,目前已经进行了大量的研究工作。早期的细粒度图像识别算法[5-7]主要基于包含强监督信息的图像数据进行训练,除了图像的类别信息之外,还需要使用额外的人工标注信息(如针对鸟嘴翅膀等关键区域的标注点以及对象标注框等)。然而标注需要一定的专家知识以及额外的标注成本,制约了方法的实际应用,例如在CT图像中准确地标注病变部位需要专业的医生。
近年来,基于弱监督信息的细粒度图像识别方法[8-20]的识别能力已经逐渐超过基于强监督信息的方法,并成为细粒度图像识别问题研究的主流方向。这类方法只需要图像标注信息,减少了对于额外标注信息的需求,降低了实际应用难度。最新的研究主要集中在以下方向:1)模型结构优化,Lin等[8]首先提出了基于双支路网络B-CNN的特征提取器,近期的许多工作基于它进行了改进[12-13]。此外,部分研究使用Transformer网络代替CNN[14-16],如Dosovitskiy等[14]提出了用于图像分类的ViT方法,He等[15]则进一步设计了专用于细粒度图像分类的Transformer网络TransFG。Wang等[17]则关注了中间层特征对性能的影响。部分模型引入了注意力机制,如Sun等[18]提出压缩多激励(OSME)模块来学习多个注意区域特征,然后在度量学习框架中应用多注意多类约束(MAMC)进行分类,Ji等[19]基于二叉树结构搭建注意力网络模型,这些方法有效地提升了识别精度,但复杂的网络结构也极大地增加了训练开销。2)网络流程优化,如Zhou等[9]提出了LIO,将自我监督整合到传统框架中来针对对象进行查看。Chang等[20]从损失函数入手,保持网络结构不变,设计了MC-loss方法,Chen等[21]提出的解构-重构学习(destruction and construction learning,DCL)直接将训练图像进行区域打乱,增强局部细节,并使用了一种对抗损失来区分原始图像和破坏图像,然而这些方法是非端到端的,训练过程中涉及大量的图片裁剪和放大操作,大大增加了训练难度。已有研究主要依靠设计复杂网络或者流程来捕获精细特征,没有考虑训练过程对该问题的重要性,本文针对细粒度图像识别类内差异大、类间差异小的问题开展研究,提出了更为有效的训练方式以及网络模型。
Mixup[22]被广泛应用于图像识别领域的网络正则化以及数据增强方向。通过混合数据来生成虚拟样本,从而达到扩充数据的效果,能够有效改善过拟合问题,提升模型对于图像识别的性能和鲁棒性。并且生成的虚拟样本往往能够包含多个类别的特征信息。受此方法启发,本文提出将模型中间层输出的特征图进行混合,借助Mixup思想提取类间和类内的特征信息。
非局部(Non-local,NL)模块通常被用来捕获图像不同位置的依赖关系以及生成注意力权重[23-24]。最新的研究将其应用于细粒度图像识别领域,如刘洋等[25]将非局部模块与Navigator进行结合,加强模型的全局信息感知能力; Ye等[26]通过NL模块将具有不同的感受野的深层神经元与多个浅层神经元相关联,使深层可以从浅层中学习到更具区分性的多尺度特征。然而,多尺度特征融合增大了训练开销,且模块的迁移性较差。
针对细粒度图像识别问题类内差异大、类间差异小的问题,本文引入Mixup思想来比较不同的图像,从而提高模型对图像的辨别能力[27-28],突出不同类别的区分性特征和相同类别的共有特征。并在需要混合的网络中间层后加入NL模块捕获特征信息。考虑到Mixup方式在获取特征信息的同时,也带来了噪声和歧义,因此,本文设计了与训练过程耦合的多损失函数来优化该问题。
1 网络模型
本文的网络模型总体架构如图2所示,首先,设计混合非局部增强(MixupNon-local,MNL)网络,通过Mixup混合NL模块提取的网络中间层特征,然后通过Adaptor在训练过程中动态调整多损失函数提升模型鲁棒性,下文将详细介绍模型的设计流程。
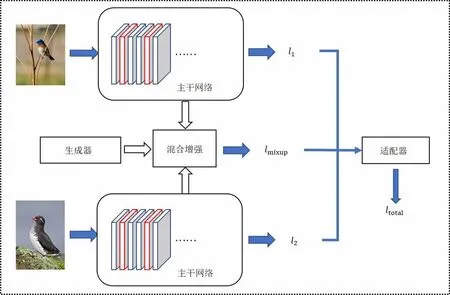
图2 网络总体架构Fig.2 Overall structure of the network
1.1 Mixup
Mixup是计算机视觉中常用的数据增强方法,其主要思想如下。
如图3所示,对于任意的2个标记数据样本(xi,yi)和(xj,yj),其中xi、xj为图像样本,yi、yj为对应标签的one-hot表示,通过线性插值混合2个样本,从而创建新的虚拟训练样本,公式表示如下:

