
基于音视频特征融合的婴幼儿哭泣检测方法研究∗
2023-10-20 08:23周娴玮龚启旭余松森
计算机与数字工程 2023年7期
刘 朋 周娴玮 龚启旭 余松森
(华南师范大学软件学院 佛山 528225)
1 引言
哭泣是婴幼儿早期表达感情的主要手段,研究发现识别婴幼儿哭泣具有一定的可行性:婴儿声音在早期相似,随着年龄增长逐渐个性化[1]。此外通过对婴儿哭泣进行实时监测可以降低父母的看护负担,具有一定的研究价值。在此背景下我们研究一种音视频融合的方法来进一步提高婴幼儿哭泣的识别精度。
婴儿监护在啼哭检测方面有不少的研究进展。啼哭检测相关研究最早可以追溯到20世纪60年代,Wasz-Hockert[2]等通过分析婴儿的啼哭语音特征。来判别婴儿是否健康。Abdulaziz[3]等基于前馈神经网络结构和共轭梯度算法对婴幼儿哭声进行分析,并发现在婴儿哭声方面使用MFCC 比LPCC效果更出色。Yizhar Lavner等[4]和Rafael Torres 等[5]使用语谱图作为输入,训练卷积神经网络CNN 识别婴儿啼哭,获得了相比较SVM 更好的效果。谢湘等[6]发现语谱图相比较听觉谱更适合婴儿哭泣检测网络的学习,并使用ResNet 神经网络识别婴儿哭泣,获得了相比较卷积网络和SVM 更好的效果。
在上述研究中,针对婴幼儿啼哭的识别只是从声音单个角度考虑,实际上婴儿哭泣的时候在表情和动作上相比较生活中的正常状态有很大的区别,面部表情和肢体动作也是啼哭状态的重要信息。在一些领域如情感识别、暴力检测中,多模态方式被提出来并且得到了不错的效果。因此可以考虑结合多模态识别是否存在婴儿哭泣。多模态融合中,音视频融合主要分为特征层融合[7]和决策层融合[8]。特征层融合将音视频分别进行特征提取,在特征网络末端进行时序同步融合后再去分析,例如在文献[9]中,提出采用CNN 加CNN的方法对音视频进行特征提取,特征层融合后放入长短期记忆网络中训练,该方法在RECOLA数据集上进行验证取得了78.87%的识别率。而决策层融合不要求特征具有严格的时序性,可以单独对单个模态进行测试之后再设置决策规则加权各独立网络的识别结果,得出一个更泛化的结果[10]。例如文献[11]中采用通用背景模型再结合openSMILE 对音视频信息进行特征提取并进行了决策层融合,在实验数据集中取得了77.5%的准确率。
基于之前工作,可以发现音视频融合网络结合声音和图像分析问题时增加输入数据的维度能够进一步提高识别准确率。而该融合网络在婴幼儿领域研究暂无的主要原因是公开数据集不足,本文通过YouTube 公开的URL 标签制作婴儿哭泣音视频数据集。此外由于各个视频帧速度的差别导致输入音视频的时序不同步,若忽略这一问题会导致识别精度较差。在此情况下设计一种算法实现时序上的近似同步。最后我们提出设计一种多模态网络架构,其网络框架如图1 所示,使用3DCNN 提取视频特征,CNN提取音频特征。将两个子网络提取的时间连续性特征进行特征层融合后在LSTM网络中识别分类。实验中我们将该网络架构与单模态的SVM、CNN、3DCNN、LSTM 网络、不使用3DCNN 以及不使用LSTM 的多模态网络架构进行比较,证明模型的可用性。

图1 特征层融合网络架构图
2 音视频数据处理
2.1 音频特征提取