图3 Mixup生成虚拟样本Fig.3 Generate virtual samples by Mixup
(1)
(2)
其中λ∈[0,1]。
通过Mixup方法混合不同的样本,可以扩充训练样本数量,且生成的样本能够让模型通过对比进行训练学习,能够直接优化细粒度图像识别中类内差异大、类间差异小的问题。
但是原始的Mixup仅考虑了底层特征信息,忽视了深层的语义特征信息。而底层特征的混合会产生歧义,容易影响高层语义特征的学习。因此,本文提出对卷积神经网络中不同深度的中间层特征图进行混合,从而更好地获取特征信息。
同时,考虑到直接对网络中间层的输出进行混合,缺少了对特征的提取和保存,容易导致训练欠拟合。因此,首先在骨干网络需要进行混合的中间层之后插入NL模块,通过混合NL模块的输出结果,指导其提取和保存类内与类间的特征信息。
1.2 NL模块
本节详细介绍了NL模块的结构、功能及其在骨干网络中的应用。
在神经网络中,卷积运算通常只能提取局部相关性,使网络很难捕获大范围或者全局中不同位置的联系。而NL模块可以很好地获取全局中不同位置之间的依赖关系,联系多个相关的区域特征,且不会改变输入特征的维度,其结构如图4(b)所示。因此,我们在骨干网络(以ResNet-50为例)的多个瓶颈(Bottleneck)(ResNet的基本组成结构,其结构如图4(c)所示)之间插入多个NL模块,提升网络对于不同尺度全局依赖关系的获取能力,并用于保存类内和类间的特征信息。插入NL模块后的骨干网络总体结构如图4(a)所示。
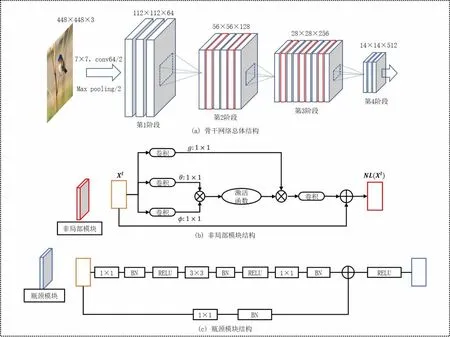
图4 ResNet-50+5NL模块结构图Fig.4 Architecture of ResNet-50+5NL module
结合文献[26]中的定义,对于第l个Bottleneck模块,Hl、Wl和Cl分别表示其输出特征图的高度、宽度和通道数。将特征表示为Xl∈RHlWl×Cl(粗体大写字母表示矩阵,所有非粗体字母表示标量。特征的上标表示相应层的索引)。为了获取特征Xl中局部位置之间的全局依赖关系,首先通过3个可学习的变换函数θ(·)、φ(·)和g(·)对Xl进行特征变换,将其投影到新的特征空间中。然后,通过函数f(·,·)计算θ(Xl)和φ(Xl)的相关性以获得全局的依赖关系,再经过softmax函数将其转换为注意力权重。将生成的注意力权重与g(Xl)相乘,获得最终的全局依赖关系,最后,通过变换函数z(·)将结果投影到原本的特征空间并与特征Xl叠加,FNL(Xl)的具体计算过程如下:
FNL(Xl)=Xl+z(f(θ(Xl),φ(X))g(Xl))
(3)
式中:θ(·)、φ(·)、g(·)和z(·)通常实现为1×1卷积,θ(·)、φ(·)、g(·)对特征X做降维处理,z(·)将结果复原到原本的特征维度,以保证与特征X的维度一致性。f(·,·)函数为嵌入高斯函数,公式如下:
f(θ(X),φ(X))=eθ(Xl)Tφ(Xl)
(4)
1.3 MNL模块
本节中将Mixup思想与NL模块相结合,提出了本文模型的主要结构——MNL模块,结构如图5所示。

图5 MNL模块结构图Fig.5 Overall structure of MNL module
首先,选取2个样本(xi,yi)和(xj,yj),xi、xj为图像样本,yi、yj为其对应标签的one-hot表示,将xi、xj分别输入网络中。根据骨干网络不同尺度卷积层的特征提取能力,我们选择了N个不同深度的中间特征层,并在每个特征层后插入与之匹配的NL模块,编号为NLm,其中m∈[1,N]。在训练阶段,随机选取一个NL模块,如NLM,2个图像样本经过NLM后的输出特征分别为:
(5)
(6)

层后的输出特征,θM(·)表示NLM中的θ(·)函数,φM(·)、gM(·)同理。

(7)
其中λ由生成器(Generator)模块产生,参考Chen等[28]的设置,在实验中Generator会针对每个批次从Beta分布中采样混合参数λ以完成特征的混合:
λ~Beta(β,β)
λ=max(λ,1-λ)
(8)

(9)
式中:p(·;φ)为MNL模型的分类器,φ为分类器参数。分类器由全局平均池化层(global average pooling,GAP)、全连接层(fully connected layer)以及Softmax层组成。
对于训练过程中的每一个批次的数据,都会随机选取NL模块并进行特征混合,以保证不同深度的NL模块都能够学到对应不同尺度的特征信息。
1.4 多损失函数
本质上,训练过程中通过Mixup方式生成的虚拟样本分类任务相比原任务更加复杂。增强的任务与原目标任务实际上并不相同,即训练过程与测试过程并不完全匹配。因此,本文提出了MNL+Adaptor架构,通过设计与训练过程耦合的多损失函数来优化Mixup带来的问题,其中Adaptor模块负责在训练过程中调节增强任务与目标任务的权重。
如图2所示,模型的损失由2部分组成,即输入的2个批次经过MNL模块的预测损失LMNL以及各自的预测损失Li和Lj,总损失函数如下:
Lt=αLMNL+(1-α)Li+Lj
(10)
式中:α由Adaptor模块产生。Adaptor内部实现为与训练步数s相关的函数f(s),f(·)可由一个或多个递减函数组成和实现,本文中选取了指数函数,f(s)公式如下:
(11)
式中:S为总训练步数;a为外部参数,用于调整变化速率。
在训练开始时,α=1,Adaptor模块控制模型以虚拟任务为主要任务,随着训练过程的进行,α逐渐趋于0,Adaptor模块将训练任务重心偏向于目标任务,降低Mixup带来的影响。
1.5 训练流程
首先,将成对的数据分别输入插入了NL模块的骨干网络;接着在MNL模块中,通过Mixup将NL提取的网络中间层特征进行混合,并分别计算原始预测与混合预测的损失函数;然后通过Adaptor动态调整多个损失之间的权重,得到混合的预测损失,最后通过反向传播更新骨干网络的参数。
2 实验与分析
2.1 实验设置
实验选用ResNet-50作为骨干网络,并在其res2模块与res3模块中分别插入2个和3个NL模块。训练和测试过程中,将输入图像的大小统一调整为448×448,为了权衡模型收敛与NL模块收敛的速度,训练过程只选取了第一、三、五个 NL模块进行混合。论文的方法使用PyTorch框架实现,训练使用4张Tesla V100-SXM2 GPU,批次大小设置为64。适当提高批次的大小有利于提升算法的鲁棒性。Beta分布的超参数β设置为0.75,初始学习率设置为0.001,每20个训练轮数(epoch)学习率乘以下降系数0.1,使用Adam作为网络优化器,共训练120个epoch。
2.2 性能评估
本文在CUB-200-2011[1]和Stanford Cars[3]数据集上进行了实验。表1为数据集的详细信息。

表1 细粒度数据集详情Tab.1 Statistics of fine-grained datasets
其中,CUB-200-2011包含200个鸟类子类别,由5 994张训练图像和5 794张测试图像组成。Stanford Cars包含了196个汽车类别,由8 144张训练图片和8 041张测试图片组成。我们在2个数据集上将本文方法与多个细粒度图像识别方法进行对比,结果如表2、表3所示。