2.1.1 音频预处理
原始音频由于信号的参数不一致等原因无法直接进行特征提取,需要对声音数据进行图2 所示的采样、归一化、预加重、分帧加窗处理一系列预处理。通过上述的步骤提高音频特征提取的质量。

图2 音频预处理流程
2.1.2 音频特征提取
研究发现婴儿的啼哭不同于成人的发声,在频域上有急剧上升、中间平稳再急剧下降的规律性[14],因此使用频域的特征进行建模可以进一步提高识别效率,此外神经网络可以直接从声音信号中归纳特征。本文通过上述两种方式进行音频特征的提取。
方法1 提取基于先验知识的声音特征,该方法统计样本数据的短时能量、基音频率、MFCC 及其1阶2阶差分均值和方差,共82维度数据。
方法2 通过卷积神经网络[15]自动提取特征。由于婴幼儿哭泣在频域上与成人的区别较大[14],我们使用原始信号的N(ms)*128 维度频谱图作为输入,卷积网络参照文献[18],第一层设置5*5 的卷积核,步长为1,输出8 张特征图,每一层卷积添加2*2的最大池化层。经过4层卷积池化之后平铺层参数为196,若设置6层卷积池化输出维度太低,难以保证特征的有效性。因此综合考虑使用4 层卷积较为合适,其模型架构如图3。

图3 CNN特征提取网络(预设N为100ms)
2.2 视频特征提取
2.2.1 视频预处理
视频由视频帧和音频组成,其包含的信息大小相比较图片和声音有指数级的增加,视频不经过预处理直接提取特征会导致特征网络训练速度缓慢、提取效果较差。本文视频预处理具体步骤如下。
统一视频参数:视频信号中主要参数帧宽,帧高,声音采样率和通道数要保持一致。由于实验数据不是统一标准的数据集,帧率不统一。如果直接剔除帧率不一致的样本会导致数据大幅度减少,针对这一情况提出一种算法拟合时序。
其中frames代表视频的总帧数,times为视频的总时间长度,Audiotimes 为声音样本单次输入的时间长度,最大为4s,inputframes 为声音样本输入时对应的视频帧长度。经过式(1)计算得出视频取帧的间隔D,按照间隔D 对视频进行帧提取,既保持帧数量的一致,又解决了视频帧与语音不同步的问题。
缩放与灰度化:视频帧原始大小320*240,总共有76800*3个像素点,使用Opencv对图像进行等比例缩放得到64*64*3的视频帧,最后将RGB图像三通道的数值进行均值化,转换为单通道的灰度图像。上述两个步骤数据量约缩小56 倍,进一步降低了网络训练难度。
2.2.2 视频特征提取
视频流特征提取的经典方法DT 和IDT[16]在处理上特征比原始视频还要大,因此本文基于相关工作中的音视频融合方法,采用图像CNN 和3DCNN两种方法提取视频流特征。
方法1:对预处理后的视频帧数据使用深度卷积网络提取特征,其结构同图3,将语音样本的时间段内对应所有视频帧分别输入,将所得的所有全连接层取均值,作为时间段内视频样本的特征向量。
方法2:采用3D 卷积网络,3DCNN[17]相比较2D卷积网络增加一个时间维度,可以捕捉视频中的时间信息。3D 卷积将多个连续帧同一感受野特征映射到特征图中,该结构中卷积层每个特征图都会与上一层连续帧相关联,进而捕捉到运动的信息。