表2 在CUB-200-2011数据集上的细粒度分类结果Tab.2 Fine-grained classification results on the CUB-200-2011 dataset
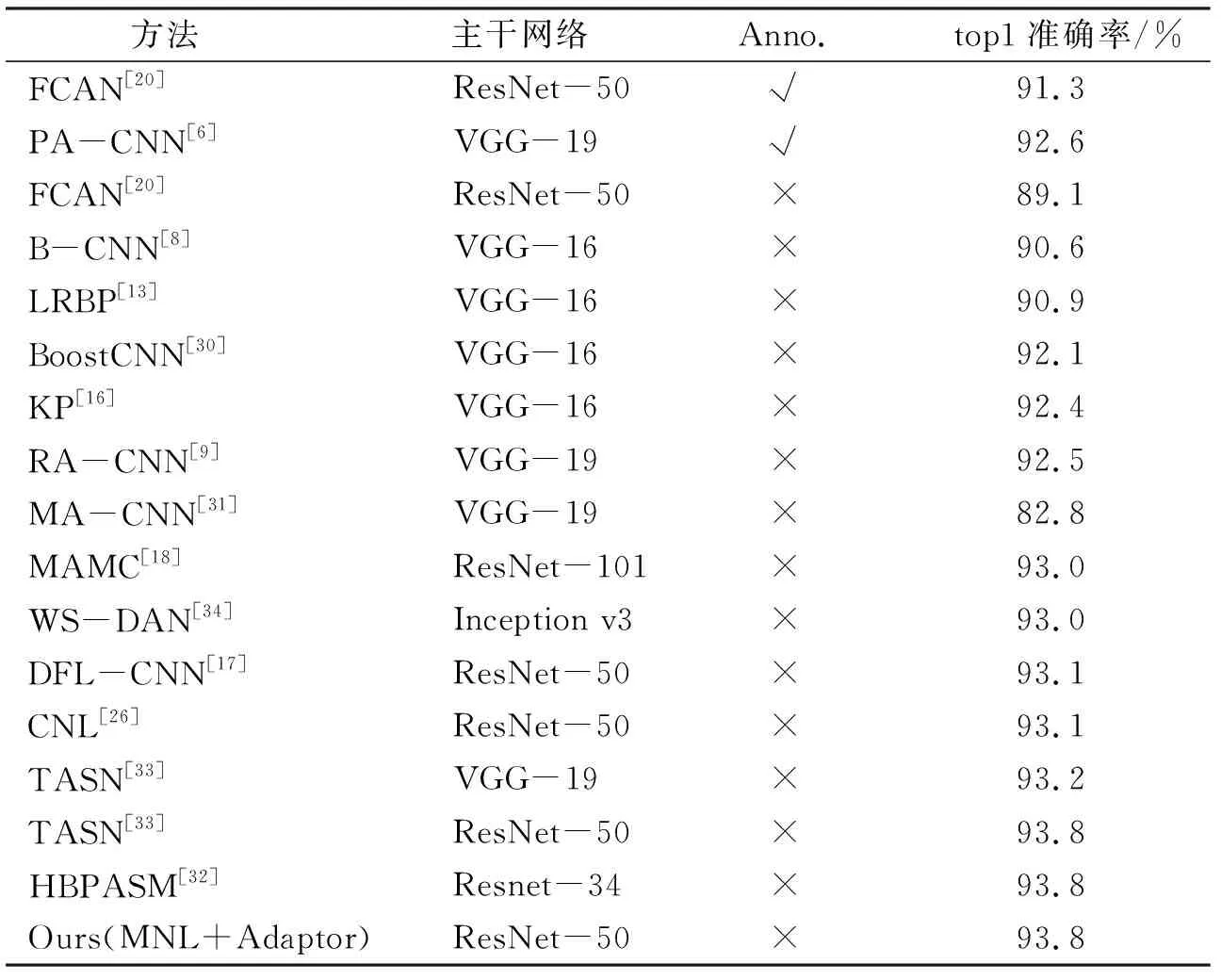
表3 在Stanford Cars数据集上的细粒度分类结果Tab.3 Fine-grained classification results on the Stanford Cars dataset
首先,依据是否有区域标注将方法分为2类,并且为了更好地对比,本文给出了每种方法使用的骨干网络。论文提出的MNL+Adaptor模型在CUB-200-2011和Stanford Cars上分别达到了87.4%与93.8%的top1识别精度,相较于基于强监督信息的方法(如FACN和PA-CNN等)有明显提升,并超过大量基于弱监督信息的算法。在使用相同骨干网络(ResNet-50)的情况下,MNL模型的识别精度优于多个最新的方法(如MCL和CNL等),并且与同样针对NL模块进行改进的CNL方法相比,论文模型保留了NL模块即插即用的优点,无须对骨干网络模型进行大量修改,可以动态地调整NL模块的嵌入。
2.3 消融实验
为了进一步验证算法的有效性,我们在CUB-200-2011数据集上研究了论文模型中不同模块对预测性能的影响。表4中展示了模型各个模块或方法对模型预测的top1、top5准确率以及模型参数量与计算复杂度的影响。

表4 在CUB-200-2011上的消融实验结果Tab.4 Experimental results of ablation on CUB-200-2011
从性能角度分析,与作为基线的ResNet-50网络模型相比,在ResNet-50中嵌入NL模块提高了1.05%的top1准确率。只使用Mixup对原始数据进行数据增强提高了1.23%的top1准确率并提高了1.21%的top5准确率。而将Mixup数据增强方法与NL模块进行简单的结合后,虽然依旧能够提高性能,但是提升效果并不明显。这是由于插入的NL模块的参数是随机初始化的,没有加载预训练参数,而Mixup方法对原始图像进行增强经过网络的层层传播,只能隐式地训练NL模块,并不能直接指导NL模块的参数学习,导致结合的效率低下。而论文提出的MNL主体结构在基线上提升了2.3%的top1准确率,更加有效地训练了NL模块,提取并保存了类内与类间特征信息。此外,基于论文方法部分对于Mixup方法弊端的分析,论文提出的与训练过程耦合的损失函数使模型识别精度达到了87.42%,有效地改善了训练过程。
从复杂度角度分析,相比于ResNet-50,本文方法在提升性能的同时增加了参数量与计算量,但该增加量主要来自于NL模块,证明本文提出的方法在不增加额外参数量的情况下有效发挥了NL模块的性能。同时,相比于大型网络ResNet-101,本文方法在参数量与计算量更少的情况下达到了更高的性能。
2.4 热力图对比分析
为了直观地分析各个模块对于模型性能的影响,在本节中使用Grad-CAM方法可视化了不同情况下模型的关注区域。通过热力图可以解释模型的分类依据,并分析每个模型的优缺点。如图6所示,从CUB-200-2011中选取了黑脚信天翁和黑背信天翁2个类别的部分图片进行可视化,由于这2种类别有着很高的相似度,因此能够更好地展示模型提取细粒度特征的性能。

图6 不同模型的热力图分析Fig.6 Heatmap comparison of different models
嘴部的白色圆环是黑脚信天翁的显著特征,并且头部也是区分其与黑背信天翁的主要部位。相比于ResNet-50,Mixup、MNL以及MNL+Adaptor均对该位置有更高的关注,并且ResNet-50的高响应注意力中包含了更多的背景区域,覆盖了更大的范围。而Mixup的高响应注意力多次出现在了尾部等非关键区域,说明在对原始图片进行混合时,图片关键区域发生叠加可能会影响图片的概念,比如头尾重叠等等。而MNL网络通过混合网络中间层经过NL模块处理过的特征图,有效地缓解了这一问题。在方法部分我们提出,引入了Mixup思想的任务相较于原任务更加复杂,通过热力图可以发现,损失函数中加入的Adaptor虽然并不能使MNL模型对于关键部位的识别更加集中,但却能够降低模型对于翅膀、身体以及尾巴等非关键部位的关注度,减少Mixup引入的噪声和歧义,改善模型的训练过程。
3 结论
本文引入了Mixup思想来提升细粒度图像识别的准确率,提出了基于混合特征提取的细粒度图像识别方法。相较于传统的Mixup方式,本文首先设计了MNL网络架构,通过混合不同深度的网络中间层的输出特征来指导网络的学习过程,并在网络中插入多个NL模块来进一步提取和保存不同尺度的类内和类间特征信息,显式地优化了类内差异大、类间差异小的问题。同时,MNL保留了NL模块即插即用的优势,能够与各种基准网络进行结合,具有很好的可迁移性。此外,本文设计了Adaptor模块进一步优化MNL,通过在训练过程中动态调整多损失函数的比重,减少了Mixup带来的噪声和歧义,合理控制了训练任务的复杂度。论文在多个公开的数据集上实验并验证了MNL+Adaptor模型架构的有效性。
猜你喜欢
红外技术(2022年11期)2022-11-25 03:20:40
现代装饰(2022年5期)2022-10-13 08:47:36
高技术通讯(2021年1期)2021-03-29 02:29:24
数学小灵通(1-2年级)(2020年4期)2020-06-24 05:47:08
电子制作(2019年16期)2019-09-27 09:34:50
中国交通信息化(2019年4期)2019-07-13 05:51:34
电子制作(2018年19期)2018-11-14 02:37:04
电子制作(2018年14期)2018-08-21 01:38:16
电脑与电信(2018年11期)2018-02-16 05:41:32
作文周刊·小学一年级版(2016年23期)2017-06-05 23:27:03