本文3D CNN 架构如图4 所示:2 层3D 卷积、2层下采样和1 层全连接,输入N 张大小为64*64 的连续帧。模型的设计参照3D卷积大小效果对比实验[19],3*3*3 和5*5*3 规格的3D 卷积核效果突出。卷积网络层数的确定主要依据3D卷积单模态前期实验,适配合适大小池化后2 层3D 卷积输出的维度数量为3200 较为合适,若卷积层数增加会导致平铺(flatten)层输出显著减少,影响提取的特征和识别精度。最终我们将128 维全连接层作为3DCNN提取的特征。

图4 3DCNN网络结构(inputframes取7帧)
3 端到端CNN+3DCNN+LSTM 多模态融合网络
数据各个模态之间具有多种联系,如果把这种联系切断从单个模态考虑问题会导致数据信息丢失,因此多模态是人工智能研究的一个关注点。在此背景下,本文提出一种多模态网络结构解决婴儿哭泣判断问题,其网络设计架构如图1 所示。 音频CNN 网络提取4 次1s 的声音特征(图3)。视觉3DCNN提取4次1s内7帧视频的特征(图4)。子网络特征提取后对8 个128 大小的全连接层级联为4*256 大小的时间序列数据,一同并入LSTM 网络,得出最终的预测结果。该方法融合了时间和空间两种维度的特征,有效地保证模型的精度。此外,基于以上的数据处理工作,我们还得到了CNN 提取的视频特征和82 维度的声学传统特征。这两种特征将在比对实验中用到。
4 实验与结果分析
4.1 数据集制作
实验中使用的正样本数据来自AudioSet[12]项目,AudioSet 包含从YouTube 视频中搜集的632 个音频事件类。涵盖了广泛的人类和动物声音,以及常见的日常环境声音。本文通过AudioSet 数据集的目录获取2370 个婴儿哭声数据的YouTube 下载地址和10s 声音时间戳。由于一些视频被用户取消器上传导致无法下载且该数据集标签准确率低,需要清洗,最终我们得到了1400 份高质量的婴儿哭泣4s 视频。反样本使用和婴幼儿生活环境相关的数据,从UCF101 数据集[13]收集乐器、婴儿爬行、尖叫等101 种人类动作,在数据集每个类别中随机取60 条作为反样本,共6050 条。初始反样本中有大量时间不够、帧率不足、无音频参数的数据,经过清洗后得到1600 个样本。将所有样本统一转换成时间长度4s 的视频和音频两种类型,最终得到如表1数据集分布。
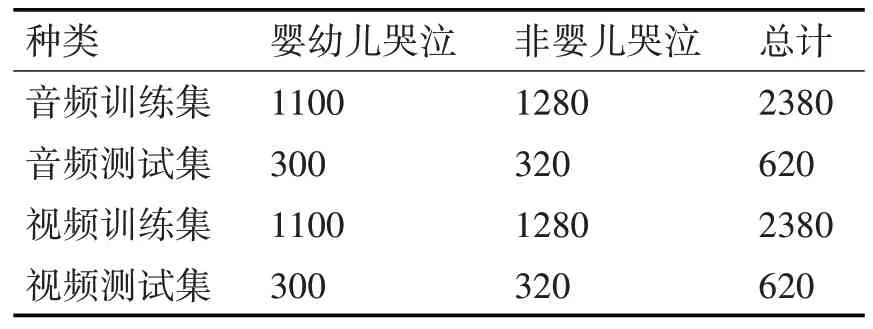
表1 数据集数量分配表
4.2 实验结果
本文在Intel(R)Xeon(R)CPU @ 2.00GHz 型号cpu,12G 内存,Tesla T4 型号GPU 环境下进行实验,为了验证本文中提出的多模态融合网络的可行性,7 个对照试验与之进行比对。所有的实验采用GPU 加速,RMSProp优化方法进行收敛。具体实验方法如下。
方法1:音频特征+SVM 模型,参照文献[6]中的对比实验,实验中使用不同的核函数。
方法2:语谱图+CNN 模型,参照文献[18],以婴幼儿哭泣频谱图作为输入数据,卷积神经网络识别,并设计3种卷积数量不同的实验。
方法3:N 帧视频流+3DCNN 模型,视觉单模态实验,与声音识别效果对比。
方法4:语谱图+LSTM 模型,使用包含时间序列信息的频谱图输入到LSTM中识别。
方法5:设计CNN+CNN+Full Connection(FC)对比实验,采用图3 中介绍的卷积网络分别提取声音和视频的特征,特征级联后在全连接网络学习,该实验的结果作为多模态实验的基准线。
方法6:文献[9]的CNN+CNN+LSTM模型。
方法7:参照方法5设计CNN+3DCNN+FC。
方法8:CNN +3DCNN++LSTM(本文提出的音视频融合方法)。该网络由2.1.2 节中CNN 网络提取声音语谱图的抽象特征,2.2.2 节中3DCNN 提取视频特征。audiotimes取1s,inputframes取7帧去设置视频提取间隔,最终提取到4个1s时间段的融合序列特征放入LSTM训练识别。
实验结果如表2所示。
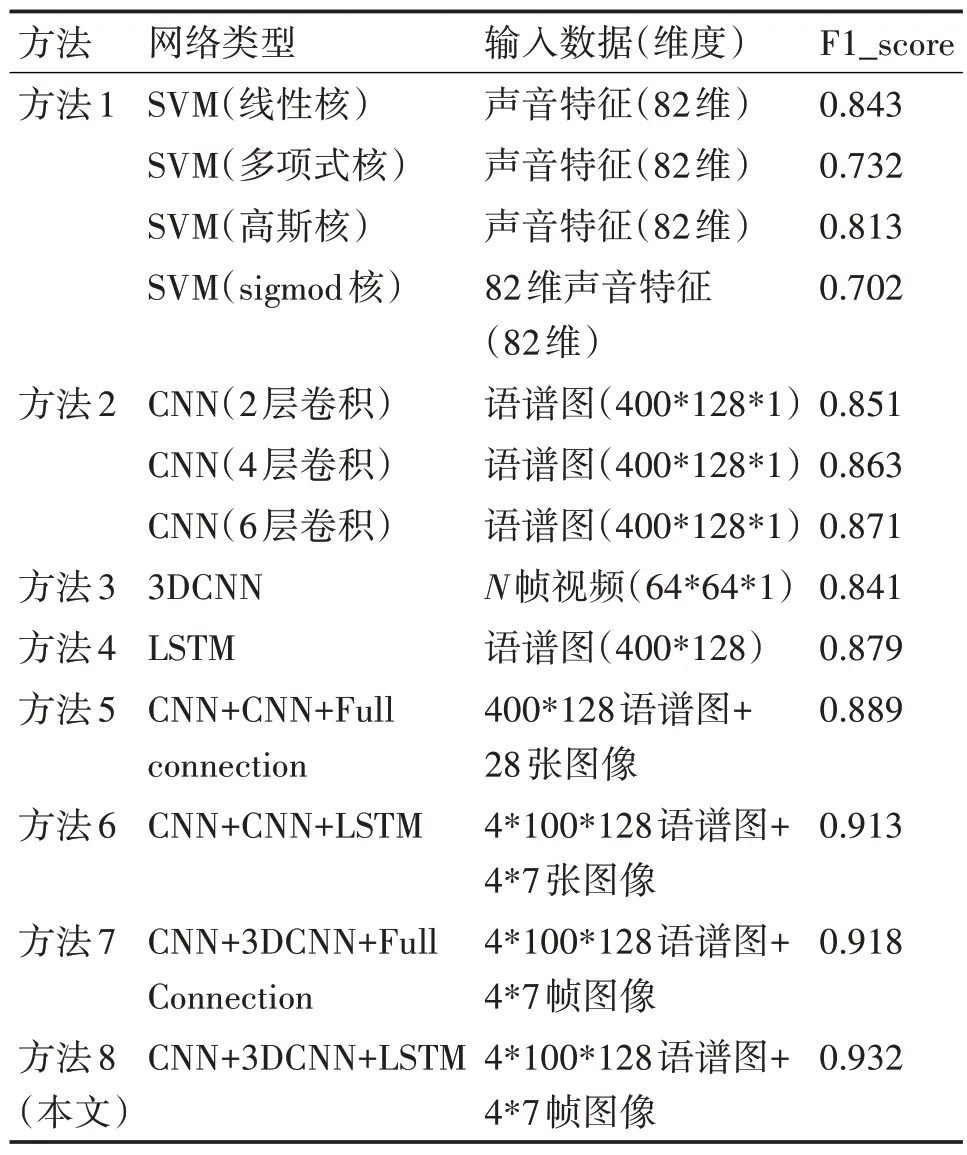
表2 各实验F1分数对比表
4.3 结果分析
根据表中各方法的结果对比信息,单模态实验中LSTM 的F1 分数最高,达到了0.879,这说明LSTM能够较好地捕捉时间序列数据中的信息先验特征,值得一提是成人声音特征与婴幼儿哭泣上有明显的区别,线性核SVM 可以很好地进行区分。单模态中F1 分数紧随其后的是卷积神经网络,卷积神经网络可以从语谱图中自动学习到需要的特征,获得了相比较支持向量机更好的精度,这也是之前相关研究首先考虑卷积的一个原因。单模态视频帧识别方法3DCNN 并不如识别声音效果好,且尝试增加卷积层数和修改卷积核时间维度会导致识别精度有所下降。分析原因发现正样本数据集中常有成人行动的画面,只通过视频识别确实存在一定量难以辨认的正样本数据。
多模态网络实验中方法8 相比较方法6,F1 分数高1.9%,这说明在其他网络结构相同的情况下3维卷积相比较2 维卷积能够捕捉视频时间特征,F1分数更高。方法6、8 中融合层采用长短期记忆网络相比较采用全连接层的方法5、7,F1 分数平均高2%,证明了长短期网络在处理时间序列数据中的优势。本文提出的方法CNN+3DCNN+LSTM 能够同时兼顾到时间和空间特征,充分利用了数据中包含的信息,因此F1分数最高,达到了93.2%。
5 结语
本文依据AudioSet 项目制作了日常生活中婴幼儿哭泣音视频数据集,相比较特定情况下搜集的数据集具有更好的实际意义,此外在提取特征时提出了一种解决数据集中样本帧率不一致的算法,最后我们设计音视频融合网络架构,通过实验表明该网络架构F1 分数比单模态最优方法高5.3%、比多模态基线系统高出4.3%。证明该方法在婴幼儿哭泣识别领域的特征提取和任务识别能力。未来工作计划与医院合作收集更详细的数据,针对婴幼儿哭声病理进行分析,这也是当前婴幼儿监护领域的难点。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02
家庭影院技术(2019年7期)2019-08-27
电子制作(2019年11期)2019-07-04
电子制作(2018年19期)2018-11-14
电子制作(2018年12期)2018-08-01
北京航空航天大学学报(2018年1期)2018-04-20
中国交通信息化(2017年2期)2017-06-06
自动化学报(2017年11期)2017-04-04
噪声与振动控制(2015年4期)2015-01-01
声学技术(2014年1期)2014-04-08
